Элементарные основы
Def. Статистическая гипотеза – некое суждение о свойствах случайной величины. Проверка статистической гипотезы – процедура сопоставления выбранной гипотезы с имеющимися экспериментальными данными, сопровождаемая количественной оценкой степени достоверности полученного вывода.
Пример 2.1. Согласно паспортным данным автомобильного двигателя, расход топлива на 100 км должен составить 10 л. Испытано 25 машин. Средний расход топлива составил 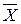 = 9.3 л. Известно, что расход топлива – СВ Х с известной дисперсией s2 = 4 л2. Проверить гипотезу: mx = 10 л.
= 9.3 л. Известно, что расход топлива – СВ Х с известной дисперсией s2 = 4 л2. Проверить гипотезу: mx = 10 л.
Обозначим Н0 – выдвигаемая гипотеза. Идея проверки состоит в вычислении по результатам эксперимента некоторой статистики К = К(Х1, …, ХN) – статистического критерия, обладающего следующим свойством: если гипотеза Н0 верна, то случайная величина К имеет строго определенный закон распределения. Чтобы проверить, справедлив ли в действительности этот закон, вся область V значений критерия К разбивается на две части: VКР – критическая область (область отклонения гипотезы) и V \ VКР – область принятия гипотезы.
Область VКР подбирается так, чтобы при предполагаемом законе распределения выполнялось равенство P(K Î VКР / Н0) = a, т.е. вероятность попадания К в VКР при верной гипотезе Н0 равна заданному числу a.
При малом значении a вступает в силу следующий принцип: маловероятное событие в единичном испытании практически невозможно. Практическим подтверждением справедливости этого принципа является игра «Русская рулетка».
Значит, если в результате эксперимента событие (K Î VКР) не выполнится, то гипотезу следует принять. В противном случае ее надо отвергнуть, т.к. при верной гипотезе данное событие практически невозможно, а если наступило – то гипотеза не верна.
Построение оптимальной критической области. При сформулированном подходе VКР не может быть определена однозначно, т.к. при любом законе распределения существует бесконечно много областей, вероятность попадания в которые равна заданному числу (см. рис. 2.1). Следовательно, метод нуждается в доработке. Для этого введем понятия ошибок I и II рода.
|
Def. Ошибка I рода состоит в отклонении верной гипотезы. Ошибка II рода состоит в принятии неверной гипотезы.
Чтобы понять разницу между этими понятиями – обратимся к примеру.
Пример 2.2. Система ПВО засекла летящий самолет. Гипотеза Н0 – самолет вражеский. В данном примере ошибка I рода состоит в том, что при верной гипотезе она была отвергнута, и вражеский самолет пропустили на свою территорию. Ошибка II рода – гипотеза была неверна, но её приняли, в результате чего был сбит свой самолет. Приведенный пример, в частности демонстрирует, что, как правило, цена ошибок I и II рода различна.
В принятых обозначениях PI = P(KÎVКР / Н0) = a – вероятность ошибки I рода; PII = P( KÎ(V \VКР) / 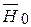 ) = b – вероятность ошибки II рода.
) = b – вероятность ошибки II рода.
Принцип оптимального выбора VКР состоит в следующем: при заданном уровне PI = a вероятность ошибки II рода должна быть минимальна (b ® min или 1– b® mах). Чтобы можно было оценить величину b, наряду с основной гипотезой Н0 выдвигают конкурирующую гипотезу Н1 = , отвергающую основную.
Вернёмся к примеру 2.1. При основной гипотезе Н0: mx = 10 л выдвинем конкурирующую, например Н1 : mx = 9 л. В качестве статистического критерия примем 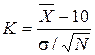 . При нормальном распределении СВ Х с параметрами mx = 10, D[X] = s2 , т.е. при верной гипотезе Н0, выбранный критерий К распределен нормально с параметрами mК = 0, D[K] = 1. Если же предположить, что верна гипотеза Н1, то случайная величина К имеет тоже нормальное распределение, но с параметрами D[K]=1,
. При нормальном распределении СВ Х с параметрами mx = 10, D[X] = s2 , т.е. при верной гипотезе Н0, выбранный критерий К распределен нормально с параметрами mК = 0, D[K] = 1. Если же предположить, что верна гипотеза Н1, то случайная величина К имеет тоже нормальное распределение, но с параметрами D[K]=1,
mК = 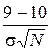 =
= 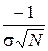 = –2,5. (2.1)
= –2,5. (2.1)
Обозначим VКР = [s, t ]. При заданном значении s величина t определяется из уравнения
P(KÎ[s, t ]) = a = U(t) – U(s), (2.2)
где U(х) 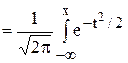 – функция Лапласа (функция нормального распределения или интеграл вероятности). Отсюда
– функция Лапласа (функция нормального распределения или интеграл вероятности). Отсюда
t = U(–1)[a + U(s)].
Иными словами, t является (a + U(s))- квантилем нормального распределения. В MathCad эта формула вычисления t имеет вид:
t:= qnorm(a + pnorm(s, 0, 1), 0, 1). (2.3)
Вероятность ошибки II рода равна
b = P( (KÏ VКР ) / H1 ) = P[KÎ( (–¥, s) 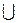 (t, +¥) )]= P[KÎ(–¥, s)] + P[KÎ(t, +¥)].
(t, +¥) )]= P[KÎ(–¥, s)] + P[KÎ(t, +¥)].
С учётом (2.1) значение b в MathCad вычисляется с помощью формулы
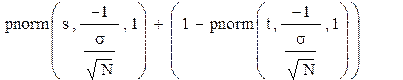 (2.4)
(2.4)
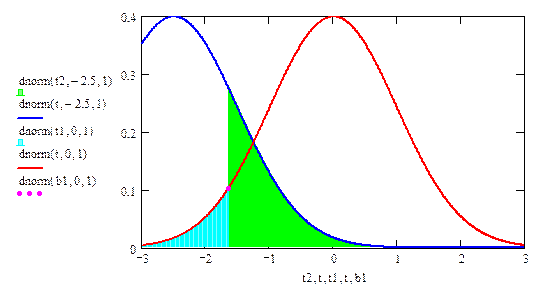
Теперь для нахождения оптимальной критической области надо определить значение s, при котором соблюдается условие (2.2) (т.е. (2.3)), а выражение (2.4) минимально. Несложно вычислить, что при a = 0.05 получим sopt = –¥, topt = – 1.64485, т.е. VКР = [–¥, –1.645]. Такая область называется левосторонней. При такой критической области b = 0.1962. На рис. 2.2 графически показаны значения a и b, найденные по формулам (2.2) и (2.4) при оптимальных границах критической области..
Def. Гипотеза вида q = b, где b – фиксированное число, называется простой.
При ней однозначно определяется распределение анализируемой СВ Х.
Def. Гипотеза вида q Î В, где В – фиксированное множество, называется сложной.
Например, гипотезы q < a, q ¹ a (а – число) – сложные.
Пусть в примере 2.1 основная гипотеза имеет вид mx = 10. Тогда при любой простой конкурирующей гипотезе mx = b, где b < 10, критическая область будет иметь ту же структуру, что и при конкурирующей гипотезе mx = 9. То есть будем иметь левостороннюю критическую область VКР = (– ¥, ta), где квантиль ta определяется из условия Р(К £ ta) = a. Следовательно, при сложной конкурирующей гипотезе mx < 10 критическая область будет такой же, см. рис. 2.3.
|
Соответственно, при сложной конкурирующей гипотезе mx >10 оптимальная критическая область будет правосторонней, т.е. VКР = ( t1– a, + ¥), где t1– a определяется из условия Р(К < t1– a) = 1 – a или Р(К ³ t1– a) = a. При a = 0.05 будет t1– a = 1.64485.
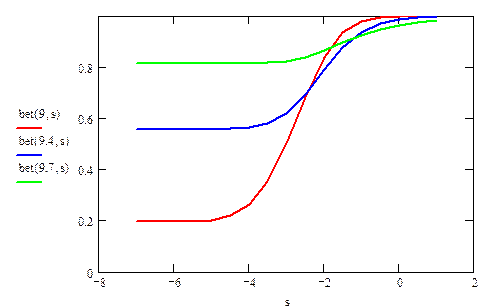


 Рис 2.3. Значение b(s) при различных простых конкурирующих гипотезах: – mХ = 9; – mХ = 9.4; – mХ = 9.7. Минимум везде достигается при s = – ¥
Рис 2.3. Значение b(s) при различных простых конкурирующих гипотезах: – mХ = 9; – mХ = 9.4; – mХ = 9.7. Минимум везде достигается при s = – ¥
Наконец, при сложной конкурирующей гипотезе mx ¹ 10 оптимальная критическая область будет двухсторонней, т.е.
VКР = (– ¥, ta/2)  ( t1– a/2, + ¥),
( t1– a/2, + ¥),
где t1– a/2 определяется из условия Р( К ³ t1– a/2) = a/2 и Р( К < ta/2) = a/2. При a = 0.05 будет t1– a/2 = 1.95997 а ta/2 = –1.95997.
Дата: 2019-02-25, просмотров: 337.