| xi | 2 | 6 | 8 | 12 | 16 | 21 | 24 | S |
| f i | 1 | 2 | 3 | 6 | 4 | 3 | 1 | 20 |
В данном примере Мо=12, так как именно этому значению признака соответствует наибольшая частота f=6.
В предыдущей теме был рассмотрен пример построения сгруппированного распределения (таблица 5).
Таблица 5
| № п/п | Xi (начало и конец интервалов) | fi | Fi |
| 8 | 104—112 | 5 | 38 |
| 7 | 95—103 | 5 | 33 |
| 6 | 86—94 | 4 | 28 |
| 5 | 77—85 | 7 | 24 |
| 4 | 68—76 | 9 | 17 |
| 3 | 59—67 | 4 | 8 |
| 2 | 50—58 | 2 | 4 |
| 1 | 41—49 | 2 | 2 |
| S=38 |
В этом распределении можно указать лишь модальный интервал значений признака: Мо=68–76, так как этому интервалу соответствует наибольшая частота f=9.
Если признак измерен по шкале порядка (ординальной шкале), значения признака могут быть выражены уже числами, которые отражают выраженность свойства (большее число соответствует большей выраженности свойства, меньшее — меньшей). Поэтому с числами в шкале порядка уже можно производить простейшие арифметические операции, складывать, вычитать, умножать, делать. Однако результаты этих вычислений следует интерпретировать с осторожностью, потому что в этой шкале не существует «эталонной» единицы измерения, неизменной единой на всех участках шкалы.
В качестве мер положения (или мер центральной тенденции) используются мода и различные квантили, а в качестве мер изменчивости, помимо дифференциальных и накопленных частот, применяется полуинтерквартильное отклонение и квартильный коэффициент асимметрии.
Квантили — значения признака, которые делят выборку на определенное количество равных частей.
Наиболее распространенные квантили — это медиана; квартили Q 1 , Q 2 , Q 3 (делят выборку испытуемых на 4 равные части); децили D 1 , D 2 , D 3 , D 4 , D 5 , D 6 , D 7 , D 8 , D 9 (делят выборку испытуемых на 10 равных частей); процентили Р1 ……….Р99 (делят выборку испытуемых на 100 равных частей).
Рассмотрим наиболее часто используемый параметр — медиану.
Медиана (Median) — Ме — это значение признака, которое делит выборку испытуемых на две равные части: 50 % испытуемых имеют значения признака меньше медианы, 50 % испытуемых имеют значения признака больше медианы; медиана является частным видом квантилей.
Медиану можно найти двумя способами:
А) Визуально, находя значение признака в упорядоченном ряду, которое делит выборку испытуемых на две равные части. Этот способ используется при небольшом числе испытуемых, когда упорядочивание всех значений признака в выборке не представляет трудности.
Если число испытуемых нечетное, медиана равна какому-то данному среднему значению. Например, в выборке из 7 человек значения признака были следующие: 89, 95, 105, 118, 121, 126, 132. Ме=118.
Если число испытуемых четное, медиана находится как среднее арифметическое двух средних значений (эта оценка медианы, конечно, приближенная). Например, 89, 95, 105, 118, 121, 126. Ме= 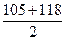 =111,5.
=111,5.
Б) По формуле, которая используется для табулированного или сгруппированного ряда:
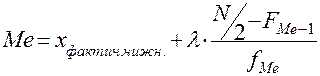 , где
, где
Ме — медиана
Xфактич.нижн.— фактическое нижнее значение признака в интервале медианы
l — длина интервала
N — объем выборки
FМе-1 — частота, накопленная к интервалу медианы, т. е. из предшествующего медиальному интервала
fМе —абсолютная частота в интервале медианы (медиальном интервале)
Произведем вычисление медианы для сгруппированного распределения, рассмотренного в предыдущей лекции.
Таблица 5
| № п/п | Xi (начало и конец интервалов) | fi | Fi |
| 8 | 104—112 | 5 | 38 |
| 7 | 95—103 | 5 | 33 |
| 6 | 86—94 | 4 | 28 |
| 5 | 77—85 | 7 | 24 |
| 4 | 68—76 | 9 | 17 |
| 3 | 59—67 | 4 | 8 |
| 2 | 50—58 | 2 | 4 |
| 1 | 41—49 | 2 | 2 |
| S=38 |
Для того чтобы вычислить медиану необходимо, прежде всего, определить в каком интервале она будет находиться, то есть в каком интервале располагается половина выборки. Воспользуемся для этого столбиком накопленных частот Fi.
Как видно, из таблицы 4, медиана будет находиться в 5-м интервале, потому что именно внутри него располагаются 18-й и 19-й испытуемые, между значениями которых и находится медиана.
Далее нужно найти первое слагаемое в формуле — фактическое нижнее значение признака из того интервала, в котором находится медиана.
Нижнее значение 5-го интервала 77. Необходимо проверить первичные данные и убедиться в том, что данное значений действительно встретилось у испытуемых. Если это произошло, то оно подставляется в формулу. В нашем примере вы можете убедиться в том, что такого значения признака у испытуемых не встречалось. В этом случае проверяется следующее по величине значение из этого интервала — значение 78. Такое значение у испытуемых было, и поэтому именно оно подставляется в формулу в качестве фактического нижнего значения признака в интервале медианы.
Объем выборки равен 38.
Частота, накопленная к интервалу медианы, FМе-1 берется из интервала, предшествующего медиальному, то есть из 4-го интервала. Она равна 17.
Абсолютная частота в интервале медианы (медиальном интервале) fМе равна 7.
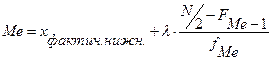 или если подставить значения:
или если подставить значения:
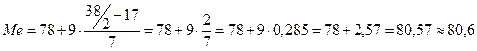
Для симметричных распределений медиана совпадает с модой, для асимметричных — не совпадает. Медиану рассматривают как цент рассеивания значений порядковой переменной.
Такие квантили как квартили (Quartiles) и процентили (Percentiles) вычисляются по формулам, очень похожим на формулу медианы. Мы их рассматривать не будем, но при необходимости эти формулы всегда можно найти в учебниках, например, Суходольского Г. В.
Изменчивость признаков, измеренных по шкале порядка, можно характеризовать и такой величиной как размах распределения. Эта меря является приближенной, она показывает лишь область существования (экспериментально выявленная) признака в данной выборке. Очевидно, что чем больше размах, тем больше и рассеивание значений признака относительно медианы. Однако при одном и том же размахе рассеивание значений в выборке может быть более или менее «кучным».
Более «чувствительной» к реальному рассеиванию является такая мера как полуинтерквартильное отклонение или междуквартильный размах. Оно вычисляется по формуле:
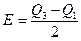 ,
,
где: Е — полуинтеквартильное отклонение;
Q3 и Q1 — третий и первый квартили.
Для симметричных распределений отклонения первого и третьего квартилей от медианы равны друг другу: Ме– Q1= Q3– Me; для асимметричных распределений эти отклонения не равны: Ме– Q1≠ Q3– M е. На этом и основана оценка асимметрии распределений.
Мерой асимметрии является квартильный коэффициент асимметрии, который определяется по формуле:
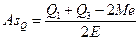 ,
,
где: AsQ — квартильный коэффициент асимметрии;
Q1 — первый квартиль;
Q3 — третий квартиль;
Ме — медиана;
Е — полуинтерквартильное отклонение.
Из этого уравнения несложно установить, что для симметричных распределений этот коэффициент равен 0, для асимметричных он будет отличаться от 0 и иметь какой-либо знак: + или –.
При скошенности распределения влево (рис. 1) квартильный коэффициент асимметрии больше 0, при скошенности распределения вправо (рис. 2) квартильный коэффициент асимметрии меньше 0. Поэтому скошенность (асимметрию) влево называют положительной, а скошенность вправо — отрицательной.
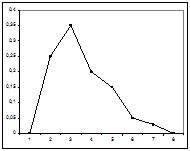 Рис.10. Левосторонняя асимметрия
Рис.10. Левосторонняя асимметрия
| 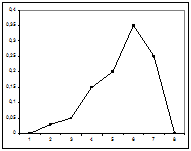 Рис. 11. Правосторонняя асимметрия
Рис. 11. Правосторонняя асимметрия
|
Однако в практике обработки результатов психологических исследований (в публикациях результатов исследований) эти параметры изменчивости, как правило, не приводятся, видимо, и не рассчитываются.
Чаще, если объем выборки достаточной большой и/или измерительная шкала «длинная», отходят от строгости канонов обработки: и для признаков, измеренных по шкале порядка, рассчитывают такие параметры как среднее арифметическое и стандартное отклонение. Эти параметры мы рассмотрим далее.
В заключение следует сказать о том, что такие параметры как мода, медиана, процентили нередко используются в качестве статистических норм в психодиагностических методиках (параметры определяются в результате исследования на выборке стандартизации, которая согласно психометрическим рекомендациям должна быть не менее 200 человек). Поскольку эти параметры рассчитываются на основе накопленных частот, то они очень хорошо показывают место данного испытуемого с его каким-то конкретным значением в выборке стандартизации.
Перейдем к описанию результатов количественного измерения. Прежде всего, напомним, что при количественном измерении происходит соотнесение эталонной единицы измерения с объектом. В результате измерения мы получаем число, которое указывает, сколько эталонных единиц измеряемого свойства содержится у объекта. При таком измерении с числами допустимы любые арифметические операции.
В качестве мер положения, кроме рассмотренных в предыдущих лекциях параметров (моды и квантилей), в интервальной шкале используется среднее арифметическое значение, а в пропорциональной к нему присоединяются среднее геометрическое и среднее гармоническое значения. Мерами изменчивости, кроме рассмотренных выше, являются дисперсия, стандартное отклонение, коэффициент асимметрии и коэффициент вариации.
В пропорциональной шкале в качестве мер положения используются все перечисленные меры и к ним добавляются еще две: среднее геометрическое и среднее гармоническое значения. Меры изменчивости — те же самые.
Рассмотрим сначала меры положения.
Среднее арифметическое значение (Mean) — 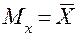 — это то значение признака, которое отражает средний уровень выраженности признака в данной выборке испытуемых. Среднее арифметическое находится по следующим формулам:
— это то значение признака, которое отражает средний уровень выраженности признака в данной выборке испытуемых. Среднее арифметическое находится по следующим формулам:
А) при небольшом количестве испытуемых
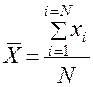 , где
, где
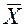 — среднее арифметическое
— среднее арифметическое
N — число испытуемых или объем выборки
i — номер испытуемого в выборке
xi — i-тое значение признака x
Б) для простого вариационного ряда (для каждого значения признака указана частота его появления в данной выборке)
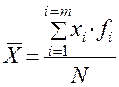 , где
, где
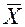 — среднее арифметическое
— среднее арифметическое
m — число значений признака, встретившихся в данной выборке
i — номер значения признака по порядку
xi — i-тое значение признака x
fi — абсолютная частота каждого i-того значения признака x
N — число испытуемых или объем выборки
В) для сгруппированного распределения находится приближенное значение среднего арифметического по следующей формуле
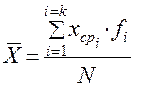 , где
, где
— среднее арифметическое
k — число интервалов в сгруппированном ряду
i — номер интервала по порядку
xср i — среднее значение каждого i-того интервала
fi — абсолютная частота каждого i-того интервала
N — число испытуемых или объем выборки
Алгоритм вычисления среднего арифметического значения в сгруппированном распределении:
1. Для каждого интервала вычисляем его среднее значение по формуле
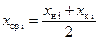 , где x н i — начальное значение i-того интервала;
, где x н i — начальное значение i-того интервала;
x к i — конечное значение i-того интервала.
2. Находим произведение среднего значения каждого интервала и абсолютной частоты этого интервала xср i· fi
3. Находим сумму этих произведений ∑xср i· fi
4. Вычисляем среднее арифметическое значение как частное от деления ∑xср i· fi на N.
Для расчетов удобно выполнять каждое действие в отдельном столбце следующей таблицы:
Таблица 7
| № п/п | Xi (начало и конец интервалов) | fi | Fi | X ср i | 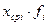
|
| k | |||||
| …. | |||||
| …. | |||||
| …. | |||||
| …. | |||||
| 3 | |||||
| 2 | |||||
| 1 | |||||
| S=N | S=…… |
Среднее геометрическое значение отражает средний прирост значений признака, а среднее гармоническое значение показывает среднюю скорость изменения признака. Понятно, что эти параметры имеет смысл рассчитывать для динамичных признаков, то есть тех, которые достаточно быстро изменяются во времени. Например, какие-либо характеристики состояний, или эффективность работы в течение рабочего дня. Такого типа признаки в практике психологических исследований встречаются не часто. Поэтому формулы для расчета этих параметров мы рассматривать не будем (они довольно сложны). При необходимости следует обратиться к учебникам Суходольского или Гласа и Стенли.
Дата: 2019-11-01, просмотров: 342.