В качестве входной информации (входных переменных модели) выступают следующие параметры: оценка риска проекта по первому критерию (вероятность попадания в зону неэффективности), оценка риска проекта по второму критерию (критерий ликвидности), оценка риска по третьему критерию (критерий покрытия).
Качественные оценки этих критериев формализуются с помощью лингвистических переменных А1, А2, А3 соответственно.
Лингвистическая переменная Aj (j=1,3) характеризуется следующим набором
<Aj,T(Aj),Uj>, (38)
где Aj – название переменной,
T(Aj) – множество значений переменной (множество термов),
Uj – универсальное множество соответствующей базовой переменной uj.
Ниже приведены значения компонент указанного набора:
- A1=”Уровень риска для первого критерия”, T(A1)=”минимальный, повышенный, критический, недопустимый”.
- A2=”Уровень риска для второго критерия”, T(A2)=”минимальный, повышенный, критический, недопустимый”.
- A3=” Уровень риска для третьего критерия ”, T(A3)=” минимальный, повышенный, критический, недопустимый ”.
Такая градация степени риска взята из классификации рисков Каблукова В.В., где он описывает данные категории следующим образом: минимальная степень допустимости риска характеризуется уровнем возможных потерь расчетной прибыли в пределах 0 – 25 %, повышенная степень – 25 – 50 %, критическая - 50 – 70 %, недопустимая – 75 – 100 %.
Каждому множеству T(Aj) соответствуют четыре терма Tji(Aj).
Каждый терм Tji(Aj) (i=1,4) характеризуется функцией принадлежности mji(uj), которая определена на соответствующем универсальном множестве Uj и выражает смысл данного терма.
Опишем сформированные функции принадлежности для первого критерия оценки риска. Здесь К1, К2, К3 – границы интервалов для соответствующих уровней риска. Границей для недопустимого уровня является единица. Значения данных интервалов можно получить из экспертного опроса.
Минимальный уровень риска для первого критерия
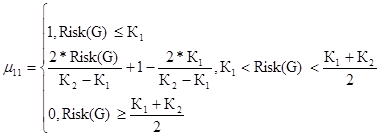 (39)
(39)
Повышенный уровень риска для первого критерия
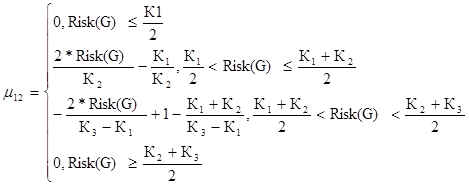 (40)
(40)
Критический уровень риска для первого критерия
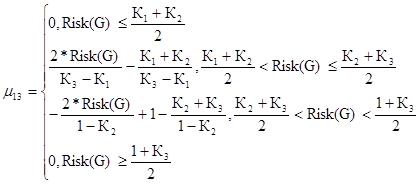 (41)
(41)
Недопустимый уровень риска для первого критерия
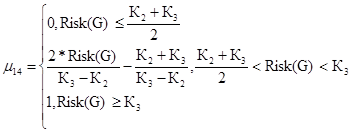 (42)
(42)
Опишем функции принадлежности к риску для критерия ликвидности. Тут тоже используются границы интервалов для соответствующих уровней риска К1, К2, К3. Где К1 – это граница недопустимого уровня риска, К2 – критического, К3 – повышенного, границей минимального уровня является единица. Значения данных интервалов можно получить из экспертного опроса.
Поскольку в результате расчетов мы получаем три значения коэффициента, которые характеризуют минимальное (Rt1), среднее (наиболее ожидаемое) (Rt2) и максимальное значение (Rt3) критерия, то для свертки этих значений воспользуемся следующей формулой
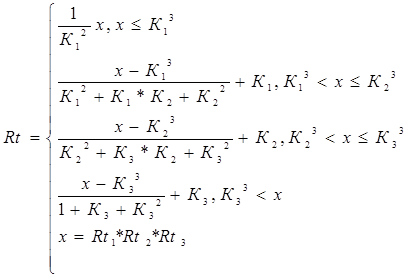 (43)
(43)
Сформируем функции принадлежности коэффициента ликвидности к введенной лингвистической переменной:
Минимальный уровень риска для второго критерия
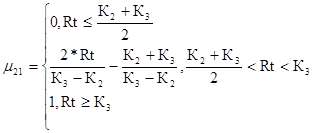 (44)
(44)
Повышенный уровень риска для второго критерия
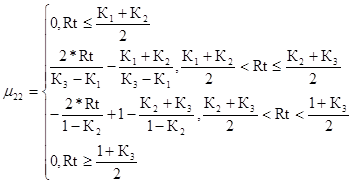 (45)
(45)
Критический уровень риска для второго критерия
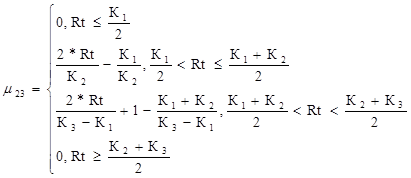 (46)
(46)
Недопустимый уровень риска для второго критерия
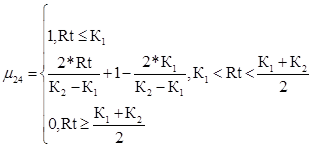 (47)
(47)
Опишем функции принадлежности для критерия покрытия. Тут также используются границы интервалов для соответствующих уровней риска К1, К2, К3, где К1 – это граница недопустимого уровня риска, К2 – критического, К3 – повышенного. Границей минимального уровня является единица. Значения данных интервалов можно получить из экспертного опроса.
Поскольку в результате расчетов мы получаем два значения, которые характеризуют минимальное (Сt1) и максимальное значение (Ct2) критерия, то для свертки этих значений воспользуемся следующей формулой
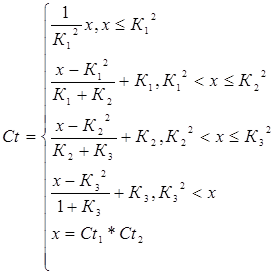 (48)
(48)
Сформируем функции принадлежности коэффициента покрытия к введенной лингвистической переменной. Минимальный уровень риска для третьего критерия
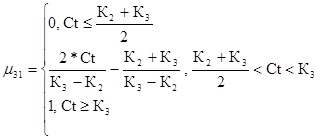 (49)
(49)
Повышенный уровень риска для третьего критерия
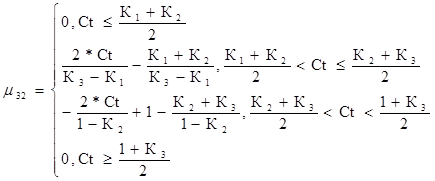 (50)
(50)
Критический уровень риска для третьего критерия
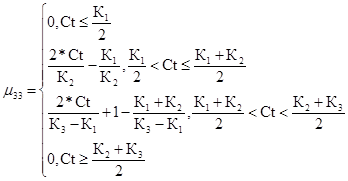 (51)
(51)
Недопустимый уровень риска для третьего критерия
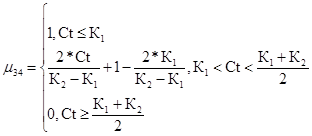 (52)
(52)
Определим теперь описание выходной переменной – уровня риска инвестиционного проекта. Это лингвистическая переменная B, которая характеризуется также набором, подобным предыдущему
<B,T(B),V>, (53)
где B – название переменной (B = «Уровень риска проекта»);
T(B) – множество термов (T(B) = «минимальный», «повышенный», «критический», «недопустимый»);
V – универсальное множество базовой переменной v (в долях единицы).
Значения функции принадлежности mk (v) термов Tk(B) (k=1,4) также могут быть получены из экспертной информации.
Сформируем функции принадлежности риска проекта к введенной лингвистической переменной. Здесь К1, К2, К3 – границы интервалов для соответствующих уровней риска. Границей для недопустимого уровня является единица. Значения данных интервалов можно получить из экспертного опроса. Минимальный уровень риска проекта
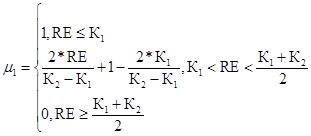 , (54)
, (54)
где RE – уровень риска инвестиционного проекта, (доли единицы).
Повышенный уровень риска для первого критерия
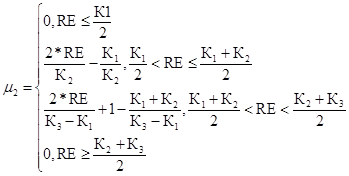 (55)
(55)
Критический уровень риска для первого критерия
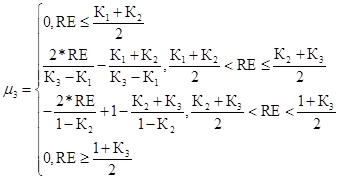 (56)
(56)
Недопустимый уровень риска для первого критерия
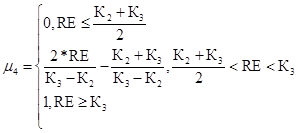 (57)
(57)
Смысл нечеткого вывода состоит в следующем. Если А - причина (предпосылка), а В- результат (заключение), то можно определить нечеткое отношение R соответствия между А и В, смысл которого отражается в знании: из А скорее всего следует В. Это знание выражено формулой R=А®В( где ® это символ нечеткой импликации). Тогда связь между нечеткой предпосылкой А’ и нечетким заключением В’ можно записать в виде
B’ = A’ · R = A’· (A®B), (58)
где значок · - это правило композиционного вывода (правило свертки).
В рассматриваемой логической системе предпосылки определяются лингвистическими переменными А1,А2,А3, а заключение – лингвистической переменной В. В каждом конкретном правиле имеются три предпосылки (по числу входных переменных) и одно заключение. Каждое такое логическое правило определяет одно из возможных состояний объекта управления, а полный набор правил характеризует все возможные состояния /17/. Поскольку каждая из трех предпосылок имеет четыре значения соответствующей лингвистической переменной, а в правилах вывода должны присутствовать все комбинации значений, то общее число правил равно 43 =64.
В виде термов одно из этих правил может быть написано следующим образом: если уровень риска для первого критерия - минимальный, уровень риска для второго критерия - минимальный, уровень риска для третьего критерия - минимальный, то уровень риска проекта – минимальный.
Анализ результатов
Дата: 2019-05-29, просмотров: 322.