Итак, в выборочном социологическом исследовании случайная величина предстает перед социологом в виде признака, для каждого значения которого (а таких значений – конечное количество) известна относительная частота его встречаемости. Эта частота интерпретируется как выборочная оценка соответствующей вероятности (вопрос о правомерности такой трактовки не прост; здесь мы его не рассматриваем; см. п.4.1 части I). Совокупность частот встречаемости всех значений признака, соответственно, трактуется как выборочное представление функции плотности того распределения вероятностей, которое и задает изучаемую случайную величину. Подчеркнем, что пока речь идет об одномерной случайной величине (ниже, переходя к оценке вероятностей встречаемости сочетаний значений разных признаков, мы тем самым перейдем к многомерным случайным величинам).
Пусть, например, вопрос в используемой социологом анкете звучит: “Какова Ваша профессия?” и сопровождается 5-ю вариантами ответов, закодированных числами от 1 до 5. Тогда частотное распределение - аналог функции плотности - будет иметь, например, вид:
Таблица 1.
Пример одномерной частотной таблицы
| Значение признака | 1 | 2 | 3 | 4 | 5 |
| Частота встречаемости (%) | 20 | 15 | 25 | 10 | 30 |
Вместо процентов могут фигурировать доли: 20% заменится на 0,2, 15 - на 0,15 и т.д. (в случае такой замены мы получим числа, конечно, в большей степени похожие на вероятности, поскольку величина вероятности, как известно, изменяется от 0 до 1).
То же частотное распределение можно выразить по-другому, в виде диаграммы вида, отраженного на рис. 1 или в виде т.н. полигона распределения, рис.2.
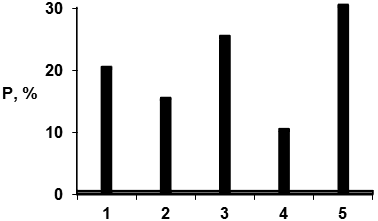
Рис.1. Диаграмма распределения, рассчитанная на основе таблицы 1.
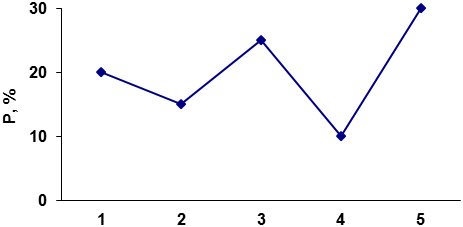
Рис. 2. Полигон распределения, рассчитанный на основе таблицы 1.
Подчеркнем, что здесь линии, связывающие отдельные точки, проведены лишь для наглядности, никакой содержательный смысл за ними не стоит (обращаем внимание читателя на то, что ниже ситуация изменится; здесь нельзя говорить об интерпретации линий из-за того, что признак – номинальный).
Казалось бы, что построение частотной таблицы или полигона распределения – дело простое, и говорить не о чем. Однако в социологии это не так. Рассмотрим проблемы, которые возникают при построении одномерных частотных таблиц. Будем учитывать тип шкалы, по которой получаются значения признака, рассмотрим номинальные, порядковые, интервальные шкалы. Однако прежде сделаем некоторое отступление для объяснения того, почему, обосновав во Введении целесообразность ограничиться номинальными данными, мы как будто отступаем от собственных принципов, переходя к шкалам более высокого типа. Дело в том, что продолжая считать номинальные данные основным объектов нашего изучения, мы не можем полностью отвлечься от других шкал. Причин тому несколько.
Во-первых, соответствующие положения фактически задействованы (иногда в неявном виде) почти во всех методах анализа, в том числе и рассчитанных на номинальные данные.
Во-вторых, хотя номинальные данные являются основным предметом изучения социолога, решение большинства задач эмпирической социологии требует “увязки” процесса такого изучения с анализом данных, полученных по шкалам высоких типов. Объясняется это тем, что именно по таким шкалам измеряются столь важные для социолога характеристики респондентов, как возраст респондента, его зарплата и т.д. Поэтому строить курс анализа данных вообще без упоминания методов изучения “числовой” информации представляется нецелесообразным.
В-третьих, хотя в литературе имеется немало работ с описанием методов статистического анализа “числовых” данных, однако при этом не всегда достаточно подробно анализируются многие их аспекты, важные для социолога-практика (например, редко затрагивается проблема разбиения диапазона изменения признака на интервалы или проблема пропущенных значений). Мы постараемся ликвидировать этот пробел хотя бы для наиболее часто используемых социологом методов – вычислении мер средней тенденции и разброса для вероятностных распределений.
Именно с “числовых” шкал мы и начнем более подробное обсуждение специфики построения распределений в социологических задачах. Приводимые ниже рассуждения справедливы для интервальныхшкал и шкал более высоких типов.
Дата: 2019-03-05, просмотров: 619.