Операция кодирования информации линейным кодом заключается в умножении информационного вектора Ak размерностью k на порождающую матрицу G ( x ); в результате получаем вектор
F(x) = Ak (x) × G(x).
Кодовую последовательность на выходе кодера можно записать в виде:
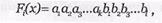
где a1a2a3...аk - информационные символы (логические 1 и 0),
b1b2b3...b1 - проверочные символы (логические 1 и 0).
Проверочные символы b1b2b3...bl формируются путем суммирования по модулю два информационных символов, стоящих на определенных позициях.
 |
Алгоритм формирования проверочных символов в общем виде можно записать так:
где cj1cj2...cjk- коэффициенты принимающие значение логических 1 и 0.
Пример: Ak ( x )=1010
1 0 0 0 1 0 1
G(x)=0 1 0 0 1 1 1
0 0 1 0 1 1 0
0 0 0 1 0 1 1
 1 0 0 0 1 0 1
1 0 0 0 1 0 1
Следовательно, F ( x )= Ak ( x ) × G ( x )=[1010]* 0 1 0 0 1 1 1 = [1010 011]
0 0 1 0 1 1 0
0 0 0 1 0 1 1
Рассмотрим построение и реализацию устройства кодирования ЛБК (7,4).
Порождающая и проверочная матрицы этого кода имеют вид:
а1а2а3а4 b1b2b3
1 0 0 0 1 0 1 1 1 1 0 1 0 0
G(x)=0 1 0 0 1 1 1 H(x)=0 1 1 1 0 1 0
0 0 1 0 1 1 0 1 1 0 1 0 0 1
0 0 0 1 0 1 1
Этот код имеет d=3 и исправляет все одиночные ошибки и обнаруживает двойные. Символы а1,а2,а3,а4 – информационные символы, b1,b2,b3 – проверочные.
По матрице запишем проверочные уравнения:
b1= a1Åa2Åa3
b2= a2Åa3Åa4
b3= a1Åa2Åa4
Таким образом, кодер состоит из (n-k)=7-4=3 сумматоров по модулю два, выходы которых соответствуют (n-k) проверочным символам.
Устройство кодирования линейного группового кода (7, 4) приведено на рисунке.
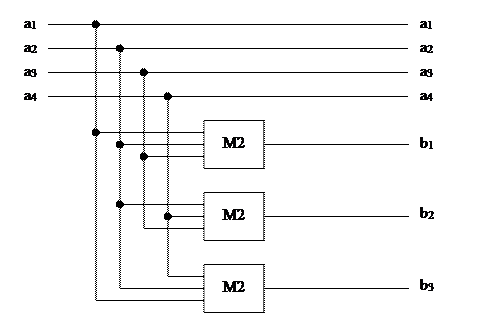
Рисунок – Кодер линейного группового кода (6, 3)
Пусть подается сообщение (а1,а2,а3,а4)=1001. Тогда слово, передаваемое в канал связи, имеет вид (1001 110).
Синдромное декодирование
Декодирование более сложный процесс, чем кодирование.

Декодирование линейных групповых кодов основано на следующем свойстве: Проверочная H(х) и порождающая G(х) матрицы удовлетворяют соотношению G(х)*Ht(х)=0, где Ht(х) - транспонированная проверочная матрица.
Если в принятом слове F(х) отсутствуют ошибки, то матричное произведение равно нулю.
F(х)*Ht(х)= Ak(x)*G(x)*Ht(х)= Ak(x)*0=0
Ecли же при передаче информации возникли ошибки, то (F+E)*Ht=F*Ht+E*Ht=0+E*Ht=E*Ht=S – синдром, где E – вектор ошибки. Длина синдрома равна (n-k). Ненулевая величина синдрома свидетельствует о наличии ошибки. Если различным ошибкам соответствуют различные синдромы, то по виду синдрома можно определить вид ошибки и, следовательно, исправить ее.
Этапы декодирования:
1. По принятому слову
|
Sj (x)= F(x)* × Ht(x).
2. По синдрому Sj ( x ) находится вектор ошибок E.
3. Из принятого вектора F(x)* вычитается вектор ошибок; в результате получаем переданное слово, F(x).
Синдромный декодер состоит из схемы, вычисляющей (n-k)-разрядный синдром, дешифратора и корректирующих сумматоров по модулю два. Схема вычисления синдрома производит умножение принятого вектора на матрицу Ht(x). При отсутствии ошибок синдром равен нулю. Если синдром не равен нулю, то возбуждаются соответствующие выходы дешифратора и сигналы с ошибочных разрядов исправляются на корректирующих сумматорах.
Схема синдромного декодера кода (6, 3) представлена на рисунке.
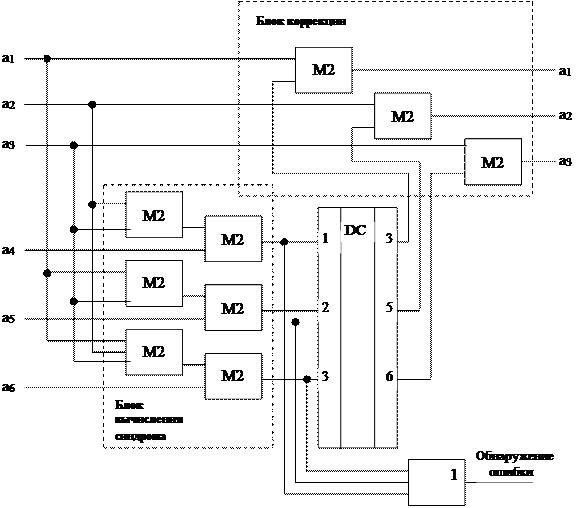 |
Рисунок – Схема синдромного декодера кода (6, 3)
Пусть F(x)=111 001, например, ошибка произошла в первом разряде, т.е. принятое слово имеет вид F(x)*=(011 001).
Вычислим синдром Sj(x)= F(x)* × Ht(x).
а1а2а3 а4а5а6
0 1 1 1 0 0 011
H(x) =1 0 1 0 1 0 Ht(x)= 101 Sj(x)= F(x)* × Ht(x)=011
1 1 1 0 0 1 111
100
010
001
Синдром равен 011 (это первая строчка матрицы Ht(x), следовательно, ошибка произошла в первом разряде) и на первом выходе дешифратора должен появиться единичный сигнал, который исправит на первом корректирующем сумматоре ошибочный сигнал на противоположный – правильный. Это обеспечит получение на выходе приемника сигнала Ak(x)=111, который и передался в канал связи.
В том случае, если требуется только обнаружение ошибок, то сигналы с выхода схемы вычисления синдрома заводится на схему ИЛИ. На выходе схемы ИЛИ будет единичный сигнал в случае ненулевого синдрома, что свидетельствует о наличии ошибок в принятом сообщении.
Декодирование по синдрому применяется для коррекции ошибок малой кратности. Основная трудность при декодировании по синдрому связана с ''проблемой селектора'', который по синдрому должен однозначно установить разряды, в которых произошли ошибки, т. е. определить вектор ошибок E.
Мажоритарное декодирование
Способ мажоритарного декодирования привлекает как простотой описания, так и невысокой сложностью схемной реализации. Идея мажоритарного декодирования линейного кода базируется на системе проверочных равенств, а именно, в кодах с мажоритарным декодированием каждый символ может быть выражен через другие символы несколькими способами. Это позволяет для определения истинного значения символа воспользоваться принципом большинства (мажоритарным принципом).
Существует три способа построения систем проверочных уравнений при мажоритарном декодировании:
– системы с разделенными проверками;
– системы с l -связанными проверками;
– системы с квазиразделенными проверками.
В системах с разделенными проверками некоторый символ, относительно которого разделяется система уравнений, входит во все уравнения. Любой другой символ входит не более чем в одну проверку. Отсюда следует, что для коррекции t ошибок система должна состоять из (2t + 1) уравнений и иметь на столько же входов мажоритарные элементы.
Пример: Пусть имеется код (6; 3), задаваемый следующей проверочной матрицей:
а1а2а3 а4а5а6
0 1 1 1 0 0
H(x) =1 0 1 0 1 0
1 1 1 0 0 1
Запишем систему уравнений:
 а4= a2Åa3
а4= a2Åa3
а5= a1Åa3
а6= a1Åa2Åa3
Из этой системы можно записать систему проверочных равенств, где равенство аi=аi называется уравнением истинности или тривиальным.
Для a1: a1= a3Åa5
а1 = а2Åa3Åa6=а4Åa6
а1= a1
 Для a2: a2= a3Åa4
Для a2: a2= a3Åa4
а2 = а1Åa3Åa6=а5Åa6
а2= a2
 Для a3: a3= a2Åa4
Для a3: a3= a2Åa4
а3 = а1Åa5
а3= a3
Видно, что каждый из принятых символов ai входит в данные системы один раз, и, следовательно, если он ошибочен, то ошибочным будет одно из трех уравнений системы; два остальных – правильны. По большинству правильных проверок мажоритарный элемент принимает правильное решение об оценке состояния разряда.
С ростом числа корректируемых ошибок растет число уравнений в системе и, следовательно, увеличивается сложность мажоритарного элемента.
Декодер для кода (6,3) требует шесть сумматоров по модулю два и три мажоритарных элемента.
Схема мажоритарного декодера кода (6, 3) представлена на рисунке.
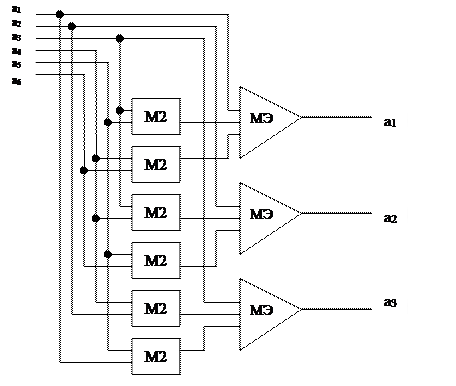
Рисунок – Схема мажоритарного декодера кода (6, 3)
Достоинства мажоритарного декодирования: простота реализации, высокая скорость декодирования.
Недостатки: такие декодеры могут декодировать малый класс кодов.
Дата: 2018-12-28, просмотров: 1085.