Матричные коды – это такие многомерные помехоустойчивые коды, которые формируются на основе использования специальных матриц путем организации проверок на четность логических 1 по строкам и столбцам матрицы. (Примечание: допускается организация проверок (формирование проверочных уравнений) на нечетность, а также одновременно на четность и нечетность).
В соответствии с ГОСТом 20687-82 передаваемые блоки информационных, символов записываются в виде столбцов и строк матрицы выбранного размера (ранга). Первоначальная запись информационных символов по строкам или столбцам не имеет принципиального значения, т.е. не сказывается на характеристиках кода. Матрицы могут быть по форме представления квадратные и прямоугольные, т.е. рангами соответственно 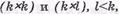 где k и l количество соответственно строк и столбцов, представляющие передаваемые информационные символы.
где k и l количество соответственно строк и столбцов, представляющие передаваемые информационные символы.
Одновременно с записью информационных символов по строкам (или по столбцам) производится формирование проверочного символа (проверки); обозначим передаваемые информационные символы знаком а, а проверочные символы знаком b . В общем виде принцип формирования матричного кода можно представить в виде следующей матрицы:
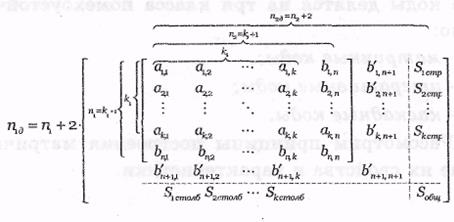
Таким образом, ранг матрицы будет равен 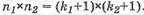
Матрицы могут быть однорядными (в каждой строке и в каждом столбце формируются по одному проверочному символу) и многорядными (в каждой строке и в каждом столбце формируются по два, три и более проверочных символов).
Примечание: для синхронных и асинхронных систем связи ГОСТ 20687-86 предусматривает различные правила формирования проверочных символов по столбцам, а именно:
- для синхронных систем связи формируется четное число логических 1;
- для асинхронных систем связи формируется нечетное число логических 1.
На приемной стороне, т.е. в декодере, формируется аналогичная матрица рангом 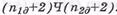 . Приемная матрица формируется следующим образом. В каждом столбце и в каждой строке по принятым информационным символам формируются проверочные символы ( bi , j ) (проверки на четность), которые записываются в матрице рядом с соответствующими принятыми проверочными символами (смотри bn,1 и b'n+1,1 b1,n и b '1, n +1 т.д.). Далее в каждой строке и в каждом столбце из принятых и вновь сформированных проверочных символов формируются синдромные символы по правилу:
. Приемная матрица формируется следующим образом. В каждом столбце и в каждой строке по принятым информационным символам формируются проверочные символы ( bi , j ) (проверки на четность), которые записываются в матрице рядом с соответствующими принятыми проверочными символами (смотри bn,1 и b'n+1,1 b1,n и b '1, n +1 т.д.). Далее в каждой строке и в каждом столбце из принятых и вновь сформированных проверочных символов формируются синдромные символы по правилу: 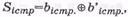
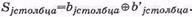
После окончания процедуры формирования синдромных символов могут быть реализованы два алгоритма декодирования матричного кода, а именно:
1) с обнаружением ошибок и повторной передачей переданного информационного блока;
2) с обнаружением позиций ошибочных информационных символов и их коррекцией.
Основные свойства одномерного матричного кода:
1) так как формирование проверочных символов осуществляется путем суммирования по модулю два информационных символов, то данный код относится к линейным кодам;
2) в связи с тем, что каждая строка имеет вес w≥d0, то данный код относится к классу блоковых кодов;
3) так как строки и столбцы матрицы образуют совокупность кодовых последовательностей линейно-независимых относительно операции суммирования по модулю два, то данный код обладает всеми свойствами групповых кодов;
4) по способу передачи кодовых символов матричные коды могут быть как систематическими, так и несистематическими.
Параметры одномерного матричного кода.
1) Nm=n1×n2 – длина кодовой последовательности, где 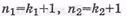 – со-
– со-
ответственно количество строк и столбцов.
При 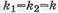 ,
, 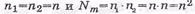 двоичных символов;
двоичных символов;
2) 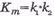 – количество информационных символов, где k1 и k2 – соответственно количестве «информационных» строк и «информационных» столбцов. При
– количество информационных символов, где k1 и k2 – соответственно количестве «информационных» строк и «информационных» столбцов. При 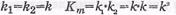 двоичных символов;
двоичных символов;
3) Rm= Km/Nm=k1/n1×k2/n2 – скорость передачи кода,
4) l т=Nm-Km -абсолютная избыточность кода,
5) rт=(1-Rm)*100% - относительная избыточность кода,
6) d 0 m - минимальное кодовое расстояние, 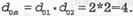 Введение одного проверочного символа в последовательность простого безызбыточного кода, т.е. в блок из k информационных символов, позволяет обнаруживать однократные и нечетные ошибки, а в соответствии с теорией кодирования, для обнаружения ошибки d0 должно быть равно или более
Введение одного проверочного символа в последовательность простого безызбыточного кода, т.е. в блок из k информационных символов, позволяет обнаруживать однократные и нечетные ошибки, а в соответствии с теорией кодирования, для обнаружения ошибки d0 должно быть равно или более 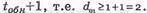 Аналогично определяется d02 по столбцам матрицы. Следовательно, одномерный матричный код имеет
Аналогично определяется d02 по столбцам матрицы. Следовательно, одномерный матричный код имеет 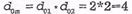 и позволяет обнаруживать двукратные ошибки
и позволяет обнаруживать двукратные ошибки 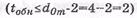 или исправлять однократные ошибки
или исправлять однократные ошибки

Для обнаружения и коррекции ошибочных информационных символов используются сформированные синдромные символы Sij строк и столбцов, и реализуется следующее правило:
- если при приеме информации ошибочным будет только один информационный символ, то синдромные символы данной строки и столбца будут ненулевыми, т.е. равны 1;
- для коррекции ошибочного символа необходимо определить его позицию в матрице, которая, как легко установить, находится на пересечении соответствующей строки и столбца с ненулевыми синдромными символами, т.е. Si и Sj .
7) Рн.ош т – вероятность необнаруженной ошибки
 |
где Р k - вероятность ошибочного приема двоичного символа.
Матричный код с одной проверкой на четность по строкам и столбцам обладает низкой корректирующей способностью. Для повышения корректирующей способности данного кода необходимо запись (кодирование) информации выполнять по строкам, а считывание кодовых символов выполнять по столбцам, или наоборот. В этом случае будет обеспечиваться обнаружение групповых ошибок кратностью tn.обн= n1д двоичных символов. Обнаружение пакетных ошибок кодом обеспечивается за счет перемежения (разноса) кодовых символов; перемежение кодовых символов позволяет преобразовать пакет ошибок в одиночные ошибки.
Достоинствами матричного кода с формированием одиночных проверок на четность по строкам и столбцам являются минимальная сложность аппаратурной и программной реализации. Не достатками кода являются высокая избыточность и низкая корректирующая способность.
С целью повышения корректирующей способности одномерных матричных кодов были разработаны двумерные матричные коды, а именно:
а) матричный код с формированием двух проверочных символов (на чет и нечет) по строкам и столбцам матрицы;
б) матричный код с формированием проверочных символов (на чет) по строкам, столбцам и диагоналям матрицы.
Принцип построения матричного кода с формированием проверок на четность по строкам, столбцам и диагоналям
В соответствии с ГОСТом 20687-85 данный способ формирования матричного кода носит название способа формирования матричного кода с диагональными проверками. Сущность данного способа построения матричного кода рассмотрим по следующей условной матрице
 |
Первоначально по информационным символам (на матрице – это большие точки) формируются проверочные символы по строкам и столбцам (на матрице кружки – под номерами I). Затем формируются проверочные символы с использованием диагональных информационных символов, начиная с информационных символов главной диагонали (на матрице эта процедура обозначена сплошными стрелками). Сформированный первый проверочный символ диагонали записывается на последнюю позицию первой строки (столбец под номером II). Затем суммируются по модулю два информационные символы следующей диагонали (на матрице - это будет нижняя диагональ и обозначенная штрихпунктирной линией; в принципе можно «двигаться» по матрице и вверх); проверочные символы столбцов не используются в формировании диагональных проверок. В качестве «недостающих» информационных символов используются проверочные символы строк. Сформированный второй проверочный символ диагональной проверки записывается на последнюю позицию второй строки. Остальные проверочные символы формируются аналогичным способом.
На приемной стороне из принятых информационных символов аналогичным способом формируются проверки на четность по строкам, столбцам и диагоналям. Сформированные проверочные символы суммируются по модулю два с принятыми проверочными символами и формируют, таким образом, синдромные символы строк, столбцов и диагоналей.
Обнаружение и коррекция ошибок проводятся следующим образом: первый ошибочный информационный символ определяется на пересечении строки и столбца с ненулевыми синдромными символами, который при считывании инвертируется; второй ошибочный информационный символ определяется и корректируется аналогичным способом, только его позиция определяется на пересечении соответствующих позиций ненулевых синдромных символов диагонали и столбца.
Таким образом, данный матричный код обеспечивает коррекцию ошибок длинной  бита и, следовательно,
бита и, следовательно, 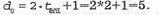 Длина кодовой последовательности
Длина кодовой последовательности 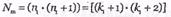 двоичных, символов, а количество информационных символов определяется равенством
двоичных, символов, а количество информационных символов определяется равенством 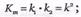 при k1=k2. В общем виде данный матричный код записывается следующим образом:
при k1=k2. В общем виде данный матричный код записывается следующим образом:
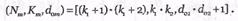
Формирование дополнительных проверок с использованием информационных символов диагоналей матрицы справа налево позволяет построить матричный код с минимальным кодовым расстоянием 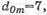 т.е. матричный код, корректирующий трехкратные ошибки. Дальнейшим развитием матричных кодов было открытие итеративных кодов.
т.е. матричный код, корректирующий трехкратные ошибки. Дальнейшим развитием матричных кодов было открытие итеративных кодов.
Дата: 2018-12-28, просмотров: 1791.