Для оценки надежности источника сведений и достоверности самих сведений был разработан условный код, известный под названием буквенно-цифровой системы. Надежность источника сведений в соответствии с этой системой обозначается буквами от А до Е, достоверность сведений— цифрами от 1 до 6. Ниже приводится расшифровка обозначений этого кода.
Надежность источника
А — абсолютно надежный источник,
Б — обычно надежный источник,
В ¦— довольно надежный источник,
Г — не всегда надежный источник,
Д — ненадежный источник,
Е — надежность источника нельзя определить.
Достоверность сведений Достоверность сведений подтверждается данными из других источников. Сведения, вероятно, правильны.
Сведения, возможно, правильны. Сомнительные сведения. Сведения неправдоподобны. Достоверность сведений нельзя установить.
Помимо создания этой простой системы оценки надежности источника, почти ничего не было сделано, чтобы облегчить выражение степени определенности и достоверности сведений, содержащихся в документах разведки, а также для -установления взаимопонимания между составителями разведывательной информации и теми, кто ею пользуется. Напротив, тот факт, что в информационной работе приходится иметь дело преимущественно с ненадежными источниками, использовался при составлении некоторых документов для оправдания нечеткости в оценке достоверности сведений.
В качестве примера можно указать на использование в информационных документах такого недопустимого выражения: «Сообщают, что...» Это выражение не сопровождается какими-либо дополнительными разъяснениями, кото- ‘ рые помогли бы читателю уяснить характер сведений. Составителю информационного документа, конечно в определенной мере, известна степень достоверности приводимых им сведений. Он должен сообщить об этом тем, кто будет читать документ. В противном случае этот документ не заслуживает внимания. Составитель документа может по крайней мере писать следующим образом: «Как сообщают перебежчики, показания которых, по-видимому, являются достоверными...», или «Как сообщает местная пресса...», или «Как сообщают туристы...» и т. д.
Приведем другой пример неудачного выражения. Иногда пишут: «Возможно, что...», не определяя при этом вероятность описываемого явления. Разведчик, изучивший явление, о котором он пишет, имеет определенные основания, чтобы судить о вероятности или невероятности данного явления. Иногда стоит задуматься над тем, что внешне значительные фразы бывают совершенно бессмысленными. Взять, к примеру, хотя бы такую фразу: «Возможно, что в данный момент в Куртэнии какой-нибудь инженер, склонившись над чертежной доской, работает над созданием нового оружия, с помощью которого можно стереть с лица земли значительную часть оборонительных укреплений Со
единенных Штатов». Разве можно представить себе в качестве основы для выработки политического курса и практических мероприятий что-либо более бесполезное, чем такая фраза?
В информационных документах используются иногда и другие, приводимые ниже выражения: «Вероятно, что...», «Весьма вероятно, что...» и т. д. Явление можно считать «вероятным» при 51 шансе за и 49 против; точно так же «вероятным» считается явление при 999 шансах из 1000. Употребляются и такие столь же неясные выражения: «Имеется много шансов, что...», «Шансы говорят в пользу того, что...» и т. д. Составитель информационного документа обычно имеет более четкое представление о степени вероятности описываемых явлений, о чем ему следует сообщить тем, кто будет читать документ, не претендуя при этом на такую точность, которой нельзя обеспечить.
Схема Кента
Чтобы показать графически все степени достоверности сведений от совершенно достоверных до совершенно недостоверных и дать каждой степени соответствующее определение, Шерман Кент составил схему, воспроизводимую нами на рис.
8, которая дает наглядную классификацию сведений с точки зрения степени их достоверности. Схема Кента определенно поможет составителю информационного документа полностью довести до сведения лиц, которым предназначается этот документ, степень достоверности приводимых в нем сведений.
Номенклатура
Разведчики стремятся в составляемых ими документах указывать степень надежности использованных источников и достоверности приведенных сведений. Для этого необходимо, чтобы документы составлялись в точных выражениях, одинаково понимаемых как автором документа, так и тем, кто будет его читать.
По степени достоверности сведения целесообразно подразделять на следующие виды.
НЕДОСТОВЕРНОСТЬ
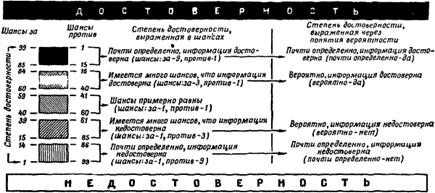 Рис. 8. Схема Кента, иллюстрирующая степень достоверности информации.
Рис. 8. Схема Кента, иллюстрирующая степень достоверности информации.
Почти определенно, что сведения достоверны
(шансы: за — 9 или более, против — 1 или менее) Равнозначные выражения-.
Примечание: Категорическое утверждение, касающееся таких фактов, явлений, проверить которые явно невозможно, выражается обычно в следующей фразе: «Можно почти определенно сказать, что...» К этому виду информации относится любое категорическое утверждение относительно будущего: «Указывают, что...»
«Мы полагаем, что...»
«Очевидно, что...» (или «Ясно, что...»)
«Почти нет сомнений, что...» (или «Несомненно, что...»)
Имеется много шансов, что сведения достоверны
(примерно 3 шанса за и 1 — против)
Равнозначные выражения-.
«Вероятно, что...» (или другие выражения, близкие к понятию «вероятно»)
«Вполне вероятно, что...»
«Похоже, что...»
«Кажется, что...»
«Должно быть»
«Предполагается, что...» (или «Ожидается, что...») «Логично будет предположить, что...»
«Разумно будет сделать вывод, что...»
Шансы за и против того, что сведения достоверна, примерно равны
(шансы: за —1, против — 1, или 50 : 50)
Имеется много шансов, что сведения недостоверны
(примерно .1 шанс за и 3 — против)
Почти определенно — сведения недостоверны
(примерно 1 шанс за и 9 и более против) Равнозначные выражения:
Для двух последних видов те же, что для первых двух, только с добавлением «не» или другого отрицания.
Неопределенные сведения
Только в том случае, если составитель информационного документа не желает даже приблизительно определить степень достоверности содержащихся в нем сведений, он может без всяких разъяснений использовать следующие выражения:
«Возможно, что...»
«Может быть...» (форму «может быть» следует использовать только в условных предложениях)
«Это могло иметь место...»
МОДЕЛЬ ИШИКАВЫ
Диаграмма Исикавы (альтернативные названия: причинно-следственная диаграмма, диаграмма Исикавы, ёлочная диаграмма, диаграмма рыбьего скелета, 5М) — это метод анализа разветвленно-сти (детализации) процесса. Она известна в литературе как диаграмма Исикавы и «рыбий скелет» (так как законченная диаграмма напоминает рыбий скелет).
Суть метода
Причинно-следственная диаграмма — это ключ к решению возникающих проблем.
Диаграмма позволяет в простой и доступной форме систематизировать все потенциальные причины рассматриваемых проблем, выделить самые существенные и провести поуровневый поиск первопричины.
Цель метода
Изучить, отобразить и обеспечить технологию поиска истинных причин рассматриваемой проблемы для эффективного их разрешения, т.е. соотнести причины с результатами (следствиями). Это один из наиболее элегантных и широко используемых инструментальных методов контроля качества.
Существуют три основных типа диаграмм причина-результат:
Анализ разветвленное™ (детализации) процесса.
Классификация производственного процесса.
Перечисление причин.
Назначение метода. Применяется при разработке и непрерывном совершенствовании продукции. Диаграмма Исикавы — инструмент, обеспечивающий системный подход к к определению фактических причин возникновения проблем.
План действий
В соответствии с известным принципом Парето, среди множества потенциальных причин (причинных факторов, по Исикаве), порождающих проблемы (следствие), лишь две-три являются наиболее значимыми, их поиск и должен быть организован. Для этого осуществляется:
. сбор и систематизация всех причин, прямо или косвенно влияющих на исследуемую проблему;
группировка этих причин по смысловым и причинно-следственным блокам;
ранжирование их внутри каждого блока;
• анализ получившейся картины. Особенности метода
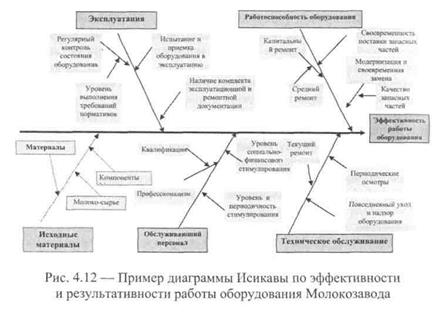
На рис. 4.11 показан основной вид диаграммы.
. Оборудование (Machine)
Материалы (Material) .
Методы (Method)
Персонал (Man)
Окружающая среда (Milieu)
• Иногда добавляют измерительную систему (Measurement Sys tem)
Все категории в английском языке начинаются с буквы «М», отсюда еще одно название метода — 5М (или 6М соответственно).
Общие правила построения
Все участники должны прийти к единому мнению относительно формулировки проблемы.
Изучаемая проблема записывается с правой стороны в середине чистого листа бумаги и заключается в рамку, к которой слева подходит основная горизонтальная стрелка — «хребет» (диаграмму Исикавы из-за внешнего вида часто называют «рыбьим скелетом»).
Наносятся главные причины (причины уровня 1), влияющие на проблему, — «большие кости». Они заключаются в рамки и соединяются наклонными стрелками с «хребтом».
Далее наносятся вторичные причины (причины уровня 2), орые влияют на главные причины («большие кости»), а те, в вою очередь, являются следствием вторичных причин. Вторичные причины записываются и располагаются в виде «средних костей», примыкающих к «большим». Причины уровня 3, которые влияют на причины уровня 2, располагаются в виде «мелких костей», примыкающих к «средним», и т. д. (Если на диаграмме приведены не все причины, то одна стрелка оставляется пустой).
При анализе должны выявляться и фиксироваться все факторы, даже те, которые кажутся незначительными, так как цель схемы — отыскать наиболее правильный путь и эффективный способ решения проблемы.
Причины (факторы) оцениваются и ранжируются по их значимости, выделяя особо важные, которые предположительно оказывают наибольшее влияние на показатель качества.
В диаграмму вносится вся необходимая информация: ее название; наименование изделия; имена участников; дата и т. д.
Дополнительная информация:
Процесс выявления, анализа и объяснения причин, является ключевым в структурировании проблемы и переходу к корректирующим действиям.
Задавая при анализе каждой причины вопрос «почему?», можно определить первопричину проблемы (по аналогии с выявлением главной функции каждого элемента объекта при функционально-стоимостном анализе).
Способ взглянуть на логику в направлении «почему?» состоит в том, чтобы рассматривать это направление в виде процесса постепенного раскрытия всей цепи последовательно связанных между собой причинных факторов, оказывающих влияние на проблему качества.
Достоинства метода Диаграмма Исикавы позволяет:
• стимулировать творческое мышление;
•представить взаимосвязь между причинами и сопоставить их относительную важность.
18ПОИСКОВЫЕ ИНТЕРНЕТ – СИСТЕМЫ, ИНТЕРНЕТ – КАТАЛОГИ И МЕГАПОИСКОВЫЕ СИСТЕМЫ
Все имеющиеся средства поиска информации в Интернете мо- гут быть условно разделены на несколько подгрупп, а именно: – средства поиска информации на отдельных сайтах; – подборки ссылок; – каталоги; – поисковые системы; – метапоисковые системы; – системы мониторинга и контент-анализа; – экстракторы объектов, событий и фактов; – системы Knowledge Discovery, Data Mining, Text Mining; – специализированные системы конкурентной разведки; – интегрированные системы. Ƿо своей сути каталоги, поисковые системы и метапоисковые системы являются веб-сайтами со специализированными базами данных, в которых хранится информация о других веб-ресурсах и документах, хранящихся на них. В результате запроса к таким сис- темам выдается список адресов, а иногда и краткое описание доку- ментов (сниппеты), где может присутствовать запрашиваемая ин- формация. Dzак правило, поиск может производиться только по ключевым словам и фразам. Активизируя на ссылку, найденную в результате запроса, пользователь попадает на оригинал документа, размещенного на некотором веб-сайте. Естественно, что если доку- мент со временем изменился или веб-сайт прекратил свое сущест- вование, то и первоначально заиндексированный поисковой систе- мой документ через некоторое время может быть не найден. Ƕсновное отличие поисковых систем от каталогов – наличие автоматического «робота», постоянно сканирующего веб-прост- ранство и накапливающего новую информацию в индексных фай- лах базы данных. В каталоги же информация заносится вручную – либо владельцами сайтов, либо обслуживающим персоналом самих каталогов. Ƿользование такими системами, как правило, бесплат- ное, это самые популярные поисковые инструменты в сети Интернет. Ǵетапоисковые системы являются поисковыми системами по поисковым системам. Ǻак как отдельные поисковые системы раз- личным образом индексируют хотя и обширные и часто пересе- кающиеся, но все-таки разные сегменты ǹети, то, естественно, и результат поиска с помощью метапоисковой системы будет, априо- ри, более полным, чем с помощью одной отдельно взятой поиско- вой системы. ǹчитать это плюсом или минусом поисковой работы зависит от поставленных целей и количества найденных докумен- тов. Если в результате поиска найдены тысячи или миллионы до- кументов, то «вручную» все равно вряд ли можно просмотреть свыше нескольких сотен. Вторым поисковым преимуществом таких систем является то, что одним запросом обеспечивается поиск во многих поисковых системах, не требуя многочисленных повторений одного и того же запроса в разных поисковых системах. ǹистемы мониторинга и контент-анализа обеспечивают регу- лярный поиск и «скачивание» информации по заданным темам и с заданных сайтов, а также анализ содержания «скачанных» доку- ментов. Ǻакие системы, как правило, обладают развитым языком запросов, что позволяет существенно детализировать и конкрети- зировать запросы по сравнению с обычными поисковыми система- ми. Во-вторых, такие системы хранят в своих базах данных полные тексты исходных документов, что обеспечивает сохранность этих документов во времени и возможность их обработки и контент- анализа, как в текущем времени, так и в ретроспективе. ǹущест- венным преимуществом таких систем является также то, что слож- ные запросы, состоящие из десятков или сотен поисковых слов и выражений, однажды составленные аналитиком-знатоком пред- метной области, могут быть сохранены в виде каталогизированного запроса или рубрики и в дальнейшем вызываться автоматически или вручную из сохраненного списка для проведения поиска или контент-анализа. ǹ помощью контент-анализа такие системы позволяют уста- навливать пересекающиеся связи между темами, понятиями и объ- ектами, поставленными на мониторинг, выявлять эмоциональную окраску документов, проводить анализ динамики появления во времени тех или иных документов, проводить сравнительный ана- лиз информационной активности по различным тематикам и мно- гое другое. Если мониторинговые системы как системы фильтрации могут выделять из информационного потока известные объекты, то экс- тракторы объектов, событий и фактов умеют выделять из потока информации объекты, неизвестные заранее, события или факты, которые лишь соответствуют определенному заранее типу, напри- мер, географические понятия, персоны, структуры и организации, события (дорожно-транспортные происшествия, катастрофы, меж- дународные встречи). Ƿри этом факты могут классифицироваться как обычные или необычные. Ƿримером обычного факта в данном случае можно считать выезд автомобилей за черту города, а приме- ром необычного факта – выезд за ту же городскую черту автомоби- ля без номерных знаков. ǹистемы типа Knowledge Discovery, технологии Data Mining и Text Mining, умеют выявлять новые знания и закономерности. Ǻа- кая система, например, может самостоятельно, без участия челове- ка, сделать вывод о факте знакомства между людьми, основываясь на имеющихся в системе данных об окончании ими одной и той же школы и одного итого же класса в одном и том же населенном пункте. Ƿравда, сами правила, по которым такая система делает выводы, все-таки создаются и задаются пока что людьми. ǹпециализированные системы для конкурентной разведки мо- гут включать в себя одно или несколько из перечисленных выше поисковых средств, специально «заточенных» под эти специфиче- ские задачи. Dzроме того, потребности конкурентной разведки предполагают использование в качестве источников информации, кроме полнотекстовых документов, еще и доступных в сети Интер- нет баз данных (БД), собственных, принадлежащих компании, до- кументов, таблиц и баз данных, а также формализованных и не- формализованных документов и БД, добытых из других источни- ков.
Дата: 2019-02-25, просмотров: 1302.