Рассмотренные математические модели детерминированных сигналов являлись известными функциями времени. Их использование позволяет успешно решать задачи, связанные с определением реакций конкретных систем на заданные входные сигналы. Случайные составляющие, всегда имеющие место в реальном входном сигнале, считают при этом пренебрежимо малыми и не принимают во внимание.
Однако единственная точно определенная во времени функция не может служить математической моделью сигнала при передаче и преобразовании информации. Поскольку получение информации связано с устранением априорной неопределенности исходных состояний, однозначная функция времени только тогда будет нести информацию, когда она с определенной вероятностью выбрана из множества возможных функций. Поэтому в качестве моделей сигнала используется случайный процесс. Каждая выбранная детерминированная функция рассматривается как реализация этого случайного процесса.
Необходимость применения статистических методов исследования диктуется и тем, что в большинстве практически важных случаев пренебрежение воздействием помехи в процессах передачи и преобразования информации недопустимо. Считается, что воздействие помехи на полезный сигнал проявляется в непредсказуемых искажениях его формы. Математическая модель помехи представляется также в виде случайного процесса, характеризующегося параметрами, определенными на основе экспериментального исследования. Вероятностные свойства помехи, как правило, отличны от свойств полезного сигнала, что и лежит в основе методов их разделения.
Учитывая, что все фундаментальные выводы теории информации базируются на указанном статистическом подходе при описании сигналов (и помех), уточним основные характеристики случайного процесса как модели сигнала.
Под случайным (стохастическим) процессом подразумевают такую случайную функцию времени 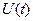 , значения которой в каждый момент времени случайны. Конкретный вид случайного процесса, зарегистрированный в определенном опыте, называют реализацией случайного процесса. Точно предсказать, какой будет реализация в очередном опыте, принципиально невозможно. Могут быть определены лишь статистические данные, характеризующие все множество возможных реализаций, называемое ансамблем. Ценность таких моделей сигналов в том, что появляется возможность судить о поведении информационной системы не по отношению к конкретной реализации, а по отношению ко всему ансамблю возможных реализаций.
, значения которой в каждый момент времени случайны. Конкретный вид случайного процесса, зарегистрированный в определенном опыте, называют реализацией случайного процесса. Точно предсказать, какой будет реализация в очередном опыте, принципиально невозможно. Могут быть определены лишь статистические данные, характеризующие все множество возможных реализаций, называемое ансамблем. Ценность таких моделей сигналов в том, что появляется возможность судить о поведении информационной системы не по отношению к конкретной реализации, а по отношению ко всему ансамблю возможных реализаций.
Основными признаками, по которым классифицируются случайные процессы, являются: пространство состояний, временной параметр и статистические зависимости между случайными величинами 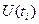 в разные моменты времени
в разные моменты времени 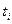 .
.
Пространством состояний называют множество возможных значений случайной величины . Случайный процесс, у которого множество состояний составляет континуум, а изменения состояний возможны в любые моменты времени, называют непрерывным случайным процессом. Если же изменения состояний допускаются лишь в конечном или счетном числе моментов времени, то говорят о непрерывной случайной последовательности.
Случайный процесс с конечным множеством состояний, которые могут изменяться в произвольные моменты времени, называют дискретным случайным процессом. Если же изменения состояний возможны только в конечном или счетном числе моментов времени, то говорят о дискретных случайных последовательностях.
Так как в современных информационных системах предпочтение отдается цифровым методам передачи и преобразования информации, то непрерывные сигналы с датчиков, как правило, преобразуются в дискретные, описываемые дискретными случайными последовательностями. Вопросы такого преобразования рассмотрены в гл. 4
Среди случайных процессов с дискретным множеством состояний нас будут интересовать такие, у которых статистические зависимости распространяются на ограниченное число k следующих друг за другом значений. Они называются обобщенными марковскими процессами к-го порядка.
В ряде практически важных задач случайный процесс наряду с вероятностным описанием можно описать совокупностью неслучайных числовых характеристик, постоянных или меняющихся во времени. От этих характеристик требуется, чтобы в условиях конкретно поставленной задачи они отражали самое существенное случайного процесса. Вероятностными характеристиками совокупности большого числа реализаций (ансамбля реализаций) являются законы распределения, которые могут быть получены теоретически или на основе экспериментальных данных.
Законы распределения являются достаточно полными характеристиками случайного процесса. Однако они сложны и требуют для своего определения обработки большого экспериментального материала. Кроме того, такое подробное описание процесса не всегда бывает нужным. Для решения многих практических задач достаточно знать более простые (хотя и менее полные) характеристики случайного процесса. Такими характеристиками являются средние значения и функция корреляции случайного процесса.
Имеется несколько различных подходов к тому, как вводить вероятностную меру на множестве реализаций. Для инженерных приложений оказывается удобным определение случайного процесса как такой функции времени x(t), значение которой в каждый данный момент является случайной величиной. Случайная величина полностью характеризуется распределением вероятностей, например плотностью P1(x1|t1);однако, чтобы охарактеризовать случайный процесс, нужно описать, связаны ли (и если да, то как) значения реализации, разделенные некоторыми интервалами времени. Так как связь только двух таких значений, описываемая распределением второго порядка Р2(х1, x2|t1, t2), может неполно характеризовать процесс в целом, вводят распределения третьего, четвертого, ..., n-го порядков: Рп (х1, ..., хп | t1, .... tn). В конкретных задачах обычно ясно, до какого порядка следует доходить в описании процесса.
В ряде практически важных задач случайный процесс наряду с вероятностным описанием можно описать совокупностью неслучайных числовых характеристик, постоянных или меняющихся во времени. От этих характеристик требуется, чтобы в условиях конкретно поставленной задачи они отражали самое существенное случайного процесса.
Вероятностные характеристики случайного процесса. В соответствии с определением случайный процесс может быть описан системой N обычно зависимых случайных величин 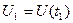 , ...,
, ..., 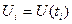 , ...,
, ...,  , взятых в различные моменты времени
, взятых в различные моменты времени 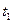 ...
... 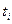 ...
... 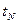 . При неограниченном увеличении числа N такая система эквивалентна рассматриваемому случайному процессу . Исчерпывающей характеристикой указанной системы является N-мерная плотность вероятности
. При неограниченном увеличении числа N такая система эквивалентна рассматриваемому случайному процессу . Исчерпывающей характеристикой указанной системы является N-мерная плотность вероятности 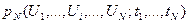 . Она позволяет вычислить вероятность
. Она позволяет вычислить вероятность 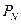 реализации, значения которой в моменты времени ,
реализации, значения которой в моменты времени , 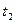 ,...,
,..., 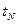 будут находиться соответственно в интервалах
будут находиться соответственно в интервалах 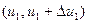 , ...,
, ..., 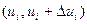 , ....
, .... 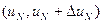 , где
, где 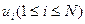 — значение, принимаемое случайной величиной
— значение, принимаемое случайной величиной 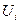 .
.
Если 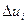 выбраны достаточно малыми, то справедливо соотношение
выбраны достаточно малыми, то справедливо соотношение
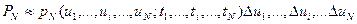
Получение N-мерной плотности вероятности на основе эксперимента предполагает статистическую обработку реализаций, полученных одновременно от большого числа идентичных источников данного случайного процесса. При больших N это является чрезвычайно трудоемким и дорогостоящим делом, а последующее использование результатов наталкивается на существенные математические трудности.
На практике в таком подробном описании нет необходимости. Обычно ограничиваются одно- или двумерной плотностью вероятности.
Одномерная плотность вероятности 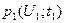 случайного процесса U ( t ) характеризует распределение одной случайной величины
случайного процесса U ( t ) характеризует распределение одной случайной величины 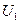 , взятой в произвольный момент времени . В ней не находит отражения зависимость случайных величин в различные моменты времени.
, взятой в произвольный момент времени . В ней не находит отражения зависимость случайных величин в различные моменты времени.
Двумерная плотность вероятности  позволяет определить вероятность совместной реализации любых двух значений случайных величин
позволяет определить вероятность совместной реализации любых двух значений случайных величин 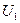 и
и 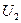 в произвольные моменты времени и
в произвольные моменты времени и  и, следовательно, оценить динамику развития процесса. Одномерную плотность вероятности случайного процесса U ( t ) можно получить из двумерной плотности, воспользовавшись соотношением
и, следовательно, оценить динамику развития процесса. Одномерную плотность вероятности случайного процесса U ( t ) можно получить из двумерной плотности, воспользовавшись соотношением
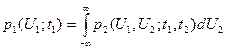 , (3.26)
, (3.26)
Использование плотности вероятности даже низших порядков в практических приложениях часто приводит к неоправданным усложнениям. В большинстве случаев оказывается достаточно знания простейших характеристик случайного процесса, аналогичных числовым характеристикам случайных величин. Наиболее распространенными из них являются моментные функции первых двух порядков: математическое ожидание и дисперсия, а также корреляционная функция.
Математическим ожиданием случайного процесса U ( t ) называют неслучайную функцию времени 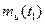 , которая при любом аргументе равна среднему значению случайной величины
, которая при любом аргументе равна среднему значению случайной величины 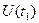 по всему множеству возможных реализаций:
по всему множеству возможных реализаций:
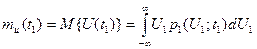 , (3.27)
, (3.27)
Степень разброса случайных значений процесса  от своего среднего значения для каждого характеризуется дисперсией
от своего среднего значения для каждого характеризуется дисперсией 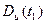 :
:
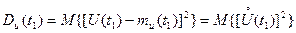 , (3.28)
, (3.28)
где 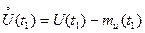 — центрированная случайная величина.
— центрированная случайная величина.
Дисперсия 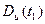 в каждый момент времени
в каждый момент времени 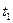 равна квадрату среднеквадратического отклонения
равна квадрату среднеквадратического отклонения  :
:
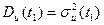 . (3.29)
. (3.29)
Случайные процессы могут иметь одинаковые математические ожидания и дисперсии , однако резко различаться по быстроте изменений своих значений во времени.
Для оценки степени статистической зависимости мгновенных значений процесса U ( t ) в произвольные моменты времени и 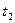 используется неслучайная функция аргументов
используется неслучайная функция аргументов 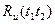 , называемая автокорреляционной или просто корреляционной функцией.
, называемая автокорреляционной или просто корреляционной функцией.
При конкретных аргументах и она равна корреляционному моменту значений процесса 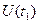 и
и 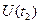 :
:
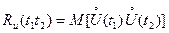 . (3.30)
. (3.30)
Через двумерную плотность вероятности выражение (3.30) представляется в виде
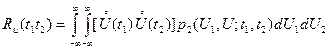 . (3.31)
. (3.31)
В силу симметричности этой формулы относительно аргументов справедливо равенство
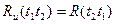 (3.32)
(3.32)
Для сравнения различных случайных процессов вместо корреляционной функции удобно пользоваться нормированной функцией автокорреляции:
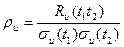 (3.33)
(3.33)
Из сравнения (1.69) и (1.70) следует, что при произвольном = 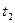 автокорреляционная функция вырождается в дисперсию:
автокорреляционная функция вырождается в дисперсию:
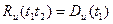 (3.34)
(3.34)
а нормированная функция автокорреляции равна единице:
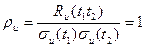 (3.35)
(3.35)
Следовательно, дисперсию случайного процесса можно рассматривать как частное значение автокорреляционной функции.
Аналогично устанавливается мера связи между двумя случайными процессами U ( t ) и V ( t ). Она называется функцией взаимной корреляции:
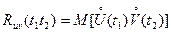 (3.36)
(3.36)
Дата: 2019-02-24, просмотров: 353.