Оптимальное решение задачи методом динамического программирования находится на основе функционального уравнения
fn-1(Sl)=optimum(Rl+1(Sl,Ul+1)+fn-(l+1)(Sl+1)) (1)
ul+1
(l=0,n-1)
Чтобы определить его, необходимо:
1.записать функциональное уравнение для последнего состояния процесса (ему соответствует l=n-1)
fn-1(Sl-1)=optimum(Rn(Sn-1,Un)+f0(Sn))
ul+1
2.найти Rn(Sn-1,Un) из дискретного набора его значений при некоторых фиксированных Sn-1 и Un из соответствующих допустимых областей (так как f0(Sn)=0, то f1(Sn-1)= optimum(Rn(Sn-1,Un)
Un
В результате после первого шага известно решение Un и соответствующее значение функции f1(Sn-1)
3.Уменьшить значение l на единицу и записать соответствующее функциональное уравнение. При l=n-k (k= 2,n) оно имеет вид
fk(Sn-k)=optimum(Rn-k+1(Sn-k,Un-k+1)+fk-1(Sn-k+1)) (2)
Un-k+1
4.найти условно-оптимальное решение на основе выражения (2)
5.проверить, чему равно значение l.Если l=0, расчет условно-оптимальных решений закончен, при этом найдено оптимальное решение задачи для первого состояния процесса. Если l не равно 0, перейти к выполнению п.3.
6.Вычислить оптимальное решение задачи для каждого последующего шага процесса, двигаясь от конца расчетов к началу.
Метод динам программ позволяет одну задачу со многими переменными заменить рядом последовательно решаемых задач с меньшим числом переменных. Решение осуществляется по шагам. Основной принцип, на котором базируется оптимизация многошагового процесса, а также особенности вычислительного метода—принцип оптимальности Беллмана.
Оптимальное поведение обладает тем свойством, что каковы бы ни были начальное состояние и начальное решение, последующие решения должны быть оптимальными относительно состояния, полученного в результате первоначального решения.
Математически он записывается выражением вида:
fn-1(Sl)=optimum(Rl+1(Sl,Ul+1)+fn-(l+1)(Sl+1)) (1)
ul+1
(l=0,n-1)Optimum в выражении означает максимум или минимум в зависимости от условия задачи.
Требования, предъявляемые к задачам, решаемым методом ДП
Динамическое программирование—математический метод для нахождения оптимальных решений многошаговых задач. Многошаговым является процесс, развивающийся во времени и распадающийся на ряд шагов, или этапов.
Одна из особенностей метода динамического программирования состоит в том, что принятые решения по отношению к многошаговым процессам рассматривается не как единичный акт, а как целый комплекс взаимосвязанных решений. Эту последовательность взаимосвязанных решений называют стратегией.Цель оптимального планирования—выбрать стратегию, обеспечивающую получение наилучшего результата с точки зрения заранее выбранного критерия. Такую стратегию называют оптимальной.
Другой важной особенностью метода является независимость оптимального решения, принимаемого на очередном шаге, от предистории, т.е. от того, каким образом оптимизируемый процесс достиг теперешнего состояния. Оптимальное решение выбирается лишь с учетом факторов, характеризующих процесс в данный момент.
Метод динам программ характеризуется также тем, что выбор оптимального решения на каждом шаге должен производиться с учетом его последствий в будущем. Это означает, что, оптимизируя процесс на каждом отдельном шаге, ни в коем случае нельзя забыть обо всех последующих шагах.
64.Экономическая постановка и построение математической модели задачи, решаемой методом ДП(на примере задачи о распределении капиталовложений). Рекуррентное соотношение Беллмана.
Предварительно поясним, что метод динамического программирования применяется прежде всего к тем задачам, в которых оптимизируемый процесс (или ситуация) разворачивается в пространстве или во времени, или в том и другом.
Пусть сам процесс (ситуация) настолько сложен, что нет возможности его оптимизировать известными методами. Тогда по методу динамического программирования СЛОЖНЫЙ процесс (операция, ситуация) разбивается (членится) на ряд этапов (шагов). Эта разбивка во многих случаях является естественной, но в общем случае привносится искусственно. Например, при рассмотрении какой-либо партии игры в шахматы любой ход каждого из игроков как раз и служит
разбивке всей партии на отдельные шаги (этапы). А в военной операции по преследованию одной ракеты другой весь непрерывный процесс приходится искусственно разбивать на этапы, например, через каждую секунду наблюдения. Метод динамического программирования позволяет оптимизацию всего сложного процесса заменить условной оптимизацией по каждому из этапов
(шагов) с последующим синтезом оптимального управления всем процессом. При этом метод предусматривает, что условная оптимизация на отдельном шаге (этапе) делается в интересах, прежде всего, всей операции.
Все вычисления, дающие возможность найти оптимальное значение эффекта, достигаемого за n шагов, fn(S0), проводятся по формуле (1), которая носит название основного функционального уравнения Беллмана или рекуррентное соотношение. При вычислении очередного значения функции fn-1 используется значение функции fn-(l+1), полученное на предыдущем шаге, и непосредственное значение эффекта Rl+1(Sl,Ul+1), достигаемого в результате выбора решения Ul+1 при заданном состоянии системы Sl. Процесс вычисления значения функции fn-1(l=0,n-1)
Осуществляется при естественном начальном условии f0(Sn)=0, которое означает, что за пределами конечного состояния системы эффект равен нулю.
65. Задача о распределении капитальных вложений (пример).
Для решения задачи об оптимальном распределении капиталовложений мы будем пользоваться функциональным уравнением Беллмана. Сначала с помощью простейшей ситуации проиллюстрируем вывод функционального уравнения Беллмана, а потом на примере докажем, как использовать это уравнение для решения интересующей нас задачи.
Начнем с оптимального распределения выделенных капиталовложений в сумме К между двумя предприятиями. Плановые отделы предприятий на основе своих расчетов сформировали функции дохода q(x) для предприятия П1 и h(x) - для предприятия П2. Функции эти означают, что если первое или второе предприятие получит капиталовложение и размере х, то первым предприятием
будет получен доход q(x), а вторым h(x), причем величина x может принимать непрерывные или известные дискретные значения от 0 до К.
Итак, пусть предприятию П1 выделены капиталовложения в сумме х, тогда предприятию П2 выделяется сумма К - х. В этом случае от первого предприятия будет получен доход q(x), а от второго - h(К - x). Если капиталовложения К были выделены на один плановый период, то общий доход от двух предприятий составит R(K, x) = q(x) + h(K - x). Очевидно, что x и соответственно К - x надо выбирать такими, чтобы R(K, x) приняло свое максимальное значение, которое мы обозначим через F(K):
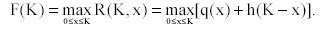
Эта запись является как бы остовом для более полных записей
функционального уравнения Беллмана. УСЛОЖНИМ нашу задачу, распределив капиталовложения на два плановых периода (два этапа). Пусть изначально решено первому предприятию П1 выделить сумму х, а второму К – х. В целом доход получался бы равным R(K, x) = q(x) +
h(K - x). Если мы будем иметь в виду, что капиталовложения распределяются на 2 периода (2 этапа), то на первом предприятии остаток капиталовложений составит .x, где 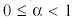 , а на втором - .(К - х), где
, а на втором - .(К - х), где 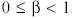 Соответственно доходы за второй период составят q(.x) -по первому предприятию и h[.(K - x)] - по второму. Оптимизацию по методу динамического программирования, как правило, начинают с концевого этапа. Поэтому начнем со второго этапа, обозначив F1 максимально возможный доход от двух предприятий на втором
Соответственно доходы за второй период составят q(.x) -по первому предприятию и h[.(K - x)] - по второму. Оптимизацию по методу динамического программирования, как правило, начинают с концевого этапа. Поэтому начнем со второго этапа, обозначив F1 максимально возможный доход от двух предприятий на втором
этапе. Получим
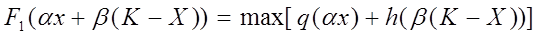
Затем к рассмотренному последнему (в нашем случае второму) этапу как бы пристраиваем предшествующий (у нас первый) этап и находим максимальный доход от двух этапов вместе:
Аналогичным образом для n этапов получаем
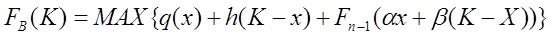
где Fn-1 - целевая функция, дающая наилучший результат за последние (n - 1) этапы. Полученное функциональное уравнение Беллмана носит рекуррентный характер, т.е. связывает значение Fn со значением Fn-1.
В более общем начертании уравнение Беллмана имеет вид
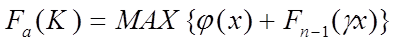
где 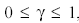 , Fn-1 - максимальный доход за (n - 1) последних этапов, Fn -
, Fn-1 - максимальный доход за (n - 1) последних этапов, Fn -
максимальный доход за все n этапов.
Дата: 2019-12-22, просмотров: 358.