Сдвигатель реализует полный набор функций сдвига 16-разрядных данных с 32-разрядным результатом. Эти функции включают арифметический, логический сдвиг и функцию нормализации. Сдвигатель также обеспечивает нахождение порядка и мантиссы для блока чисел. Эти базовые функции могут быть скомбинированы для преобразования форматов чисел любой сложности, включая их представление с плавающей запятой. Структурная схема вычислительного блока сдвигателя приведена на рисунке 13.4.
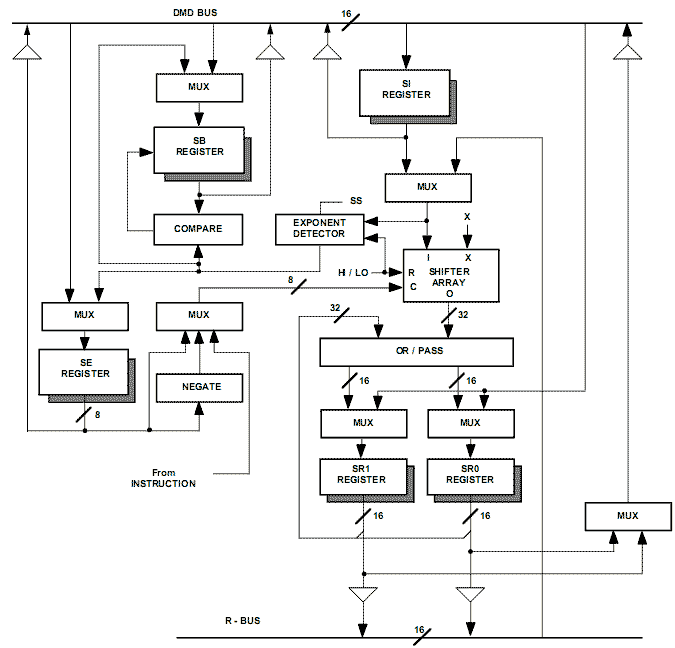
Рисунок 13.4 - Структурная схема сдвигателя данных сигнальных процессоров семейства ADSP-2100
Сдвигатель может быть разделен на следующие блоки: сдвигающая матрица, логика элементов побитового "ИЛИ"/"Передача без изменения", устройство вычисления порядка числа и устройство сравнения порядков чисел.
Сдвигающая матрица представляет собой 16×32 циклический сдвигатель. На него поступают 16-разрядные числа и сдвигатель может разместить эти биты в любом месте 32-разрядного выходного числа вплоть до полного выдвижения их за пределы области выходного результата. Это дает 49 возможных мест размещения входных бит в 32-разрядном поле выходного числа. Положение входных бит на выходе сдвигателя определяется управляющим кодом (C) и сигналом HI/LO (сдвиг вверх/вниз).
Сдвигающая матрица и связанная с ней логика окружены набором регистров. Входной регистр сдвигателя SI подключен ко входу сдвигающей матрицы и устройству вычисления порядка числа. Шестнадцатиразрядный регистр SI доступен по записи и чтению по шине DMD. Сдвигающая матрица и вычислитель порядка числа могут также получать данные из регистров AR, MR или SR по шине результата (R-шине). Регистр результата SR 16-разрядный, поэтому он разделен на две 16-разрядных секции SR0 и SR1. Регистры SR0 и SR1 могут быть записаны по шине DMD и считаны как по шине DMD, так и по шине результата R-шине. Регистр SR может быть также подключен к логика элементов побитового "ИЛИ" для осуществления операций сдвига удвоенной точности.
Регистр SE (“shifter exponent”) это 8-разрядный регистр, предназначенный для хранения порядка числа при его преобразовании к формату с плавающей запятой и обратно. Регистр SE доступен для записи и чтения младшими 8 битами шины данных памяти данных DMD. В этом регистре хранится 8-разрядный дополнительный код в формате 8.0.
Регистр SB (“shifter block”) применяется при блочных операциях с плавающей запятой, где он содержит значение порядка для блока чисел, когда этот регистр содержит число разрядов, на которое должны быть сдвинуты все числа для нормализации самого большого значения в блоке. Регистр SB 5-разрядный, он хранит самое последнее значение порядка блока. Регистр SB доступен для записи и чтения младшими 5 битами шины данных памяти данных DMD. В этом регистре хранится 5-разрядный дополнительный код в формате 5.0.
При считывании значений из регистров SE и SB по шине данных, они приводятся к 16-разрядному формату при помощи аппаратной операции расширения знака.
Любой из регистров SI, SE или SB может быть считан и записан в течении одного машинного цикла. Регистры читаются в начале машинного цикла, а записываются в конце этого же цикла. При считывании любого из регистров читается число, записанное в него в конце предыдущего цикла. Новый результат вычислений, записанный в регистр не может быть считан из него до следующего машинного цикла.
Лекция № 14
ТЕМА: Программируемые интегральные логические схемы (ПЛИС) и базовые матричные кристаллы. Выспроизводительные FPGA-микросхемы
Основные вопросы, рассматриваемые на лекции:
1. ПЛМ
2. ПМЛ
3. PLD
4. БМК
5. Выспроизводительные FPGA-микросхемы
Программируемые логические матрицы и программируемая матричная логика (ПЛМ и ПМЛ)
Программируемые логические матрицы
Программируемые логические матрицы появились в середине 70-х годов Основой их служит последовательность программируемых матриц элементов И и ИЛИ. В структуру входят также блоки входных и выходных буферных каскадов (БВх и БВых).
Входные буферы, если не выполняют более сложных действий, преобразуют однофазные входные сигналы в парафазные и формируют сигналы необходимой мощности для питания матрицы элементов И.
Выходные буферы обеспечивают необходимую нагрузочную способность выходов, разрешают или запрещают выход ПЛМ на внешние шины с помощью сигнала ОЕ, а иногда выполняют и более сложные действия. Основными параметрами ПЛМ (рис. 14.1) являются число входов т, число термов L и число выходов п.
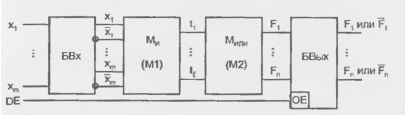
Рисунок 14.1 - Базовая структура ПЛМ.
Переменные Xj ... xm подаются через БВх на входы элементов. И (конъюнкторов), и в матрице И образуются L термов. Под термом здесь понимается конъюнкция, связывающая входные переменные, представленные в прямой или инверсной форме. Число формируемых термов равно числу конъюнкторов или, что то же самое, числу выходов матрицы И
Термы подаются далее на входы матрицы ИЛИ. т. е. на входы дизъюнкторов. формирующих выходные функции. Число дизъюнкторов равно числу вырабатываемых функций n.
Таким образом, ПЛМ реализует дизъюнктивную нормальную форму (ДНФ) воспроизводимых функций (двухуровневую логику).
ПЛМ способна реализовать систему п логических функций от т аргументов, содержащую не более L термов. Воспроизводимые функции являются комбинациями из любого числа термов, формируемых матрицей И. Какие именно термы будут выработаны и какие комбинации этих термов составят выходные функции, определяется программированием ПЛМ.
Схемотехника ПЛМ
Выпускаются ПЛМ как на основе биполярной технологии, так и на МОП-транзисторах. В матрицах имеются системы горизонтальных и вертикальных связей, в узлах пересечения которых при программировании создаются или ликвидируются элементы связи.
На рис. 14.2, а в упрошенном виде (без буферных элементов) показана схемотехника биполярной ПЛМ К556РТ1 с программированием пережиганием перемычек. Показан фрагмент для воспроизведения системы функций.
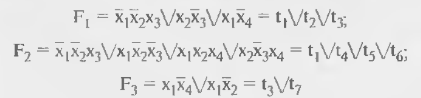
размерностью 4, 7, 3. Параметрами микросхемы К556РТ1 являются 16, 48, 8. Элементами связей в матрице И служат диоды, соединяющие горизонтальные и вертикальные шины, как показано на рис. 14.2, б, изображающем цепи выработки терма t1. Совместно с резистором и источником питания цепи выработки термов образуют обычные диодные схемы И. До программирования все перемычки целы, и диоды связи размещены во всех узлах координатной сетки. При любой комбинации аргументов на выходе будет ноль, т. к. на вход схемы подаются одновременно прямые и инверсные значения аргументов, а хх — 0. При программировании в схеме оставляются только необходимые элементы связи, а ненужные устраняются пережиганием перемычек. В данном случае на вход конъюнктора поданы x1. х2 и х3. Высокий уровень выходного напряжения (логическая единица) появится только при наличии высоких напряжений на всех входах, низкое напряжение хотя бы на одном входе фиксирует выходное напряжение на низком уровне, т. к. открывается диод этого входа. Так выполняется операция И, в данном случае вырабатывается терм 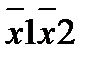 x3.
x3.
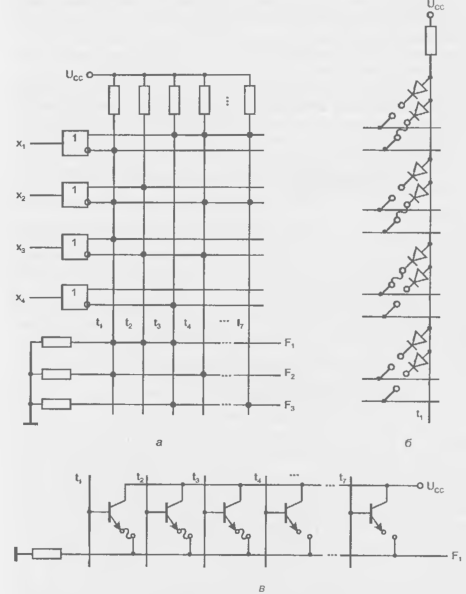
Рисунок 14.2 - Схемотехника ПЛМ, реализованной в биполярной технологии (в) и элементы связей в матрицах И (б) и ИЛИ (в)
Элементами связи в матрице ИЛИ служат транзисторы (рис 14.2, а), включенные по схеме эмиттерного повторителя относительно линий термов и образующие схему ИЛИ относительно выхода (горизонтальной линии). На рис. 14.2, в показана выработка функции F1. Работа схемы ИЛИ, реализованной в виде параллельного соединения эмиттерных повторителей. При изображении запрограммированных матриц наличие элементов связей (целые перемычки) отмечается точкой в соответствующем узле. В схемах на МОП-транзисторах в качестве базовой логической ячейки используют инвертирующие (ИЛИ-НЕ, И-НЕ) Соответственно этому меняются и операции, реализуемые в первой и второй матрицах ПЛМ. В частности, в схемотехнике n-МОП базовой ячейкой обычно служит ячейка ИЛИ-НЕ, а структура ПЛМ имеет вид (рис. 14.3). Такая ПЛМ является последовательностью двух матриц ИЛИ-НЕ, одна из которых служит для выработки термов, другая — для выработки выходных функций.
Терм t1 в данном случае равен:
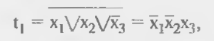
а функция:

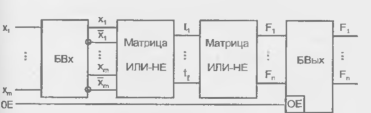
Рисунок 14.3 - Схемотехника ПЛМ. реализованной на МОП-транзисторах.
На основании этих выражений можно заключить, что известная связь между операциями выражаемая правилами де Моргана, говорит о фактическом совпадении функциональных характеристик биполярной ПЛМ и ПЛМ на МОП-гранзисторах: если на входы последней подавать аргументы, инвертированные относительно аргументов биполярной ПЛМ, то на выходе получим результат, отличающийся от выхода биполярной ПЛМ только инверсией.
Подготовка задачи к решению с помощью ПЛМ
Имея в виду подбор ПЛМ минимальной сложности, следует уменьшить по возможности число термов в данной системе функций. Содержанием минимизации функций будет поиск кратчайших дизъюнктивных форм. Вести поиск минимальных по числу термов представлений задачи следует до уровня, когда число термов становится равным L — параметру имеющихся ПЛМ. Дальнейшая минимизация не требуется. Если размерность имеющихся ПЛМ обеспечивает решение задачи в ее исходной форме, то минимизация не требуется вообще, т. к. не ведет к сокращению оборудования.
Программирование ПЛМ
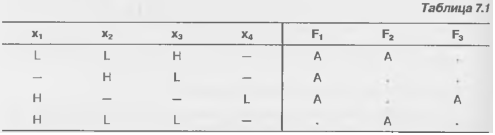
Программирование ПЛМ, выполняемое пользователем, проводится с помощью специальных устройств (программаторов) и сведения для них о данной ПЛМ должны иметь определенную форму. Имеются программаторы, которые принимают в качестве информации о ПЛМ таблицу функционирования (истинности), однако удобнее задавать сведения о самих перемычках. Символы, используемые при таком задании сведений для программирования ПЛМ:
Н — переменная входит в терм в прямом виде, т. е. нужно оставить целой перемычку прямого входа и пережечь перемычку инверсного входа;
L — переменная входит в терм в инверсном виде, т. е. нужно сохранить перемычку у инверсного входа и пережечь у прямого"
"—" — переменная не входит в терм и не должна влиять на него, т. е. нужно пережечь перемычки обоих входов.
Оставление перемычек у обоих входов переменной как бы устраняет из матрицы соответствующую схему И, поскольку в силу равенства х 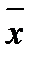 = 0 выход этой схемы всегда нулевой и не влияет на работу матрицы ИЛИ, на вход которой подается;
= 0 выход этой схемы всегда нулевой и не влияет на работу матрицы ИЛИ, на вход которой подается;
А— указывается в выходном столбце (столбце функции) и свидетельствует о связи данной схемы И с выходом ПЛМ через матрицу ИЛИ. Перемычка должна быть сохранена;
"." — указывает на то, что данная схема И не подключается к выходу и должна иметь пережженную перемычку в матрице ИЛИ.
В принятой символике для программирования ПЛМ взятого ранее примера сведения будут заданы таблицей (табл. 14.1)
Таблица 14.1
Упрощенное изображение схем ПЛМ
Схемы ПЛМ достаточно громоздки, и поэтому изображать их желательно с максимально возможным упрощением. Используются изображения, в которых многовходовые элементы И, ИЛИ условно заменяются одновходовыми.
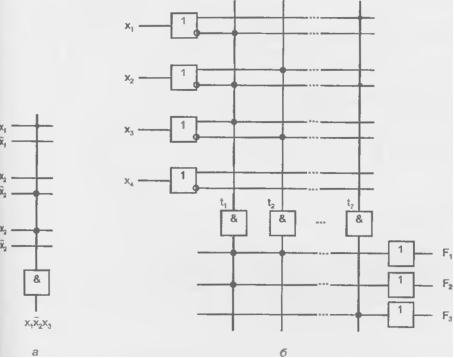
Рисунок 14.4 - Упрощенное изображение схемы многовходового логического элемента (а) и ПЛМ (б)
Единственная линия входа таких элементов пересекается с несколькими линиями входных переменных. Если пересечение отмечено точкой, данная переменная подается на вход изображаемого элемента, если точки нет, то переменная на элемент не подается. Пример многовходового конъюнктора с входами x1x2x3 показан на рис. 14.4, а. Схема рис. 14.2, а в новом упрощенном изображении имеет вид, приведенный на рис. 14.4, б.
Воспроизведение скобочных форм переключательных функций
С помощью ПЛМ можно воспроизводить не только дизъюнктивные нормальные формы переключательных функций, но и скобочные формы. В этом случае сначала получают выражения в скобках, а затем они рассматриваются как аргументы для получения окончательного результата. В схеме появляются обратные связи — промежуточные результаты с выхода вновь подаются на входы, логическая глубина схемы увеличивается, задержка выработки результата растет. Пусть, например, требуется получить функцию:
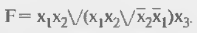
Для этого следует применить включение ПЛМ по схеме (рис. 14.5).
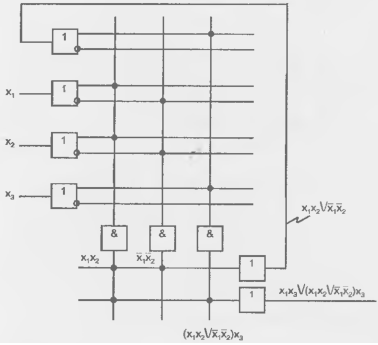
Рисунок 14.5 - Схема включения ПЛМ при воспроизведении скобочных форм переключательных функций
Наращивание (расширение) ПЛМ
Если размерность задачи превосходит возможности имеющихся ПЛМ, приходится их наращивать. Когда число функций в системе N превосходит число выходов ПЛМ. несколько ПЛМ включаются параллельно по входам (рис 14.6). На выходах каждой из ПЛМ воспроизводится часть функций. Общее число ПЛМ определяется как [ N/n ]. Так как число термов предполагается достаточным (ℓ сист < ℓ ) все ПЛМ могут быть запрограммированы на одни и те же термы
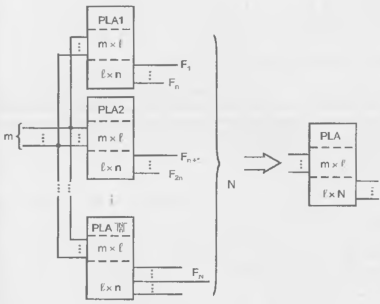
Рисунок 14.6 - Схема расширения ПЛМ по числу выходов
Если число термов системы ℓ сист ℓ превышает число термов ПЛМ (ℓ сист ℓ ), то к одной ПЛМ подключаются дополнительные с тем же числом входов и выходов. По входам ПЛМ включаются параллельно а соответствующие выходы соединяются по ИЛИ или просто объединяются, если это выходы с третьим состоянием или возможностями монтажной логики. Каждая ПЛМ программируется на свои термы, затем из термов "собираются" на выходах нужные функции (рис 14.7)
Расширение числа входов— наиболее сложная задача связанная с декомпозицией системы функций. В частном случае, если все термы содержат не более m переменных, множество термов можно разбить на подмножества, содержащие не более m одинаковых переменных. Для реализации потребуется число ПЛМ, равное числу подмножеств, а выходы ПЛМ будут соединены так же, как и при расширении числа термов. Входными переменными каждой ПЛМ будут только связанные с образованием термов данного подмножества.
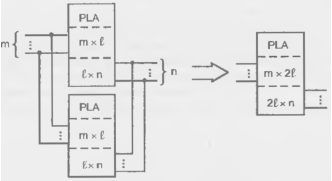
Рисунок 14.7 - Схема расширения ПЛМ по числу термов.
Часто в числе входных переменных ПЛМ имеются тактирующие сигналы, взаимно исключающие друг друга в смысле одновременности вхождения в термы. Такие сигналы можно разделить на группы (подмножества), каждая из которых вместе с оставшимися переменными может обрабатываться отдельной ПЛМ (рис 14.8).
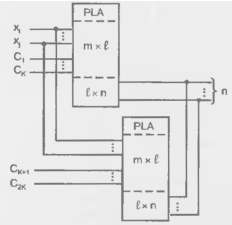
Рисунок 14.8 - Схема первого варианта расширения ПЛМ по числу входа.
Стандартным приемом расширения ПЛМ по входам является перенос избыточного числа аргументов на предварительный дешифратор, выходы которого разрешают работу одной из ПЛМ, обрабатывающих оставшуюся часть аргументов. Этот прием рассматривался ранее применительно к наращиванию дешифраторов и других схем. Расширение числа входов ПЛМ на единицу, произведенное по такому методу, показано на рис. 14.9. Для значительного расширения числа входов этот прием мало пригоден, т. к. избыточные переменные образуют слова, подвергающиеся полной дешифрации, что резко увеличивает число ПЛМ в схеме (удваивает с добавлением каждого избыточного входа).
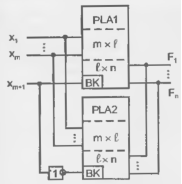
Рисунок 14.9 - Схема расширения числа входов ПЛМ на единицу.
Первые отечественные ПЛМ были выпущены в составе серии К556 (микросхемы РТ1, РТ2 схемотехнологии ТТЛШ с программированием прожиганием перемычек). Их размерность 16 входов, 48 термов, 8 выходов, задержка около 50 нс. Микросхема РТ1 имеет выходы с открытым коллектором. Микросхема РТ2 имеет выходы с тремя состояниями.
Программируемая матричная логика
Одно из важных применений БИС программируемой логики — замена ИС малого и среднего уровня интеграции при реализации так называемой произвольной логики. В этих применениях логическая мощность ПЛМ зачастую используется неполно. Это проявляется, в частности, при воспроизведении типичных для практики систем переключательных функций, не имеющих больших пересечений друг с другом по одинаковым термам. В таких случаях возможность использования выходов любых конъюнкторов любыми дизъюнкторами (как предусмотрено в ПЛМ) становится излишним усложнением. Отказ от этой возможности означает отказ от программирования матрицы ИЛИ и приводит к структуре ПМЛ (PAL, GAL).
В ПМЛ (рис. 14.10) выходы элементов И (выходы первой матрицы) жестко распределены между элементами ИЛИ (входами матрицы ИЛИ). В показанной ПМЛ m входов, n выходов и 4n элементов И, поскольку каждому элементу ИЛИ придается по четыре конъюнктора.
В сравнении с ПЛМ схемы ПМЛ имеют меньшую функциональную гибкость. т. к. в них матрица ИЛИ фиксирована, но их изготовление и использование проще. Преимущества ПМЛ особенно проявляются при проектировании несложных устройств.
Подготовка задач к решению на ПМЛ имеет много общего с подходом к решению задач на ПЛМ, но есть и различия. Для ПМЛ важно уменьшить число элементов И для каждого выхода, но если для ПЛМ стремятся искать представление функции с наибольшим числом общих термов, то для ПМЛ это не требуется, поскольку элементы И фиксированы по своим выходам и не могут быть использованы другими выходами (т. е. для других функций).
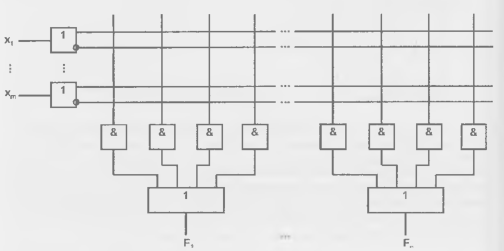
Рисунок 14.10 - базовая структура ПМЛ.
Функциональные разновидности ПЛМ и ПМЛ
Рассмотренные структуры ПЛМ и ПМЛ - базовые с которых началось развитие этих направлений. В дальнейшем происходило обогащение функциональных возможностей ПЛМ и ПМЛ с помощью ряда приемов, в первую очередь следующих.
Схемы с программируемым выходным буфером
В этих схемах обеспечивается возможность получения выходных функций в прямом или инверсном виде. В такой схеме (рис. 14.11) выработанные матрицами функции Fi*...Fn* проходят через выходной буфер, разрядные схемы которого выполнены как сумматоры по модулю 2.
В показанной на рисунке схеме вторые входы сумматоров получают нулевые сигналы от потенциала "земли" через плавкие перемычки ПП. При этом Fj* = Fi и функции с выхода матриц передаются через буфер без изменений. Если пережечь перемычку у нижнего входа сумматора, то он получит сигнал логической единицы от источника питания через резистор R. Складываясь по модулю 2 с единицей, функции Fj* инвертируются. Следовательно, в линиях с целыми перемычками функции проходят через буфер неизменными, а в линиях с отсутствующими перемычками — инвертируются.
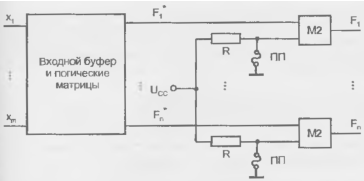
Рисунок 14.11 - Схема программируемого выходного буфера.
Программируемый буфер дает дополнительные возможности для минимизации числа термов в реализуемой системе. В исходной системе можно заменять функции их инверсиями, если это приводит к уменьшению числа термов. Никаких последствий в смысле введения дополнительных схем это не вызовет — возврат к исходной системе будет обеспечен просто программированием буфера.
Пример
Пусть нужно воспроизвести систему из двух функций:
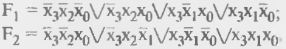
Карты Карно для этих функций (рис. 14.12) показывают контуры, соответствующие 8 различным термам системы:
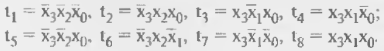
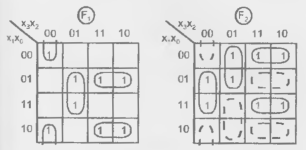
Рисунок 14.12 - Карты Карно для примера воспроизведения функций В ПЛМ с программируемым выходным буфером.
При инвертировании функции единицы занимают в карте Карно те позиции, которые были нулями. Видно, что при инвертировании одной из функций получим карты Карно с меньшим количеством различных термов. При инвертировании, например, функции F2 получим карту с контурами, показанными штриховыми пиниями, и систему функций.
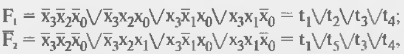
в которой всего пять различных термов Возврат от функции 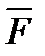 2 к функции F2 осуществляется пережиганием перемычки в линии выхода F2.
2 к функции F2 осуществляется пережиганием перемычки в линии выхода F2.
Схемы с двунаправленными выводами
Используя элементы с тремя состояниями выхода, можно построить схему, в которой некоторые выводы можно приспосабливать для работы о качестве входов или выходов в зависимости от программирования перемычек. В такой схеме один из конъюнкторов предназначен для управления элементом с тремя состояниями выхода (рис. 14.13). Выход элемента одновременно связан с матрицей И как вход.
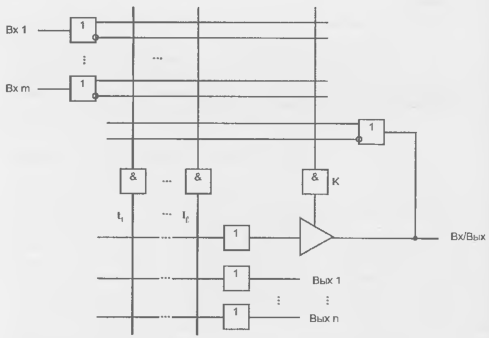
Рисунок 14.13 - Схема с двунаправленным буфером.
Возможны четыре режима вывода Вх/Вых в зависимости от того, как запрограммированы входы конъюнктора К:
1. Все перемычки нетронуты. В этом режиме на выходе конъюнктора К будет нуль, буфер имеет третье состояние выхода и вывод функционирует как вход.
2. Все перемычки пережжены, на выходе конъюнктора единица, буфер активен, вывод работает как выход (его сигналы не используются в матрице И).
3. Выход с обратной связью. Этот режим отличается от предыдущего только тем, что сигналы вывода используются в матрице И.
4. Управляемый выход. Здесь входы конъюнктора программируются. При заданной комбинации входных сигналов конъюнктор приобретает единичный выход, и вывод срабатывает как выход.
В схеме с некоторым числом двунаправленных выводов можно изменять соотношение числа входов-выходов. Если число входов равно m, число выходов n и число двусторонних выводов р, то можно иметь число входов от m до m + р и число выходов от n до n +р при условии, что сумма числа входов и выходов не превосходит m + n + р.
Схемы с памятью
Эти схемы позволяют строить автоматы наиболее удобным способом, т. к. помимо комбинационной части содержат на кристалле триггеры (регистры), обычно типа D (рис. 14.14). ПЛМ с памятью характеризуется четырьмя параметрами. Кроме трех обычных параметров, она имеет и параметр г — число элементов памяти (разрядов регистра). Структура рис. 14 14 совпадает с канонической схемой автомата. Результат данного шага обработки информации зависит в ней от результатов предыдущих шагов, что обеспечивается обратной связью с регистра на вхол ПЛМ. Максимальное число внутренних состояний автомата 2Т. Автомат рассматривается как синхронный — петля обратной связи активизируется только по разрешению тактовых сигналов ТС.
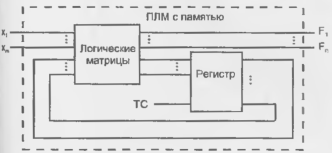
Рисунок 14.14 - Структура ПЛМ с памятью.
ПМЛ с разделяемыми коньюнкторами
Наряду с модификациями схем, рассмотренными выше, существуют и специфические модификации, относящиеся только к ПМЛ. К ним относится вариант с так называемыми разделяемыми конъюнкторами. Прием "разделения конъюнкторов" состоит в следующем. Для двух смежных элементов ИЛИ отводится некоторое количество конъюнкторов (например, 16), которое может быть произвольно разделено между этими смежными элементами. Другие элементы ИЛИ использовать данный набор конъюнкторов не могут. Полного программирования матрицы ИЛИ здесь не возникает, но все же эта модификация является шагом в направлении к ПЛМ. Вариант с разделяемыми конъюнкторами смягчает наиболее очевидное ограничение функциональных возможностей простых (жестких) ПМЛ — фиксированное число элементов И на входах элементов ИЛИ, которого может не хватить при воспроизведении сложных функций. Имея ПМЛ с разделяемыми конъюнкторами и размешан сложную функцию рядом с простой, можно позаимствовать часть общего набора конъюнкторов у простой функции в пользу сложной.
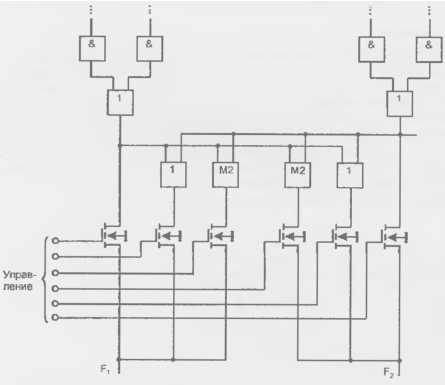
Рисунок 14.15 - Пример реализации разделения термов в ПМЛ.
Вариант схемотехнической реализации разделяемости конъюнкторов показан на рис. 14.15. В ПМЛ имеется дополнительный набор элементов ИЛИ и сложения по модулю 2 (ИСКЛЮЧАЮЩЕЕ ИЛИ), с помощью которого можно комбинировать сигналы выходов обеих основных схем ИЛИ для образования окончательных значений функций F1 и F2 Выходы основных схем ИЛИ могут объединяться по операциям дизъюнкции или сложения по модулю 2 и распределяться по основным выходам F1 и F2. Операция сложения по модулю 2 дает дополнительные функциональные возможности. Характер получаемых функций зависит от того, какой из трех транзисторов в показанных двух группах будет проводящим.
ПМЛ серии К1556
Первая отечественная ПМЛ появилась в серии KPI556 (микросхема ХЛ8, за которой последовали ИС ХП4, ХПб, ХП8). Микросхема ХЛВ — ПМЛ с двунаправленными выводами (входами-выходами), структура которой показана на рис. 14.16. Число входов может изменяться от 10 (входы, показанные с левой стороны матрицы) до 16, если все двунаправленные выводы В2...В7 запрограммированы как входы. Число выходов изменяется от 2 до 8. Суммарное число входов и выходов не может превышать 18.
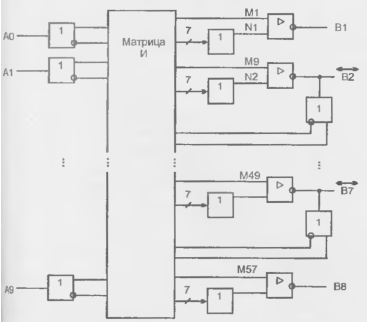
Рисунок 14.16 - Структура ПМЛ КР1556ХЛ8.
Выходные буферы ПМЛ получают разрешение или запрещение работы от матрицы И, как было рассмотрено в предыдущем параграфе. Набор элементов ИЛИ состоит из 8 элементов с семью входами, т. е. на каждый элемент ИЛИ приходится по 7 конъюнкторов с числом входов от 10 до 16. Исходя из сказанного, можно оценить и размерность матрицы И. содержащей 2048 узлов (64 х 32).
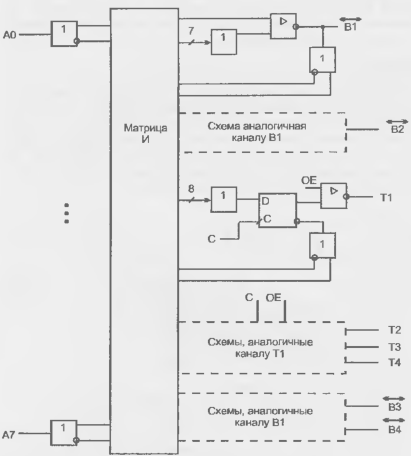
Рисунок 14.17 - Структура ПМЛ КР1556ХП4.
В микросхемах типа ХП имеются элементы памяти — триггеры типа D. число которых совпадает с цифрой в обозначении ИС (4. 6 или 8). Структура ИС ХП4 (рис. 14.17) имеет первый уровень логики, на котором образуются термы входных переменных, второй уровень — матрица ИЛИ. состоящая из 8 дизъюнкторов (четырех 7-входовых и четырех 8-входовых). Выходные усилители выполнены по схеме с тремя состояниями. Четыре D-триггера имеют управление от положительного фронта внешнего синхросигнала С. Сигнал ОЕ управляет буферами, подключенными к выходам триггеров.
Число входов у ПМЛ типа ХП — восемь, число выходов 8(4), 8(2) и 8 для ХП4, ХП6 и ХП8 соответственно, задержка между выводами вход-выход не более 40 нс, а между тактовым сигналом и выходом не более 25 нс. Потребление тока — 180 мА.
Пример подготовки задачи к решению с помощью ПМЛ
Пусть на ПМЛ КР1556ХП4 требуется реализовать 4-х разрядный синхронный счетчик, выполняющий помимо операции счета также операцию параллельной асинхронной загрузки.
Для реализации устройства на основе ПЛМ или ПМЛ его функции нужно определить как систему переключательных функций.
Обозначим выходы разрядов счетчика, начиная с младшего, через Q0, Q1, Q2, Q3- Сигнал асинхронной звгрузки обозначим как LE (Load Enable). Загружаемое слово — А3А2А1А0. Триггер младшего разряда счетчика переключается от каждого входного сигнала при отсутствии сигнала загрузки и принимает значение А0 при загрузке. Следовательно, для его выхода в новом состоянии можно записать
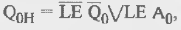
где первое слагаемое отображает процесс переключения триггера, а второе — параллельную загрузку.
Следующий разряд переключается только при условиях отсутствия сигнала загрузки и единичном состоянии триггера младшего разряда. При Q0 = 0 этот триггер сохраняет свое состояние. Для его выхода можно записать:
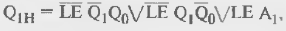
где первое слагаемое отображает переключение триггера, второе — сохранение его состояния при QQ = 0, третье — загрузку.
Продолжая аналогичные рассуждения, для последующих разрядов счетчика можно получить соотношения:
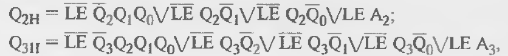
где первые слагаемые отображают процесс переключения разряда, последние — параллельную загрузку, а промежуточные — сохранение состояния при отсутствии условий переключения.
Поскольку искомые функции содержат не более пяти конъюнкций, возможна их непосредственная реализация на микросхеме ХП4 (в этой микросхеме число элементов И нв входах элементов ИЛИ составляет 7 или 8 для разных выходов. При проектировании устройств на основе ПЛМ и ПМЛ пользуются подсистемами автоматизации проектирования, т. к. ручная подготовка задачи может оказаться неприемлемо громоздкой. Для подсистемы автоматизированного проектирования подготовка данных проводится с использованием входного языка таблиц или систем булевых уравнений, записанных в предусмотренной языком форме. Данные для программатора, пережигающего перемычки, получаются автоматически.
В подобных подсистемах имеются также режимы входного контроля ИС, проверяющего целостность перемычек ИС до программирования; ввода данных с эталона, т. е. уже запрограммированной ИС, установленной в специальную соединительную розетку; сравнения данных о программировании, находящихся в памяти подсистемы, с состоянием перемычек ИС и др.
В зарубежной схемотехнике ПМЛ получили широкое распространение. Примером может служить микросхема PAL22V10 (буква V появилась от слова Versatile — гибкий, подвижный). У этой микросхемы 10 выходов, различающихся числом подключенных к ним конъюнкторов. Разные выходы имеют от 8 до 16 конъюнкторов. Выходные величины вырабатываются не просто дизъюнкторами, а более сложными схемами, называемыми макроэлементами (макроячейками).
Схема макроэлемента PAL 22V10 содержит триггер типа D с цепями тактирования, асинхронного сброса AR и синхронной установки SP1 (рис. 14.18). Мультиплексор "4—1" работает на выходной буфер, мультиплексор "2—1" передает сигналы обратной связи в матрицу И. Цепи с плавкими перемычками программируют мультиплексоры. На вход мультиплексора "4—1" подаются прямой и инверсный сигналы от логической части ПМЛ, а также регистровый выход (с триггера) и его инверсия. Сигнал обратной связи можно взять с выхода ПМЛ или с выхода триггера. При установке выходного буфера в третье состояние внешний вывод может быть использован как вход. Таким образом, любой из 10 программируемых выходов может быть либо входом, либо комбинационным или регистровым выходом при Н-активности или L-активности выходного сигнала.
Макроячейки, подобные макроэлементам микросхемы 22V10, имеются также в широко известных схемах типа GAL фирмы Lattice Semiconductor.
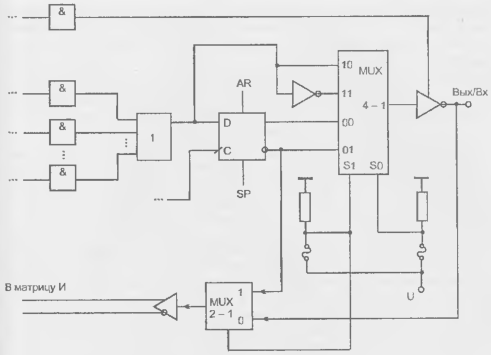
Рисунок 14.18 - Схема макроэлемента PAL 22V10.
Пример более сложной структуры PLD
На рис. 14.19 показана структура (матрица И и один из 12 макроэлементов) БИС, интересная тем, что, будучи простой, сочетает в себе, тем не менее, несколько типичных для PLD приемов повышения функциональной гибкости: возможность разделения термов между соседними макроэлементами, программируемость полярности вырабатываемой логической функции (реализуемость F или F), программируемость типа триггера (D или Т), возможность выбора комбинационного или регистрового выхода, двунаправленность внешнего вывода.
Единая матрица И имеет 32 входа для подачи входных переменных и два входа для подачи сигналов обратной связи е выхода мультиплексора и использования внешнего вывода макроячейки в качестве входа при установке выходного буфера в третье состояние.
Конъюнкторы, имеющие по 68 входов, вырабатывают термы, которые подаются на элементы ИЛИ (по четыре терма на каждый из двух элементов ИЛИ). Столбец из четырех программируемых мультиплексоров реализует разделяемость термов, позволяя данному макроэлементу не только использовать термы от своих конъюнкторов, но и получать термы от соседних макроэлементов (при программировании мультиплексоров 1 и 4 на передачу данных от верхних входов) или отдавать свои термы соседям с выходов четырехвходовых дизъюнкторов.
Окончательный набор термов формируется дизъюнктором, на входы которого поступают выходные сигналы мультиплексоров столбца. Программирование мультиплексора на передачу данных от нижнего входа исключает поступающие на него термы из формируемого набора.
Выработанная логическая функция передается в дальнейшие части макроэлементу через сумматор по модулю 2. на второй вход которого при программировании может быть подана логическая единица или логический ноль. В первом случае, проходя через элемент М2, функция инвертируется, во втором — не изменяется. Выход элемента М2 подключен к мультиплексору, информационные входы которого помечены буквами D и Т. Если этот мультиплексор запрограммирован на передачу сигнала от входа D, то триггер просто получает сигнал и функционирует как триггер типа D Если же мультиплексор запрограммирован на передачу сигнала от входа Т. то триггер через обычный элемент сложения по модулю 2 замкнут в петлю обратной связи. При этом нулевое значение сигнала на верхнем входе обычного (не программируемого) элемента М2 обеспечивает передачу на вход триггера сигнала его текущего состояния Q, т. е. при поступлении тактового импульса состояние триггера сохранится. Единичное значение сигнала на верхнем входе элемента М2 приводит к сложению величины Q с единицей по модулю 2, т. е. к подаче на вход триггера через мультиплексор величины О, что ведет к переключению триггера. Видно, что в этом случае триггер работает как синхронный триггер типа Т. причем роль сигнала Т играет сигнал на выходе программируемого элемента М2.
Мультиплексор, информационные входы которого помечены буквами R (от Registered) и С (от Combinatorial), осуществляет в зависимости от программирования выбор типа выхода макроэлемента — в виде запоминаемого сигнала Q от триггера или непосредственно комбинационной функции по линии С, идущей в обход триггера. Через буфер с тремя состояниями выход макроэлемента связан с контактной площадкой (внешним выводом). Если буфер находится в третьем состоянии контакт может использоваться как входной, с которого сигнал поступает в матрицу И.
Для управления триггером можно выбрать с помощью мультиплексора со входами А и S либо синхронный вариант (т. е. тактирование общим синхросигналом всей микросхемы), либо асинхронный (т. е. с выработкой сигнала тактирования от отдельного терма, иначе говоря, разрешением принятия информации при появлении определенной комбинации входных сигналов матрицы И).
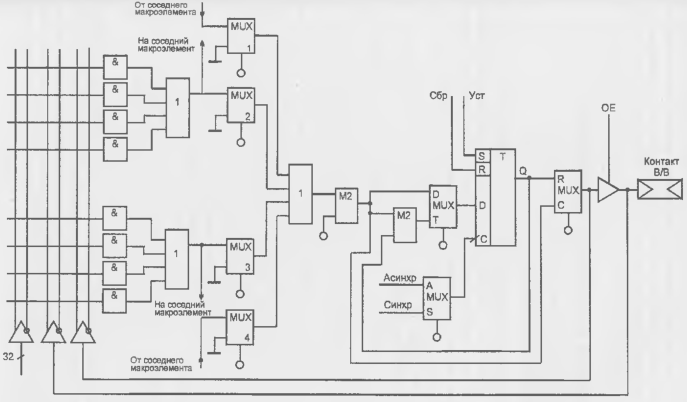
Рисунок 14 19 - Структура БИС типичной PLD.
Микросхема реализована по КМОП технологии, ее сложность оценивается числом 1800 эквивалентных вентилей. Двенадцать макроэлементов за счет комбинирования своих термов с термами соседних макроэлементов позволяют получать логические функции от 4, 8, 12 либо 16 термов. Время распространения сигналов через матрицу составляет приблизительно 25 нс.
Базовые матричные кристаллы (вентильные матрицы с масочным программированием)
Первые образцы базовых матричных кристаллов (БМК) появились в 1975 г. как средство реализации нестандартных схем высокопроизводительной ЭВМ без применения микросхем малого и среднего уровней интеграции. Разработка БМК, кроме того, позволила выполнить и нетиповые части машины на БИС
Стоимость проектирования БИС/СБИС велика и достигает десятков или даже сотен миллионов долларов. Ясно, что производство БИС/СБИС становится рентабельным только при достаточно большом объеме их потребления, чего нет при разработке нестандартных частей конкретных систем.
Выход из создавшихся трудностей был найден на путях разработки БИС/СБИС, функционирование которых может быть приспособлено к решению той или иной задачи на заключительных этапах их производства. При этом полуфабрикаты производятся в массовом количестве без ориентации на конкретного заказчика. Придание полуфабрикатам индивидуального характера лишь на заключительных стадиях производства БИС/СБИС обходится значительно дешевле и требует значительно меньшего времени на проектирование. Такие БИС/СБИС называют полузаказными в отличие от полностью заказных.
Развитие полузаказных БИС/СБИС привело к появлению ряда их разновидностей. Применительно к БМК эto канальные, бесканальные и блочные архитектуры.
Прежде чем подробнее остановиться на рассмотрении перечисленных вариантов, уточним терминологию. Термин БМК характерен для литературы на русском языке и поэтому используется здесь наиболее часто. В английской терминологии принят термин GA (Gate Array), чему соответствует русский термин — вентильная матрица. В силу тенденции к единообразию терминов "вентильная матрица" предпочтительнее, и, видимо, со временем станет основным обозначением данного типа БИС/СБИС. Основа БМК первого поколения — совокупность регулярно расположенных на кристалле базовых ячеек (БЯ), между которыми имеются свободные зоны для создания соединений (каналы). Эта архитектура называется канальной. Базовые ячейки занимают внутреннюю область БМК, в которой они расположены по строкам и столбцам, и содержат группы нескоммутированных элементов (транзисторов, резисторов и др.). В периферийной области кристалла размещены ячейки ввода-вывода, набор схемных компонентов которых ориентирован на реализацию связей БМК с внешними цепями. Таким образом, БМК является заготовкой, которая преобразуется в требуемую схему выполнением необходимых соединений. Потребитель может реализовать на основе БМК некоторое множество устройств определенного класса, задав для кристалла тот или иной вариант рисунка межсоединений компонентов.
Первые БМК (фирмы Amdahl Corp., США) выполнялись по схемотехнике ЭСЛ, для которой полный процесс изготовления включал 13 операций с фотошаблонами. Для изготовления схемы на основе БМК (такие схемы называют МАБИС или БИСМ) требуются только 3 индивидуальных (переменных) шаблона для задания рисунка межсоединений. Соответственно этому сроки и стоимость проектирования МАБИС в 3...5 раз меньше, чем для полностью заказных БИС/СБИС.
Плата за сокращение сроков и стоимости проектирования — неоптимальность результата. МАБИС проигрывают по площади кристалла и быстродействию полностью заказным схемам, т. к. часть их элементов оказывается избыточной (не используется в данной схеме), взаимное расположение элементов и пути межсоединений не являются наилучшими и т. д.
Промышленное производство БМК широко развернулось с начала 80-х годов. Применяются схемотехнологии КМОП, ТТЛШ, ЭСЛ и др. В настоящее время уровень интеграции БМК достиг миллионов вентилей на кристалле. При проектировании БМК стремятся наилучшим образом сбалансировать число базовых ячеек, трассировочные ресурсы кристалла и число контактных площадок для подключения внешних выводов. Неудачные соотношения между указанными параметрами могут существенно ограничивать полноту использования ресурсов кристалла при построении МАБИС.
Трассировочная способность БМК определяется, прежде всего, площадью, отводимой для межэлементных связей в ортогональных направлениях. Учитывается и число слоев межсоединений. Недостаточная трассировочная способность приводит к уменьшению числа задействованных при построении МАБИС базовых ячеек. Избыточная трассировочная способность ведет к нерациональному использованию площади кристалла, что понижает уровень интеграции БМК и повышает его стоимость. Примерно то же можно сказать и о числе внешних выводов БМК. Для современных БМК может потребоваться до 500...600 внешних выводов. При проектировании БМК требуемые трассировочная способность и число внешних выводов рассчитываются по эмпирическим формулам, основанным на статистических данных, полученных из опыта построения систем различного назначения. Эта работа выполняется до изготовления БМК и в этом смысле не входит в компетенцию системотехника. Системотехник (потребитель) должен иметь представление о существующих БМК, их разновидностях и особенностях, а также о средствах и методике разработки МАБИС.
До описания разновидностей БМК остановимся подробнее на основных понятиях и определениях.
Базовая ячейка (БЯ) уже определялась как некоторый набор схемных элементов, регулярно повторяющийся на определенной площади кристалла. Этот набор может состоять из нескоммутированных элементов, а также из частично скоммутированных. Базовые ячейки внутренней области БМК именуются матричными базовыми ячейками (МБЯ), ячейки периферийной зоны — периферийными базовыми ячейками (ПБЯ). Применяются два способа организации ячеек БМК:
из элементов МБЯ может быть сформирован один логический элемент, а для реализации более сложных функций используются несколько ячеек;
из элементов МБЯ может быть сформирован любой функциональный узел, а состав элементов ячейки определяется схемой самого сложного узла.
Функциональная ячейка (ФЯ) — функционально законченная схема, реализуемая путем соединения элементов в пределах одной или нескольких БЯ. Библиотека функциональных ячеек — совокупность ФЯ. используемых при проектировании МАБИС. Эта библиотека создается при разработке БМК и избавляет проектировщика МАБИС от работы по созданию на кристалле тех или иных типовых подсхем, т. к. предоставляет для их реализации готовые решения. Библиотека содержит большое число (сотни) функциональных элементов, узлов и их частей. Пользуясь библиотекой, проектировщик реализует схемы, работоспособность которых уже проверена, а параметры известны. Работая с библиотекой, он ведет проектирование на функционально-логическом уровне, поскольку проблемы схемотехнического уровня уже решены при создании библиотеки. Библиотечные элементы имеют различную сложность (логические элементы, триггеры, более сложные узлы или их фрагменты). В состав библиотечного элемента могут входить одна или несколько БЯ. Площадь библиотечного элемента кратна площади БЯ. При проектировании МАБИС функциональная схема изготовляемого устройства, как принято говорить, должна быть покрыта элементами библиотеки.
Эквивалентный вентиль (ЭВ) — группа элементов БМК, соответствующая возможности реализации логической функции вентиля (обычно это двух-входовой элемент И-НЕ либо ИЛИ-НЕ). Понятие "эквивалентный вентиль" предназначено для оценки логической сложности БМК.
Каналы трассировки — пути на БМК для возможного размещения межсоединений.
Классификация БМК
Классификация БМК показана на рис. 14.20. Первоначальной и, в известной мере, классической является структура канального БМК (рис. 14.21, а). Во внутренней центральной) области такого БМК расположена матрица базовых ячеек 1 и каналы для трассировки 2.
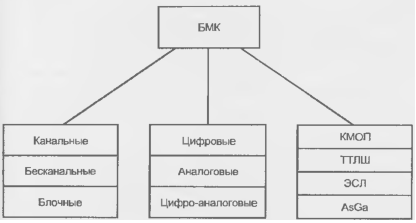
Рисунок 14.20 - Классификация базовых матричных кристаллов.
Каналы могут быть вертикальными и горизонтальными как на рис. 14.21. а. либо только вертикальными (рис. 14.21. б). Канальные БМК могут иметь большие возможности по созданию связей, по имеют низкую плотность упаковки из-за значительных затрат площади кристалла на области межсоединений.
Канальная архитектура характерна для биполярных БМК, т. к. значительная мощность рассеивания биполярных БЯ сама по себе препятствует плотной их упаковке.
Повышение уровня интеграции БМК ведет к быстрому росту числа необходимых межсоединений между базовыми ячейками, а значит и площади, отводимой для них. Поиск путей создания БМК высокого уровня интеграции с минимизацией площади, отводимой под межсоединения, привел к бесканальной архитектуре БМК. Внутренняя область такого БМК содержит плотно упакованные ряды базовых ячеек и не имеет фиксированных каналов для трассировки межсоединений (рис. 14.21, в). В этом кристалле любая область, в которой расположены БЯ (строка, столбец либо их часть) может быть использована как для создания логической схемы, так и для создания межсоединений. Вследствие более рационального расположения связей в бесканальном БМК уменьшается и задержка передачи сигналов по связям, т. к. и длины и паразитные емкости межсоединений уменьшаются.
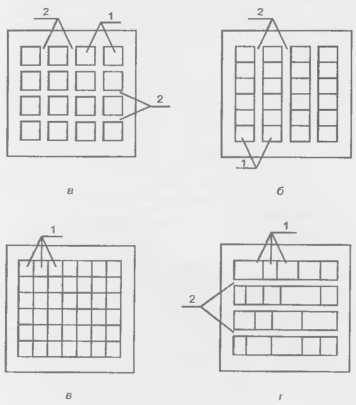
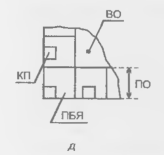
Рисунок 14.21 - Структуры БМК различных типов (а), (б), (а), (г) и расположение областей БМК (д).
Бесканальные БМК характерны для КМОП-схемотехники, в которой компактность схемных элементов и малая мощность рассеяния БЯ при их работе на не слишком высоких частотах способствуют возможностям плотной упаковки базовых ячеек.
Бесканальные БМК реализуются в вариантах "море вентилей" и "море транзисторов ". Первый содержит массив законченных логических элементов, второй — массив транзисторов.
Так как в бесканальных БМК, называемых иногда универсальными, положение трассировочных каналов и ячеек на рабочем поле не является жестким и при проектировании конкретной МАБИС площадь кристалла может перераспределяться между трассировочными каналами и функциональными ячейками, потери площади кристалла снижаются. Например, в БМК с плотным расположением на рабочем поле рядов транзисторов в некоторых рядах реализуются логические элементы, а другие ряды используются под трассировочные каналы, в них транзисторы остаются песком мутированными и не используются (над ними проходят трассы). В зависимости от загруженности каналов, для них может быть отведено различное число рядов транзисторов.
В КМОП БМК используются также архитектуры с переменной длиной ячеек (рис. 14.21, г). Здесь каждая строка представляет собою последовательное соединение пар n- и р-канальных транзисторов. Если в такой длинной цепи разместить в заданных местах пары запертых транзисторов, то цепочка будет разделена на базовые ячейки произвольной длины. Возможность варьирования длиной БЯ ведет к более рациональному построению МАБИС и, следовательно, к повышению уровня интеграции реализуемых на БМК схем.
Внутренняя область кристалла (ВО) окружена периферийной областью (ПО) (рис. 14.21, д), расположенной по краям прямоугольной пластины БМК. В периферийной области расположены специальные ПБЯ, набор схемных элементов которых ориентирован на решение задач ввода/вывода сигналов, а также контактные площадки (КП). Рост уровня интеграции ведет к возможностям реализации на одном кристалле все более сложных устройств и систем. Это вызвало к жизни блочные структуры БМК, архитектура которых упрощает построение комбинированных устройств, содержащих как блоки логической обработки данных, так и память или другие специализированные блоки. При этом в БМК реализуются несколько блоков-подматриц, каждый из которых имеет как бы структуру БМК меньшей размерности. Между блоками располагаются трассировочные каналы (рис. 14.22). На периферии блоков изготовляются внутренние буферные каскады для формировании достаточно мощных сигналов, обеспечивающих передачу сигналов по межблочным связям, имеющим относительно большую длину
Тип обрабатываемых сигналов (цифровые, аналоговые) влияет на качество и состав схемных элементов базовых ячеек. В связи с этим БМК подразделяются на цифровые, аналоговые и цифроаналоговые. Аналоговые и цифроаналоговые БМК, появившиеся позднее цифровых и менее распространенные, имеют состав базовых ячеек, позволяющий получать на их основе такие схемы, как операционные усилители, аналоговые ключи и компараторы и т. д.
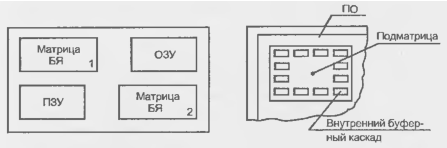
Рисунок 14.22 - Блочная структура БМК.
Классификация по используемой схемотехнике отражает только основные варианты БМК. Варианты максимального быстродействия реализуются на схемах типа ЭСЛ или, что более экзотично, на арсениде галлия. Большое место занимает схемотехника КМОП, проявляющая свойственные ей известные достоинства. На основе схемотехнологии ТТЛШ выполнялись БМК среднего быстродействия.
Кроме перечисленных, известны и другие по схемотехнике БМК. Например, БМК на основе схемотехники БиКМОП, кремний на диэлектрике и др. Однако эти варианты не принадлежат, по крайней мере пока, к числу широко распространенных.
Важной характеристикой БМК является число слоев межсоединений (в настоящее время это 2...6). Многослойность облегчает трассировку и позволяет изготовлять БМК более высокого уровня интеграции. В простейшем случае двухслойной трассировки на первом (нижнем) уровне обычно выполняются переменные соединения внутри БЯ (часть соединений не зависит от реализуемой на БМК схемы и постоянна) и связи по вертикальным каналам. Этот слой делается либо в виде диффузионной области самого кристалла, либо в виде поли кремниевых или металлических дорожек. Второй слой металлизированных соединений дает разводку горизонтальных трасс и обслуживающих линий (питание, "земля", синхронизация и т. д.).
В четырехслойном кристалле в первом слое задаются связи внутри БЯ, во втором — вертикальные трассы, в третьем — горизонтальные, а в четвертом — обслуживающие цепи.
При увеличенном числе слоев можно исключить трассировочные каналы между ячейками, перейдя к бесканальным структурам. На рис. 14.23 показан компонентный состав БЯ БМК типа ЭСЛ, рассчитанный на реализацию двухъярусных логических элементов. Не рассматривая функциональные возможности схем, получаемых на основе таких БЯ, укажем только, что резисторы R0. входящие в состав источников тока для вышележащих переключателей, могут включаться параллельно или последовательно. Это даст возможность получить несколько значений переключаемых токов, т. е. модификации схем, отличающиеся быстродействием и потребляемой мощностью.
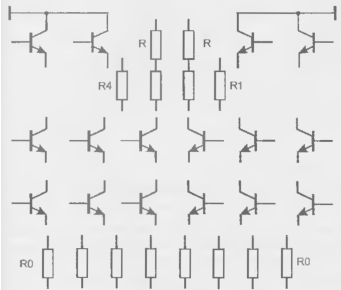
Рисунок 14.23 - Компонентный состав базовой ячейки БМК типа ЭСЛ.
На рис. 14.24 представлен один из вариантов БЯ БМК inria КМОП. Схемными элементами таких БЯ служат только транзисторы с р- и n-каналами. Число транзисторов в ячейке выбирается по результатам анализа частоты использования различных логических элементов в устройствах заданного класса и преобладающих требований по нагрузочной способности, быстродействие и т. д. Высокий коэффициент использования транзисторов дают кристаллы с числом транзисторов в ячейке 4, 8 или 10. На рис. 14.24 показаны топология и электрическая схема ячейки с 4 транзисторами. Квадратные элементы топологического рисунка — контактные площадки к затворам и фиксированные контактные окна к элементам ячейки. Транзисторы можно соединять последовательно или параллельно, т. е. можно получать типовые подсхемы логических элементов И-НЕ и ИЛИ-НЕ. В схемотехнике КМОП транзисторы с противоположными по типу проводимости каналами всегда используются попарно, поэтому пары транзисторов могут иметь общий затвор.
Усложнение ячейки достигается объединением простых ячеек в группу.
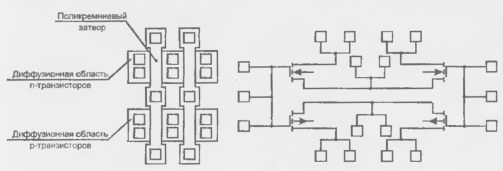
Рисунок 14.24 - Вариант базовой ячейки БМК типа КМОП.
Параметры БМК
Параметры БМК можно разделить на 4 группы:
□ функциональные возможности (число эквивалентных вентилей, тип БЯ, число МБЯ и ПБЯ, состав библиотеки функциональных ячеек и т. п.);
□ электрические параметры (уровни напряжений, кодирующих логические сигналы, напряжения питания, потребляемые токи, задержки распространения сигналов, максимальные частоты переключений и т. п.);
□ конструктивно-технологические (тип корпуса, число выводов, число уровней металлизации, площадь кристалла и т. п.);
□ эксплуатационные характеристики (устойчивость к воздействию внешних факторов, надежность и т. п.).
В табл. 14.2 приведены основные параметры некоторых отечественных БМК представляющих разные схемотехнологические типы.
Таблица 14.2

На уровне мировой техники изготовляются БМК с миллионами эквивалентных вентилей, обладающих задержками 0,1...0,2 нс.
.
Лекция № 15
ТЕМА: FPGA. Сложные программируемые логические устройства (CPLD). Использование программируемых логических интегральных схем (ПЛИС)
Основные вопросы, рассматриваемые на лекции:
1. FPGA
2. CPLD
3. ПЛИС
4. Применение FPGA, CPLD, ПЛИС
5. Переспективы развития FPGA, CPLD, ПЛИС.
Продолжением линии ПМЛ стали БИС/СБИС CPLD (Complex Programmable Logic Devices), а линии БМК— FPGA (Field Progiammable Gate Arrays). Стремление объединить достоинства обеих линий привело к созданию БИС/СБИС смешанной (комбинированной) архитектуры, для которых еше не выработано общепринятое название (фирма Altera пользуется названием FLEX (Flexible Logic Element MatriX) гибкие). Рост уровня интеграции дал возможность размещать на кристалле схемы, сложность которых соответствует целым системам. Эти схемы именуются SOC (Systems On Chip).
Сказанное иллюстрируется рис. 15.1, где пол MPGA понимаются Mask Programmable GAs (вентильные матрицы с масочным программированием или БМК).
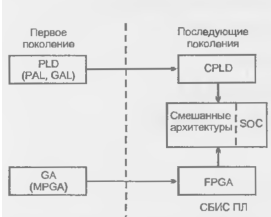
Рисунок 15.1 - Взаимосвязь поколений СБИС программируемой логики.
В разработке СБИС ПЛ участвуют уже десятки фирм, ведущими среди них являются Xilinx, Altera, Actel, Atmel, AMD (Vantis), Lattice (все США) и некоторые другие. Перечисленные фирмы достаточно полно представляют спектр продукции в области СБИС ПЛ, хотя и не исчерпывают ее. Последующее изложение темы ориентировано в основном на разработки фирм Xilinx, Altera и Actcl.
Сфера применения СБИС ПЛ чрезвычайно широка, на них могут строиться не только крупные блоки систем, но и системы в целом, включая память и процессоры. Области применения СБИС ПЛ уточняются в дальнейшем, предварительно отмстим важность таких применений, как отработка прототипов систем при их проектировании, даже если конечная реализация систем рассчитана на другие средства, и создание малотиражных изделий быстрыми и эффективными способами.
СБИС ПЛ классифицируются по нескольким признакам.
Классификация по конструктивно-технологическому типу программируемых элементов
Классификация СБИС ПЛ по конструктивно-технологическому типу показана на рис. 15.2. Программируемость, т. е. реализуемость конкретного проекта на стандартной СБИС, обеспечивается наличием в ней множества двухполюсников, проводимость которых может быть задана пользователем либо очень малой (это соответствует разомкнутому ключу), либо достаточно большой (это соответствует замкнутому ключу). Состояния ключей задают ту или иную конфигурацию схеме, формируемой на кристалле. Число программируемых двухполюсников (программируемых точек связи ПТС) в СБИС ПЛ зависит от ее сложности и может доходить до нескольких миллионов. Для современных СБИС ПЛ характерны следующие виды программируемых ключей:
П перемычки типа antifuse (русский термин отсутствует); П ЛИЗМОП транзисторы с двойным затвором);
П ключевые транзисторы, управляемые триггерами памяти конфигурации ("теневым" ЗУ).
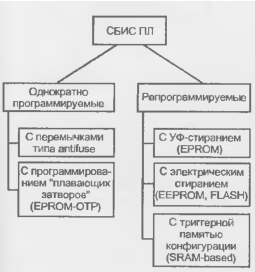
Рисунок 15.2 - Классификация СБИС ПЛ по типу программируемых элементов.
Программирование с помощью перемычек типа antifuse является однократным. Высококачественные перемычки фирмы Actel (рис. 15.3) компактны, имеют очень малые токи в первоначальном (непроводящем) состоянии (около одного фемтоампера. 1 фА = 10-15А). Перемычка образована трехслойным диэлектриком с чередованием слоев "оксид-нитрид-оксид". Соответственно чередованию слоев Oxid-Nitrid-Oxid перемычки также называют перемычками типа ONO.
Программирующий импульс напряжения пробивает перемычку и создает проводящий канал из поликремния между электродами (один электрод поликремниевый, другой — диффузионная область n+). Величина тока, создаваемого импульсом программирования, влияет на диаметр проводящего канала, что позволяет управлять параметрами проводящей перемычки (ток 5 мА создает перемычки со средним значением сопротивления 600 Ом, ток 15 мА — 100 Ом). Размер ℓ зависит от топологической нормы применяемой технологии (близок к ней). Паразитная емкость перемычки для топологической нормы I мкм менее 10 фФ. Параметры обоих состояний перемычки должны сохраняться около 40 лет.
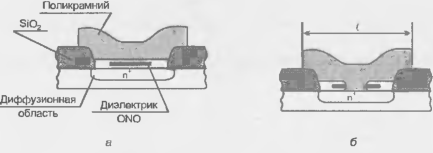
Риcунок 15.3 - Программируемые перемычки типа ONO до (а) и после (б) программирования.
Элементы EPROM и EEPROM (Flash) на ЛИЗМОП транзисторах с плавающим затвором используются в схемах программируемой памяти. Точно так же используются они и в СБИС ПЛ. Из элементов с УФ-стиранием выделился вариант вообще без возможности стирания данных — вариант EPROM-OTP (OTP, One Time Programmable). Если в обычных EPROM стирание данных производится облучением кристалла через прозрачное окошко в корпусе, то в схемах OTP дорогостоящий корпус с окошком заменен на дешевый без окошка, т. е. возможность стирания исключается.
Схемы с триггерной памятью конфигурации (SRAM-based) впервые разработаны фирмой Xilinx.
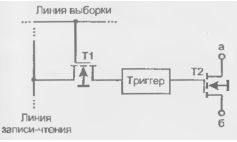
Рисунок 15.4 - Схема ключевого транзистора, управляемого триггером памяти конфигурации.
Загрузка соответствующих данных в память конфигурации программирует СБИС ПЛ. Быстрый процесс оперативного программирования может производиться неограниченное число раз. В СБИС ПЛ с триггерной памятью конфигурация разрушается при каждом выключении питания. При включении питания необходим процесс программирования (инициализации, конфигурирования) схемы — загрузка данных конфигурации из какой-либо энергонезависимой памяти, что требует времени порядка десятков и даже сотен миллисекунд, если речь не идет о специальных СБИС ПЛ с так называемым динамическим оперативным репрограммированием.
Триггеры памяти конфигурации распределены по всему кристаллу СБИС вперемешку с элементами схемы, которые они конфигурируют. Ключевой транзистор Т2 (в английской терминологии pass-transistor) можно назвать программируемой точкой связи ПТС. В английской терминологии используется название Programmable Interconnection Point, сокращенно PIP.
Репрограммирование СБИС ПЛ с триггерной памятью конфигурации производится в том же режиме, что и рабочий режим, путем записи кодовой последовательности в цепочку триггеров. Стирание информации как специфический процесс воздействия на запоминающие элементы, требующий относительно длительных операций, вообще устранено. Несмотря на повышенную сложность запоминающего элемента и его энергозависимость в силу указанных и других (рассматриваемых ниже) достоинств. СБИС ПЛ с триггерной памятью конфигурации занимают важнейшее место в новых вариантах FPGA и CPLD.
Говоря об общих свойствах СБИС ПЛ, следует отметить, что благодаря регулярной структуре они реализуются с уровнем интеграции, близким к максимальному. Так как для средств программирования межсоединений требуются затраты дополнительной площади кристалла, СБИС ПЛ по уровню интеграции уступают БМК, но в последнее время все более успешно их догоняют.
В отличие от БМК, СБИС ПЛ выпускаются как полностью готовые, в них реализованы уже не только логические элементы, триггеры и т п., но и межсоединения. Потребитель СБИС ПЛ не обращается к их изготовителю для выполнения каких-либо завершающих операций, т. к. программирование выполняет самостоятельно. Это дает основания отнести СБИС ПЛ к стандартной продукции, что сопровождается известными преимуществами массовостью производства и снижением стоимости.
Как и при разработке других микросхем высшего уровня интеграции, в случае СБИС ПЛ большое внимание уделяется вопросам понижения потребляемой мощности. С ростом сложности СБИС потребляемая мощность становится наиболее критическим фактором. Так как мощность пропорциональна квадрату напряжения питания Ucc, его снижение дает значительный эффект. Если длительное время типовым напряжением питания микросхем и в том числе БИС/СБИС ПЛ было 5 В, то сейчас это могут быть напряжения 3,3 В; 2,7 В; 1,8 В и даже 1,5 В.
Поскольку передача сигналов низкого уровня по внешним связям неприемлема из-за малой помехоустойчивости таких сигналов, часто в СБИС используются два напряжения питания: повышенное для схем ввода/вывода данных и меньшее для питания основных логических схем и накопителей памяти. Соответственно этому для разных областей кристалла могут изготовляться транзисторы с разными пороговыми напряжениями.
Для быстродействующих низковольтных схем разрабатывается глубоко субмикронная технология КМОП и возрождается старая идея построения схем типа "кремний на диэлектрике" (SOI, Silicon On Insulator), в которых устранены многие паразитные схемные элементы. В схемах особо низковольтной логики достигается очень малая мощность элементов, например, 4,3 нВт/вентиль/МГц. При этом плотность упаковки такова, что достижима схемная сложность до 40 млн вентилей (около 100 млн транзисторов).
В схемах СБИС ПЛ нередко используется иерархия режимов понижения мощности.
В активных режимах часто при программировании используется так называемый Турбо-бит, с помощью которого выбирается один из двух режимов. Значение ON этого бита увеличивает скорость работы схемы при ограничении мощности допустимым значением. При состоянии OFF этот бит дает режим уменьшения мощности (со снижением скорости).
Для реализации режима с Турбо-битом используются специальные схемы выявления фактов изменения входных сигналов. Каждый вход снабжается несложной схемой, содержащей элементы ИЛИ, М2 и элемент задержки. Любое изменение входного сигнала выявляется и вызывает подачу на схему нормального питания, необходимого для быстрого протекания в ней процессов переключения. Затем автоматически питание схемы снижается, токи переходят на микроамперные уровни, и потребляемая мощность падает до начала новых переходных процессов из-за новых изменений входных сигналов. Схема выявления перепадов входных сигналов увеличивает задержку на пути "вход-выход" СБИС на 30—40%. Программируемый Турбо-бит дает возможность пользователю предпочесть любой из вариантов работы схемы — более скоростной или более экономичный по потребляемой мощности. Турбо-бит включен в файл программирования СБИС.
Режим Standby Power (мощности в режиме ожидания) используется, когда все входные переменные сохраняют неизменные значения. При этом схема сохраняет готовность к переходу в рабочий режим. Могут применяться и режимы глубокого понижения мощности с очень малым уровнем ее потребления. В этих режимах схема сохраняет свое информационное состояние, но для перехода в рабочий режим с обычными параметрами быстродействия требуется определенное время.
Эффективность СБИС ПЛ стимулирует быстрый рост соответствующей отрасли промышленности и объемов их производства, а также научных исследований по развитию их архитектур, схемотехники, алгоритмов решения практических задач.
Программируемые пользователем вентильные матрицы (FPGA)
Программируемые пользователем вентильные матрицы (ППВМ или FPGA) топологически сходны с канальными БМК. В их внутренней области размешается множество регулярно расположенных идентичных конфигурируемых логических блоков (КЛБ), между которыми проходят трассировочные каналы, а на периферии кристалла расположены блоки ввода/вывода (БВВ или IOB, Input/Output Blocks). Таким образом, архитектуру ППВМ можно представить рисунком, подобным рис. 14.21, а, д, если вместо наименования "базовая ячейка" иметь в виду наименование КЛБ, а вместо "периферийной ячейки" — БВВ. К наиболее известным FPGA относятся БИС/СБИС семейств ХС2000, ХС3000, ХС4000, ХС5000 и Spartan фирмы Xilinx, которая в 1985 г. впервые выпустила FPGA с триггерной памятью конфигурации. Среди FPGA с перемычками типа antifuse следует отметить семейства ACTI, I200XL, АСТЗ, 3200DX фирмы Actel. используемые, в частности, в космической аппаратуре США.
Свойства и возможности FPGA зависят в первую очередь от характера их КЛБ и системы межсоединений.
Логические блоки FPGA
В качестве КЛБ (далее для краткости просто ЛБ — логические блоки) используются:
транзисторные пары, простые логические вентили И-НЕ. ИЛИ-НЕ и
т. и. Такие ЛБ называют SLC — Simple Logic Cells;
логические модули на основе мультиплексоров;
логические модули на основе программируемых ПЗУ, такие ЛБ называют LUTs — Look-Up Tables.
Важной характеристикой ЛБ является их "зернистость" (Granularity). Другой важной характеристикой считается "функциональность" (Functionality). Первое свойство связано с тем, насколько "мелкими" будут те части, из которых можно "собирать" нужные схемы, второе — с тем, насколько велики логические возможности ЛБ.
Примером наиболее мелкозернистого может служить ЛБ фирмы Crosspoini Solutions (рис.15.5, а). Блок содержит цепочки транзисторов с р- и n-каналами (на рисунке использованы американские обозначения транзисторов, более простые, чем отечественные). ЛБ — пара из транзисторов разного типа проводимости (выделенный прямоугольник). Между цепочками транзисторов имеются трассировочные каналы, в которых могут быть реализованы необходимые межсоединения элементов.
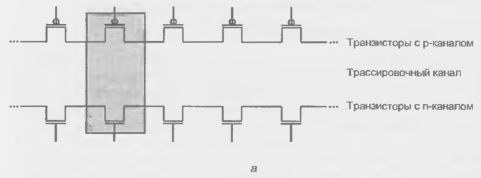
Рисунок 15.5 - Схема мелкозернистых логических блоков (а).
Рисунлк 15.5. (окончание) Реализация межсоединений для воспроизведения функции x1x2vx3x4 (б) и пояснения к этой реализации (в. г).
На рис. 15.5, б показан пример межсоединений, дающих реализацию функции
F = x1x2vx3x4. Пары транзисторов в прямоугольниках из штриховых линий имеют такие постоянные напряжения на затворах, что оказываются запертыми. Эти пары разделяют цепочки на части, изолированные друг от друга. В трех секциях собраны схемы типа рис. 15.5, в, т. е. ячейки И-НЕ обычного для схемотехники КМОП типа. Эти ячейки соединены между собою как показано на рис. 15.5, г, что и приводит к нужному результату.
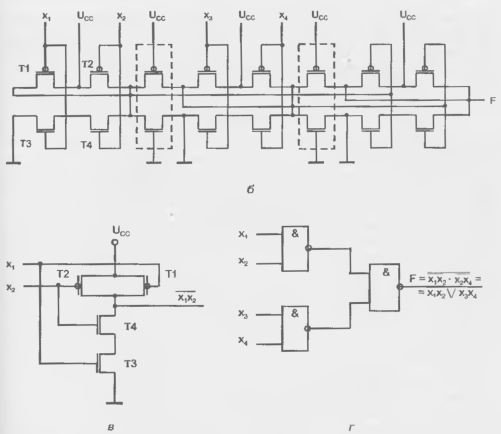
Мелкозернистость ЛБ ведет к большей гибкости их использования, возможностям реализовать воспроизводимые функции разными способами, получая разные варианты в координатах "площадь кристалла — быстродействие". В то же время мелкозернистость ЛБ усложняет систему межсоединений FPGA в связи с большим числом программируемых точек связи. Примерами более крупнозернистых ЛБ могут служить используемые в семействе микросхем ACT фирмы Actel. На рисунке (см. рис. 2.15, а) был показан ЛБ семейства ACTI, состоящий из ipcx мультиплексоров "2—1" и элемента ИЛИ, для которого воспроизводимую функцию можно представить следующим образом:
Подключая ко входам ЛБ переменные и константы, можно получить все комбинационные функции двух переменных, все функции трех переменных с, по меньшей мере, одним положительно юнатным входом, многие функции четырех переменных и некоторые функции большего числа переменных, вплоть до восьми. В целом получаются 702 различных варианта (макроса). Например, подключая ко входам переменные и константы соответственно (рис. 8.6), где S0 = с; S1 = SA — В0 = 0, А0= А 1 = 1, В 1 = a, S B =Ь, получим функцию F = abV  .
.
Крупнозернистый блок семейства ХС4000Е (рис. 15.6) в качестве основы имеет три табличных функциональных логических преобразователя G. F и Н. а также ряд программируемых мультиплексоров (отмечены номерами 1...12
или надписями у выходов) и два триггера
В FPGA с триггерной памятью реконфигурации, как правило, применяют крупнозернистые блоки. В таких блоках реализуются более сложные функции, что ведет к упрощению программируемой части межсоединений. В то же время труднее полностью использовать логические элементы блоков, что ведет к потерям площади кристалла и быстродействия. Иными словами, меняя зернистость, можно выиграть в одном и проиграть в другом.
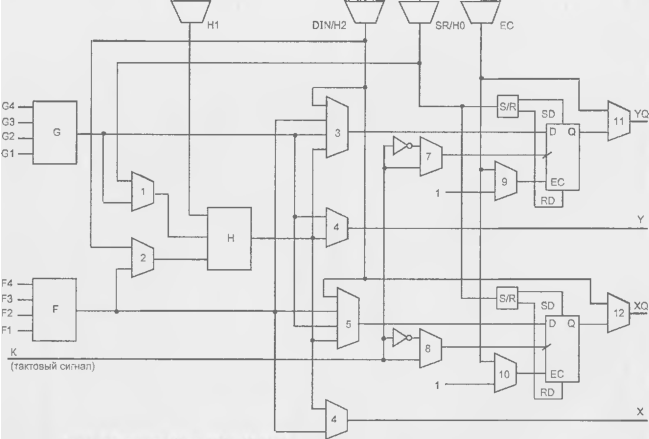
Рисунок 15.6 - Схема логического блока FPGA ХС4000Е.
Табличные преобразователи представляют собой ППЗУ, для которых аргументы логической функции служат адресом. Воспроизводятся любые функции числа аргументов n при организации памяти 211 х 1. Число воспроизводимых функций, т. е. число возможных вариантов программирования ЗУ, составляет 22" Логические преобразователи G и F (блоки памяти с организацией 16 х 1) воспроизводят функции 4-х аргументов. Их выходные сигналы могут непосредственно передаваться на выходы Y п X при соответствующем программировании мультиплексоров 4 и 6. либо использоваться иным образом. Через мультиплексоры 1 и 2 выходы преобразователей G и F могут быть поданы на входы преобразователя Н, если мультиплексоры запрограммированы на передачу сигналов от нижних входов Кроме того, преобразователь Н может использоваться как третий независимый генератор функций со входами Н0, H1 и Н2, если мультиплексоры 1 и 2 запрограммированы иначе. Входной сигнал H1 может добавляться как дополнительный аргумент и при подаче на преобразователь Н выходов преобразователей G и F. При подаче выходных сигналов преобразователен G и F на вход преобразователя Н он воспроизводит функции большего, чем 4 числа аргументов (от 5 до 9, причем для 5 аргументов воспроизводятся любые функции, а для 6...9 лишь некоторые).
В зависимости от программирования мультиплексоров 3 и 5, триггеры принимают данные от логических преобразователей или внешнего входа D1N. Сигналы К тактирования триггеров поступают от общею входа через мультиплексоры 7 и 8. программирование которых позволяет индивидуально изменять полярность фронта, тактирующего триггеры. Сигнал разрешения тактирования ЕС также поступает oт общего входа, но, благодаря мультиплексорам 9 и 10, можно либо использовать сигнал разрешения, либо постоянно разрешить тактирование. Триггеры имеют асинхронные входы установки и сброса (SD — Set Direct и RD — Reset Direct), один из которых через программируемый селектор S/R может быть подключен к выходу коммутатора SR, который, в свою очередь, может программироваться для подключения к любому из внешних выводов ЛБ С1...С4 Это же возможно и для других выходов коммутаторов верхней строки рис. 15.6.
В специальных режимах блоки G и F функционируют как обычные ОЗУ, способные хранить 32 бита данных. Возможна реализация двухпортовых ОЗУ. буферов FIFO и т. д. Память распределена по всему кристаллу.
Блоки ввода/вывода FPGA
Характерные черты блока ввода/вывода рассмотрим па примере семейств ХС4000, ХС4000Е (рис. 8.8). Блок имеет два канала — для ввода сигналов и для вывода. В каждом канале сигналы могут передаваться прямым путем или фиксироваться в триггерах в зависимости от программирования мультиплексоров 7 и 4. При переводе буфера 1 в третье состояние выходной контакт не должен оставаться разомкнутым, т. к. на "плавающем" высокоомном входе элементов типа КМОП может накапливаться любой заряд, что может имитировать ввод в схему непредусмотренных сигналов.
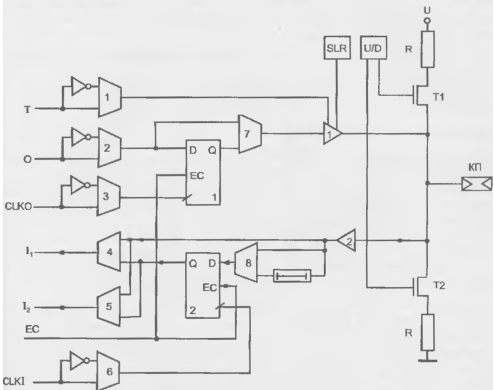
Рисунок 15.7 - Схема блока ввода/вывода FPGA семейства ХС4000Е
Благодаря резисторам R потенциал разомкнутой контактной площадки КП либо "подтягивается" к высокому уровню, либо привязывается к нулевой точке. Выбор между этими вариантами программируется элементами памяти конфигурации, имеющимися в схеме U/D (Up/Down). Выходной буфер 1 имеет регулировку крутизны фронта (линия SLR, Slew Rale). Скорости нарастания выходного сигнала можно придать одно из двух значений (быстрая и медленная), для чего имеется программируемый элемент памяти в схеме SLR. Пологие фронты снижают уровень помех, возникающих при работе схемы, и желательны везде, где это приемлемо по соображениям быстродействия. При включении питания во всех буферах устанавливается режим пологих фронтов. Если внешний вывод работает в режиме входа (буфер 1 в третьем состоянии, буфер 2 активен), то внешний сигнал может подаваться в микросхему либо напрямую, либо через триггер, либо в обоих вариантах одновременно. В последнем случае блок ввода/вывода может демультиплексировать внешние сигналы (например, для шин адресов/данных сохранять адрес в триггере и передавать данные но прямому входу). Синхросигналы триггеров различны для входного (CLK1) и выходного (CLK0) триггера. Их полярности, как и полярность выходного сигнала О (Output), могут программироваться соответствующими мультиплексорами.
Сигнал на входе триггера 2 можно специально задерживать на несколько наносекунд программированием мультиплексора 8. Это сделано для такого подбора временного положения сигнала относительно тактирующего импульса, при котором обеспечивается совместимость с шиной PCI.
Системы межсоединений FPGA
Системы межсоединений (системы коммутации), как и логические блоки, реализуются в широком диапазоне архитектурных и технологических решений. Линии связей в FPGA обычно сегментированы, т. е. составлены ire проводящих сегментов (участков, не содержащих ключей) различной длины, соединяемых друг с другом программируемым элементом связи (ключом). Малое количество сегментов ведет к недостаточно эффективному использованию логических блоков, слишком большое — к появлению большого числа программируемых ключей в линиях связи, что увеличивает затраты площади кристалла и вносит дополнительные задержки сигналов.
Короткие сегменты затрудняют реализацию длинных связей, длинные — коротких. Поэтому целесообразна иерархическая система связей с несколькими типами межсоединений для передач на разные расстояния. Целью построения системы связей является обеспечение максимальной коммутируемости блоков при минимальном количестве ключей и задержек сигналов, а также предсказуемость последних, облегчающая проектирование.
Наличие ключей и схем для их программирования усложняют межсоединения FPGA сравнительно с межсоединениями БМК.
Критерий трассировочной способности системы межсоединений отображает возможность создания в FPGA множества схем типового применения (только с помощью программируемых ключей, т. к. сегментная часть соединений стандартная). Быстродействие FPGA существенно зависит от задержек сигналов в связях. Ключ в линии связи имеет схему замещения в виде RC-звена. В последовательной цепочке RC-звеньев задержка зависит от числа звеньев квадратично, поэтому цепи с большим числом ключей в них особенно нежелательны. Может оказаться целесообразным разбиение длинной линии на несколько коротких с помощью промежуточных буферных каскадов.
В разработке FPGA с однократным программированием перемычками antifuse ведущую роль играет фирма Actet. Логические блоки в FPGA этой фирмы располагаются в виде горизонтальных рядов, между которыми имеются трассировочные каналы. В каналах горизонтально в четыре строки расположены сегменты различной длины и различного взаимного положения по горизонтали. Через ЛБ и трассировочные каналы проходят вертикальные сегменты. Каждый вход ЛБ соединен со своим вертикальным сегментом, пересекающим ближайший канал. В зависимости от положения входа ЛБ, ближайший канал может находиться выше или ниже данного ряда ЛБ. Выход ЛБ имеет свой вертикальный сегмент, пересекающий несколько каналов (рис. 15.8).
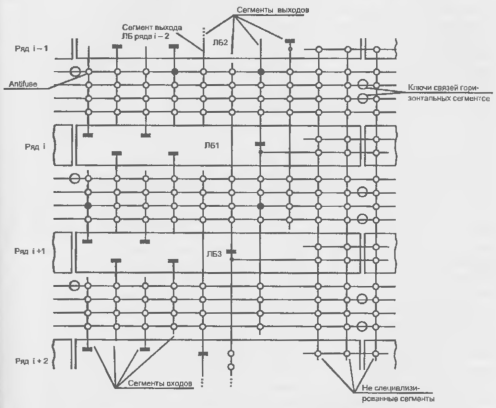
Рисунок 15.8 - Система коммутации fpga фирмы Actel (для упрощения рисунка пересечения горизонтальных и вертикальных линий без их соединения показаны просто светлыми кружками, хотя точнее было бы показать их в виде-ф-)
В каждом пересечении сегментов предусмотрена программируемая перемычка, позволяющая соединять эти сегменты. Такая система коммутации обеспечивает разнообразие вариантов соединения ЛБ между собой. Выход какого-либо ЛБ соединяется с теми горизонтальными сегментами, которые связаны с входами других ЛБ, получающих сигнал от данного выхода. На рис. 15.8 показаны ЛБ с 4 входами, имеющими выводы в ближайший трассировочный канал. Кружками обозначены программируемые перемычки, позволяющие создавать связи между линиями пересечения. Выходы ЛБ соединены с вертикальными сегментами, пересекающими два канала выше данного ряда и два канала ниже его. Имеются ключи, связывающие при необходимости концы горизонтальных сегментов друг с другом для удлинения линий связи. В каналах имеются также непрерывные по всей длине сегменты, один из которых заземлен, а другой соединен с источником питания, что позволяет подавать на любой из входов ЛБ сигналы логического нуля или логической единицы. В вертикальных направлениях идут также неспециализированные сегменты, пересекающие несколько рядов ЛБ и трассировочных каналов. Каждый такой вертикальный сегмент может соединяться с горизонтальными, которые он пересекает. К таким сегментам есть связи от выходов соседних ЛБ. Наличие неспециализированных вертикальных сегментов увеличивает трассировочную способность системы коммутации.
На рис. 15.8 для примера показаны зачерненными кружками те перемычки, которые должны быть запрограммированы для подачи сигнала с выхода ЛБ1 на входы блоков ЛБ2 и ЛБЗ.
В семействах FPGA фирмы Actel экономно реализуется адресация программируемых перемычек. Чтобы запрограммировать перемычку, г. с. замкнуть ее, к ней следует приложить повышенное напряжение Unp. Это осуществляется следующим образом. Вначале выполняется предзаряд всех сегментов напряжением Unp/2. Для этого в схеме имеются специальные транзисторные ключи, включенные параллельно перемычкам и используемые только при программировании и тестировании FPGA В рабочих режимах ключи заперты и практически не влияют на работу схемы. При замыкании всех этих ключей сегменты соединяются в единые линии, которым и задают необходимые потенциалы. Для замыкания перемычки воздействуют на линии строки и столбца, в пересечении которых находится перемычка. Одна из этих линий заземляется, а другая подсоединяется к напряжению Uпp. Как видно, при этом только перемычка на пересечении адресующих линий попадает под напряжение Unp. Все остальные попадают под напряжение Unp/2, не пробивающее перемычку. Транзисторы логических блоков и блоков ввода/вывода, находящиеся в контакте с ceгментами и при программировании перемычек попадающие под повышенное напряжение, специально проектируются с необходимой электрической прочностью Тестирование FPGA производится многократно — до, во время и после программирования.
Система межсоединений FPGA фирмы Xilinx — иерархическая, включающая в себя связи общего назначения (General-Purpose Interconnects), длинные линии (Long Lines) прямые связи (Direct Interconnects) линии тактирования (Clock Lines). Не все перечисленные разновидности связей встречаются одновременно в одной FPGA. Связи общего назначения имеются у всех FPGA, а прямые связи, например, не у всех.
Связи общего назначения FPGA ХС4000Е показаны рис. 15.9, а. В этой системе переключательные блоки (переключательные матрицы) расположены на пересечении горизонтальных и вертикальных трассировочных каналов, каждый из которых имеет восемь линий.
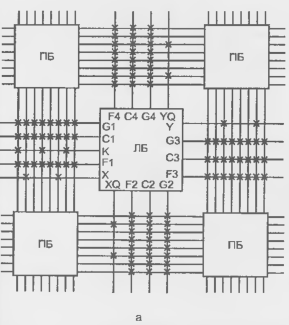
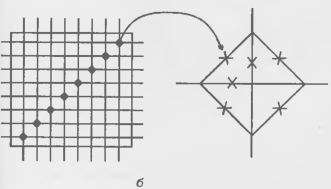
Рисунок 15.9 - Схема связей общего назначения с линиями одинарной длины (а) и схема переключательного блока (б) FPGA семейства ХС4000Е.
Линии могут иметь одинарную длину (соединяя соседние переключательные блоки ПБ) или двойную (соединяя ПБ через один для сокращения числа ПБ в длинных путях). На рис. 15.9, а показана схема с одинарными линиями. Связи общего назначения позволяют подводить сигналы к разным сторонам логического блока ПБ. Крестиками отмечены программируемые точки связи. Структура одного ПБ показана на рис. 15.9, б. Она позволяет передавать сигналы влево-вправо или вверх-вниз между смежными одинарными линиями, а также изменять направление передачи сигнала. Схема, соответствующая зачерненному квадрату (рис. 15.9, б), показана отдельно справа. Видно, что для обеспечения перечисленных передач в эту схему должны входить 6 ключевых транзисторов. Прохождение сигналов через ПБ вносит в процесс распространения сигнала задержку, зависящую от конкретного пути, что создает проблему возможных гонок сигналов и сбоев в работе схемы.
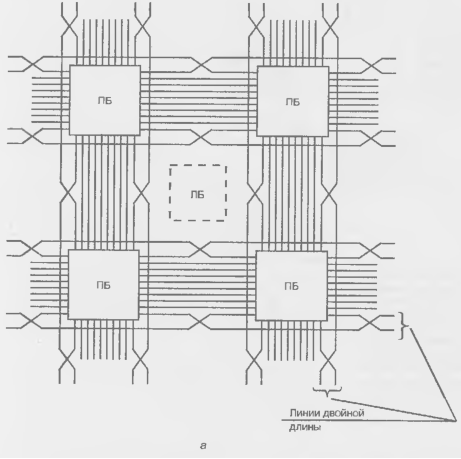
Рисунок 15.10 - Схема связей общего назначения с линиями двойной длины FPGA ХС4000Е (а).
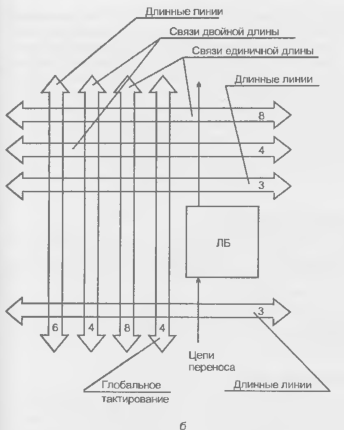
Рисунок 15.10 (окончание) - Общие ресурсы связей этой микросхемы (б).
Для ускорения и упрощения дальних передач приняты специальные меры Наряду со связями общего назначения типа рис. 15.9 имеются связи с линиями двойной длины, в которых переключательные блоки соединены через один, что уменьшает их число при дальних передачах. Фрагмент таких связей представлен на рис. 8.10, а.
Для передач на большие расстояния с очень малой задержкой или для передач на разные приемники с малой расфазировкой сигналов служат длинные линии (здесь термин "длинные линии" имеет прямой смысл, и его не следует путать с аналогичным термином, употребляемым при согласовании волновых сопротивлений). Длинные линии пересекают кристалл вдоль или поперек по всей его длине или ширине (на рисунках не показаны).
В микросхемах семейства ХС4000Е различают несколько типов длинных линий: горизонтальные и вертикальные линии (по несколько на каждую строку и столбец логических блоков), линии для тактирования блоков ввода/вывода (по две линии вдоль блоков ввода/вывода), так называемые глобальные линии с выходами на определенные БВВ. и линии для распределенных дешифраторов. При этом на каждый Л Б приходится по 8 горизонтальных и вертикальных связей с линиями одинарной длины, по 4 с линиями двойной длины, по 6 горизонтальных и вертикальных длинных линий, 4 вертикальных глобальных длинных линии и 2 линии (вертикальных) для образования цепей переноса при построении сумматоров, счетчиков и т. д. Всего на каждый логический блок приходится 24 вертикальных линии и 18 горизонтальных (рис. 8.11, б)
Области применения FPGA и других СБИС ПЛ
Вначале развитие FPGA связывалось с переносом концепции БМК в область малотиражной аппаратуры, но в дальнейшем в связи с появлением репрограммируемости стало ясным, что это нечто большее. Это, в частности, видно из приведенных ниже примеров.
Рассмотренные области применения не являются исключительной прерогативой FPGA, иногда возможно применение других СБИС ПЛ для решения перечисленных задач.
Построение реконфигурируемых систем
В различной аппаратуре встречаются ситуации, в которых те или иные блоки работают поочередно. Например, средства кодирования и декодирования при записи и чтении данных, использующие помехоустойчивые коды. Обе функции никогда не выполняются одновременно. Поэтому не обязательно иметь два устройства (кодер и декодер), а можно иметь одну FPGA с двумя разными конфигурациями, хранимыми в ПЗУ. То есть одна и та же аппаратная часть может выполнять различные преобразования после соответствующей перестройки.
Задачи логической эмуляции
При отладке устройств традиционно пользовались изготовлением прототипа и программными моделями. Изготовление прототипа — сложная и дорогостоящая задача, но с его помощью можно вести тестирование с реальными сигналами и на высоких скоростях, наблюдая фактические возможности устройства. Программное моделирование лишено указанных достоинств, но проще и дешевле. Модели легко изменяются для удаления ошибок в проекте и в них просто обеспечивается хорошая наблюдаемость процессов в объекте исследования. Применение FPGA в задачах логической эмуляции дает сочетание достоинств обоих классических подходов. Система из FPGA легко создается и изменяется, но, с другой стороны, может работать с реальными сигналами и частотами их изменения. Однако по затратам труда и времени создание системы на FPGA сложнее, чем создание программной модели. Поэтому программные модели не зачеркиваются появлением репрограммируемых FPGA. Следует также помнить, что полные свойства окончательно изготовленного устройства логическая эмуляция на FPGA отобразить не может, т. к. временные характеристики зависят от конкретной трассировки схемы, чего еще нет на этане логической эмуляции. Таким образом, логическая эмуляция не отменяет прежние методы разработки и тестирования схем, а лишь хорошо дополняет их.
Кстати говоря, применение репрограммируемых FPGA может принести большую пользу при обучении студентов. Студенческие проекты требуют большой доработки исходных вариантов. На традиционных средствах (макетах) эту работу выполнить сложно из-за трудоемкости и дороговизны. Применение репрограммируемых FPGA может существенно упростить ситуацию.
Построение динамически ре конфигурируемых систем
Динамическая реконфигурация (Run-Time Reconfiguration) применима в системах с выполнением действий по шагам, последовательным во времени, когда в данное время требуется только одна определенная настройка FPGA. Вместо нескольких аппаратных блоков можно использовать один перестраиваемый, т. е. сэкономить аппаратные ресурсы за счет многократного использования одних и тех же средств в разных ролях. FPGA с динамическим реконфигурированием обозначаются DRFPGA (Direct Rcconfigurable FPGA).
Сама DRFPGA может иметь практически любое число настроек, рост их количества ограничивается лишь емкостью памяти для их хранения. Устройства с DRFPGA уже используются практически и дают ожидаемый положительный эффект. В таких устройствах требуется быстрая смена настроек. Обычная настройка с введением в FPGA последовательного потока битов или байт-последовательного потока занимает достаточно большое время. В DRFPGA задача решается иначе. В самой системе уже имеется набор загруженных настроек, быстро сменяющих друг друга соответственно требованиям реализуемого алгоритма. В современной литературе ставится также вопрос о построении FPGA-процессоров с иными в сравнении с микропроцессорами свойствами. Алгоритмы работы процессора загружаются в FPGA принципиально подобно загрузке в память микропроцессорной системы выполняемой программы. Но при работе системы, в противоположность микропроцессорной системе, возникает сильно выраженный параллелизм на уровне мелкозернистых логических блоков с простейшими командами (типа воспроизведения функции от данного числа аргументов). Такие FPGA-процессоры могут давать хорошие результаты при параллельной обработке данных, где большое число переменных преобразуется сходным образом.
Обогащение цифровой элементной базы
Одним из применений FPGA можно считать обогащение элементной базы цифровых устройств новыми микросхемами типа FPIC (FPID) — Field Programmable Interconnect Circuits (Devices).
Микросхемы FPIC содержат программируемые соединения и блоки ввода/вывода, но не имеют логических блоков. Они предназначены для произвольного соединения своих внешних выводов согласно программированию. Для окончательно изготовляемых продуктов это не является необходимым, но при отработке прототипов и в системах с динамически реконфигурируемой структурой такие микросхемы бесспорно полезны. Соединяя СБИС ПЛ через FPIC, можно легко изменять их межсоединения, чего не обеспечивают технологии с жесткой трассировкой (печатные платы и др.). Область применения FPIC более узка, чем у таких СБИС ПЛ как FPGA и CPLD, соответственно тиражность их производства ниже и стоимость выше.
Сложные программируемые логические схемы (CPLD) и СБИС программируемой логики смешанной архитектуры (FLEX и др.)
Сложные программируемые логические ИС (СПЛИС) архитектурно произошли от структур PLD (PAL, GAL) и называются CPLD (Complex Programmable Logic Deivices).
Для русского эквивалента этого названия примем СПЛИС, хотя в ряде работ встречается наименование ПЛИС Следовать этому нежелательно, т. к. многие авторы трактуют термин ПЛИС как наименование всех ИС программируемой логики вообще. Приемлемым вариантом названия для CPLD является и СПЛУ— сложные программируемые логические устройства, что соответствует переводу термина CPLD на русский язык
Архитектурно CPLD состоят из центральной коммутационной матрицы, множества функциональных блоков ФБ (именуемых также макроячейками, макроэлементами и др.) и блоков ввода/вывода на периферии кристалла. Архитектура CPLD показана на рис. 15.11, где через ПМС обозначена программируемая матрица соединений (Р1А, Programmable Interconect Array).
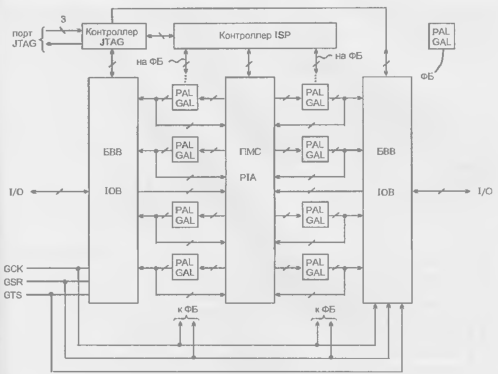
Рисунок 15.11 - Архитектура CPLD.
Функциональные блоки CPLD
Эти блоки подобны PLD и содержат многовходовую (wide) программируемую матрицу элементов И, вырабатывающую конъюнктивные термы из поступающих на ее входы переменных, группу элементов ИЛИ, между которыми распределяются выработанные термы, и некоторые другие элементы, обогащающие функциональные возможности ФБ и подобные. Функциональные блоки реализуют двухуровневую логику с вариантами формируемого результата (прямой или инверсный, комбинационный выход или регистровый выход и т. д.)
Системы коммутации CPLD
В отличие от типичных для FPGA систем сегментированных связей, в CPLD используется непрерывная или одномерно непрерывная система связей, причем все связи идентичны, что дает хорошую предсказуемость задержек сигналов в связях — важное достоинство, облегчающее проектирование и изготовление работоспособных схем высокого быстродействия. В самих линиях связи число программируемых ключей мало, но многие из ключей не будут задействованы, так что система коммутации с единой матрицей в целом требует довольно большого числа ключей.
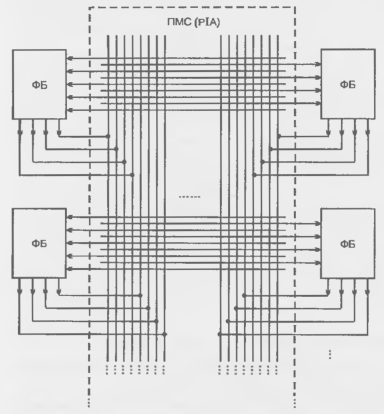
Рисунок 15.12. Схема коммутации функциональных блоков CPLD с помощью программируемой матрицы соединений.
Типичная ПМС (рис. 15.12) позволяет соединять выход любого ФБ со входами других. Входы ФБ связаны с горизонтальными линиями, пересекающими все вертикальные линии. Любой вход может быть подключен к любому выходу программированием точек связи между вертикальными и горизонтальными линиями. Иначе говоря, ПМС обеспечивает полную коммутируемость блоков.
Внутри самих ФБ может существовать локальная система коммутации, подобная глобальной.
CPLD и СБИС ПЛ смешанной архитектуры производятся многими фирмами. К ведущим фирмам относятся Altera (семейства MAX, FLEX, APEX и др.), Atmel (семейство ATF 1500 и др.), Vantis (ранее была известна как фирма AMD, семейство MACH), Xilinx (семейство ХС9500), Philips, Cypress Semicond. и т. д.. В рамках каждого семейства потребителю предлагается ряд представителей, различных по сложности, стоимости и другим параметрам, с целью гибкого обслуживания разнообразных потребностей. Общее число разновидностей CPLD оказывается очень большим. Для более подробного рассмотрения выделим характерные CPLD из продукции ведущих фирм.
Классическими представителями CPLD являются микросхемы МАХ 7000, фирмы Altera, имеющие память конфигурации типа EEPROM. Для "старых" CPLD небольшой сложности триггерная память конфигурации вообще не была характерной. В дальнейшем с освоением глубоко субмикронной технологии и многослойных металлизации положение изменилось, триггерная память конфигурации появилась и в CPLD, но, строго говоря, одновременно изменилась и их архитектура, так что соответствующие СБИС правильнее относить к СБИС ПЛ смешанной архитектуры (FLEX. APEX), рассматриваемым ниже.
CPLD МАХ 7000
На рис. 15.13 показан фрагмент CPLD MAX 7000S, дающий достаточно полное представление о ней, т. к. структура CPLD в целом составляется повторением изображенного на фрагменте яруса из логических блоков ЛБ и блоков ввода/вывода БВВ то или иное число раз (на рис. 15.13 повторяющиеся ярусы должны располагаться сверху вниз) в зависимости от числа ЛБ у данной CPLD, т. е. от ее сложности. На рисунке выделены логические блоки ЛБ, содержащие по 16 макроячеек МЯ, получающих термы от локальных программируемых матриц И (ЛПМИ), программируемая матрица соединений ПМС и блоки ввода/вывода БВВ.
Микросхемы семейства МАХ 7000 имеют маркировку ЕРМ7ХХХ (усовершенствованные варианты отмечаются дополнительной буквой в конце), где в трех последних позициях размещается число МЯ у данной микросхемы (от 032 у младшею представителя до 256 у старшего). Как и во всех СБИС ПЛ, логические операции производятся в ЛБ, которые соединяются в единую схему с помощью ПМС. Каждый ЛБ содержит 16 макроячеек, так что у младшего представителя семейства 2 логических блока, у старшего — 16.
ПМС обеспечивает возможность подачи на любой вход ЛБ сигнала от любого источника (выходов ЛБ или контактов ввода/вывода), причем она организована так, что на пути сигнала нет программируемых ключей, и задержки сигналов малы. Подача сигнала из ПМС в ЛБ (рис. 15.14) происходит через конъюнктор, открытый по второму входу единичным логическим сигналом с помощью программируемого транзистора, когорый не находится в цепи передачи сигнала. На вход ЛБ можно передать сигнал с любой вертикальной линии ПМС. Вертикальные линии непрерывны и идут по всей длине между двумя столбцами из ЛБ.
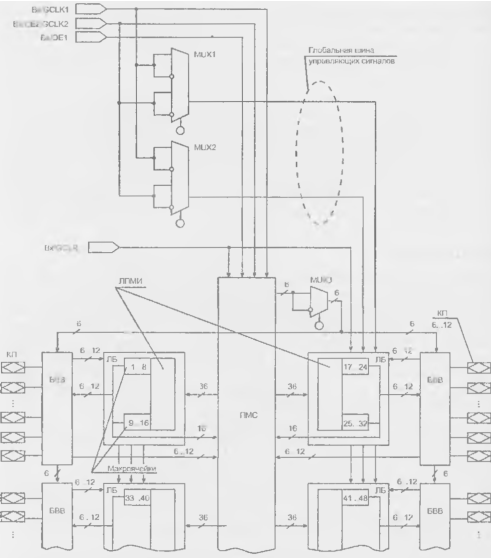
Рисунок 15.13. Фрагмент структуры cpld max 7000S
Каждый ЛБ непосредственно связан со своим блоком ввода/вывода, имеющим от 6 до 12 контактов (КП — контактная площадка). Как видно, не все макроячейки moгут иметь внешний вывод. Часть из них может быть использована только для подачи сигнала обратной связи в ПМС, что является естественным при построении ряда узлов (счетчиков и др.) ПМС получает следующие сигналы: 16 сигналов обратной связи от каждого ЛБ, от 6 до 12 сигналов от ББВ. четыре сигнала (вверху на рис. 8.14) от специализированных входов. Разное число контактов у БВВ позволяет выбирать более экономичный вариант там, где требования интерфейса это допускают.
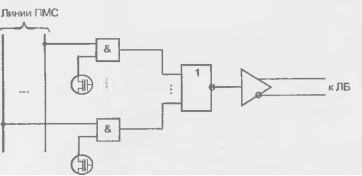
Рисунок 15.14 - Схема передачи сигналов из программируемой матрицы соединений в логические блоки.
К специализированным сигналам относятся так называемые глобальные сигналы тактирования GCLK1 и GCLK2 и сброса GCLR, а также сигналы разрешения выходов ОЕ. Здесь и в других случаях термин "глобальный" означает "единый для всех одноименных блоков СБИС". При необходимости перечисленные линии могут быть использованы как простые входы ПМС. Из ПМС поступает по 36 сигналов для каждого ЛБ и еще 6 сигналов, которые передаются в прямом или инверсном виде через мультиплексор MUX3 для глобальной шины разрешения выходов блока ввода/вывода.
Логический блок обеспечивает построение как комбинационных цепей, так и схем с элементами памяти. Одна из макроячеек МБ показана на рис. 15.15. Из матрицы элементов И в матрицу распределения термов МРТ поступает 5 основных термов (на рисунке слева). МРТ дает возможность использовать эти термы для сборки по ИЛИ с последующей подачей результата на элемент сложения по модулю 2 для образования комбинационной функции, а также для управления триггером но входам сброса (CLRn), установки (PRn). Терм t может быть использован для тактирования триггера или разрешения тактирования в зависимости от программирования мультиплексора MUX2. Триггер может тактироваться от глобального сигнала GCLK с минимальной задержкой поступления сигнала синхронизации от общего входа микросхемы, что типично при реализации синхронных автоматов. Тактирование от глобального сигнала может сопровождаться индивидуальным управлением от сигнала разрешения тактирования ENA, что характерно для построения апериодических автоматов, и, наконец, возможно тактирование локальным сигналом от терма t, что соответствует асинхронным схемам.
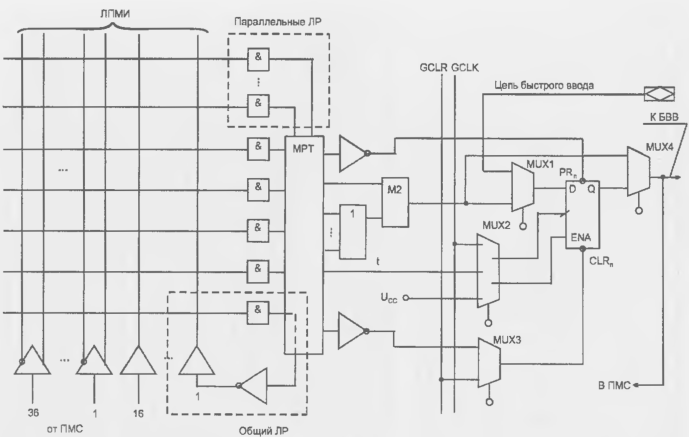
Рисунок 15.15 - Схема макроячеек CPLD MAX 7000S.
Имеются асинхронные сигналы установки и сброса PRn и CLRn, кроме того, сброс возможен и от глобального сигнала GCLR при соответствующем программировании мультиплексора MUX3.
Имеется возможность быстрой загрузки триггера от внешнего вывода по прямой цепи (программируется мультиплексором MUX1). В другом состоянии MUX1 перелает на вход триггера значение функции, выработанное комбинационной частью макроячейки. Мультиплексор MUX4 позволяет подавать на выход макроячейки (к БВВ) либо непосредственно комбинационную функцию, либо хранящуюся в триггере (регистровый выход).
Если для реализации функции макроячейкой недостаточно числа ее собственных термов, можно воспользоваться дополнительно ресурсами двух типов логических расширителей ЛР. Так называемый общий (разделяемый) расширитель образуется за счет использования для него пятой линии термов макроячеек. Терм этой линии вводится в матрицу И и становится доступным (общим) для всех макроячеек. Так как в Л Б 16 макроячеек, общий расширитель может иметь до 16 линий (рис. 15.15).
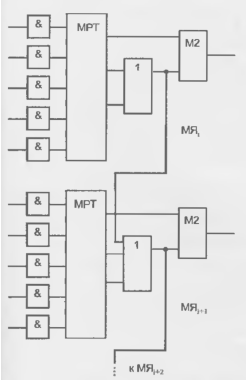
Рисунок 15.16 - Схема параллельного расширителя макроячеек CPLD MAX 7000S.
Логический расширитель, называемый параллельным, образуется за счет коммутации термов предшествующих макроячеек, которые передаются в последующие (рис. 15.16), так что макроячейки связываются в цепочку. Можно образовать цепочку, длина которой не превышает восьми звеньев. Понятно, что вследствие последовательного включения вентилей ИЛИ в выработку результата вносится дополнительная задержка.
Блок ввода/вывода (рис. 15.17) дает возможность гибкого управления разрешением выходного буфера. ПМС формирует шесть глобальных сигналов разрешения выхода ОЕ. Для некоторых представителей семейства МАХ 7000 имеется возможность программирования выхода как выхода с открытым коллектором (ОК), кроме того, может программироваться и скорость изменения выходных сигналов с целью, указанной ранее (эта скорость связана с уровнем создаваемых помех)
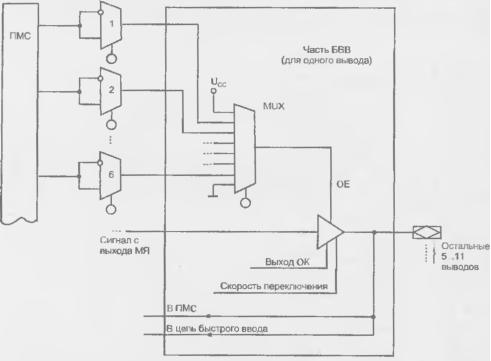
Рисунок 15.17 - Схема блока ввода/вывода CPLD MAX 7000S
После семейства МАХ 7000, принадлежащего ко второму поколению CPLD. фирма Altera выпустила семейство третьего поколения МАХ 9000. Между обоими семействами много общего, но третьему поколению присуши и новые свойства: интерфейс JTAG, программирование в системе ISP без применения повышенных напряжений и др.
Развитие архитектур СБИС ПЛ идет по пути создания комбинированных структур, сочетающих достоинства FPGA и CPLD. Так, например, фирме Altera выпустила семейство FLEX 8000 (Flexible Logic Element MatriX) и позднее FLEX 10K с триггерной памятью конфигурации. По архитектуре микросхемы типа FLEX занимают промежуточное положение между классическими вариантами CPLD и FPGA. Сохранив ряд качеств предшествующих разработок CPLD, микросхемы FLEX в то же время имеют логические элементы табличного типа (LUT). их логические блоки расположены в виде матрицы, причем трассировочные каналы проходят горизонтально и вертикально между ЛБ, что характерно для FPGA. Одновременно с этим трассы в каналах не сегментированы, а непрерывны, что типично для CPLD и дает хорошую предсказуемость и малые величины задержек.
Микросхемы семейства FLEX 10К
Фрагмент структуры микросхем FLEX 10К, по которому можно судить о микросхеме в целом (остальные части являются повторением фрагмента), показан на рис. 15.18. Фрагмент содержит логические блоки, имеющие локальные ПМС и составленные из логических элементов ЛЭ (LE, Logic Element) табличного типа, строки и столбцы глобальной программируемой матрицы соединений ГПМС и элементы ввода/вывода ЭВВ, подсоединенные к концам строк и столбцов ГПМС. Кроме того, микросхема содержит реконфигурируемые модули памяти РМП (ЕАВ). Впервые такая встроенная память появилась в семействе FLEX 10К, до этого ресурсы памяти состояли в тех элементах, которые используются к логических преобразователях табличного типа.
Память может быть организована в вариантах 2048 * 1, 1024 * 2, 512 * 4 и 256 * 8 и ориентирована на реализацию буферов FIFO или (только для FLEX10KE) двухпортовых ОЗУ. Отдельные РМП могут объединяться для создания более емких блоков памяти.
В микросхемах FLEX реализовано двухуровневое разбиение средств логического преобразования данных. Наименьшей структурной единицей, выполняющей логические операции, является логический элемент (ЛЭ. LE). Компактная группа из восьми ЛЭ образует логический блок ЛБ (LAB, Logic Array Block). Логические блоки выступают как самостоятельные структурные единицы на следующем уровне иерархии. Все они расположены по строкам и столбцам, которым соответствуют строки и столбцы глобальной программируемой матрицы соединений ГПМС.
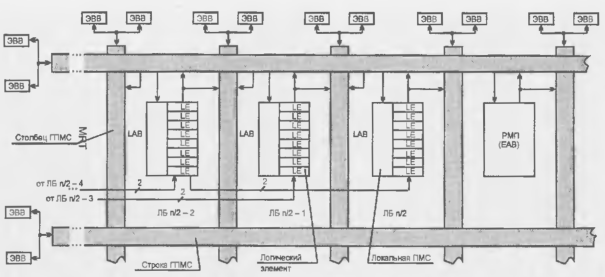
Рисунок 15.18 - Фрагмент структуры СБИС FLEX 10К.
Логический элемент
Логический элемент (рис. 15.19, а) имеет четырехвходовой табличный функциональный преобразователь типа LUT (память емкостью 16 бит), схему переноса, схему каскадирования, программируемый триггер, схему управления сбросом/установкой триггера и несколько программируемых мультиплексоров. Функциональный преобразователь ФП-4 может также работать в режиме воспроизведения двух функций трех переменных (16 бит памяти в этом случае разбиваются на два блока по 8 бит), одна из которых — функция переноса, необходимая для таких схем, как счетчики или сумматоры с последовательными переносами или другие схемы с функциями переноса. В микросхемах FLEX удалось реализовать цепи переноса высокого быстродействия (с задержкой 1 нс на каскад), поэтому в библиотеке функциональных блоков немало рекомендованных структур с последовательным переносом, отличающихся схемной простотой.
Функциональный преобразователь реализует функции с малыми задержками. Синхронный триггер может функционировать как триггер D, Т, RS, JK Входные сигналы асинхронных сброса и установки вырабатываются схемой управления, в которую поступают два локальных управляющих сигнала ЛУС1, ЛУС2, сигнал общего сброса СБИС и входная переменная D3 В схеме управления установкой/сбросом (СУ уст/сбр) имеются программируемые мультиплексоры, благодаря которым можно задать одни из шести режимов воздействия на триггер. Все режимы асинхронные — это операции сброса, установки или загрузки в разных вариантах.
Триггер может быть использован совместно с комбинационной частью логического элемента или независимо, как отдельный элемент, если на его вход через мультиплексор 1 поступает сигнал со входа D4.
Выходные сигналы ЛЭ через мультиплексоры 3, 4 могут подаваться в глобальную и локальную программируемые матрицы соединений в программируемом комбинационном или регистровом варианте.
Тактирование триггера возможно от любого из двух локальных управляющих сигналов ЛУСЗ и ЛУС4.
Функции более чем четырех аргументов могут быть получены двумя способами в виде композиций из функций 4-х переменных. Первый способ (рис. 15.19, б) предполагает использование схем каскадирования, имеющихся в каждом ЛЭ. Схему каскадирования можно настраивать на любую логическую операцию, кроме сложения по модулю 2 и равнозначности. С помощью схем каскадирования отдельные функции 4-х переменных объединяются и функцию большего числа аргументов. Второй способ, более обычный для СБИС ПЛ, использует схему с обратными связями (рис. 15.19, в), результатом при этом является получение "функции от функций". Вначале логическими элементами вырабатываются функции, зависящие от не более чем 4-х аргументов, а затем эти функции играют роль аргументов для ЛЭ, формирующего окончательный результат.
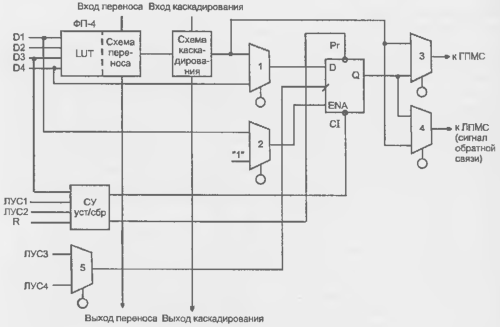
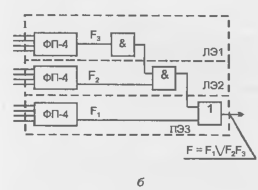
Рисунок 15.19 - Схема логического элемента СБИС FLEX 10К (а) и схемы воспроизведения.
Возможности обоих способов соответствуют возможностям декомпозиции воспроизводимых функций.
В СБИС семейства FLEX 10К впервые были включены встроенные реконфигурируемые матрицы памяти РМП (EABs, Embedded Array Blocks) с общей емкостью от приблизительно 6 Кбит до более чем 20 Кбит статической памяти. Такие блоки расположены в центре каждой строки матрицы логических блоков. В каждом блоке имеется 2048 программируемых битов памяти. Возможности блока не ограничиваются его использованием как блока памяти. Блок может быть и функциональным преобразователем табличного типа для получения сложных функций (в области цифровой обработки сигналов, арифметико-логических операций, интерфейсных функций и т. п.). Например, в одном блоке можно реализовать множительное устройство 4x4, способное работать на частотах до 50 МГц. Если же строить подобное устройство без применения EABs. то потребовалось бы занять 8 логических блоков LAB и максимальная рабочая частота составила бы приблизительно 20 МГц. Подробности устройства глобальной системы коммутации и работу элементов ввода/вывода рассматривать не будем. В них много сходства с работой схем аналогичного назначения, рассмотренных ранее.
СБИС программируемой логики типа "система на кристалле"
Уменьшение топологических норм проектирования и ряд технологических усовершенствований довели уровень интеграции современных микросхем СБИС ПЛ до величин в несколько миллионов эквивалентных вентилей, а быстродействие до тактовых частот в 500...600 и более МГц. На таких кристаллах можно разместить целую систему (процессорную часть, память, интерфейсные схемы и др.).
Определение СБИС как "система на кристалле" возникло вследствие двух факторов. Во-первых, из-за высокого уровня интеграции, позволяющего разместить на кристалле схему высокой сложности (систему). При этом разные по функционированию блоки реализуются одними и теми же аппаратными средствами благодаря их программируемости. Такие СБИС обозначаются в англоязычной литературе термином generic. Во-вторых, из-за того, что СБИС приобретает специализированные области, выделенные на кристалле для определенных функций — аппаратные ядра (Hardcores). Системы разного назначения разделяются, тем не менее, на типовые части, что и ставит вопрос о целесообразности введения в СБИС ПЛ наряду с программируемой логикой специализированных областей с заранее определенными функциями.
Введение специализированных аппаратных ядер, имея ряд позитивных следствий, сужает в то же время круг потребителей СБИС, поскольку в сравнении с полностью программируемыми схемами (типа generic) уменьшается их универсальность.
Реализация сложных функций специализированными аппаратными ядрами значительно уменьшает площадь кристалла в сравнении с их реализациями па конфигурируемых логических блоках. Для некоторых аппаратных ядер площадь снижается на порядок, для других меньше.
Таким образом, введение специализированных аппаратных ядер в FPGA и CPLD процесс противоречивый по результатам. Он сокращает площадь кристалла при реализации сложных функций и ведет к достижению максимального быстродействия, но и таит в себе нежелательные последствия для изготовителя СБИС т. к. может ощутимо сузить рынок их сбыта, а это ведет к росту цен и потере в какой-то мере конкурентоспособности продукции.
Что же будет преобладать? Здесь ключевой вопрос — какие именно специализированные аппаратные ядра будут выбраны для реализации.
Самый очевидный выбор - блоки ОЗУ. Эти блоки в той или иной мере нужны почти лля всех систем, причем некоторые из них требуют очень больших объемов памяти. Выяснились уже и условия эффективного использования ядер памяти — не слишком крупные блоки, возможность изменять организацию памяти, возможность иметь асинхронный и синхронный режимы работы, организовывать буферы FIFO и двухпортовую память. Многие FPGA уже давно основываются па SRAM-ячейках (обычно на каждый конфигурируемый ЛБ тратится 16...32 бит ОЗУ), и эти ячейки могут быть применены не только для конфигурирования ЛБ, но и организуются в простые ОЗУ, которые могут далее объединяться в более емкие регистровые файлы. Однако такой вариант не дает максимального быстродействия и существенно снижает количество доступной пользователю логики кристалла, Т. к. каждые 16...32 бита памяти "выводят из строя" целый ЛБ, т. е. по эквивалентной сложности 10...20 логических вентилей.
В среднем блок ОЗУ с заказным проектированием емкостью 256...512 бит может быть реализован па площади в приблизительно 1/10 от той, которая затрачивается на подобный блок, составленный из распределенных на кристалле ячеек памяти конфигурации. Времена доступа также уменьшаются в 1,5...4 раза.
Области ОЗУ — первые и, безусловно, главные специализированные аппаратные ядра. Других не так уж много. Это умножители, используемые в некоторых СБИС ПЛ, а также схемы интерфейса JTAG. Ядра интерфейса JTAG успешно внедрились во многие СБИС ПЛ, поскольку они выполняют важные функции, нужные очень многим, занимают очень небольшую площадь на кристалле и позволяют достичь высокою быстродействия. Самыми сложными из практически известных ядер являются контроллеры шины PCI, также необходимые в очень многих приложениях и требующие максимального быстродействия.
Семейство СБИС типа APEX 20К/КЕ
Перспективы существенного расширения перечня реализованных специализированных аппаратных ядер явно ограничены. Для реализации систем на кристалле фирма Altera выпустила семейство СБИС типа APEX 20К/КЕ, построенных по архитектуре, названной Multicore. В них комбинируются табличные методы реализации функций и реализации их двухуровневыми структурами, т. е. сочетаются характерные признаки FPGA и CPLD. Имеется встроенная память и гибкая система интерфейсов (рис. 15.20).
Рисунок 15.20 - Структура СБИС семейства APEX 20К.
Эти СБИС отличались наибольшим среди промышленных СБИС ПЛ объемом встроенной памяти (от 58 до 540 Кбит для разных микросхем). Сложность — от 263 К до 2,67 М системных вентилей. Сочетание средств логической обработки из арсеналов FPGA и CPLD облегчает обработку разнотипных функций (трактов передачи данных, автоматов с памятью). При реализации автоматов задержки выработки функций возбуждения триггеров составляют 4,8 не, что соответствует работе автомата на частотах около 200 МГц. Ядро ОЗУ состоит из блоков ESB (Embedded System Block) по 2 Кбит, число блоков от 26 (у младших представителей семейства) до 264 (у старших). Блоки могут работать независимо (с вариантами организации 128 * 16, 256 * 8, 512 * 4, 1024 * 2, 2048 * 1) или соединиться с другими для образования более емкой памяти. Вместе со схемами близлежащих логических блоков блоки памяти могут образовывать стандартные SRAM, буферы FIFO, двухпортовую намять, а в некоторых микросхемах возможна организация ассоциативной памяти САМ (Content-Addressable Memory). Имеются обширные возможности выбора сигналов интерфейса -в семействе "К" это 2,5 В I/O; 3,3 В PCI, LVCMOS (низковольтные схемы КМОП) и LVTTL (низковольтные ТТЛ). В семействе "КЕ" выбор сигналов интерфейса значительно шире.
Семейство СБИС типа Virtex
В качестве "истинной программируемой системы на кристалле" фирма Xilinx представляет СБИС ПЛ Virtex. Как и APEX 20К, это кристаллы с мегавентильным уровнем интеграции и большими емкостями встроенной памяти. Представители семейства имеют от 38 до 851 Кбит встроенной памяти, к которой могут добавляться от 24 до 1038 Кбит памяти от схем конфигурации логических блоков типа LUT. Схемы работают на системной частоте 180...200 МГц. Достижимый процент использования вентилей оценивается как 90%. Число пользовательских выводов лежит в диапазоне 180...804. Линии ввода/вывода программируются на ряд стандартов интерфейсных сигналов (GTL+. LVTTL, SSTL3-1 и др.).
Файл конфигурации (для кристаллов с 100 тыс. эквивалентных вентилей) имеет объем 2 Мбита и загружается за менее чем 3 мс, что является малым временем, способствующим применению микросхем в системах с реконфигурацией аппаратных средств.
Система межсоединений сохраняет многое из свойственного предыдущим семействам СБИС ПЛ фирмы Xilinx, но имеет и своеобразие. В дополнение к прежним ресурсам межсоединений созданы новые диагональные связи с хорошей предсказуемостью задержек.
Логические ячейки ЛЯ содержат 4-входовые преобразователи типа LUT, схемы переноса и управления СПУ и D-триггсры с общим (глобальным) тактированием и входами сброса/установки (рис. 15.21, а). Для упрощения программного обеспечения средств проектирования ЛЯ соединяются парами в секции (Slice). Две секции составляют конфигурируемый логический блок КЛБ (CLB). Имеются схемы PLL, обеспечивающие коррекцию временных соотношений для тактовых импульсов.
Логические ячейки имеют высокоскоростные схемы переноса для построения каскадных структур. Благодаря им такие схемы, как 32-разрядный счетчик или АЛУ работают на частотах до 100 МГц.
Основа LUT — статическое ЗУ емкостью 16 бит с задержкой выработки функций 1,2 нс. Память может использоваться и по прямому назначению с возможностью объединения в более крупные блоки. Можно объединять два элемента LUT для воспроизведения функций пяти переменных.
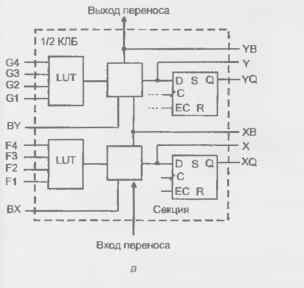
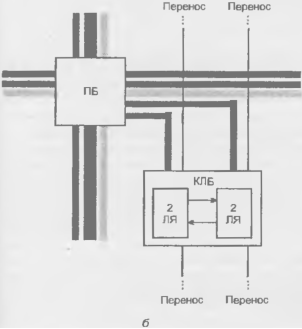
Рисунок 15.21- Схема секции (а) и схема связей КЛБ с системой межсоединений (б)
Рисунок 15.21 (окончание) - Общий план (в) СБИС семейства Virtex
Блоки ввода/вывода в регистровом режиме имеют задержки по пути "такт-выход" 6 нс без PLL и 3,5 нс с PLL. Максимальный темп передач ввода/вывода 110 МГц без PLL и 160 МГц с PLL
В области памяти содержится набор 2-портовых SRAM по 4 Кбит каждый с несколькими вариантами организации (4К * 1, 2К * 2, 1К * 4, 512*8, 256 * 16). Память синхронная, время цикла 10 нс. Предусмотрены конфигурации памяти типа видеобуфера, буферов FIFO.
Внутренняя область состоит из матрицы блоков (Versa Block), содержащих переключательные блоки ПБ и КЛБ (рис. 8.22, б). Внутри КЛБ созданы быстрые пути трассировки. Между КЛБ образованы связи общего назначения и некоторое количество прямых связей {см. §8.2). Линии обратных связей обладают малыми задержками, поэтому воспроизведение сложных функций с помощью нескольких LUTs не ведет к большим потерям быстродействия. Прямые связи обеспечивают межсоединения двух смежных КЛБ в горизонтальном направлении, разгружая в известной степени систему межсоединений общего назначения.
С каждым Versa-блоком связан ПБ (GRM, General Routing Matrix), коммутирующий горизонтальные и вертикальные связи. В системе связей есть не только линии одинарной длины, передающие сигналы от одной GRM к другой смежной, но и буферированные линии передач на расстояние в 6 GRM. По всей длине и ширине кристалла проходят длинные линии.
На периферии кристалла расположены блоки ввода/вывода с буферированием входных и выходных сигналов и управлением третьим состоянием.
Программируются такие возможности, как регулировка крутизны фронта, "подтягивание" линии к высокому потенциалу, регулировка задержки и другие аспекты операции буферирования. Возможен выбор того или иного стандарта сигналов интерфейса, включая GTL+, SSTL, LVTTL. Многообразные ресурсы трассировки дополнены средствами, названными VersaRing. Это интерфейс между логикой внутренней области и блоками ввода/вывода, позволяющий перекоммутировать связи с внешними выводами, так что при модификации схемы во внутренней области связи с моща-жом печатной платы могут не изменяться.
Параметры микросхем семейства Virtex приведены в табл. 8.4 (см. §8.5). Микросхемы типа "система на кристалле" выпускаются и рядом других фирм: Ultra 39К (Cypress Semicond.), QL (Quick Logic), ispLSHOOV (Lattice Semicond.), ProASlC500K (Actel), PSD (WSI) и др.
Лекция № 16
ТЕМА: . Программируемые аналоговые БИС. МАБИС. ПАИС. Пример синтеза аналогового устройства
Основные вопросы, рассматриваемые на лекции:
1. ПАИС
2. МАБИС
3. Примеры синтеза аналоговых устройств
Дата: 2019-03-05, просмотров: 889.