Для установления эффективности влияния некоторых факторов (лекарственного
препарата, метода лечения, курения, занятий спортом и т.д.) на
определенный контролируемый показатель используются критерии достоверности.
При числовом выражении признаков, их нормальном распределении в
совокупности, одинаковой или незначительно различающейся дисперсии по
сравниваемым группам используются критерии параметрической
статистики (параметрические критерии). Однако если имеются сомнения в
возможности применения указанных критериев или если исследуемый признак
является качественным, следует использовать непараметрические критерии.
Название «непараметрические» многие авторы связывают с тем, что методы
сравнения наблюдений не зависят от вида распределения и нет необходимости
расчета параметрических критериев.
В основе расчета непараметрических критериев лежит упорядочивание
(ранжирование) имеющихся значений по отношению друг к другу, типа
«больше ― меньше» или «лучше ― хуже». Это разграничение значений не
предполагает точных количественных соотношений, а следовательно, и
ограничений на параметры и вид распределения. Поэтому для
использования непараметрических критериев нужно меньше информации,
нежели для использования критериев параметрических. В качестве
оценок при непараметрических методах используются относительные
характеристики – ранги, инверсии, серии, знаки и др. В случае
применимости параметрических критериев (нормальное распределение
признака и незначительно различающиеся групповые дисперсии) они, как
учитывающие большее количество информации, оказываются более
мощными, чем непараметрические критерии, и именно им следует отдать
предпочтение, хотя они и более трудоемки.
Впрочем, при современной вычислительной технике понятие «трудоемкость»
становится условным. Персональный компьютер позволяет начинать
сравнение вариационных рядов с параметрических методов (критерий
Стьюдента, дисперсионный анализ). Такая практика особенно выгодна в
тех научных работах, когда анализируются результаты многих
(физиологических, биохимических, гематологических,
психофизиологических, социологических и др.) исследований, полученных у
одних и тех же лиц в динамике. В этом случае на ПК вариационные ряды
удобно сравнивать по единой программе. Однако напомним о возможной
ошибке: сравнение их параметрическими методами будет заканчиваться
получением недостаточно достоверных данных. В этих случаях исследование
следует продолжить с применением непараметрических критериев. Особенно
эффективно применение непараметрических критериев при малых выборках
(п = 30). Мощность непараметрических критериев, как правило, лишь
незначительно меньше мощности соответствующих параметрических критериев,
а значит, используя параметрические критерии даже в случае
применимости параметрических, мы не слишком рискуем ошибиться.
Непараметрические методы нашли широкое применение в
микробиологических, иммунологических, фармакологических
исследованиях. Гигиенистам, физиологам часто приходится иметь дело
с малой численностью персонала при изучении условий жизнедеятельности на
обитаемых технических объектах, а врачам-клиницистам ― при изучении
редких клинических форм. Учитывая ряд преимуществ исследований при малых
выборках, они часто применяются и во многих других случаях.
Непараметрические критерии существенно проще в вычислительной части, что
позволяет использовать их для «быстрой проверки» результатов.
Непараметрические методы, используемые для сравнения результатов
исследований, т.е. для сравнения выборочных совокупностей, заключаются в
применении определенных формул и других операций в строгой
последовательности (алгоритмы, шаги). В конечном результате
высчитывается определенная числовая величина. Эту числовую величину
сравнивают с табличными пороговыми значениями. Критерием достоверности
будет результат сравнения полученной величины и табличного значения при
данном
числе наблюдений (или степеней свободы) и при заданном пороге
безошибочного прогноза. Таким образом, критерий в статистической
процедуре имеет основное значение, поэтому процедуру статистической
оценки в целом иногда называют тем или иным критерием.
Использование непараметрических критериев связано с такими понятиями,
как нулевая гипотеза (Н0), уровень значимости, достоверность статистических
различий. Нулевой гипотезой называют гипотезу, согласно которой две
сравниваемые эмпирические выборки принадлежат к одной и той же
генеральной совокупности. Если вероятность (Р) нулевой гипотезы мала, то
отклонение от нее утверждает, что сравниваемые статистические выборки
принадлежат к разным генеральным совокупностям. Уровень значимости ―
это такая вероятность, которую принимают за основу при статистической оценке
гипотезы. В качестве максимального уровня значимости, при котором нулевая
гипотеза еще отклоняется, принимается 5 %. При уровне значимости больше 5 %
нулевая гипотеза принимается, и различия между сравниваемыми
совокупностями принимаются статистически недостоверными, незначимыми.
Особого внимания заслуживает вопрос о мощности (чувствительности) критериев.
Каждый из изучаемых критериев имеет характерную для себя мощность.
Оценки значимости различий необходимо начинать с наименее мощного критерия.
Если этот критерий опровергает нулевую гипотезу, то на этом анализ заканчивается.
Если же нулевая гипотеза этим критерием не опровергается, то следует
проверить изучаемую гипотезу более мощным критерием. Однако если
значение характеристики, вычисленной для менее мощного критерия, оказалось
очень далеким от критического значения, то мало надежды, что более мощный
критерий опровергнет нулевую гипотезу.
Следует сказать и о выборе для статистической оценки результатов подходящих
критериев. Предлагаются примеры выбора адекватных методов статистической
обработки данных в зависимости от задач медико-биологических исследований.
Разумеется, предпочтение следует отдавать менее трудоемким методам, хотя
данное требование имеет относительное значение в тех случаях, когда
имеется возможность использовать современную вычислительную технику.
Перед выбором адекватного метода статистического сравнения данных
необходимо ответить на следующие основные вопросы:
1.Результаты получены в количественном или альтернативном (атрибутивном)
виде, т.е., иными словами, результат каждого измерения представлен числом
или альтернативной (атрибутивной, двухвариантной) оценкой: «есть признак» ―
«нет признака», «есть симптом» ― «нет симптома» и т.д.?
2. Сравниваются независимые выборки (результаты исследования основной и
контрольной групп) или зависимые выборки, т.е. результаты исследования одних
и тех же лиц (экспериментальных животных) в динамике?
3. Сравниваются две или несколько выборок?
Таким образом, полученный в медико-биологическом исследовании материал
может быть отнесен к одному из вариантов, для каждого из которых
приведены адекватные методы сравнения выборок.
Фактический материал исследования в выборках представлен в
количественном виде, выборки независимые, сравниваются две выборки.
Адекватные методы сравнения выборок:
критерий Стьюдента (t);
сравнение средних значений двух независимых малых
выборок по Лорду (U);
критерий Вилкоксона-Манна-Уитни (U);
критерий Мостеллера;
критерий Розенбаума (Q);
критерий Уайта (К).
Варианты в выборках имеют количественное выражение,
выборки независимые, сравниваются несколько выборок.
Адекватные методы сравнения:
дисперсионный анализ;
сравнение нескольких независимых выборок по Немени.
Варианты имеют количественное выражение, выборки функционально
связаны (зависимые, согласованные), т.е. с попарно связанными
вариантами; сравниваются две выборки. Адекватные методы сравнения:
критерий Стьюдента (разностный метод) (t);
ранговый критерий Манна-Уитни для разностей пар (Т);
критерий знаков (Z);
максимум-критерий для разностей пар.
Варианты представлены в количественном виде, выборки зависимые,
сравниваются несколько выборок. Адекватные методы сравнения:
ранговый дисперсионный анализ для нескольких зависимых
выборок по Фридману ( 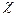 2 ―критерий);
2 ―критерий);
множественное сравнение зависимых выборок по Вилкоксону (W).
Варианты в выборках представлены в альтернативном виде
(«есть признак» ― «нет признака»), выборки независимые,
сравниваются две выборки. Адекватные методы сравнения:
критерий Стьюдента (t) (для сравнения данных
исследования в относительных величинах с применением при
необходимости поправок Йейтса);
критерий 2;
точный метод Фишера (ТМФ);
критерий Вандер-Вардена (X).
Варианты представлены в альтернативном виде, сравниваются несколько
независимых выборок. Адекватные методы сравнения:
дисперсионный анализ;
критерий 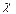 2 (по Р. Руниони).
2 (по Р. Руниони).
VII.Выборки представлены в альтернативном виде, выборки зависимые,
сравниваются две выборки. Адекватные методы сравнения:
модифицированный критерий Макнимара ( 2 ― критерий Макнимара);
критерий итерации по Веберу.
Выборки представлены в альтернативном виде, выборки зависимые,
сравниваются несколько выборок. Адекватный метод:
критерий Кохрана (Q).
Методы в каждой из приведенных 8 групп расположены в порядке убывания их
мощности. Мощность определяется вероятностью выявления существующих
достоверных различий. Вместе с тем, чем она больше, тем более трудоемок метод.
Для некоторых методов имеются ограничения, обусловленные, главным образом,
числом единиц наблюдения в выборочной совокупности, что также необходимо
учитывать при выборе метода.
Таким образом, непараметрические критерии обладают рядом важных и
неоспоримых достоинств. Использование их не требует знания законов
распределения изучаемых совокупностей, они могут быть применены к
совокупностям не только количественным, но также к полуколичественным
и качественным. Эти методы позволяют проводить статистическую обработку
результатов исследования при малом числе наблюдений. Они сочетают в
себе простоту расчетов с достаточной мощностью.
Критерий согласия ( 2)
С помощью 2 определяют соответствие (согласие) эмпирического
распределения теоретическому и тем самым оценивают достоверность различия
между выборочными совокупностями. Критерий 2 применяется в тех случаях,
когда нет необходимости знать величину того или иного параметра
(среднюю или относительную величину) и требуется оценить достоверность
различия не только двух, но и большего числа групп.
В практике работы врача метод 2 может широко использоваться
при оценке эффективности прививок, действия препаратов, результатов
различных методов лечения и профилактики заболеваний, влияния условий труда
и быта на заболеваемость рабочих. С помощью критерия 2 можно определить,
влияют или нет сроки госпитализации на течение заболевания, влияет ли
материальное обеспечение населения на уровень заболеваемости и т.д.
Критерий 2 определяется по формуле:
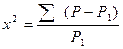 ,
,
где Р ― фактические (эмпирические) данные; Р1 ― «ожидаемые» (теоретические)
данные, вычисленные на основании нулевой гипотезы.
Определение критерия 2 основано на расчете разницы между
фактическими и «ожидаемыми» данными. Чем больше эта разность (Р - Р1),
тем с большей вероятностью можно утверждать, что существуют различия в
распределении сравниваемых выборочных совокупностей. Полученную
величину 2 оценивают по специальной таблице. При этой оценке
учитывается число степеней свободы, т.е. число «свободно варьирующих»
элементов, или число клеток таблицы, которые могут быть заполнены
любыми числами без изменения общих итоговых цифр.
Для нахождения числа степеней свободы (k) можно применять
формулу: k = (s - 1)(r - 1), где s ― число граф первоначальной
таблицы (без графы «итого»); r ― число строк таблицы (без строки «всего»).
Для того чтобы опровергнуть нулевую гипотезу, вычисленный критерий
согласия 2 должен быть равен или больше табличного (критического)
значения 2 при уровне вероятности нулевой гипотезы р = 5%.
Если условие задачи содержит только одну степень свободы, то расчет критерия
2 можно проводить алгебраическим способом, обозначив поля таблицы
«а», «b», «с», «d». Вычисление критерия 2 в этом случае производится по
формуле:
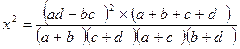 .
.
Применение критерия 2 очень эффективно в случаях, когда
надо сопоставить статистические совокупности с большим количеством
групп (градаций признака) или когда сравниваемых совокупностей больше двух.
Критерий Манна ― Уитни (критерий однородности Т)
Непараметрическим аналогом критерия Стьюдента является критерий
Манна-Уитни. Данный критерий не связан с конкретными законами
распределения. Сущность критерия Манна-Уитни состоит в том, что
обе группы наблюдений объединяются в одну и она упорядочивается по
возрастанию. Каждому элементу группы предписывается его ранг. При
этом элемент, обладающий наименьшим значением, получает ранг №1, следующим
2 ― ранг №2 и т.д. Последний ранг N, где N ― суммарная численность
группы, получает элемент, принимающий наибольшее значение. Если несколько
элементов имеют одинаковые значения, то всем им предписывается один
и тот же ранг, равный среднему арифметическому номеров, под которыми
стоят элементы в упорядоченной группе.
Присвоив элементам ранги, опять разводим их по своим группам.
Вычисляем значение критерия Т, где Т ― сумма рангов элементов
меньшей из групп. Вводим нулевую гипотезу об однородности двух выборок.
Полученное значение критерия Т сравниваем с двумя критическими значениями,
взятыми из специальной таблицы. Если наблюдаемое значение Т находится между
этими критическими значениями, то принимаем нулевую гипотезу: выборки
извлечены из одной генеральной совокупности.
Критерий Манна-Уитни используется при оценке эффективности новых
лекарственных препаратов, новых методов физиотерапевтического лечения,
сравнения результатов биохимического исследования в двух группах лиц и т.д.
Критерий Вилкоксона
Данный критерий используется как непараметрический критерий, при
любом типе распределения. Критерий Вилкоксона относится к ранговым
критериям, причем присваиваемые значения признака (ранга) могут
быть как положительными, так и отрицательными.
Наблюдения снимаются дважды: до эксперимента и после эксперимента.
Под экспериментом понимается некоторое воздействие на объект, в результате
которого наблюдаемые показатели могут измениться в ту или иную сторону:
например, прием лекарственного препарата или определенная методика лечения
приводят к некоторым изменениям контролируемых показателей. При этом у
различных индивидуумов данные изменения также будут различными. Задача
критерия ― по статистическим данным установить эффективность
воздействия. Поскольку изменения показателя у каждого объекта могут быть
вызваны самыми разными случайными причинами, а нас интересует влияние
именно нашего эксперимента, то для того, чтобы исключить случайные
воздействия, требуется рассматривать группу объектов. И чем больше объем этой
группы, тем более взаимно сокращаются положительные и отрицательные
случайные отклонения и, наоборот, ярче проявляются отклонения
систематические, вызванные эффектом эксперимента.
Группа наблюдений до эксперимента выступает в роли контрольной группы,
а группа наблюдений после эксперимента ― в роли экспериментальной группы.
Однако в данной ситуации мы располагаем гораздо большей информацией,
чем информация из двух произвольных групп наблюдения: парные данные
выдают непосредственно для каждого объекта зависимость наблюдаемого
показателя от произведенного воздействия (возросло значение показателя
или уменьшилось и на сколько единиц измерения). В качестве наблюдаемого
значения удобно использовать разность наблюдаемых показателей до и после
эксперимента для каждого индивидуума.
Таким образом, из двух групп наблюдений получается одна выборка значений,
среди которых могут быть как положительные (уменьшение показателя),
так и отрицательные (увеличение показателя). При нулевой разнице
наблюдение не учитывается. Далее производится ранжирование выборки,
причем несколько иначе, чем, например, в критерии Манна-Уитни, где
используется простое упорядочивание. В нашем случае, прежде чем
приступить к упорядочиванию выборочных значений, их вначале
заменяют соответствующими абсолютными величинами, а затем
полученные положительные числа ранжируют по возрастанию.
Расставленные таким образом ранги изменения показателя являются
промежуточными, далее каждому рангу приписывается знак «+» или «-» в зависимости
от знака соответствующей ему разности. Значит, часть рангов окажется
положительными числами, а другая часть ― отрицательными. Такие
ранги называются «знаковыми». Сумма знаковых рангов
― случайная величина W, называемая «критерий Вилкоксона».
В случае когда исследуемое воздействие неэффективно, количество
положительных и отрицательных разностей (а также и знаковых рангов)
в среднем должно уравновешиваться, так как нет превалирующего
изменения показателя в ту или иную сторону. Следовательно, среднее значение
критерия Вилкоксона W должно быть равно нулю (нулевая гипотеза).
Далее действия стандартны: для конкретной выборки разностей
вычисляем Whнабл. По специальной таблице находим соответствующие
критические точки (с учетом желаемого уровня значимости) и определяем
принадлежность Wнабл. критической области или области принятия нулевой гипотезы.
Критерий Вилкоксона может применяться в медицинской практике при
оценке, например, эффективности новых методов медикаментозной
терапии, диеты, эффективности хирургических вмешательств и т.д.
Таким образом, критерий Вилкоксона игнорирует вид распределения,
и его выводы справедливы при любом виде распределения.
Критерий Краснела―Уоллиса (проверка однородности нескольких групп)
Если генеральная совокупность имеет распределение, отличное от
нормального, то требуются критерии проверки однородности групп, которые не
зависят от вида закона распределения (т.е. от всевозможных параметров). В
частности, непараметрическим аналогом дисперсионного анализа является
критерий Краснела―Уоллиса, основанный на рангах.
Итак, однородность групп наблюдения – это нулевая гипотеза. Для построения
критерия проверки нулевой гипотезы используем ранги. Общее число наблюдений
по всем группам обозначим N:
N= п1 + n 2+ п3 + ... + nk ,
где п1,n 2 … + ... + nk , ― числа элементов по группам соответственно.
Упорядочим все N элементов независимо от группы по возрастанию.
Тогда каждый из элементов получает свой ранг ― номер места в упорядоченном
ряду. Если среди элементов ряда имеются совпадающие, то всем им присваивается
один и тот же ранг, равный среднему арифметическому их номеров, мест
упорядоченного ряда. Заметим, что сумма всех N рангов, согласно
формуле суммы арифметической прогрессии, равна:
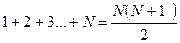 .
.
Далее вычислим средние ранги по группам как средние арифметические
соответствующих величин. Аналогично общий средний ранг равен:
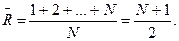
Если верна нулевая гипотеза, выборки однородны, то сами наблюдения, а
следовательно, и ранги должны быть по величине рассредоточены по группам
более или менее равномерно, т.е. средние ранги не должны существенно
различаться между собой. При их сравнении можно использовать отклонения
от общего среднего:
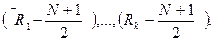
Для суммарной характеристики таких отклонений с учетом численности
групп введем случайную величину
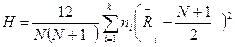 ,
,
называемую статистикой Краскела—Уоллиса.
Эта статистика Н ― критерий проверки нулевой гипотезы.
Его структура такова, что распределение Н с ростом численности групп
стремится к распределению 2с (k-1) степенями свободы (действительно,
распределения средних стремятся к нормальному распределению);
разности также распределены нормально; сумма квадратов таких
величин имеет распределение 2 , а соответствующие значения параметров,
необходимых
для этого распределения, обеспечивают сомножители 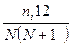 .
.
Фактически, при численности каждой из групп 5 элементов уже
обеспечивается удовлетворительное приближение. Итак, подставляя
данные в приведенную выше формулу критерия Н, получаем Ннабл .Критическую
точку распределения х2с Z = (k-1) степенями свободы находим при выбранном
уровне значимости по специальной таблице. Если оказывается, что Ннабл меньше
2крит, то на выбранном уровне значимости нулевая гипотеза об однородности
выборок принимается (опытные данные этой гипотезе не противоречат).
Если же Ннабл. больше 2крит, то нулевая гипотеза об однородности групп
наблюдений отвергается, и группы следует сравнивать попарно.
Критерий Краскела-Уоллиса используется в практической медицине
при оценке эффективности различных лекарственных препаратов, методов лечения и т.д.
Дискриминантный анализ
Дискриминантный анализ позволяет построить так называемые решающие
правила на основе оптимального набора диагностических признаков и определить
группы больных, здоровых и группы риска. Цель дискриминантного анализа
состоит в формировании одной или нескольких групп (классов) на основании
выборок из генеральных совокупностей и выработке определенного решающего
правила, с помощью которого производится отнесение вновь поступающих
индивидуумов к какой-либо из указанных групп (классов).
Дискриминантный анализ иногда называется кластер-анализом, или
таксономией, или задачей автоматической классификации. Цель задачи:
формирование индивидуумов в одно родные классы (группы, кластеры,
таксоны), когда характеристики и число классов не заданы. При этом
элементы внутри классов должны быть «сходны» между собой, а между
классами ― «различны». Этот вид задач иногда называется «распознаванием
образов с обучением». Решение задачи состоит из двух этапов: этапа
обучения, т.е. выработки решающего правила, и собственно этапа
дискриминации (распознавания), т.е. отнесения вновь поступающих
индивидуумов при помощи правила, выработанного на первом этапе, к
соответствующей группе.
Перечень вопросов задачи должен раскрывать причины, вызывающие
осложнения. Затем формируется обучающая последовательность: к одному
классу этой последовательности относят тех больных, которые прошли курс
лечения, не имея осложнений, к другому ― больных, перенесших
осложнения. По этой последовательности строится решающее правило,
которое, учитывая индивидуальные особенности больного, прогнозирует
возможные осложнения при проведении лечения.
С этой целью составляется анкета, учитывающая индивидуальные особенности
больного и особенности течения его заболевания. По такому вопроснику
составляется обучающая последовательность (класс): для каждого метода
лечения отбирается группа больных, для которых известен результат лечения.
При этой обучающей последовательности строится решающее правило,
прогнозирующее попадание каждого больного после лечения в соответствующую
группу (класс). Наличие решающего правила для каждого метода
лечения дает возможность выбора с учетом наиболее благоприятных
прогнозов результатов лечения.
Таким образом, при решении перечисленных выше задач прослеживается
одна и та же схема: специалисты-врачи оценивают состояние больного по
субъективным симптомокомплексам, получая при этом многочисленную
информацию, которая должна подлежать классификации (т.е.
распределению по соответствующим классам). Классы образуют
так называемые обучающие последовательности, на основе которых
строится нужное решающее правило, т.е. решается задача дискриминации.
Проблема классификации состоит в объединении индивидуумов в группы
или классы по результатам клинического, социологического,
психофизиологического, санитарно-гигиенического исследования.
Математическое аналитическое представление о классах (группах) основано
на понятиях близости или расстояния между отдельными индивидуумами.
Введение некоторой метрики, определяющей расстояние между
двумя точками (индивидуумами), дает возможность установить расстояние,
при котором две точки считаются «близкими» или «далекими».
Исходная информация приводится в виде матрицы-таблицы, у которой
каждый объект (индивид), или так называемая операбельная таксономическая
единица ― ОТЕ (будем обозначать его буквой Y) рассматриваемой
совокупности (например, больной или здоровый), представлен в виде строки.
Общее число строк равно числу объектов, подлежащих классификации.
Пусть это число индивидов равно n. Каждый индивид описывается, как уже
было указано, кодированными данными (будем обозначать их буквами
X с индексами). Пусть общее число признаков равно р. Тогда мы исходную
информацию всегда можем представить в виде таблицы.
Для решения задачи классификации необходимо прежде всего количественно
определить понятия сходства и разнородности. Что означает, например,
«два объекта Yi, и Yj различны»? Задача была бы решена, если бы два
объекта Yiи Yj, попадали в один и тот же класс всякий раз, когда
расстояние (отдаленность) между соответствующими точками было
бы «достаточно малым», и, наоборот, попадали бы в разные классы, если
бы расстояние между точками было бы «достаточно большим».
Основную единицу, используемую в каком-либо определенном
исследовании классификаций, обычно называют операбельной таксономической
единицей (ОТЕ), или единицей наблюдения. Это составной элемент объекта,
являющийся носителем признаков, подлежащих регистрации, и основой
счета. В медицинских исследованиях это, как правило, индивид (больной,
умерший, родившийся, здоровый человек). Иногда единица наблюдения
совпадает с единицей совокупности (например, при переписи населения).
Единица совокупности ― первичный объект статистического наблюдения,
являющийся носителем изучаемых признаков. Численность единиц
совокупности определяет ее объем (п) и распространенность изучаемого
явления, т.е. статистическая совокупность ― это группа фактов, событий,
обладающих варьирующими признаками, но объединенных единой качественной
основой (сущностью).
Основные этапы, на которые распадается процедура формирования классов,
состоят в следующем:
Выбирают п индивидов (n ОТЕ), подлежащих классификации, и по
каждому из них исследуют и кодируют соответствующее число
признаков. Если признаков мало, то классификация очень
«чувствительна» к произвольному выбору признаков.
Сравнивают всех индивидов (ОТЕ) друг с другом для определения
сходства или различия с помощью признаков. Один из
простейших показателей сходства некоторой пары индивидов
(ОТЕ) ― доля признаков, которые у них совпадают. Множество
измеренных коэффициентов сходства можно представить в виде матрицы.
На основе матрицы вычисленных коэффициентов сходства
можно распределить всех индивидуумов по классам. Каждый индивид имеет
«сходство» с другими индивидами внутри класса и «отличен» от индивидов
других классов. В некоторых случаях, объединяя по несколько классов в
группы более высокого ранга, можно получать иерархическую структуру.
Последний этап ― проверка правильности классификации
путем прогнозирования для новых индивидов (ОТЕ), т.е., по существу,
решение задачи дискриминации.
Метод стандартизации
Основное правило статистики ― «сравнивать сравнимое» ― предполагает
сопоставление обобщающих показателей, полученных на однородных
статистических совокупностях. Однако нередко бывают случаи, когда
необходимо сравнить показатели здоровья населения в районах с различной
возрастно-половой структурой населения, показатели деятельности
лечебно-профилактических учреждений с разным составом больных и т.п.
Анализируя показатели общественного здоровья в различных группах населения,
можно заметить, что уровень рождаемости будет выше там, где более высока
доля женщин детородного возраста среди населения, больничная летальность
будет выше в стационаре, где больше больных с тяжелыми формами
заболеваний, показатель смертности будет выше в том населенном пункте,
где больше удельный вес лиц пожилого возраста. Такая же проблема
возникает при сравнении показателей в динамике, так как возрастной и
половой состав групп населения с течением времени меняется. Наиболее
правильным при анализе различных показателей здоровья считается
сравнение специальных коэффициентов, но не всегда этого бывает достаточно.
Использование метода стандартизации позволяет расчетным путем устранить
влияние различных структур сравниваемых совокупностей на обобщающие
коэффициенты. Стандартизация (англ. standard ― образец, эталон) в
статистике ― это особый прием вычисления стандартизованных показателей,
которые по статистической сущности являются общими интенсивными
коэффициентами.
Общие интенсивные коэффициенты (рождаемость, смертность,
заболеваемость, инвалидность и т.д.) правильно отражают частоту
распространения явления лишь в том случае, когда состав сравниваемых
групп однороден. Если же сравниваемые совокупности (население, рабочие,
больные и т.д.) имеют неоднородный состав (возрастно-половой,
профессиональный, по тяжести и продолжительности заболеваний),
то наиболее правильным способом анализа будет сопоставление
стандартизованных (соответственно по возрасту, полу,
профессиональному составу, тяжести и продолжительности заболеваний)
коэффициентов.
Метод стандартизации рационально применять при условии, когда имеющиеся
различия в составе сравниваемых коллективов являются существенными и
могут повлиять на размеры общих коэффициентов. Для элиминирования
(исключения) влияния структуры сравниваемых совокупностей на
коэффициенты их приводят к единому стандарту, т.е. при этом условно
допускается, что состав сравниваемых коллективов одинаков. Целесообразно
выбрать стандарт, близкий по существу к сравниваемым совокупностям,
или в качестве стандарта принять состав одной из них.
Стандартизованные коэффициенты показывают, каковы были бы общие
интенсивные показатели (рождаемости, смертности, летальности, естественного
прироста, плодовитости и др.), если бы на их величину не оказывала
влияние неоднородность в составах сравниваемых коллективов.
Стандартизованные коэффициенты являются условными величинами и
применяются исключительно в целях сравнения, по ним нельзя давать такую
же оценку, как по фактическим данным, в том числе оценивать достоверность
различий. При изменении взятого стандарта изменяются и
стандартизованные коэффициенты. Поэтому при анализе важны не сами
абсолютные их значения, а степень различия коэффициентов между собой.
В практике здравоохранения используют три метода стандартизации ― прямой,
косвенный и обратный (метод Керриджа). В практической
деятельности врача стандартизованные коэффициенты чаще рассчитываются
по одному признаку, в научных целях можно получать стандартизованные
коэффициенты с учетом изменения двух признаков, но этот метод является
более сложным и используется редко.
Прямой метод стандартизации применяется наиболее часто.
При прямом методе стандартизации за стандарт принимается
состав среды и предполагается, что он одинаков в обеих
сравниваемых совокупностях. Единая структура позволяет определить
«ожидаемое» число больных (умерших, инвалидов и т.д.) для каждой
из сравниваемых совокупностей.
Использование прямого метода стандартизации возможно, если:
известны состав среды (совокупности) и состав
явления по изучаемому признаку (т.е. можно
рассчитать специальные интенсивные коэффициенты
по возрасту, полу и любому другому изучаемому признаку);
число наблюдений достаточно велико в каждой выделенной
для изучения группировке (т.е. вычисленные специальные коэффициенты достоверны).
Прямой метод расчета стандартизованных коэффициентов рациональнее
проводить по трем основным последовательным этапам:
I этап ― вычисление общих и специальных интенсивных коэффициентов;
II этап ― выбор (или расчет) стандарта;
III этап ― определение и оценка стандартизованных коэффициентов.
Если за стандарт брать не относительные, а абсолютные цифры, то можно
выделить 4 и даже 5 этапов вычисления стандартизованных коэффициентов:
I этап ― расчет общих и специальных (по каждой группе – половой,
возрастной и др.) интенсивных показателей (или средних величин) для двух
сравниваемых совокупностей;
II этап ― выбор и расчет стандарта;
III этап ― расчет «ожидаемых величин» для каждой группы стандарта;
IV этап― определение стандартизованных показателей;
V этап ― сравнение групп по общим интенсивным (или средним) и
стандартизованным показателям. Выводы.
Целесообразно все эти расчетные операции представить в виде этапов
стандартизации и оформить их в виде таблицы.
За стандарт рациональнее принимать экстенсивные коэффициенты,
вычисленные на то же основание, что и интенсивные коэффициенты
(%, %о, %00, %000), определяемые на I этапе. Можно за стандарт принять
и абсолютные данные, но тогда расчеты будут более трудоемкими.
На практике используют три источника выбора стандарта:
собственные данные по одной из изучаемых групп (наиболее быстрый
способ получения стандартизованных коэффициентов);
собственные данные в сумме по всем изучаемым группам
(наиболее реальное отражение);
данные извне (литературные, учетные и др.).
Стандарт следует избирать каждый раз применительно к конкретному
изучаемому материалу в связи с задачами, стоящими перед
исследователем. Так, например, при сравнении младенческой смертности двух
районов города за стандарт целесообразно принять возрастной или
половой состав младенцев (детей до 1 года) города, а при сравнении
младенческой смертности в городе и сельской местности ― возрастной
или половой состав младенцев области.
Вычисленные стандартизованные коэффициенты показывают, что если бы
состав группы (населения, женщин, младенцев, работающих и т.д.) был
одинаковым, то наблюдалось бы такое соотношение истинных показателей
(общих или специальных интенсивных коэффициентов), как соотношение
значений стандартизованных коэффициентов.
Косвенный метод стандартизации показателей применяется в двух случаях:
при отсутствии данных о составе явления (больных, умерших и т.д.),
т.е. числителя интенсивного показателя;
при наличии малых чисел изучаемого явления.
Суть метода заключается в том, что за стандарт принимают специальные
интенсивные коэффициенты (например, летальность больных в каком-либо
отделении многопрофильной больницы) и рассчитывают так называемые ожидаемые
числа заболеваний для сравниваемых групп больных с учетом их
фактической численности. Вычисление стандартизованных коэффициентов
косвенным способом можно разбить на три этапа:
I этап ― выбор стандарта. Для стандарта чаще используются
данные извне (опубликованные в литературе, отчетные данные) при условии,
что эти коэффициенты близки по уровням к предполагаемой летальности,
заболеваемости, смертности, инвалидности изучаемого населения. Реже
используются собственные данные в сумме по сравниваемым группам или по
одной группе с наибольшим количеством наблюдений;
II этап ― вычисление «ожидаемых» чисел на основе стандарта и фактического
состава сравниваемых групп населения;
III этап ― вычисление стандартизованных коэффициентов по формуле:
Стандартизованный коэффициент = Общий показатель стандарта х
х Фактическое число изучаемого явления.
Ожидаемое число изучаемого явления
Косвенный метод стандартизации имеет очень большое значение для анализа
деятельности лечебно-профилактических учреждений. При наличии
стандарта летальности, частоты осложнений по каждой нозологической форме
можно рассчитать «ожидаемые» числа и показатели с учетом разнообразного
состава больных в отделениях.
Обратный метод стандартизации в деятельности врача появился относительно
недавно [Керридж, 1958]. Этот метод используется реже, чем прямой и
косвенный. Обратный метод стандартизации используется при отсутствии
данных о составе среды, т.е. знаменателя для расчета интенсивных
показателей. Результаты этого метода тем точнее, чем более дробные
возрастные интервалы применяются при стандартизации. Расчет стандартизованных
показателей обратным методом проводится в 3 этапа:
I этап ― выбор стандарта (повозрастные коэффициенты заболеваемости или
смертности населения). За стандарт чаще принимаются внешние данные:
уровни заболеваемости или смертности за предыдущие годы либо
коэффициенты заболеваемости или смертности по другим районам, но не по
собственным, а по иным источникам. За стандарт принимаются и собственные
данные, если можно рассчитать специальные коэффициенты;
II этап ― расчет ожидаемой численности населения в каждой изучаемой
группе в соответствии с принятыми за стандарт показателями заболеваемости
(смертности) населения и фактическим числом заболевших (умерших)
в отдельных возрастных группах населения;
III этап ― вычисление стандартизованных показателей поформуле:
Стандартизованный коэффициент = Ожидаемая численность населения х
Фактическая численность населения
х Общий интенсивный коэффициент стандарта.
У обратного метода много общего с косвенным, только
«ожидаемые» числа рассчитываются не для изучаемых явлений, а
для численности населения.
Таким образом, применение любого из трех методов стандартизации в
оценке здоровья населения дает врачу возможность показать зависимость
различных показателей здоровья населения от тех или иных факторов риска,
объективно оценить проводимую профилактическую работу, выявить наиболее
значимые приоритетные факторы, определяющие уровень заболеваемости,
смертности, инвалидности, рождаемости и другие показатели здоровья в
определенной больнице, поликлинике, на конкретном предприятии, в районе,
области и т.д.
В заключение необходимо еще раз подчеркнуть, что выбор конкретного
метода стандартизации зависит от того, насколько полный статистический
материал имеется в наличии. Пря мой метод дает более надежные результаты,
но в случае невозможности его применения следует использовать косвенный
или обратный методы стандартизации: они достаточно точны для
практического применения. Стандартизация позволяет нам сделать
правильный вывод о том, действительно ли имеется разница общих
интенсивных коэффициентов в сравниваемых коллективах или эти
различия зависят только от не одинаковой структуры коллективов.
Важно помнить, что величина стандартизованных коэффициентов
зависит от выбора стандарта, поэтому сравнение стандартизованных
показателей (разных больных, поликлиник, районов, областей, стран и т.д.)
можно проводить, если они вычислены с применением одного и того же
стандарта. С учетом этого большое значение имеет создание единых
стандартов и формирование базы стандартов с целью их широкого
использования при анализе различных показателей здоровья.
Кроме того, стандартизованные коэффициенты, как величины условные,
пригодны прежде всего для сравнения между собой с целью
элиминирования (исключения) различных факторов, определяющих
уровень здоровья населения. Для знания реальных размеров
явления (смертность, летальность, заболеваемость населения т.д.)
необходимо применять обычные интенсивные (общие и специальные) коэффициенты.
Метод корреляции
Все явления в природе и обществе находятся во взаимной связи. Выяснение
наличия связей между изучаемыми явлениями ― одна из важных
задач статистики. Многие медико-биологические и медико-социальные
исследования требуют установления вида связи (зависимости) между
случайными величинами. Сама постановка большого круга задач
в медицинских исследовательских работах предполагает построение
и реализацию алгоритмов «фактор ― отклик», «доза ― эффект».
Зачастую нужно установить наличие эффекта при имеющейся дозе
и оценить количественно полученный эффект в зависимости от дозы. Решение
этой задачи напрямую связано с вопросом прогнозирования определенного
эффекта и дальнейшего изучения механизма возникновения именно такого
отклика.
Как известно, случайные величины X и Y могут быть либо независимыми,
либо зависимыми. Зависимость случайных величин подразделяется на
функциональную и статистическую (корреляционную).
Функциональная зависимость ― такой вид зависимости, когда каждому
значению одного признака соответствует точное значение другого.
В математике функциональную зависимость переменной X от переменной
Y называют зависимостью вида X= f(Y), где каждому допустимому значению
Y ставится в соответствие по определенному правилу единственно возможное
значение X.
Например: взаимосвязь площади круга (S) и длины окружности (L). Известно,
что площадь круга и длина окружности связаны вполне определенным
отношением S = rL, где r – радиус круга. Умножив длину окружности
на половину ее радиуса, можно точно определить площадь крута. Такую
зависимость можно считать полной (исчерпывающей). Она полностью объясняет
изменение одного признака изменением другого. Этот вид связи характерен
для объектов, являющихся сферой приложения точных наук.
В медико-биологических исследованиях сталкиваться с функциональной
связью приходится крайне редко, поскольку объекты этих исследований
имеют большую индивидуальную вариабельность (изменчивость). С
другой стороны, характеристики биологических объектов зависят,
как правило, от комплекса большого числа сложных взаимосвязей и не могут
быть сведены к отношению двух или трех факторов. Во многих
медицинских исследованиях требуется выявить зависимость какой-либо
величины, характеризующей результативный признак, от нескольких
факториальных признаков.
Дело в том, что на формирование значений случайных величин X и Y
оказывают влияние различные факторы. Обе величины ― и X, и
Y ― являются случайными, но так как имеются общие факторы, оказывающие
влияние на них, то X и Y обязательно будут взаимосвязаны. И связь эта
уже не будет функциональной, поскольку в медицине и биологии часто
бывают факторы, влияющие лишь на одну из случайных величин и
разрушающие прямую (функциональную) зависимость между значениями
X и Y. Связь носит вероятностный, случайный характер, в численном выражении
меняясь от испытания к испытанию, но эта связь определенно присутствует
и называется корреляционной.
Корреляционной является зависимость массы тела от роста, поскольку
на нее влияют и многие другие факторы (питание, здоровье,
наследственность и т.д.). Каждому значению роста (X) соответствует множество
значений массы (Y), причем, несмотря на общую тенденцию, справедливую
для средних: большему значению роста соответствует и большее
значение массы, ― в отдельных наблюдениях субъект с большим ростом
может иметь и меньшую массу. Корреляционной будет зависимость
заболеваемости от воздействия внешних факторов, например
запыленности, уровня радиации, солнечной активности и т.д. Имеется
корреляционная зависимость между дозой ионизирующего излучения и
числом мутаций, между пигментом волос человека и цветом глаз, между
показателями уровня жизни населения и смертностью, между числом
пропущенных студентами лекций и оценкой на экзамене.
Именно корреляционная зависимость наиболее часто встречается в
природе в силу взаимовлияния и тесного переплетения огромного множества
самых разных факторов, определяющих значение изучаемых показателей.
Корреляционная зависимость ― это зависимость, когда при изменении
одной величины изменяется среднее значение другой.
Строго говоря, термин «зависимость» при статистической обработке
материалов медико-биологических исследований должен использоваться
весьма осторожно. Это связано с природой статистического анализа,
который сам по себе не может вскрыть истинных причинно-следственных
отношений между факторами, нередко опосредованными третьими факторами,
причем эти третьи факторы могут лежать вообще вне поля зрения
исследователя. С помощью статистических критериев можно дать только
формальную оценку взаимосвязей. Попытки механически
перенести данные статистических расчетов в объективную реальность
могут привести к ошибочным выводам. Например, утверждение: «Чем
громче утром кричат воробьи, тем выше встает солнце», несмотря на явную
несуразность, с точки зрения формальной статистики вполне правомерно.
Таким образом, термин «зависимость» в статистическом анализе подразумевает
только оценку соответствующих статистических критериев.
Корреляционные связи называют также статистическими (например,
зависимость уровня заболеваемости от возраста населения). Эти связи
непостоянны, они колеблются от нуля до единицы. Ноль означает отсутствие
зависимости между признаками, а единица ― полную, или функциональную,
связь, когда имеется зависимость только от одного признака.
Мерой измерения статистической зависимости служат раз личные
коэффициенты корреляции. Выбор метода для определения взаимосвязей
обусловлен видом самих признаков и способами их группировки.
Для количественных данных применяют линейную регрессию и
коэффициент линейной корреляции Пирсона. Для качественных признаков
применяются таблицы сопряженности и рассчитываемые на их основе
коэффициенты сопряженности (С и Ф), Чупрова (К). Для при знаков,
сформированных в порядковой (ранговой, балльной) шкале, можно применять
ранговые коэффициенты корреляции Спирмена или Кендэла.
Любую существующую зависимость по направлению связи можно
подразделить на прямую и обратную. Прямая зависимость
― это зависимость, при которой увеличение или уменьшение значения
одного признака ведет, соответственно, к увеличению или уменьшению второго.
Например: при увеличении температуры возрастает давление газа
(при его неизменном объеме), при уменьшении температуры снижается
и давление. Обратная зависимость имеется тогда, когда при увеличении
одного признака второй уменьшается, и наоборот: при уменьшении
одного второй увеличивается. Обратная зависимость, или обратная
связь, является основой нормального регулирования почти
всех процессов жизнедеятельности любого организма.
Оценка силы корреляционной связи проводится в соответствии со шкалой тесноты.
Если размеры коэффициента корреляции от ±0,9(9) до ±0,7, то связь
сильная, коэффициенты корреляции от ±0,31 до ±0,69 отражают связь средней
силы, а коэффициенты от ±0,3 до нуля характеризуют слабую связь.
Известное представление о наличии или отсутствии корреляционной связи
между изучаемыми явлениями или признаками (например, между массой тела и
ростом) можно получить графически, не прибегая к специальным расчетам. Для
этого достаточно на чертеже в системе прямоугольных координат отложить,
например,
на оси абсцисс величины роста, а на оси ординат ― массы тела и нанести ряд точек,
каждая из которых соответствует индивидуальной величине веса при данном
росте обследуемого. Если полученные точки располагаются кучно по наклонной
прямой к осям ординат в виде овала (эллипса) или по кривой линии,
то это свидетельствует о зависимости между явлениями. Если же точки
расположены беспорядочно или на прямой, параллельной абсциссе либо ординате,
то это говорит об отсутствии зависимости.
По форме корреляционные связи подразделяются на прямолинейные, когда
наблюдается пропорциональное изменение одного признака в зависимости от
изменения другого (графически эти связи изображаются в виде прямой линии или
близкой к ней), и криволинейные, когда одна величина признака
изменяется непропорционально изменению другой (на графике эти связи
имеют вид параболы, эллипса или иной кривой линии).
Таким образом, корреляционные связи различаются по характеру (прямые
и обратные),
по форме (прямолинейные и криволинейные), по силе (сильная, средняя,
слабая). И, наконец, корреляционные связи могут иметь разную
достоверность. Существуют статистически значимые связи с высокой
вероятностью достоверного прогноза минимум на 95 %, максимум ―
на 99 % и выше. И могут быть статистически незначимые корреляционные
связи, когда вероятность достоверного прогноза ниже 95 %.
В основу исчисления коэффициента корреляции берется оценка
совпадений колебаний значений взаимосвязанных признаков.
Если объективно существующие колебания (вариации) этих значений
совпадают, то можно говорить о наличии корреляции. Если колебания
не совпадают, корреляции нет.
Дата: 2019-03-05, просмотров: 393.