Data is information stored in a form, suitable for later processing, storage and transmission.
Data is one of the most important types that need to be managed for effective development, provision and maintenance of services.
Data management – is the process associated with the accumulation, organization, storage, updating, use and distribution of data.
Data management include:
• Data analysis.
• Database management.
• Extract, transform and load data.
• Data mining.
• Data quality support.
• Data protection.
• Data encoding.
• Data architecture.
Data analytics (DA) is the science of examining raw data with the purpose of drawing conclusions about that information.
Data analytics is used in many industries to allow companies and organization to make better business decisions and in the sciences to verify or disprove existing models or theories.
Data analytics is distinguished from data mining by the scope, purpose and focus of the analysis. Data miners sort through huge data sets using sophisticated software to identify undiscovered patterns and establish hidden relationships.
Data analytics focuses on inference, the process of deriving a conclusion based solely on what is already known by the researcher.
The science is generally divided into:
- exploratory data analysis (EDA), where new features in the data are discovered;
- confirmatory data analysis (CDA), where existing hypotheses are proven true or false.
Qualitative data analysis (QDA) is used in the social sciences to draw conclusions from non-numerical data like words, photographs or video.
The term "analytics" has been used by many business intelligence (BI) software vendors as a buzzword to describe quite different functions.
Data analytics is used to describe everything from online analytical processing (OLAP) to CRM analytics in call centers.
Here is a huge amount of data available in the Information Industry. This data is of no use until it is converted into useful information. It is necessary to analyze this huge amount of data and extract useful information from it.
Extraction of information is not the only process we need to perform; data mining also involves other processes such as Data Cleaning, Data Integration, Data Transformation, Data Mining, Pattern Evaluation and Data Presentation.
Once all these processes are over, we would be able to use this information in many applications such as Fraud Detection, Market Analysis, Production Control, Science Exploration, etc.
Data Mining is defined as extracting information from huge sets of data (fig. 6.1).
In other words, we can say that data mining is the procedure of mining knowledge from data. The information or knowledge extracted so can be used for any of the following applications:
- Market Analysis;
- Fraud Detection;
- Customer Retention;
- Production Control;
- Science Exploration.
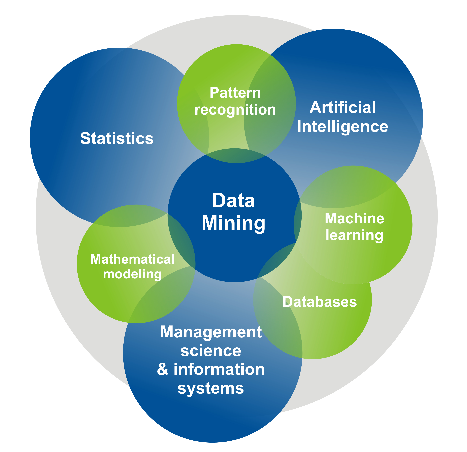
Figure 6.1 - Data Mining
Data Mining is used to implement large-scale analytical projects in business, marketing, the Internet, telecommunications, industry, geology, medicine, pharmaceutics and other fields.
Data Mining allows you to start the process of finding significant correlations and relationships as a result of analyzing a huge array of data using modern methods of pattern recognition and applying unique analytical technologies, including decision trees and classifications, clustering, neural network methods, and others.
In general, Data Mining can be described as a technology designed to search in large volumes of data of non-obvious, objective and practically useful regularities.
Data Mining is based on effective methods and algorithms designed to analyze unstructured data of large volume and dimension.
The key point is that the data of large volume and large dimension appear to be devoid of structure and connections. The purpose of data mining technology is to identify these structures and find patterns where there is at first glance chaos and arbitrariness.
Here is an actual example of the application of data mining in the pharmaceutical and medicinal industry. Interaction of medicinal substances is an increasing problem faced by modern healthcare. Over time, the number of prescription drugs (over-the-counter and various additives) increases, which makes it increasingly likely that drug interactions will cause serious side effects that doctors and patients are unaware of.
Researchers at Stanford University in California examined the FDA (Food and Drug Administration) database of drug side effects and found that two commonly used drugs, paroxetine and pravastatin, increase the risk of developing diabetes if used together.
A study to conduct such an analysis based on FDA data revealed 47 previously unknown adverse interactions.
Дата: 2019-02-02, просмотров: 670.