The main part of the visual interface of the future will be 3D graphics. This appearance of the shell is more informative and easier to understand by the user. The software developers tried to use pseudo-three-dimensional interface elements in their projects long before the appearance of powerful computers. In Windows three-dimensional elements are also present - look at least at the buttons.
One of the most promising projects in this area is the "Project Looking Glass", a company of Sun Microsystems. The created 3D desktop looks like a real space in which you can zoom in, delete, rotate objects, position them one after another. The development is based on the use of Java technology. One of the advantages of this project is the low system requirements for a computer on which this shell can be installed.
If you group the methods of interaction or control with a computer system, you get the following:
1. Traditional methods of management.
2. Voice control.
3. Gesture control.
4. Neurointerface.
5. Other types of management.
Traditional ways of management
As we all know, we use keyboards, mice, trackballs, touchpads, joysticks, remote controls, etc. The pros and cons of this control are well known.
Today we are too attached to the usual image of the computer - monitor, system unit, keyboard and mouse. Meanwhile, very soon not only the appearance of computers will change, but the very approach to data transmission.
Voice control
It should be noted that the voice output of the information is quite accessible, the computer can speak. Much more difficult with voice input. It is believed that problems with word recognition are almost solved. Of course, there are language features, but when tuning to a specific language and adjusting to the features of a particular user's speech, recognizing words now does not seem a huge problem. For example, Apple introduced the Siri system with its iPhone 4S smartphone to recognize voice commands. Currently, voice control is suitable for more or less simple situations, for example, for an "intelligent" house.
Gesture control
This kind of management became known to users first of all thanks to the device Microsoft Kinect, which, by the way, will soon be released not only for the Xbox game console, but for a regular computer and other electronic devices. Currently, gesture management is most suitable for managing various media devices.
Advantages of managing gestures: contactless control; The intuition of a large number of teams. Disadvantages of managing gestures: the need for initial initiation; Low accuracy of recognition of gestures; The need to memorize non-obvious gestures; High probability of errors; Lack of common standards for the application and display of gestures.
Neurointerface
The advantages of a neural interface: potentially the fastest command input; Potentially the ability to give commands of any complexity; Free hands and eyes. Disadvantages of the neurointerface: a complex implementation; Additional devices (sensors, helmets, etc.); High probability of errors; Special attention to safety when managing real objects; Need to calibrate for a specific user.
In recent years, many new technologies have appeared, which in the future will radically change the look of user interfaces. Suffice it to recall Siri and Google Glass - these are harbingers of a new stage in the development of interfaces.
Today, MIT Media Lab employees are working on the creation of fluid interfaces that allow information to flow freely from one storage system to another.
For example, a device created in the MIT Media Lab called Finger Reader helps blind people read books by simply swiping fingers along the lines. FineReader reads the text and makes its acoustic processing. At the same time, not only audio but also tactile interaction is realized - the device vibrates, marking punctuation marks, spaces between words, and announcing the end of the sentence. Thus, the information flows from the analog storage system (book) to the digital (FingerReader), and then it is voiced (voice) and assimilated by the user. In this case, the human body itself acts as an interface - the device only tells what to do.
The development of the Internet of things will inevitably lead to the fact that many devices will not have interfaces that are familiar to us at all. For example, user identification will be performed by scanning the iris or fingerprint, and the information will come in the form of voice messages or holography. That is, the interface of the future generally will not need a physical medium such as a computer or a smartphone.
Database systems
Bases of database systems
One of the most important applications of computers is the processing and storage of large amounts of information in various areas of human activity: in the economy, banking, trade, transport, medicine, science, etc.
Modern information systems are characterized by huge amounts of stored and processed data.
Information system is a system which performs automated collection, processing and presentation of data. The information system includes hardware, software and maintenance personnel. Databases are the basis of information systems.
The database is an organized set of data to ensure their effective storage, retrieval and processing in a computer system under the control of a DBMS (database management system).
A database can be of any size and of varying complexity.
A database may be generated and maintained manually or it may be computerized. A computerized database may be created and maintained either by a group of application programs written specifically for that task or by a database management system.
A database management system is a collection of programs that enables users to create and maintain a database.
The DBMS is hence a general-purpose software system that facilitates the processes of defining, constructing, manipulating, and sharing databases among various users and applications.
The database system contains not only the database itself but also a complete definition or description of the DB structure and constraints.
This definition is stored in the DBMS catalog, which contains information such as the structure of each file, the type and storage format of each data item, and various constraints on the data.
The information stored in the catalog is called meta-data, and it describes the structure of the primary database.
The architecture of DBMS packages has evolved from the early monolithic systems, where the whole DBMS software package was one tightly integrated system, to the modern DBMS packages that are modular in design, with a client/server system architecture.
In a basic client/server DBMS architecture, the system functionality is distributed between two types of modules. Now we specify an architecture for database systems, called the three-schema architecture that was proposed to help achieve and visualize these characteristics.
Data models
By structure of a database, we mean the data types, relationships, and constraints that should hold for the data.
Most data models also include a set of basic operations for specifying retrievals and updates on the database. In addition to the basic operations provided by the data model, it is becoming more common to include concepts in the data model to specify the dynamic aspect or behavior of a database application. This allows the database designer to specify a set of valid userdefined operations that arc allowed on the database objects.
Common logical data models for databases include:
- Hierarchical database model;
- Network model;
- Relational model;
- Object-oriented model;
- Multidimensional model.
The hierarchical model organizes data into a tree-like structure, where each record has a single parent or root (fig. 5.1). Sibling records are sorted in a particular order. That order is used as the physical order for storing the database.
This model is good for describing many real-world relationships.
This model was primarily used by IBM’s Information Management Systems in the 60s and 70s, but they are rarely seen today due to certain operational inefficiencies.
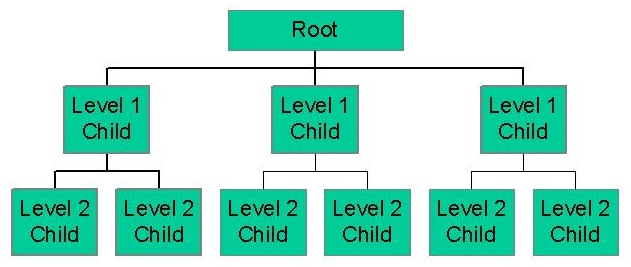
Figure 5.1 - The hierarchical model
The network model builds on the hierarchical model by allowing many-to-many relationships between linked records, implying multiple parent records (fig. 5.2). Based on mathematical set theory, the model is constructed with sets of related records. Each set consists of one owner or parent record and one or more member or child records. A record can be a member or child in multiple sets, allowing this model to convey complex relationships.
It was most popular in the 70s after it was formally defined by the Conference on Data Systems Languages (CODASYL).
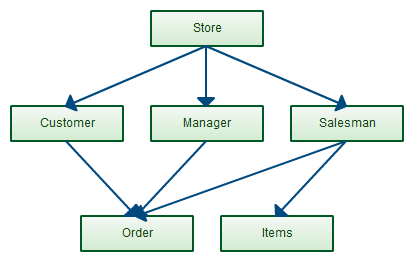
Figure 5.2 - The network model
The most common model, the relational model sorts data into tables, also known as relations, each of which consists of columns and rows (fig. 5.3). Each column lists an attribute of the entity in question, such as price, zip code, or birth date. Together, the attributes in a relation are called a domain. A particular attribute or combination of attributes is chosen as a primary key that can be referred to in other tables, when it’s called a foreign key.
Each row, also called a tuple, includes data about a specific instance of the entity in question, such as a particular employee.
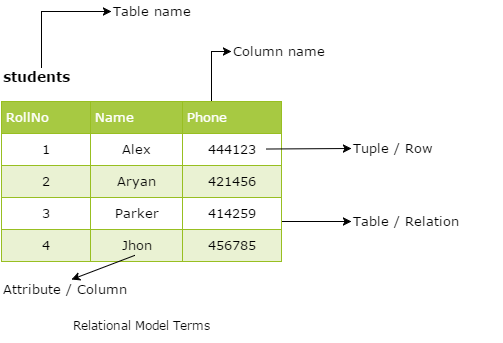
Figure 5.3 - The relational model
The model also accounts for the types of relationships between those tables, including one-to-one, one-to-many, and many-to-many relationships.
Within the database, tables can be normalized, or brought to comply with normalization rules that make the database flexible, adaptable, and scalable. When normalized, each piece of data is atomic, or broken into the smallest useful pieces.
Relational databases are typically written in Structured Query Language (SQL). The model was introduced by E.F. Codd in 1970.
Object-oriented database model defines a database as a collection of objects, or reusable software elements, with associated features and methods (fig. 5.4).
The object-oriented database model is the best known post-relational database model, since it incorporates tables, but isn’t limited to tables. Such models are also known as hybrid database models. This models combines the simplicity of the relational model with some of the advanced functionality of the object-oriented database model. In essence, it allows designers to incorporate objects into the familiar table structure.
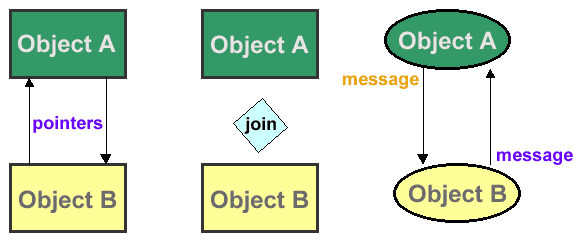
Figure 5.4 - Object-oriented database model
Multidimensional model is a variation of the relational model designed to facilitate improved analytical processing (fig. 5.5). While the relational model is optimized for online transaction processing (OLTP), this model is designed for online analytical processing (OLAP).
Each cell in a dimensional database contains data about the dimensions tracked by the database. Visually, it’s like a collection of cubes, rather than two-dimensional tables.
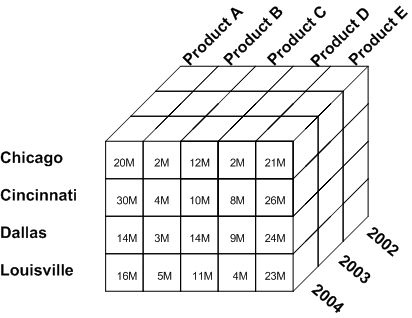
Figure 5.5 - Multidimensional model
Normalization
Normalization is the process of efficiently organizing data in a database.
There are two goals of the normalization process: eliminating redundant data (for example, storing the same data in more than one table) and ensuring data dependencies make sense (only storing related data in a table).
Both of these are worthy goals as they reduce the amount of space a database consumes and ensure that data is logically stored.
The normalization process, as first proposed by Codd (1972), takes a relation schema through a series of tests to "certify" whether it satisfies a certain normal form.
The database community has developed a series of guidelines for ensuring that databases are normalized.
These are referred to as normal forms and are numbered from one (the lowest form of normalization, referred to as first normal form or 1NF) through five (fifth normal form or 5NF). In practical applications, you'll often see 1NF, 2NF, and 3NF.
First normal form (1NF) sets the very basic rules for an organized database:
- eliminate duplicative columns from the same table;
- create separate tables for each group of related data and identify each row with a unique column or set of columns (the primary key).
Second normal form (2NF) further addresses the concept of removing duplicative data:
- meet all the requirements of the first normal form;
- remove subsets of data that apply to multiple rows of a table and place them in separate tables;
- create relationships between these new tables and their predecessors through the use of foreign keys.
Third normal form (3NF) goes one large step further:
- meet all the requirements of the second normal form;
- remove columns that are not dependent upon the primary key.
Дата: 2019-02-02, просмотров: 1421.