Тема №1 «Производственные комплексы в экономике России»
План
1. Производственный комплекс, понятие, структура.
2. Производственные комплексы, классификация.
Производственный комплекс, понятие, структура.
Производственный комплекс – это совокупность предприятий, связанных между собой общим технологическим процессом и работающих с целью получения максимального экономического результата. Кроме производственных корпусов (цехов) в состав комплекса входят складские помещения, административные здания, объекты инфраструктуры, например, электрические подстанции, котельные, подъездные пути, насосные станции, помещения для отдыха работников и другие сооружения.
Важный параметр производственного комплекса характер территориальной организации основных элементов производственного комплекса, его структуры, прежде всего промышленных узлов, а также объединяющих их сооружений производственной инфраструктуры. Разного рода промышленные комплексы, образуемые предприятиями, взаимодействующими по производственно-технологическому принципу, кусты перерабатывающих и обрабатывающих предприятий, использующие либо общую сырьевую базу, либо единый источник рабочей силы, или работающие на одного потребителя, следует рассматривать как локальные функциональные элементы производственного комплекса.
Тема № 2 «Понятие информационного обеспечения, его структура»
План
1. Понятие информационного обеспечения.
2. Внемашинное информационное обеспечение.
3. Внутримашинное информационное обеспечение.
Рисунок 1 - Централизованная БД
Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных компьютерах вычислительной сети. Работа с такой БД осуществляется с помощью системы управления распределенной базой данных (СУРБД).
По способу доступа к данным БД разделяются на БД с локальным доступом и БД с удаленным (сетевым) доступом.
Системы централизованных БД с сетевым доступом предполагают различные архитектуры подобных систем: файл-сервер и клиент-сервер.
Появление персональных компьютеров и локальных вычислительных сетей привело к разработке архитектуры «файл-сервер», показанной на рисунке 2. При такой архитектуре приложение, выполняемое на ПК, может получить прозрачный доступ к файл-серверу, на котором хранятся совместно используемые файлы. Когда приложению, работающему на ПК, требуется получить данные из совместно используемого файла, сетевое программное обеспечение автоматически считывает требуемый блок данных с сервера. Наиболее популярные БД для ПК, включая Microsoft Access, Paradox и dBase, поддерживают архитектуру «файл-сервер», при которой на каждом ПК работает своя копия СУБД.
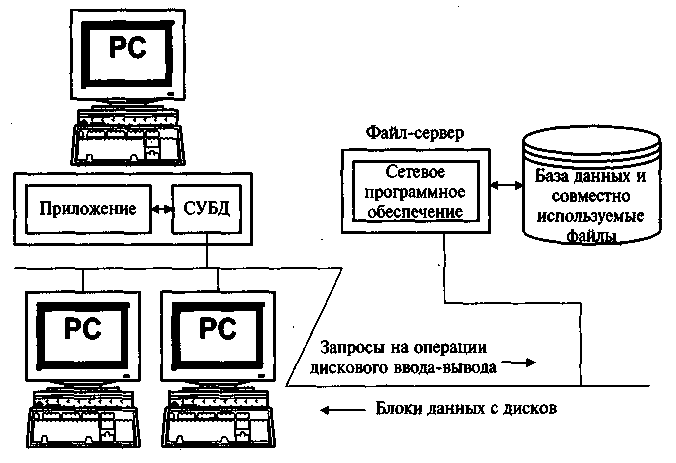
Рисунок 2 - . Архитектура «файл-сервер»
При выполнении обычных запросов эта архитектура обеспечивает великолепную производительность, поскольку в распоряжении каждой копии СУБД находятся все ресурсы ПК. Однако рассмотрим приведенный выше пример. Поскольку запрос требует последовательного просмотра БД," СУБД постоянно запрашивает все новые блоки данных из БД, которая физически расположена на сервере сети. Очевидно, что в результате СУБД запросит и получит по сети все блоки файла. При выполнении запросов такого типа эта архитектура создает слишком большую нагрузку на сеть и уменьшает производительность работы.
Архитектура «клиент-сервер» показана на рисунке 3. При такой архитектуре ПК объединены в локальную сеть, в которой имеется сервер баз данных, содержащий общие БД. Функции СУБД разделены на две части. Пользовательские программы, такие, как приложения, для формирования интерактивных запросов и генераторы отчетов, работают на клиентском компьютере. Хранение данных и управление ими обеспечиваются сервером. В этой архитектуре SQL стал стандартным языком, предназначенным для обработки и чтения данных, содержащихся в БД. SQL обеспечивает взаимодействие между пользовательскими программами и ядром БД.
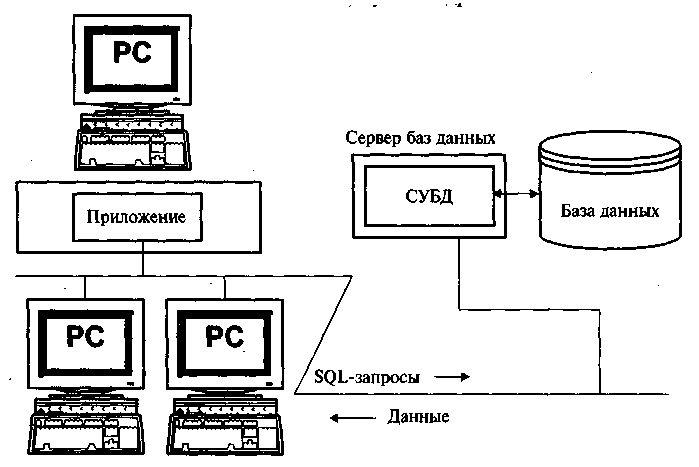
Рисунок 3 - Архитектура «клиент-сервер»
Вернемся к примеру определения потребности материалов на деталь. При архитектуре «клиент-сервер» запрос передается по сети на сервер БД в виде SQL-запроса. Ядро БД на сервере обрабатывает запрос и просматривает БД, которая также расположена на сервере. После вычисления результата ядро БД посылает его обратно по клиентскому приложению, которое отображает его на экране ПК. Архитектура «клиент-сервер» позволяет сократить трафик и распределить процесс загрузки базы данных. Функции работы с пользователем, такие, как обработка ввода и отображение данных, выполняются на ПК пользователя. Функции работы с данными, такие, как дисковый ввод-вывод и выполнение запросов, выполняются сервером БД. Наиболее важно здесь то, что SQL обеспечивает четко определенный интерфейс между клиентской и серверной системами, эффективно передавая запросы на доступ к БД. Эта архитектура используется в современных СУБД Oracle, Informix, Sybase и др.
С ростом популярности СУБД появилось множество различных моделей данных. У каждой из них имелись свои достоинства и недостатки, которые сыграли ключевую роль в развитии реляционной модели данных, появившейся во многом благодаря стремлению упростить проектирование, упорядочить работу с моделями данных и повысить ее эффективность.
Основным средством организации и автоматизации работы с БД являются системы управления базами данных (СУБД).
Выбор СУБД определяется многими факторами, но главным из них является возможность работы с конкретной моделью данных (иерархической, сетевой, реляционной).
Иерархическую модель БД изображают в виде дерева (рисунок 4). Элементы дерева вершины 1—14 представляют совокупность данных, например логические записи. Каждой вершине соответствует множество экземпляров записей, составляющих логический файл. Вершины расположены по уровням и связаны между собой отношениями подчиненности. Одна-единственная вершина верхнего уровня является корневой. Иерархическая модель данных обеспечивает так называемые одно-многозначные отношения между данными. Примером таких отношений могут служить следующие: одному изделию соответствует несколько материалов, используемых на различных операциях обработки, сборки.
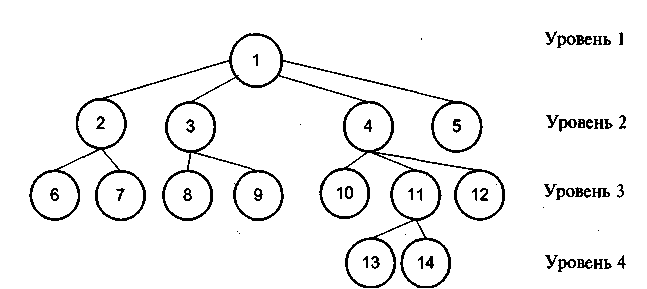
Рисунок 4 - Схема иерархической модели БД
Сетевые модели БД соответствуют более широкому классу объектов управления, хотя требуют для своей организации и дополнительных затрат. Сетевая модель позволяет любому объекту быть связанным с любым другим объектом. Сетевые модели сложны, что создает определенные трудности при необходимости модернизации или развития СУБД. Пример сетевой модели БД представлен на рисунке 5. На рисунке видно, что одно изделие изготавливается в результате выполнения нескольких операций, а одна операция может использоваться для изготовления различных изделий.
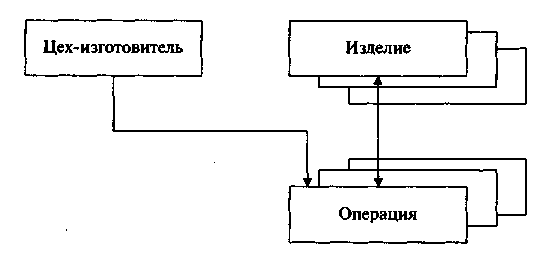
Рисунок 5 - Сетевая модель БД
Реляционная модель БД представляет объекты и взаимосвязи между ними в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами. На этой модели базируются практически все современные СУБД. Эта модель более понятна, «прозрачна» для конечного пользователя организации данных. К преимуществам реляционной модели БД можно отнести также более высокую гибкость при расширении БД, состава запросов к ней.
Таблица 1 – Реляционная модель БД
| Код технологической группы оборудования | Код изделия | Программа выпуска |
| 3 | 20370 | 600 |
| 3 | 20510 | 2000 |
| 5 | 50200 | 1500 |
| 5 | 50230 | 300 |
Реляционная организация БД в виде таблицы содержит программу выпуска изделий (таблица 1). Эта база данных включает в себя три атрибута: код технологической группы оборудования, код изделия, программу выпуска.
Одно из основных различий между тремя типами моделей СУБД состоит в том, что для иерархических и сетевых СУБД их структура не может быть изменена после ввода данных, тогда как для реляционных СУБД структура может изменяться в любое время. Для больших БД, структура которых остается длительное время неизменной, именно иерархические и сетевые СУБД могут оказаться наиболее эффективными, ибо они могут обеспечивать более быстрый доступ к информации БД, чем реляционные СУБД. Однако большинство СУБД для ПК работают с реляционной моделью. К реляционным моделям относят, например, Clipper, dBase, Paradox, FoxPro, Access, Oracle.
В последние годы все большее признание и развитие получают объектно-ориентированные базы данных (ООБД), толчок к появлению которых дали объектно-ориентированное программирование и использование ПК для обработки и представления Практически всех форм информации, воспринимаемых человеком.
В чем принципиальное отличие реляционных и объектно-ориентированных баз данных? В ООБД модель данных более близка сущностям реального мира. Объекты можно сохранить и использовать непосредственно, не раскладывая их по таблицам. Типы данных определяются разработчиком и не ограничены набором предопределенных типов. В объектных СУБД данные объекта, а также его методы помещаются в хранилище как единое целое. Объектная СУБД именно то средство, которое обеспечивает запись объектов в базу данных. Существенной особенностью ООБД можно назвать объединение объектно-ориентированного программирования (ООП) с технологией баз данных для создания интегрированной среды разработки приложений.
ООБД обеспечивает доступ к различным источникам данных, в том числе, конечно, и к данным реляционных СУБД, а также разнообразные средства манипуляции с объектами баз данных. Традиционными областями применения объектных СУБД являются системы автоматизированного проектирования (САПР), моделирование, мультимедиа, поскольку именно из нужд этих отраслей выросло новое направление в базах данных.
Хранилища данных и базы знаний.
Хранилище данных {data warehouse) — это автоматизированная информационно-технологическая система, которая собирает данные из существующих баз и внешних источников, формирует, хранит и эксплуатирует информацию как единую. Оно обеспечивает инструментарий для преобразования больших объемов детализированных данных в форму, которая удобна для стратегического планирования и реорганизации бизнеса и необходима специалисту, ответственному за принятие решений. При этом происходит слияние из разных источников различных сведений в требуемую предметно-ориентированную форму с использованием различных методов анализа.
Хранилище информации предназначено для хранения, оперативного получения и анализа интегрированной информации по всем видам деятельности организации.
Данные в таком хранилище характеризуются следующими свойствами:
■ предметная ориентация — данные организованы согласно предмету, а не приложению (в соответствии со способом их применения);
■ интегрированностъ — данные согласуются с определенной системой наименований, хотя могут принадлежать различным источникам и их формы представления могут не совпадать;
■ упорядоченность во времени — данные согласуются во времени для использования в сравнениях, трендах и прогнозах;
■ неизменяемость и целостность — данные не обновляются и не изменяются, а только перезагружаются и считываются, поддерживая концепцию «одного правдивого источника».
■ большой объем и сложные взаимосвязи данных.
К основным категориям данных, которые располагаются в хранилище, относятся: метаданные, описывающие способы извлечения информации из различных источников, методы их преобразования из различных структур и форматов и доставки в хранилище; фактические данные (архивы), отражающие состояние предметной области и конкретные моменты времени; суммарные данные, полученные на основе проведенных аналитических расчетов.
В информационных хранилищах используются статистические технологии, генерирующие информацию об информации; процедуры суммирования; методы обработки электронных документов, аудио-, видеоинформации, графов и географических карт.
Для уменьшения размера информационного хранилища до минимума при сохранении максимального количества информации применяются эффективные методы сжатия данных.
Для преобразования данных из хранилища в предметно-ориентированную форму требуются языки запросов нового поколения. Руководителям организации данные доступны посредством SQL-запросов, инструментов создания интерактивных отчетов на экране, более развитых систем поддержки принятия решений, многомерного просмотра данных посредством гипертекстовой технологии.
Для хранения данных обычно используются выделенные серверы, или кластеры серверов (группа накопителей, видеоустройств с общим контроллером).
Создание информационного хранилища данных требует решения ряда организационных вопросов, а также удовлетворения следующих требований к аппаратному и программному обеспечению.
Скорость загрузки. В хранилищах необходимо обеспечить периодическую загрузку новых порций данных, укладывающихся в достаточно узкий временной интервал. Требуемая производительность процесса загрузки не должна накладывать ограничения на размер хранилища.
Технология загрузки. Загрузка новых данных в хранилище включает преобразование данных, фильтрацию, переформатирование, проверку целостности, организацию физического хранения, индексирование и обновление метаданных. Это дает возможность объединить разнородную информацию из пакетов, применяемых в структурных подразделениях организации.
Управление качеством данных. В хранилище должна быть обеспечена локальная и глобальная согласованность данных. Мера качества построенного хранилища — объективность исходных данных и степень разнообразия возможных запросов.
Поддержка различных видов данных. В хранилище могут накапливаться данные не только стандартных типов, но и более сложных, таких, как текст, изображения, а также уникальных типов, определяемых разработчиками.
Скорость обработки запросов. Сложные запросы, важные для принятия ответственных решений, должны обрабатываться за секунды или минуты. Скорость обработки запроса должна зависеть от его сложности, а не от объема БД.
Масштабируемость. Хранилище организации может достигнуть нескольких сотен гигабайт. СУБД не должна иметь никаких архитектурных ограничений и должна поддерживать модульную и параллельную обработку, сохранять работоспособность в случае локальных аварий и иметь средства восстановления.
Обслуживание большого числа пользователей. Доступ к хранилищу данных не ограничивается узким кругом специалистов организации. Сервер БД должен поддерживать сотни пользователей без снижения скорости обработки запросов.
Сети хранилищ данных. Сервер должен содержать инструменты, координирующие перемещение данных — между хранилищем организации, информационными системами банков, ГНИ и т. п. Пользователи должны иметь возможность обращаться к нескольким хранилищам с одной клиентской рабочей станции.
Администрирование. СУБД должна обеспечить контроль за приближением к ресурсным ограничениям, сообщать о затратах ресурсов и позволять устанавливать приоритеты для различных категорий пользователей или операций, а кроме того, уметь осуществлять трассировку и настройку системы на максимальную производительность. Качество построенного хранилища определяется удобством доступа к нему для конечного пользователя.
Интегрированные средства многомерного анализа. Для обеспечения высокопроизводительной аналитической обработки необходимы средства многомерных представлений, инструменты, поддерживающие удобные функции создания предварительно вычисленных суммарных показателей и автоматизирующих генерацию таких предварительно вычисленных агрегированных величин.
Средства формирования запросов. Пользователь должен иметь возможность проведения аналитических расчетов, последовательного и сравнительного анализа, а также доступ к детальной и агрегированной информации.
Использование информационных хранилищ дает существенный выигрыш по производительности в системах принятия решений, в системах обработки большого числа транзакций с большим объемом обновления данных.
База знаний
Активно развивающейся областью использования компьютеров является создание баз знаний (БЗ) и их применение в различных областях науки и техники. База знаний представляет собой семантическую модель, предназначенную для представления в ЭВМ знаний, накопленных человеком в определенной предметной области. Основные функции базы знаний: создание, загрузка; актуализация, поддержание в достоверном состоянии; расширение, включение новых знаний; обработка, формирование знаний, соответствующих текущей ситуации.
Для выполнения указанных функций разрабатываются соответствующие программные средства. Совокупность этих программных средств и баз знаний принято называть искусственным интеллектом.
Искусственный интеллект в настоящее время находит применение в таких областях, как планирование и оперативное управление производством, выработка оптимальной стратегии поведения в соответствии со сложившейся ситуацией, экспертные системы и т. д.
План
1. Внешнее и внутренние информационное окружение предприятия.
2. Информационный контур, информационное поле.
План
1. Роль структуры управления в формировании ИС.
2. Типы данных в организации.
3. Категории ИС для обработки различных типов данных.
4. Управляющие информационные системы.
5. Системы поддержки принятия решений.
6. Информационные системы поддержки деятельности руководителя.
Типы данных в организации
Активно работающие компании не испытывают недостатка в данных. Данные находятся везде — в рабочих файлах персональных компьютеров, базах данных, видеои графических презентациях, бумажных и электронных документах. Вся информация, которую использует менеджер в повседневной деятельности и в процессе принятия решений, может быть условно разделена на три категории: формализованная, частично формализованная и неформализованная. В зависимости от степени формализации определяются и типы решений — структурированные, частично структурированные и неструктурированные.
Компьютер обрабатывает данные, представленные в формализованном виде — в виде чисел. С такими же данными имеют дело и формальные математизированные средства статистики. Таким образом, формализация данных является важнейшей составляющей работы информационных систем. Примером формализованных данных является представление результатов деятельности компании в виде наборов числовых таблиц: финансовые отчеты, баланс, денежные транзакции, платежи, оперативные сводки о выполнении суточных заданий, заказы, накладные и т. д. Действия с формализованными данными легче автоматизируются и могут проходить практически без участия человека.
Часть информации изначально является неформализованной, но поддается частичной формализации матричными методами. Например, для того чтобы оценить влияние факторов внешнего окружения или ответные действия самого предприятия, часто применяются матицы BCG (Boston Consulting Group). Для оценки степени успешности бизнеса по характеристикам получения и расходования денежных средств на поддержку деятельности или для оценки перспектив бизнеса на конкретном рынке в конкретной ценовой обстановке используется матрица GEMPM (General Electric Multifactor Portfolio Model) из Portfolio-анализа.
Матрица строится по некоторому алгоритму, который заполняет клетки матрицы формальными параметрами, имеющими реальный неформальный смысл. Например, ячейки матрицы BCG (2x2) — «вопросительные знаки», «звезды», «дойные коровы», «собаки». Матрица GEMPM строится в системе координат «сила бизнеса — привлекательность рынка», оценки производятся по девяти параметрам (матрица 3x3). В этих случаях принятие решений осуществляется тандемом «человек-компьютер»: оптимальное решение выбирает человек, пользуясь набором сценариев, предоставленных компьютером. Сценарии строятся по принципу «что, если...?» с помощью систем поддержки принятия решения (Decision Support System — DSS).
Значительная часть данных, особенно на верхнем уровне управления, бывает неформализованной — политические новости, сведения о партнерах и конкурентах, информация с фондовых и валютных бирж, сводные неформальные отчеты по периодам, деловая переписка, протоколы встреч, семинаров, научные публикации и обзоры, гипертексты в Интернете. Такие данные наиболее трудно формализуемы, по их анализ является обязательной составляющей деятельности высшего руководителя. В этом случае основная тяжесть в принятии решения и ответственность за его результаты лежит на руководителе — здесь огромную роль играют его знания, деловой опыт, компетенция и, конечно, интуиция. Компьютерные, информационные экспертные системы (Expert System — ES) только дополняют эти качества.
Если данные являются недостаточно структурированными и фраг-ментированными среди разнообразных платформ, операционных систем, различных СУБД и приложений, то особенно важным процессом является концентрация по некоторым согласованным правилам этих данных в массивы, называемые метаданными (Metadata). Решения для управления метаданными предоставляют расширенные возможности доступа к массивам структурированных данных вместе с отображением их взаимоотношений с другими массивами информации. Использование специальных хранилищ — репозиториев (Repository) — также может рационализовать или придать смысл этим данным за счет идентификации и сравнения.
Работа с неформализованными данными вызывает значительные трудности. Эти структуры данных, разбитые на категории, довольно сложно поддерживать с помощью репозитория. Особенно это касается систем управления смыслом и содержанием (Content Management Systems — CMS), a также документацией. Специализированные репозитории и поисковые машины предоставляют только отдельные решения, и ни одно из них не покрывает весь спектр данных. Тем не менее, для решений на базе репозиториев существует возможность объединения как формализованных, так и неформализованных метаданных, что может быть достигнуто путем разработки соответствующих интерфейсов к этим новым технологиям. Подобный репозитории станет центральным каналом доступа ко всем корпоративным массивам данных, идентифицируя взаимоотношения между данными, а также то, насколько сотрудники, заказчики и партнеры их используют.
Экспертные системы
Экспертные системы это направление исследований в области искусственного интеллекта по созданию вычислительных систем, умеющих принимать решения, схожие с решениями экспертов в заданной предметной области.
Как правило, экспертные системы создаются для решения практических задач в некоторых узкоспециализированных областях, где большую роль играют знания экспертов.
Экспертные системы имеют одно большое отличие от других систем искусственного интеллекта: они не предназначены для решения каких-то универсальных задач. Экспертные системы предназначены для качественного решения задач в определенной разработчиками области, в редких случаях – областях.
Экспертное знание – это сочетание теоретического понимания проблемы и практических навыков ее решения, эффективность которых доказана в результате практической деятельности экспертов в данной области. Фундаментом экспертной системы любого типа является база знаний, которая составляется на основе экспертных знаний специалистов. Правильно выбранный эксперт и удачная формализация его знаний позволяет наделить экспертную систему уникальными и ценными знаниями.
На сегодняшний день создано уже большое количество экспертных систем. С помощью них решается широкий круг задач, но исключительно в узкоспециализированных предметных областях. Как правило, эти области хорошо изучены и располагают более менее четкими стратегиями принятия решений.
Экспертная система имеет разветвленную сеть, позволяющую делать запросы и глубокий поиск в базах данных и хранилищах знаний.
Экспертные системы широко применяются в бизнесе, часто работают независимо и не включаются в корпоративные информационные сети. Как правило, они являются узко специализированными: транспортные, медицинские, банковские, торговые, юридические и т. д.
План
1. Управленческий учет и отчетность.
2. Автоматизированные информационные системы.
Рисунок 1 – Обобщенная структура ИТ предприятия
Тема №1 «Производственные комплексы в экономике России»
План
1. Производственный комплекс, понятие, структура.
2. Производственные комплексы, классификация.
Дата: 2019-02-02, просмотров: 547.