Васильев В.П.
ЭКОНОМЕТРИЯ и Статистический анализ с применением Excel
Для всех экономических специальностей.
.
Минск 2017
Лабораторная работа 1 Репрезентативность информации, 3
Лабораторная работа 2 Оценка степени соответствия эмпирического распределения нормальному с использованием значений асимметрии и эксцесса. 4
Лабораторная работа 3. Исследование распределений случайных величин методами описательной статистики. 8
Лабораторная работа 4. Корреляционный анализ двухфакторных выборок. 13
Лабораторная работа 5. Регрессионно-корреляционный анализ двухфакторных выборок. 20
Лабораторная работа 6. Корреляционный анализ многофакторных выборок. 25
Лабораторная работа 7. Регрессионно-корреляционный анализ многофакторных выборок. 29
Лабораторная работа 8.Нелинейная регрессия. 32
Лабораторная работа 9.Статистический анализ выборок с категорийными переменными. 37
Лабораторная работа 10. Построение модели регрессии при наличии гетероскедастичности и автокорреляции. 42
Лабораторная работа11. Системы эконометрических уравнений. 48
Лабораторная работа 12 Расчет и оценка параметров динамической эконометрической модели. 51
Приложение 1. 55
Приложение 2. 56
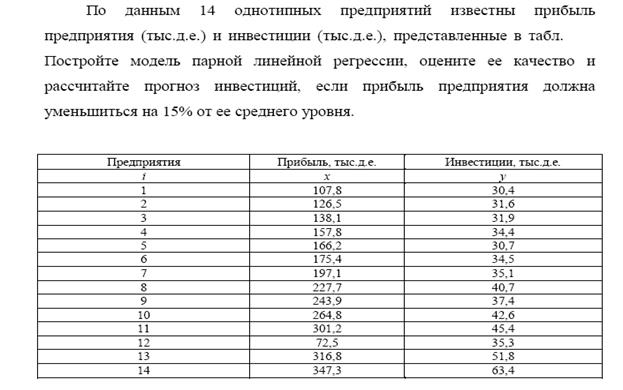
Задания
Задание 1. Какой должна быть численность выборки для нахождения средней себестоимости 1 т прироста крупного рогатого скота по 350 сельскохозяйственным организациям региона, ошибка которой не должна превышать 0,3 млн. рублей с вероятностью 75%. Стандартное отклонение признака – 2,1 млн. рублей.
Задание 2. Определите численность выборки для расчета удоя на среднегодовую корову в 200 сельскохозяйственных организациям региона, если необходимо, чтобы ошибка не превышала 100 кг с вероятностью 90%. Стандартное отклонение признака – 653 кг.
Задание 3. Сколько сельскохозяйственных организаций из 350 необходимо обследовать, чтобы определить среднюю себестоимость производства 1 т зерна, ошибка которой не будет превышать 15 тыс. рублей с вероятностью 75%. Стандартное отклонение признака – 76,5 тыс. рублей.
Задание 4. Определите численность выборки для нахождения среднего значения среднесуточного прироста свиней по 190 сельскохозяйственным организациям региона, ошибка которого не будет превышать 20 г с вероятностью 75%. Стандартное отклонение признака – 116 г.
Лабораторная работа 3. Исследование распределений случайных величин методами описательной статистики.
Цель работы: научиться обрабатывать выборки из генеральных совокупностей средствами компьютерной графики и с использованием инструментов MS EXCEL
Задачи:
-изучить средства для генерации наборов случайных чисел;
-уметь производить выборку из множества случайных чисел;
-проводить ранжирование выборок и генеральных совокупностей;
-вычислять моменты распределения случайных величин;
-строить диаграммы распределения выборок.
Инструментарий: приложение «Анализ данных».-вкладка Данные Если отсутствует приложение, то необходимо загрузить команду Настройки, установив опцию Пакет анализа .В случае если в настройках отсутствует данное приложение, то необходимо войти в библиотеку системы и инсталлировать приложение(делать это лучше под руководством системного программиста).
Теоретические сведения
1.Для выполнения этой работы необходимо знать элементы теории вероятности и математической статистики, в частности иметь понятия о моментах случайной величины, распределениях, способах представления распределений.
2.Сведения о возможностях приложения « Анализ данных»
2.1.Генерация случайных чисел используется для моделирования явлений, имеющих случайную природу, по известному закону распределения .В составе приложения Анализ данных имеются несколько популярных распределений:Нормальное,дискретное,модельное,Пуассона,биномиальное и др. Параметрами окна генерации случайных чисел являются:
-число переменных- целое;
-число случайных чисел- целое число, характеризует количество чисел по каждой переменной;
-тип распределения (равномерное, Бернулли, Пуассона, нормальное и т.д.);
-параметры распределения табл.1;
-выходной интервал (на том же листе, на новом листе, в новой книге) и место куда поместить сгенерированные последовательности.
2.2.Инструмент выборка, производит выборку подмножества мощности n<m из заданного множества, либо случайным ,либо периодическим образом.
2.3.Инструмент Гистограмма -позволяет построить интервальную гистограмму распределения случайной величины (С.В.). Входные данные –диапазон изменения СВ(блок данных на рабочем листе) и интервал карманов(блок данных сформированный заранее, верхних границ интервалов покрывающих область изменения СВ.
2.4.Инструмент «Описательная статистика» - позволяет вычислять все числовые моменты распределения случайной величины. Входные данные:
-диапазоны данных, как минимум два, задаются ссылками;
-группирование (строки, столбцы);
-выходной интервал (ссылка);
-статистики (флажки).
3.Уметь работать с объектами MS- Excel различными статистическими функциями(среднее, дисперсия, эксцесс, минимум, максимум и др.) и диаграммами (гистограммы, графики, точечные)
Табл.1.Некоторые законы распределения
| Распределение | Параметры | Область применения |
| Биномиальное | 0<R<1,n-целое(число испытаний) | Массовое производство |
| Пуассона | l>0 | Массовое обслуживание, исследование надежности |
| Нормальное | a-мат. ожидание, s> 0-дисперсия | При большом количестве не сильно выделяющихся случайных факторов |
| Равномерное | А<В два числа | Массовое производство |
| Модельное | Множество Рi≤1, SRi=1 | При известном законе распределения |
| Бернулли | Р =1 или Р =0 | Для моделирования событий с двумя исходами |
Ранжирование рядов данных.
1.Пусть задан набор данных.
2.Проведем сортировку по убыванию(или возрастанию).
3. Меньшему (большему) значению начисляется меньший ранг. Наименьшему значению начисляется ранг 1.
4. Наибольшему (меньшему) значению начисляется ранг, соответствующий количеству ранжируемых значений. Например, если n=7, то наибольшее значение получит ранг 7, за возможным исключением для тех случаев, которые предусмотрены правилом 2
В случае, если несколько значений равны, им начисляется ранг, представляющий собой среднее значение из тех рангов, которые они получили бы, если бы не были равны. Например, 3 наименьших значения равны 10 секундам. Если бы мы измеряли время более точно, то эти значения могли бы различаться и составили бы, скажем, 10.2 сек; 10.5 сек; 10.7 сек. В этом случае они получили бы ранги, соответственно, 1, 2 и 3. Но поскольку полученные нами значения равны, каждое из них получает средний ранг:
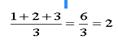
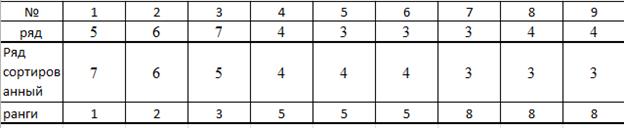
Пример Задан ряд.
| № | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| ряд | 5 | 6 | 7 | 4 | 3 | 3 | 3 | 4 | 4 |
Выполним сортировку по возрастанию

5.Проведем ранжирование
Элементу 7 присвоим 1, элементам 6 и 5 ранги 2 и 3,элементу 4 присвоим ранги
(4+5+6)/3=5 , элементу 3 ранг (7+8+9)/3=8
Проверка сумма рангов должна равняться S=(n+1)*n/2
В данном случае 45.
Выполнение работ ы
- Выполните генерацию случайных чисел по закону распределения ,используя приложение АНАЛИЗ ДАННЫХ, например сгенерировать последовательность из 20 чисел задав, например распределение Пуассона
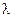 =10 или нормальное математическое ожидание равно 0,5 дисперсия 2 ,полученную последовательность считаем генеральной совокупностью.
=10 или нормальное математическое ожидание равно 0,5 дисперсия 2 ,полученную последовательность считаем генеральной совокупностью.
| 2 | 4 | 0 | 3 | 4 | 1 | 3 | 2 | 2 | 2 | 2 | 2 | 4 | 2 | 2 | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 1 | 0 | 4 | 4 | 3 | 3 | 1 | 3 | 3 | 2 | 2 | 1 | 2 | 2 | 3 | 1 | 1 | 4 | 2 | 3 | 3 | 3 | 2 | 3 |
2. Проведите ранжирование и рассчитайте Моду и Медиану ряда.
3. Определите и задайте интервал «Карманов», например интервал карманов
0 1 2 3 4
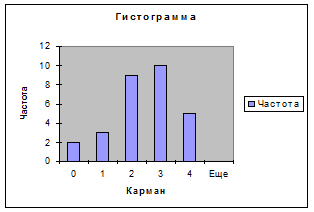
- Постройте гистограмму распределения, команда ГИСТОГРАММА.
Для этого введите исходный диапазон ,интервал карманов и место расположения. Получите частотную таблицу и график.
| Карман | Частота |
| 0 | 2 |
| 1 | 3 |
| 2 | 9 |
| 3 | 10 |
| 4 | 5 |
| Еще | 0 |
 |
- Самостоятельно, увеличьте число карманов в два раза и повторите построение гистограммы.
- Проведите выборку из генеральной совокупности, используя команду, ВЫБОРКА объем 10 элементов. Проведите ранжирование, используя команду РАНГ. Вычислите МОДУ И МЕДИАНУ выборки, сравните с модой и медианой генеральной совокупности. Сделайте выводы.
- .Постройте гистограмму выборки.
- Вычислите основные моменты случайной величины (среднее, дисперсию, асимметрию, эксцесс) выборке (используйте функции , категории статистические) и генеральной совокупности, сделайте вывод .
- Проверьте свои расчеты, команда ОПИСАТЕЛЬНАЯ СТАТИСТИКА.
| Столбец1 | |
| Среднее | 2,46 |
| Стандарт ошибка | 0,143456 |
| Медиана | 3 |
| Мода | 3 |
| Стандарт. Отклонен. | 1,014386 |
| Дисперсия | 1,02898 |
| Эксцесс | -0,09455 |
| Асимметричность | -0,43679 |
| Интервал | 4 |
| Минимум | 0 |
| Максимум | 4 |
| Сумма | 123 |
| Счет | 50 |
- Сгенерируйте другое распределение, например нормальное и повторите пп.5-8
- Оформите отчет.
Самостоятельно.
Выполните расчет статистических показателей и сравните с результатами инструмента «Описательная статистика» , вычислите и оцените средние и дисперсии.
Таблица – Посещаемость занятий студентами и их оценки на экзамене см лаб.раб.2
| Номер | Пропуски | Оценка | Номер | Пропуски | Оценка |
| 1 | 1 | 8 | 14 | 1 | 5 |
| 2 | 4 | 5 | 15 | 4 | 3 |
| 3 | 3 | 4 | 16 | 3 | 7 |
| 4 | 0 | 7 | 17 | 2 | 5 |
| 5 | 2 | 7 | 18 | 0 | 7 |
| 6 | 6 | 2 | 19 | 1 | 9 |
| 7 | 5 | 1 | 20 | 5 | 6 |
| 8 | 1 | 10 | 21 | 3 | 5 |
| 9 | 0 | 9 | 22 | 2 | 7 |
| 10 | 7 | 3 | 23 | 3 | 3 |
| 11 | 4 | 5 | 24 | 2 | 8 |
| 12 | 3 | 4 | 25 | 0 | 10 |
| 13 | 2 | 6 |
Контрольные вопросы
1. Что такое случайная величина и ее закон распределения. Приведите примеры распределений.
2. Что такое моменты случайной величины. Какие моменты Вы знаете. Охарактеризуйте их.
3.Что такое генеральная совокупность и выборка.
4.Способы представления выборок.
5.Какие инструменты для выполнения статистических расчетов существуют в MS EXCEL
Выполнение работы.
1.Занесем данные в ячейки рабочего листа MS EXCEL
2. Заполним столбец Х*У, подсчитаем средние значения и стандартные отклонения используя функции среднее() , стандотглонГ()
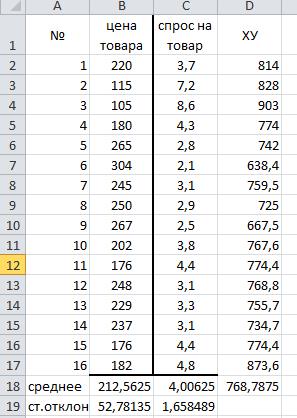
.
Подсчитаем ковариацию признаков, используя формулу
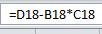
и корреляцию
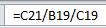
Результат

Коэффициент корреляции равен -0,945. Значение свидетельствует о сильной обратной связи переменных.
4.Проверим его значимость и вычислим доверительный интервал.
Самостоятельно рассчитайте силу связи между факторами таблицы.
| фондоотдача в мил.руб | фондоворужонность. в мил руб |
| 1,45 | 6,4 |
| 1,3 | 7,8 |
| 1,37 | 9,76 |
| 1,62 | 7,9 |
| 1,91 | 5,35 |
| 1,68 | 9,9 |
| 1,94 | 4,5 |
| 1,89 | 4,88 |
| 1,94 | 3,46 |
| 2,06 | 3,6 |
| 2 | 3,56 |
| 1,02 | 5,65 |
| 1,85 | 4,28 |
| 0,9 | 8,9 |
| 0,62 | 8,52 |
| 1,09 | 7,19 |
| 1,6 | 4,82 |
| 1,53 | 5,46 |
| 1,4 | 6,2 |
Сделайте вывод.
Самостоятельно выполните исследование.
На предприятии Х проводился социологический опрос удовлетворенности своей работой. Получены данные.
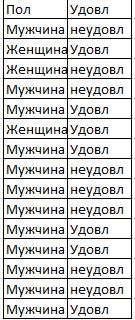
Рассчитать коэффициенты ассоциации и контингенции.
Примечание : при заполнении таблицы используйте функцию СчетЕсли()
Ранговые коэффициенты связи. В анализе социально-экономических явлений часто приходится прибегать к различным условным оценкам с помощью рангов, а взаимосвязь между отдельными признаками измерять с помощью непараметрических коэффициентов связи.
Ранжирование — это процедура упорядочивания объектов изучения, которая выполняется на основе предпочтения.
Ранг — порядковый номер значений признака, расположенных в порядке возрастания или убывания величин. Если значения признака имеют одинаковую количественную оценку, то ранг всех значений принимается равным средней арифметической из соответствующих номеров мест, которые они занимают. Данные ранги называются связными.
Среди непараметрических методов оценки тесноты связи наибольшее значение имеют ранговые коэффициенты Спирмена и Кендэла. Эти коэффициенты могут быть использованы для определения тесноты связи как между количественными, так и между качественными признаками. Коэффициент корреляции Спирмена
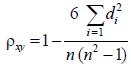
di квадраты разности рангов,n число наблюдений.
Если среди значений признаков х и у встречается несколько одинаковых, образуются связанные ранги, т. е. одинаковые средние номера; например, вместо одинаковых по порядку третьего и четвертого значений признака будут два ранга по 3,5. В таком случае коэффициент Спирмена вычисляется как:
где
j - номера связок по порядку для признака х;
Аj - число одинаковых рангов в j-й связке по х;
k - номера связок по порядку для признака у;
Вk - число одинаковых рангов в k-й связке по у.
Для проверки значимости коэффициента корреляции Спирмена используют те же методы, что и для коэффициента корреляции количественной шкалы.
Выполнение работы
Рассмотрим данные таблицы 1 Посещаемость занятий студентами и их оценки на экзамене (лабораторной работы 2), фрагмент исходной Excel таблицы.
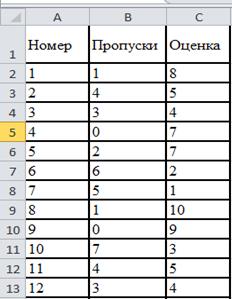
Выполним ранжирование рядов данных.(фрагмент таблицы ранжирование рядов),используя функцию

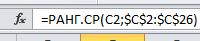
Обратите внимание, что вторым аргументом функции является массив , имеющих абсолютные адреса ячеек
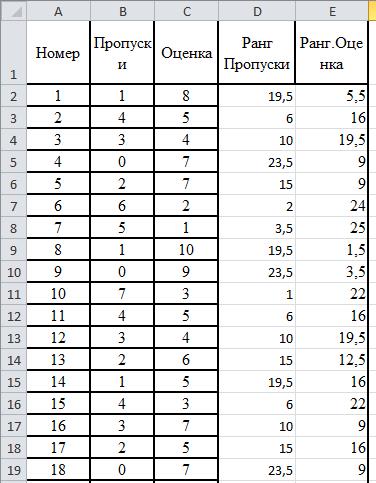
Вычислим разности рангов и квадраты разностей
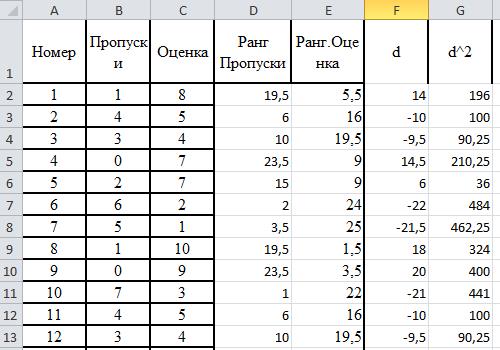
Подсчитаем сумму квадратов рангов
S=4548
Так как среди данных встречаются повторения, то для расчета коэффициента корреляции Спирмена , используем формулу
, где ,
j - номера связок по порядку для признака х;
Аj - число одинаковых рангов в j-й связке по х;
k - номера связок по порядку для признака у;
Вk - число одинаковых рангов в k-й связке по у.
Для подсчета одинаковых рангов по связкам, целесообразно скопировать в отдельную часть листа столбцы рангов и выполнить сортировки.
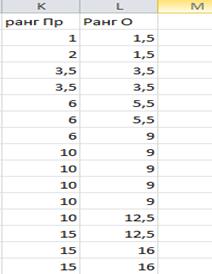
Из отсортированных данных видно, что повторяются 6 наблюдений с рангами
3,5 ; 6; 10; 15; 19,; 23,5
аналогично по оценкам одинаковые ранги у 8 наблюдений-это ранги
1,5 ; 3,5 ; 5,5 ;9 ; 12,5 ;16 ,19,5 22
, таким образом
Число рангов по связке Пропуск равно 6 , число рангов по связке оценка 8
Тогда
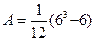 =17,5
=17,5
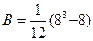 =42
=42
Число наблюдений-25
Тогда коэффициент корреляции Спирмена равен -0,767

Подсчитаем значимость
Тнабл= 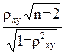 =5,73
=5,73
Ткр=1,73
Вывод коэффициент корреляции значим.
Самостоятельно рассчитать доверительный интервал.
Выполнение работы.
1.Занесем данные в ячейки рабочего листа MS EXCEL.
2. Построим график корреляционного поля, используя диаграмму Точечная , данные оси ОХ Объем производства.
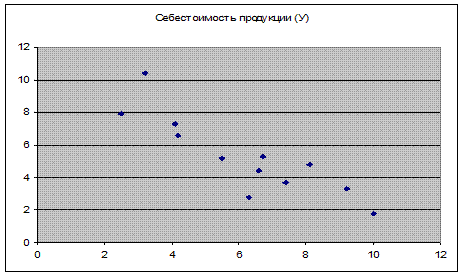
Из графика можно предположить о наличии линейной связи данных.
3. Определим количественные характеристики связи, используя настройку
Анализ данных \корреляция.
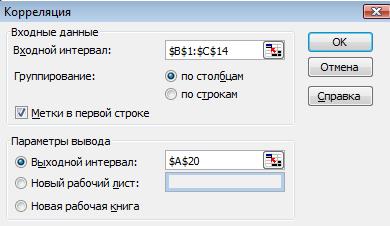
Результат
| Объем производства | Себестоимость продукции (У) | |
| Объем производства | 1 |
|
| Себестоимость продукции (У) | -0,871020552 | 1 |
Коэффициент корреляции равен -0,87. Значение свидетельствует о сильной связи данных.
4.Проверим его значимость и вычислим доверительный интервал.
4.1. Проверка значимости
Вычислим величину
Тнабл= 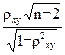
Т набл= -5,015033743
Для вычисления критического значения Используя функцию СТЬЮДРАСПОБР, категория статистические ,по заданному уровню значимости α=0,05 и числу степеней свободы (n-2)=10 определяют критическую точку tα/2 , n-2. Если модуль Т меньше tα/2 , n-2
С вероятностью 5% и степенями свободы 10 критическое значение распределения Стьюдента равно Ткр = 2,228139
|Т набл| > Ткр , что свидетельствует о его значимости коэффициента корреляции
4.2. .Рассчитаем д доверительные интервалы коэффициента корреляции
а)Выполним преобразование Фишера над коэффициентом корреляции, Фишер(ρ)
Ф(ρ)= - 1,337
б) вычислим отклонение ΔZ = 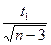 , где t1 значение функции Лапласа, встроенная функция НОРМСТОБР.
, где t1 значение функции Лапласа, встроенная функция НОРМСТОБР.
Величина отклонения с вероятностью 95% ΔZ= 0,548
в) Предельные значения интервала в пространстве Фишера
А= -1,337-0,548=-1,885
В=-1,337+0,548=-0,789
г) Обратное преобразование Фишера даст значения границ доверительного интервала для ρ вероятностью 95% -0,958 и -0,658
.5. Построим уравнение регрессии используя Анализ данных \ Регрессия.
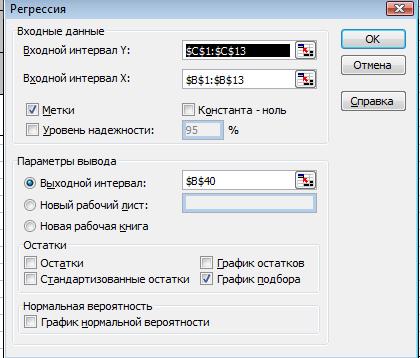
Протокол Регрессионного анализа.
| Регрессионная статистика | |
| Множественный R | 0,871020552 |
| R-квадрат | 0,758676802 |
| Нормированный R-квадрат | 0,734544482 |
| Стандартная ошибка | 1,24847364 |
| Коэффициенты | t-статистика | P-Значение | Нижние 95% | Верхние 95% | |
| Y-пересечение | 10,82788711 | 10,3015 | 1,2099E-06 | 8,48589 | 13,16988 |
| Объем производства | -0,900198446 | -5,6069 | 0,000225 | -1,25792 | -0,54247 |
6.Оценки значимости.
6.1 Модель работает на 87%
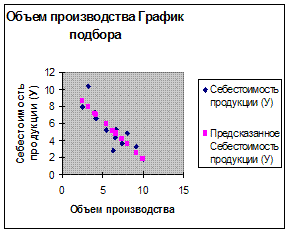 Коэффициент детерминации Множественный R= 0.76
Коэффициент детерминации Множественный R= 0.76
Уравнение регрессии У= 10,82- 0,9*Х
6.2. Оценки значимости коэффициентов
а) По критерию Стьюдента, необходимо сравнить данные Т статистики с критическим значением Стьюдента, найденным в пункте 4.1.
Для первого коэффициента 10,3015 >2,228139 для второго 5,6069>2,228139 , что свидетельствует о их значимости
б) оценка по Р значению.
Если величина в столбце Р значение меньше 0,05, то с вероятностью 0,95 соответствующий коэффициент значим.
в) доверительные интервалы для значимых коэффициентов регрессии
8.4886<10.827<13.17
-1.258<-0.9 <-0.542
7. График подбора регрессии
Изобразим на графике граничные линии регрессий доверительного интервала.
Для этого используем формулы
У=-0,542 х+13,69
У=-1,258Х+8,486
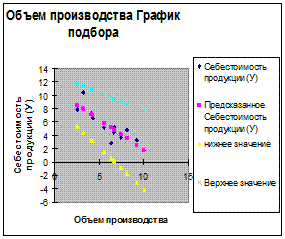
Подсчитаем среднюю себестоимость продукции, если объем производства составит 5т.у.е. У= -0,9*5+10,82=-4.5+10.82=6.32
Определим степень доверия
У=-0,542*5+13,69=10,98
У=-1,258*5+8,486=2,196
С вероятностью 95% Себестоимость будет в пределах(2,196;10,98) и в среднем 6,32
Какой будет объем производства, если себестоимость равна 2,5
Х=-(2,5-10,82) / 0,9=9,24
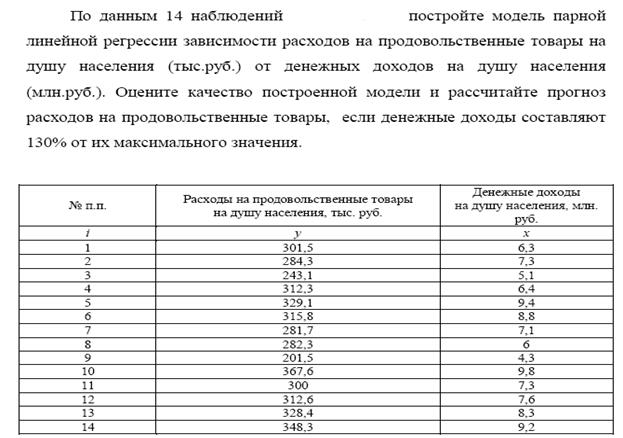
Самостоятельно провести анализ данных из таблиц и построить модель
Теоретические сведения
Большинство экономических объектов и явлений описываются не одним, а целой системой показателей. С этой целью необходимо провести выборку банков и провести их оценку по ряду признаков. В качестве примеров можно назвать уставной фонд, привлекаемые средства, оборотные средства, вклады населения ,невозвращенные кредиты и т.д. Обозначим символами Х, а соответствующие анализируемые признаки символами Хjполучим таблицу
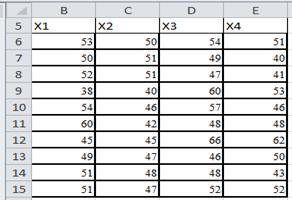
Данные представленные в таблице можно интерпретировать матрицей А размерности (10*4) и представляют собой многомерную случайную величину (МСВ),строки которой элементы выборки, а столбцы случайные значения признаков. Данная матрица представляет собой СМВ. Строки и столбцы которой представляют случайные величины. Каждая случайная величина характеризуется системой моментов средними, отклонениями и др. сами же величины могут быть независимыми или связаны друг с другом. Связи между ними характеризуются не одним, а целой системой величин, которые образуют матрицы парных ковариаций и корреляций. Задачи, решаемые в данной работе, связаны с вычислением и исследованием свойств этих матриц.
Выполнение работы
1.Центрирование МСВ
1.1.Вычислим средние и стандартные отклонения по значениям элементов каждого столбца Получим для средних и для стандартных отклонений строки

В свободном месте листа ,например в ячейки Н6:К6 Введем формулу вида

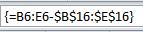
Не забудьте нажать Ctrl+Shift+Enter
Получим
и скопируем ее на остальные ячейки
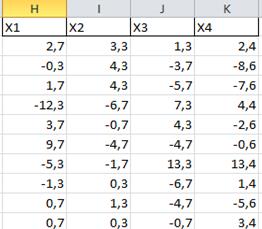
Получим матрицу В Подсчитаем среднее для преобразованной матрицы В .
1.2.Нормирование матрицы.
В свободном месте листа ,например в ячейки М6:Р6

Введем формулу вида

и скопируем ее на остальные ячейки
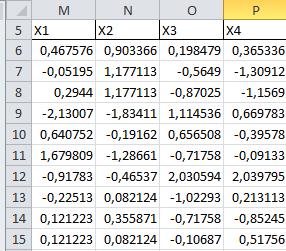
Подсчитайте среднее и стандартное отклонение для столбцов матрицы.
Самостоятельно Постройте матрицу парных корреляций для выборки и вычислите частные и множественные коэффициенты корреляции
| Рентабельность | фондоотдача | фондоворужонность. |
| 13,25 | 1,45 | 6,4 |
| 10,16 | 1,3 | 7,8 |
| 13,72 | 1,37 | 9,76 |
| 12,85 | 1,62 | 7,9 |
| 10,63 | 1,91 | 5,35 |
| 9,13 | 1,68 | 9,9 |
| 25,83 | 1,94 | 4,5 |
| 23,39 | 1,89 | 4,88 |
| 14,68 | 1,94 | 3,46 |
| 10,05 | 32,4 | 2,06 |
| 14 | 11,52 | 2 |
| 9,66 | 17,28 | 1,02 |
| 10,03 | 16,2 | 1,85 |
| 9,13 | 13,32 | 0,9 |
| 5,17 | 17,28 | 0,62 |
| 9,9 | 9,72 | 1,09 |
| 12,62 | 16,2 | 1,6 |
| 5,02 | 24,84 | 1,53 |
Выполнение работы.
1.Занесем данные в ячейки рабочего листа MS EXCEL.
2. Определим количественные характеристики связи, используя настройку
Анализ данных \корреляция.
| Рентабельность | ненормир.Оборотные с-ва | фондоотдача | фондоворуж. | нормир.обор.с-ва | |
| Рентабельность | 1 |
|
|
|
|
| Ненорм.Обор с-ва | -0,3735 | 1 |
|
|
|
| фондоотдача | 0,47878 | 0,192469 | 1 |
|
|
| фондоворуж. | -0,29462 | -0,241921 | -0,66241838 | 1 |
|
| Норм.обор.с-ва | -0,38508 | 0,021457 | -0,07516782 | 0,019524 | 1 |
3.Проверим значимость коэффициентов парных корреляций и вычислим их доверительные интервалы.
3.1. Проверка значимости
Вычислим величину
Тнабл= 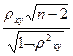
Таблица Т расч , для каждого коэффициента корреляции
| 0 |
|
|
|
|
| -2,1308 | 0 |
|
|
|
| 2,8857 | 1,037856 | 0 |
|
|
| -1,6313 | -1,31932 | -4,6789 | 0 |
|
| -2,2079 | 0,113569 | -0,3988 | 0,103333 | 0 |
Т кр=2,048
Отсюда можем сделать вывод о значимости только 4 коэффициентов
Для вычисления интервальных оценок воспользуемся методикой предыдущей работы, раздел 4.2
Данные удобно представить таблицей.
| фишер | Zr | ΔZ | мин =Zr-Δ | мах=Zr+Δ |
| р,1 | -0,3925 | 0,328970 | -0,72149828 | -0,06356 |
| р,2 | 0,52140 |
| 0,1924356 | 0,85037 |
| р,4 | -0,4060 |
| -0,7349811 | -0,07704 |
| r 3,2 | -0,7971 |
| -1,1260814 | -0,46814 |
После выполнения обратных преобразований Фишера получим.
| гран.корел | ρl=F(мин) | ρh=F(мах) |
| р,1 | -0,617836 | -0,0634 |
| р,2 | 0,190094 | 0,69126 |
| р,4 | -0,626103 | -0,0768 |
| 3,2 | -0,809673 | -0,4367 |
4.Расчет частных коэффициентов корреляции.
Частные коэффициенты корреляции характеризуют силу линейной связи двух факторов, без учета влияния остальных
Р= 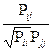 , Р I,j алгебраическое дополнение соответствующего элемента матрицы парных корреляций.
, Р I,j алгебраическое дополнение соответствующего элемента матрицы парных корреляций.
Для вычисления их используем прием.
а) вычислим обратную матрицу матрицы парных корреляций
б) вычислим ее определитель
в) с помощью специальной вставки , выполним умножение элементов обратной матрицы на значение определителя.
а)Обратная матрица.
| 2,317 | 1,112 | -1,148 | 0,176 | 0,779 |
| 1,112 | 1,599 | -0,616 | 0,300 | 0,342 |
| -1,148 | -0,616 | 2,367 | 1,086 | -0,272 |
| 0,176 | 0,300 | 1,086 | 1,842 | 0,107 |
| 0,779 | 0,342 | -0,272 | 0,107 | 1,270 |
Определитель
0,2257
Матрица алгебраических дополнений
| 0,523 | 0,251 | -0,259 | 0,040 | 0,176 |
| 0,251 | 0,361 | -0,139 | 0,068 | 0,077 |
| -0,259 | -0,139 | 0,534 | 0,245 | -0,061 |
| 0,040 | 0,068 | 0,245 | 0,416 | 0,024 |
| 0,176 | 0,077 | -0,061 | 0,024 | 0,287 |
Теперь использованием формулы, для частных коэффициентов корреляции , вычислим их значение, но только для значимых коэффициентов.
| 0,5778 | 1,0000 |
|
|
| -0,4904 | -0,3166 | 1,0000 |
|
| 0,0851 |
| 0,5202 | 1,0000 |
| 0,4539 |
|
|
|
Оценим их значимость по тем же критериям
5. Построение модели регрессии
У-рентабельность
Протокол регрессии
| Регрессионная статистика | |
| Множественный R | 0,753923 |
| R-квадрат | 0,568400 |
|
|
|
|
|
|
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | |
| Y-пересечение | 17,1885 | 6,7479 | 2,5472 | 0,0174 |
| ненормир.Оборотные с-ва | -0,5002 | 0,1413 | -3,5401 | 0,0016 |
| фондоотдача | 6,2535 | 2,2228 | 2,8133 | 0,0094 |
| фондоворуж. | -0,2059 | 0,4822 | -0,4269 | 0,6731 |
| нормир.обор.с-ва | -0,0513 | 0,0201 | -2,5470 | 0,0174 |
Из протокола видно, что модель работает на 75%
Имеет вид
У=17,18- 0,5Х1+6,25Х2-0,206Х3-0,05Х4
Все коэффициенты кроме третьего значимы.
Имеет место мультиколлинеарность, второй и третьей переменной, одну из них надо исключить из анализа
Новая модель.
| Множественный R | 0,75183 |
| R-квадрат | 0,56525 |
| Нормированный R-квадрат | 0,51509 |
| Стандартная ошибка | 4,03248 |
Самостоятельно выполните анализ данных из приложения 1
Самостоятельно. Рассчитать потребление мяса в г.п. Пуховичи, зимой. если известны данные выборки
| № п/п | Душевое потребление мяса, кг (Y) | Душевой доход, тыс. дол. (Х1) | Город/Поселок ГТ | Время года |
| 1 | 35 | 1,2 | Поселок | Осень |
| 2 | 31 | 0,7 | город | Осень |
| 3 | 28 | 0,6 | Поселок | Лето |
| 4 | 40 | 0,8 | город | Весна |
| 5 | 45 | 0,4 | Поселок | Весна |
| 6 | 31 | 0,6 | Поселок | Осень |
| 7 | 30 | 0,8 | город | Лето |
| 8 | 28 | 0,3 | Поселок | Лето |
| 9 | 42 | 0,6 | Поселок | Весна |
| 10 | 50 | 0,9 | город | Весна |
| 11 | 53 | 0,8 | город | Зима |
| 12 | 42 | 0,7 | город | Осень |
| 13 | 60 | 1,5 | Поселок | Весна |
| 14 | 35 | 0,5 | Поселок | Зима |
| 15 | 28 | 0,4 | Поселок | Лето |
| 16 | 37 | 0,8 | город | Осень |
| 17 | 45 | 0,9 | город | Весна |
| 18 | 43 | 1,3 | Поселок | Лето |
| 19 | 40 | 0,9 | город | Осень |
| 20 | 51 | 1 | Поселок | Весна |
Проверьте.
На координатной плоскости изобразим корреляционное поле и график полученного уравнения регрессии.
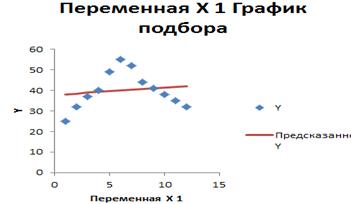
Из рисунка видно, что фактические точки наблюдений в первые три месяца находятся ниже линии уравнения регрессии. В период с апреля по сентябрь наблюдается противоположная тенденция, а именно, точки корреляционного поля расположены выше прямой линии. Наконец, в последние 3 месяца года точки снова опускаются ниже линии уравнения регрессии.
Анализ показывает, что между отклонениями ei существует определенная закономерность. Иными словами, в данном случае присутствует автокорреляция.
При изучении экономических процессов и явлений встречается положительная и отрицательная автокорреляция. Положительная автокорреляция означает, что за отрицательным отклонением следует положительное и наоборот.
К основным причинам, которые вызывают появление автокорреляции следует отнести ошибки спецификации, инертность экономических показателей, эффект паутины и сглаживание исходных данных.
Ошибки спецификации. Неправильный выбор формы связи между факторным и результативным показателями часто приводит к появлению автокорреляции. Если вернуться к рисунку то очевидно, что в этом случае параболическая зависимость более адекватно отражает изучаемый экономический процесс. Поэтому расчет параметров параболы и последующее использование этой линии для анализа экономических явлений позволит существенно снизить влияние автокорреляции и, соответственно, повысить качество эконометрической модели.
Инертность экономических показателей. Многие экономические показатели обладают определенной цикличностью. Известно, что экономический цикл – это динамическая характеристика экономики, включающая периодические взлеты и падения в развитии экономической системы.
Обычно выделяют 4 фазы экономического цикла: оживление, бум, спад, подъем. Понятно, что переход от одного цикла к последующему не может произойти мгновенно. Иными словами, динамика развития экономической системы обладает определенной инертностью.
Эффект паутины. Очень часто производственно-экономические показатели реагируют на изменение внешних условий с запаздыванием. Например, увеличение цены на зерно в начале года не приведет сразу же к улучшению финансового состояния сельскохозяйственного предприятия. Должно пройти определенное время, чтобы созрел урожай и продукция была реализована по новым ценам.
Сглаживание исходных данных. В некоторых случаях данные по некоторому достаточно продолжительному интервалу времени получают усреднением данных по отдельным подынтервалам. Это приводит к определенному уменьшению колебаний внутри изучаемого периода и может вызвать автокорреляцию.
Автокорреляция имеет несколько негативных моментов. Данное явление, прежде всего, снижает качество эконометрической модели. В некоторых случаях характеристики полученного уравнения регрессии будут завышенными и, следовательно, использование таких эконометрических моделей для анализа и прогнозирования экономики даст нам искаженные результаты.
Методы определения автокорреляции могут быть использованы только после расчета параметров эконометрической модели и отклонений ei.
Графический метод.
При использовании графического метода по оси абсцисс откладываются либо время получения данных, либо порядковый номер наблюдения. Ось ординат, в свою очередь, служит для указания отклонений ei. Анализ отклонений показывает отсутствие или наличие связи между отклонениями и, следовательно, в этом случае вероятность наличия или отсутствия автокорреляции. Графический метод не всегда может дать однозначный ответ на вопрос о наличии автокорреляции и её направлении.
Критерий Дарбина-Уотсона (DW).
Общая схема критерия Дарбина-Уотсона состоит в следующем.
1. Строится уравнение регрессии и определяются отклонения 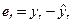 для каждого наблюдения, общее количество которых составляет T.
для каждого наблюдения, общее количество которых составляет T.
2. Рассчитывается критерий DW по формуле:

На примере информации из таблицы 1 покажем методику расчета рассматриваемого критерия.
Таблица 3 – Схема расчета критерия Дарбина-Уотсона
| t | yt | 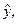
| et | et2 | (et – et-1)2 |
| 1 | 25 | 38,115 | -13,115 | 171,9 | 44,36 |
| 2 | 32 | 38,458 | -6,458 | 41,6 | 21,72 |
| 3 | 37 | 38,801 | -1,801 | 3,2 | 7,08 |
| 4 | 40 | 39,143 | 0,857 | 0,8 | 75,00 |
| 5 | 49 | 39,486 | 9,514 | 90,8 | 32,04 |
| 6 | 55 | 39,829 | 15,171 | 230,7 | 11,16 |
| 7 | 52 | 40,171 | 11,829 | 140,4 | 69,56 |
| 8 | 44 | 40,514 | 3,486 | 12,3 | 11,16 |
| 9 | 41 | 40,857 | 0,143 | 0,0 | 11,16 |
| 10 | 38 | 41,199 | -3,199 | 10,0 | 11,16 |
| 11 | 35 | 41,542 | -6,542 | 42,4 | 11,16 |
| 12 | 32 | 41,885 | -9,885 | 97,0 | |
| Итого: | 841,1 | 305,51 |
Расчетные значения были определены на основании уравнения регрессии =37,77 + 0,34t.
Значения столбца et-1 получаются путем перемещения значений колонки et на один уровень вниз. Из этого следует, что при заполнении столбца et-1 первое значение теряется.
После заполнения таблицы и нахождения соответствующих сумм легко рассчитать критерий Дарбина-Уотсона:
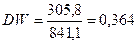
3. На заключительном этапе анализа необходимо сравнить фактическое значение критерия Дарбина-Уотсона с табличными данными. Существуют специальные таблицы определения критических точек для распределения Дарбина-Уотсона. С помощью этих таблиц можно определить критические точки d1 и d2 при требуемом уровне значимости (например, 0,05). Конкретные значения d1 и du зависят от количества наблюдений (опытов) n, а также от числа факторных переменных эконометрической модели m. В нашем примере значения d1 и du2 составляют 0,971 и 1,331, соответственно (n=12; m=1; уровень значимости принят равным 0,05).
При сравнении фактических и расчетных значений критерия Дарбина-Уотсона можно сделать вывод о наличии автокорреляции и её направленности. Для этого следует руководствоваться следующими правилами:
0 ≤ DW < d1 – существует положительная автокорреляция;
d1 ≤ DW < d2 – невозможно сделать вывод о наличии автокорреляции;
d2 ≤ DW < 4 – d2 – автокорреляция отсутствует;
4 – d2 ≤ DW < 4 – d1 - невозможно сделать вывод о наличии автокорреляции;
4 – d1 ≤ DW < 4 – существует отрицательная автокорреляция.
d1 d2 значение статистики Дарбина-Уотсона. Приложение 3
Таким образом, выполняется первое неравенство: 0 ≤ DW=0,364 < d1=0,971 и это подтверждает факт наличия положительной автокорреляции в нашем примере.
Можно воспользоваться более грубым способом
DW близко к нулю существует положительная автокорреляция;
DW близко к двум автокорреляция отсутствует;
DW близко к 4 – существует отрицательная автокорреляция
Автокорреляция, как указывалось ранее, представляет собой негативное явление, которое ухудшает качество эконометрических моделей. Поэтому, необходимо знать и уметь применять на практике различные способы смягчения автокорреляции. Чаще всего автокорреляция вызывается неправильной спецификацией модели. Следовательно, для уменьшения автокорреляции необходимо попытаться изменить форму эконометрической модели.
Иногда автокорреляция связана с отсутствием в модели какого-нибудь важного фактора. Поэтому, необходимо данный фактор (или несколько факторных переменных) включить в уравнение регрессии. Однако, если уменьшить автокорреляцию наиболее очевидными методами не получается, то данное явление обусловлено какими-то внутренними особенностями исходных данных.
Задание. По заданным исходным данным для заданной модели
1. Выделить эндогенные и экзогенные переменные.
Самостоятельно решить задачу
Задача Рассматривается модель функционирования торгового предприятия:
Y=b12C+a11S +έ1
C=b21Y+a22T+έ2
где Y - среднемесячные расходы предприятия (млн. руб.);
C среднемесячные доходы предприятия (млн. руб.);
S – торговые площади (кв. м);
T - торговое оборудование предприятия (млн. руб.).
Требуется
- Выделить эндогенные и экзогенные переменные.
- Записать приведенную форму модели.
- Определить коэффициенты приведенной формы модели.
- Вычислить значения инструментальных переменных.
- Определить коэффициенты структурной формы модели двух шаговым методом наименьших квадратов.
- Проверить значимость полученных уравнений и их коэффициентов
| Y | C | S | N |
| 5 | 2.1 | 10 | 1.5 |
| 5.9 | 3.2 | 15 | 2.0 |
| 6.4 | 3.8 | 30 | 2.8 |
| 7.7 | 5.24 | 36.0 | 2.8 |
| 9.3 | 6.4 | 52.7 | 6 |
| 9.8 | 6.4 | 52.7 | 6.0 |
| 11.2 | 8.1 | 64.0 | 7.37 |
| 12.0 | 9.3 | 83.4 | 9.38 |
| 13.7 | 10.0 | 94.3 | 10.31 |
| 14.0 | 11.3 | 100.0 | 11.05 |
| 14.6 | 12.0 | 104.7 | 11.28 |
| 15.85 | 13.32 | 120.7 | 13.28 |
Методы выделения тренда.
1. Скользящее среднее
2. Экспотенциальное сгдаживание.
3. Метод Фурье
Метод скользящих средних базируется на предположении, считающимся тривиальным: при определении средних значений случайные отклонения погашаются. При сглаживании этим методом фактические значения ряда динамики заменяются средними значениями, которые характеризуют срединную точку периода скольжения
Х к=1/5 (хк-2+х к-1+хк+хк+1+хк+2).
Самостоятельно выполните анализ временных рядов из файла Самост. Временные ряды
Самостоятельно Обработать временной ряд Приложения 2.
Приложение 1
Урожайность с ц/га
Орг..удобрения
Минер.удобрения
Фондоворужонность.
Качество пашни
1
25,2
0,9
229
57
27,7
2
29,6
2,6
241
45,4
30
3
29
3,2
262
53,9
30,3
4
30,5
2,7
297
58,5
31,2
5
37,9
2,1
358
49,2
34,7
6
43,6
5,9
417
54,3
40,4
7
37,9
4,3
278
57,4
37,5
8
21,1
1,2
214
50,2
26,8
9
24,7
1
253
46,2
27,4
10
30
5,6
268
42,1
31,6
11
39,5
6,6
370
52,7
35,5
12
34,6
2,2
301
47,3
34,2
13
29,1
1,4
267
69,4
26,1
14
49,3
8,8
357
49,9
42,6
15
27,7
1
246
55
30,6
16
36
4,1
306
52,3
38,2
17
32,8
6,6
297
44,1
32,4
18
35,8
1,2
370
39
33,7
19
25,9
2,5
217
43,6
28,1
20
31,3
1,6
274
55,8
31,9
21
25,7
2,7
292
57,7
32
22
29,9
1,7
277
57,9
31,8
Приложение 2
| i | Ряд | ||||||||||||
| 1 | 34,18981 | ||||||||||||
| 2 | 75,12776 | ||||||||||||
| 3 | 58,81507 | ||||||||||||
| 4 | 38,29251 | ||||||||||||
| 5 | 28,57673 | ||||||||||||
| 6 | 17,20807 | ||||||||||||
| 7 | 5,94361 | ||||||||||||
| 8 | -19,9495 | ||||||||||||
| 9 | -13,5539 | ||||||||||||
| 10 | 7,766463 | ||||||||||||
| 11 | 1,946117 | ||||||||||||
| 12 | -10,8058 | ||||||||||||
| 13 | 10,99628 | ||||||||||||
| 14 | 37,11521 | ||||||||||||
| 15 | 22,15092 | ||||||||||||
| 16 | 56,19745 | ||||||||||||
| 17 | 45,13513 | ||||||||||||
| 18 | 43,23677 | ||||||||||||
| 19 | 19,65716 | ||||||||||||
| 20 | -15,8856 | ||||||||||||
| 21 | -33,7403 | ||||||||||||
| 22 | -4,02929 | ||||||||||||
| 23 | -6,28788 | ||||||||||||
| 24 | -5,69742 | ||||||||||||
| 25 | 24,56248 | ||||||||||||
| 26 | 23,52716 | ||||||||||||
| 27 | 28,85584 | ||||||||||||
| 28 | 27,89142 | ||||||||||||
| 29 | 27,1705 | ||||||||||||
| 30 | 28,17369 | ||||||||||||
| 31 | 35,35716 | ||||||||||||
| 32 | -11,8794 | ||||||||||||
| 33 | -28,0553 | ||||||||||||
| 34 | -6,42963 | ||||||||||||
| 35 | -23,5943 | ||||||||||||
| 36 | -1,55448 | ||||||||||||
| 37 | 16,51492 | ||||||||||||
| 38 | 15,74033 | ||||||||||||
| 39 | 37,45865 | ||||||||||||
| 40 | 35,45363 | ||||||||||||
| 41 | 20,09745 | ||||||||||||
| 42 | 20,8121 | ||||||||||||
| 43 | 24,86951 | ||||||||||||
| 44 | 8,030622 | ||||||||||||
| 45 | -19,5174 | ||||||||||||
|
| m=1 | m=2 | m=3 | m=4 | m=5 | ||||||||
| n | dL | dU | dL | dU | dL | dU | dL | dU | dL | dU | |||
| 6 | 0,610 | 1,400 | - | - | - | - | - | - | - | - | |||
| 7 | 0,700 | 1,356 | 0,467 | 1,896 | - | - | - | - | - | - | |||
| 8 | 0,763 | 1,332 | 0,559 | 1,777 | 0,368 | 2,287 | - | - | - | - | |||
| 9 | 0,824 | 1,320 | 0,629 | 1,699 | 0,455 | 2,128 | 0,296 | 2,588 | - | - | |||
| 10 | 0,879 | 1,320 | 0,697 | 1,641 | 0,525 | 2,016 | 0,376 | 2,414 | 0,243 | 2,822 | |||
| 11 | 0,927 | 1,324 | 0,658 | 1,604 | 0,595 | 1,928 | 0,444 | 2,283 | 0,32 | 2,645 | |||
| 12 | 0,971 | 1,331 | 0,812 | 1,579 | 0,658 | 1,864 | 0,512 | 2,177 | 0,379 | 2,506 | |||
| 13 | 1,010 | 1,340 | 0,861 | 1,562 | 0,715 | 1,816 | 0,574 | 2,094 | 0,445 | 2,390 | |||
| 14 | 1,045 | 1,350 | 0,905 | 1,551 | 0,767 | 1,779 | 0,632 | 2,030 | 0,505 | 2,296 | |||
| 15 | 1,077 | 1,361 | 0,946 | 1,543 | 0,814 | 1,750 | 0,685 | 1,977 | 0,562 | 2,220 | |||
| 16 | 1,106 | 1,371 | 0,982 | 1,539 | 0,857 | 1,728 | 0,734 | 1,935 | 0,615 | 2,157 | |||
| 17 | 1,133 | 1,381 | 1,015 | 1,536 | 0,897 | 1,710 | 0,779 | 1,900 | 0,664 | 2,104 | |||
| 18 | 1,158 | 1,391 | 1,046 | 1,535 | 0,933 | 1,696 | 0,820 | 1,872 | 0,710 | 2,060 | |||
| 19 | 1,180 | 1,401 | 1,074 | 1,536 | 0,967 | 1,685 | 0,859 | 1,849 | 0,752 | 2,023 | |||
| 20 | 1,201 | 1,411 | 1,100 | 1,537 | 0,998 | 1,676 | 0,984 | 1,828 | 0,792 | 1,991 | |||
| 21 | 1,222 | 1,420 | 1,125 | 1,538 | 1,026 | 1,669 | 0,927 | 1,812 | 0,829 | 1,964 | |||
| 22 | 1,239 | 1,429 | 1,147 | 1,541 | 1,053 | 1,664 | 0,958 | 1,797 | 0,863 | 1,940 | |||
| 23 | 1,257 | 1,437 | 1,168 | 1,543 | 1,078 | 1,660 | 0,986 | 1,785 | 0,895 | 1,920 | |||
| 24 | 1,273 | 1,446 | 1,188 | 1,546 | 1,101 | 1,656 | 1,013 | 1,775 | 0,925 | 1,902 | |||
| 25 | 1,288 | 1,454 | 1,206 | 1,550 | 1,123 | 1,654 | 1,038 | 1,767 | 0,953 | 1,886 | |||
| 26 | 1,302 | 1,461 | 1,224 | 1,553 | 1,143 | 1,652 | 1,062 | 1,759 | 0,979 | 1,873 | |||
| 27 | 1,316 | 1,469 | 1,240 | 1,556 | 1,162 | 1,651 | 1,084 | 1,753 | 1,004 | 1,861 | |||
| 28 | 1,328 | 1,476 | 1,255 | 1,560 | 1,181 | 1,650 | 1,104 | 1,747 | 1,028 | 1,850 | |||
| 29 | 1,341 | 1,483 | 1,270 | 1,563 | 1,198 | 1,650 | 1,124 | 1,743 | 1,050 | 1,841 | |||
| 30 | 1,352 | 1,489 | 1,284 | 1,567 | 1,214 | 1,650 | 1,143 | 1,739 | 1,071 | 1,833 | |||
Васильев В.П.
ЭКОНОМЕТРИЯ и Статистический анализ с применением Excel
Для всех экономических специальностей.
.
Минск 2017
Лабораторная работа 1 Репрезентативность информации, 3
Лабораторная работа 2 Оценка степени соответствия эмпирического распределения нормальному с использованием значений асимметрии и эксцесса. 4
Лабораторная работа 3. Исследование распределений случайных величин методами описательной статистики. 8
Лабораторная работа 4. Корреляционный анализ двухфакторных выборок. 13
Лабораторная работа 5. Регрессионно-корреляционный анализ двухфакторных выборок. 20
Лабораторная работа 6. Корреляционный анализ многофакторных выборок. 25
Лабораторная работа 7. Регрессионно-корреляционный анализ многофакторных выборок. 29
Лабораторная работа 8.Нелинейная регрессия. 32
Лабораторная работа 9.Статистический анализ выборок с категорийными переменными. 37
Лабораторная работа 10. Построение модели регрессии при наличии гетероскедастичности и автокорреляции. 42
Лабораторная работа11. Системы эконометрических уравнений. 48
Лабораторная работа 12 Расчет и оценка параметров динамической эконометрической модели. 51
Приложение 1. 55
Приложение 2. 56
Лабораторная работа 1 Репрезентативность информации,
Назначение. Для упрощения сбора информации и проведения расчетов экономическое исследование может проводиться не по всей совокупности единиц, подлежащих обследованию, а по её части, которая репрезентирует (представляет) данную совокупность. Подлежащая изучению совокупность, из которой производят отбор, называется генеральной совокупностью, а часть её, подлежащая обследованию, — выборочной совокупностью или выборкой. Результаты изучения выборки дают возможность судить о всей совокупности.
Пример. Рассчитайте численность выборки, характеризующей цену реализации некоторого товара, если известно, что на рынке присутствует 200 фирм, занимающихся его реализацией, а ошибка полученных результатов не должна превышать 1 ден. ед. с вероятностью 90%. Дисперсия цены реализации равна 15,7.
Методика выполнения. Поскольку обследованию подвергаются не все объекты, а только часть из них, невозможно избежать ошибок в полученных результатах. Поэтому численность выборки должна быть достаточной для обеспечения заданной точности, которая характеризуется предельной ошибкой (e) и вероятностью (р) того, что полученное значение не выйдет за границы предельной ошибки. Для расчета численности выборки используется не само значение вероятности, а коэффициент t, непосредственно от неё зависящий. Некоторые значения t для часто встречающихся в расчетах вероятностей следующие:
| p | 0,5000 | 0,7500 | 0,9000 | 0,9500 | 0,9900 | 0,9950 | 0,9990 |
| t | 0,6745 | 1,1504 | 1,6449 | 1,9600 | 2,5759 | 2,8771 | 3,2901 |
Численность выборки для бесповторного отбора определяется по формуле
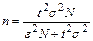 ,
,
где N – численность генеральной совокупности;
s – стандартное (среднее квадратическое) отклонение признака в генеральной совокупности.
Значение дисперсии может быть заимствовано из проводимых ранее обследований данной или аналогичной совокупности, а если таковых нет, проводится специальное выборочное обследование небольшого объема.
В рассматриваемом случае численность выборки должна быть равна
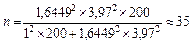
т. е. для обеспечения заданной точности необходимо иметь 35 наблюдений.
Задания
Задание 1. Какой должна быть численность выборки для нахождения средней себестоимости 1 т прироста крупного рогатого скота по 350 сельскохозяйственным организациям региона, ошибка которой не должна превышать 0,3 млн. рублей с вероятностью 75%. Стандартное отклонение признака – 2,1 млн. рублей.
Задание 2. Определите численность выборки для расчета удоя на среднегодовую корову в 200 сельскохозяйственных организациям региона, если необходимо, чтобы ошибка не превышала 100 кг с вероятностью 90%. Стандартное отклонение признака – 653 кг.
Задание 3. Сколько сельскохозяйственных организаций из 350 необходимо обследовать, чтобы определить среднюю себестоимость производства 1 т зерна, ошибка которой не будет превышать 15 тыс. рублей с вероятностью 75%. Стандартное отклонение признака – 76,5 тыс. рублей.
Задание 4. Определите численность выборки для нахождения среднего значения среднесуточного прироста свиней по 190 сельскохозяйственным организациям региона, ошибка которого не будет превышать 20 г с вероятностью 75%. Стандартное отклонение признака – 116 г.
Дата: 2018-12-21, просмотров: 456.