Якщо популяція містить періодичний тренд, наприклад, звичайну синусоїду, то ефективність систематичної вибірки залежить від значення 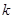 . Це можна наочно побачити на рис. 1.5.1. Висота кривої на ньому відповідає спостереженню
. Це можна наочно побачити на рис. 1.5.1. Висота кривої на ньому відповідає спостереженню 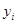 .
.
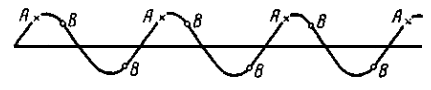
Рис.1.5.1. Періодична варіація
Вибіркові точки 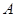 представляють найменш сприятливий для систематичної вибірки випадок. Він має місце, якщо
представляють найменш сприятливий для систематичної вибірки випадок. Він має місце, якщо 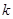 дорівнює періоду синусоїди або цілому числу, яке кратне цьому періоду. Кожне спостереження в систематичній вибірці буде однаковим, тому вибірка не буде більш точною, ніж одиничне спостереження, добуте з популяції навмання.
дорівнює періоду синусоїди або цілому числу, яке кратне цьому періоду. Кожне спостереження в систематичній вибірці буде однаковим, тому вибірка не буде більш точною, ніж одиничне спостереження, добуте з популяції навмання.
Найбільш сприятливим буде випадок (вибірка 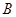 ), коли
), коли 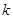 - непарне число, яке кратне напівперіоду. Середнє значення кожної систематичної вибірки буде в точності дорівнювати середньому для популяції, оскільки відхилення вверх або вниз від прямої на рис. 1.5.1 взаємно урівноважаться. Отже, дисперсія середнього вибірки буде дорівнювати нулю. У проміжках між цими двома випадками ефективність вибірки буде залежати від співвідношення між та довжиною хвилі.
- непарне число, яке кратне напівперіоду. Середнє значення кожної систематичної вибірки буде в точності дорівнювати середньому для популяції, оскільки відхилення вверх або вниз від прямої на рис. 1.5.1 взаємно урівноважаться. Отже, дисперсія середнього вибірки буде дорівнювати нулю. У проміжках між цими двома випадками ефективність вибірки буде залежати від співвідношення між та довжиною хвилі.
Популяції, які можна описати точною синусоїдою, на практиці, не зустрічаються. Однак популяції з більш або менш вираженим періодичним трендом − не рідкість. Прикладами можуть бути транспортний потік на певній ділянці дороги на протязі доби та об’єм продаж у магазині на протязі семи днів тижня. Для оцінювання середнього за деякий період часу було б, очевидно, не доцільно формувати систематичну вибірку, роблячи спостереження щоденно о 4 годині дня кожний четвер. Навпроти, потрібно розосереджувати вибірку вздовж періодичної кривої, у випадку продаж, наприклад, слідкуючи за тим, щоб кожний день тижня був однаково представлений у вибірці.
У деяких популяціях зустрічаються менш помітні періодичні коливання. Наприклад, якщо є ряд щоденних платіжних відомостей для невеликої ділянки підприємства, то список робітників у кожній з них може бути складений у одному й тому ж порядку та містити від 19 до 23 прізвищ. Тоді систематична вибірка кожного 20-го робітника за період декількох тижнів може включати записи, які відносяться до одного і того ж робітника або до двох чи до трьох робітників, що належать до найбільш високооплачуваної групи. Аналогічно систематична вибірка прізвищ з міського довідника, де під однаковим прізвищем, спочатку, значиться голова домогосподарства, а потім його діти, може містити дуже багато голів домогосподарств чи дуже багато дітей. Якщо часу вистачає, щоб дослідити характер періодичності, то систематичну вибірку можна побудувати так, щоб скористатися її особливостями. В супротивному разі, коли періодичність передбачається, але характер її невідомий, краще застосовувати просту або стратифіковану випадкову вибірку.
Автокорельовані популяції
Для багатьох реальних популяцій є підстави очікувати, що два спостереження 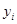 та
та 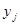 будуть більш схожими, якщо одиниці
будуть більш схожими, якщо одиниці 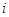 та
та 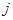 розташовані в ряді недалеко одна від одної. Таке буває, коли будь-які природні причини обумовлюють повільну зміну значень при просуванні вздовж ряду. В математичній моделі такої ситуації можна вважати, що між та
розташовані в ряді недалеко одна від одної. Таке буває, коли будь-які природні причини обумовлюють повільну зміну значень при просуванні вздовж ряду. В математичній моделі такої ситуації можна вважати, що між та 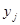 існує додатна кореляція, яка залежить тільки від відстані між ними,
існує додатна кореляція, яка залежить тільки від відстані між ними, 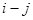 , та прямує до нуля при збільшенні цієї відстані.
, та прямує до нуля при збільшенні цієї відстані.
Для з’ясування того, чи можна застосовувати цю модель до конкретної популяції, можна обчислити коефіцієнти кореляції 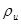 між парами спостережень, що знаходяться на відстані
між парами спостережень, що знаходяться на відстані 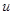 одиниць одне від одного, та побудувати графік відповідних значень як функції
одиниць одне від одного, та побудувати графік відповідних значень як функції 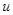 . Цей графік, чи функція, яку він представляє, називається корелограмою. Навіть якщо модель можна застосовувати до будь-якої скінченої популяції, корелограма для неї не буде гладкою функцією через неправильності, обумовлені скінченим характером популяції. При порівнянні систематичного та стратифікованого випадкового відборів із популяцій, що описуються моделлю, ці неправильності ускладнюють отримання результатів для будь-якої скінченої популяції. Таке порівняння можна провести, якщо розглядати середнє з цілого ряду популяцій, отриманих навмання з деякої нескінченої надпопуляції, до якої можна застосувати цю модель. Такий прийом вже застосовувався в теоремі 1.3.2.
. Цей графік, чи функція, яку він представляє, називається корелограмою. Навіть якщо модель можна застосовувати до будь-якої скінченої популяції, корелограма для неї не буде гладкою функцією через неправильності, обумовлені скінченим характером популяції. При порівнянні систематичного та стратифікованого випадкового відборів із популяцій, що описуються моделлю, ці неправильності ускладнюють отримання результатів для будь-якої скінченої популяції. Таке порівняння можна провести, якщо розглядати середнє з цілого ряду популяцій, отриманих навмання з деякої нескінченої надпопуляції, до якої можна застосувати цю модель. Такий прийом вже застосовувався в теоремі 1.3.2.
Отже, ми припускаємо, що спостереження 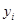
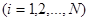 вилучені з над популяції, для якої
вилучені з над популяції, для якої
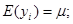
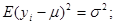
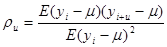 (1.6.1)
(1.6.1)
де
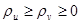 при довільних
при довільних 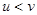 .
.
Здобуття одного набору значень з цієї надпопуляції призводить до утворення деякої скінченої популяції обсягом 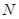 .
.
Середня дисперсія по всім скінченим популяціям при систематичному відборі позначається через
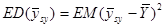 .
.
Для цього класу популяцій неважко показати, що стратифікований випадковий відбір краще простого випадкового відбору, але відносно систематичного відбору загального твердження сформулювати не можна. Всередині цього класу існують надпопуляції, для яких систематичний відбір краще стратифікованого випадкового відбору, але існують і такі, для яких, при певних значеннях 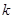 , систематичний відбір поступається стратифікованому випадковому відбору.
, систематичний відбір поступається стратифікованому випадковому відбору.
Якщо припустити, що корелограма є випуклою вниз функцією, то можна довести одну загальну теорему.
Теорема 1.6.1. Якщо, разом з умовами (1.6.1), виконується
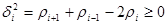 ,
, 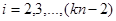 ,
,
то при будь якому обсязі вибірки
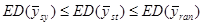 .
.
Далі, за винятком випадку 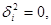 , виконується
, виконується
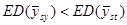 .
.
Теорема 1.6.1 була доведена Кокреном у 1946 році.
Наведемо частину доведення при 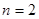 , яка показує, яку роль відіграє умова випуклості вгору. Члени пари, які утворюють систематичну вибірку, завжди відстоять один від одного на
, яка показує, яку роль відіграє умова випуклості вгору. Члени пари, які утворюють систематичну вибірку, завжди відстоять один від одного на 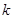 одиниць. Отже,
одиниць. Отже,
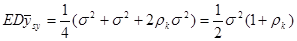 .
.
У випадку стратифікованої вибірки для кожної одиниці, що вилучається з відповідної страти, існує можливих місць, що утворюють 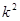 можливих комбінацій розташування вибірки. Числа комбінацій, для яких відстань між одиницями складає
можливих комбінацій розташування вибірки. Числа комбінацій, для яких відстань між одиницями складає 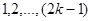 , будуть такими:
, будуть такими:
| Відстань | 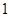 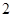  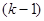 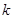 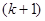 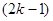
| Підсумок |
| Число комбінацій | 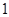 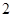 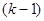 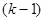 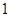
| 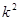
|
Отже, середнє значення 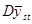 , яке береться по всім
, яке береться по всім 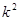 комбінаціям, може бути подане у вигляді
комбінаціям, може бути подане у вигляді
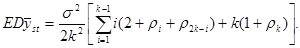
Аналогічно 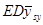 можна виразити у вигляді
можна виразити у вигляді
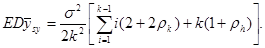
Отже,
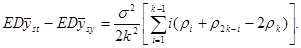
Якщо
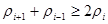
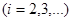 ,
,
то неважко показати, що кожний член всередині дужок додатний. Теорема доведена.
Середня відстань між одиницями дорівнює як для систематичної вибірки, так і для стратифікованої вибірки, але завдяки умові випуклості стратифікована вибірка більш програє у точності, коли відстань між одиницями менше , ніж виграє, коли ця відстань більше .
В 1949 році Кенуй показав, що нерівності, які містяться у твердженні теореми 1.6.1, залишаються справедливими, якщо зробити менш жорсткими дві умови (1.6.1), а саме
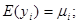
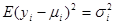 .
.
В цьому випадку кожна з трьох середніх дисперсій для надпопуляції збільшується в однаковому ступені.
Реальні популяції
Дослідження були проведені для різних реальних популяцій. Деякі з цих досліджень наведені в таблиці 1.7.1. Перші три дослідження проводилися за допомогою географічних мап. У першому з них популяція складається з 288 значень висот точок, які знаходяться на відстані 0,1 милі одна від одної у гірській місцевості.
У двох наступних популяціях даними є долі довжин відрізків прямих, які проведені на мапі з розфарбуванням, що приходяться на області з визначеним покриттям (під травою, лісом і т.п.). Ці приклади можна вважати найбільш близькими до моделей з неперервною у строгому сенсі варіацією.
Наступні три дослідження засновані на показах температури на протязі 192 послідовних днів у наступних точках: (а) 12 дюймів під поверхнею трави, (б) 4 дюйма під поверхнею землі, (в) у повітрі. Ці три дослідження відображають три різних ступені впливу (у напрямку збільшення) на характеристику, що вивчаються, а саме - нестійкі щоденні зміни погоди та повільні сезонні зміни.
У останніх дослідженнях спостерігались рослини або дерева, що ростуть у послідовних точках, які розташовані вздовж деякої лінії. При обстеженні картоплі, типовою для цієї групи, скінчена популяція складається зі значень врожаю на 96 грядках деякого поля.
У деяких обстеженнях 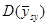 порівнювали з
порівнювали з 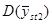 для стратифікованої випадкової вибірки з об’ємом страт
для стратифікованої випадкової вибірки з об’ємом страт 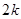 і двома одиницями у кожній страті. Таке порівняння є цікавим, оскільки за даними вибірки можна дістати незміщену оцінку . Для
і двома одиницями у кожній страті. Таке порівняння є цікавим, оскільки за даними вибірки можна дістати незміщену оцінку . Для 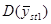 (з об’ємом страти і однією одиницею у кожній страті) або для
(з об’ємом страти і однією одиницею у кожній страті) або для 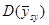 її отримати неможна. У більшості джерел безпосереднє порівняння з
її отримати неможна. У більшості джерел безпосереднє порівняння з 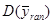 у явному вигляді не проводиться, але взагалі
у явному вигляді не проводиться, але взагалі 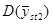 дає виграш у точності у порівнянні з
дає виграш у точності у порівнянні з 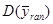 .
.
У роботах Йетса та Фінні порівняння проводиться відносно цілої низки значень 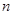 та для кожної скінченої популяції.
та для кожної скінченої популяції.
Таблиця 1.7.1 Реальні популяції, що вивчені при аналізі систематичного відбору
| Автор | Обсяг популяції
| Вид даних |
| Yates (1948) | 288 | Значення висот у точках, що знаходяться на відстані 0,1 милі одна від одної, отримані за мапою англійського державного картографічного управління |
| Osborne (1942) | * | Відсоток площі під (а) оброблюваною землею, (б) чагарником, (в) травою, (г) лісом на паралельних прямих, які проведені на мапі з розфарбуванням |
| Osborne (1942) | * | Відсоток площі під ялиною Дугласа, який підрахований за допомогою паралельних прямих, що проведені на мапі з розфарбуванням |
| Yates (1948) | 192 | Температура ґрунту (12 дюймів під поверхнею трави) на протязі 192 послідовних днів |
| Yates (1948) | 192 | Температура ґрунту (4 дюймів під поверхнею землі) на протязі 192 послідовних днів |
| Yates (1948) | 192 | Температура повітря на протязі 192 послідовних днів |
| Yates (1948) | 96 | Врожай картоплі на 96 грядках |
| Finney (1948) | 160 | Об’єм лісу, придатного до продажу, у розрахунку на ділянку шириною у 3 ряди та змінної довжини (Mt. Stuart forest) |
| Finney (1948) | 288 | Об’єм підростаючого лісу на ділянку шириною у 2,5 ряди та довжиною у 80 рядів (Black’s Mountain forest) |
| Finney (1950) | 292 | Об’єм лісу на ділянку шириною в 2 ряди та змінної довжини (Dehra Dun forest) |
| Johnson (1943) | 400** | Число саджанців на 1 фут довжини гряди для 4 гряд саджанців листяних порід |
| Johnson (1943) | 400** | Число саджанців на 1 фут довжини гряди для 3 гряд саджанців хвойних порід |
| Johnson (1943) | 400** | Число пересаджених дерев хвойних порід на 1 фут довжини гряди для 6 гряд |
* Теоретично нескінчене, якщо вважати, що товщина прямих нескінченно мала
** Наближено. Насправді це число змінювалось від гряди до гряди.
Для цих випадків дані таблиці 1.7.2 є геометричним середнім відношень дисперсій для окремих значень . Інші автори проводили порівняння тільки для одного значення у кожній популяції, але іноді приводили данні для різних ознак або декількох реальних популяцій одного і того ж характеру. При цьому знову бралось геометричне середнє з відношень дисперсій.
Таблиця 1.7.2 Відносна точність систематичного та стратифікованого випадкового відбору
| Данні | Розмах значень
| Відносна точність систематичного відбору в порівнянні зі стратифікованим відбором | |
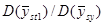
| 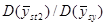
| ||
| Висоти | 2 − 20 | 2,99 | 5,68 |
| Відсоток площі (4 типів покриття) | − | − | 4,42 |
| Відсоток площі під ялиною Дугласа | − | − | 1,83 |
| Температура ґрунту (12 дюймів) | 2 − 24 | 2,42 | 4,23 |
| Температура ґрунту (4 дюйма) | 4 − 24 | 1,45 | 2,07 |
| Температура повітря | 4 − 24 | 1,26 | 1,65 |
| Картопля | 3 − 16 | 1,37 | 1,90 |
| Об’єм лісу (Mt. Stuart) | 2 − 32 | 1,07 | 1,35 |
| Об’єм лісу (Black’s Mt) | 2 − 24 | 1,19 | 1,44 |
| Об’єм лісу (Dehra Dun) | 2 − 32 | 1,39 | 1,89 |
| Листяні саджанці | 14 | − | 1,89 |
| Хвойні саджанці | 14 − 24 | − | 2,22 |
| Пересадженні хвойні дерева | 12 − 22 | − | 0,93 |
Хоча ці данні обмежені за масштабами, результати справляють враження. В тих дослідженнях, де можливе порівняння з , систематична вибірка незмінно дає, хоча і помірний, але цілком відчутний виграш у точності. Медіанне значення відношень 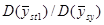 дорівнює 1,4. Виграш у точності у порівнянні з
дорівнює 1,4. Виграш у точності у порівнянні з 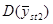 суттєвіший, тут медіанне значення відношень дорівнює 1,9. Характер знайдених результатів взагалі відповідає очікуваному, хоча зважаючи на невелику кількість обстежень важко було розраховувати на отримання певних висновків. Виграш виявився найбільшим для тих видів даних, відносно яких можна було припустити, що їхня варіація найбільш близька до неперервної. З цієї точки зору і при переході від ґрунтових температур до температур повітря можна було очікувати, що відношення
суттєвіший, тут медіанне значення відношень дорівнює 1,9. Характер знайдених результатів взагалі відповідає очікуваному, хоча зважаючи на невелику кількість обстежень важко було розраховувати на отримання певних висновків. Виграш виявився найбільшим для тих видів даних, відносно яких можна було припустити, що їхня варіація найбільш близька до неперервної. З цієї точки зору і при переході від ґрунтових температур до температур повітря можна було очікувати, що відношення 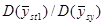 зменшиться. З останніх трьох ознак (дані про лісові розсадники) виграшу у точності не виявилось лише для одного − пересаджених хвойних дерев
зменшиться. З останніх трьох ознак (дані про лісові розсадники) виграшу у точності не виявилось лише для одного − пересаджених хвойних дерев 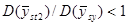 , які старіші й більш однорідні, ніж молоді саджанці.
, які старіші й більш однорідні, ніж молоді саджанці.
Дата: 2019-07-24, просмотров: 355.