Алгоритм прямого включення можна значно покращити, якщо врахувати, що "готова" послідовність є вже впорядкованою. Тому можна скористатися бінарним пошуком точки включення в "готову" послідовність. Програмна реалізація такого модифікованого методу включення матиме вигляд процедури:
Procedure Binary_Insertion;
Var
i, j, m, L, R : integer; x : basetype;
Begin
for i:=2 to N do
Begin
x:=a[i]; L:=1; R:=i;
while L<R do
Begin
m:=(L+R) div 2;
if a[m]<=x then L:=m+1 else R:=m
end;
for j:=i downto R+1 do
a[j]:=a[j-1];
a[R]:=x
End
End ;
Аналіз бінарного включення. Зрозуміло, що кількість порівнянь у такому алгоритмі фактично не залежить від початкового порядку елементів. Місце включення знайдено, якщо L=R. Отже вкінці пошуку інтервал повинен бути одиничної довжини. Таким чином ділення його пополам на i-ому етапі здійснюється log(i) раз. Тому кількість операцій порівняння буде:
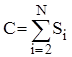 , де
, де 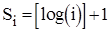 ,
, 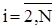 .
.
Апроксимуючи цю суму інтегралом, отримаємо наступну оцінку :
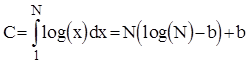 , де
, де 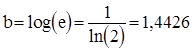 .
.
Однак істинна кількість порівнянь на кожному етапі може бути більшою ніж log(i) на 1. Тому
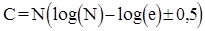 .
.
Нажаль покращення, що породженні введенням бінарного пошуку, стосується лише кількості операцій порівняння, а не кількості потрібних переміщень елементів. Фактично кількість перестановок M залишається величиною порядку N2. Для досить швидких сучасних ЕОМ рух елемента, тобто самого ключа і зв’язаної з ним інформації, займає значно більше часу, ніж порівняння самих ключів. Крім того сортування розглядуваним методом вже впорядкованого масиву за рахунок log(i) операцій порівняння вимагатиме більше часу, ніж у випадку послідовного сортування з прямим включенням. Очевидно, що кращий результат дадуть алгоритми, де перестановка, нехай і на велику відстань, буде пов’язана лише з одним елементом, а не з переміщенням на одну позицію цілої групи.
Сортування прямим вибором
На відміну від включення, коли для чергового елемента відшукувалося відповідне місце в "готовій" послідовності, в основу цього методу покладено вибір відповідного елемента для певної позиції в масиві. Цей прийом базується на таких принципах :
1) на i-ому етапі серед елементів a i , a i+1 , ..., a N вибирається елемент з найменшим ключем a min ; 2) проводиться обмін місцями a min та a i .
Процес послідовного вибору і перестановки проводиться поки не залишиться один єдиний елемент - з самим найбільшим ключем.
Такий алгоритм можна записати у вигляді послідовності команд :
for i:=1 to N-1 do
Begin
k:=номер найменшого ключа серед a[i], ..., a[N];
обмін місцями a[k] та a[i]
End;
А програмна реалізація методу прямого вибору матиме вигляд процедури
Procedure Straight_Selection;
Var
i, j, k : integer; x : basetype;
Begin
for i:=1 to N-1 do
Begin
x:=a[i]; k:=i;
for j:=i+1 to N do
if a[j]<x then begin x:=a[j]; k:=j end;
x:=a[k]; a[k]:=a[i]; a[i]:=x
End
End;
Аналіз прямого вибору. Очевидно, що кількість порівнянь ключів Ci на i-ому виборі не залежить від початкового розміщення елементів і дорівнює N- i. Таким чином
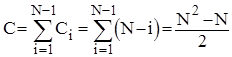
Кількість же перестановок залежить від стартової впорядкованості масиву. Це стосується переприсвоєнь у внутрішньому циклі по j при пошуку найменшого ключа.
В найкращому випадку початково впорядкованого масиву Mi=4 ; в найгіршому випадку зворотно впорядкованого масиву Mi=Ci+4 ; для довільного масиву рівномовірно можливе значення Mi=Ci/2+4. Тому для оцінки ефективності алгоритму по перестановках можна скористатися наступними співвідношеннями:
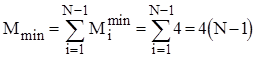 ;
;
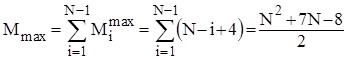 ;
;
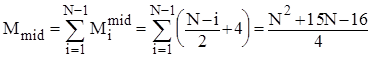 .
.
Як і в попередньому випадку алгоритм прямого вибору описує процес стійкого сортування.
Сортування прямим обміном
Даний метод базується на повторенні етапів порівняння сусідніх ключів при русі вздовж масиву. Якщо наступний елемент виявиться меншим від попереднього, то відбувається обмін (звідси і назва методу). Таким чином, при русі з права наліво за один етап найменший ключ переноситься на початок масиву. Зрозуміло, що кожен наступний прохід можна закінчувати після позиції знайденого на попередньому етапі мінімального елемента, оскільки всі елементи перед ним вже впорядковані. Розглядуваний процес дещо нагадує виштовхування силою Архімеда бульбашки повітря у воді. Тому цей алгоритм ще називають "бульбашковим" сортуванням.
Програмна реалізація методу прямого обміну або "бульбашки" матиме вигляд процедури:
Procedure Buble_Sort;
Var
i, j : integer; x : basetype;
Begin
for i:=2 to N do
for j:=N downto i do
if a[j-1]>a[j] then begin x:=a[j]; a[j]:=a[j-1]; a[j-1]:=x end
End;
Якщо етапи порівняння та обміну проводити зліва направо, то відбуватиметься виштовхування найбільшого елемента вкінець масиву. Очевидно такий процес відповідає опусканню під дією сили тяжіння камінця у воді. Назвемо цей алгоритм "камінцевим" сортуванням :
Procedure Stone_Sort;
Var
i, j : integer; x : basetype;
Begin
for i:=1 to N-1 do
for j:=1 to N-i do
if a[j]>a[j+1] then begin x:=a[j]; a[j]:=a[j+1]; a[j+1]:=x end
End;
Обидва алгоритми згідно із визначаючим принципом вимагають досить великої кількості обмінів. Тому виникає питання, чи не вдасться підвищити їх ефективність хоча б за рахунок зменшення операцій порівняння? Цього можна добитися при допомозі наступних покращень:
1) фіксувати, чи були перестановки в процесі деякого етапу. Якщо ні, то - кінець алгоритму ;
2) фіксувати крім факту обміну ще і положення (індекс) останнього обміну. Очевидно, що всі елементи перед ним або після нього відповідно для сортування "бульбашкою" або "камінцем" будуть впорядковані ;
3) почергово використовувати алгоритми "бульбашки" і "камінця". Тому що для чистої "бульбашки" за один прохід "легкий" елемент виштовхується на своє місце, а "важкий" опускається лише на один рівень. Аналогічна ситуація з точністю до навпаки і для "камінця". Такий алгоритм називається "шейкерним" сортуванням.
Читачу пропонується самостійно модифікувати наведені вище процедури з врахуванням цих покращень.
Аналіз прямого обміну. Розглянемо спочатку чисту "бульбашку". Для "камінця" оцінки будуть такими ж самими. Зрозуміло, що кількість порівнянь ключів Ci на i-ому проході не залежить від початкового розміщення елементів і дорівнює N-i. Таким чином
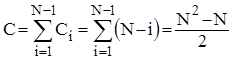
Кількість же перестановок залежить від стартової впорядкованості масиву. В найкращому випадку початково впорядкованого масиву Mi=0 ; в найгіршому випадку зворотньо впорядкованого масиву Mi=Ci*3; для довільного масиву рівноймовірно можливе значення Mi=Ci*3/2. Тому для оцінки ефективності алгоритму по перестановках можна скористатися наступними співвідношеннями:
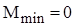 ;
;
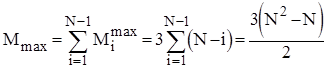 ;
;
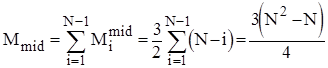 .
.
Очевидно, що і цей алгоритм, аналогічно з іншими прямими методами, описує процес стійкого сортування.
Розглянемо тепер покращений варіант "шейкерного" сортування. Для цього алгоритму характерна залежність кількості операцій порівняння від початкового розміщення елементів в масиві. В найкращому випадку вже впорядкованої послідовності ця величина буде 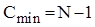 . У випадку зворотньо впорядкованого масиву вона співпадатиме з ефективністю для чистої "бульбашки".
. У випадку зворотньо впорядкованого масиву вона співпадатиме з ефективністю для чистої "бульбашки".
Як видно, всі покращення не змінюють кількості переміщень елементів (переприсвоєнь), а лише зменшують кількість повторюваних порівнянь. На жаль операція обміну місцями елементів в пам’яті є "дорожчою" ніж порівняння ключів. Тому очікуваного виграшу буде небагато. Таким чином "шейкерне" сортування вигідне у випадках, коли відомо, що елементи майже впорядковані. А це буває досить рідко.
Дата: 2019-05-28, просмотров: 536.