Все микропроцессоры можно разделить на следующие группы:
- МП с гарвардской архитектурой;
- МП с фоннеймановской архитектурой;
- МП типа CISC (Complex Instruction Set Computing) с полным на-
бором команд;
- МП типа RISC (Reduced Instruction Set Computing) с сокращен-
ным набором команд;
- МП типа MISC (Minimum Instruction Set Computing) с минималь-
ным набором команд и весьма высоким быстродействием (в настоящее
время эти модели находятся в стадии разработки).
По числу и типу команд микропроцессоры бывают с CISC –архитек-турой и с RISC-архитектурой. CISC-процессоры – это микропроцессоры с полным набором команд. Как правило, CISC-процессорами являются универсальные микропроцессоры. Объясняется это тем, что универсальные микропроцессоры используются для решения широкого круга задач. А значит необходимо, чтобы как можно большее количество операций поддерживалось на аппаратном уровне соответствующими командами. Поскольку различные по сложности операции требуют для своего выполнения различного времени, то для CISC-процессоров характерно, что разные их команды выполняются в течение разного времени. Работа микропроцессора синхронизируется сигналами тактового генератора. А значит, разное время выполнения команд можно интерпретировать как разное количество тактов сигналов синхронизации. В специализированных задачах CISC-процессор является функционально избыточным, сложным, дорогим и потребляет неоправданно большую энергию от источника питания. Для многих специализированных задач нет необходимости использовать и разрабатывать микропроцессор с развитой системой команд. Достаточно иметь только те команды, которые нужны для решения данной задачи. Характерно это, например, для микропроцессоров сетевых маршрутизаторов, в задачу которых не входит обработка графики или выполнение каких-либо сложных математических расчетов. Между тем, для них важна скорость обработки запросов от пользователей сети и скорость пересылки больших потоков данных, т.е. выполнение достаточно простых команд пересылки с максимальным быстродействием. Поэтому было предложено создать класс микропроцессоров, имеющих ограниченный набор простых команд, но выполняемых в течение минимально короткого времени, а именно одного такта сигнала синхронизации. Такие микропроцессоры получили название RISC-процессоров. RISC-процессоры – это микропроцессоры с сокращенным набором простых команд. Изначально для них характерна была более простая аппаратная реализация и система команд типа регистр-регистр. Но со временем принцип минимизации времени выполнения команд стали использовать и для достаточно сложных команд путем распараллеливания в микропроцессоре действий по их выполнению. Такой принцип называется конвейеризацией. Согласно этому принципу в микропроцессоре организуются конвейеры, представляющие собой очереди, между которыми обмен осуществляется через буферы. Такая организация позволяет начинать выполнение следующей команды, не дожидаясь результата предыдущей, если для нее результат предыдущей команды не нужен. Поэтому, несмотря на то, что команда может выполняться в течение нескольких тактов, при выполнении нескольких команд «в нахлест» друг на друга в общем потоке команд, среднее время окажется минимальным для отдельной команды. На сегодняшний день в качестве основного отличия CISC- и RISC-процессоров является не уровень сложности и развитости системы команд, а среднее время выполнения на одну команду. В RISC-процессорах оно минимально и по возможности одинаковое для всех команд.
При реализации микропроцессоров традиционно используется два подхода к построению архитектуры:
- Архитектура фон Неймана
- Гарвардская архитектура
В архитектуре фон Неймана применяется однородная память микропроцессора. В эту память могут записываться различные программы. При этом специальная программа-загрузчик работает с ними как с данными. Затем управление может быть передано этим программам и они уже начинают выполнять свой алгоритм. При подобном подходе к управлению микропроцессором удается достигнуть максимальной гибкости микропроцессорной системы.
В качестве недостатка архитектуры фон Неймана можно назвать возможность непреднамеренного нарушения работоспособности системы (программные ошибки) и преднамеренное уничтожение ее работы (вирусные атаки). В Гарвардской архитектуре принципиально различаются два вида памяти микропроцессора:
- Память программ (для хранения инструкций микропроцессора)
- Память данных (для временного хранения и обработки переменных)
В гарвардской архитектуре принципиально невозможно осуществить операцию записи в память программ, что исключает возможность случайного разрушения управляющей программы в случае ошибки программы при работе с данными или атаки третьих лиц. Кроме того, для работы с памятью программ и с памятью данных организуются отдельные шины обмена данными (системные шины), как это показано на рисунке 2.
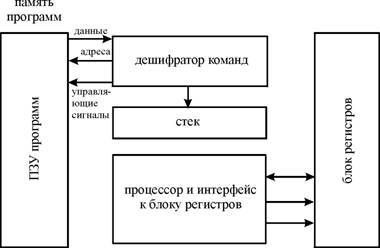
Рисунок 2 - Структурная схема гарвардской архитектуры
Эти особенности определили области применения гарвардской архитектуры. Гарвардская архитектура применяется в микроконтролерах и в сигнальных процессорах , где требуется обеспечить высокую надёжность работы аппаратуры. В сигнальных процессорах Гарвардская архитектура дополняется применением трехшинного операционного блока микропроцессора. Трехшинная архитектура операционного блока позволяет совместить операции считывания двух операндов с записью результата выполнения команды в оперативную память микропроцессора. Это значительно увеличивает производительность сигнального микропроцессора без увеличения его тактовой частоты.
В Гарвардской архитектуре характеристики устройств памяти программ и памяти данных не всегда выполняются одинаковыми. В памяти данных и команд могут различаться разрядность шины данных и распределение адресов памяти. Часто адресные пространства памяти программ и памяти данных выполняют различными. Это приводит к различию разрядности шины адреса для этих видов памяти. В микроконтроллерах память программ обычно реализуется в виде постоянного запоминающего устройства, а память данных — в виде ОЗУ. В сигнальных процессорах память программ вынуждены выполнять в виде ОЗУ. Это связано с более высоким быстродействием оперативного запоминающего устройства, однако при этом в процессе работы осуществляется защита от записи в эту область памяти.
Применение двух системных шин для обращения к памяти программ и памяти данных в гарвадской архитектуре имеет два недостатка — высокую стоимость и большое количество внешних выводов микропроцессора. При использованиии двух шин для передачи команд и данных, микропроцессор должен иметь почти вдвое больше выводов, так как шина адреса и шина данных составляют основную часть выводов микропроцессора. Для уменьшения количества выводов кристалла микропроцессора фирмы-производители микросхем объединили шины данных и шины адреса для внешней памяти данных и программ, оставив только различные сигналы управления (WR, RD, IRQ) а внутри микропроцессора сохранили классическую гарвардскую архитектуру. Такое решение получило название модифицированная гарвардская архитектура.
Модифицированная гарвардская структура применяется в современных микросхемах сигнальных процессоров. Ещё дальше по пути уменьшения стоимости кристалла за счет уменьшения площади, занимаемой системными шинами пошли производители однокристалльных ЭВМ — микроконтроллеров. В этих микросхемах применяется одна системная шина для передачи команд и данных (модифицированная гарвардская архитектура) и внутри кристалла.
По организации структуры микропроцессорных систем различают одно- и многомагистральные микроЭВМ. В одномагистральных микроЭВМ все устройства имеют одинаковый интерфейс и подключены к единой информационной магистрали, по которой передаются коды данных, адресов и управляющих сигналов.
В многомагистральных микроЭВМ устройства группами подклю-
чаются к своей информационной магистрали. Это позволяет осущест-
вить одновременную передачу информационных сигналов по несколь-
ким (или всем) магистралям. Такая организация систем усложняет их
конструкцию, однако увеличивает производительность.
Лекция № 3
| ТЕМА: . Структура микропроцессора 8086. Универсальный процессор 8086, универсальные микропроцессоры ix 86. |
Основные вопросы, рассматриваемые на лекции:
1. Структура микропроцессора 8086
2. Нзначение регистров 8086
3. Работа 8086 в min конфигурации
Рассмотрим назначение и работу отдельных узлов микропроцессора ВМ86. В нем имеется четырнадцать 16-разрядных регистров (вместо семи 8-разрядных регистров в ВМ8О), которые по своему назначению можно разделить на три группы (рис. 1.1, 6). Регистры АХ, ВХ, СХ, DХ образуют группу регистров общего назначения (РОН). Эти регистры могут без ограничений участвовать в выполнении арифметических и логических операций. Некоторые другие операции, например операции над цепочками байтов и слов, предписывают регистрам данной группы специальное использование: АХ — аккумулятор, ВХ — база, СХ Счетчик, ЕХ — данные. В отличие от регистров других групп РОН обладают свойством раздельной адресации старших и младшихбайтов. Поэтому РОН можно рассматривать как совокупность
Двух наборов 8-разрядных регистров: набора Н, содержащего АН, ВН, СН, ОН, и набора содержащего АЕ, СЕ, 1Л. Регистры всех других групп являются неделимыми и оперируют 16-разрядными словами, даже в случае использования только старшего или младшего байта.Регистры SР, ВР, Si и DI образуют группу указательных и индексных регистров, назначение которых заключается в том, что они содержат значения смещений, используемых для адресации в пределах текущего сегмента памяти. При этом регистры-указатели SР и ВР хранят смещения адреса в пределах текущего сегмента памяти, выделенного под стек, а индексные регистры SI и DI содержат смещения адреса в пределах текущего сегмента памяти, выделенного под данные. С этим связаны и обозначения регистров: SР — указатель стека, ВР — указатель базы, SI — индекс источника и DI — индекс места назначения. Регистры этой группы могут использоваться и как регистры общего назначения.
Регистры СS, DS, SS и ЕS, образующие группу сегментных регистров, играют важную роль во всех действиях ЦП, связанных с адресацией памяти. Обозначения регистров расшифровываются следующим образом: СS — кодовый или программный сегмент, ЕS — сегмент данных, SS — стековый сегмент и ЕS — Дополнительный сегмент. Содержимое любого из этих регистров определяет текущий начальный адрес сегмента памяти, выделенного пользователем под информацию, соответствующую названию регистра.
Содержимое регистра СS определяет начальный адрес сегмента памяти, в котором располагается объектный код программы. Выборка очередной команды осуществляется относительно содержимого СS с использованием значения указателя команд IP. Содержимое регистра CS определяет начальный адрес текущего сегмента данных, так что обращение к данным в памяти ЦП осуществляет относительно содержимого DS. Для обращения к другим трем сегментам: дополнительному, стековому или программному — используется специальный указатель, который называется префиксом замены сегмента и располагается в соответствующих командах.
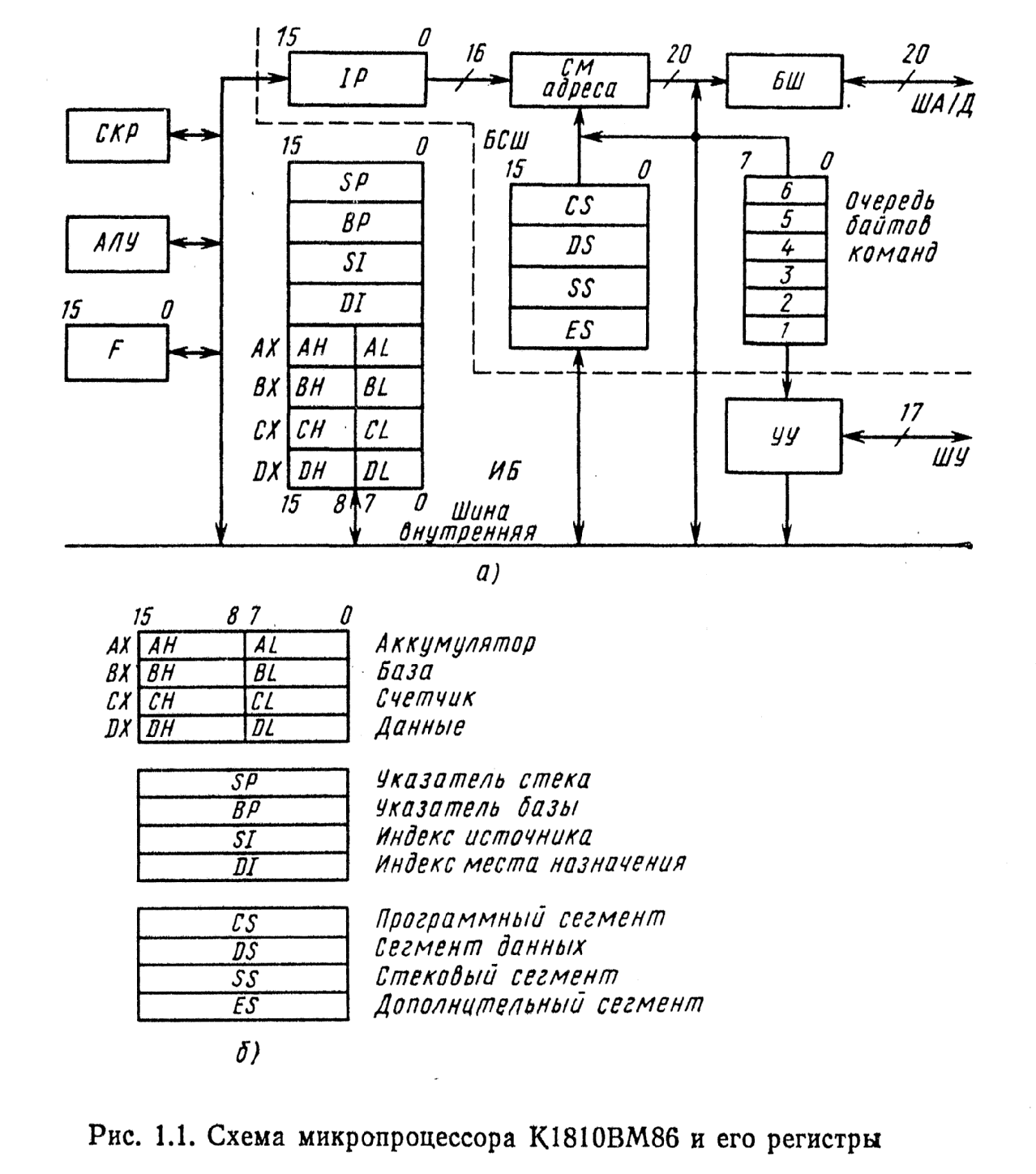
Рисунок 3.1 – Структура 8086 и его регистры
Содержимое регистра SS определяет текущий сегмент, выделенный для организации стека. Все обращения к памяти, при которых для вычисления адреса прямо или косвенно используются регистры BP или SР, осуществляются относительно содержимого регистра SS. К таким обращениям относятся, например, все операции со стеком, включая и те, которые связаны с операциями вызова подпрограмм, прерываниями и операциями возврата. Обращения к данным, использующие регистр ВР (но не SР) , могут производиться также и относительно одного из трех других сегментных регистров путем использования префикса замены сегмента.
Содержимое регистра ЕS определяет начальный адрес сегмента, рассматриваемого как дополнительный сегмент данных. В частности, обращения к данным в операциях с цепочками байтов или слов осуществляются относительно ЕS, а в качестве смещения берется содержимое DI.
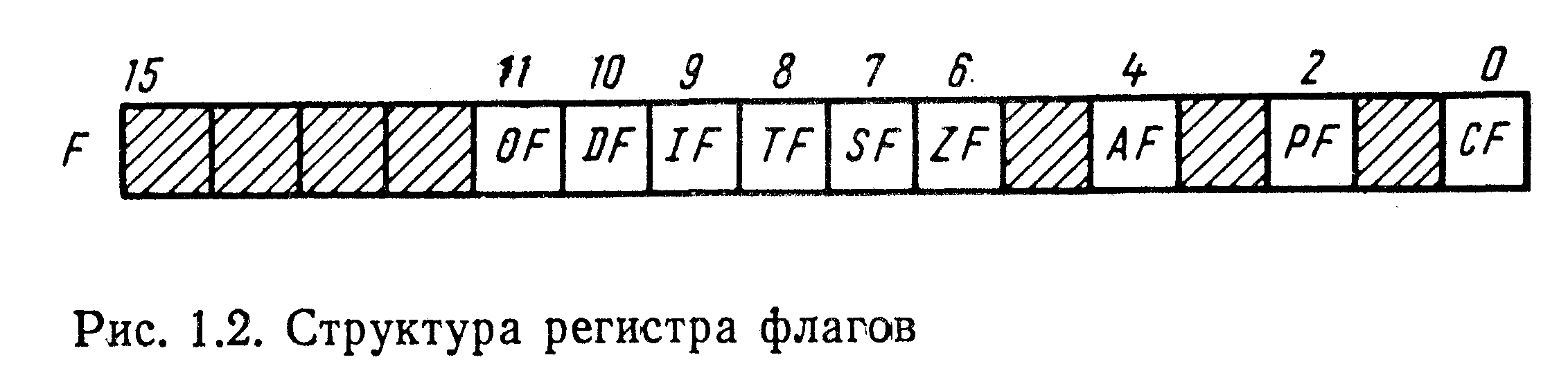
Рисунок 3.2 – Регистр флагов
Кроме перечисленных регистров имеются два 16-разрядных регистра: IР — указатель команд; F — регистр флагов. В регистре IР формируется относительный (относительно СS) адрес команды, подлежащей исполнению. В регистре F (рис. 1.2) используются следующие девять разрядов: СF — перенос, РF — четность, АF — вспомогательный перенос, ZF — нулевой результат, SF — знак, ТF — пошаговый режим, IЕ — разрешение прерывания, DF — направление, OF — переполнение. Неиспользованные разряды на рисунке заштрихованы.
Флаги AF, CF, PF, SF и ZF эквивалентны соответствующим флагам ВМ80 и характеризуют признаки результата последней арифметической, логической или иной операции, влияющей на эти флаги. Установка того или другого флага производится в следующих случаях:
АF — при выполнении операции производится перенос “1” из младшей тетрады байта в старшую или осуществляется заем “1” из старшей тетрады;
СF— при переносе “1” из старшего бита байта (слова) или при займе единицы в старший бит;
PF — если в представлении результата операции содержится четное число единиц;
SF—при получении в старшем бите результата;
ZF — если в результате выполнения операции получено нулевое значение.
К этой группе флагов относится также флаг OF (отсутствующий у ВМ8О), который устанавливается при наличии переполнения в результате выполнения арифметических операций над числами со знаком.
Флаги DF, IF и TF используются для управления работой процессора. Флаг DF управляет направлением обработки данных в операциях с цепочками байтов или слов. При DF = 1 цепочка обрабатывается снизу вверх, т. е. происходит автоматическое уменьшение (автодекремент) адреса текущего элемента цепочки. При DF = 0 цепочка обрабатывается сверху вниз, т.е. происходит автоматическое увеличение (автоинкремент) адреса.
Флаг IF предназначается для разрешения или запрещения (маскирования) внешних прерываний. При IF = 0 внешние прерывания запрещены, т.е. процессор не реагирует на их запросы.
Флаг ТF применяется для задания процессору пошагового режима, при котором процесор после выполнения каждой команды останавливается и ждет внешнего запуска. Пошаговый режим задается установкой флага ТF = 1 и обычно необходим при отладке программ.
Как отмечалось выше, разрядность адресов микропроцессора равна 20. Однако для упрощения операций хранения и пересылки адресной информации процессор манипулирует 16-разрядными логическими адресами, к которым относятся начальные (базовые) адреса сегментов памяти и значения смещений в этих сегментах. Логические адреса используются для вычисления 20-разрядных физических (абсолютных) адресов с помощью следующей процедуры. Содержимое каждого сегментного регистра рассматривается как 16 старших разрядов А19—А4 начального адреса соответствующего сегмента. Младшие разряды А3—А0 этого адреса всегда полагаются равными нулю и поэтому не запоминаются в регистрах, а приписываются справа к старшим разрядам во время операции вычисления физических адресов. Эта операция выполняется сумматором СМ адреса, расположенным в блоке БСШ, и состоит в сложении 20-разрядного начального адреса сегмента с 16-разрядным смещением, которое дополняется четырьмя старшими разрядами А19—А16, равными нулю, как показано на рис. 1.3. Сумматор адресов осуществляет, например, следующие вычисления: СS+IР — при выборке очередной команды, SS+SР — при обращении к стеку, DS+SI и ЕS+DI — при обработке строк, DS+ЕА—при обращении к запоминающему устройству с произвольной выборкой (ЕА — исполнительный адрес, формирование которого описано ниже).
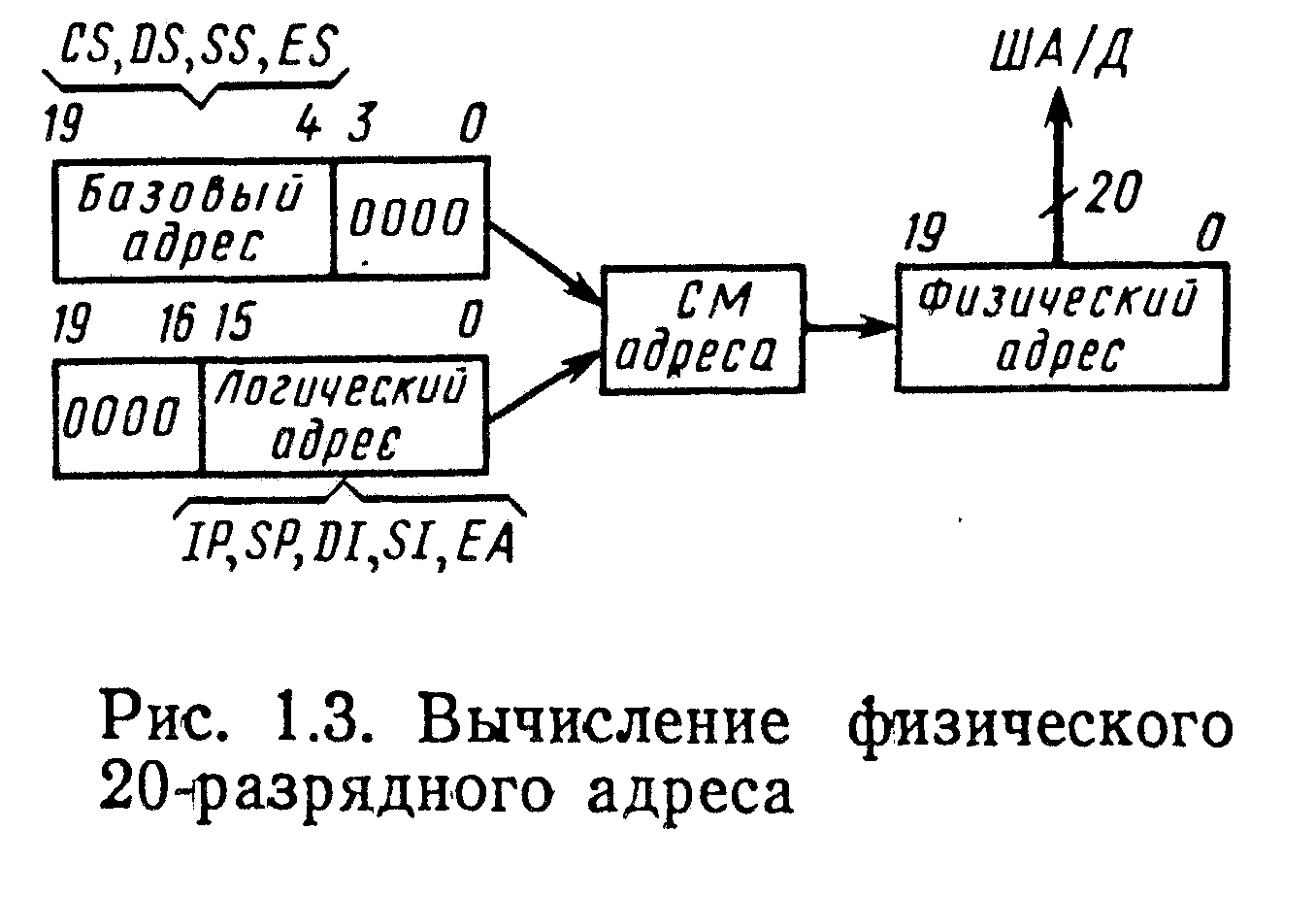
Рисунок 3.3 – Вычисление 20- разрядного физического адреса.
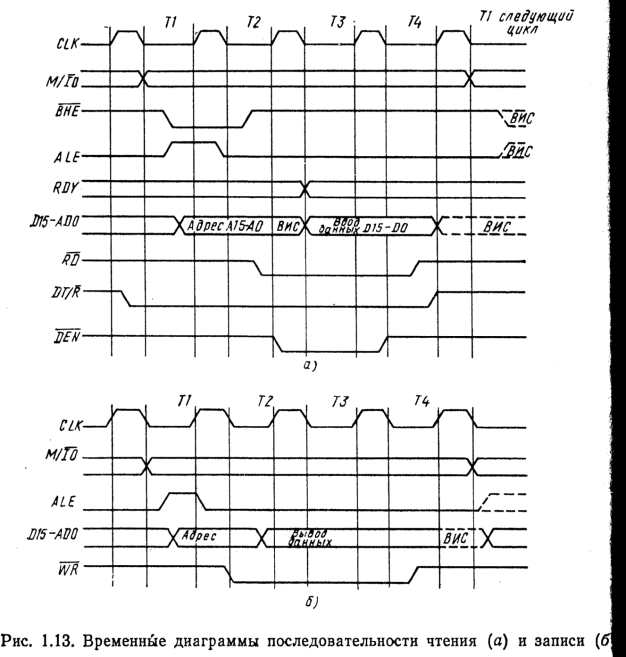
Рисунок 1.3 – Временные диаграммы циклов чтения/записи
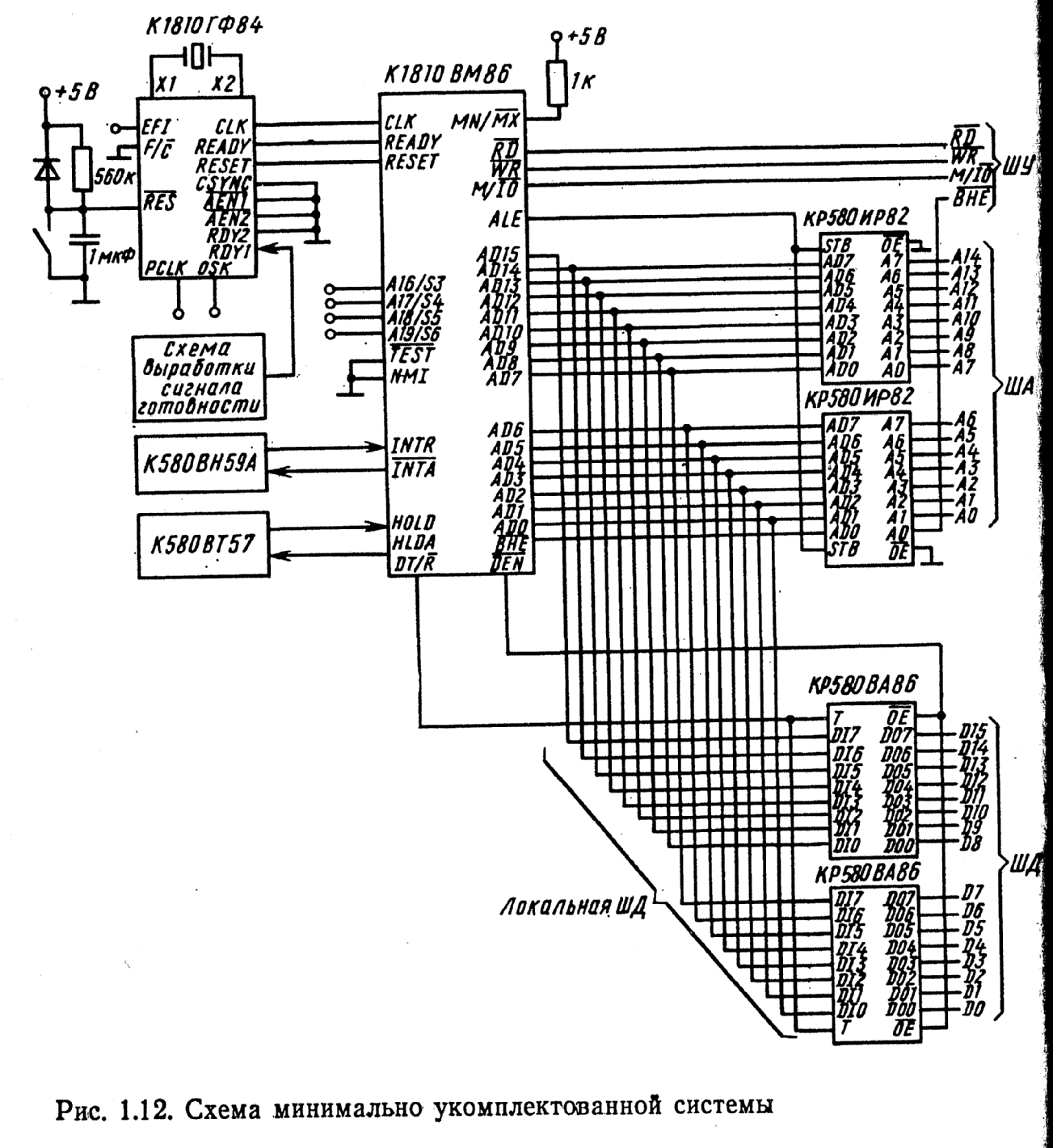
Рисунок 3.4 – Структура минимально укомплектованной системы
Лекция № 4
ТЕМА: Организация и способы обмена информацией между микропроцессорами и внешними устройствами. Программно-упраляемый способ обмена информацией
Основные вопросы, рассматриваемые на лекции:
1. Организация и способы обмена информацией между микропроцессорами и внешними устройствами
2. Программно-упраляемый способ обмена информацией
3. Схема подключения портов отображенных на память
Вводом-выводом информации называют процесс передачи данных между микропроцессором и основной памятью (ОЗУ, ПЗУ), между микропроцессором и внешними устройствами, а также между основной памятью и внешними устройствами. Различают три режима ввода-вывода: программный, по прерываниям и прямой доступ к памяти.
Программный ввод-вывод инициируется программой работы микропроцессора, т.е. в определенных местах программы записываются команды опроса портов или обращения к памяти, под управлением которых осущетсвляется процесс ввода-вывода. Поэтому программный ввод-вывод называют еще синхроннымрежимом ввода-вывода, т.е. управляемым командами микропроцессора. Эти команды выполняются немедленно, если внешние устройства имеют свойство постоянной готовности к приему или передаче данных. Такими устройствами могут быть, например, светодиодные или ЖК-индикаторы на выходе порта вывода или набор кнопок на входе порта ввода. Если внешнее устройство таким свойством не обладает, то при выполнении команды необходимо осуществлять проверку управляющего сигнала готовности внешнего устройства к передаче или приему данных. Если готовность устройства не подтверждается, то микропроцессор переходит в режим ожидания активного уровня сигнала готовности. Недостатком такой организации ввода-вывода являются большие временные затраты на ожидание готовности медленного внешнего устройства. Однако такой способ ввода-вывода имеет преимущество, заключающееся в простой аппаратной реализации. Поэтому такой режим ввода-вывода используется преимущественно для осуществления обмена данными с устройствами постоянно готовыми к этому обмену.
Дальнейшее развитие МПС состоит в подключении внешних устройств. В системе команд ВМ86, как и ВМ8О, предусмотрены специальные команды ввода — вывода. Однако обращение к ВУ чаще осуществляется аналогично обращению к ячейкам ЗУ, так что порты ВУ подключаются к линиям, которые управляют работой памяти. В этом случае процессор не отличает обращение к ВУ от обращения к ячейке ОЗУ. Преимущество такого способа подключения ВУ заключается в том, что появляется возможность использования большого числа команд, предназначенных для обработки операндов из адресуемой области памяти. Вместо двух команд (ввода IN и вывода ОUТ), предусмотренных
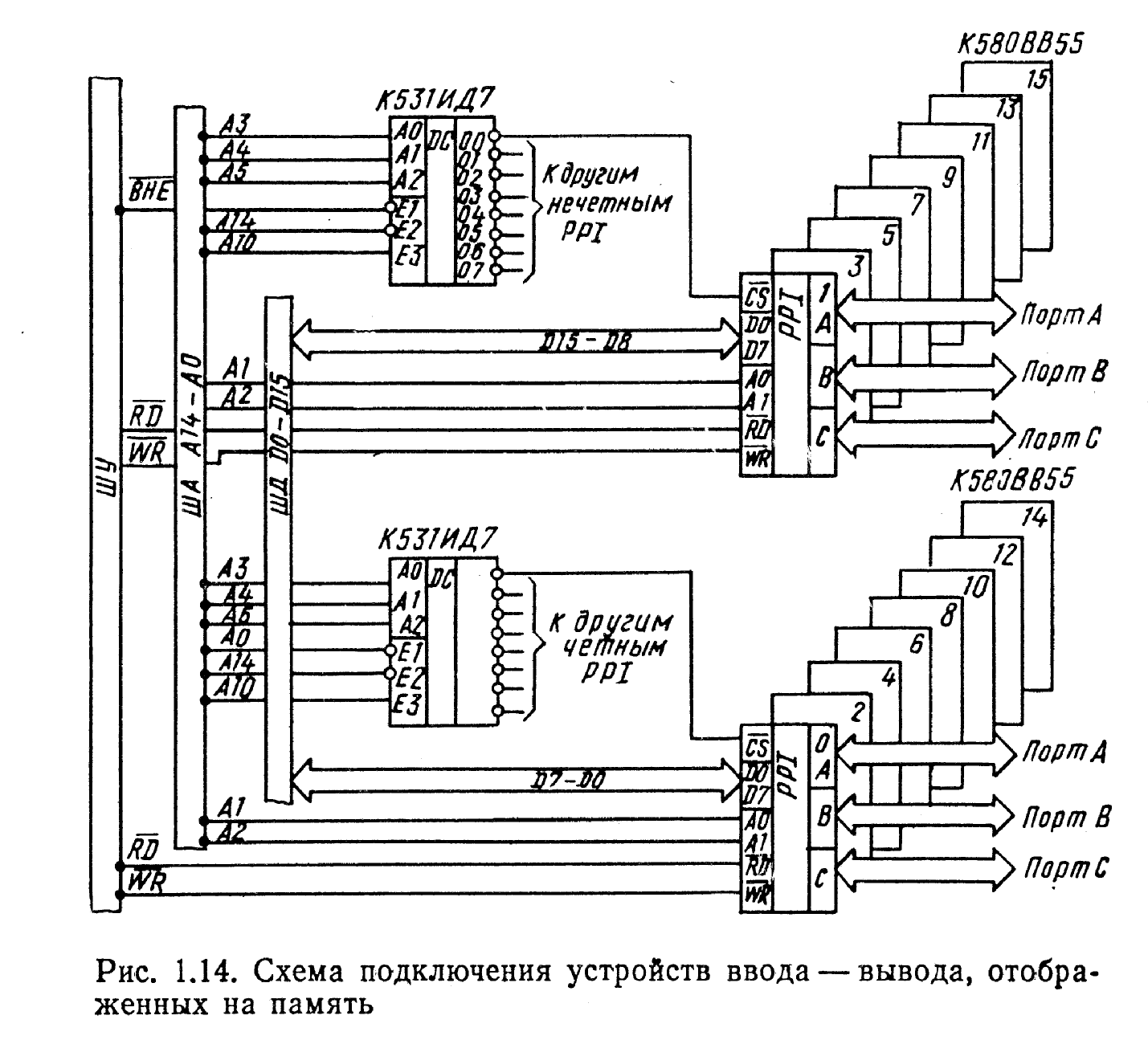
Рисунок 4.1 – Схема подключения портов отображенных на память
для передачи байта или слова из УВВ в аккумулятор и обратно, появляется возможность выполнения арифметических и логических операций с участием данных из ВУ, а также операций пересылок между любым внутренним регистром и ВУ, между памятью и ВУ, а также из одного ВУ в другое. На рис. 4.1 показан возможный способ использования программируемого параллельного адаптера К580ВВ55 в качестве порта ввода — вывода, подключенного к линиям ОЗУ. Применение микросхемы К531ИД7 для дешифрации сигналов выбора устройства (С8) позволяет обеспечить выбор до 24 программируемых 16-разрядных ВУ или до 48 8-разрядных ВУ.
В рассматриваемой минимально укомплектованной системе с двумя фиксаторами адреса используются, как отмечалось ранее, пятнадцать младших адресных разрядов. Поэтому для адресации портов ввода — вывода можно использовать, например, разряды А10 и А14, что в совокупности с разрядами АЗ—А5 обеспечит область адресации ВУ в пределах от 0400Н до О439Н. Всякий раз при низком уровне сигнала А14 и при высоком уровне сигнала А1О в дешифраторе К531ИД7 будут дешифрироваться адресные разряды АЗ, А4 и А5. Выбор старшего, младшего или обоих байтов
данных осуществляется с помощью сигналов АО и ВНЕ, как показано в табл. 4.1.
Использование дешифраторов позволяет устанавливать произвольные значения адресов портов ввода — вывода.
Таблица 4.1

Однако при организации 16-разрядных портов и использова- нии команд передачи двухбайтовых слов необходимо следить за правильностью адресации отдельных байтов, чтобы в пересылаемом слове не оказались байты из разных портов. Во избежание таких недоразумений при передаче 16-разрядных данных ко всем портам следует обращаться, как к ячейкам с четными адресами.
Хотя использование схемы подключения ВУ как памяти позволяет увеличить гибкость системы, такое построение имеет и некоторые недостатки. Во-первых, сокращается число адресов для ячеек памяти, что не является существенным, поскольку адресное пространство велико.
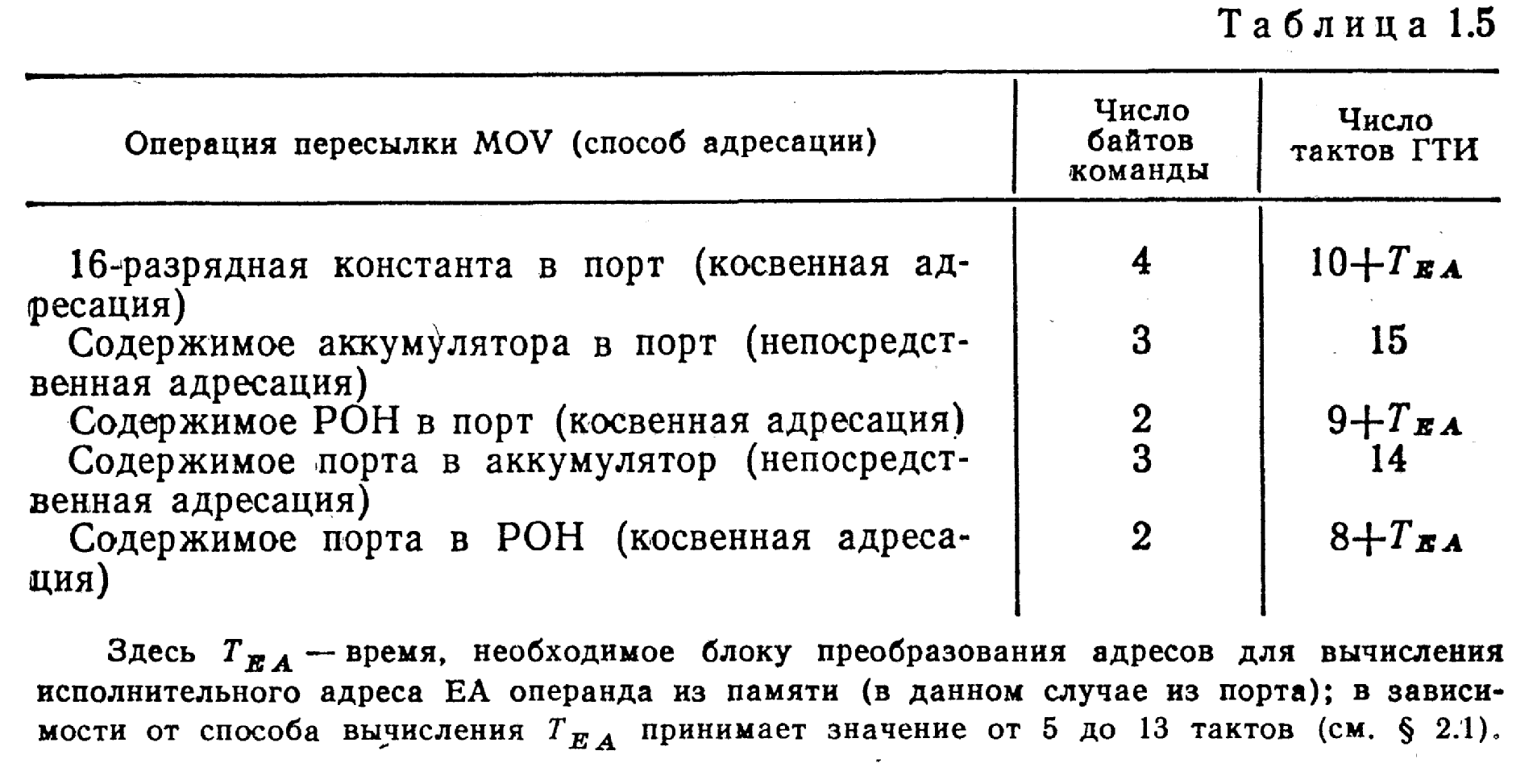
Во-вторых, обращение к подключенным описанным способом ВУ характеризуется меньшим быстродействием по сравнению со случаем подключения ВУ к линиям ввода — вывода. для выполнения команды Т или ОIЛ достаточно 10 тактов ГТИ и 2 байт памяти, тогда как команды пересылки МОУ требуют большего числа тактов и байтов, как указано в табл. 1.5.
Следует отметить, что при использовании линий ввода
вывода требуется различать циклы обращения к ВУ и к памяти. С этой целью применяется управляющий сигнал М/IO, который принимает значения «О» и «1» соответственно. Таким образом, схема подключения ВУ к линиям ввода — вывода аналогична схеме подключения ВУ к линиям ОЗУ (см. рис. 4.1), за исключением того, что для разрешения работы дешифраторов вместо сигнала А14 используется сигнал М/IО, а входы ЕЗ обоих дешифраторов соединены с источником питания.
Таблица 4.2
Лекция № 5
ТЕМА: Ввод-вывод информации через прерывания,
Основные вопросы, рассматриваемые на лекции:
1. Ввод-вывод информации через прерывания
2. БИС 8259А
3. Каскадирование контроллеров.
Большое значение для микропроцессорных систем, работающих в реальном времени, имеет обеспечение экстренного обслуживания ВУ по их запросам. По принятию запроса МП прерывает текущую программу и переходит на подпрограмму обслуживания ВУ, пославшего запрос. Для организации систем прерываний при наличии многих ВУ предназначена БИС программируемого контроллера прерываний (ПКП) К580ВН59А, способная работать как с ВМ8О, так и с ВМ86. Вариант контроллера 8259А, который можно использовать только совместно с 8086.
Задача контроллера состоит в приеме запросов прерывания от ВУ, сравнении их приоритетов и посылки запроса прерывания в ЦП вместе с информацией о местоположении соответству ющей подпрограммы. В функции ПКП также входит изменение дисциплины обслуживания ВУ, т. е. установка различных режимов присвоения приоритетов ВУ в соответствии с общими требованиями к системе.
Блоки ПКП и их работа. ВИС 8259А позволяет обслуживать восемь ВУ, число которых может быть увеличено до 64 в МПС на основе 8080 и до 256 в МПС на основе 8086 путем подключения дополнительных ВИС ПКП. На рис. 5.1 изображена схема ПКП.
Буфер данных БД вместе со схемой управления обменом по шд D7—D0 обеспечивает прием управляющих слов (команд) в контроллер при программировании, а также выдачу состояний регистров контро.лера и информации об адресе подпрограммы. Регистр запросов прерываний РЗП служит для запоминания всех запросов от ВУ по входам IR7—IR0. Регистр масок прерываний РМП хранит маску, с помощью которой можно запретить обслуживание запросов по любому входу. Схема сравнения приоритетов СхСПр выбирает запрос с наибольшим приоритетом ёреди вновь поступивших и уже обслуживаемых запросов. Регистр обслуживаемых прерываний РОП содержит единицы на позициих, соответствующих обслуживаемым запросам, причем каждая единица запрещает обслуживание запросов с меньшим приоритетом, если отсутствует режим спецмаскирования,управляющее устройство УУ, содержащее регистры команд инициализации РКИ и регистры рабочих команд РРК, обеспечивает выработку внешних и внутренних управляющих сигналов. Блок каскадирования БК осуществляет связь ведущей БИС контроллера с ведомыми при использовании нескольких ПКП в микропроцессорной системе.
Для лучшего понимания работы контроллера 8259 рассмотрим последовательность его действий в системе, на 8086:
1. ПКП воспринимает запросы прерывания по входам IR от одного или нескольких ВУ, записывает единицы в соответствующие разряды РЗП, проверяет маскирование, определяет запрос с наивысшим приоритетом и посылает сигнал прерывания INТ на соответствующий вход МП.
2. Если прерывания разрешены (1NТЕ= 1) , МП заканчивает выполнение текущейкоманды и активизирует сигнал подтверждения прерывания INTA.
3. По получении первого импульса INTA ПКП устанавливает в «1» разряд регистра РОП, соответствующий запросу, под лежащему обслуживанию, а одноименный разряд регистра РЗП сбрасывается в«0».
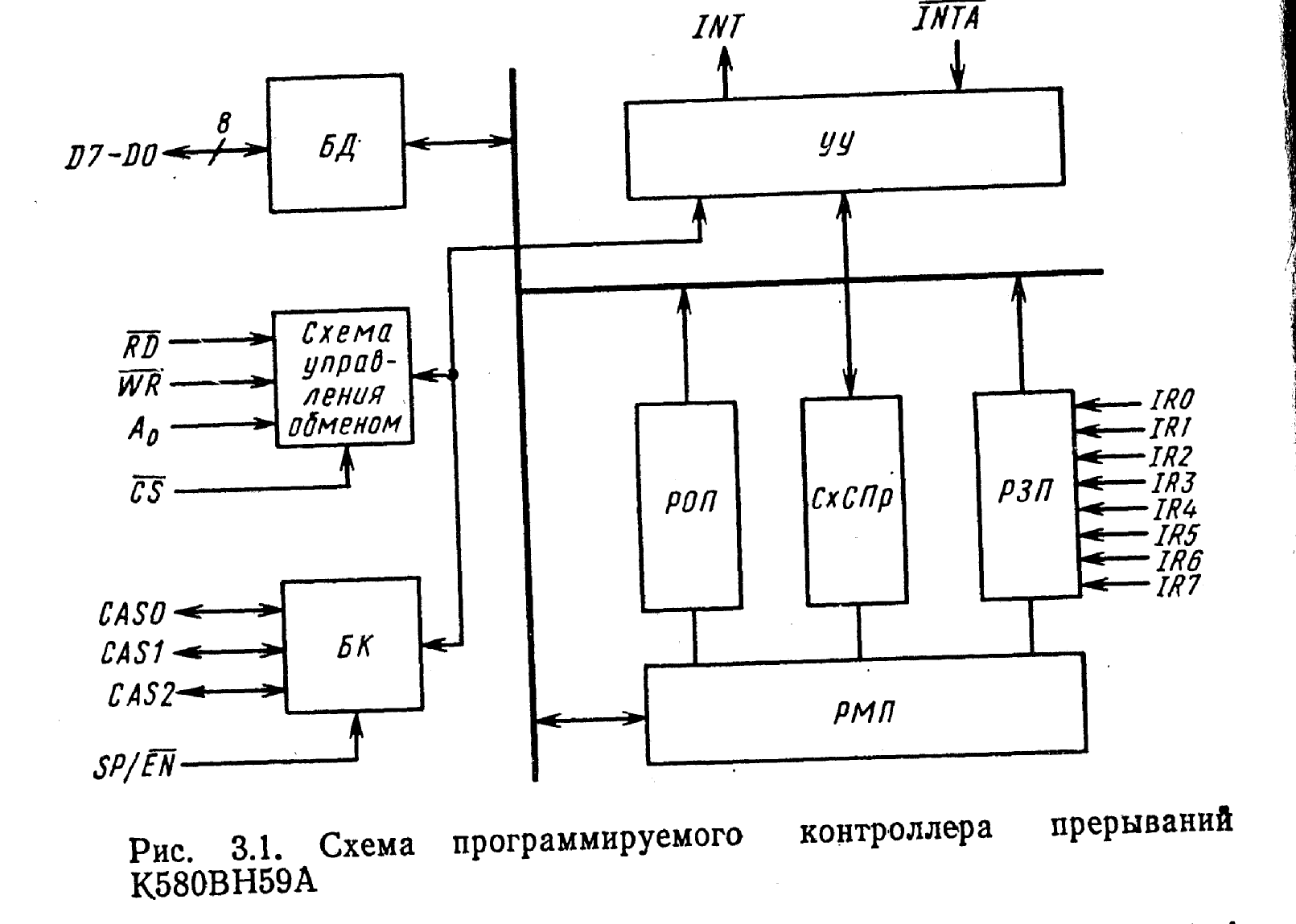
Рисунок 5.1 – Структурная схема 8259А
4. МП вырабатывает второй импульс INTA, по получении которого контроллер посылает по ШД в МП 8-разрядный указатель (вектор), используемый для определения начального адреса подпрограммы обслуживания прерывания.
5. МП переходит на выполнение подпрограммы обслуживания прерывания.
При работе контроллера с 8086 вместо команды САLL используется специальный указатель, по которому МП определяет один из 256 начальных адресов, расстояние между которыми равно четырем. Разряды D2—D0 указателя содержат двоичный код номера обслуживаемого запроса, а разряды D7—D3—значения разрядов адреса А15—А11, зоны ЗУ, в которой содержатся входы в подпрограммы.
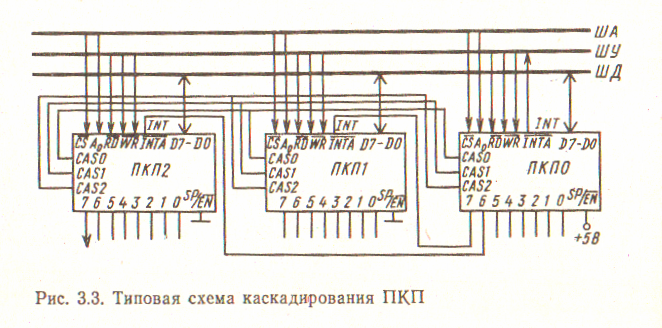
Рисунок 5.2 – Типовая схема каскадирования 8259А
Каскадирование контроллеров прерываний. Контроллеры прерываний имеют встроенные средства для их каскадирования с целью увеличения числа уровней прерываний. На рис. 5.2 показана типовая схема каскадирования, содержащая три контроллера, в которой коятроллер ПКП0 является ведущим, а остальные два — ведомыми. Включение контроллера в качестве ведущего или ведомого определяется соответствующим подключением вывода SР/ЕN к источнику питания в первом случае и к общей шине —во втором. Шины каскадирования САS2—САS0 всех контроллеров соединяются параллельно, причем выводы САS2—САS0 ведущего контроллера работают как выходы, а у ведомых контроллеров — как входы. Когда активизируется вход запроса ведомого контроллера, ведущий контроллер разрешает ведомому выдать номер соответствующего уровня прерывания по второму импульсу INTA.
Лекция № 6
| ТЕМА: Прямой доступ в память. 8237.
|
Основные вопросы, рассматриваемые на лекции:
1. Назначение DMA
2. Организация DMA
3. 8237.
Работа РТС, выполненной на базе микропроцессора, сопровождается интенсивным обменом данными между вычислителем и внешними устройствами (ВУ) . Для организации обмена обычно используются различные контроллеры, позволяющие согласовывать работу того или иного ВУ с работой системы. Примерами могут служить контроллеры ПКП и ПККД, а также широко известный контроллер прямого доступа в память (ПДП) 8237. В функции контроллеров входит анализ сигналов от ВУ, дешифрация адреса ВУ, адресация памяти (для ПДП), синхронизация обмена, согласование форматов данных, выдача управляющих сигналов и т. д. Чем шире многообразие ВУ, тем большее число различных контроллеров необходимо для их обслуживания. Специфика РТС состоит, в частности, в использовании большого числа специализированных ВУ, что заставляет каждый раз проектировать соответствующий контроллер. Кроме того, помимо функций управления ВУ и передачей данных на эти контроллеры возлагают дополнительные функции по предварительной обработке передаваемых данных ( например, кодирование, декодирование, анализ условий окончания передачи) . Для снижения трудоемкости проектирования и повышения эффективности системы ввода—вывода а РТС, создаваемых на основе центрального процессора 8086, удобно использовать специализированный сопроцессор ввода—вывода 8089. Этот сопроцессор сочетает в себе свойства универсального контроллера ПДП со свойствами специализированного процессора, который позволяет осуществлять различные преобразования данных во время пересылок.
Прямой доступ к памяти (DMA) - это метод непосредственного обращения к памяти, минуя процессор. Процессор отвечает только за программирование DMA: настройку на определенный тип передачи, задание начального адреса и размера массива обмениваемых данных. Обычно DMA используется для обмена массивами данных между системной памятью и устройствами ввода-вывода.
Обмен данными между процессором и устройствами ввода-вывода осуществляется по системной шине, "хозяином" которой является процессор. При использовании контроллера DMA на время обмена данными он должен получить управление системной шиной, т.е. стать ее "хозяином". По окончании обмена подсистема DMA возвращает процессору право управления шиной.
Архитектура компьютера PC AT включает в себя подсистему DMA, состоящую из двух контроллеров DMA Intel 8237, регистра старшего адреса DMA и регистров страниц DMA. Эти контроллеры обеспечивают 7 каналов DMA.
Система обеспечивает передачу данных по каналам DMA как по одному байту за цикл DMA, так и по два байта за цикл, исходя из возможностей архитектуры процессора (двухбайтной шины данных). Чтобы сохранить преемственность подсистемы DMA в PC AT с аналогичной подсистемой в PC XT каскадирование "байтного" контроллера DMA с распределением каналов XT осуществляется через "словный" контроллер DMA.
Общий алгоритм ПДП.
Для осуществления прямого доступа к памяти контроллер должен выполнить ряд последовательных операций:
- принять запрос (DREQ) от устройства ввода-вывода;
- сформировать запрос (HRQ) в процессор на захват шины;
- принять сигнал (HLDA), подтверждающий захват шины;
- сформировать сигнал (DACK), сообщающий устройству о начале обмена данными;
- выдать адрес ячейки памяти, предназначенной для обмена;
- выработать сигналы (MEMR, IOW или MEMW, IOR), обеспечивающие управление обменом;
- по окончании цикла DMA либо повторить цикл DMA, изменив адрес, либо прекратить цикл.
Формирование адреса памяти.
Контроллеры DMA обеспечивают формирование только 16 младших разрядов адреса памяти. Причем старшая часть адреса (А15-А8 для DMA1 или А16-А9 для DMA2) во время цикла DMA по шине данных поступает в регистр старшего адреса DMA и далее на шину адреса, а младшая часть адреса (А7-А0 для DMA1 или А8-А1 для DMA2) выдается на шину адреса непосредственно из контроллера. Восемь старших разрядов адреса памяти содержатся в регистре страниц DMA. Разряд А16 из регистра страниц DMA запрещается, когда выбран DMA2. Разряд A0 не связан с DMA2 и всегда содержит нуль при передаче слова.
Это означает, что:
- размер блока данных, который может быть передан или адресован, измеряется не байтами (8 бит), а словами (16 бит);
- слова всегда должны быть расположены на четной границе.
Таким образом, контроллер DMA и регистр страниц определяют 24-разрядный адрес, что обеспечивает передачу данных в пределах адресного пространства 16 М байт.
Регистры страниц.
Регистр страниц вместе с контроллерами DMA он определяет полный (24-разрядный) адрес для каналов DMA.
Адреса портов регистров страниц:
| Канал DMA | Адрес порта регистра страниц |
| 0 | 087h |
| 1 | 083h |
| 2 | 081h |
| 3 | 082h |
| 4 | - |
| 5 | 08Вh |
| 6 | 089h |
| 7 | 08Ah |
| Регенерация | 08Fh |
* Содержимое регистра страниц в целях регенерации должно быть равно 00h.
Адресация портов.
В таблице приведены адреса портов - регистров адреса ОП и управления/состояния контроллеров DMA, а также форматы регистров:
| Функции регистров | Формат | Адреса портов | Чтение/запись | |
| DMA1 | DMA2 | |||
| Регистр состояния (STAT) Read Status Register) | 8 | 008h | 0D0h | Чтение |
| Регистр команд (CR) (Write Command Register) | Запись | |||
| Регистр режима (MOD) (Write Mode Register) | 6 | 00Bh | 0D6h | Запись |
| Регистр режима (MOD)*** (Read Mode Register) | Чтение | |||
| Запись одиночных разрядов регистра маск (Write Single Mask Register) | 4 | 00Ah | 0D4h | Запись |
| Регистр команд (CR)*** (Read Command Register) | 8 | Чтение | ||
| Запись всех разрядов маски (Write Mask Register) | 4 | 00Fh | 0DEh | Запись |
| Регистр маски (MASK)*** (Read Mask Register) | Чтение | |||
| Программный регистр запросов (REQ)** Write Request Register) | 4 | 009h | 0D2h | Запись |
| Регистр запросов *** (Read Request Register) | Чтение | |||
| Базовый и текущий регистры адреса - канал 0 | 16 | 000h | 0C0h | Запись |
| Текущий регистр адреса канал 0 | 16 | 000h | 0C0h | Чтение |
| Базовый и текущий регистры cчетчика - канал 0 | 16 | 001h | 0C2h | Запись |
| Текущий регистр счетчика - канал 0 | 16 | 001h | 0C2h | Чтение |
| Базовый и текущий регистры адреса - канал 1 | 16 | 002h | 0C4h | Запись |
| Текущий регистр адреса - канал 1 | 16 | 002h | 0C4h | Чтение |
| Базовый и текущий регистры cчетчика - канал 1 | 16 | 003h | 0C6h | Запись |
| Текущий регистр счетчика - канал 1 | 16 | 003h | 0C6h | Чтение |
| Базовый и текущий регистры адреса - канал 2 | 16 | 004h | 0C8h | Запись |
| Текущий регистр адреса - канал 2 | 16 | 004h | 0C8h | Чтение |
| Базовый и текущий регистры cчетчика - канал 2 | 16 | 005h | 0CAh | Запись |
| Текущий регистр счетчика - канал 2 | 16 | 005h | 0CAh | Чтение |
| Базовый и текущий регистры адреса - канал 3 | 16 | 006h | 0CCh | Запись |
| Текущий регистр адреса - канал 3 | 16 | 006h | 0CCh | Чтение |
| Базовый и текущий регистры cчетчика - канал 3 | 16 | 007h | 0CEh | Запись |
| Текущий регистр счетчика - канал 3 | 16 | 007h | 0CEh | Чтение |
| Временный регистр данных(TR)** Read Temporary Register)¦ | 16 | 00Dh | 0DAh | Чтение |
| Общий сброс (Master Clear) | * | Запись | ||
| Сброс F/F(Clear Byte Pointer Flip-Flop) | * | 00Ch | 0D8h | Запись |
| Установка F/F *** (Set Byte Pointer Flip-Flop) | Чтение | |||
| Сброс регистра маски (Clear Mask Register) | * | 00Eh | 0DCh | Запись |
| Сброс счетчика MODE *** (Clear Mode Counter) | Чтение | |||
- * Это не регистры, а непосредственные команды для контроллера DMA.
- ** Эти регистры используются только в режиме ПАМЯТЬ-ПАМЯТЬ.
- *** Эти регистры и команды контроллера DMA не реализованы в контроллере 8237А и в "Периферийном контроллере" STC62C008, но реализованы в большинстве современных комплектов процессорных БИС.
Режимы обслуживания.
В активном цикле обслуживание подсистемы DMA возможно в одном из четырех режимов. Окончание обслуживания распознается по переходу регистра счетчика слов из 0000Н в FFFFН. При этом возникает сигнал окончания счета (TC), который может вызвать автоинициализацию, если она запрограммирована, или маскирование канала при ее отсутствии.
Одновременно с TC вырабатывается выходной сигнал -EOP. Во время автоинициализации первоначальные значения регистров текущего адреса и счетчика восстанавливаются из соответствующих базовых регистров. После автоинициализации канал готов выполнять другое обслуживание подсистемы DMA без вмешательства CPU, как только обнаружится достоверный DREQ.
Дата: 2019-03-05, просмотров: 625.