Когда транскрипция готова, компьютер рассчитывает, как долго будет звучать каждая фонема, то есть сколько в ней фреймов — так называют фрагменты длиной 25 миллисекунд. Затем каждый фрейм описывается по множеству параметров: частью какой фонемы он является и какое место в ней занимает; в какой слог входит эта фонема; если это гласная, то ударная ли она; какое место она занимает в слоге; слог — в слове; слово — в фразе; какие знаки препинания есть до и после этой фразы; какое место фраза занимает в предложении; наконец, какой знак стоит в конце предложения и какова его главная интонация.
Другими словами, для синтеза каждых 25 миллисекунд речи используется множество данных. Информация о ближайшем окружении обеспечивает плавный переход от фрейма к фрейму и от слога к слогу, а данные о фразе и предложении в целом нужны для создания правильной интонации синтезированной речи.
Чтобы прочитать подготовленный текст, используется акустическая модель. Она отличается от акустической модели, которая применяется при распознавании речи. В случае с распознаванием модели нужно установить соответствие между звуками с определёнными характеристиками и фонемами. В случае с синтезом акустическая модель, должна, наоборот, по описаниям фреймов составить описания звуков.
Откуда акустическая модель знает, как правильно произнести фонему или придать верную интонацию вопросительному предложению? Она учится на текстах и звуковых файлах. Например, в неё можно загрузить аудиокнигу и соответствующий ей текст. Чем больше данных, на которых учится модель, тем лучше её произношение и интонирование.
Голоса
Наконец, о самом голосе. Узнаваемыми наши голоса, в первую очередь, делает тембр, который зависит от особенностей строения органов речевого аппарата у каждого человека. Тембр вашего голоса можно смоделировать, то есть описать его характеристики — для этого достаточно начитать в студии небольшой корпус текстов. После этого данные о вашем тембре можно использовать при синтезе речи на любом языке, даже таком, которого вы не знаете. Когда роботу нужно что-то сказать вам, он использует генератор звуковых волн — вокодер. В него загружается информация о частотных характеристиках фразы, полученная от акустической модели, а также данные о тембре, который придаёт голосу узнаваемую окраску.
Автоматический синтез
текста (АС), операция, в которой по заданной грамматической и семантической информации строится содержащий эту информацию текст на естественном языке; операция выполняется по некоторому алгоритму в соответствии с заранее разработанным описанием данного языка. Обратная операция называется автоматическим анализом текста. АС подразделяется на три этапа:
- семантический ≈ переход от смысловой записи фразы к её синтаксической структуре;
- синтаксический ≈ переход от синтаксической структуры фразы к представляющей фразу цепочке лексико-грамматических характеристик словоформ;
- лексико-морфологический ≈ переход от лексико-грамматической характеристики к реальной словоформе. АС ≈ необходимый этап в разных видах автоматической обработки текстов, в частности при машинном переводе. АС следует отличать от автоматического порождения текстов, при котором строятся произвольные правильные тексты безотносительно к какому бы то ни было предварительному смысловому заданию.
14. Компьютерный контент-анализ и авторизация текстов. Проект ВААЛ.
Контент-анализ,количественный анализа текстов и текстовых массивов с целью последующей содержательной интерпретации выявленных числовых закономерностей. Основная идея контент-анализа проста и интуитивно наглядна. При восприятии текста и особенно больших текстовых потоков мы достаточно хорошо ощущаем, что разные формальные и содержательные компоненты представлены в них в разной степени, причем эта степень по крайней мере отчасти поддается измерению: ее мерой служит то место, которое они занимают в общем объеме, и/или частота их встречаемости.
Замысел контент-анализа заключается в том, чтобы систематизировать эти интуитивные ощущения, сделать их наглядными и проверяемыми и разработать методику целенаправленного сбора тех текстовых свидетельств, на которых эти ощущения основываются.
При этом предполагается, что вооруженный такой методикой исследователь сможет не просто упорядочить свои ощущения и сделать свои выводы более обоснованными, но даже узнать из текста больше, чем хотел сказать его автор, ибо, скажем, настойчивое повторение в тексте каких-то тем или употребление каких-то характерных формальных элементов или конструкций может не осознаваться автором, но обнаруживает и определенным образом интерпретируется исследователем.
Реально главной отличительной чертой контент-анализа является не его декларируемая во многих определениях «систематичность» и «объективность» (эти черты присущи и другим методам анализа текстов), а его квантитативный характер. Контент-анализ – это прежде всего количественный метод, предполагающий числовую оценку каких-то компонентов текста, могущую дополняться также различными качественными классификациями и выявлением тех или иных структурных закономерностей.
С точки зрения лингвистов и специалистов по информатике, контент-анализ является типичным примером прикладного информационного анализа текста, сводящегося к извлечению из всего разнообразия имеющейся в нем информации каких-то специально интересующих исследователя компонентов и представлению их в удобной для восприятия и последующего анализа форме. Многочисленные конкретные варианты контент-анализа различаются в зависимости от того, каковы эти компоненты и что именно понимается под текстом. Конкретные прикладные цели контент-анализа также варьируют в широких пределах. В их числе – описание тенденций в изменении содержания коммуникативных процессов; описание различий в содержании коммуникативных процессов в различных странах; сравнение различных СМИ; выявление используемых пропагандистских приемов; определение намерений и иных характеристик участников коммуникации; определение психологического состояния индивидов и/или групп; выявление установок, интересов и ценностей (и, шире, систем убеждений и «моделей мира») различных групп населения и общественных институтов; выявление фокусов внимания индивидов, групп и социальных институтов и др.
В 1930–1940-х годах были выполнены исследования, признаваемые ныне классикой контент-анализа, прежде всего работы Г.Лассуэлла, деятельность которого продолжалась и в послевоенные годы. Во время Второй мировой войны имел место самый, пожалуй, знаменитый эпизод в истории контент-анализа – это предсказание британскими аналитиками времени начала использования Германией крылатых ракет «Фау-1» и баллистических ракет «Фау-2» против Великобритании, сделанное на основе анализа (совместно с американцами) внутренних пропагандистских кампаний в Германии. Начиная с 1950-х годов контент-анализ как исследовательский метод активно используется практически во всех науках, так или иначе практикующих анализ текстовых источников – в теории массовой коммуникации, в социологии, политологии, истории и источниковедении, в культурологии, литературоведении, прикладной лингвистике, психологии и психиатрии.
Локальные контент-аналитические проекты периодически реализуются в ходе различного рода социологических мониторингов – общенациональных и региональных. Наиболее широкое распространение контент-анализ получил в теории массовой коммуникации, политологии и социологии.
Существует ряд исследовательских методов – либо специально разработанных для анализа политических текстов (например, метод когнитивного картирования), либо применимых и применяемых для этой цели (например, метод семантического дифференциала или различные подходы, предполагающие изучение структуры текста и механизмов его воздействия), – которые не могут быть сведены к стандартному контент-анализу даже при максимально широком его понимании.
Тем не менее контент-анализ действительно занимает среди аналитических методов особое место в силу того, что является среди них самым технологичным и в силу этого в наибольшей степени подходящим для систематического мониторинга больших информационных потоков. Помимо этого, контент-анализ достаточно гибок для того, чтобы в его рамки мог быть успешно «вписан» весьма разнообразный круг конкретных типов исследований. Наконец, будучи в основе своей количественным методом (хотя и содержащим немалую качественную составляющую), контент-анализ в определенной степени поддается формализации и компьютеризации.
Проект ВААЛ
Система ВААЛ, работа над которой ведется с 1992 года, позволяет прогнозировать эффект неосознаваемого воздействия текстов на массовую аудиторию, анализировать тексты с точки зрения такого воздействия, составлять тексты с заданным вектором воздействия, выявлять личностно-психологические качества авторов текста, проводить углубленный контент-анализ текстов и делать многое другое.
 Области возможного применения
Области возможного применения
· Составление текстов выступлений с заранее заданными характеристиками воздействия на потенциальную аудиторию.
· Активное формирование эмоционального отношения к политическому деятелю со стороны различных социальных групп.
· Составление эмоционально окрашенных рекламных статей.
· Поиск наиболее удачных названий и торговых марок.
· Психо- и гипнотерапия.
· Неявное психологическое тестирование и экспресс-диагностика.
· Создание легких в усвоении учебных материалов.
· Научные исследования в области психолингвистики и смежных с нею дисциплинах.
· Журналистика и другие сферы деятельности, использующие в качестве инструмента СЛОВО.
· Социологические и социолингвистические исследования.
· Информационные войны.
· Контент-анализ текстов.
· Мониторинг СМИ.
Система позволяет
· Оценивать неосознаваемое эмоциональное воздействие фонетической структуры текстов и отдельных слов на подсознание человека.
· Генерировать слова с заданными фоносемантическими характеристиками.
· Оценивать неосознаваемое эмоциональное воздействие фонетической структуры текстов на подсознание человека.
· Задавать характеристики желаемого воздействия и целенаправленно корректировать тексты по выбранным параметрам в целях достижения необходимого эффекта воздействия.
· Оценивать звуко-цветовые характеристики слов и текстов.
· Производить словарный анализ текстов.
· Осуществлять полноценный контент-анализ текста по большому числу специально составленных встроенных категорий и категорий, задаваемых самим пользователем.
· Производить выделение тем, затрагиваемых в текстах, и осуществлять на основе этого автоматическую категоризацию.
· Производить эмоционально-лексический анализ текстов.
· Настраиваться на различные социальные и профессиональные группы людей, которые могут быть выделены по используемой ими лексике.
· Производить вторичный анализ данных путем их визуализации, факторного и корреляционного анализа.
Реализация
Система реализована в виде набора DLL-библиотек, которые подключаются к наиболее популярному текстовому процессору WordforWindows. Просто в главном меню появляется новый пункт. Такой способ реализации позволяет сохранить для пользователя привычную удобную среду создания документов и максимально облегчает освоение системы ВААЛ.
15. Семантические сети. Моделирование семантики слова.
Термин «семантическая сеть" обозначает семейство представлений, основанных на графах. Эти представления отличаются главным образом именами вершин, связей и выводами, которые можно делать в этих структурах.
Под семантической сетью подразумевают систему знаний некоторой предметной области, имеющую определенный смысл в виде целостного образа сети, узлы которой соответствуют понятиям и объектам, а дуги - отношениям между объектами. При построении семантической сети отсутствуют ограничения на число связей и на сложность сети. Для того чтобы формализация оказалась возможной, семантическую сеть необходимо систематизировать.
Базовые структуры в этих моделях знаний могут быть представлены графом, множество вершин и дуг которого образуют сеть. Развитию моделей этого класса в большей степени послужили проблемы алгоритмизации понимания естественного языка. Семантические сети (СС) обычно используют для представления знаний общего характера.
Кроме общих исходных предпосылок различные СС существенно отличаются. Это объясняется тем, что конкретные типы СС разрабатываются для различных целей различных приложений.
Не всякий помеченный сетевой граф можно рассматривать как СС, поскольку семантичность не присуща графу априори. Для того, чтобы приписать графу некоторую семантику, необходимо тщательно определить:
1. Что обозначают вершины и дуги графа.
2. Как их можно использовать при обработке.
Создание СС – это реализация попытки обеспечить интегрированное представление данных, категорий (типов) данных, свойств категорий и операций над данными и категориями. Особенность СС заключается в целостности системы, выполненной на ее основе, т.е. возможности разделить базу знаний и механизм вывода, при этом интерпретация СС реализуется с помощью использующих эту сеть процедур.
При построении семантической сети отсутствуют ограничения на число элементов и связей. Поэтому систематизация отношений между объектами в сети необходима для дальнейшей формализации. Пример семантической сети представлен на рисунке ниже.
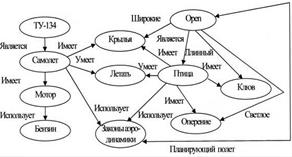
Моделирование семантики.
При моделировании семантики предложения прежде всего возникает вопрос о том, что считать смыслом предложения. Однозначного ответа на него в настоящее время не существует. Однако большинство исследователей сходится на том, что смысл предложения представляет собой сложное, многоаспектное образование. В содержании предложения сложнейшим образом сфокусированы характеристики экстралингвистической действительности, ее отражения в сознании человека в виде концептуальных структур, коммуникативных установок участников общения, а также особенности самого языка. При моделировании семантики предложения каждый из названных аспектов может получить статус исходного или даже единственного, если прочие аспекты по каким-либо соображениям не рассматриваются. В зависимости от того, какой исходный аспект кладется в основу моделирования семантики предложения, возможны, в принципе, четыре подхода: онтологоцентрический, концептоцентрический, синтактикоцентрический, антропоцентрический. В рамках каждого из них существует некоторая система воззрений, разработанных с различной степенью детальности. Поэтому важно выявить фундаментальные принципы и постулаты, которыми можно руководствоваться, строя теорию с преимущественной ориентацией на какой-нибудь один аспект.
16. Системы автоматического аннотирования и реферирования.
Рефератомназывают:
· доклад на определенную тему, включающий обзор соответствующих литературных и других источников;
· изложение содержания научной работы, книги и т.д.
Под аннотациейпонимается краткая характеристика произведения печати или рукописи. Обычно аннотация приводится после библиографического описания источника.
Аннотацию от реферата отличают:
· существенно меньший объем;
· обязательная констатация назначения аннотируемого произведения (для каких категорий читателей оно предназначено).
Автоматические реферирование и аннотирование получили значительную актуальность в связи с развитием Internet и каталогов информационных ресурсов. Для экономии времени поиска пользователям предлагаются каталоги аннотаций и рефератов источников.
Формирование рефератов и аннотаций вручную требует колоссальных человеческих ресурсов, поэтому и возникла задача создания методов автоматического реферирования и аннотирования.
Автоматическое реферирование и аннотирование — одно из направлений компьютерной обработки естественно-языковых текстов *. И в этом качестве оно относится к фундаментальным технологиям ИИ.
Основные тенденции для данной области:
· аннотированные каталоги перерастают в гипертекстовые (с их минусами и плюсами);
· на всех крупных сайтах Internet предусматривают оглавления (карта сайта — sitemap) и функции поиска по сайту;
· использование онтологических словарей-тезаурусов общего и специализированного назначения, а также методов ИИ.
Потребности в средствах автоматического реферирования и аннотирования испытывают: корпоративные системы документооборота; поисковые машины и каталоги ресурсов Internet; автоматизированные информационно-библиотечные системы; каналы вещания; службы рассылки новостей и др.
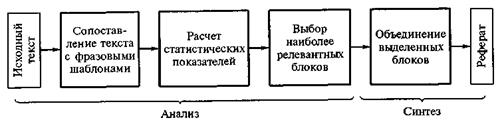
Методы автоматического реферирования и аннотирования подразделяются на поверхностные и глубинные.
Поверхностные методыбазируются на «экстрагировании» текста, т.е. извлечении из него фрагментов, оцениваемых системой как важнейшие, и объединении их в реферат или аннотацию. Важность фрагментов определяется:
· по маркерам важности (оборотам типа «идея ... состоит в...», «главным результатом ... является...», «в заключении нужно сказать, что...» и т.д.);
· по количеству заданных в запросе ключевых слов, входящих во фрагмент, и др.
При объединении выделенных предложений в реферат или аннотацию учитываются их зависимости друг от друга (удаленность выделяемых мыслей). «Стыки» между предложениями (фрагментами) «сглаживаются».
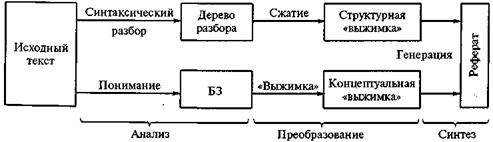
Глубинные методы, развиваемые в настоящее время, базируются на применении тезаурусов и развитых механизмов синтаксического разбора текста.
К традиционным системам автоматического реферирования и аннотирования, реализующим поверхностные методы, можно отнести:
· MicrosoftWord (функция автоматического реферирования);
· ОРФО 5.0 (разработчик — компания «Информатик»), включающую функцию автоматического аннотирования русских текстов;
· «Либретто» (разработчик — компания «МедиаЛингва»), обеспечивающую автоматическое реферирование и аннотирование русских и английских текстов (система встраивается в Word);
· пакет «МедиаЛингваАннотатор SDK 1.0», служащий инструментарием для реализации функций автоматического реферирования и аннотирования в прикладных ИАС;
· поисковую систему «Следопыт», включающую средства автоматического реферирования и аннотирования документов;
· поисковую машину «Золотой Ключик» компании Textar, обеспечивающую составление рефератов и аннотаций;
· IntelligentTextMiner (IBM);
· OracleContext;
· программные компоненты для разработки систем управления знаниями InxightSummarizer фирмы InxightSoftware, Inc.
Перечисленные средства обеспечивают выбор оригинальных фрагментов из исходных документов и соединение их в короткий текст.
Сделаем два замечания. Во-первых, источниками информации для рефератов и аннотаций могут служить не только тексты, но и видеозаписи, разнообразные табличные документы и т.д. Во-вторых, краткое изложение предполагает передачу основной мысли не обязательно теми же словами.
Основные требования к реферату:
· сжатие (объем реферата должен составлять от 5 до 30 % от объема исходного документа);
· возможность использования нескольких источников;
· выражение всех основных мыслей оригинала.
Выделяют три вида рефератов:
1. повествовательные, формирующие общее представление об источнике;
2. информационные, заменяющие источник (содержат основную или новую фактическую информацию);
3. критические (обзоры), отражающие не только суть источника, но и мнение о нем (т.е. содержащие дополнительные выводы, которых нет в оригинале).
Построение реферата человеком включает следующие этапы:
o анализ источника;
o выделение в источнике наиболее важных и информативных фрагментов;
o формирование выводов.
Отметим следующие новые задачи, связанные с компьютерным реферированием.
1. Создание одноязычных рефератов из источников на разных языках.
2. Построение рефератов по гибридным источникам, включающим как текстовые, так и числовые данные в разных формах (таблицы, диаграммы, графики и т. д.).
3. Создание рефератов на основе массивов документов. Например, построение единого реферата по сборнику тезисов докладов научной конференции. Одна из областей применения подобных средств — формирование новостных сообщений по газетным источникам.
4. Растущий объем мультимедийной информации обусловливает актуальность разработки средств ее автоматического реферирования. Методы извлечения семантики из мультимедийной информации находятся на начальных стадиях развития.
Средства автоматического аннотирования в целом аналогичны средствам автоматического реферирования. Однако требования к сжатию текста для них, как правило, на порядок более жесткие.
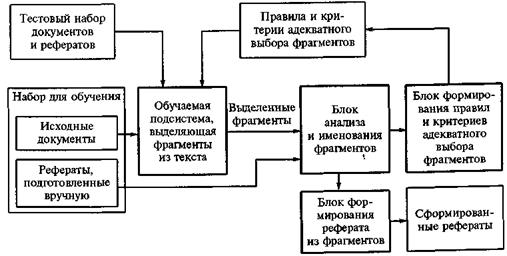
Обобщенная архитектура систем автоматического реферирования (3 типа):
Первый тип.
Второй тип.
Третий тип.
17. Экспертные системы. Системы искусственного интеллекта. Лингвистический аспект искусственного интеллекта.
Понятие и назначение экспертной системы (ЭС).
В начале 80-х годов в исследованиях по искусственному интеллекту сформировалось самостоятельное направление, получившее название "экспертные системы" (ЭС). Основным назначением ЭС является разработка программных средств, которые при решении задач, трудных для человека, получают результаты, не уступающие по качеству и эффективности решения, решениям получаемым человеком-экспертом. ЭС используются для решения так называемых неформализованных задач, общим для которых является то, что:
· задачи не могут быть заданы в числовой форме;
· цели нельзя выразить в терминах точно определённой целевой функции;
· не существует алгоритмического решения задачи;
· если алгоритмическое решение есть, то его нельзя использовать из-за ограниченности ресурсов (время, память).
Кроме того, неформализованные задачи обладают ошибочностью, неполнотой, неоднозначностью и противоречивостью как исходных данных, так и знаний о решаемой задаче.
Экспертная система - это программное средство, использующее экспертные знания для обеспечения высокоэффективного решения неформализованных задач в узкой предметной области. Основу ЭС составляет база знаний (БЗ) о предметной области, которая накапливается в процессе построения и эксплуатации ЭС. Накопление и организация знаний - важнейшее свойство всех ЭС.
Экспертная система — это программное средство, использующее знания экспертов, для высокоэффективного решения задач в интересующей пользователя предметной области. Она называется системой, а не просто программой, так как содержит базу знаний, решатель проблемы и компоненту поддержки. Последняя из них помогает пользователю взаимодействовать с основной программой.
Эксперт — это человек, способный ясно выражать свои мысли и пользующийся репутацией специалиста, умеющего находить правильные решения проблем в конкретной предметной области. Эксперт использует свои приёмы и ухищрения, чтобы сделать поиск решения более эффективным, и ЭС моделирует все его стратегии.
Инженер знаний — человек, как правило, имеющий познания в информатике и искусственном интеллекте и знающий, как надо строить ЭС. Инженер знаний опрашивает экспертов, организует знания, решает, каким образом они должны быть представлены в ЭС, и может помочь программисту в написании программ.
Средство построения ЭС — это программное средство, используемое инженером знаний или программистом для построения ЭС. Этот инструмент отличается от обычных языков программирования тем, что обеспечивает удобные способы представления сложных высокоуровневых понятий.
Пользователь — это человек, который использует уже построенную ЭС. Так, пользователем может быть юрист, использующий для квалификации конкретного случая; студент, которому ЭС помогает изучать информатику и т. д. Термин пользователь несколько неоднозначен. Обычно он обозначает конечного пользователя. Однако из рис.2 следует, что пользователем может быть:
· создатель инструмента, отлаживающий средство построения ЭС;
· инженер знаний, уточняющий существующие в ЭС знания;
· эксперт, добавляющий в систему новые знания;
· клерк, заносящий в систему текущую информацию.
Важно различать инструмент, который используется для построения ЭС, и саму ЭС. Инструмент построения ЭС включает как язык, используемый для доступа к знаниям, содержащимся в системе, и их представления, так и поддерживающие средства – программы, которые помогают пользователям взаимодействовать с компонентой экспертной системы, решающей проблему.
Системы ИИ
Термин искусственный интеллект (ИИ) является русским переводом английского термина artificalintelligence. Создателем ИИ многие ученые считают Алана Тьюринга, автора знаменитой машины Тьюринга, которая стала одним из математических определений алгоритма. В 1950 году в английском журнале “Mind” в статье “ComputingMachineryandIntelligence” (в русском переводе статья называлась «Может ли машина мыслить?») Алан Тьюринг предложил критерий, позволяющий определить, обладает ли машина мыслительными способностями. Этот тест заключается в следующем: человек и машина при помощи записок ведут диалог, а судья (человек), находясь в другом месте, должен определить по запискам, кому они принадлежат, человеку или машине. Если ему это не удается, то это будет означать, что машина успешно прошла тест. До сих пор не одна машина такой тест не прошла.
Не существует единого и общепринятого определения ИИ. Это не удивительно, так как нет универсального определения человеческого интеллекта.
Дата: 2019-03-06, просмотров: 410.