Контекстный поиск
Средства контекстного поиска позволяют искать документы по содержащимся в них словам и фразам, которые могут объединяться логическими операциями. Результаты поиска ранжируются по релевантности (соответствия критерию поиска) на основе частоты встречаемости слов запроса в найденных документах и во всей коллекции в целом.
Для обеспечения высокой скорости поиска по коллекции документов предварительно создается индекс, в котором для каждого слова устанавливаются ссылки на все документы, где это слово встречалось. Дополнительно в индексе хранится информация о положении слова в документе, частоте встречаемости и т.п. Все слова в текстовом индексе могут храниться в нормальной форме, что уменьшает его объем в несколько раз. Дополнительно из индекса устраняются часто встречающиеся стоп-слова, не участвующие в поиске (союзы, предлоги, наречия и т.п.).
В результате учета морфологии (русского и английского языков) находятся документы, содержащие все грамматические формы слов запроса. Использование синтаксического анализатора при индексации документов позволяет снимать морфологическую омонимию в тех случаях, когда различные слова имеют совпадающие грамматические формы. Подключение тезауруса позволяет расширить запрос близкими по смыслу словами, используя разные типы смысловых связей.
Тематический поиск
Возможности тематического поиска опираются на средства автоматического анализа текста и позволяют найти в коллекции документов как документы по заданной теме, так и темы, связанные по смыслу с заданной. Эти возможности могут оказать большую помощь при поиске, например в случае, если пользователь затрудняется точно подобрать ключевые слова, или же, если он хочет сузить область поиска, уточнив тематику, по которой следует искать документы.
Поиск по теме обладает более высокой точностью и полнотой по сравнению с простым контекстным поиском. Так, если контекстный поиск находит все документы, содержащие заданные слова, то тематический поиск возвращает лишь те документы, в которых словам запроса соответствует одна из ключевых тем. Кроме того, он позволяет найти документы, вовсе не содержащие слов из названия заданной темы, однако имеющие к ней отношение.
Эта возможность оказывается полезна, прежде всего, аналитику, ведущему мониторинг событий, связанных с интересующей темой. Она позволяет определить «смысловое окружение» темы в коллекции документов и, уточнив зарос, выбрать требуемую информацию. Например, в ответ на запрос «нефть» можно получить следующий список тем «добыча нефти», «экспорт нефти», «государственная нефтяная компания Азербайджана», «Азербайджан», «Ангарский НХК», «топливные компании», «ЮКОС» и т.д.
Нечеткий поиск
Технология нечеткого поиска позволяет расширять запрос близкими по написанию словами, содержащимися в коллекции документов, по которым ведется поиск. Оригинальный алгоритм способен найти все лексикографически близкие слова, отличающиеся заменами, пропусками и вставками символов.
Нечеткий поиск целесообразно применять при поиске слов с опечатками, а также в тех случаях, когда возникают сомнения в правильном написании фамилии, названия организации и т.п. Например, запрос «Инкомбанк» может быть расширен словами: «инкомбан», «инко-банки», «винкомбанке». А если пользователь забыл точное название медицинского препарата «ипрониазид», то можно задать что-нибудь похожее, например «импронизид», нужные документы будут найдены.
Алгоритмы, используемые при реализации нечеткого поиска, основаны на оригинальной системе ассоциативного доступа к словам, содержащимся в текстовом индексе. В качестве единиц поиска используются цепочки букв, составляющих слово. Для ускорения поиска предварительно создается отдельный индекс, содержащий фрагменты слов со ссылками на слова, в которых эти фрагменты встретились. Таким образом находятся слова, фрагменты которых совпадают с фрагментами слова в запросе. Задавая длину фрагментов и их количество в слове, можно регулировать полноту поиска — отбирать слова по степени близости к запросу.
Поиск по подобию
Поиск документов по подобию позволяет найти документы, близкие по содержанию к заданному. В качестве модели смысла текста при сравнении документов используются семантическая сеть или набор ключевых тем.
Семантическая (смысловая) структура коллекция документов строится с использованием средств автоматического анализа текста и нейросетевых алгоритмов, в частности алгоритмов классификации на основе самоорганизующихся тематических карт, тематических сетей и пр.

Тематическая карта разбита на ряд шестиугольных областей, каждой из которых соответствует множество близких по содержанию документов - тематический класс. При этом близким областям обычно соответствуют близкие классы документов, что является основной особенностью карты. Яркость области пропорциональна количеству отнесенных к ней документов. Встречающиеся на карте названия отражают основные темы документов в соответствующих областях.
Щелкнув мышью по выбранной области, можно просмотреть фрагмент карты в увеличенном масштабе. Для смещения окна увеличения по карте следуют использовать стрелки "компаса", расположенного под картой. Щелчок по центру компаса вызывает возврат к полному виду карты.
Для получения подробной информации об интересующей области достаточно щелкнуть мышью шестиугольник карты. При этом справа от карты отображается список основных тем документов в выбранной области. Снизу под картой представляется список всех документов, относящихся к области, с автоматически построенными рефератами. Щелкнув мышью по названию темы, можно получить список документов по теме из области. Посещенные области карты помечаются голубым цветом.
Такое отображение позволяет наглядно изобразить тематический состав большой коллекции документов в целом (десятки тысяч текстов) и помочь пользователю сориентироваться в океане информации.
Семантическая (тематическая) сеть документов представляется рядом основных тем коллекции с ассоциативными связями между ними. Щелкнув мышью по интересующей теме, можно перейти к следующему фрагменту сети, который содержит темы, наиболее сильно связанные с выбранной. Размер шара, соответствующего теме, пропорционален общему количеству документов по теме. Яркость связи пропорциональная силе ассоциативной связи между парой тем. При этом стрелкой обозначены связи от темы к подтеме.
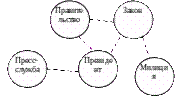
Для поиска фрагмента семантической сети, относящегося к интересующему запросу, пользователь вводит соответствующие слова в поле формы программного приложения. Яркость окраски шаров, соответствующих найденным темам, пропорциональна релевантности (близости) тем к запросу. Для поиска смысловых цепочек вводятся слова, описывающие пару тем. На рисунке отображается ряд путей, представляющих наиболее сильные связи между заданными темами. Для удобства восприятия на картинке отображается не более двадцати тем, наиболее сильно связанных с введенным запросом или выбранной темой. Программное приложение обеспечивает возможность фильтровать темы, отображаемые на картинке, по частоте встречаемости в документах, фильтровать связи между темами по силе ассоциации в коллекции документов.
В нижней части экрана программного приложения отображается список документов по темам запроса, которые упорядочены по релевантности. Дополнительно на каждый документ выдается его реферат, также построенный автоматически, который содержит наиболее информативный фрагмент (или фрагменты) текста. В зависимости от вида поиска (по запросу или по отдельной теме) реферат может быть общий или тематический. В правом окне дополнительно отображается полный список связанных тем. Щелкнув мышью по выбранной теме в списке, можно получить в нижней части экрана список документов, которые относятся и к темам запроса и к выбранной теме - раскрывают смысловую связь. При этом перемещение по навигатору, сопровождающееся сменой фрагмента семантической сети, не происходит.
Дата: 2019-03-06, просмотров: 397.