Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов. Эти значения могут быть получены на основе экстраполяционных методов, например с использованием средних абсолютных приростов факторных признаков; они могут быть получены также методами экспертных оценок или непосредственно заданы исследователем экономического процесса. Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
Продолжим рассмотрение нашего примера. С доверительной вероятностью 0,95 постройте доверительный интервал ожидаемого значения результативного признака, если факторный признак увеличится на 5% от своего среднего значения.
Построим точечный прогноз 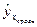 при хпрогн.. = 1,05 *
при хпрогн.. = 1,05 * 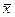 =1,05* 507,56 = 532,94 (руб.). Для этого подставим в оценочное уравнение регрессии
=1,05* 507,56 = 532,94 (руб.). Для этого подставим в оценочное уравнение регрессии 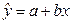 соответствующее значение хпрогн.. Тогда прогнозное значение расходов на питание при прогнозном значении дохода, равном 532,94 рубля, в среднем составит
соответствующее значение хпрогн.. Тогда прогнозное значение расходов на питание при прогнозном значении дохода, равном 532,94 рубля, в среднем составит 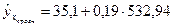 =136,36 (руб.).
=136,36 (руб.).
Точечный прогноз дополним расчетом стандартной ошибки  и соответственно интервальной оценкой прогнозного значения
и соответственно интервальной оценкой прогнозного значения 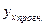 :
: 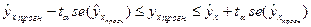 , где
, где
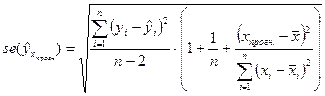 .
.
Задача 2 составлена по теме «Классическая обобщенная линейная модель множественной регрессии» и предполагает построение и анализ двухфакторного уравнения линейной регрессии вида:
Расчет параметров такого уравнения множественной регрессии (пункт 1) осуществляется МНК.
Поясните экономический смысл коэффициентов регрессии b_1 и Ь_2: это показатели силы связи, характеризующие абсолютное (в натуральных единицах измерения) изменение результативного признака при изменении факторного признака на единицу своего измерения при фиксированном влиянии второго фактора.
Пункты 2, 3 и 4 связаны с расчетом и анализом относительных показателей силы связи в уравнении множественной регрессии – частных коэффициентов эластичности и стандартизованных коэффициентов регрессии.
Пункт 6 предполагает ознакомление с методикой дисперсионного анализа по модели множественной регрессии.
Задача 3 составлена по теме «Системы эконометрических уравнений». Для ее выполнения необходимо ознакомиться со следующими понятиями:
Система одновременных уравнений — это система эконометрических уравнений (эконометрическая модель), содержащая взаимозависимые переменные, которые включены в одно из уравнений модели в качестве результативного признака, а в другие уравнения - в качестве факторного признака.
Примером системы одновременных уравнений может служить следующая гипотетическая модель:
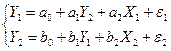
где 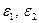 — случайные ошибки.
— случайные ошибки.
Эндогенные переменные — это взаимозависимые переменные, которые определяются внутри модели (системы). Как правило, каждое уравнение модели определяет одну эндогенную переменную, стоящую в левой части уравнения. Таким образом, число уравнений в системе равно числу эндогенных переменных.
Экзогенные переменные — это независимые переменные, которые определяются вне системы. В приведенной выше системе одновременных уравнений 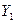 и
и 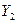 являются эндогенными, a
являются эндогенными, a 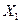 и
и 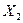 — экзогенными переменными.
— экзогенными переменными.
Предопределенные переменные — это экзогенные и лаговые (за предшествующие промежутки или моменты времени) эндогенные переменные системы.
Структурная форма модели — это система уравнений, отражающая взаимосвязь между переменными в соответствии с положениями экономической теории и характеризующая структуру экономики или ее сектора. Параметры структурной формы модели называют структурными параметрами (в приведенной выше системе это параметры 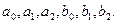 .Если модель содержит тождества, то без потери общности их можно назвать уравнениями, в которых структурные параметры при переменных равны 1.
.Если модель содержит тождества, то без потери общности их можно назвать уравнениями, в которых структурные параметры при переменных равны 1.
Приведенная форма модели — это система уравнений, в которой каждая эндогенная переменная есть линейная функция от всех предопределенных переменных модели.
Структурные параметры системы одновременных уравнений нельзя определить обычным МНК, так как правая часть системы одновременных уравнений содержит эндогенные переменные В этом случае была бы нарушена предпосылка о причинно-следственной зависимости между факторным и результативным признаками, а также ряд других предпосылок обычного МНК. Наиболее распространенными методами расчета структурных параметров системы одновременных уравнений являются косвенный и двухшаговый методы наименьших квадратов
Косвенный МНК состоит в следующем:
(а) Составляют приведенную форму модели и определяют численные значения параметров каждого ее уравнения обычным МНК.
(б) Путем алгебраических преобразований переходят от приведенной формы к уравнениям структурной формы модели, получая тем самым численные опенки структурных параметров.
Двухшаговый МНК состоит в следующем:
(а) Составляют приведенную форму модели и определяют численныезначения ее параметров обычным МНК.
(б) Выявляют эндогенные переменные, находящиеся в правой части структурного уравнения, параметры которого определяют двухшаговым МНК, и находят их расчетные значения по соответствующим уравнениям приведенной формы модели.
(в) Обычным МНК определяют параметры структурного уравнения, используя в качестве исходных данных фактические значения предопределенных переменных и расчетные значения эндогенных переменных, стоящих в правой части данного структурного уравнения.
Возможность применения косвенного или двухшагового МНК для оценки структурных параметров уравнения модели зависит от того, можно ли однозначно выразить структурные параметры через приведенные коэффициенты модели. Данную проблему называют проблемой идентификации. Если структурные параметры уравнения модели однозначно определяются по приведенным коэффициентам, то говорят, что данное уравнение точно идентифицировано. Структурные параметры такого уравнения можно найти косвенным МНК. Если из приведенной формы модели можно получить несколько оценок структурных параметров, то говорят, что уравнение сверхидентифицировано. Структурные параметры такого уравнения определяются двухшаговым МНК. Если структурные параметры уравнения модели нельзя найти через приведенные коэффициенты, то такое структурное уравнение называется сверхидентифицируемым, и численные оценки его найти нельзя.
Чтобы определить, идентифицировано ли структурное уравнение модели, применяют так называемое порядковое условие идентификации. Для этого по каждому уравнению и модели в целом подсчитывают:
K — число предопределенных переменных модели;
k — число предопределенных переменных в каждом уравнении;
m — число эндогенных переменных в каждом уравнении.
Далее для каждого уравнения в отдельности проверяют следующее соотношение:
K - k * m - 1.
Если это соотношение имеет знак больше ( K - k > m - 1 ), то уравнение сверхидентифицировано.
Если это соотношение имеет знак равно ( K - k = m - 1 ), то уравнение точно идентифицировано.
Если это соотношение имеет знак меньше ( K - k < m - 1 ), то уравнение неидентифицировано.
Обратите во внимание, что нет необходимости исследовать на идентификацию тождества модели, поскольку их структурные параметры известны и равны 1. Однако переменные, входящие в тождества, учитываются при подсчете числа эндогенных и предопределенных переменных модели.
Пример. Пусть имеется следующая эконометрическая модель:
Функция потребление: 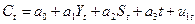
Функция инвестиций: 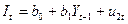
Функция заработной платы: 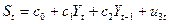
Тождество дохода: 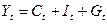
где Ct- расходы на конечное потребление в период t; Yt, Yt-1 — совокупный доход в периоды t, t-1 соответственно; It—валовые инвестиции периода t; St — расход на зарплату в период t; Gt— государственные расходы в году t; u1, u2, u3 — случайные ошибки.
Данная модель представляет собой систему одновременных уравнений, так как она содержит взаимозависимые переменные. Проверим выполнение порядкового условия идентификации для каждого уравнения модели пункт 1 задачи 3. В модели 4 эндогенных переменных, находящиеся в левой части каждого из уравнений. Это переменные: C_t,I_t,S_t,Y_t . остальные 2 переменные модели t и G_t — это экзогенные переменные. Кроме того, модель содержит лаговую эндогенную переменную Y_t-1 . Таким образом, общее число предопределенных переменных модели K = 3 .
Для первого уравнения m = 3 (в него входят эндогенные переменные C_t,I_t,S_t ), k = 1 (уравнение включает одну предопределенную переменную t ). Имеем: K - k = 3 - 1 = m - 1 = 3 - 1,
Следовательно, уравнение точно идентифицировано.
Для второго уравнения: m = 1 (I_t),k = 1 (Y_t-1) . Имеем:
K - k = 3 - 1 = 2 > m - 1 = 1 - 1 = 0,
Следовательно, второе уравнение сверх идентифицировано.
Для третьего уравнения: m = 2 (S_t,Y_t),k = 1 (Y_t-1) . Имеем:
K - k = 3 - 1 = 2 > m - 1 = 2 - 1 = 1,
Следовательно, третье уравнение сверх идентифицировано. Последнее уравнение модели представляет собой тождество, его не надо проверять на идентификацию. Приведенная форма модели пункт 2 имеет вид:
C_t = A_0 + A_1 Y_t-1 + A_2 G_t + A_3 t + \nu_1
I_t = B_0 + B_1 Y_t-1 + B_2 G_t + B_3 t + \nu_2
S_t = D_0 + D_1 Y_t-1 + D_2 G_t + D_3 t + \nu_3
Y_t = E_0 + E_1 Y_t-1 + E_2 G_t + E_3 t + \nu_2
Через заглавные буквы A,B,D,E обозначены приведенные коэффициенты модели v_1,v_2,v_3,v_4 — случайные ошибки (обозначения выбраны произвольно).
Следовательно, пункт 3, параметры первого уравнения модели можно оценить косвенным МНК. Для этого:
1) определим обычным МНК параметры каждого из уравнений приведенной формы модели;
2) выразим зависимость C_t = a_0 + a_1 Y_t + a_2 S_t + a_3 t + u_1 из приведенной формы модели.
Порядковое условие показало, что второе уравнение модели сверхидентифицировано. Однако заметим, что правая часть этого уравнения не содержит эндогенных переменных. Поэтому нарушения предпосылок обычного МНК не происходит, и параметры данного уравнения можно оценивать обычным МНК.
Третье уравнение модели сверхидентифицировано. В его правой части содержится эндогенная переменная Y_t , что приводит к нарушению предпосылок обычного МНК. Чтобы найти структурные параметры этого уравнения:
1) определим обычным МНК параметры четвертого уравнения приведенной формы модели;
2) найдем расчетные значения переменной Y_t :
Y_t = E_0 + E_1 Y_t-1 + E_2 G_t + E_3 t
3) Определим обычным МНК параметры третьего структурного уравнения, используя при построении системы нормальных уравнений данные о фактических значениях факторного признака Y_t-1 и результата S_t , а также данные о расчетных значениях факторного признака Y_t .
Задачи 4 и 5 посвящены теме «Модели стационарных и нестационарных временных рядов», и прежде всего проблеме автокорреляции уровней временного ряда и ее последействиям, а также наличию во временном ряде тенденции.
Временные ряды применяются для прогнозирования экономических показателей. При этом имеют ввиду кратко- и среднесрочные прогнозы, так как долгосрочные прогнозы требуют обязательного применения методов анализа специальных экспертных оценок.
Такие прогнозы нужны для:
Ø планирования в экономике, производстве, торговле;
Ø управления и оптимизации социально-экономических процессов;
Ø управления важными параметрами демографических процессов в экологии;
Ø принятия оптимальных решений в бизнесе.
Временной ряд отличается по своим свойствам от последовательности наблюдений х1, х2,…,хn, образующих случайную выборку, так как 1) члены временного ряда не являются статистически независимыми; 2) они не являются одинаково распределенными.
Основные факторы, формирующие значения членов временного ряда делятся на:
а) долговременные. Они формируют общую тенденцию изменений переменной x(t). Эта тенденция может быть описана функцией – трендом
b) сезонные. Они формируют периодически повторяющиеся в определенное время года колебания переменной x(t). Это воздействие может быть описано периодической функцией S(t) тригонометрического вида.
с) циклические (конъюнктурные). Они формируют изменения переменной x(t), обусловленные действиями долговременных циклов экономической, демографической, астрофизической природы (волны Кондратьева, демографические ямы, циклы солнечной активности).
d) случайные. Их воздействие обусловливает стохастическую (случайную) природу переменных x(t). Результат воздействия этих факторов обозначим с помощью случайных величин (остатков, ошибок). Они отражают влияние не поддающихся учету и регистрации случайных факторов.
Первые три составляющие компоненты являются закономерными (неслучайными).
В процессе формирования временного ряда не обязательно участвуют одновременно все эти факторы. Однако во всех случаях участие случайных факторов имеет место.
Основная цель регрессионного анализа – выявить систематические компоненты и оценить характер нерегулярности в случайной компоненте. Теорию ошибок можно применить для оценки адекватности эконометрической модели только в том случае, когда случайная компонента нерегулярна.
Рассматриваем процесс yt= ut + vt + et.
1. Графически представить и описать поведение временного ряда
2. Выявить временной тренд
3. Доказать отсутствие сезонных (циклических) колебаний и зависимости последующего уровня ряда от предыдущих, либо произвести их адекватный учет
4. Сгладить временной ряд (удаление низко- или высоко-частотных составляющих временного ряда)
5. Исследовать случайную составляющую временного ряда, построить и проверить адекватность математической модели для ее описания. Выявить автокорреляцию во временном ряду
6. Прогнозирование развития изучаемого процесса на основе имеющегося временного ряда
7. Исследование взаимосвязи между различными временными рядами.
Приступая к решению пункта 1 задачи 4, изучите вопрос об изменении автокорреляции уровней временного ряда. При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих.
Зависимость значений уровней временного ряда от предыдущего (сдвиг на один временной интервал), предпредыдущего (сдвиг на два временных интервала) и т.д. уровней того же временного ряда называется автокорреляцией во временном ряду.
Коэффициент автокорреляции первого порядка – линейный коэффициент корреляции между уровнями исходного временного ряда и уровнями того же ряда, сдвинутыми на один момент времени. Его расчет производится по стандартным формулам для расчета линейного коэффициента корреляции для пар наблюдений в моменты t и t-1, причем общее число пар наблюдений равно n-1. Если он близок к единице, то можно выявить наличие во временном ряде тенденции, т.е. высокая теснота связи между текущим и непосредственно предшествующим уровнями временного ряда.
Коэффициент автокорреляции порядка 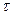 можно определить по формуле:
можно определить по формуле:
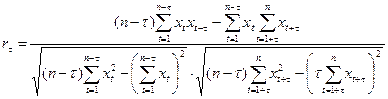 При расчете лаг выбирают из соотношения t£n/4.
При расчете лаг выбирают из соотношения t£n/4.
2 важных свойства коэффициента автокорреляции:
1) Он строится по аналогии с линейным коэффициентом корреляции и таким образом характеризует тесноту только линейной связи текущего и предыдущего уровней ряда. Поэтому по коэффициенту автокорреляции можно судить о наличии линейной (или близкой к линейной) тенденции. Для некоторых временных рядов, имеющих сильную нелинейную тенденцию (например, параболу второго порядка или экспоненту), коэффициент автокорреляции уровней исходного ряда может приближаться к нулю.
2) По знаку коэффициента автокорреляции нельзя делать вывод о возрастающей или убывающей тенденции в уровнях ряда. Большинство временных рядов экономических данных содержит положительную автокорреляцию уровней, однако при этом могут иметь убывающую тенденцию.
Последовательность коэффициентов автокорреляции уровней первого, второго и т.д. порядков называют автокорреляционной функцией временного ряда. График зависимости ее значений от величины лага (порядка коэффициента автокорреляции) называется коррелограммой.
Анализ автокорреляционной функции и коррелограммы позволяет определить лаг, при котором автокорреляция наиболее высокая, а следовательно, и лаг, при котором связь между предыдущими и текущим уровнями ряда наиболее тесная, т.е. при помощи анализа автокорреляционной функции и коррелограммы можно выявить структуру ряда.
Ø Если наиболее высоким оказался коэффициент автокорреляции первого порядка, исследуемый ряд содержит только тенденцию.
Ø Если наиболее высоким оказался коэффициент автокорреляции порядка t, ряд содержит циклические колебания с периодичностью в t моментов времени.
Ø Если ни один из коэффициентов автокорреляции не является значимым, можно сделать следующие предположения:
o ряд не содержит тенденции и циклических колебаний и имеет структуру случайной компоненты.
o ряд содержит сильную нелинейную тенденцию, для выявления которой нужно провести дополнительный анализ.
В пункте 2 требуется определить функциональную форму и найти параметры математического уравнения, наилучшим способом описывающего тенденцию, или тренда.
Существует несколько способов определения типа тенденции:
Ø качественный анализ изучаемого процесса,
Ø построение и визуальный анализ графика зависимости уровней ряда от времени
Ø расчет некоторых основных показателей динамики,
Ø расчет коэффициентов автокорреляции уровней ряда. Тип тенденции можно определить путем сравнения коэффициентов автокорреляции первого порядка, рассчитанных по исходным и преобразованным уровням ряда:
o если временной ряд имеет линейную тенденцию, то его соседние уровни тесно коррелируют; в этом случае коэффициент автокорреляции первого порядка уровней исходного ряда должен быть высоким.
o если временной ряд содержит нелинейную тенденцию, например, в форме экспоненты, то коэффициент автокорреляции первого порядка по логарифмам уровней исходного ряда будет выше, чем соответствующий коэффициент, рассчитанный по уровням ряда. Чем сильнее выражена нелинейная тенденция в изучаемом временном ряду, тем в большей степени будут различаться значения указанных коэффициентов. Выбор наилучшего уравнения в случае, если ряд содержит нелинейную тенденцию, можно осуществить путем перебора основных форм тренда, расчета по каждому уравнению скорректированного коэффициента детерминации и выбора уравнения тренда с максимальным значением скорректированного коэффициента детерминации.
Для расчета параметров уравнения тренда примените обычный МНК (значения независимой переменной t , как правило, принимаются равными 1,2,3,... ). В случае нелинейных зависимостей проведите ленеаризацию исходной функции. Дайте интерпретацию параметров тренда.
Коэффициент регрессии b в линейном тренде есть средний за период цепной прирост уровней ряда. В экспоненциальной функции величина (e^b) представяет собой средний за период цепной темп роста уровней ряда. Начальный уровень ряда в момент (период времени) 0 в линейном тренде выражается параметром a, в экспоненциальном тренде — величиной e^a .
Пример. По следующим данным (1;213), (2;171), (3;291), (4;309), (5; 317), (6; 362), (7; 351), (8, 361), где первый элемент пары – это номер года, а второй – спрос, найти среднее значение, среднее квадратическое отклонение, коэффициенты автокорреляции (для лагов, равных 1 и 2) и частный коэффициент автокорреляции первого порядка. Определить уравнение тренда для временного ряда, полагая тренд линейным.
Решение. Среднее значение равно 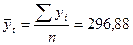 (ед.). Дисперсия равна
(ед.). Дисперсия равна 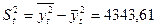 ;
; 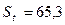 (ед.).
(ед.).
Найдем коэффициент автокорреляции r(t) временного ряда:
| yt | 213 | 171 | 291 | 309 | 317 | 362 | 351 |
| Yt+t | 171 | 291 | 309 | 317 | 362 | 351 | 361 |
Вычислим необходимые суммы: 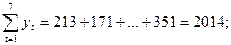
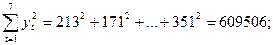
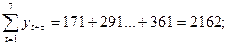
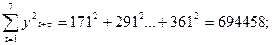
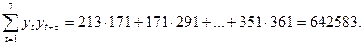
Теперь найдем коэффициент автокорреляции r(1)=0,725; r(2)=0,842. Коэффициента автокорреляции 1-го порядка для лага t=2 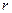 (2)=0,842. Для нахождения уравнения тренда определим
(2)=0,842. Для нахождения уравнения тренда определим 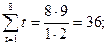
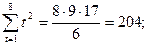
Теперь найдем 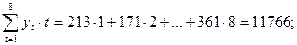
Из системы нормальных уравнений находим a=181,32; b=25,679 и уравнение тренда будет таким:
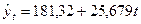 , т.е. спрос ежегодно увеличивается в среднем на 25,7 ед. Проверка по критерию Фишера показала, что уравнение тренда значимо.
, т.е. спрос ежегодно увеличивается в среднем на 25,7 ед. Проверка по критерию Фишера показала, что уравнение тренда значимо.
Пункт 3. Точечный прогноз в уравнении тренда — это расчетное значение переменной X_t, полученная путем подстановки в уравнение тренда значений t = n + 1 и т.д. Интервальный прогноз рассчитывается в соответствии с методикой, изложенной для уравнения парной линейной регрессии (см. указания к п.5 задачи 1). Например, по данным предыдущей задачи, найти точечный прогноз на 9-й год и интервальную оценку прогноза среднего значения спроса.
Решение. В уравнение регрессии подставим t=9 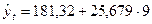 =412,4 (ед.) и найдем точечный прогноз.
=412,4 (ед.) и найдем точечный прогноз.
Для нахождения интервальной оценки прогноза вычислим tтабл.(0,95; 6)=2,45 и по формуле 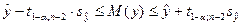 получим 346,9£у(ср.(9))£477,9 (ед.). Таким образом, с надежностью 95% среднее значение спроса на товар на 9 год будет заключено в интервале от 346,9 до 477, 9 единиц.
получим 346,9£у(ср.(9))£477,9 (ед.). Таким образом, с надежностью 95% среднее значение спроса на товар на 9 год будет заключено в интервале от 346,9 до 477, 9 единиц.
В задаче 5 исследуется специфика статистической оценки взаимосвязи двух временных рядов.
1) на предварительном этапе анализа временных рядов нужно выявить: содержат или нет ряды сезонные и циклические колебания. Если да, то необходимо устранить сезонную или циклическую компоненты из уровней каждого ряда, поскольку их наличие приведет к завышению истинных показателей силы и тесноты связи изучаемых временных рядов в случае, если оба ряда содержат циклические колебания одинаковой периодичности, либо к занижению этих показателей в случае, если сезонные или циклические колебания содержат только один из рядов или периодичность колебаний в рассматриваемых рядах различна. В дальнейшем будем предполагать, что изучаемые временные ряды не содержат периодических колебаний.
2) Для количественной характеристики зависимости между временными рядами используется линейный коэффициент корреляции. Если рассматриваемые временные ряды имеют тенденцию, коэффициент корреляции по абсолютной величине будет высоким. Но из этого еще нельзя сделать вывод о причинно- следственной связи между рядом Х и рядом У. Высокий коэффициент корреляции в данном случае будет потому, что х и у зависят от времени или содержат тенденцию. Пример: коэффициент корреляции между численностью выпускников ВУЗов и числом домов отдыха с 1970 по 1990 год составил 0,8.
Для того, чтобы получить коэффициенты корреляции, характеризующие причинно-следственную связь между изучаемыми рядами, следует избавиться от ложной корреляции, которая вызвана наличием тенденции в каждом ряду.
Наличие тенденции в каждом из временных рядов означает, что на зависимую переменную у и независимую переменную х оказывает воздействие фактор времени, который в модели непосредственно не учтен. Влияние фактора времени будет выражено в корреляционной зависимости между значениями остатков за текущий и предыдущий моменты времени, которая получила название «автокорреляция в остатках».
Методы исключения тенденции
Сущность всех методов исключения тенденции заключается в том, чтобы устранить или зафиксировать воздействие фактора времени на формирование уровней ряда. Основные методы исключения тенденции можно разделить на 2 группы:
1) методы, основанные на преобразовании уровней исходного ряда в новые переменные, не содержащие тенденции. Полученные переменные используются далее для анализа взаимосвязи изучаемых временных рядов. Эти методы предполагают непосредственное устранение трендовой компоненты Т из каждого уровня временного ряда. Здесь в свою очередь два основных метода:
a. метод последовательных разностей;
b. метод отклонений от трендов.
2) методы, основанные на изучении взаимосвязи исходных уровней временных рядов при элиминировании (исключении) воздействия фактора времени на зависимую переменную и независимые переменные модели. В первую очередь это метод включения в модель регрессии по временным рядам фактора времени.
Пример. Метод последовательных разностей
Основная задача – выявление основной тенденции изучаемого процесса, выраженной неслучайной составляющей f(t) (тренда либо тренда с циклической или (и) сезонной компонентой).
Для определения вида тренда (тенденции) рассчитайте
а) цепные абсолютные приросты d1=Xt-Xt-1;
b) абсолютные ускорения уровней ряда, или вторые разности: d2=dТ-dt-1
c) цепные коэффициенты роста: Kt=Xt-Xt-1 – логарифмы уровней ряда
Проанализируйте полученные результаты:
Ø если приблизительно одинаковые цепные абсолютные приросты, то следует выбрать линейный тренд (Xt=a+bt).
Ø если примерно постоянные абсолютные ускорения уровней ряда, следует выбрать параболу второго порядка (Xt=a+b1t+ b2t2).
Ø если примерно одинаковые цепные коэффициенты роста, моделирование тенденции следует проводить с использованием экспоненциальной кривой (Xt=ea+bt).
Для расчета параметров применить обычный метод МНК (значения t=1,2,3...). В случае нелинейных зависимостей провести линеаризацию исходной функции.
Из двух функций предпочтение отдать той, при которой меньше сумма квадратов отклонений фактических данных от расчетных на основе этих функций. Для выявления основной тенденции чаще всего используется метод наименьших квадратов. Значения временного ряда рассматриваются как зависимая переменная, а время t – как объясняющая: yt=f(t)+et, где et –возмущения, удовлетворяющие основным предпосылкам регрессионного анализа, т.е. представляют независимые и одинаково распределенные случайные величины, распределение которых предполагаем нормальным.
Интерпретация параметров тренда:
В линейном тренде b- это средний за период цепной прирост уровней ряда.
В экспоненциальной функции величина eb- это средний за период цепной темп роста уровней ряда.
Начальный уровень ряда в момент (в период времени) 0 в линейном тренде выражается параметром а, в экспоненциальном тренде – величиной еа.
Автокорреляция в остатках. Критерий Дарбина -Уотсона
Если вид функции тренда выбран неудачно, то вряд ли можно говорить о том, что отклонения от нее (возмущения et) являются независимыми. В этом случае наблюдается заметная концентрация положительных и отрицательных возмущений, и можно предполагать их взаимосвязь. Если последовательные значения коррелируют между собой, то говорят об автокорреляции возмущений (остатков, ошибок).
В случае выявления автокорреляции целесообразно вновь вернуться к проблеме спецификации уравнения регрессии (выбора функции тренда) пересмотреть набор, включенных в него переменных и т.п.
Существует два наиболее распространенных метода определения автокорреляции остатков. Первый метод – это построение графика зависимости остатков от времени и визуальное определение наличия или отсутствия автокорреляции.
Второй метод - наиболее простой и достаточно надежный критерий определения автокорреляции возмущений – критерий Дарбина – Уотсона. С помощью него проверяется гипотеза об отсутствии корреляции между соседними остаточными членами ряда еt и еt-1, где еt - выборочная оценка et. Статистика критерия имеет вид:
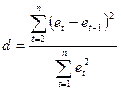 .
.
Алгоритм выявления автокорреляции остатков на основе критерия Дарбина-Уотсона следующий:
1) Выдвигается гипотеза Н0 об отсутствии автокорреляции остатков.
2) По специальным таблицам определяются критические значения критерия dL и dU для заданного числа наблюдений n, числа независимых переменных модели k и уровня значимости a. По этим значениям числовой промежуток [0; 4] разбивают на 5 отрезков:
| Есть положительная автокорреляция остатков. Н0 отклоняется. С вероятностью Р=(1-a) принимается Н1. | Зона неопределенности | Нет оснований отклонять Н0 (автокорреляция остатков отсутствует) | Зона неопределенности | Есть отрицательная автокорреляция остатков. Н0 отклоняется. С вероятностью Р=(1-a) принимается Н1* | ||||||
| 0 | dL | du | 2 | 4-dU | 4-dL |  4 4
| ||||
Статистика d заключена в границах от 0 до 4; при отсутствии автокорреляции d»2; при полной положительной автокорреляции d»0; при полной отрицательной d»4;
Для d-статистики найдены верхняя и нижняя критические границы на уровнях значимости a.=0,01; 0,025; и 0,05.
Если фактически наблюдаемое значение d попадает в зону неопределенности, то на практике предполагают существование автокорреляции остатков и отклоняют гипотезу Н0.
Недостатком критерия является наличие области неопределенности критерия, также методика расчета направлена только на выявление автокорреляции остатков первого порядка, а также то, что критические значения d-статистики определены для объемов выборки не менее 15.
Вопросы к экзамену
1. Основные понятия эконометрики (предмет эконометрики, особенности взаимосвязей экономических переменных, введение случайной компоненты в экономическую модель, понятие эконометрической модели, классификация эконометрических моделей).
2. Этапы построения эконометрической модели. Характеристика первого этапа.
3. Характеристика экономических данных
4. Основные понятия статистического анализа (случайная величина, распределение, основные распределения, числовые характеристики случайных величин.
5. Нормальный закон распределения. Распределение Стьюдента.
6. Статистическое оценивание параметров распределения: определение оценивания параметров распределения, формулировка задачи оценки параметров в общем виде, основные свойства оценок.
7. Метод наименьших квадратов (МНК).
8. Парная линейная регрессия (метод оценивания параметров линейной регрессии, требования к ошибкам ei, свойства оценок.
9. Анализ статистической значимости коэффициентов линейной регрессии.
10. Интерпретация коэффициентов парной линейной регрессии.
11. Анализ остатков. Критерий Дарбина-Уотсона (DW-критерий).
12. Оценка качества модели (коэффициент корреляции, индекс корреляции, коэффициент детерминации).
13. Методика множественного корреляционного анализа: этапы многофакторного корреляционного анализа, отбор факторов.
14. Описание этапа сбора и статистической оценки исходной информации в множественном корреляционном анализе.
15. Спецификация множественной регрессионной модели .(построение системы нормальных уравнений для двухфакторной линейной регрессии). Интерпретация коэффициентов множественной регрессии..
16. Анализ статистической значимости коэффициентов двухфакторной линейной регрессии. Парные и частные коэффициенты корреляции, их интерпретация.
17. Бетта-коэффициенты и коэффициенты эластичности, их назначение и интерпретация.
18. Оценка качества модели множественной регрессии: критерий Фишера. Множественные коэффициенты корреляции и детерминации.
19. Проверка условий, выполнение которых предполагалось при оценивании уравнения регрессии. Автокорреляция остатков. Критерий Дарбина-Уотсона.
20. Временные ряды, их характеристики.
21. Гомоскедастичность и гетероскедастичность. Причины гетероскедастичности. Обнаружение гетероскедастичности.
22. Тест ранговой корреляции Спирмена.
23. Общие сведения о временных рядах: понятие тренда, сезонной компоненты, циклической компоненты. Основные этапы анализа временных рядов.
24. Определение вида тренда. Расчет параметров тренда. Интерпретация параметров тренда.
25. Основные понятия системы одновременных уравнений. Проблема идентификации.
26. Методы расчета структурных параметров системы.
27. Экономическое прогнозирование на основе построенной модели.
28. Понятие ошибок при построении доверительного интервала.
Литература
Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. М.: ЮНИТИ,1998.
Доугерти К. Введение в эконометрику. М.: МГУ,1999.
Канторович Г.Г. Эконометрика //Методические материалы по экономическим дисциплинам для преподавателей средних школ и вузов. Экономическая статистика. Эконометрика. Программы, тесты, задачи, решения /Под ред. Л.С.Гребнева. М.: ГУ-ВШЭ, 2000.
Кремер Н.Ш., Путко Б.А. Эконометрика. М.:ЮНИТИ-ДАНА, 2002.
Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. М.: Дело, 1999.
Катышев П.К., Магнус Я.Р., Пересецкий А.А. Сборник задач к начальному курсу эконометрики. М.: Дело, 2002.
Практикум по эконометрике /Под ред. Н.И. Елисеевой. М.: Финансы и статистика, 2001.
Эконометрика /Под ред. Н.И. Елисеевой. М.: Финансы и статистика, 2001.
Экономико-математические методы и прикладные модели /Под ред. В.В. Федосеева. –М.: ЮНИТИ,1999.
О.О. Замков, Черемных Ю.А., Толстопятенко А.В. Математические методы в экономике. –М.: Дело и Сервис,1999.
Мардас А.Н. Эконометрика. –СПб.: Питер, 2001.
Дата: 2019-02-02, просмотров: 716.