Анотація
Лінійне рівняння регресії. Прогнозування в умовах невизначеності: тест рекурсивної оцінки коефіцієнтів регресії; тест рекурсивної оцінки значень Y; тест рекурсивної оцінки помилок регресії. Застосування матриць до моделі лінійної регресії.
5.1 Лінійне рівняння регресії
Припустимо, що члени ряду Y1, Y2, ..., Yn є реалізацією взаємно незалежних ідентичних нормальних випадкових величин, і члени ряду представлені нормальними випадковими величинами. Найбільш проста модель при цьому вийде, якщо припустити, що члени ряду мають одне й те ж стандартне відхилення, рівне σ, але відрізняються значеннями своїх математичних сподівань E(Yi). Зазвичай припускається, що E(Y) залежить від деякої величини X. Якщо ця залежність лінійна, то модель називається моделлю [парної] лінійної регресії. Коефіцієнти лінійного рівняння регресії приймаються за наближені значення коефіцієнтів моделі. У такому випадку:
 (5.1)
(5.1)
де і = 1, 2, ..., n;
β1, β2– не залежитьвід і, тобто являються константами моделі.
Ми отримаємо інше, більш поширене визначення моделі [парної] лінійної регресії, якщо зауважимо, що будь-яка випадкова величина Y з математичним очікуванням μ і стандартним відхиленням σ може бути представлена як Y = μ + ε, де випадкова величина ε має математичне сподівання, рівне нулю , і стандартне відхилення σε = σ.
Отже, статистична модель
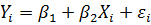 , (5.2)
, (5.2)
де і = 1, 2,..., n;
Yi – випадкова величина;
Xi - константа;
ε1, ε2, ..., εn – нормальнівипадкові величиниз одним і тим же математичним сподіванням, рівним 0, та стандартним відхиленням σ;
β1, β2 – константи моделі, що не залежатьвід і, називається моделлю [парної] лінійної регресії.
Параметри β1, β2 називаються коефіцієнтами регресії. Випадкові величини ε1, ε2, ..., εn називаються випадковими членами або помилками. Присутність випадкових членів в моделі означає, що залежність між Y і X не є строго лінійною. Ми також додатково припустимо, що ε1, ε2, ..., εn є взаємно незалежними випадковими величинами. Причому X називається регресором, а Y - залежною змінною. Коли ми говоримо, що Xi - константа, то мається на увазі, що вона є такою при фіксованому і, а при різних і X може приймати різні значення. Ми розглядаємо Yi як випадкову величину для фіксованого i. Якщо i ≠ j, то Yi і Yjбудуть різними випадковими величинами з різними математичними очікуваннями, рівними β1 + β2Хi і β1 + β2Хj відповідно, хоча і з однаковими стандартними відхиленнями, рівними σ.
Важливо відзначити, що в моделі (5.2) коефіцієнт β2 дорівнює середньому зміни в Y при збільшенні X на одиницю. Дійсно,
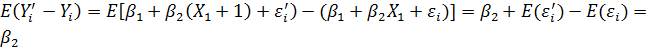 ,
,
де 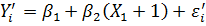
У прогнозуванні звичайно передбачається, що і = 1, 2, ..., n відповідають моментам часу, які мають однаковий крок (місяць, квартал і т.д.). Допускається, щоб деякі значення ібули відсутні. Не обов'язково також, щоб перше значення дорівнювало 1. Давайте розглянемо декілька прикладів.
1. Ми отримаємо модель, лінійно залежну від часу, якщо візьмемо Xi= і:
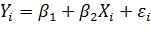 , де і = 1, 2, … , n.
, де і = 1, 2, … , n.
2. Якщо Xi = і2, то залежність Y від часу буде квадратичною:
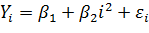 , де і = 1, 2, … , n.
, де і = 1, 2, … , n.
3. Якщо припустити, що Хi = Ln (і), то виходить логарифмічна модель:
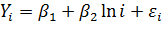 , де і = 1, 2, … , n.
, де і = 1, 2, … , n.
4. Розглянемо наступну модель, яку називають моделлю постійної еластичності:
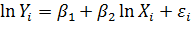 , де і = 1, 2, … , n.
, де і = 1, 2, … , n.
Вона буде еквівалентна моделі:
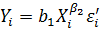 , де і = 1, 2, … , n.
, де і = 1, 2, … , n.
5. 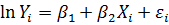 –модель при Xi = і еквівалентна моделі постійного зростання
–модель при Xi = і еквівалентна моделі постійного зростання 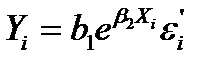 з тим же застереженням щодо випадкового члена εi, що і в попередній моделі.
з тим же застереженням щодо випадкового члена εi, що і в попередній моделі.
5.2 Прогнозування в умовах невизначеності: тест рекурсивної оцінки коефіцієнтів регресії; тест рекурсивної оцінки значень Y; тест рекурсивної оцінки помилок регресії
Тест рекурсивної оцінки коефіцієнтів регресії тісно пов'язаний з уже знайомою нам концепцією expost прогнозування. Ідея тесту полягає в побудові expost 95%-них довірчих інтервалів для коефіцієнтів β1 і β2. Для цього спочатку задають число k, за умови, що 0 < k < n. Зазвичай розглядають невеликі значення k, щоб можна було простежити динаміку зміни коефіцієнтів b1 і b2 на досить великому інтервалі. Потім для перших k даних знаходять коефіцієнти рівняння регресії b1(k) і b2(k) і відповідні 95%-ні довірчі інтервали для β1 і β2. Процедура повторюється для k + 1, k + 2 і т.д., аж до n. Динаміка зміни b2 і відповідних 95%-них довірчих інтервалів для β2 показана на рис. 5.1.
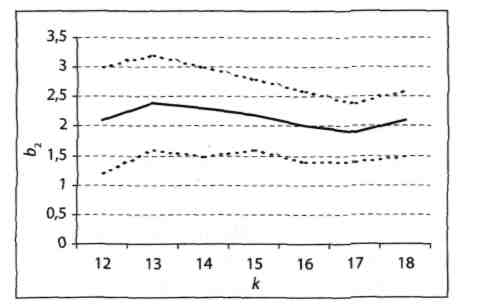
Рисунок 5.1 - Динаміка змін коефіцієнта b2 і відповідних 95%-них довірчих інтервалів для β2
Примітка. Середня лінія відповідає рекурсивним значенням b2, а пунктирні лінії позначають верхні та нижні межі відповідних довірчих інтервалів.
Для кожного значення k (12 ≤ k ≤ 18) відповідний 95%-ний інтервал з центром в b2(k) з імовірністю 95% містить параметр β2. Так як β2 є параметром моделі і не залежить від k, то той факт, що смуга на рис. 5.1 не має поступального руху вгору або вниз, а робить коливальні рухи навколо деякого числа, вказує на те, що процес, як видно, слідує моделі лінійної регресії.
Тест рекурсивної оцінки значень Y заснований на формулі:
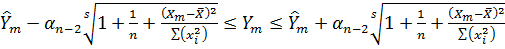 , (5.3)
, (5.3)
яку використовують при побудові 95%-них інтервалів прогнозу для значень Y. Він дає досить чітке уявлення про те, наскільки даний процес слідує моделі лінійної регресії. Тут, як і в попередньому тесті, ми задаємо число k в діапазоні 0 <k < n і потім за допомогою формули (5.3) визначаємо 95%-ний інтервал прогнозу Δк +1 для Yk +1, при заданих значеннях пар даних (X1, Y1), (X2, Y2),..., (Xk, Yk). Нагадаємо, що серединою інтервалу Δк +1 є expost прогноз. Випадкова величина Yk +1 з ймовірністю 95% повинна опинитися в інтервалі Δк +1. Потім ми додаємо пару даних (Xk+l, Yk+l) і повторюємо всю процедуру для k + 1 пар даних (X1, Y1), (X2, Y2),..., (Xk+1, Yk+1) і т.д. В результаті ми отримаємо рекурсивні інтервали Δk+1, Δk+2, ..., Δn. Серединою кожного такого інтервалу Δi буде значення expost прогнозу. Відповідні 95%-ні рекурсивні інтервали прогнозу для значень Y наведені на рис. 5.2.
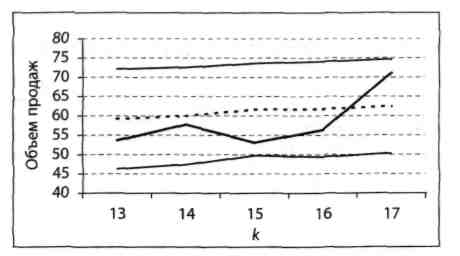
Рисунок 5.2 - 95%-і рекурсивні інтервали прогнозу для значень Y
Примітка. Окреслена напівжирним лінія в середині смуги відповідає даним за останні 5 кварталів.
Пунктирна лінія на рис. 5.2 показує значення expost прогнозів. І хоча вихідні дані з ними не збігаються, вони потрапляють в смугу, задану відповідними 95%-ними рекурсивними інтервалами прогнозу. Цей тест підтверджує висновок, отриманий в результаті розглянутого раніше тесту рекурсивної оцінки коефіцієнтів регресії, про те, що дані, можливо, слідують моделі лінійної регресії.
Зазвичай замість тесту рекурсивної оцінки значень Y, який ми тільки що вивчили, розглядається еквівалентний йому тест рекурсивної оцінки помилок регресії. Якщо ми позначимо довжину 95%-ного рекурсивного інтервалу прогнозу Δk як 2Lk, то формула (5.3) може бути записана в наступному вигляді:
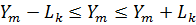 . (5.4)
. (5.4)
Нерівність (5.4) еквівалентна твердженню, що помилкаехpost прогнозування  зймовірністю 95% повинназнаходитись в інтервалі:
зймовірністю 95% повинназнаходитись в інтервалі: 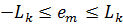 .
.
Як іу вище описаних тестах, тут задають число k в діапазоні 0 < k < n, а потім послідовно знаходять 95%-ніінтервали прогнозу [-Lk+1; Lk+1], [–Lk+2; Lk+2], ..., [-Ln; Ln] для помилок еk+1, ek+2, ..., еn. На рис. 5.3 представлені результати тесту рекурсивної оцінки помилок регресії.
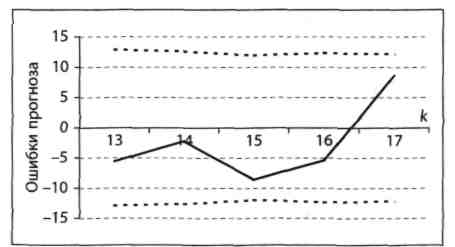
Рисунок 5.3 – Помилки expost прогнозів і відповідні 95%-ні рекурсивні інтервали прогнозу для помилок е
На рис. 5.3 дві пунктирні лінії, розташовані симетрично відносно горизонтальної осі, представляють границі 95%-них рекурсивних інтервалів прогнозу для помилок еі. Самі помилки представлені лінією між ними. Хоча значення помилок і не виходять за межі смуги, прогнозист може вирішити, що вони занадто великі.
У більшості випадків вони складають більше 10% від відповідних значень Y. Він може вирішити, що для отримання більш точного прогнозу потрібно врахувати вплив економічних та інших умов.
5.3 Застосування матриць до моделі лінійної регресії
Детермінований матричний предиктор має сенс будувати в тих ситуаціях, коли можливість застосування статистичних методів моделювання повністю виключена. Прикладом може служити ситуація, в якій дослідник володіє всього двома, трьома спостереженнями. Щоб перейти до формального опису моделі з таким предиктором, введемо позначення:
Хti – величина i-го показника у момент часу t;
Xt-1i– величина i-го показника у момент часу t-1;
D хti – величина зміни (приросту) i-го показника.
Далі природно припустити, що будь-яка зміна довільного i-го показника залежить від величини решти показників. Це може бути функціональна або регресійна залежність. Розглянемо випадок, коли малий об'єм ретроспективних даних не дозволяє реалізувати відомі методи ідентифікації цієї залежності. Єдино доступною альтернативою ідентифікації в подібній ситуації є підхід, заснований на значному спрощенні цієї залежності. В якості такої спрощеної форми зручно використовувати лінійне представлення приростів. Відразу помітимо, що модель, побудована за двома спостереженнями, не може претендувати на застосування для розрахунків, поширюваних за рамки, обкреслені короткостроковими прогнозами. Тому при розгляді короткострокових періодів таке спрощення не приводить до значного зростання помилки прогнозування навіть у тому випадку, коли істинна залежність явно нелінійна.
Модель цієї простої (лінійної) залежності будується в припущенні, що приріст будь-якого з показників формується під впливом всіх остаточних, будучи як би сумарною величиною, причому кожен показник окремо робить незначний вплив, і серед них немає домінуючих. Для реалізації цього припущення вводиться в розгляд характеристика, що встановлює ступінь впливу j-гo показника на зміни, що відбуваються в і-му. В якості такої характеристики зручно використовувати непрямий темп приросту
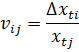
Якщо умовитися, що на формування приросту всі показники надають рівномірну дію, то, розділивши nij на (n–1), одержимо ту частку в прирості i-го показника, яка сформована під впливом j-го. Використання введеної міри ступеня впливу j-го показника на i-й дозволяє виразити приріст Dхt через суму добутків
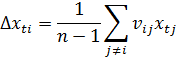
Враховуючи, що Dхti = xti – xt–1 можна величину будь-якого і-го показника представити у вигляді суми попереднього значення xti і приросту Dхti:
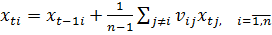 .
.
Для одержаної системи рівнянь (5.3), ввівши позначення
 .
.
можна використовувати компактний матричний запис
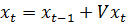 .
.
Вважаючи, що невідомим вектором в цій системі є хt, запишемо його таким чином:
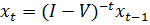 , (5.5)
, (5.5)
де через I позначена одинична матриця.
Зворотну матрицю (I–V)-1 називатимемо матричним предиктором. Він визначає перехід із стану, описуваного вектором значень попереднього моменту часу, в стан, представлений вектором значень теперішнього моменту часу. Позадіагональні елементи зворотної матриці інтерпретуються як непрямі темпи зростання рівномірно розподілених частин прогнозованих показників, а діагональні – як прямі темпи зростання частини, що залишилася.
У припущенні, що матричний предиктор перспективного періоду майже не відрізняється від матричного мультиплікатора поточного періоду, вираз (5.5) дозволяє розраховувати прогнозні оцінки. Основна перевага даного підходу полягає у тому, що з його допомогою можна проводити розрахунки для багатовимірних рядів динаміки навіть у тому випадку, коли дослідник має в своєму розпорядженні спостереження лише за два періоди. Правда, статистична надійність таких прогнозних розрахунків не перевіряється і спирається, в основному, на ту обставину, що навіть при зміні характеру динаміки прогнозованих процесів структура самого предиктора, як правило, змінюється трохи. Як показує практика прогнозних розрахунків, застосування цієї моделі переважно звичних розрахунків з використанням темпів зростання, в яких зовсім не враховується взаємодія між модельованими показниками.
Дата: 2018-12-21, просмотров: 363.