Задача статистического регулирования технологического процесса состоит в том, чтобы на основании результатов периодического контроля выборок малого объема принимать решение «процесс налажен» или «процесс разлажен». Поскольку разладки технологического процесса происходят в случайные моменты времени и эти события подчиняются определенным статистическим закономерностям, то такая задача решается методами математической статистики. Рассмотрим простейшую схему такой задачи. Выдвигаются две гипотезы: нулевая гипотеза Но - технологический процесс налажен, если параметр Ө распределения контролируемого показателя качества X равен Ө 0, и альтернативная гипотеза Н1- технологический процесс разлажен, если параметр Ө равен Ө1. В общем виде это записывается следующим образом:
Но: Ө = Ө 0 (технологический процесс налажен);
Н1: Ө = Ө1 (технологический процесс разлажен).
На основании результатов контроля единиц продукции из выборки х1, х2,..., xn можно с помощью определенных статистических критериев (о которых будет сказано далее) принять одну из этих двух гипотез.
Как мы помним, случайная величина X может быть непрерывной или дискретной. Например, диаметр отверстия представляет собой непрерывную случайную величину, которая теоретически может принимать все значения в интервале, ограниченном допуском, скажем, между 34,5 и 35,5 мм. Практически эти значения ограничиваются определенной точностью измерительных средств. Непрерывную величину мы получаем при контроле качества продукции по количественному признаку с помощью измерительных средств, позволяющих получить значение контролируемого параметра с большой точностью.
Дискретную величину мы получаем, например, при контроле качества продукции по альтернативному признаку, т. е. по признаку годен или не годен. В результате такого контроля мы подсчитываем число дефектных единиц продукции или число дефектов. При этом нас не интересует истинное значение параметра X, достаточно лишь установить, соответствует ли оно установленному допуску, соответствует ли установленному образцу или нет.
Наиболее часто применяемым при решении задач статистического контроля качества распределением непрерывной случайной величины X является нормальное распределение 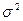 .
.
Как известно, нормальное распределение определяется двумя параметрами: математическим ожиданием µ и дисперсией 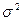 .
.
При статистическом регулировании технологических процессов при нормальном распределении случайной величины X проверяют гипотезы:
Но : μ = μ0 (технологический процесс налажен);
H1 : μ = μ1 (технологический процесс разлажен),
если разладка связана с изменением математического ожидания μ.
Если же разладка связана с увеличением дисперсии σ2, то в этом случае проверяют гипотезы:
Н0 : σ = σ 0 (технологический процесс налажен);
Н1: σ = σ 1 (технологический процесс разлажен).
При статистическом регулировании в качестве средних значений обычно используют выборочное среднее арифметическое 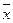 или выборочную медиану Ме, а в качестве меры рассеяния — выборочное среднее квадратическое отклонение S или выборочную дисперсию S2 или размах R.
или выборочную медиану Ме, а в качестве меры рассеяния — выборочное среднее квадратическое отклонение S или выборочную дисперсию S2 или размах R.
При выборе между средним арифметическим и медианой, а также между средним квадратическим отклонением и размахом надо учитывать следующие соображения. Среднее арифметическое является более эффективной статистикой, чем медиана (при нормальном распределении контролируемого параметра X), что позволяет при равных исходных условиях использовать объем выборки примерно в полтора раза меньший. Точно также среднее квадратическое отклонение является более эффективной статистикой, чем размах, что также позволяет использовать существенно меньший объем выборки. Однако вычисление медианы и размаха проще среднего арифметического и среднего квадратического отклонений, поэтому первым двум статистикам иногда отдают предпочтение.
В случае, когда контролируемым показателем качества является дискретная случайная величина, подчиняющаяся биномиальному или пуассоновскому законам распределения, разладка процесса характеризуется увеличением доли дефектной продукции от значения р0 до значения p1. В этом случае проверяют гипотезы:
Но: р = р0 (технологический процесс налажен);
Н1:р = р1 (технологический процесс разлажен).
Технологический процесс должен обеспечивать на выходе продукцию, полностью соответствующую всем требованиям, т. е. с показателями качества, значения которых лежат внутри установленных для них допусков. «Вылет» за пределы допуска не допустим, это - брак.
При серийном и массовом производстве, как известно, для множества однотипных изделий по каждому показателю качества можно построить гистограмму и распределение, например, нормальное. «Хвосты» распределения всегда выходят за пределы допуска, показывая, что образуется брак. Вероятность появления брака всегда можно вычислить с помощью функции нормального распределения.
Требования к технологическому процессу. Уровень несоответствий
Современная продукция, особенно сложные технические изделия, состоит из сотен и даже тысяч элементов, изготовляемых независимо. При этом несоответствия по важным (ключевым) показателям качества для компонентов или сборки приводят к тем или иным дефектам в готовой продукции. При этом вероятность (или доля) бездефектной продукции Pбездеф (по всем показателям) может быть рассчитана но формуле:
Pбездеф=(1-q1)(1-q2)….(1-qk), (84)
где q1 ....qk — вероятности (доли) несоответствий, но отдельным ключевым показателям качества компонентов и операций сборки продукции.
Уровень несоответствий определяется в единицах ppm. Ppm – количество дефектных изделий на миллион.
Если вероятность (доля) несоответствий по каждому отдельному показателю составляет всего 10 ppm (для большинства наших технологических процессов сегодня — это недостижимо), то при числе ключевых показателей 1000 получим
Pбездеф=1-(10 ppm ·1000)=1-0,01=0,99.
Таким образом, даже при таких «идеальных» технологических процессах мы уже будем иметь 1% дефектной продукции.
10 ppm - это малая величина, которая «неподвластна» контролю качества, ведь это всего 10 элементов с отклонением за пределы допуска на миллион выпушенных. Контроль, но принципу «годен — негоден», т. е.. по альтернативному признаку с участием человека «не чувствует» таких величин. Контролеры даже при сплошном контроле будут пропускать несоответствия из-за «потери бдительности». Необходимо организовать работу процессов так, чтобы они сами по себе обеспечивали эти «малые ppm». Для этого процесс должен обеспечивать относительно малый разброс показателя качества, существенно меньший, чем ширина поля допуска. Но это возможно только при абсолютной стабильности процесса. Даже незначительное отклонение технологического процесса по настройке может приводить к увеличению «вылетов» значений показателя качества за пределы допуска в десятки раз.
От процесса требуется следующее:
1. Процесс должен обеспечивать весьма малый естественный разброс показателя качества, т. е. «присущий процессу» разброс должен быть достаточно мал, параметр σ должен быть не более 1/10 или в крайнем случае - 1/8 поля допуска. А центр настройки процесса (параметр 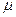 ) должен лежать в центре поля допуска или незначительно от него отстоять.
) должен лежать в центре поля допуска или незначительно от него отстоять.
2. Процесс должен быть стабильным, т. е. нужно сделать так, чтобы = const и σ = const. Только в этом случае не будет происходить неожиданного увеличения несоответствий из-за отклонения 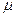 и при возрастании σ. А это значит, что необходимо выявить те факторы и причины, которые приводят к дестабилизации процесса.
и при возрастании σ. А это значит, что необходимо выявить те факторы и причины, которые приводят к дестабилизации процесса.
Таким образом, необходимо экспериментально определить, какие факторы влияют на изменение центра настройки конкретного технологического процесса (т.е на изменение параметра ) и какие - на изменение (увеличение) разброса процесса (т.е. на увеличение параметра 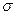 ).
).
Например, используя очень точное оборудование можно выявить влияние свойств сырья на входе процесса или технологических режимов на качество готовой продукции. При увеличении разброса показателей качества на выходе технологического процесса общее стандартное отклонение процесса увеличится, а значит, увеличатся и «вылеты» за границы допуска. Причиной этого является не само оборудование, а плохая организация процесса, т.е. внешние факторы, которые нужно найти и ликвидировать.
Очень многие количественно измеримые показатели при многократных измерениях достаточно точно могут быть описаны нормальным законом распределения. Это, например, такие показатели качества, как геометрические размеры, твердость, толщина покрытия и т. д. Отдельные значения данного показателя качества X разбросаны вокруг общего среднего значения , которое является фактическим центром настройки технологического процесса, а величина разброса индивидуальных значений X вокруг характеризуется значением σ, которое является средней величиной отклонения одного значения X от . Таким образом, отражает настройку (наладку) технологического процесса и является центральным фактическим значением показателя X в текущее время работы технологического процесса, а σ отражает разброс технологического процесса, т. е. его «кучность». Чем меньше σ, тем меньше разброс, точки лежат «кучнее», т. е. тем выше технологическая точность.
В практических задачах точно определить и σ невозможно, но можно по выборочным значениям х1, х2, …. хn (n — объем выборки) произвести оценки
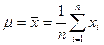 ; (86)
; (86)
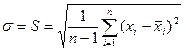 (87)
(87)
где 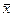 -функция выборочного среднего арифметического;
-функция выборочного среднего арифметического;
S - функция выборочного среднего квадратического отклонения при неизвестном .
На рисунке 17 изображена плотность нормального распределения (называемая «гауссовой кривой») W( x) и доли распределения в различных интервалах.Величина W(х) при разных значениях х показывает, как «плотно», как «густо» лежат индивидуальные значения х в том или ином месте числовой осп. Площадь под всей кривой W( x) равна единице, а площадь под W(х) внутри любого заданного интервала равна вероятности попадания или доле продукции внутри данного интервала (по показателю качества х).

|






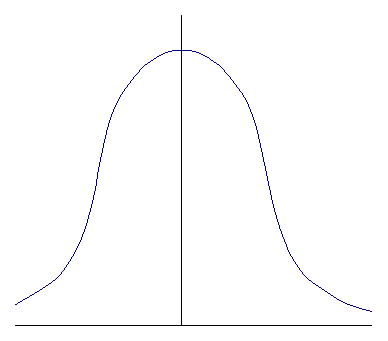
± σ доля = 68,26 %

± 2σ доля = 95,44 %
 |
± 3σ доля = 99,73 %
 |
Рисунок 17 – Плотность нормального распределения
Как видно из рисунка 17, чем шире интервал по сравнению с величиной σ, тем большая доля распределения будет попадать в этот интервал. Однако «хвосты» распределения всегда выходят за границы интервала и резко убывают при увеличении числа «сигм».
Если указываемый интервал - это допуск на данный показатель качества, а гауссова кривая с известными или оцененными σ и описывает поведение технологического процесса в данный период времени, то, как это очевидно из графического представления, можно вычислить (оценить, предсказать) долю соответствующей продукции и доли с завышенным и заниженным значениями показателя качества. Долю продукции в единицах ppm за пределом одной из границ допуска можно оценить при помощи показателей (индексов) возможностей.
Для понимания статистической методологии и для практической работы с технологическими процессами важно, чтобы технологи, специалисты службы качества и другие сотрудники представляли поведение технологического процесса в текущий момент времени в виде гауссовой кривой. Важно также, чтобы специалисты хорошо понимали (желательно, в количественных оценках) зависимость долей несоответствующей продукции от величин параметров и σ:
1) при смещении центра настройки технологического процесса ( ) от центра поля допуска суммарный уровень несоответствий (суммарная доля заниженных и завышенных значений) возрастает.
2) при расширении гауссовой кривой (т. е. увеличении среднего разброса, увеличении σ) уровень несоответствий по обе стороны допуска возрастает, поэтому важно обеспечить стабильность технологического процесса по центру настройки и величине разброса.
Важно отмстить еще одно свойство нормального распределения, касающееся выборочного среднего арифметического. Если из стабильного процесса с нормальным распределением W(х) берутся выборки постоянного объема n и по каждой такой выборке вычисляется среднее арифметическое значение, то:
- выборочные средние арифметические значения 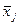 (j — номер выборки) являются случайными величинами, распределенными по нормальному закону W(
(j — номер выборки) являются случайными величинами, распределенными по нормальному закону W( 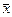 ) с параметрами
) с параметрами 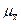 и
и 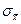 , причем центр распределения W(
, причем центр распределения W( 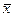 ) совпадает с центром исходного распределении W(х), т. е.
) совпадает с центром исходного распределении W(х), т. е.
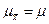 , (88)
, (88)
- средние арифметические имеют разброс в 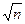 раз меньший, чем отдельные выборочные значения , т. е.:
раз меньший, чем отдельные выборочные значения , т. е.:
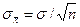 . (89)
. (89)
Соотношение распределений W(х) и W( 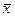 ) изображено на рисунке 18.
) изображено на рисунке 18.
|

|
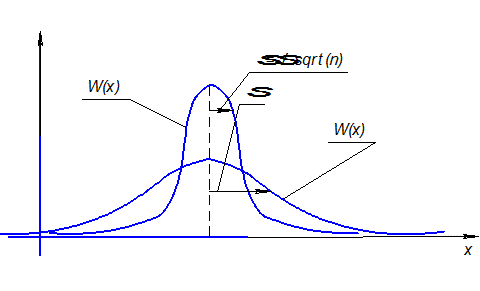
Рисунок 18 – Соотношение распределений W(х) и W( 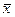 )
)
Отсюда следуют важные выводы:
- среднее арифметическое (даже по большой выборке) не является истинным центром настройки технологического процесса (центром распределения ), но дает возможность оценить более точно, чем отдельные выборочные значения xj.
Это свойство, в частности, интуитивно использует опытный наладчик станка-автомата: он делает несколько пробных деталей, вычисляет или оценивает «на глаз» среднее арифметическое, а затем корректирует настройку станка, учитывает отличие этого среднего от требуемого целевого значения настройки. Он делает так, потому, что знает из практики: по среднему настройка получается точнее, чем по индивидуальным значениям. Возможная погрешность будет в 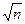 раз меньше, где n – число изготовленных пробных деталей;
раз меньше, где n – число изготовленных пробных деталей;
- соотношение (89) позволяет определять необходимый объём выборки для заданной точности оценки , например, при настройке технологического процесса. Необходимо обеспечить, чтобы за время взятия этой выборки процесс оставался стабильным, т. е. чтобы было =const; σ =const. Иначе увеличение n бессмысленно.
Следует отметить также, что даже если исходное распределение W( x) не совсем нормальное, то W( 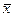 ) будет значительно ближе к нормальному, чем исходное. Это позволяет успешно применять контрольные карты Шухарта с несколькими выборками, даже если исходное распределение отличается от нормального.
) будет значительно ближе к нормальному, чем исходное. Это позволяет успешно применять контрольные карты Шухарта с несколькими выборками, даже если исходное распределение отличается от нормального.
Литература:
1. Пора заняться технологическим процессом [Текст] / М. И. Розно // Методы менеджмента качества. – 2004.- № 7. – С. 39-45
ЛЕКЦИЯ № 16 (4 ч)
Дата: 2018-11-18, просмотров: 469.