Язык LISP, разработанный Джоном Маккарти первоначально рассматривался как язык обработки списков или как язык обработки символьной информации. Однако, впоследствии оказалось, что язык LISP является адекватным средством программной реализации алгоритмов записанных в виде определения функции. Синтаксис языка LISP позволяет практически один-в-один переводить функциональную нотацию в программу, например, функция, вычисляющая максимум из двух чисел записывается математически как:
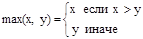
и на языке LISP : (defun max (x y) (if (> x y) x y)).
Язык программирования LISP содержит большой набор предопределенных функций и предоставляет средства определения новых. Для компоновки законченной программы из набора вспомогательных функций используется суперпозиция (вложенность) функций с возможностью рекурсивного вызова. В LISP'е имеются средства позволяющие управлять процессом вычисления функций и передачей значений от одной функции к другой. Выбранный способ представления функции (в виде списка) позволяет реализовывать не только обычные функции, но и функционалы, т.е. функции которые в качестве своего аргумента и (или) возвращаемого значения используют другие функции.
Функциональное программирование - это способ составления программ, в которых единственным действием является вызов функции, единственным способом расчленения программы на части является описание функции, т. е. задание ее имени и выражения для ее вычисления, а единственным правилом композиции - оператор суперпозиции функции. Никаких ячеек памяти, ни операторов присваивания, ни циклов, ни блок-схем, ни передач управления. Язык LISP подходит под это описание, его можно считать функциональным языком программирования.
В настоящее время существует множество диалектов языка LISP: FreeLISP, XLISP, muLISP, CommonLISP и т. д.. Некоторых из них содержат элементы нетипичные для функционального подхода к программированию (блок, цикл и т.п.). Появление подобных конструкций скорее дань традиции, чем насущная необходимость. В предлагаемом пособии мы рассмотрим те средства языка, которые являются необходимыми для реализации функционального стиля программирования.
2.1. Атомы и списки. Функции
Язык программирования LISP оперирует с двумя основными структурами данных - атомами и списками.
Списком называется последовательность элементов, заключенных в скобки, элементом списка может быть либо атом, либо список. Используя формальное определение, можно записать вышесказанное следующими формулами:
<список> ::= <пустой список> | (<список без скобок>)
<список без скобок> ::= <голова списка> <хвост списка>
< голова списка> ::= <атом> | <список>
< хвост списка> ::= <список без скобок>
В качестве разделителей элементов списка обычно используется пробел (несколько пробелов подряд воспринимаются как один). Примеры списков:
(A B C D E)
(1 2 3 4 5 6)
(1 (2 3) (4 (5 6)))
(TEST)
()
Второй и третий примеры - разные списки, т.к. они состоят из разных элементов. Первый - построен только из атомов, второй – из атома и двух списков. Четвертый пример - список из одного элемента - атома, атом TEST и список (TEST) - разные объекты. Последний пример - пустой список, он не содержит каких-либо элементов. Пустой список эквивалентен атому nil.
Кроме представления различных объектов для обработки, списки используются для вызова функций. В этом случае, интерпретатор языка LISP воспринимает первый элемент списка как имя функции, а остальные элементы списка - как ее аргументы. Например:
(+ 2 2) --> 4
(* (+ 3 2) (- 3 2)) --> 5
здесь использованы функции арифметических операций сложения, умножения и вычитания. Списки. представляющие вызов функции, называются S-выражениями.
Атом - элементарный объект, не имеющий структуры, он не может быть разбит на составные части. Атомы и списки в LISPе не являются типами данных в том смысле, как это понимается в процедурных языках программирования. Это структуры, предоставляющие способ представления одних объектов через совокупность других (обычно более простых), и ничего более. В языке нет ограничений на множество значений принимаемых атомами или списками.
В программе на языке LISP атомы могут обозначать константы и функции, имеющие фиксированный смысл; определенные пользователем константы, переменные и функции; и, наконец, атомы могут обозначать самих себя, т.е. те последовательности символов, которыми атомы изображаются. Последнее обстоятельство позволяет использовать язык LISP в качестве базового языка при организации символьных и аналитических вычислений, так как дает возможность работать с объектами, которым не присвоено никакого конкретного значения. В отличие от переменных в процедурных языках программирования атомы в LISPе.
1) могут не принадлежать какому-либо определенному типу (вещественная переменная, символьная переменная),
2) могут не иметь определенного значение фиксированного типа,
3) могут не быть связанными с областью памяти для хранения этих значений.
Атомы в языке LISP могут быть свободными или связанными. Свободный атом обозначает сам себя, т.е. последовательность символов, образующих его имя. Обозначим стрелкой «-->« связь любого допустимого в языке LISP выражения с его значением. Тогда
127 --> 127
TRUE --> TRUE
Связанный атом в качестве своего значения может иметь любое допустимое LISP-выражение: атом или список. Установить некоторое значение атома (связать его) или изменить значение, установленное ранее, можно с помощью операции присвоения, для обозначения которой используется функция setq. Например:
(setq A 26) A --> 26
(setq BETA Z1) BETA --> Z1
(setq D DELTA) D --> DELTA
(setq X A) X --> 26
В первом примере атом A приобретет числовое значение 26. В четвертом примере атом X получит значение 26, т.к. вместо атома A в момент подстановки будет использовано его значение.
В некоторых версиях языка LISP атомы изначально являются не связанными ни с какими значениями. В этом случае, если мы хотим в качестве значения атома установить его самого, можно воспользоваться присваиванием (setq A (quote A)) или (setq A 'A).
Функция quoteили'не вычисляет свой аргумент, а переносит его один к одному и выдает в качестве результата. Она является важной функцией языка, т.к. позволяет задать отличие списка, предназначенного для обработки от списка, определяющего S-выражение. Например, следующие похожие вызовы приведут к разным результатам:
(setq X '(A B C)) X --> (A B C)
(setq X (A B C))ошибка, не определена функция A.
Особую роль в языке играют атомы T и nil. В логических выражениях они имеют значение «истина» и «ложь», соответственно. Кроме того, атом nil эквивалентен пустому списку. Числовые атомы, имена которых состоят из последовательности цифр, в качестве своего значения имеют соответствующее число, и это значение не может быть изменено.
Списки являются основной структурой данных языка LISP. При помощи списков можно представить практически любой математический объект: множество, тензор, граф, и т. д.. Функции также могут быть представлены в виде списка (S-выражения). Последнее утверждение имеет далеко идущие последствия, т.к. любая программа на языке LISP является какой-либо функцией, которая может иметь своим значением список представляющий другую функцию. Иными словами, исполнение программы на LISP'е может приводить к порождению новой программы.
2.2. Функции работы со списками.
Поскольку списки являются основными структурами данных в языке LISP, постольку основными функциями языка следует считать функции работы со списками.
Первая из них функция list - предназначена для построения списка. Функция list имеет произвольное число аргументов и в качестве своего значения возвращает список, составленный из значений своих аргументов:
(list 1 2 3) --> (1 2 3)
(setq A 1)
(setq B 2)
(setq C 3)
(list A B C) --> (1 2 3)
(list (list 1 2) (list 3 4)) --> ((1 2) (3 4))
В последнем случае список состоит из двух элементов, которые в свою очередь являются списками: (1 2) и (3 4).
Далее, для выделения элементов списка предназначены функции car и cdr. В качестве своего аргумента эти функции должны получать список, а возвращаемыми значениями будут голова списка и хвост списка соответственно (см. формальное определение списка приведенное ранее). Например:
(car '(A B C)) --> A
(cdr '(A B C)) --> (B C)
(car (list 1 2 3)) --> 1
(cdr (list 1 2 3)) --> (2 3)
(setq L (list (list 1 2) (list 3 4)))
L --> ((1 2) (3 4))
(car L) --> (1 2)- голова списка L
(cdr L) --> ((3 4)) -хвост списка L
Для выделения произвольного элемента списка используется суперпозиции функций car и cdr:
(setq L (list 1 2 3 4))
L --> (1 2 3 4)
(car L) --> 1
(car (cdr L)) --> 2
(car (cdr (cdr L))) --> 3
Поскольку различные комбинации car и cdr используются довольно часто, то в языке LISP имеется возможность порождать специальные имена функций, эквивалентных комбинациям car и cdr. Имена таких функций начинаются с символа «c», затем произвольная комбинация символов «a» и «d» и завершающий символ «r». Каждый символ «a» в такой комбинации имени функции соответствует вызову функции car, а символ «d» - cdr. То есть, (cddar X)эквивалентно(cdr (cdr (car X))).Для выделения второго элемента списка можно использовать функцию cadr, третьего - caddr, четвертого - cadddr и т.д.
Функция cons служит для добавления в список нового элемента. Она имеет два аргумента, второй аргумент обычно является списком, а первый - добавляется в этот список в качестве головы и результат возвращается в качестве значения функции. Другими словами, функция cons собирает вместе то, что функции car и cdr разбили на части. Если L - произвольный список, то (cons (car L) (cdr L)) --> L.
Еще примеры:
(cons 1 (list a b c)) --> (1 a b c)
(cons (list 1) (list a b c)) --> ((1) a b c)
2.3. Основные функции
Наряду с функциями car, cdr, cons и listосновными считаются следующие функции.
Функции, вырабатывающие логические значения, называются предикатами. Атом T используется как стандартное обозначение логического значения «истина», атом nil - «ложь». Одним из примеров предиката является часто используемая функция atom. Её аргументом может быть любое выражение. Функция возвращает значение T, если значением аргумента является атом, и nil в противном случае. Например:
(atom 734) --> T
(atom (list 1 2 3)) --> nil
Функция null проверяет: является список пустым или нет:
(null (list 1 2 3)) --> nil
(null (cdr (list 1))) --> T
В языке LISP реализованы основные арифметические операции. Внешнее их представление близко к математической записи и не требует подробных комментариев. Символы +, -, *, / обозначают операции сложения, вычитания, умножения и деления соответственно.
(+ 2 3) --> 5
(* (+ (- 5 1) 7) 2) --> 18
В языке LISP для числовых атомов определены встроенные функции сравнения: «<« - меньше, «>« - больше, «=« - равно, «/=« - неравно:
(> 7 5) --> T
(= 6 3) --> nil
(setq three 3)
(<three 3) --> nil
Перечисленные функции сравнения применимы только к числовым аргументам. Для нечисловых аргументов используется функция eq (neq). Списки произвольной структуры позволяет сравнивать функция equal. Например,
(setq A '(1 (2 3) 4))
(equal A '(1 (2 3) 4)) --> T
(equal A '(1 2 3 4)) --> nil
Для выбора одного из двух вариантов нахождения значения функции предназначена условная функция if. Эта функция имеет три аргумента, если значение первого аргумента «истина», то функцией возвращается значение второго аргумента, в противном случае - третьего:
(if T a1 a2) --> a1
(if nil a1 a2) --> a2
Если необходимо выбирать более чем из двух вариантов – можно воспользоваться условным выражением cond. Функция cond имеет произвольное число аргументов, каждый из которых должен быть списком из двух элементов. При вычислении функции cond LISP просматривает поочередно каждую пару начиная с первой, если значение первого элемента очередной пары «истина», то возвращается значение второго элемента пары и обработка функции cond прекращается, в противном случае происходит переход к следующей паре. Если ни в одной паре первый элемент не имеет значение «истина», то значение функции cond будет nil. Во избежание этого в качестве первого элемента последней пары следует использовать атом T. Например:
(cond ((= N 0) 1)
(T (* N (- N 1))))
(cond ((= X 0) 0)
((< X 0) -1)
(T 1) )
Функция cond может быть представлена как суперпозиция нескольких функций if:
(cond (<t1> <e1>)
(<t2> <e2>)
...
(T <eN>) )
эквивалентно
(if <t1> <e1> (if <t2> <e2> (... <eN>) ... ))
Функцию cond не следует отождествлять с условным оператором и ее использование вполне допустимо при реализации функциональных алгоритмов.
2.4. Функции ввода/вывода
Непосредственное чтение из файла осуществляется функциями read и readch. Обе эти функции не имеют параметров.
Функция readch в качестве значения возвращает следующий символ из текущего файла ввода.
Функция read в качестве значения возвращает лисповское выражение (список или атом) из текущего файла ввода. Как только интерпретатор встречает (read), вычисления приостанавливаются до тех пор, пока пользователь (если текущим устройством ввода является клавиатура) не закончит ввод. Функция read «читает» выражение и возвращает в качестве значения само это выражение, после чего вычисления продолжаются.
У приведенного выше вызова функции read не было аргументов, но у этой функции есть значение, которое совпадает с введенным выражением. По своему действию read представляет собой функцию, но у нее есть побочный эффект, состоящий именно в том, что вводится выражения. В силу этого, read является не совсем «чистой» функцией. Будем называть такие функции «функциями с побочным эффектом» или псевдофункциями.
Если прочитанное значение необходимо сохранить для дальнейшего использования, то вызов read должен быть аргументом функции присваивания, например, setq, которая свяжет полученное выражение с заданным атомом. Например:
(setq input (read))
(+ 2 3)
Input
(+ 2 3)
Функция read совместно с другими функциями позволяют читать выражения внешние по отношению к программе. Из них можно строить новые выражения или новые программы.
Функция print выводит в файл, уже выбранный для вывода вычисленное значение аргумента и символ «перевод строки». Например:
$ (print "Вывод текста на экран!")
Вывод текста на экран!
Как и функция read,print является псевдофункцией, у которой есть как побочный эффект, так и значение. Значением функции является значение ее аргумента, а побочным эффектом - печать этого значения.
Отметим, что функции ввода-вывода очень гибки, поскольку их можно использовать в качестве аргументов других функций. Например:
(+ (print 2) 3)
Если мы используем print на самом верхнем уровне, S-выражение печатается дважды. Причиной этого служит то, что функция print (так же, как и read в подобной ситуации) не только используется для своего действия (печати), но, кроме того, имеет и значение (этим значением служит значение ее аргумента), которое также печатается.
Например,
(setq x '(1 2 3))
(1 2 3)
(print x)
(1 2 3)
(1 2 3)
Функция print часто используется временно внутри программы для печати промежуточных результатов в процессе отладки программы.
Функция prin1 выводит в файл, уже выбранный для вывода значение аргумента без последующего перевода строки. Таким образом, функция prin1 действует так же, как и функция print, но в файл вывода не выводится символ «перевод строки». Например:
(setq x '(1 2 3))
(1 2 3)
(prin1 x)
(1 2 3)(1 2 3)
Как функцией print, так и функцией prin1 можно выводить кроме атомов и списков и другие типы данных, например, строки:
(prin1 "a b c")
A b ca b c
Вывод выражений часто желательно разбить на несколько строк. Перевод строки можно осуществить функцией terpri (TERminate PRInting). У функции terpri нет аргументов и в качестве значения она возвращает nil. Например:
(progn (prin1 a) (terpri) (print b) (prin1 c))
a
b
cc
Функция prognреализует возможности фон-Неймановского стиля программирования в LISPе. Она последовательно вычисляет значения своих аргументов, список которых рассматривается как последовательность команд. При этом функция реагирует на специальные конструкции, которые управляют переходами, разветвлениями , циклами. Данная функция не вписывается в функциональный стиль программирования и, поэтому здесь подробно не рассматривается[1].
Функцию print можно определить с помощью terpri и prin1 следующим образом: (progn (prin1 x) (terpri))
Функция spaces выводит в файл, уже выбранный для вывода указанное количество символов «пробел» и возвращает их количество. Например:
$(spaces 11)
………..11
2.5. Другие функции
В языке LISP имеется большое количество различных встроенных функций. В этом разделе мы рассмотрим лишь некоторые из них, пояснения относительно других - будем давать в следующих разделах по мере необходимости.
Функция setq применяется для связывания атома, она имеет два аргумента: первый - имя атома, второй - произвольное выражение. В результате выполнения функции setq указанный атом принимает значение равное вычисленному значению второго аргумента:
(setq A 23) A --> 23
(setq B (list A 35)) B --> (23 35)
В качестве своего значения функция setq возвращает значения второго аргумента. Следовательно, возможно «ступенчатое» использование функции:
(setq X (cons C (setq Y (list D E)))) Y --> (D E) X --> (C D E)
Функция set также применяется для связывания атома, в отличие от setq первый аргумент в качестве значения должен выдать имя атома, второй, как и для setq - произвольное выражение. В результате выполнения функции set атом-значение первого аргумента принимает значение вычисленного второго аргумента:
(setq A 'B) A --> B
(set A 35) B --> 35
Для setq и set основным результатом является не возвращаемое значение, а побочный эффект - связывание атома. Таким образом, она является типичным примером псевдофункции (другой пример псевдофункций: рассмотренные выше функции read и print). Имеется множество других примеров функций с побочными эффектами. С подобными функциями всегда следует обращаться осторожно, т.к. побочные эффекты могут привести к непредсказуемым результатам и нарушают строго функциональный подход[2].
Логические функции not, and и or выполняют операции отрицания, конъюнкции и дизъюнкции:
(not T) --> nil
(and T nil) --> nil
(or T nil) --> T
В большинстве версий языка LISP функции and и or определены как функции от нескольких аргументов и реализованы как «ленивые» функции. Кроме того, при использовании логических функций следует помнить, что логическое значение «ложь» в LISP’е обозначается тем же атомом, что и пустой список (nil), а «истиной» считается, кроме атома T – любое значение, не являющееся nil. Если очередной аргумент функции and имеет значение nil, то последующие аргументы не вычисляется, значением функции считается nil,если все аргументы функции andвычислены и ни один из них не имеет значения nil, то значением функции and считается значение последнего аргумента. Аналогично для функции or: если очередной аргумент имеет значение T (не nil) - не вычисляется второй аргумент. Например:
(or '() 12345)
(or '(1 2 3) 12345)
(1 2 3)
(and '(1 2 3) (setq x 1))
(and '() (setq y 2))
Nil
Это свойство позволяет использовать функции для организации выполнения последовательности действий. В приведенном примере, учитывая, что функция terpri вырабатывает значение nil,используется конструкция (not (terpri)):
(and (prin1 a) (not (terpri)) (print b) (prin1 c))
a
b
cc
Для объединения двух списков предназначена функция append, она имеет два аргумента - оба должны быть списками, в результате своего действия она соединяет эти два списка в один:
(append (list 1 2 3) (list a b c)) --> (1 2 3 a b c)
Следует различать действия функций cons и append, так например:
(append (list a b) (list c d)) --> (a b c d),
но (cons (list a b) (list c d)) --> ((a b) c d).
Это два разных списка, первый из них - список из четырех элементов - (a b c d), второй - список из трех элементов - ((a b) c d), причем первый элемент сам является списком - (a b).
В языке LISP имеется множество других функций для обработки списков и других целей, например, функция reverse - инвертирующая список: (reverse (list 1 2 3)) --> (3 2 1), функция length - определяющая количество элементов в списке: (length (list a b c)) --> 3и т. д. Практически все они могут быть определены через основные.
2.6. Порядок вычислений в LISP'е
Любое допустимое LISP-выражение вычисляется в ходе обработки интерпретатором языка LISP. Вычисления проводится по-разному для атома и списка.
Вычисление атома заключается в использовании его значения, установленного в процессе связывания атома. Значением атома может быть другой атом, список или функция. Вычисление атома производится независимо от того, одиночный это атом, является ли он элементом списка, т.е. аргументом функции. Например:
(setq A B) A --> B
(setq B C) B --> C
(setq D B) D --> C
в результате первого присваивания атом A получит значение B (в этот момент атом B не связан с другим значением, его значением является он сам) и, аналогично, при втором присваивании атом B получает значение C. В третьем случае, при исполнении функции setq будет вычислено значение атома B (в данном случае C) и атом D будет связан с полученным значением. При последующих вычислениях атомов A и D будут использованы их значения B и C соответственно:
(setq E A) E --> B
(setq F D) F --> C
В результате проведенных операций атом A имеет своим значением B, а атом B, в свою очередь, C. При вычислении значения атома интерпретатор языка LISP использует лишь один уровень связи значений. В операции (setq X A) используется связь A-->B и игнорируется следующий уровень B-->C. Для принудительного вычисления различных уровней связи значений предназначена функция eval. При вызове функции eval (как и любой другой функции языка LISP) вычисляется значение ее аргумента, а значением функции eval будет значение от полученного результата. Иными словами, значением функции eval будет значение значения ее аргумента. Приведём ещё один пример:
(setq X Y) X --> Y
(setq Y Z)
(eval X) --> Z
(setq Z T)
(eval (eval X)) --> T
Предотвратить или отменить вычисление выражения (вычисление интерпретатором или функцией eval) можно при помощи функции quote. (quote X) всегда имеет своим значением X, независимо от того, является атом X связанным или свободным. Если действительны последние присвоения для X, Y и Z, действие функции quote можно продемонстрировать на следующих примерах:
X --> Y
(quote X) --> X
(eval X) --> Z
(eval (qoute X)) --> Y
(eval (eval (quote X) --> Z
Функцию отмены вычислений можно использовать для того, чтобы связанный атом сделать свободным:
(setq X (quote X)) X --> X
Как было сказано выше, в языке LISP вызовы функций представлены в виде списков (S-выражений). Первый элемент списка - имя функции, следующие элементы - аргументы функции. Вычисление любого списка сводится к попытке интерпретации его первого элемента как имени функции (при неудаче появляется сообщение об ошибке), а остальных элементов как аргументов этой функции. Попытка задать список непосредственно во входной строке языка окончится неудачей, так как интерпретатор воспримет список как функцию и попытается её вычислить. Для задания не вычисляемого списка можно использовать функцию list, используется также функция quote, отменяющая интерпретацию списка. Однако результаты применения функций list и quote могут быть разными, если элементы, из которых строится список, являются связанными:
(setq A 1)
(setq B 2)
(setq C 3)
(list A B C) --> (1 2 3)
(quote (A B C)) --> (A B C)
Любая функция языка программирования LISP может использовать значение другой функции в качестве своего аргумента, т.е. допускается вложенность или суперпозиция функций. В этом случае интерпретатор языка придерживается «естественного» порядка вычислений: изнутри-наружу[3]. Перед нахождением значения функции любого уровня вложенности вычисляются значения ее аргументов.
(cons (car (list 1 2)) (quote 2 3)) --> (1 2 3)
В приведенном примере перед нахождение значения функции cons вычисляются значения ее аргументов - функции car и quote; исполнение функции car, в свою очередь, приводит к предварительному вычислению функции list и так далее. Функции quote и eval позволяют управлять порядком вычислений: отменять вычисление выражения или проводить повторные вычисления соответственно.
Рассмотренная ранее функция setq «неправильная» функция, так как при ее исполнении не вычисляется значение ее первого аргумента:
(setq X Y) X --> Y
(setq X 1) X --> 1
в последнем случае значение 1 принимает атом X, хотя и является связанным, если бы вычислялось его значение, то значение 1 принял бы атом Y. Более «правильная» функция set - имеет тот же побочный эффект что и setq, но вычисляет значения обоих своих аргументов:
(setq A B) A --> B
(set A 1) A --> B B --> 1
Дело в том, что функция setq более короткая форма записи функции set с отменой вычисления первого аргумента.
(setq A B) <==> (set (quote A) B)
Поскольку функция quote используется довольно часто, для нее используется более лаконичная форма записи:
(quote X) <==> 'X
2.7. Определение новых функций
Программная реализация функционального алгоритма сводится к определению новых собственных функций программиста и, среди них, некоторой основной функции, для которой входные данные играют роль аргументов, а возвращаемое значение - результатом решаемой задачи. Для определения новых функций в языке LISP существует несколько способов. Рассмотрим их по порядку.
Дата: 2016-10-02, просмотров: 316.