Кодировки входных данных.
Вначале поговорим о длине входа (условия) задачи. Дело в том, что кодировать условия задачи можно разными способами. Поясним это на примерах.
Пример 1. Задача: Требуется найти количество единиц в двоичной записи целого числа.
Если число n задается в виде n+1 единицы *1...1*, то длина входа n+3. Если число задается в десятичной форме, это уже lgn. К этим двум способам добавим двоичную запись числа n. Ее длина log2n.
Но рассмотрим еще один подход к решению задачи. Пусть у нас есть 2n перенумерованных ячеек, в каждой из которых содержится число, равное количеству единиц в двоичной записи номера ячейки. Тогда длина входа задачи для числа n равна 2n log2n.
Пример 2. Задача о простоте числа.
Если число n задается в виде n+1 единицы *1...1*, то длина входа n+3. Если число задается в десятичной форме, это уже lgn. Если n задано в мультипликативной форме n=p1a1…pkak (числа pi– простые, а сама мультипликативная форма задает разложение числа на простые множители), то длина входа равна S(lgpi+lgai), где суммирование ведется от 1 до k.
Пример 3. Задачи на графах.
Выше было много примеров задач на графах. Граф с n вершинами и m ребрами можно задать списками ребер и вершин. В этом случае длина входа лежит между 4n+10m и 4n+10m+(n+2m)[lgn]. Если граф задается списками соседей его вершин, то длина входа лежит между 2n+8m и 2n+8m+2m[lgn]. Порядок же матрицы инциденций графа равен n2-n+1.
Так как понятие входа (условия) задачи не может быть формализовано хотя бы потому, что не формализовано само понятие задачи, то здесь мы вновь вынуждены уповать на наши интуитивные представления.
Это и иллюстрирует первый из приведенных выше примеров. Описанные там два подхода к заданию входа фактически относятся к разным задачам. То есть, понимание условия задачи на интуитивном уровне дает возможность предлагать "разумную" кодировку в том смысле, что разумность заключается в соответствии кодировки условиям задачи.
Первый пример иллюстрирует и важность еще одной меры сложности задачи - объем требуемой при решении памяти. При первом подходе к кодировке входа в данном примере объем памяти в константу раз отличается от длины входа и представляет собой линейную или логарифмическую функцию от n. Время решения задачи, например, ее сложность в худшем (см. ниже) на МТ такая же. Во втором случае решение просто сводится к чтению ответа (на МТ это один такт работы), объем же памяти экспоненциально зависит от n.
Пусть мы теперь имеем "разумные" кодировки. На этом уровне принимается интуитивная гипотеза о некоторой эквивалентности всех возможных "разумных" кодировок входных данных одной и той же массовой задачи.
Второй пример показывает варианты длины кодировок в зависимости от способа задания чисел. Варианты длины кодировок в третьем примере зависят уже от структуры входных данных. Но в обоих случаях можно говорить о, так называемой, полиномиальной эквивалентности.
В дальнейшем нам полезно будет понятие полиномиальной эквивалентности двух функций. Две неотрицательные функции S(n) и R(n) полиномиально эквивалентны, если существуют два полинома Q(x) и P(x) такие, что для всех n справедливы неравенства S(n)£P(R(n)) и R(n)£Q(S(n)).
Пусть S и R две "разумные" схемы кодирования задачи массовой Z. Длины входа в этих схемах для задачи I обозначим через S(I) и R(I). К ним можно применить определение полиномиальной эквивалентности.
В третьем примере все три схемы полиномиально эквивалентны, а во втором полиномиально эквивалентны две последние.
О мерах сложности
Сегодня понятие алгоритма ассоциируется в первую очередь с программой на некотором языке программирования. С точки зрения тезиса Черча, это достаточно естественно.
Однако нас будет интересовать не только проблема эквивалентности различных типов алгоритмов, но также возможность их сравнения и те свойства моделей алгоритмов, которые позволяют оценивать сложность.
Здесь есть определенное противоречие. Проще оценивать сложность алгоритма в рамках достаточно замысловатой модели, например, современного языка программирования. В то же время хотелось бы понимать, насколько подобная модель сравнима, например, с машиной Тьюринга. И не только в смысле эквивалентности, но и при пересчете оценок сложности алгоритма в рамках различных моделей вычисления. Это вопрос очень сложный. Поэтому здесь мы его лишь вскользь коснемся и приведем несколько примеров. В дальнейшем мы периодически будем к нему возвращаться.
В случае решения индивидуальной задачи на машине Тьюринга естественно оценивать сложность алгоритма числом тактов работы МТ. Для НАМ такой мерой может быть количество выполненных в процессе работы преобразований.
В случае НМТ сложность определяется следующим образом. Для одного и того же слова I может существовать множество различных отгадок {U}. На каждой из них обычная головка работает tT(I,U) тактов. В качестве времени решения задачи на входе I рассматривается
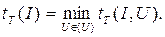
Обратим внимание на то, что понятие «отгадка», с одной стороны, имеет «оракульный подтекст», а с другой – связано с примитивным полным перебором. Пусть существует конечная запись U', обозначающая объект, соответствующий ответу «да». Например, перечень вершин гамильтонова цикла или обход коммивояжера нужного веса. Так как угадывающая головка случайным образом пишет все возможные слова, то один из вариантов ее работы – упомянутая запись. Но в приведенной выше формуле минимум берется по всем возможным записям, поэтому и U’ будет учтена. Дальше работает обычная головка, которая читает отгадку и проверяет. Отгадки, конечно, могут иметь разную длину, поэтому суммарное время чтения и проверки для них может быть разное. Формула даст минимум по этим временам. Пусть он достигается на слове-отгадке V. Так как поиск этого минимума нам ничего с вычислительной точки зрения не стоит, то, можно считать, слово V сразу пишется угадывающей головкой. В этом заключается «оракульность» отгадки. Но оракульность эта достигается бесплатностью перебора по всем возможным записям случайно работающей угадывающей головки. В этом заключается переборный характер механизма получения отгадки.
Для ОМТ сложность решения задачи на входе I определяется совершенно так же, как и для МТ. (Только вычисления-то эти очень разные!)
Кроме временных характеристик рассматриваются и пространственные. В случае МТ сложность задачи может характеризоваться количеством ячеек ленты, которые просматривались головкой в процессе работы.
Говоря о сложности вычисления РАМ, РАСП или упрощенного АЛГОЛа временную сложность индивидуальной задачи оценивают с помощью количества выполненных в процессе решения команд. Но здесь выделяются два подхода.
Если каждая команда требует единицы времени, а каждый регистр занимает единицу памяти, то говорят о моделях вычисления с равномерным весом.
Модель вычисления с логарифмическим весом предполагает, что представление целого числа n в регистре требует ëlog|n|û+1 битов. При этом емкость регистров не ограничена. Время, затраченное на выполнение команды пропорционально длине ее операндов.
Сложность решения массовой задачи можно определять разными способами, исходя их сложности решения индивидуальных задач.
Ниже через Т обозначим некоторую модель вычисления (НАМ, МТ, РАМ и т.п.).
Пусть |Z(n)| - число индивидуальных задач I массовой задачи Z, длина входа которых не превосходит n.
Обозначим время работы алгоритма T (модели вычислений T) на входе I через tT(I). В случае решения массовой задачи в качестве меры сложности рассматривается функция tT(n) от длины |I| входа задачи I. Наиболее распространены две меры сложности: "в худшем" и "в среднем". В первом случае

А во втором
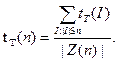
Максимум и сумма берутся по всем индивидуальным задачам I таким, что |I|£n.
Будем различать сложность задачи TZ и сложность алгоритма A(Z) решения этой задачи TA(Z). Если фиксирован алгоритм решения задачи A(Z), то по его описанию любой пользователь имеет возможность подробно (пошагово) увидеть, как он работает. Если в качестве сложности алгоритма выбрана некоторая характеристика его работы, например, одна из приведенных выше мер, то используя описание алгоритма, это меру можно вычислить.
Итак, под сложностью алгоритма понимается значение некоторой функции от длины входа. В то же время сложность задачи, как функция от длины входа – это отдельное понятие. Здесь может быть несколько подходов.
Если сложность задачи напрямую определяется сложностью алгоритмов ее решения, то в большинстве случаев удается говорить лишь об оценках этой сложности. Задачу можно решать несколькими алгоритмами, поэтому полагают, что
TZ ≤ TA(Z).
Верхней оценкой сложности является наименьшая из известных на данный момент сложность алгоритма ее решения. Если, TA(Z) - полиномиально ограниченная функция, то говорят, что алгоритм A(Z) (задача Z) имеет полиномиальную сложность, а если экспоненциально ограниченная – то экспоненциальную сложность. В следующем разделе мы в качестве примеров такого подхода рассмотрим несколько известных вам задач.
Если бы была известна некоторая нижняя оценка сложности
F(n)≤ TZ,
совпадающая с верхней, то, то сложность задачи была бы определена, а исследователи бы знали, что существующий на данный момент алгоритм ее решения является наилучшим из возможных и дальнейшие попытки поиска более быстрого алгоритма будут безуспешными. Но такая ситуация имеется лишь в очень малом количестве сравнительно простых задач, таких как приведенные ниже: задача нахождения минимального числа (здесь сложность равна O(n)) или задача сортировки (здесь сложность равна O(nlogn)).
Дело в том, что нижняя оценка сложности получается из анализа структуры задачи, а не из методов ее решения. На сегодня типичной является ситуация, когда нижняя оценка – экспонента, нижняя – линейная функция. Экспоненциальные нижние оценки сложности для некоторых задач были впервые получены в 1980-х годах.
Другой подход к анализу сложности связан с понятием схемы из функциональных элементов.
Теоремы сравнения
Подведем теперь некоторый итог нашему рассмотрению. Для этого мы сформулируем и обсудим несколько утверждений. Подробные доказательства можно найти в [3] и в [1].
Интуитивно очевидно, что сводить сравнительно бедный (простой) формализм к более богатому (сложному) тяжелее, чем наоборот. С другой стороны, оценивать сложность решения той или иной задачи с помощью программы на современном языке программирования проще, чем сложность ее решения на МТ. В то же время многие теоретические результаты сформулированы для такой модели, как МТ. Утверждения данного раздела и позволяют проверить, насколько такие оценки теоретически обоснованы.
Первые два утверждения касаются НАМ и МТ.
Теорема. Пусть T - машина Тьюринга с алфавитом A и С - надалфавит А. Тогда существует нормальный алгорифм Маркова Á над С, вполне эквивалентный алгоритму Тьюринга ÂT,C.
Справедливо и обратное утверждение.
Теорема. Пусть Á - нормальный алгорифм Маркова в алфавите A, D,dÏA. C={D,d}ÈA. Тогда существует машина Тьюринга T такая, что алгоритм Тьюринга ÂT,C в алфавите C обладает следующим свойством. Для любого слова P в алфавите A ÂT,C применим в том и только в том случае, когда к этому слову применим Á, а результатом работы ÂT,C является слово Á(P), окруженное конечными последовательностями из D.
Займемся теперь сравнение РАМ и РАСП.
Теорема. Как при равномерном, так и при логарифмическом весе для любой РАМ-программы с временной сложностью T(n) найдется эквивалентная ей РАСП программа с временной сложностью, не превосходящей kT(n), k - некоторая постоянная.
Теорема. Как при равномерном, так и при логарифмическом весе для любой РАСП-программы с временной сложностью T(n) найдется эквивалентная ей РАМ программа с временной сложностью, не превосходящей kT(n), k - некоторая постоянная.
Эти утверждения позволяют использовать в рассуждениях ту из моделей, которая в данном случае более удобна.
Рассмотрим теперь связь РАМ и МТ.
Возьмем задачу в форме распознавания Z и соответствующий ей язык LZ. Все перечисленные формальные схемы алгоритма позволяют ввести понятие допустимости языка алгоритмом.
Например, МТ допускает язык LZ тогда, когда она останавливается в специально отведенном для этого конечном состоянии qy только на словах этого языка, являющихся условиями индивидуальных задач с ответом "да".
Конечно, вместо состояния можно требовать написания какого-то символа на ленте. Так в РАМ, РАСП и упрощенном АЛГОЛе говорят, что программа допускает язык LZ тогда, когда она останавливается, записав на выходной ленте 1 только на словах этого языка, являющихся условиями индивидуальных задач с ответом "да".
Заметим, что на всех остальных словах программа либо вообще не останавливается (зацикливается), либо останавливается с некоторой другой записью на ленте.
Теорема. Пусть L - язык, допускаемый некоторой РАМ за время T(n) при логарифмическом весе. Если в программе РАМ нем умножений и делений, то существует многоленточная МТ, допускающая этот язык за время O(T2(n)).
Аналогичное утверждение для равномерного веса неверно.
Действительно, в случае МТ равномерного веса быть не может. В ячейке записан один символ. Его расшифровка внутри программы просто должна развернуть всю запись числа. А как это делается: явным образом с занятием новых ячеек или неявно в виде последовательности выполняемых команд, - это уже не важно.
Для РАМ же логарифмический вес является абстрактным упрощением, которое иногда полезно, если применяется осознанно.
Сказанное поясняет пример умножения n чисел вида 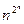 .
.
РАМ это может сделать за O(n) шагов при равномерном весе. Ведь в регистр помещается число любого размера. В то время как на МТ только вклад тактов, на которых осуществляется считывание входного слова, составит более 2n. То есть даже полиномиальной эквивалентности между сложностями вычислений в этих моделях.
Дата: 2019-07-30, просмотров: 364.