В этом разделе мы приведем некоторые необходимые для дальнейшего сведения о булевых функциях.
Схема из функциональных элементов (булева схема) - это способ вычисления булевых функций: Bn®Bm. Эта схема может быть представлена в виде ациклического графа с тремя видами вершин. Вершинам с нулевой полустепенью захода (число таких вершин равно n) сопоставляются n входных переменных. Вершинам с нулевой полустепенью исхода (число таких вершин равно m) сопоставляются m выходных значений функции.
Всем остальным вершинам (функциональным элементам) сопоставляются некоторые булевы функции. В этом случае полустепень захода равна числу переменных функции, а ребра помечены числами, указывающими номера аргументов функции. Схема отождествляется с формулой, если из каждой такой вершины выходит ровно одно ребро.
Совокупность таких функций (типов функциональных элементов), на которых строится схема, образует базис схемы. Вычисление происходит поэтапно.
Функция в вершине схемы считается вычисленной сразу, как только известны значения ее аргументов. Базис называется полным, если для любой булевой функции существует схема вычисления в данном базисе.
Базисом может быть любая полная система булевых функций (вспомним теорему Поста). Поэтому без ограничения общности можно рассмотреть фиксированный базис.
Пример такого базиса дает следующее утверждение следующее утверждение.
Теорема. Базис из трех функций {È, &, Ø} является полным.
Определение. Схема из функциональных элементов (СФЭ) — это конечный ориентированный граф без ориентированных циклов, в каждую вершину которого входит не более 2 рёбер. При этом каждой вершине приписывается символ: переменная xj, если в эту вершину рёбра не входят; отрицание, если в вершину входит одно ребро; конъюнкция или дизъюнкция, если в вершину входит 2 ребра. Некоторым вершинам приписывается *. Элементами схемы называются вершины, помеченные логическими операциями.
Сложностью схемы S, которая вычисляет функцию f от n переменных в базисе B называется число функциональных элементов LB , n(S(f)) в этой схеме.
Схемной сложностью LB , n(f) вычисления функции f в базисе B называется минимальный размер схемы, вычисляющей f в данном базисе.
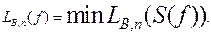
Здесь минимум берется по всем схемам, вычисляющим функцию f(x1,…,xn) в базисе B.
Если базис фиксирован, B то индекс опускаем. Отдавая дань истории, функция L(n) выражающая максимальную сложность функций от n переменных, называется функцией Шеннона.
Какие для этой функции существуют оценки?
Этот вопрос для нас важен в связи с тем, что СФЭ можно использовать для подхода к анализу сложности задачи.
Рассмотрим задачу в форму распознавания. Закодируем вход задачи Z булевским вектором из Bn, тогда решение задачи – это некоторое отображение φz: Bn®B1. (Ниже при доказательстве теоремы Кука такая конструкция будет описана).
Предположим, что это отображение в явном виде построено, тогда будет определена некоторая булевская функция. Схемная сложность этой функции может задавать сложность решения задачи.
Опр. Класс булевых функций, для которых существуют схемы полиномиальной сложность и обозначим через P/poly.
В связи с тем, что этот класс будет рассматриваться ниже, нас интересуют оценки функции Шеннона.
Эта задача была решена советским математиком О.Б.Лупановым. Кратко приведем основные результаты. (Изложение ведется по лекциям [7]).
Оценки сложности СФЭ.
Оценки функции Шеннона L(n) строятся из тех же соображений, что и оценки сложности задачи. Верхние оценки получаются путем построения конкретной СФЭ, реализующей функцию f(n). Для этого было разработано в 1950-е годя целое направление в дискретной математике – методы синтеза СФЭ. А вот нижние оценки получаются «из мощностных соображений».
Построим СФЭ, реализующую функцию f = 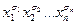 . Перегруппируем множители, собрав в одном месте переменные с нулевыми степенями. Тогда, перенумеровав переменные, функцию можно переписать в виде
. Перегруппируем множители, собрав в одном месте переменные с нулевыми степенями. Тогда, перенумеровав переменные, функцию можно переписать в виде
f = (xi & . .. & xk)& 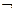 (хк+1 Vхк+2 V ...V хп).
(хк+1 Vхк+2 V ...V хп).
Заметим, что в этой формуле не более n операций. Значит, сложность схемы данной функции не превосходит n. Отсюда следует очевидный метод построения СФЭ по совершенной ДНФ функции. С его помощью строится СФЭ сложности не более (n +1) 2n.
Утв. L(n) ≤(n +1) 2n.
Замечание. На самом деле легко доказать, что L(n)≤ (n + 1) 2n-1. Действительно, посмотрим на таблицу значений нашей функции и выясним, чего в ней больше: нулей или единиц. В зависимости от этого будем использовать, соответственно, СДНФ либо СКНФ. В самом худшем случае будет 2n-1 дизъюнкций или коньюнкций.
Дальнейшее улучшение позволяет избавиться и от множителя n. Построим по индукции СФЭ, которая будет реализовывать множество функций Kn – множество всех конъюнкции - со сложностью C(n), которая асимптотически равна 2n+1.
Обозначим через Kn множество всех функций вида . Сейчас мы будем строить схему, которая реализует все функции из Kn. Сложность такой схемы обозначим C(n). При n = 1 получается схема без элементов. Предположим, что мы уже построили схему для всех множеств с номерами меньше n. Зафиксируем число k < n. Построим схему, реализующую все функции из Kn, используя в качестве подсхем две схемы: для Kk и для Kn-k. Тогда первые k сомножителей реализуются конъюнктором Kk, а остальные n-k – конъюнктором Kn-k.
Возьмём по одному выходу из схем для Kk и Kn-k, реализующие их, и подключим их к конъюнктору. Получим схему, реализующую одну конъюнкцию от n переменных. Также поступим со всеми 2n конъюнкциями от n переменных, то есть будем строить их, используя соответствующие выходы в схемах Kk и Kn-k, связывая их конъюнктором. Итого получим схему для Kn, затратив C(k)+C(n — k)+2n элементов. Теперь возьмём k := n/2 и получим С(п) ≤2n +2С( n/2) = 2n(2n/2+2С( n/4))=2n+2n/2+1+4С( n/4)) . Отсюда следует, что можно (асимптотически) улучшить оценку для L(n): реализовав все конъюнкции ценой ~ 2n элементов, склеим их не более чем 2n дизъюнкциями, в итоге получим схему сложности порядка 2n+1.
Дальнейшее улучшение в n раз дает метод Шеннона синтеза схем. Он просто использует разложение функции по k переменным
F(x1,…,xn) = 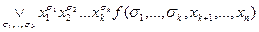 .
.
Пусть k = n-q. Реализуем все конъюнкции Kk первых k переменных, при этом потратим 2k элементов. Кроме этого, может потребоваться реализовать все функции от q переменных, которых всего 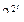 . Каждую из них можно реализовать со сложностью q2q. При склейке основной схемы по указанной выше формуле потребуется ещё 2k конъюнкторов (для вычисления слагаемых) и ещё 2k -1 дизъюнкторов. Итого
. Каждую из них можно реализовать со сложностью q2q. При склейке основной схемы по указанной выше формуле потребуется ещё 2k конъюнкторов (для вычисления слагаемых) и ещё 2k -1 дизъюнкторов. Итого
L(n) <  2k + 2k + (2k — 1) + q 2q < 3 • 2k + q 2q .
2k + 2k + (2k — 1) + q 2q < 3 • 2k + q 2q .
Положим q := [logn] — 1. Тогда
L(n) < 6•2n-[logn] + n•logn•2n/2-1 =12•2n / n + n•logn•2n/2-1 < 12•2n / n .
Наконец, следующая теорема О.Б.Лупанова дает окончательную неулучшаемую асимптотическую оценку.
Теорема. Справедливо соотношение L(n) < 2n / n .
Доказательство. Рассмотрим произвольную булеву функцию n переменных. Отделим q := n-k первых переменных и рассмотрим таблицу, в которой 2k строк и 2q столбцов. Строки занумеруем всевозможными значениями последних k переменных, а столбцы — всевозможными значениями первых q переменных. Ячейки таблицы заполним значениями функции. Каждый столбец представляет собой значения функции, полученной подстановкой констант в первые q переменных, то есть  . Разрежем таблицу на горизонтальные полоски по s строк в каждой (последняя полоса будет, возможно, меньше; пусть в ней s' < s строк). Число полос будет равно p=[2k /s]< 2k /s+1.
. Разрежем таблицу на горизонтальные полоски по s строк в каждой (последняя полоса будет, возможно, меньше; пусть в ней s' < s строк). Число полос будет равно p=[2k /s]< 2k /s+1.
Через Ii обозначим индикатор i-й полосы, то есть функцию, которая равна единице на строках этой полосы, и только на них. Обозначим теперь

Такие функции называются обрезанными функциями. Ясно, что
= 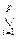
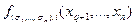 .
.
Тогда имеем
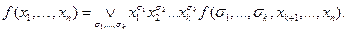 .
.
Реализуем все конъюнкции первых q переменных, потратив 2q элементов. Кроме этого, реализуем все конъюнкции последних k переменных, потратив 2k элементов. Все обрезанные функции имеют не более s ненулевых значений, значит, их количество не превышает 2s. Поскольку все конъюнкции последних переменных уже есть, на изготовление СДНФ для каждой обрезанной функции уйдёт всего s дизъюнкций, значит, всего на реализацию обрезанных функций каждой полосы мы потратим не более s2s элементов, а всего — не более ps 2s.
На сборку каждой  уйдёт ещё p дизъюнкций (поэтому всего на это уйдёт p 2q операций), а на сборку функции f уйдёт ещё 2q конъюнкций и 2q дизъюнкций.
уйдёт ещё p дизъюнкций (поэтому всего на это уйдёт p 2q операций), а на сборку функции f уйдёт ещё 2q конъюнкций и 2q дизъюнкций.
Суммируя полученные оценки, имеем
L( f) < 2q + 2k + ps2s + p2q + 2q + 2q = 3 2q + ps 2s + p2q + 2k.
Вспоминая, что р< 2k /s+1, получаем
L( f) < 3 • 2 q +(2k /s+ 1)(s2s + 2q) + 2k.
Видно, что s должно быть порядка п, но всё же чуть меньше его. Что касается к, то нужно, чтобы 2k /s→∞, чтобы нам не мешала единица в скобках. Положим k := [2 log n] и s := [n — 4 log n]. Подставляя эти значения, получаем оценку порядка 2n / n.
Теорема доказана.
Чтобы доказать, что получена асимптотически неулучшаемая оценка, нужно аналогичную асимптотику L(n) 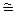 > 2n / n снизу.
> 2n / n снизу.
Пусть P* (n) — функции, существенно зависящие от n переменных. N(h, n) — число функций, существенно зависящих от n переменных, которые реализуются схемами сложности, не превосходящей h. N'(h, n) — число функций, существенно зависящих от n переменных, которые реализуются схемами сложности ровно h; N''(h, n) — число схем сложности h для функций, существенно зависящих от n переменных. Очевидно, что N' = N, потому что всегда можно дополнить схему ничего не делающими элементами. Очевидно также, что N≤N'', так как одну функцию можно реализовать разными схемами, но не наоборот.
Покажем, что для любого ε>0, число функций, реализуемых схемами сложностью меньше (1-ε ) 2n /n, гораздо меньше, чем всех функций. Итак, покажем, что для ho= (1-ε ) 2n / n выполнено соотношение N( ho, n)<< |P*(n)|. Мы будем оценивать величину N, мажорируя её величиной N''.
Пусть y(p, q) — число графов с q ребрами и p= h + n вершинами (n входов и h элементов), N''(h, n, q) — число схем с q ребрами. Сколько схем можно сделать из одного графа? У нас имеется не более:
· 2q способов выбрать ориентацию ребер;
· ( h + n) n способов выбрать входы;
· 3h способов присвоения вершинам различных ФЭ;
· h + n способов выбора выхода.
Число γ(n,m) связных графов с n вершинами и m ребрами не превосходит nm-nconstn+m. Действительно, чтобы из n-вершинного дерева сделать m-рёберный граф, нужно дополнительно провести ещё m—(n— 1)= k ребро. Из каждой вершины дерева можно выпустить куда-то ребро (так, чтобы второй конец пока не входил ни в какую вершину). Это можно сделать, очевидно, 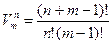 способами. Теперь эти концы надо как-то подсоединить к имеющимся вершинам. Это можно сделать mn способами. Значит, существует не более
способами. Теперь эти концы надо как-то подсоединить к имеющимся вершинам. Это можно сделать mn способами. Значит, существует не более
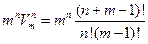 способов получить из дерева граф. А поскольку количество деревьев не превосходит 4n-1, то в итоге имеем оценку сверху
способов получить из дерева граф. А поскольку количество деревьев не превосходит 4n-1, то в итоге имеем оценку сверху
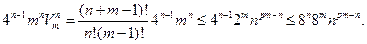 Таким образом, достаточно взять const = 8.
Таким образом, достаточно взять const = 8.
Отсюда получаем:
N(h, n, q) ≤ γ(n,m) 2q (h + n)n+1 3h ≤ consth+n+q(h + n)q—h+1 2q 3h. (15)
Вспоминая, что q ≤ 2h, и собирая константы в новую константуB , имеем:
N''(h, n, q)≤ B3h+n(h + n)h+1.
Теперь получим оценку для N''(n, h):
N''(h, n, q)≤ B3h+n(h + n)h+1.

Нам нужно убедиться, что N''(ho,n) < |P*(n)| при достаточно больших n. Заметим, что
|P*(n)| > 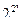 — n
— n 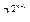 ≈ . Таким образом, требуемое неравенство будет выполнено, если при n→∞ будет выполняться
≈ . Таким образом, требуемое неравенство будет выполнено, если при n→∞ будет выполняться
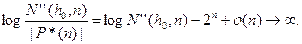
Далее для достаточно больших n:
log N’’(ho,n) — 2n + o(1) ≤ (ho + n) log(C(ho + n)) — 2n + o(1)≤((1-ε)2n/n+n)n
-2n + o(l) = (1-ε)2n + n2 - 2n + o(l) = n2 + o(1) — ε2n →∞ при n→∞.
Что и требовалось доказать.
Теорема. Справедливо соотношение L(n) 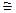 2n / n .
2n / n .
Теория NP-полноты
В конце 60-х и начале 70-х годов был внесен интересный вклад в теорию сложности, касающийся сравнения различных типов алгоритмов. Главная роль здесь принадлежит американскому математику С.А.Куку.
Три фундаментальных части предложенной Куком концепции заключаются в следующем.
1. Были введены определения двух классов задач. Один из них был связан с полиномиальными алгоритмами, а другой - с переборными.
2. Были введены понятия сводимости задач. Сводимость позволяла характеризовать принадлежность к определенному классу.
3. Для некоторой конкретной задачи было конструктивно доказано, что она в определенном смысле может рассматриваться, как самая сложная. (С помощью сводимости затем множество таких самых сложных задач было дополнено.)
Классы P и NP.
Рассмотрим дискретную оптимизационную задачу Z в форме распознавания. Ей, как было выше описано, сопоставляется язык LZ.
Класс P - это класс языков, допускаемых МТ за полиномиальное время. (То есть эта МТ, во-первых, допускает язык, а, во-вторых, время ее работы ограничено полиномом.)
Задачи (языки) из этого класса называют полиномиально разрешимыми.
В случае НМТ для одного и того же слова I, представляющего собой запись условия некоторой индивидуальной задачи, может существовать множество различных отгадок {U}. Зафиксируем слово I и рассмотрим все возможные вычисления НМТ на различных отгадках. На каждой из них обычная головка работает tT(I,U) тактов.
Если хотя бы для одного такого вычисления НМТ за конечное число шагов остановится в конечном состоянии qy ,то это вычисление называется принимающим, tT(I,U) полагается равным числу тактов работы НМТ. В противном случае (НМТ зацикливается или останавливается в состоянии qn) вычисление называется непринимающим.
В качестве меры трудоемкости решения задачи I в форме распознавания на НМТ рассматривается величина
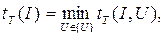
где минимум берется по всем принимающим вычислениям.
Если для некоторой массовой задачи Z НМТ допускает ее индивидуальную задачу I тогда и только тогда, когда I имеет ответ "да", то говорят, что НМТ допускает язык LZ .
Класс NP - это класс языков, допускаемых НМТ за полиномиальное время. (То есть эта НМТ, во-первых, допускает язык, а, во-вторых, время ее работы ограничено полиномом.)
Теорема. Если ZÎNP, то существует такой полином p, что Z может быть решена на детерминированной МТ за время O(2p(n)).
Доказательство. Пусть T - НМТ, решающая Z за время q(n). То есть для каждого I найдется отгадка U(I) такая, что после ее записи НМТ работает уже как обычная МТ, а число тактов работы не превосходит q(n). Ясно, что число символов самой отгадки (ее нужно прочесть в процессе решения) не может превосходить q(n).
Пусть k - число символов в алфавите НМТ. Тогда всего нужно рассмотреть kq(n) отгадок. Построим такую МТ, которая работает также, как обычная головка нашей НМТ, а на входной ленте у нее записаны все kq(n) отгадок. Она поочередно просматривает отгадки. Если хотя бы на одной она останавливается в состоянии, то вычисление завершается. Временная сложность не превосходит q(n)kq(n), что при надлежащем выборе полинома не превосходит O(2p(n)).
Теорема доказана.
Сводимость задач
Смысл сводимости
Мы уже видели, что существует определенный качественный разрыв между алгоритмами полиномиальной и экспоненциальной сложности. Но сложность алгоритма решения задачи еще не полностью характеризует сложность решения задачи. Действительно, для одной и той же задачи могут быть построены алгоритмы решения разной сложности. С эти связана одна из самых важных проблем теории сложности - получение "хороших" нижних оценок сложности задачи.
Если для некоторой задачи Z построен алгоритм сложности O(f(n)), то можно говорить, что сложность решения задачи не превосходит O(f(n)). Таким образом, верхние оценки сложности решения задачи могут быть получены конструктивным образом с помощью построения конкретных алгоритмов. Нижние оценки - это утверждения следующего типа: "Задача Z не может быть решена никаким алгоритмом со сложностью, меньшей O(g(n))". Эти оценки нельзя получить, построив конкретный алгоритм. (Может быть, это просто плохой алгоритм, а в будущем кто-то построит хороший.) Эти оценки строятся путем анализа свойств задачи, возможностей кодировок условия и пр. Тривиальная нижняя оценка - длина входа задачи. Но выше мы видели, что проблемы кодировки входа достаточно тонкие. Хотя в большинстве случаев здесь можно все прояснить.
Лишь для небольшого количества задач верхние и нижние оценки сложности близки. Например, сложность сортировки n чисел равна O(nlogn). То есть, известен конкретный алгоритм, который с такой сложностью сортирует n чисел. Кроме того, доказано, что эту задачу нельзя решить быстрее, чем за O(nlogn) шагов.
Для многих полиномиальных задач верхняя и нижняя оценки различаются степенью полинома. Это может быть достаточно существенное различие, но в силу сказанного выше оно все же не столь критично как различие экспоненциальной верхней оценки, например, от линейной нижней. А это, к сожалению, достаточно типичная ситуация для многих задач дискретной оптимизации.
Но кроме разделения задач на два класса: с полиномиальной и экспоненциальной верхней оценкой сложности,- хотелось бы, в свою очередь, более детально разобраться со вторым классом.
Вот для этого и служит понятие сводимости. Это, грубо говоря, установление некоторой связи между парой задач. Смысл этой связи иллюстрирует следующий пример. Пусть известно две задачи X и Y. Задача X сформулирована 200 лет назад и с тех пор ничего лучшего, чем экспоненциальный алгоритм для нее не построено. Задача Y сформулирована вчера, и мы хотим приложить максимум усилий для ее эффективного решения. Под таким решением мы подразумеваем полиномиальный алгоритм.
Предположим теперь, что существует некоторое понятие сводимости. Если эта сводимость так устанавливается между X и Y, что наличие полиномиального алгоритма для Y влечет за собой существование полиномиального алгоритма для X, то интуитивно ясно, что подобный факт существенно повлияет на наш оптимизм в вопросе эффективного решения задачи Y и, возможно, после здравого рассуждения мы ограничимся эвристиками и переборными алгоритмами для нашей новой задачи.
Было введено несколько определений сводимости.
Полиномиальная сводимость
Рассмотрим класс задач NP. Здесь можно говорить о сводимости языков. Формальное определения полиномиальной сводимости следующее.
Определение. Говорят, что язык L1ÍA* сводится к языку L2ÍB*, если существует такое отображение f: A*®B*, что выполняются два условия.
1. Функция f вычисляется за полиномиальное время. (Например, существует МТ, которая за полиномиальное число тактов вычисляет эту функцию.)
2. Для любого входа IÎA* соотношение IÎL1 выполняется тогда и только тогда, когда выполняется соотношение f(I)ÎL2.
Сводимость языков обозначается L1µL2.
Вначале приведем два простых примера.
Пример. Задача "гамильтонов цикл" сводится к задаче "коммивояжер".
Схема решения. Матрица весов ребер A задачи коммивояжер строится из матрицы инциденций графа G задачи гамильтонов цикл по правилам: наличие ребра в G соответствует единице в A, а его отсутствие соответствует двойке. Число B для задачи коммивояжер определяется равным числу вершин в G.
Определим задачу «3-КНФ» как частный случай задачи «КНФ-выпонимость», в котором каждая КНФ содержит не более трех литералов.
Теперь приведем два очевидных свойства соотношения "сводимость".
Лемма. Если L1µL2 и L2ÎP, то L2ÎP.
Доказательство. Смысл этого утверждения в том, что сведения некоторой новой задачи к известной полиномиально разрешимой позволяет утверждать, что эта новая также полиномиально разрешима.
Мы приводим доказательство этого утверждения, так как оно конструктивно и, по сути дела, описывает алгоритм решения новой задачи.
Пусть A и B алфавиты языков L1 и L2, а функция f: A*®B* осуществляет полиномиальную сводимость L1 к L2.
Так как L2ÎP, то существует МТ, которая за полиномиальное число тактов решает эту задачу. Обозначим эту машину через М2. Через Мf обозначим машину Тьюринга, которая за полиномиальное число тактов вычисляет эту функцию f. Верхние оценки сложности решения обозначим через p2(n) и pf(n), где p2 и pf - некоторые полиномы.
Построим теперь МТ, которая решает первую задачу (допускает язык L1). Пусть задан некоторый вход IÎL1 (условие индивидуальной задачи). Сначала с помощью Мf преобразуем его во вход f(I) второй задачи. Затем с помощью М2 выясняем справедливость соотношения f(I)ÎL2. Так как для любого входа IÎA* соотношение IÎL1 выполняется тогда и только тогда, когда выполняется соотношение f(I)ÎL2, то требуемый алгоритм построен. Время работы ограничено O(p2(pf(I)) + pf(I))), что является полиномом, от n.
Лемма доказана.
Мы видим, что в построенном алгоритме по одному разу работают обе машины Тьюринга. В случае программы на некотором современном языке программирования это аналогично ситуации, когда некоторая программа составляется путем последовательного однократного выполнения двух других программ.
Соотношение полиномиальной сводимости транзитивно, то есть справедливо следующее соотношение.
Лемма. Если L1µL2 и L2µL3, то L1µL3.
Доказательство этого утверждения очевидно.
Определение. Задача из NP называется NP-полной, если к ней полиномиально сводится любая задача из NP.
Класс NP-полных задач обозначается через NPC.
Сводимость по Тьюрингу
Это иной подход к понятию сводимости. Заметим, что в оригинальной работе Кука использовался именно он.
Этот тип сводимости касается более широкого класса задач, чем задачи в форме распознавания.
В задачах оптимизации Z для каждого входа I условия задачи определяют множество конечных объектов SZ(I), которые являются ее решениями. Так, в задаче "гамильтонов цикл" это некоторый гамильтонов цикл, а в задаче "коммивояжер" на минимум - это гамильтонов цикл минимального веса. Первая из этих задач является задачей в форме распознавания, а вторая таковой не является. Но даже при решении первой как задачи в форме распознавания ответом будет только утверждение о наличии или отсутствии гамильтонова цикла, в то время как ее же решение в оптимизационной форме предполагает в качестве ответа предъявление требуемого гамильтонова цикла в случае его наличия.
Считается, что некоторый алгоритм решает задачу Z, если он выдает некоторый sÎSZ(I), если множество SZ(I) не пусто. В противном случае он выдает некоторый условленный ответ, например, "нет".
Выше мы видели, что для формальных рассуждений удобно представлять задачу в форме распознавания в виде некоторого языка. По той же причине рассматриваемые здесь задачи удобно представлять в виде известного формального объекта, называемого словарным отношением.
Пусть имеется алфавит A. Обозначим через A+ множество всех непустых слов этого алфавита. Словарным отношением над алфавитом A называется бинарное отношение RÍA+xA+.
Со словарным отношением R свяжем язык L над A. Определим некоторое словарное отношение R={(I,s): IÎA+ и IÎL}. Здесь s- любой фиксированный символ алфавита A.
Говорят, что функция f: A*®A*реализует словарное отношение R тогда и только тогда, когда для каждого IÎA+ имеет месть f(I)=D, если не существует yÎA+ такого, что(I,y)ÎR; в противном случае f(I)=y для некоторого yÎA+, (I,y)ÎR.
МТ разрешает отношение R, если она вычисляет функцию f, которая реализует R.
Если раньше речь шла только о кодировании условия задачи Z, то теперь схема кодирования включает как кодирование входа I, так и кодирование решения SZ(I). Тогда задаче Z можно сопоставить словарное отношение R={(x,y)}, где x - код входа индивидуальной задачи, а y -код некоторого ее решения. (Как и раньше, чтобы не загромождать изложение мы не будем различать сам вход и его код.)
Сводимость по Тьюрингу базируется на определенном выше понятии оракульной МТ.
Определение. Пусть R и R' - два словарных отношения над A. Будем говорить, что R сводится по Тьюрингу к R', если существует оракульная машина Тьюринга M с входным алфавитом A такая, что для любой функции g:A*®A*, реализующей словарное отношение R', релятивизированная программа Mg будет полиномиальной программой ОМТ, а функция, вычисляемая программой Mg, будет реализовывать отношение R.
Обозначим этот тип сводимости как RµTR'. Как и в случае полиномиальной сводимости имеет место транзитивность.
Лемма. Если L1µTL2 и L2µTL3, то L1µTL3.
Данное понятие сводимости относится уже не только к задача в форме распознавания, т.е. оно является более широким и, возможно, позволяет анализировать сложность задач за пределами класса NP задачи.
Определение. Словарное отношение R назовем NP -трудным, если существует NP-полный язык L (представленный как словарное отношение), который сводится по Тьюрингу к R, т.е. LµTR.
Более неформально NP-трудная задача определяется как задача, к которой по Тьюрингу сводится некоторая NP-полная задача.
Пример. Задача "разбиение" сводится по Тьюрингу к задаче "K-е по порядку подмножество".
Первая определена выше. Вторая задача состоит в следующем. Задано конечное множество A, каждый его элемент a имеет размер s(a), выраженный натуральным числом. Заданы также два неотрицательных числа K£2|A| и
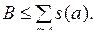
Вопрос заключается в следующем. Существует ли не менее K различных подмножеств A'ÍA, удовлетворяющих условию s(A')£B, где
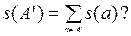
Весьма вероятно, что эта задача не принадлежит классу P. Более того, она может не принадлежать и NP.Интуитивно очевидный путь ее решения на НМТ требует угадывания K подмножеств множества A. Пока неизвестен способ записать эти угаданные подмножества на ленте в виде слова, длина которого была бы полиномом от |A|logKlogs(A). Если говорить о полиномиальной сводимости, то сегодня неизвестно никакой NP-полной задачи, которая бы сводилась к задаче "K-е по порядку подмножество".
Покажем теперь, что задача "разбиение" сводится по Тьюрингу к задаче "K-е по порядку подмножество".
Пусть S(A, s, B, K) - программа для решения задачи "K-е по порядку подмножество". Положим |A|=n. Условие индивидуальной задачи "разбиение" задаются просто в виде множества A с размерами элементов. Программа для решения задачи "разбиение" начинается с вычисления s(A). Если оно нечетно, то ответ "нет". В противном случае полагаем B=s(A)/2 и применяем приведенный ниже алгоритм (он использует процедуру S(A, s, B, K)), позволяющий определить число L* подмножеств A'ÍA, удовлетворяющих условию s(A')£B.
1. Шаг 1. Положить Lmin=0, Lmax=2n.
2. Шаг 2. Если Lmin-Lmax=1, то положить L*= Lmin и остановиться.
3. Шаг 3. Положить L=(Lmin+Lmax)/2 и вызвать подпрограмму S(A, s, B, L). Если ответ "да", то положить Lmin=Lи перейти к шагу 2. В противном случае положить Lmax=L и перейти к шагу 2.
Подпрограмма S(A, s, B, L) вызывается ровно n раз. Требуется еще один вызов S(A,s,B-1,L*) для определения ответа в задаче "разбиение". Если ответ будет "да", то все подмножества A'ÍA, удовлетворяющих условию s(A')£B, должны удовлетворять и условию s(A')£B-1. Поэтому ответом в задаче "разбиение" будет "нет". В противном случае должно существовать некоторое подмножество A'ÍA, удовлетворяющее условию s(A')=B. Поэтому ответом в задаче "разбиение" будет "да".
Мы видим, что данный тип сводимости, возможно, позволяет выйти за пределы класса NP и оценивать сложность задач, сформулированных не только в виде задач распознавания. Ряд известных оптимизационных задач мы задавали в форме распознавания: задача о коммивояжере, задача ЦЛП, задача о клике и др. В этой форме они принадлежат классу NP и, как мы ниже увидим, являются NP-полными. Их NP-полнота доказывается с использованием полиномиальной сводимости. Если их задавать в традиционной для них оптимизационной форме, то нельзя использовать понятие полиномиальной сводимости. В то же время можно использовать сводимость по Тьюрингу. Ко всем таким задачам можно по Тьюрингу сводить NP-полные задачи. Поэтому оптимизационная форма NP-полной задачи, как правило, является NP-трудной задачей.
Теорема Кука
Само понятие NP-полноты - инструмент исключительно описательный. Из приведенных выше утверждений легко получить следующую теорему.
Теорема. Если L1µL2 и L1 является NP-полной задачей, тогда LÎтакже NP-полная задача.
Это утверждение позволяет гипотетически разбить весь класс NP на части. То есть выделить в нем некоторое множество сравнительно простых задач. Это класс P. И множество задач самых сложных – класс NPC. Это множество NP-полных задач.
Пусть, например, появилась некоторая новая задача Z. Мы пытаемся оценить ее сложность. Если мы придумали полиномиальный алгоритм ее решения, то она относится к классу P. Если наши усилия по построению такого алгоритма долго не увенчиваются успехом, то мы можем попытаться доказать с помощью сформулированной теоремы NP-полноту задачи Z. Если это удается, то можно утверждать, что новая задача в некотором смысле не проще многих известных задач, NP-полнота которых уже доказана.
Но доказательство NP-полноты можно проводить разными способами. Пока нам ясно два: использовать сформулированную только что теорему и технику сведения одной конкретной задачи к другой или непосредственно исходить из определения. Первый способ кажется предпочтительней (да так, наверное, и есть). Но для применения теоремы нужно иметь хотя бы одну NP-полную задачу.
Вот в этом и основной смысл теоремы Кука. Он доказал, пользуясь только определением, NP-полноту одной конкретной задачи. Всюду в дальнейшем пустой символ будем обозначать через L.
Теорема Кука. Задача о выполнимости (ЗВ) NP-полна.
Мы приведем схему доказательства этой теоремы, взятую из лекций А.Разборова.
По определению NP-полноты мы должны доказать два факта.
1. ЗВ лежит в NP.
2. Любая задача Z из NP полиномиально сводится к ЗВ.
Для доказательства первого факта мы должны построить НМТ, которая за полиномиальное время решает ЗВ. Это очевидно. Действительно, вход задачи - КНФ f от p переменных x1,…,xp, заданная в виде конъюнкции из m конъюнкций. Если она обращается в единицу на некотором наборе значений переменных x1=a1,…,xp=ap, то угадывающая головка данный набор длины p напишет. Подстановка в формулу и проверка требует полиномильного по длине входа времени.
Доказательство второго факта строится по следующему принципу. По входу w задачи Z строится вход задачи ЗВ. Это некоторая КНФ fw, которая обращается в единицу тогда и только тогда, когда на слове w задача Z имеет ответ "да".
Так как задача Z (язык LZ) лежит в NP, то имеется НМТ TZ={S, A, F, q0, d}, решающая эту задачу (допускающая язык LZ) за полиномиальное от длины входа |w|=n время. Пусть p(n) - полином, ограничивающий число тактов работы NMT. Для простоты индексации будем считать, что подобрано подходящее k, такое что p(n)<nk.
Идея состоит в том, чтобы смысл данной фразы записать в виде логической формулы. Наглядно представить себе подобную формулу позволяет подробное описание всех шагов вычисления TZ на входе w. Их легче всего представить в виде таблицы, строки которой - конфигурации работы TZ на стадии проверки. Такая таблица называется допускающей таблицей и имеет вид.
| Номера конфигураций/ячеек | -nk | ... | v+1 | v | ... | -1 | 0 | 1 | ... | n | n+1 | ... | nk |
| 1 | L | … | L | av | … | a1 | q0 | w1 | … | wn | L | … | L |
| 2 | |||||||||||||
| ... | |||||||||||||
| nk |
Ее размеры очевидным образом ограничены условием полиномиального времени работы: количество столбцов не превосходит времени работы, а число строк просто равно числу тактов работы НМТ. В первой строке написана отгадка a1,…,av и код слова индивидуальной задачи (слово языка LZ) w1,…,wn . В следующей строке приведена конфигурация НМТ после первого такта ее работы и т.д. Ясно, что построение такой таблицы потребует полиномиального по длине входа n времени.
Грубо говоря, эта таблица будет теперь входом задачи о выполнимости. То есть, по ней мы построим некоторую КНФ, которая выполнима тогда и только тогда, когда данный вход описывает именно таблицу допустимости.
Логика же здесь простая. Должны быть справедливы одновременно четыре утверждения.
1. В каждой клетке таблицы записан ровно один символ, причем это или пустой символ, или буква алфавита A, или символ (номер) состояния из S. (Пусть это условие можно записать в виде некоторой конъюнкции f0).
2. В первой строке записана начальная конфигурация, например, в том виде, что на рисунке выше. (Пусть это условие можно записать в виде некоторой конъюнкции fstart).
3. В последней строке записана некоторая допускающая конфигурация, т.е. машина остановилась в состоянии qy. (Пусть это условие можно записать в виде некоторой конъюнкции faccept).
4. Каждая следующая строка в таблице получается вследствие допустимого перехода МТ. Этот переход осуществляется путем выполнения некоторой команды qiaj®qrat{Z},заданной функцией переходов d.(Пусть это условие можно записать в виде некоторой конъюнкции fcomputs).
В результате получаем КНФ
fw = f0&fstart&faccept&fcomputs.
Если она обращается в единицу, то выполняются все вышеприведенные четыре условия, которые влекут за собой допустимость некоторого корректного вычисления НМТ на индивидуальной задаче w некоторой массовой задачи Z. Набор значений переменных в задаче о выполнимости, на котором КНФ обращается в единицу, и даст нам содержимое допускающей таблицы, которая и описывает данное корректное вычисление.
С другой стороны, если мы имеем некоторое корректное вычисление НМТ на индивидуальной задаче w некоторой массовой задачи Z, то оно может быть представлено в виде допускающей таблицы, по которой строится КНФ
fw = f0&fstart&faccept&fcomputs.
И просто по построению эта КНФ должна быть выполнима на том входе, который задает содержимое допускающей таблицы.
Остается построить за полиномильное время четыре вышеупомянутые конъюнкции.
В качестве переменных рассмотрим множество булевских переменных
Var = {xijs, i=-nk,…,nk; j=-nk,…,nk; sÎSÈA}.
Эти переменные обращаются в единицу, если на пересечении i-й строки и j-го столбца допускающей таблицы стоит символ s.
Покажем, что первая из четырех конъюнкций f0 выражается в следующем виде.
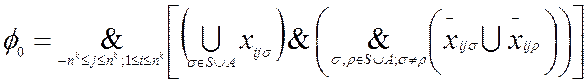
Знак конъюнкции означает, что логическое условие в скобках должно выполняться для каждой клетки таблицы. Первое из условий в круглых скобках соответствует требованию наличия в каждой клетки таблицы хотя бы одного символа (из области значений введенного выше множества переменных Var). То требование, что в клетке должно быть не более одного символа, записано в виде логического выражения во второй круглой скобке формулы для f0.
Так как число состояний и число символов алфавита являются константами, то длина выражения в скобках от n не зависит. Поэтому длина всей конъюнкции f0 равна O(n2k).
Следующая конъюнкция fstart выражается формулой
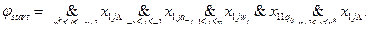
Здесь все понятно. Это просто логическая запись требования к содержимому первой строки таблицы. Для индивидуального входа w и отгадки a оно должно быть именно таким, как показано на рисунке выше. Длина всей конъюнкции fstart равна O(nk).
Что касается конъюнкции faccept , то она выражается формулой
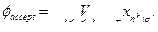
Смысл в том, что в последней строке допускающей таблицы должна стоять конфигурация, содержащая символ конечного состояния. Длина всей конъюнкции faccept равна O(nk).
Самым сложным является вычисление конъюнкции fcomputs. Мы не будем выписывать его во всей строгости, приведем лишь общую идею формулы. Как уже говорилось выше, эта конъюнкция должна быть формальной записью того условия, что каждая следующая строка в таблице получается вследствие допустимого перехода МТ. А сам переход осуществляется путем выполнения некоторой команды qiaj®qrat{Z},заданной функцией переходов d. Обозначим через fi(i+1) условие того, что правильно осуществлен переход между соседними конфигурациями. Тогда fcomputs выглядит следующим образом

Для нахождения fi(i+1) заметим следующее. Две соседние строки допускающей таблицы различаются не более чем в трех клетках. То есть все изменения сосредоточены в "окошке" таблицы" следующего вида
| (i,j-1) | (i,j) | (i,j+1) |
| (i+1,j-1) | (i+1,j) | (i+1,j+1) |
Первая строка таблицы правильно заполнена в силу условия fstart. Заполняем таблицу, начиная со второй строки. Поэтому в паре i-й и (i+1)-й строк проверка того условия того условия, что каждая следующая строка в таблице получается вследствие допустимого перехода МТ, сводится к правильности проверки заполнения (i+1)-й строки. Для этого "проходим" всю пару вышеупомянутыми окошками.
Если в верхней части окошка нет символа состояния, то в нижней части символы алфавита совпадают с верхними. Как только символ состояния встретился, читаем стоящий рядом символ алфавита. Так как число состояний, число букв алфавита и число правил переходы - постоянные величины, то логическое условие, определяющее правильность перехода между соседними конфигурациями, не зависит от n. Действительно, вспомним теорему о полноте базиса из трех булевых функций: &, È и Ø. В качестве простого упражнения можно записать упомянутое условие через эти функции.
Но для построения конъюнкции fi(i+1) все равно нужно пройти всю строку. Поэтому и длина всей конъюнкции fcomputs равна O(n2k).
Таким образом, все четыре требуемые конъюнкции построены за полиномиальное время.
Теорема доказана.
Итак, у нас появилась первая NP-полная задача. Для доказательства NP-полноты следующей задачи можно либо повторить что-то похожее на только что доказанную теорему, либо использовать понятие сводимости.
Дата: 2019-07-30, просмотров: 383.