Как было ранее показано (см. п. 2.1.), фактографические методы прогнозирования можно условно разделить на две большие группы: статистические и методы аналогий.
Статистические методы прогнозирования
Статистические методы изучены лучше всего, однако не являются единственно возможными. В ряде случаев прибегают к построению сценариев развития, морфологическому анализу, историческим аналогиям. Новым подходом к прогнозированию НТП является, в частности, «симптоматическое» прогнозирование, суть которого заключается в выявлении «предвестников» будущих сдвигов в технике и технологии. Однако в практике экономики преобладающими по-прежнему являются статистические методы (что связано с наличием инерционности). Немаловажным является и то, что статистические методы опираются на аппарат анализа, развитие и практика которого имеют достаточно длительную историю.
Процесс статистического прогнозирования распадается на 2 этапа:
• Индуктивный, заключающийся в обобщении данных, наблюдаемых за более или менее продолжительный период времени, и в представлении соответствующих статистических закономерностей в виде модели. Процесс построения модели включает: выбор формы уравнения, описывающего динамику или взаимосвязь явлений; оценивание его параметров.
• Дедуктивный — собственно прогноз. На этом этапе определяют ожидаемое значение прогнозируемого показателя.
Не всегда статистические методы используются в чистом виде. Часто их включают в виде важных элементов в комплексные методики, предусматривающие сочетание статистических методов с другими, например, экспертными оценками.
Статистические методы основаны на построении и анализе динамических рядов, либо данных случайной выборки. К ним относятся методы прогнозной экстраполяции, корреляционный и регрессионный анализ. В группу статистических методов можно включить метод максимального правдоподобия и ассоциативные методы — имитационное моделирование и логический анализ.
Динамику исследуемых показателей развития хозяйственной системы можно прогнозировать при помощи двух различных групп количественных методов: методов однопараметрического и многопараметрического прогнозирования. Общим для обеих групп методов является, прежде всего, то, что применяемые для параметрического прогнозирования математические функции, основываются на оценке измеряемых значений прошедшего периода (ретроспективы). Однопараметрическое прогнозирование базируется на функциональной зависимости между прогнозируемым параметрам (переменной) и его прошлым значением, либо фактором времени.
ŷt+1=ſ(yt,yt-1,…,yt-n). (2.1)
При обработке таких прогнозов пользуются методом экстраполяции трендов, экспоненциальным сглаживанием или авторегрессией.
В основе многопараметрических прогнозов лежит предположение о причинной взаимосвязи между прогнозируемым параметром и несколькими другими независимыми переменными:
ŷt+1=f(x), или; (2.2)
ŷt+1=f(x1, x2,…, xn).
Однопараметрические методы следует использовать при краткосрочном (менее одного года) прогнозирования показателей, изменяющихся еженедельно или ежемесячно. Многопараметрические оправдывают себя для средне- и долгосрочного прогнозирования.
 |
Да нет да нет
Нет
|
 |  |  | |||||
 | |||||||
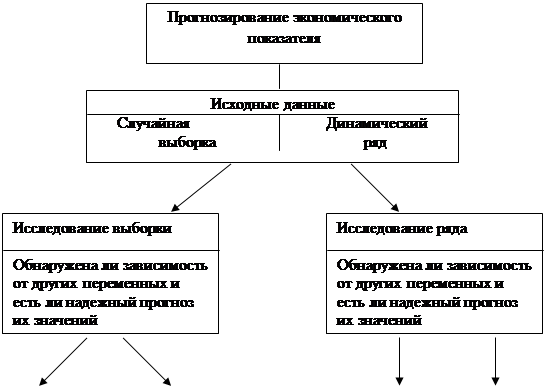
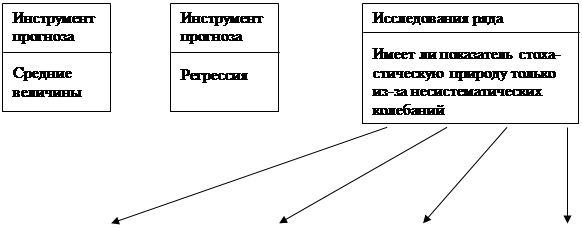
Рис.2.2.Схема выбора статистического метода прогнозирования
Выбор конкретного параметрического метода прогнозирования, кроме того, зависит от характера исходной статистической базы. В качестве исходных данных могут быть взяты выборочные наблюдения и динамические ряды. В первом случае в качестве инструмента прогноза применяется регрессия. Значительно чаще, чем случайная выборка, информационной базой для прогноза являются динамические ряды.
Тогда в качестве инструментов прогноза выступают тренды, авторегрессия, смешанная авторегрессия и т.п. Выбор адекватного подхода зависит от того, обнаружены ли экзогенные факторы, влияющие на значение зависимой переменной или нет, влияют ли на зависимую переменную предшествующие значения этой же переменной и т.д. В целом процесс выбора конкретного метода статистического параметрического прогнозирования показан на рис. 2.2. [39].
Методы экстраполяции сводятся к обработке имеющихся данных об объекте прогнозирования за прошлое время и распространению обнаруженной в прошлом тенденции на будущее.
Методы моделирования — наиболее сложный метод прогнозирования, состоящий из разнообразных подходов к прогнозированию сложных систем, процессов и явлений. Эти методы могут пересекаться и с экспертными методами.
Экстраполяция трендов
Наиболее распространенными из группы математических методов являются методы прогнозной экстраполяции. Временной ряд при экстраполяции представляется в виде суммы детерминированной (неслучайной) составляющей, называемой трендом, и стохастической (случайной) составляющей, отражающей случайные колебания или шумы процесса.
Прогнозную экстраполяцию можно разбить на два этапа.
• Выбор оптимального вида функции, описывающей ретроспективный ряд данных. Выбору математической функции для описания тренда предшествует преобразование исходных данных с использованием сглаживания и аналитического выравнивания динамического ряда.
• Расчет коэффициентов (параметров) функции, выбранной для экстраполяции.
Для оценки коэффициентов чаще остальных используется метод наименьших квадратов (МНК).
Сущность МНК состоит в отыскании коэффициентов модели тренда, минимизирующих ее отклонение от исходного временного ряда:
S = ∑(yt - ŷ)2 → min, (2.3)
где ŷ, - расчетные (теоретические) значения тренда;
у — фактические значения ретроспективного ряда;
n — число наблюдений.
Подбор модели в каждом конкретном случае осуществляется по целому статистически ряду критериев (дисперсии, корреляционному отношению и др.). Кроме того, для выбора зависимости
ŷt=f(t)
существует несколько подходов. Это метод последовательных разностей, метод характеристик прироста, визуальный (глазомерный) выбор формы. Расчет оценок прироста показателя, дополненный визуальным выбором взаимосвязи, уменьшает риск неправильного выбора модели для прогнозирования. В частности, могут быть рекомендованы следующие аппроксимирующие зависимости:
∆ Y / ∆ t = const → ŷt =a0 + a1 t, (2.4)
∆ ln y / ∆ t = const → ŷt = a0 ta, (2.5)
∆ ln y / ∆ ln t = const → ŷt = a0 tt1, (2.6)
∆ Y2 / ∆ X2 = const → ŷt = a0 + a1 t + a2 t2, (2.7)
∆ (t / y) / ∆ t = const → ŷt = t / (a0 + a1 t). (2.8)
В Приложении 1 показаны графические зависимости, позволяющие осуществлять визуальный выбор формы зависимости прогнозируемого показателя от фактора времени, а в Приложении 2 - системы нормальных уравнений, применяемые для оценки параметров полиномов невысоких степеней.
Для выявления более четкой тенденции уровни, нанесенные на график, можно сгладить (элиминировать) с помощью трех приемов:
• метода технического выравнивания - когда на графике визуально (на глаз) проводится равнодействующая линия, отражающая на взгляд исследователя тенденцию развития;
• метода механического сглаживания - расчет скользящих и экспоненциальных средних;
• метода аналитического выравнивания - построение тренда.
Преимущество трендовой модели в более высокой степени надежности. Кроме того, она позволяет экономически интерпретировать параметры уравнения тренда и достаточно наглядно изображает тенденцию и отклонения от нее на графике.
В рыночной ситуации можно порекомендовать конкретные виды функций, наиболее пригодные для экстраполяции [29].
Спрос на ряд непродовольственных товаров может быть описан степенной функцией или экспонентой (особенно на активных этапах жизненного цикла товаров). Общие закономерности спроса отражаются кривой Гомперца. При изучении влияния фактора времени на спрос может быть использована логистическая (сигмоидальная) кривая. Процесс затухания роста спроса по мере перехода населения к группам населения с более высоким доходом отражается полулогарифмической кривой.
В развитии рынка как единого экономического пространства (как и в развитии локальных рынков) могут проявиться определенная повторяемость, цикличность, обусловленная как внутренними свойствами рынка, так и внешними причинами.
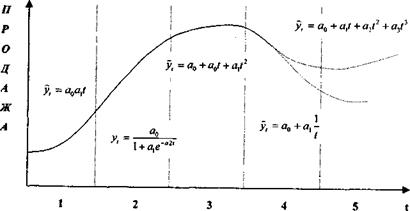
Рис. 2.3. Моделирование тенденции продажи товара по стадиям жизненного цикла
Условные обозначения:
1 - выведение товара на рынок; 2 - рост; 3 - зрелость; 4 - упадок; 5 - реанимация спроса.
Внутригодовая цикличность носит часто сезонный характер.
При изучении сезонных процессов часто применяется спектральный анализ, который позволяет прогнозировать тенденции, динамика которых содержит колебательные или гармонические составляющие [31].
Сезонные волны можно описать гармоникой ряда Фурье:
ŷ=α0+∑mk(αk coskt + bk sinkt), (2.9)
где t - номер гармоники ряда Фурье;
а о и а k , bk — определяют по МНК;
k - число гармоник (1,2,...)
В условиях переходной экономики возрастает значимость прогнозирования жизненного цикла товара (ЖЦТ). Автором концепции ЖЦТ считается известный маркетолог Теодор Левитт, предложивший ее в 1965г.
Суть прогноза заключается в том, чтобы определить, как надолго и насколько интенсивно будет сохраняться спрос на данный товар. Прогноз ЖЦТ - многоплановый процесс, важной составляющей которого является подбор для каждого этапа соответствующей трендовой модели, отражающей не только рост, стабилизацию или спад, но и степень ускорения или замедления этих процессов. Такой прогноз является составным элементом прогнозирования покупательного спроса и рыночной конъюнктуры.
Жизненный цикл товара можно графически смоделировать в виде сложной кривой (рис. 2.3).
Математически смоделировать весь жизненный цикл товара практически невозможно, пришлось бы использовать сложную многочленную функцию, которую трудно интерпретировать. Целесообразно использовать метод линейно-кусочных агрегатов, то есть моделировать и прогнозировать каждый этап ЖЦТ с помощью трендовой и (или) многофакторной модели, отражающей закономерности каждого этапа.
Отмеченные ранее методы механического выравнивания могут также выступать в роли самостоятельных методов статистического прогнозирования.
Прогнозирование на основе адаптивных скользящих средних производится с использованием следующих формул:
Mi = Mi-1 + (yi - yi-m) / (m), (2.10)
где Mi – скользящая средняя, отнесенная к концу интервала.
Mi = ŷt = (∑t+pi=1 yi) / (m). (2.11)
Первый член уравнения (2.10) – Мi-1 несет «груз прошлого» - инерцию развития, а второй адаптирует среднюю к новым условиям. Таким образом, средняя как бы обновляется, «впитывая» информацию о фактически реализуемом процессе (степень обновления определяется весом 1/т).
Экспоненциальные средние. Влияние прошлых наблюдений должно затухать по мере удаления от момента, для которого определяется средняя. Для этой цели используют экспоненциальное сглаживание, применяемое в краткосрочном прогнозировании (идея Н.Винера):
Qt = α · yt + (1+α) · Qt-1, (2.12)
где Qt - экспоненциальная средняя на момент t ;
а - коэффициент, характеризующий вес текущего наблюдения (параметр сглаживания).
При расчете по формуле (2.12) необходимо выбрать Qt-1. Часто
Qt-1 принимают равным yt.
Применение метода успешно, когда ряд имеет достаточно большое число уровней. Чем меньше а, тем больше роль «фильтра», поглощающего колебания 0< а <1. Практически диапазон а ограничивается величинами 0,1; 0,3. Хорошие результаты дает а = 0,1. При выборе а следует иметь в виду, что для повышения скорости реакции на изменение процесса развития необходимо повысить а, однако это уменьшает «фильтрационные» возможности средней.
Специфика экономических процессов состоит в том, что они обладают взаимосвязью и инерционностью (см. п. 1.3). Последнее означает, что значение фактического показателя в момент времени зависит определенным образом от состояния этого показателя в предыдущих периодах, т.е. значения прогнозируемого показателя должны рассматриваться как факторные признаки. Уравнение авторегрессионной зависимости в общем имеет вид:
ŷt = α0 + α1 · yt-1 + α2 · yt-2 +...+ αk · yt-k, (2.13)
где ŷt – прогнозируемые значения показателя в момент времени t;
yt-1 – значения показателя y в момент времени (t-i);
α1 – i-тый коэффициент регрессии.
Часто прогнозируемый показатель зависит не только от предшествующих состояний, но и от других факторов x. Тогда говорят о смешанной авторегрессии:
ŷt = α1 · yt-1 + α2 · yt-2 +...+ αk · yt-k + b1 · x1 + b2 · x2 +...+ bm · xm =
= ∑ki=1 αi · yt-I + ∑mj=1 bj · xj. (2.14)
Оценки αi и bj находят по МНК.
Все приведенные выше модели позволяют получить точечные оценки. Для определения наиболее вероятных интервалов варьирования прогнозных показателей необходимо найти доверительные оценки. В общем виде расчет доверительного интервала может быть представлен следующим образом:
ŷt+a ± ta Sŷ, (2.15)
где ŷt+a - точечный прогноз;
Sŷ – средняя квадратическая ошибка прогноза;
ta – t-статистика Стьюдента;
α – период упреждения прогноза.
В общем виде для полиномов различных степеней:
 |
Sŷt+2 = Sy √T`α (T` · T)-1 · Tα, (2.16)
где (T` · T) – матрица системы нормальных уравнений;
Sy – среднее квадратическое отклонение фактических значений от расчётных.
В частности, для линейного тренда:
 |
Sŷ = Sy √1 + 1 : n + (tα - t)2 : ∑(t')2, (2.17)
Где tα – заданное на период упреждения значение переменной t,
t – среднее значение t, т.е. значение порядкового номера уровня, стоящего в середине ряда;
∑(t')2 – сумма квадратов отклонений значений независимой переменной от их средней.
Важно иметь в виду, что экстраполяция в рядах динамики носит приближенный и условный характер. Поэтому применение методов экстраполяции не должно становиться самоцелью, а при разработке социально-экономических прогнозов должна привлекаться дополнительная информация, на основе которой в полученные методом экстраполяции количественные оценки вносятся соответствующие коррективы.
Дата: 2019-07-30, просмотров: 436.