Аннотация
В рамках данного дипломного проекта разработан интерпретатор языка Пролог с визуальным вводом программы и возможностью работы с универсальными базами данных.
Настоящая пояснительная записка включает в себя описание механизма вывода в языке Пролог и роли логического программирования в развитии вычислительной техники.
Приводится описание разработанного интерпретатора, а также необходимые для работы с ним документа: требования по эксплуатации, руководство по установке, руководство пользователя, тексты программ.
Приводится расчет затрат на разработку программного продукта.
Приводится анализ опасных и вредных факторов, возникающих при эксплуатации программы интерпретатора.
Содержание
Введение.......................................................................................................... 4
1. Исследовательская часть............................................................................. 8
1.1. Роль реляционных языков в развитии вычислительной техники.......... 8
1.2. Основные механизмы дедукции............................................................ 10
1.3. Исчисление предикатов как язык для решения задач.......................... 12
1.3.1 Унификация и принцип резольвенции в исчислении предикатов...... 13
1.3.2. Методы поиска доказательства в исчислении предикатов................ 15
1.3.2.1. Исчисление предикатов при решении задач................................... 15
1.3.2.2. Стратегии перебора......................................................................... 16
1.3.2.3. Стратегии упрощения...................................................................... 17
1.3.2.4. Стратегии очищения........................................................................ 18
1.3.2.5. Формы доказательства с отфильтровыванием предшествующих вершин........................................................................................................................... 4
1.3.2.6. Стратегии поддерживающего множества......................................... 4
1.3.2.7. Стратегии упорядочения................................................................... 5
1.4. Анализ характеристик существующих интерпретаторов...................... 6
1.5. Необходимость разработки интерпретатора языка Пролог................. 8
1.6. Выбор языка программирования........................................................... 8
2. Конструкторская часть............................................................................. 10
2.1. Синтаксис программ на Прологе в нотации Бэкуса-Наура................. 10
2.2. Общая структура интерпретатора........................................................ 10
2.2.1. Принцип работы предкомпилятора................................................... 11
2.2.1.1. Работа лексического анализатора................................................... 11
2.2.1.2. Синтаксический анализатор............................................................ 12
2.2.1.3. Анализ арифметического выражения............................................. 13
2.2.1.4. Анализ параметров предикатов...................................................... 15
2.2.1.5. Проверка типов параметров............................................................ 15
2.3. Работа интерпретатора.......................................................................... 16
2.3.1. Выполнение обращений к базам данных........................................... 18
2.3.2. Вычисление арифметических выражений.......................................... 19
2.4. Объекты, используемые компилятором и интерпретатором............... 19
2.4.1. Объекты переменных TPrologVariable, TPrologVariables, TPrologVariableList, TPrologVariableStruct.................................................................................... 19
2.5.2. Стандартные функции и предикаты................................................... 21
2.6. Представление Пролог-программы в виде объектов........................... 21
2.7. Основные модули................................................................................... 23
2.8. Демонстрационная программа по выбору конфигурации компьютера. 25
3. Технологическая часть.............................................................................. 28
3.1. Требования по эксплуатации интерпретатора языка Пролог............. 28
3.2. Установка системы................................................................................. 28
3.3. Руководство пользователя программы интерпретатора языка Пролог. 29
3.3.1. Запуск программы.............................................................................. 29
3.3.2. Перечень функций, реализуемых системой....................................... 29
3.3.3. Редактирование Пролог-программы................................................. 29
3.3.4. Запуск программы на Прологе и ее отладка..................................... 34
3.3.5. Работа с меню...................................................................................... 35
3.4. Описание процесса выполнения программы, написанной на языке Пролог. 38
3.5. Общие сведенья об интерпретаторе...................................................... 39
3.6. Особенности работы Пролог-программы с базами данных................ 39
3.7. Описание стандартных предикатов....................................................... 40
3.8. Описание функций.................................................................................. 43
4. Организационно-экономическая часть.................................................... 45
4.1. Расчет затрат на разработку интерпретатора Пролог......................... 45
5. Промышленная экология и безопасность................................................ 47
5.1. Введение................................................................................................. 47
5.2. Анализ характера загрязнения окружающей среды при производстве вычислительной техники............................................................................... 48
5.2.1. Источники загрязнения....................................................................... 48
5.2.2. Очистка воздуха от вредных примесей.............................................. 50
5.3. Анализ влияния опасных и вредных факторов, при эксплуатации программы интерпретатора Пролог................................................................................ 52
5.3.1. Повышенный уровень шума на рабочем месте................................. 53
5.3.2. Опасный уровень напряжения электрической цепи, замыкание которой может произойти через человека............................................................................. 54
5.3.3. Пожарная опасность........................................................................... 55
5.3.4. Повышенный уровень электромагнитных излучений....................... 56
5.3.5 Повышенная яркость света.................................................................. 57
5.3.6. Прямая и отраженная блеклость........................................................ 58
5.3.7. Нарушение микроклимата рабочих помещений............................... 58
5.3.8. Защита от психофизиологических факторов..................................... 59
5.4. Анализ использования защитных экранов для снижения влияния опасных и вредных факторов, во время работы на автоматизированном рабочем месте. 60
5.4.1 Основные функции защитных экранов, необходимые для снижения влияния вредных и опасных факторов, во время работы с программным средством. 60
5.4.1.1. Защита от электростатического и электромагнитного воздействий. 61
5.4.1.2. Защита от рентгеновского излучения............................................. 61
5.4.1.3. Защита от ультрафиолетового излучения...................................... 61
5.4.2. анализ основных типов защитных экранов, которые приемлемы для снижения влияния вредных и опасных факторов, во время с программным средством. 62
5.4.2.1. Сетчатый (частичная защита зрения).............................................. 62
5.4.2.2. Стеклянный двухслойный с заземлением (частичная защита зрения, частичная защита здоровья)......................................................................... 62
5.4.2.3. Стеклянный многослойный с заземлением (полная защита зрения, полная защита здоровья).......................................................................................... 63
5.5. Расчет необходимого звукопоглощения, при работе с АРМ............... 63
Заключение.................................................................................................... 66
Литература.................................................................................................... 67
Приложения................................................................................................... 68
Приложение 1................................................................................................ 68
Приложение 2................................................................................................ 73
Приложение 3................................................................................................ 81
Приложение 4................................................................................................ 87
Введение
Разрабатываемый программный продукт предназначен для визуального создания, редактирования и интерпретации программ, написанных на языке Пролог с возможностью работы с универсальными базами данных.
Постоянно возрастающий объем информации, которую необходимо обрабатывать современным компьютерам предъявляет более широкие требования к современным базам данных. Если на заре развития компьютерной техники база данных была обычным файлом, который представлял собой типизированный файл, к которому можно было обращаться по абсолютному номеру записи, то сейчас база данных представляет собой интеллектуальную среду, которая включает в себя подчас несколько таблиц с данными, связанными между собой. Причем конечный пользователь из-за сложности структуры базы не знает, в каком месте файла хранятся данным, с которыми он работает. Современные базы данных обладают встроенными возможностями защиты прав доступа, а также способами поддержки целостности данных и их непротиворечивости. Это достигается за счет включения в сами базы данных отдельный частей программы, которые действуют независимо от пользовательской программы как программы-серверы. Доступ к таблицам стал значительно проще за счет использования языка SQL, который помогает быстро выбирать нужный пользователю сегмент информации из общего объема, также удалять ненужную информацию и добавлять новую.
Базы данных сейчас используются не только как обычные хранилища информации, но и как хранилища знаний. Поэтому появляется новое требование к базам данных, которое пришло от баз знаний, - это возможность логического вывода новых знаний из уже известных, а также работа в режиме экспертной системы.
В самом узком смысле термин экспертная система используется для описания одной из небольшого числа программ, разработанных общепризнанными специалистами в инженерии знаний. Назначение этих программ состоит в воспроизведении возможности решения задач, которыми обладает эксперт. Большинство экспертных систем не может полностью заменить человека. Такие системы используются для повышения эффективности работы и расширения знаний персонала средней квалификации.
В широком смысле экспертная система - это любая программа, применяемая для экспертных консультаций. Данное определение охватывает все программы, используемые в качестве экспертных систем, не учитывая того момента, что истинные эксперты могли и не участвовать в создании этих программ.
В любой системе экспертных консультаций обязательно должны иметься следующие три компоненты:
1. язык представления знаний, с помощью которого можно интуитивно представить знания о сложной области;
2. стратегия решения задач, позволяющая выполнять действия с представленными знаниями столь же компетентно, как это делают эксперты-люди;
3. интерфейс с пользователем, обеспечивающий естественность и удобство доступа к знаниям, которыми обладает программа, и способный объяснять свои ответы, как неопытным пользователям, так и пользователям-экспертам[1].
Традиционным языком в создании экспертным систем является язык Пролог. Это классический язык логического программирования. Он имеет встроенный механизм вывода, основанный на принципе резолюций, помогающий формально обращаться со знаниями. Кроме того, язык Пролог является реляционным языком программирования, то есть оптимально приспособлен для работы с реляционными базами данных. Так как Пролог оперирует правилами, программисту не нужно задумываться над программированием последовательности действий для машины, как это делается при программировании на процедурных языках. Программист просто составляет совокупность правил, описывающую данную предметную область, а Пролог выполняет составленную программу, используя алгоритм бэктрекинга.
Как указывалось ранее, немаловажным в экспертной системе является интерфейс с пользователем как профессионалам в данной предметной области, так и непрофессионалом. Вследствие этого, интерфейс с человеком должен осуществляться на естественном языке. Так как Пролог является декларативным языком и основан на исчислении высказываний, то на нем достаточно несложно можно написать обработку естественного языка.
Актуальным вопросом всегда был вид представления знаний. Изначально в Прологе база знаний хранилась в текстовом файле в формате языка Пролог, который загружался в память, и компилировался во время исполнения программы. Это было явным недостатком Пролога, так как ведение такой базы знаний возможно только человеком и только вручную, то есть, используя только текстовый редактор, а не какую-то специализированную программу. Это ограничивало возможности применения Пролога. Кроме этого, еще одним ограничением было то, что Прологу приходилось загружать в память всю базу знаний. То есть, если оперативной памяти компьютера не хватало, то программа не могла работать.
Подключение к Прологу универсальных баз данных позволяет снять эти два ограничения. Универсальными базами данных могут пользоваться другие программы, которые специализированы для ввода того или иного формата представления знаний. Таким образом, увеличивается скорость и качество ввода знаний. Более того, знания могут добавляться прямо по ходу выполнения Пролог-программы. Становится возможным поступление данных сразу с разных точек (с разных компьютеров).
Также использование баз данных позволяет снять ограничение на объем оперативной памяти компьютера, так как менеджер баз данных грузит в память только те данные, которые требуются в настоящий момент, а не все сразу. Также не нужна компиляция знаний во время выполнения программы, так как они уже находятся в нужном формате. Использование баз данных замедляет скорость работы программы, так как ей приходится обращаться к диску за данными, но менеджер баз данных позволяет уменьшить это замедление за счет кэширования данных и опережающего чтения.
Разрабатываемая система позволяет снять высокие требования к объему памяти компьютера, так как использует универсальные базы данных. Теперь база знаний может храниться в файле базы данных и загружаться в память компьютера по необходимости. Использование баз данных позволяет работать с одной базой знаний нескольким программам, а также предоставляется возможность удобного редактирования базы с помощью других программ. Загрузка и поиск записей в БД возложена на операционную систему, которая централизовано и эффективно распределяет доступ к базам данных для нескольких программ, а также за счет встроенного кэширования позволяет снизить зависимость скорости выполнения программы от скорости работы диска.
Система содержит интегрированную среду разработчика, которая предоставляет широкие возможности по визуальному вводу, редактированию и отладке программы на Прологе.
Исследовательская часть
Техники
В настоящее время растет круг практических систем, использующих достижения искусственного интеллекта на современных ЭВМ, появились престижные проекты создания ЭВМ новых поколений, в которых интеллектуальный интерфейс с конечным пользователем (непрофессионалом в информатике) является центральным элементом. В японском проекте создания ЭВМ пятого поколения язык Пролог прямо называется базовым языком программирования[5].
Близость Пролога к конечному пользователю объясняется тем, что он является декларативным языком. Чтобы задать определенную последовательность действий, приводящих к решению задачи, в программе на Прологе необходимо описать ее содержание в терминах объектов и отношений между ними. Таким образом, вместо алгоритма решения задачи, программист составляет ее логическую спецификацию.
Что же касается построения алгоритма, то это автоматически выполняется самой Пролог-системой с помощью встроенного механизма вывода. При этом цель решения задачи представляется в виде запроса к базе знаний, в которой содержится описание предметной области задачи. Для поиска в базе данных значений, требуемых в запросе, Пролог-система инициирует механизм вывода. Таким образом, вычисления в Прологе представляют собой процесс дедукции, направленный на построение доказательства целевого утверждения задачи.[1]
Семантика языка Пролог значительно отличается от семантики других языков программирования. Вообще, языки программирования можно разбить на три широкие категории в соответствии с природой семантики этих языков:
· Процедурные языки;
· Функциональные языки;
· Реляционные языки.
Смысл конструкции процедурного языка определяется в терминах поведения компьютера при выполнении этой конструкции. В функциональном языке смысл конструкции (например, вызов функции) определяется в терминах значения, которое она вырабатывает. А в реляционном языке – отношение между отдельными сущностями или классами сущностей. Таким образом, процедурные языки можно назвать языками низкого уровня, так как они дают картину мира, близкую к взгляду на мир с позиций компьютера. Языки же высокого уровня обеспечивают взгляд на мир, приближающийся к картине мира, представленной в спецификации задачи. При использовании идеального реляционного языка становится возможным написание программы, структурно изоморфной по отношению к своей спецификации, то есть для каждой вариации формы спецификации будет существовать соответствующая вариация формы программы.
Хотя Пролог и далек от идеального реляционного языка, он в то же время достаточно близок к такому языку. Это позволяет программисту воспользоваться упомянутыми выше преимуществами идеальных реляционных языков. Программист может мыслить в терминах структуры отношений, не заботясь о точности их трансляции в программу. То есть данный язык позволяет работать специалисту на высоком концептуальном уровне.[1]
Возможны три точки зрения программиста на Пролог-программу.
1. Реляционный подход. При этом программа рассматривается как множество взаимоопределенных, возможно очень сложных, взаимоотношений. Реляционный подход пригоден в том случае, когда хорошо известна структура предметной области. Процесс программирования при этом сводится к аксиоматическому определению каждого отношения. Входной и выходной потоки, а также поведение программы являются результатами действия запросов к отношению. Если отношение реализовано корректно, то будут правильными также входной и выходной потоки.
2. Подход к программе с позиций потока данных. Такой взгляд на программу уместен, когда известна природа выходного потока (то есть множество ответов). При программировании реализуется такая внутренняя структура программы, которая создает желаемый выходной поток. Если важен порядок следования ответов в выходном потоке, то при построении программы следует в явной форме учитывать процедурные факторы.
3. Поведенческий подход к программе. Поведенческий подход пригоден тогда, когда известно лишь желаемое поведение программы. Процесс программирования связан с построением такой внутренней структуры программы, которая обеспечит заданное поведение. При разработке такой программы следует обязательно учитывать процедурные факторы и влияние побочных эффектов.
Эти три подхода не являются взаимоисключающими, они представляют собой разные способы мышления в процессе программирования. С точки зрения стиля программирования рекомендуется применять либо реляционный подход, либо подход к программе с позиций потока данных, а к поведенческому следует прибегать лишь в случае крайней необходимости. Причина заключается в том, что программы, при составлении которых применялся поведенческий подход, почти всегда трудно читать, сопровождать и переводить с одной версии Пролог на другую.
Основные механизмы дедукции
Существуют два метода логического вывода, называемые прямой цепочкой рассуждений и обратной цепочкой.
Прямая цепочка рассуждений предполагает использование правил для логического вывода новых фактов, а также фактов, которые имплицитно существовали ранее, но могут быть сделаны явными посредством применения правил. То есть механизм вывода работает для пополнения изначального запаса истинных фактов фактами, которые подразумеваются посредством набора правил. Подобная прямая цепочка рассуждений на практике неприменима: в системе с реальным числом правил имеется столь много подразумеваемых (скрытых) фактов, что, будучи обнаружены, они затмят те несколько фактов, которые действительно представляют интерес и являются полезными.
Однако системы, основанные на прямой цепочке рассуждений, существуют. Любая такая система имеет дополнительный механизм (иногда весьма специфичный в зависимости от проблемы) для того, чтобы определить, с каким следующим правил ей предстоит работать. Вместо простого цикла, который механически выбирает правила, механизм выбора четко устанавливает приоритет выбора тех или иных фактов и правил.
Рассмотрим теперь иной способ получения логического вывода на основе фактов и правил. Начнем с заключения, которое представляет для нас интерес и не является явным истинным фактом. Оно не находится среди хранимых фактов, когда мы запускаем систему.
Механизм вывода просматривает все правила, которые приводят к данному факту как к заключению. Затем механизм просматривает посылки этих правил. Возможно, они уже хранятся среди истинных фактов. Тогда можно считать, что изучаемых факт является истинным и должен быть добавлен в хранилище истинных фактов. Если ни одно из правил не может быть использовано для непосредственного определения рассматриваемого значения из-за того, что необходимо установить истинность их посылок, то в таком случае необходимо идти в обратном направлении и попытаться установить достоверность всех посылок в тех правилах, которые могут применяться для установления истинности конечного вывода. Перемещение на много уровней назад в древовидной структуре даст нам факты, которые являются истинными. Это и есть обратная цепочка рассуждений.
Механизм вывода на Прологе основан на обратной цепочке рассуждений. Процесс выполнения программы сводится к установлению истинности определенного предложения в Прологе (и обычно в определении величин определенных переменных в процессе) посредством обратной цепочки рассуждений и продолжается до тех пор, пока не будут найдены некоторые базовые истинные факты, известные системе.[3]
Предикатов
Унификация – процесс, являющийся основным в формальных преобразованиях, выполняемых при нахождении резольвент.
Термы литерала могут быть переменными буквами, константными буквами и выражениями, состоящими из функциональных букв и термов. Подстановочный частный случай литерала получается при подстановке в литералы термов вместо переменных. Например, для литерала 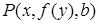 частными случаями будут
частными случаями будут 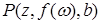 ,
, 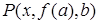 ,
, 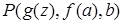 ,
, 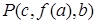 .
.
Первый частный случай называется алфавитным вариантом исходного литерала, поскольку здесь вместо переменных, входящих в 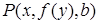 , подставлены лишь частные переменные. Последний из четырех частных случаев называется константным частным случаем, или атомом, так как ни в одном из термов этого литерала нет переменных.
, подставлены лишь частные переменные. Последний из четырех частных случаев называется константным частным случаем, или атомом, так как ни в одном из термов этого литерала нет переменных.
В общем случае любую подстановку можно представить в виде множества упорядоченных пар 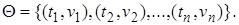 Пара
Пара 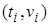 означает, что повсюду переменная
означает, что повсюду переменная 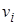 заменяется термом
заменяется термом 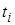 . Существенно, что переменная в каждом ее вхождении заменяется одним и тем же термом. Для получения частных случаев литерала
. Существенно, что переменная в каждом ее вхождении заменяется одним и тем же термом. Для получения частных случаев литерала  были использованы четыре подстановки
были использованы четыре подстановки
Обозначим через  частный случай литерала P, получающийся при использовании подстановки
частный случай литерала P, получающийся при использовании подстановки 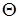 . Например,
. Например, 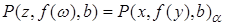 . Композицией
. Композицией  двух подстановок
двух подстановок  и
и  называется результат применения
называется результат применения  к термам подстановки с последующим добавлением пар из , содержащие переменные, не входящие в число переменных из . Можно показать, что применение к литералу P последовательно подстановок и дает тот же результат, что и применение подстановки , то есть
к термам подстановки с последующим добавлением пар из , содержащие переменные, не входящие в число переменных из . Можно показать, что применение к литералу P последовательно подстановок и дает тот же результат, что и применение подстановки , то есть  . Можно также показать, что композиция подстановок ассоциативна:
. Можно также показать, что композиция подстановок ассоциативна: 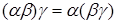 . Если подстановка применяется к каждому элементу множества
. Если подстановка применяется к каждому элементу множества 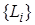 литералов, то множество соответствующих ей частных случаев обозначается через
литералов, то множество соответствующих ей частных случаев обозначается через 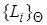 . Множество литералов называется унифицируемым, если существует такая подстановка , что
. Множество литералов называется унифицируемым, если существует такая подстановка , что 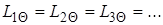 . В этом случае подстановку называют унификатором , поскольку ее применение сжимает множество до одного элемента. Наиболее общим (или простейшим) унификатором для будет такой унификатор
. В этом случае подстановку называют унификатором , поскольку ее применение сжимает множество до одного элемента. Наиболее общим (или простейшим) унификатором для будет такой унификатор 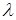 , что если - какой-нибудь унификатор для , дающий , то найдется подстановка
, что если - какой-нибудь унификатор для , дающий , то найдется подстановка  , для которой
, для которой 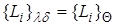 .
.
Существует алгоритм, называемый алгоритмом унификации, который приводит к наиболее общему унификатору для унифицируемого множества литералов и сообщает о неудаче, если множество неунифицируемо. Алгоритм начинает работу с пустой подстановки и шаг за шагом строит наиболее общий унификатор, если такой существует.
Пусть исходные предложения задаются в виде и 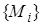 и переменные, входящие в
и переменные, входящие в  , не встречаются в и обратно. Пусть
, не встречаются в и обратно. Пусть  и
и 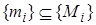 - такие два подмножества и , что для объединения
- такие два подмножества и , что для объединения 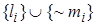 существует наиболее общий унификатор
существует наиболее общий унификатор 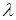 . Тогда говорят, что два предложения
. Тогда говорят, что два предложения 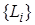 и разрешаются, а новое предложение
и разрешаются, а новое предложение 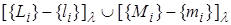 является их резольвентой. Резольвента представляет выведенное предложение, и процесс образования резольвенты из двух "родительских" предложений называется резольвенцией.
является их резольвентой. Резольвента представляет выведенное предложение, и процесс образования резольвенты из двух "родительских" предложений называется резольвенцией.
Иными словами мы хотим иметь возможность находить доказательство того, что некоторая правильно построенная формула W в исчислении предикатов логически следует из некоторого множества S правильно построенных формул. Это задача эквивалентна задаче доказательства того, что множество 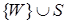 неудовлетворимо. Процессы выявления неудовлетворимости некоторого множества предложений называются процессами опровержения.
неудовлетворимо. Процессы выявления неудовлетворимости некоторого множества предложений называются процессами опровержения.
Принцип резольвенции непротиворечив и полон. Непротиворечивость означает, что если когда-нибудь мы придем к пустому предложению, то исходное множество обязано быть неудовлетворимым. Полнота означает, что если исходное множество неудовлетворимо, то, в конце концов, мы придем к пустому предложению.[2]
Стратегии перебора
Непосредственное применение принципа резольвенции соответствует простой процедуре полного перебора при построении опровержения. Такой перебор мы начинается множества S, к которому добавляется резольвенты всех пар предложений в S с тем, чтобы образовать множество R. Затем добавляются резольвенты всех пар предложений в R с тем, чтобы образовать множество R(R(S))=R2(S), и т.д. Этот метод перебора как правило непригоден для практики, так как множества R(S), R2(S),… слишком быстро разрастаются. Практические процедуры доказательства определяются стратегиями перебора, применяемыми для его ускорения. Такие стратегии бывают трех типов: стратегии упрощения, стратегии очищения и стратегии упорядочения.[2]
Стратегии упрощения
Иногда множество предложений удается упростить, исключив из него некоторые предложения или исключив из предложений определенные литералы. Эти упрощения таковы, что упрощенное множество предложений выполнимо тогда и только тогда, когда выполнимо исходное множество предложений. Таким образом, применение стратегий упрощения позволяет снизить скорость роста новых предложений.
Исключение тавтологий.
Любое предложение, содержащее литерал и его дополнение (такое предложение называется тавтологией), можно отбросить, так как любое невыполнимое множество, содержащее тавтологию, остается невыполнимым и после ее удаления.
Исключение путем означивания предикатов.
Иногда появляется возможность означить (выяснить значение истинности) литералы, и это оказывается удобнее, чем включать соответствующие предложения в S. Такое означивание легко провести для константных частных случаев. Например, если предикатная буква E обозначает отношение равенства, то означивание константных частных случаев типа E(7,3), когда они появляются, провести легко, хотя нам бы не хотелось добавлять к S полную таблицу, содержащих много константных частных случаев литералов E(x,y) и ~E(x,y).
Если какой-нибудь литерал предложения получает значение истинности T, то все предложения можно отбросить, не нарушая при этом свойства невыполнимости оставшегося множества. Если же какой-нибудь литерал при означивании получает значение истинности F, то из этого предложения можно исключить данное вхождение литерала.[2]
Исключение подслучаев.
Предложение  называется подслучаем предложения
называется подслучаем предложения 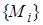 , если существует такая подстановка
, если существует такая подстановка  , что
, что 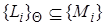 . Например,
. Например,
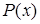 - подслучай предложения
- подслучай предложения 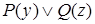 ,
,
- подслучай предложения 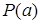 ,
,
- подслучай предложения 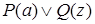
 - подслучай предложения
- подслучай предложения 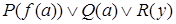 .
.
Предложение в S, являющиеся подслучаем другого предложения в S, можно исключить из S, не нарушая свойства невыполнимости оставшегося множества. Отбрасывание предложений, являющихся подслучаями других, часто ведет к значительному уменьшению числа резольвенций, необходимых для нахождения доказательства.[2]
Стратегии очищения
Стратегии очищения основаны на тех теоретических результатах в теории доказательства с помощью резольвенций, в которых утверждается, что для нахождения опровержения не нужны все резольвенции. Иными словами, достаточно выполнить резольвенции только для предложений, удовлетворяющих определенным требованиям. Обозначим через 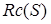 объединение множества S и множества всех резольвент всех пар предложений из S , удовлетворяющих критерию C. Ясно, что
объединение множества S и множества всех резольвент всех пар предложений из S , удовлетворяющих критерию C. Ясно, что 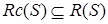 .
.
Про стратегию очищения, использующую критерий C, говорят, что в ней используется "резольвенция по отношению к C". Для применения такой стратегии сначала вычисляется , затем  и т.д. до тех пор, пока при некотором n в
и т.д. до тех пор, пока при некотором n в  не окажется пустого предложения обозначемого nil.
не окажется пустого предложения обозначемого nil.
Потенциальное достоинство стратегии очищения, в том, что на каждом уровне требуется меньше резольвенций. Однако уровень, на котором появляется пустое предложение, обычно возрастает, так что стратегия очищения приводит обычно к узконаправленному, но более глубокому перебору. Стратегия очищения полезна лишь в том случае, если она уменьшает все затраты усилий на перебор, включая усилия, необходимые для проверки критерия C.[2]
Предшествующих вершин
Доказательство с отфильтровыванием предшествующих вершин производится с использованием AF-графа. Граф опровержения имеет AF-форму, если каждая из его вершин соответствует одному из следующих предложений:
1. базовому предложению;
2. предложению, непосредственно следующему за базовым;
3. предложению, непосредственно следующему за двумя небазовыми предложениями A и B, из которых B предшествует A (отсюда термин отфильтровывание предшествующих вершин).
Граф в виде лозы представляет собой частный случай графа в AF-форме: каждая из его вершин соответствует либо предложению 1, либо предложению 2. Но граф типа лозы существует не для всех неудовлетворимых множеств. Ниже приведен пример такого графа.[2]
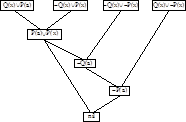
Рис 1.1. Вид графа в AF-форме.
Стратегии упорядочения
На основе резольвенций, обеспечиваемых различными стратегиями очищения, иногда можно искать опровержение, упорядочив выполняемые резольвенции. В стратегиях упорядочения не запрещаются никакие типы резольвенций, а лишь даются указания на то, какие из них надо выполнять в первую очередь. Стратегии упорядочения соответствуют эвристическим стратегиям перебора для поиска на графах. При хорошем упорядочении не обязательно вычислять все элементы множеств R(S), R2(S) и т.д. Если пустое предложение появляется впервые на уровне n, что хочется думать, можно прямо направить на этот уровень, не заполняя нижние уровни.
Две довольно эффективные стратегии упорядочения – это стратегия предпочтения одночленам и стратегия наименьшего числа компонент. В стратегии предпочтения одночленам делается попытка сначала построить резольвенты между одночленами, т.е. предложениями, содержащими один литерал. Если это удается, то сразу же получается опровержение. Если же не могут найти пару одночленов, у которых есть резольвента, то пытаются найти резольвенту для пар одночлен-двучлен и т.д. Как только какая-нибудь пара предложений разрешается, полученную резольвенту сразу сопоставляют с одночленами с тем, чтобы найти возможные резольвенты. Во избежание совершения невыгодной цепочки одночленных резольвенций обычно устанавливается граничный уровень.
Стратегия предпочтения одночленам оправдана гарантированным укорочением длины предложений, вызываемым одночленными резольвентами. Так как цель построения резольвент состоит в образовании пустого предложения, то стратегия предпочтения одночленам напрашивается сама собой. При введении граничных уровней для возможности использования и других резольвенций такая стратегия не препятствует нахождению опровержения и, как правило, сильно ускоряет процесс перебора.
Стратегия наименьшего числа компонент упорядочивает резольвенции согласно длине получаемых резольвент. Так, два предложения, дающие наиболее короткую резольвенту, разрешаются в первую очередь. Эта стратегия в некотором смысле дороже, поскольку до выполнения резольвенции надо подсчитать длины потенциальных резольвент и упорядочить их.[2]
Конструкторская часть
Синтаксический анализатор
На начальном этапе массив лексем разбивается на несколько подмассивов по одному для каждого предиката. При разбиении массива проверяется следующее правило: каждое предложение начинается с имени предиката и заканчивается точкой. Таким образом, выделяются лексемы соответствующие каждому предикату.
Затем работа продолжается с каждым из подмассивов отдельно. Пользуясь вышеописанным правилом, выделяется отдельное предложение и отправляется на синтаксический анализ.
Предложение в Прологе имеет следующий формат:
ИмяПредиката (Параметр1, Параметр2, …) if
Условие1(Параметр11, Параметр12, …),
Условие2(Пераметр21, Параметр22, …),
УсловиеN(ПараметрN1, ПараметрN2, …).
При синтаксическом анализе, во-первых, проверяется заголовок предложения. Проверяется имя предиката и параметры (их количество и тип) и наличие слова “if”. Если в качестве параметра стоит переменная, то считается, что переменная может быть любого типа, а константы подвергаются жесткому контролю.
Из массива лексем предложения выделяются отдельные условия. В этом случае должны быть выполнены следующие требования:
· Все условия разделены запятыми друг от друга;
· Цепочка условий заканчивается точкой;
· Внутри условия все скобки (круглые и квадратные) должны быть закрыты.
Проверка условий делится на три части в зависимости от типа первой лексемы:
· Вызов предиката, если первая лексема - имя предиката;
· Вызов базы данных, если первая лексема - имя базы данных;
· Вычисление арифметического выражения - во всех остальных случаях.
При синтаксическом анализе вызовов предикатов и баз данных выполняется разбор параметров примерно такой же, как при анализе заголовка предложения.
При анализе арифметического выражения строится дерево, соответствующее выражению.
Проверка типов параметров
На вход поступает объект с параметром и имя типа, с которым сравнивается параметр. На выходе мы должны выдать логическое значение, говорящее может ли параметр хотя бы теоретически относиться к сравниваемому типу.
Если параметром является переменная, то считается, что она может быть любого типа. Числовые, строковые и логические константы могут быть опознаны сразу.
Сложнее дело обстоит со структурами и списками, а также анализом составных типов.
При анализе составного типа необходимо выяснить, относится ли параметр к одному из типов составного типа. Если да, значит необходимо возвратить истину.
Рассматривая структуру, мы должны проверить тип каждого из элементов, составляющих структуру. Если все элементы имеют правильные типы, то возвратить истину.
Список может быть записан двумя способами:
1. [Элемент1, Элемент2, … , ЭлементN]
2. [Голова|Хвост]
В первом случае мы должны проверить тип каждого из элементов.
При рассмотрении второго случая необходимо учитывать то, что Голова имеет тип элемента списка, а Хвост – тип списка.
Работа интерпретатора
Функция работы интерпретатора представляет собой рекурсивную функцию, выполняющую алгоритм бэктрекинга.
Алгоритм бэктрекинга заключается в следующем. Для первого оператора Пролог-программы интерпретатор находит решение, удовлетворяющее этому оператору. Если решение было найдено, то переходим к следующему оператору. На втором операторе, с учетом результатов на предыдущем шаге, программа пытается решение для второго оператора. Если решение было найдено, то программа идет дальше. В противном случае, программа должна вернуться на шаг назад и подобрать другое решение для первого условия, а затем опять попытаться выполнить второе условие. Такой процесс идет до тех пор, пока не будет выполнено последнее условие, и предложение будет объявлено истинным. Или, если программа не сможет больше подобрать решения для первого условия, то все предложение будет объявлено ложным.
Принцип действия интерпретатора основан на рекурсивном вызове функции TPrologProgram.ExecutePredicate, которая выполняет предикат. На вход функции поступает объект TStackNode, в котором содержатся входные параметры, а также номер предложения, с которого необходимо начинать выполнять предикат. Функция ExecutePredicate возвращает логическое значение, указывающее на то, было ли найдено решение для предиката или нет. Входные и выходные параметры предиката хранятся в поле InputParameters.
Последовательность действий, которые выполняет функция ExecutePredicate, выглядит следующим образом:
1. В каждое предложение программа пытается подставить входные параметры. Если подстановка прошла успешно (это определяется функцией FindNamedAreas), то интерпретатор пытается выполнить это предложение. В противном случае просмотр продолжается.
2. Необходимо найти решение для каждого из условий предложения. Интерпретатор проходит по каждому из условий предложения последовательно.
3. Перед выполнением условия проверяется, запускается на оно на прямом пути или на обратном. Если на прямом пути, то в дополнительный стек заносится еще один элемент TSubStackNode, в котором содержатся следующие данные: само условие, список имен созданных на данном шаге переменных и список имен переменных свободных до текущего шага. Если условие запускается на обратном пути, то объект TSubStackNode не создается, так как был создан ранее.
4. Если текущее условие предикат или база данных, то для них необходимо создать новый объект TStackNode и сформировать пакет входных параметров. Затем, если текущее условие база данных, то вызывается функция обработки баз данных ExecuteExtDataPredicate, если условие стандартный предикат, то - ExecuteStandardPredicate, и, если это предикат пользователя то рекурсивно вызывается ExecutePredicate.
Если текущее условие - выражение, то выполняется функция ExecuteArithmeticTerm.
5. Если после своего выполнения условие вернуло значение False, то запускается механизм обратного прохода. Уничтожается последний элемент TSubStackNode, и программа возвращается к предыдущему условию и пытается найти новое решение для него.
6. Если все условия были выполнены, то формируются выходные параметры и функция возвращает истину. В противном случае, программа возвращается к пункту 1 и пытается найти еще одно предложение, соответствующее входным данным.
7. Если были исчерпаны все предложения и ни для одно не было найдено решения, то необходимо возвратить False.
WHERE
<поле1>=<значение1> and
<поле2>=<значение2> and
…
<полеN>=<значениеN>
В запросе используются только условия-равенства, так как в Прологе при сопоставлении значении на входе в предикат используется только сравнение.
В список условий помещаются только те поля, значения которых на входе определены.
При первом обращении к базе берется первая запись из запроса.
При последующих вызовах базы данных (в случае обратного пути в бэктрекинге) объект SQL-запроса не создается, а используется ранее созданный, и применяется функция Next для доступа к следующей записи.
Таким образом, доступ к базе данных осуществляется как обычным предикатам, которые состоят только из предложений-фактов.
Основные модули
Модуль CompileUnit. В данном модуле определяется класс пролог-программы - TPrologProgram, а также два класса, использующихся при запуске интерпретатора: TStackNode и TSubStackNode. Модуль CompileUnit является ядром интерпретатора.
Модуль ProgramClasses. В данном модуле описываются основные классы, использующиеся в объектах TPrologProgram, TStackNode и TSubStackNode как контейнерные:
– TLexemRecord - представляет одну лексему, выделенную из текста программы;
– TPrologVariable - представляет переменную во время выполнения пролог-программы.
– TPrologVariableList - контейнерный класс, использующийся в TPrologVariable, для представления списков;
– TPrologVariableStruct - контейнерный класс, использующийся в классе TPrologVariable, для представления структур;
– TPrologVariables - класс, представляющий собой список переменных TPrologVariable с возможностью доступа к переменной по имени;
– TSubTermPredicate - класс использующийся в TPrologTerm для представления обычного предикатного условия в предложении;
– TSubTermExtData - класс использующийся в TPrologTerm для представления предикатного условия вызова базы данных в предложении;
– TSubTermExpression - класс использующийся в TPrologTerm для представления арифметических выражений в предложении;
– TPrologTerm - класс использует TSubTermPredicate, TSubTermExtData, TSubTermExpression как контейнерные для представления одного условия в предложении;
– TPredicateClause - использует массив объекстов TPrologTerm и TPrologVariable для представления одного предложения в программе;
– TProgramDomain - класс использующийся в TPrologProgram как контейнерный для описания типов;
– TProgramExtData - класс использующийся в TPrologProgram как контейнерный для описания баз данных;
– TProgramPredicate - класс использующийся в TPrologProgram как контейнерный для описания предикатов;
– TPrologFile - класс использующийся в TPrologProgram как контейнерный для описания файлов открытых во время выполнения программы;
Модуль PrologRunTime описывает класс ошибок TRunTimeError, а также все функции и встроенные предикаты Пролога.
MainFormUnit - модуль описания главной формы TMainForm;
ProgFormUnit - модуль описания окна инспектора TProgForm;
DomConstrFormUnit - модуль описания конструктора типов TExtDataForm;
ExtDataFormUnit - модуль описания конструктора баз данных TExtDataForm;
PredicateConstrFormUnit - модуль описания конструктора предикатов TPredicateConstrForm;
EditorFormUnit - модуль описания окна редактора TEditorForm
ConsoleUnit - модуль описания окна консоли TConsole;
ErrorsFormUnit - модуль описания окна ошибок компиляции TErrorsForm;
StackFormUnit - модуль описания окна стека программы TStackForm;
RunTimeDebugFormUnit - модуль описания окна отладки программы TRunTimeDebugForm;
BreakPointsFormUnit - модуль описания окна контрольных точек TBreakPointsForm;
ProjectOptionsFormUnit - модуль описания окна опций проекта.
Технологическая часть
Требования по эксплуатации интерпретатора языка Пролог
Программа интерпретатора языка Пролог предназначена для эксплуатации на персональных вычислительных машинах на базе процессоров семейства Pentium и выше в минимальной конфигурации с 16 Мб оперативной памяти. Для установки программы необходимо:
· в минимальной конфигурации - 1.5 Мб дискового пространства;
· в полной конфигурации (с установкой Borland Database Engine) - 10 Мб дискового пространства.
В качестве операционной системы может использоваться Microsoft Windows 95, Windows 98, Windows NT.
Установка системы
Система поставляется на четырех дискетах размером 3.5" и объемом 1.44 Мб.
Установка программы производится с дискет, путем запуска из операционной системы Windows файла "Setup.exe", находящегося на первой дискете. Далее необходимо действовать согласно указаниям.
При установке программы необходимо указать директорию, в которую будет производиться инсталляция.
В процессе установки программа спросит, устанавливать ли Borland Database Engine на машину или нет. Если BDE уже установлена на компьютер ранее, то повторная установка не требуется.
По завершении процесса установки программа-инталлятор создаст в системном меню раздел с названием "Prolog", а внутри него ярлык на файл "Prolog.exe" с названием "Prolog with databases", ярлык на help-файл и на файл "readme.txt".
Пролог
Запуск программы
Запуск программы можно произвести несколькими способами.
Нажать кнопку "Пуск", выбрать в меню пункт "Программы", выбрать пункт "Prolog". После того, как раскроется подменю, нажать на строку "Prolog with databases".
Дважды щелкнуть по иконке Пролога на рабочем столе
Воспользоваться "проводником" или другим менеджером файлов.
Работа с меню
Для удобства пользователя при выборе команд в программу введена система меню, которая содержит следующие пункты:
– Файл
– Окна
– Проект
– Настройка
– Помощь
Меню Файл содержит следующие пункты.
Создать - позволяет создать новую программу на Прологе.
Открыть - позволяет открыть имеющийся файл и выводит стандартное окно Windows для открытия файла:
Рис.3.9. Вид окна для открытия файла.
При открытии файла в инспектор загружается информация о типах, базах данных и предикатах, а в редактор - текст программы. Если формат файла был нарушен, то он не будет загружен.
Вспомнить - за этим пунктом скрывается подменю, состоящее из имен последних восьми файлов, которые открывались Пролог-системой. Нажав на название нужного файла в этом подменю можно быстро загрузить его.
Сохранить - позволяет сохранить файл на диск. Если файл создавался с помощью пункта меню Создать, то выводится диалоговое окно, позволяющее присвоить имя сохраняемому файлу.
Сохранить как - позволяет присвоить новое имя файлу. При выборе этого пункта меню будет выведено на экран диалоговое окно для ввода имени файла.
Печать - формирует печатную форму из данных, содержащихся в инспекторе, окне редактора и окне опций проекта. После окончания процесса формирования печатной формы на экране появится окно, в котором можно будет просмотреть вид печатной формы. В этом окне можно выделить область текста и скопировать в буфер обмена. При нажатии в окне печати на кнопку "Печать" будет начат вывод на принтер. Общий вид печатной формы можно представить следующим образом:
<Имя печатаемого файла>
DOMAINS
<Объявления типов>
ALIAS
<Имя алиаса в Borland Database Engine, которое использует данная программа>
DATABASES
<Описание структур баз данных>
PREDICATES
<Описание параметров предикатов>
GOAL
<Имя запускаемого предиката>
CLAUSES
<Текст программы>
Выход - позволяет завершить работу программы интерпретатора Пролог.
Меню Окна позволяет открыть следующие окна:
Инспектор;
Консоль;
Редактор;
Контрольные точки;
Стек;
Трассировка.
Меню Проект содержит следующие пункты:
Опции - выводит на экран диалоговое окна с опциями проекта, в котором можно указать имя алиаса, которым будет пользоваться программа написанная на Прологе, а также имя запускаемого предиката.
Запуск - позволяет запустить Пролог-программу на исполнение.
Меню Настройка содержит пункт Параметры редактора. При выборе этого пункта появляется диалоговое окно, в котором можно выбрать тип и размер шрифта для окна редактора.
Меню Помощь содержит следующие пункты:
Предметный указатель - загружает help-файл и показывает главную страницу.
О программе - выводит окно с информацией о программе.
Языке Пролог
Выполнение программы, написанной на языке Пролог, ведется с использованием алгоритма бэктрекинга.
Предложение просматривает все свои условия последовательно и пытается найти решение для каждого из них. Найдя решение для первого условия, интерпретатор переходит к поиску решения для второго условия с учетом значений переменных, которые были изменены первыми условием. Если решение было найдено, то программа переходит к следующему условию. В противном случае интерпретатор должен вернуться к предыдущему условию и попытаться найти для него другое решение отличное от ранее найденного, а затем опять попытаться выполнить второе условие. Перед началом обратного пути уничтожаются все переменные, которые были созданы перед этим шагом и очищаются те переменные, которые были свободны. Такой процесс происходит до тех пор, пока не будет найдено общее решение верное для всех условий предложения. В этом случае предложение объявляется истинным и выполнение его прекращается. Если такого общего решения найдено не было, то предложение объявляется ложным.
Арифметические выражения и стандартные предикаты процесс бэктрекинга игнорируют и выполняются, так как выполняются однозначно.
Предикаты ввода с консоли.
ReadString(<свободная переменная>) - читает с консоли строку. В качестве параметра обязательно должна передаваться свободная переменная. В противном случае будет выдано сообщение об ошибке и программа закончит свою работу.
ReadInteger(<свободная переменная>) - читает с консоли целое число.
ReadReal(<свободная переменная>) - читает с консоли реальное число.
Предикаты работы с файлами.
Данная версия Пролога работает только с текстовыми файлами.
Для идентификации файла при работе программы используется целочисленный номер обработчика файла, по которому можно обращаться к файлу.
FileOpenRead(<имя файла>:String, <номер обработчика>:Integer) - открыть файл для чтения. Предикат возвращает во втором параметре номер обработчика файла. Во втором параметре предиката должна стоять свободная переменная.
FileOpenWrite(<имя файла>:String, <номер обработчика>:Integer) - открыть файл для записи. Предикат возвращает во втором параметре номер обработчика файла. Во втором параметре предиката должна стоять свободная переменная.
FileRead(<номер обработчика>:Integer,<значение>) - чтение из файла. Второй параметр должен быть свободной переменной, иначе интерпретатор выдаст ошибку "Неверные параметры при вызове предиката".
FileWrite(<номер обработчика>:Integer,<значение>:String) - запись в файл.
FileClose(<номер обработчика>:Integer) - закрытие файла. Данный предикат применять не обязательно, так как при завершении программы интерпретатор сам закрывает все открытые файлы.
EOF(<номер обработчика>:Integer) - проверка конца файла. Предикат истинен, если конец файла достигнут.
Разное.
StringToList (String, <список>) - превращает строку в список, состоящий из символов этой строки, и возвращает его через параметр <список>.
Fail - предикат всегда возвращает ложь.
Описание функций
Арифметические функции.
Sin (<Integer, Real>):Real - операция синуса. Аргументом может быть как реальное, так и целое число. Функция возращает реальное число.
Cos (<Integer, Real>) :Real - операция косинуса.
Tan (<Integer, Real>) :Real - операция тангенса.
Exp (<Integer, Real>) :Real - экспонента.
Ln (<Integer, Real>) :Real - натуральный логарифм.
Int (<Integer, Real>) :Integer - выделение целой части числа. Функция используется также для явного преобразования реального числа в целое.
Frac (<Integer, Real>) :Real - выделение дробной части числа.
Abs(<Integer, Real>):<Integer, Real> - взятие модуля числа.
Функции работы со строками.
SubStr(String, N1:Integer, N2:Integer):String - выделение подстроки, начиная с элемента с индексом N1 длиной N2 символов.
FindStr(S1:String, S2:String):Integer - находит позицию подстроки S2 в строке S1 и возвращает индекс первого символа подстроки в строке S1. Если в строке S1 не было найдено подстроки S2, то функция возвращает 0.
Chr(Integer):String - возвращает символ, соответствующий числу по таблице ASCII.
Asc(String):Integer - возвращает ASCII-код первого символа строки.
NumbToStr(<Integer или Real>):String - превращает число в строку
StrToNumb(String):<Integer или Real> - превращает строку в целое или реальное число, в зависимости от содержания строки. Интерпретатор сначала пытается преобразовать строку в целое число. Если не получается, то пытается превратить строку в реальное число. Если преобразование не удалось, то выводится сообщение об ошибке.
Логические функции.
Not(Boolean):Boolean - инвертирует значение логического выражения. (ВНИМАНИЕ: чтобы инвертировать значение, возвращаемое предикатом или базой данных необходимо перед именем предиката или базы данных поставить символ "~")
Введение
Охрана труда – система законодательных актов и норм, направленных на обеспечение безопасности труда, и соответствующих им социально-экономических, технических, организационных и санитарно-гигиенических мероприятий.
Полностью безопасных и безвредных производств не бывает. Задача охраны труда – свести к минимуму вероятность поражения или заболевания работающего с одновременным обеспечением комфорта для плодотворного труда.
Современное промышленное производство связано с использованием сложных технологических процессов и разнообразного оборудования, являющих источниками физических, химических и других факторов, оказывающих прямое или косвенное влияние на безопасность, здоровье и работоспособность человека.
Конструктивное несовершенство технических устройств и неправильная организация труда может приводить к действию на человека неблагоприятных психофизических факторов.
Нормализация и оптимизация производственной среды и предупреждение вредных выбросов в окружающую среду является необходимым условием жизнедеятельности человека. Улучшение условий труда, повышение его безопасности и безвредности имеет большее экономическое значение. Оно влияет на производительность труда, качество и себестоимость продукции.
В разделе «Промышленная экология и безопасность» выявляются наиболее существенные факторы, и производится выбор, обоснование и расчеты средств защиты и систем нормализации труда и предотвращения вредных выбросов в окружающую среду.
Источники загрязнения
В общем случае вычислительная техника представляет собой некоторую конструкцию, то есть совокупность деталей, находящихся в определенных пространственных, механических, электрических, магнитных и энергетических взаимосвязях. Поэтому в процессе производства вычислительной техники используется целый комплекс технологических приемов, связанных с переработкой различных по своей природе исходных материалов, последующей обработкой и сборкой деталей для получения функционально завершенного изделия.
В технологиях производства ЭВМ используются процессы, отрицательно воздействующие на окружающую среду, такие как литье, термическая, гальваническая и механическая обработка, резка, пайка, сварка и окраска. Источники, объекты первичного отрицательного воздействия и применяемые способы защиты среды обобщены в таблице 5.4.
Литейное производство связано с загрязнением атмосферы пылью, окисью углерода, сернистым ангидридом, а сточных вод механическими взвесями, в виде пыли, флюсов, окалины.
При термической обработке в атмосферу через систему вентиляции могут выбрасываться пары масла, окиси углерода, аммиака, цианистого водорода, а также пыли. Электротермическое оборудование потребляет воду для охлаждения, и в сточных водах могут находиться вредные вещества.
Гальванические работы сопряжены с использованием больших объемов воды для приготовления растворов электролитов и промывных операций. Поэтому сточные воды в этих случаях значительно загрязнены ядовитыми химическими веществами. Кроме того, воздух, удаляемый от технологического гальванического оборудования, содержит большое количество вредных веществ в различных агрегатных состояниях:
– капельножидким (брызги),
– тонкодисперсионном аэрозоле,
– паро- и газообразном.
При механической обработке материалов для охлаждения оборудования и инструмента, промывки деталей, санитарно-гигенической обработки помещений широко используется вода. сточные воды в этих случаях могут быть загрязнены минеральными маслами, мылами, металлической и абразивной пылью, эмульгаторами. Кроме того, при механической обработке металлов в атмосферу через систему вентиляции могут выбрасываться пыль, стружка, туманы масел и эмульсий, а при обработке неметаллических материалов – вредные пары связующих смол и пыль.
Таблица 5.1.
| Технологический процесс | Объект отрицательного воздействия | Источник загрязнения | Способ защиты |
| Литье | Атмосфера | Пыле- газовыделение | Пылеулавливание, фильтрация |
| Гидросфера | Сточные воды | Фильтрование, отстаивание, реагентная обработка | |
| Термическая обработка | Атмосфера | Пыле- газовыделение | Пылеулавливание, фильтрация |
| Гидросфера | Сточные воды | Фильтрование, отстаивание, реагентная обработка | |
| Гальваническая обработка | Атмосфера | Выделение вредных веществ в различном агрегатном состоянии | Очистка |
| Гидросфера | Сточные воды | То же | |
| Механическая обработка | Атмосфера | Пыле- газовыделение | Пылеулавливание, фильтрация |
| Гидросфера | Сточные воды | То же | |
| Резка, сварка, пайка | Атмосфера | Пыле- газовыделение | Пылеулавливание, фильтрация |
| Гидросфера | Сточные воды | То же | |
| Лакокрасочные работы | Атмосфера | Газовыделение, лакокрасочные туманы | Фильтрация |
| Гидросфера | Сточные воды | То же | |
| Сборка | Гидросфера | Сточные воды | То же |
Газовая и плазменная резка металлов, технологические процессы сварки и пайки сопровождаются выделением пыли и токсичных газов, а сточные воды могут загрязняться механическими примесями, кислотами.
Лакокрасочные работы связаны с выделением в атмосферу вредных веществ в вид паромов растворителей и лакокрасочных аэрозолей в процессе нанесения покрытия и при высыхании изделий. При уборке такого рода помещений сточные воды могут загрязняться примесями растворителей лаков и красок.
Процесс получения функционально завершенного изделия заканчивается сборочными операциями. Отрицательное воздействие на окружающую среду процессов сборки менее ощутимо. Однако и в этих случаях при проведении санитарно-гигенической обработки производственных помещений в сточные воды могут попадать различные нежелательные примеси.
Пожарная опасность
Пожары в ВЦ представляют особую опасность, так как сопряжены с огромными материальными потерями.
В качестве горючего компонента на ВЦ могут служить строительные материалы для акустической и эстетической отделки помещений, перегородки, окна, двери, полы, мебель, стеллажи, магнитные ленты и диски, изоляция силовых кабелей, а также радиотехнические детали и соединительные провода электронной схемы.
Окислитель в виде кислорода воздуха имеется в любой точке помещения ВЦ.
Источниками воспламенения на ВЦ могут быть электрические искры, дуги и перегретые участки. Источники воспламенения возникают в электронных схемах, кабельных линиях, вспомогательных электрических и электронных приборах, а также в устройствах, применяемых для технического обслуживания элементов ЭВМ.
Таким образом, на ВЦ могут присутствовать все три основные фактора, способствующих возникновению пожара.
Кабельные линии электропитания состоят из горючего изоляционного материала, а также содержат вероятные источники открытого огня. Они являются –наиболее опасным элементом в конструкции ЭВМ и вычислительного центра с точки зрения возникновения и развития пожара.
Другим местом, где может возникнуть пожар, является хранилище информации. Ущерб от пожара определяется не только стоимостью сгоревших магнитных лент и дисков, но и потерей информации, записанной на ней.
Для обеспечения своевременных мер по обнаружению и локализации пожара, эвакуации рабочего персонала, а также для уменьшения материальных потерь необходимо выполнять следующие условия:
– наличие системы автоматической пожарной сигнализации;
– наличие эвакуационных путей и выходов;
– наличие первичных средств тушения пожаров: пожарные стволы, внутренние пожарные водопроводы, сухой песок, огнетушители.
Следует обратить особое внимание на то, что применение воды в машинных залах ЭВМ, ввиду опасности повреждения дорогостоящего электронного оборудования возможно только в исключительных случаях, когда пожар угрожает принять крупные размеры.
Повышенная яркость света
Свет является важным стимулятором не только зрительного анализатора, но и организма в целом, а также общей работоспособности человека. Положительное влияние его на производительность труда и качество работы в настоящее время не вызывает сомнений.
Обеспечение гигиенически рациональных условий освещения способствует длительному сохранению работоспособности, что приводит к росту производительности труда и к снижению ошибок в процессе труда.
Поскольку при работе с программным комплексом главным источником визуального отображения информации является монитор, который представляет собой самосветящийся прибор, то общая освещенность может вызвать перегрузку зрительных органов, что приводит к повышенному утомлению зрения в процессе выполнения работ и повышает опасность травматизма зрительных органов.
Освещенность рабочей зоны должна соответствовать нормам СНиП 11-4-79 «Искусственное освещение для зрительной работы малой степени точности (разряд V) и работа с самосветящимися материалами (разряд VII).
Яркость в поле зрения работающего должна быть распределена равномерно. Поскольку в поле зрения работающего постоянно находятся поверхности, значительно отличающие по яркости (например: экран монитора – текстовый документ и т.д.) то при переводе взгляда в яркоосвещенной на слабоосвещенную поверхность глаз должен переадаптироваться. Частая переадаптация ведет развитию утомления зрения. Степень неравномерности определяется коэффициентом неравномерности, который согласно требованиям СНиП 11-4-79 для данного вида работ должен быть не менее 0.3 в пределах рабочей области.
С программным средством
Защита зрения оператора является основной функцией экрана. Зрение больше всего страдает от –повышенной яркости экрана электронно-лучевого монитора и недостаточного контраста изображения. Защитный экран уменьшает общую яркость изображения, вместе с тем темные участки изображения остаются хорошо различимыми, поскольку сильно увеличивается общий контраст и устраняются блики.
Экраны выполняют следующие защитные функции:
Воздействий
Основным источником вредного воздействия на организм человека являются электромагнитные колебания низкой частоты, связанные с работой схем развертки электронного луча. Они воздействуют на обмен веществ в организме и могут приводить к патологическим изменениям в клетках мягких тканей.
Другим источником вредного воздействия является электростатический заряд, скапливающийся на лицевой поверхности монитора. Вызываемая им деионизация атмосферы вокруг оператора угнетающе действует на нервную систему, способствуя развитию депрессии у оператора.
Заключение
В результате проектирования был разработан интерпретатор языка Пролог с возможностью работы с универсальными базами данных.
Для удобства работы с программы была создана интегрированная среда разработчика, имеющая средства для визуального ввода программы, систему меню, экранных форм и оперативной подсказки, правила работы с которыми изложены в руководстве пользователя.
Был проведен расчет затрат на разработку программы интерпретатора и интегрированной среды разработчика.
Рассмотрены вопросы, связанные с промышленной экологией и безопасностью при работе с программой интерпретатора.
Предлагаемая программа интерпретатора языка Пролог создана в соответствии с требованиями технического задания.
Литература
1. Дж. Малпас Реляционный язык Пролог и его применение - М.:Наука,1990
2. Логический подход к искусственному интеллекту под ред. Г.П.Гаврилова - М.:Мир,1990
3. Д. Марселлус Программирование экспертных систем на Турбо Прологе - М.:Финансы и статистика, 1994
4. У. Клоксин, К.Меллиш Программирование на языке Пролог - М.:Мир, 1987
5. Язык Пролог в пятом поколении ЭВМ под ред. Н.И. Ильинского - М.:Мир, 1988
6. Дж. Доорс, А.Р.Рейблейн, С.Вандера Пролог-язык программирования будущего - М.:Финансы и статистика, 1990
7. И. Братко Программирование на языке Пролог для искусственного интеллекта - М.:Мир, 1990
8. Ахо А. Теория синтаксического анализа, перевода и компиляции - М.:Мир, 1979
Приложения
Приложение 1
Интерфейсная часть модуля интерпретатора
unit CompileUnit;
interface
uses Windows,Classes, SysUtils, ProgFormUnit, ProgramClasses, SyncObjs,
Forms, dbTables, ProjectOptionsFormUnit;
{DEFINE PRED_COMPILER_DEBUG}
const
StandardLexemsCount=16;
type
TSubStackNodeType=(ssntPredicate, ssntStdPredicate,
ssntArithmetic, ssntExtData);
TProgramSubStackNode=class(TObject)
ClauseIndex :integer; //индекс предложения, на котором
//была достигнута истина
CreatedVariables :TStrings; //созданные на этом шаге переменные
FreeBefore :TStrings; //Переменные, которые перед этим шагом были свободны
TempVariables :TPrologVariables;
//Arithmetic :Boolean; //True-если арифметический терм
iType :TSubStackNodeType; //Тип элемента
Term :TPrologTerm; //Терм в программе, которому
//соответсвует данный элемент
Belong :TObject; //объект TProgramStackNode,
//которому принадлежит данный объект
ExtDataQuery :TQuery;
TheEndWasReached :Boolean;
//VarPacket :TPrologVariables; //пакет с переменными,
//который отправляется дальше
procedure ClearCreatedVariables;
procedure StepBack;
constructor Create;
destructor Destroy; override;
end;
TTraceMode=(tmNoTrace, tmTrace, tmStep);
//tmNoTrace - нет трассировки
//tmTrace - трассировка
//tmStep - трассировка, не заходя внутрь вызываемых предикатов
TProgramStackNode=class(TObject)
//полностью описывает текущее состояние программы
PredicateName :string; //имя предиката
Predicate :TProgramPredicate;
InputParameters :TPrologVariables;
Variables :TPrologVariables; //переменные
SubStack :array of TProgramSubStackNode;//integer; //массив, в котором хранятся индексы,
//на которых было достигнуто истинное значение терма
CreatedVariables :array of array of string; //Массив,
//в котором хранятся имена созданных на i-м шаге переменных
TermNumb :integer; //Номер терма, на котором стоит программа
ClauseNumb :integer; //Номер предложения в предикате
ClausesCount :integer;
TraceMode :TTraceMode;
OnBreakPoint :Boolean; //True-если в данный момент стоим на контрольной точке
constructor Create;
destructor Destroy; override;
end;
TPrologProgram=class(TObject)
Domains :array of TProgramDomain;
ExtData :array of TProgramExtData;
Predicates :array of TProgramPredicate;
Stack :array of TProgramStackNode;
BreakPoints :array of Integer;
StartPredicate :string;
OnTheRun :Boolean; //True-если программа запущена
Files :array of TPrologFile;
function CompileProgram:Boolean;
procedure RecieveStructurData;
procedure CutLexemsToPredicates(Lexems:TLexemsArray);
function CheckingBeforeCompile:Boolean;
procedure RunProgram(TraceMode:TTraceMode);
procedure EraseProgramStack;
function AddNodeToStack:TProgramStackNode;
function FindPredicate(PredicateName:string):TProgramPredicate;
function ExecutePredicate(var StackNode:TProgramStackNode):Boolean;
procedure DeleteLastNodeFromStack;
function DebugProcess(StackNode:TProgramStackNode):Boolean;
function PreDebugProcess(StackNode:TProgramStackNode):Boolean;
procedure CreateBreakPointsArray;
function CheckPredicateClausesCount(
Term:TPrologTerm;
SubStackNode:TProgramSubStackNode):Boolean;
constructor Create;
destructor Destroy; override;
function TranslateLexems (ProgPart:TStrings; //var Lexems:TStringList;
var LexemsRecs:TLexemsArray;
Comments:Boolean=False):TPoint;
function AnalizeLexem(st:string):TLexemRecord;
procedure AddLexem(var LexemsRecs:TLexemsArray;
st:string; x,y,APos:integer);
procedure CheckBreakPoints(StackNode:TProgramStackNode);
end;
var
PrologProgram :TPrologProgram;
function TranslateSintax (var Predicate:TProgramPredicate):TPoint;
function AnalizeListElements(LRecs:TLexemsArray;
var DstVar:TPrologVariable):Boolean;
function AnalizeStructElements(LRecs:TLexemsArray;
var DstVar:TPrologVariable):Boolean;
function AnalizeArguments(Predicate:TProgramPredicate;
Lexems:TLexemsArray; var VArr:TVariablesArray;
CheckFlag:Boolean=True):boolean;
function CheckConstantType(
Param:TPrologVariable; Domain:string):boolean;
function CheckPredicateParameters(SubTerm
:TSubTermPredicate):Boolean;
function GetHelpContext (Lexem: TLexemRecord):LongInt;
function TestReservedFunction(st:String):Boolean;
function TestReservedPredicate(st:String):Boolean;
Приложение 2
Интерфейсная часть модуля с дополнительными классами интерпретатора.
unit ProgramClasses;
interface
uses Classes, SysUtils, ProgFormUnit, dbtables, db, ProjectOptionsFormUnit;
type
TLexemErrors=(leString,leComment, leOk);
//leString Не найден конец строки
//leComment не найден конец комментария
//Виды лексем
TLexemType=(ltPredicate, ltDomain, ltExtData,
ltVariable, ltFunction, ltUnknown,
ltPlus,ltMinus,ltMultiply,ltDivide,
ltLeftBracket,ltRightBracket,
ltLeftSquareBracket,ltRightSquareBracket,
ltListDivider,ltComma,ltPoint,
ltPointAndComma,ltEqual,ltIf,ltExclamation,
ltString,ltReal,ltInteger,ltTrue,ltFalse,
ltAnonimous, ltGT, ltLT, ltGE, ltLE,
ltReservedPredicate, ltNil, ltAnd, ltOr, ltNotEqual,
ltComment);
TLexemRecord=record
iType :TLexemType;
//Для LPredicate и LDomain обязателен идентификатор в st
st :string;
x,y :integer; //координаты лексемы
AbsPos :integer; //абсолюная позиция в тексте
NoInverse :Boolean; //Для ltPredicate - признак отсутствия или
//наличия знака инверсии
end;
TLexemsArray=array of TLexemRecord;
TPrologVariablesTypes=(vtString,vtInteger,vtBoolean,
vtReal,vtList,vtStruct,vtUnknown,vtAnonimous);
TPrologVariable=class(TObject)
iType :TPrologVariablesTypes; //Тип переменной
Name :string; //Имя переменной
Data :Pointer; //Объект с хранимой информацией
procedure CreateVariable(DomainType:string; vName:string);
procedure DestroyVariable;
constructor Create;
destructor Destroy; override;
procedure ClearVariable;
function CreateCopy:TPrologVariable; //создает точную копию переменной
//Имя переменной переносится и в копию
procedure AssignVariable (v:TPrologVariable); //присваивает значение
//переменной. Имя переменной не меняется
end;
TVariablesArray=array of TPrologVariable;
TPrologListType=(pltStdList,pltHeadTail);
//pltStdList - Элементы списка хранятся в Elements
//pltHeadTail - представлен в виде головы и хвоста(используются только
//два элемента массива elements
TPrologVariableList=class(TObject)
ListName :string; //имя типа списка
ElemName :string; //Имена типа элементов
ListType :TPrologListType; //Тип списка.
Elements :TVariablesArray; //Элементы находятся в Data
DividerPos :integer; //позиция разделителя в случае ListType=pltHeadTail
//указывает, после какого элемента стоит разделитель
procedure ConvertList;
constructor Create;
destructor Destroy; override;
end;
TPrologVariableStruct=class(TObject)
StructName :string; //имя типа структуры
ElemTypes :array of string; //имена типов элементов
Elements :array of TPrologVariable; //Элементы находятся в Data
constructor Create;
destructor Destroy; override;
end;
TPrologVariables=class(TObject)
VarArr :array of TPrologVariable;
constructor Create;
destructor Destroy; override;
function Count:integer;
function High:integer;
procedure AddVariable(v:TPrologVariable);
procedure DeleteVariable(n:integer); overload;
procedure DeleteVariable(vName:string); overload;
procedure DeleteLastVariable;
function AddNewVariable:TPrologVariable;
function VariableByName(vName:string):TPrologVariable;
function GetVariable(ind:integer):TPrologVariable;
procedure SetVariable(ind:integer; v:TPrologVariable);
procedure ClearAndDestroyVariables;
property Variables[ind:integer]:TPrologVariable read GetVariable
write SetVariable; default;
end;
TSubTermPredicate=class(TObject)
Name :string;
StandardPredicate :Boolean; //True - если предикат стандартный
Params :TVariablesArray;
NoInverse :Boolean; //признак отсутствия инверсии
constructor Create;
destructor Destroy; override;
end;
TSubTermExtData=class(TObject)
Name :string;
Params :TVariablesArray;
NoInverse :Boolean; //признак отсутствия инверсии
constructor Create;
destructor Destroy; override;
end;
TExpressionOperation=
(eoPlus, eoMinus, eoMultiply, eoDivide, eoEqual,
eoGT, eoLT, eoGE, eoLE, eoVariable, eoFunction,
eoAnd, eoOR, eoNotEqual);
TSubTermExpression=class(TObject)
Operation :TExpressionOperation;
VarName :String; //имя перменной
FuncName :string; //имя функции
StringStr :string; //строка для строки константы
NumberInt :integer; //число для целой контанты
NumberReal :Extended; //число для реальной контанты
BooleanVal :Boolean; //Число для логической константы
Operand :TPrologVariable;
LeftHand :TSubTermExpression; //Указатель на данные тип
//TSubTermExpression, TPrologVariable
RightHand :TSubTermExpression;
FuncParams :array of TSubTermExpression;
constructor Create;
destructor Destroy; override;
end;
TPrologTermType=(pttExpression,pttPredicate,pttExtData,pttCutting);
TPrologTerm=class(TObject)
TermType :TPrologTermType; //тип терма
Data :pointer; //указатель на объектом с содержимым терма
x,y :integer;
constructor Create;
destructor Destroy; override;
end;
TTermsArray=array of TPrologTerm;
TProgramDomain=class(TObject)
//Внутренний формат доменов
iType :TDomainTypes;
Name :string;
Params :TStrings;
ListParam :string;
constructor Create;
destructor Destroy; override;
end;
TProgramExtData=class(TObject)
Name :string;
Fields :TStrings;
FieldsTypes :TStrings;
FieldsLengths :TStrings;
FileName :string;
Table :TTable;
DataSource :TDataSource;
constructor Create;
destructor Destroy; override;
function Open:Boolean;
procedure Close;
end;
TPredicateClause=class(TObject)
Params :TVariablesArray;
Terms :TTermsArray;
x,y, Endx, EndY :integer;
constructor Create;
destructor Destroy; override;
end;
TProgramPredicate=class(TObject)
Name :string;
Params :TStrings;
Text :TStrings;
Lexems :TLexemsArray;
Clauses :array of TPredicateClause;
constructor Create;
destructor Destroy; override;
end;
TFileOpenMode=(fomRead,fomWrite,fomNotOpened);
TPrologFile=class(TObject)
Name :string;
HandlerNumb :integer;
OpenMode :TFileOpenMode;
FileVar :TextFile;
constructor Create;
destructor Destroy; override;
procedure OpenRead(FileName:string);
procedure OpenWrite(FileName:string);
procedure Close;
function EndOfFile:Boolean;
procedure ReadFile(var st:string);
procedure WriteFile(st:string);
end;
TVariableSize=record
Name :string;
iType :TPrologVariablesTypes;
size :integer;
end;
const
SimplePrologTypesCount=4;
SimplePrologTypes:set of TPrologVariablesTypes=
[vtString, vtInteger, vtBoolean, vtReal];
PrologVariablesSizes:array [0..5] of TVariableSize=
((Name:'STRING'; iType:vtString; Size:SizeOf(string)),
(Name:'INTEGER'; iType:vtInteger; Size:SizeOf(integer)),
(Name:'BOOLEAN'; iType:vtBoolean; Size:SizeOf(Boolean)),
(Name:'REAL'; iType:vtReal; Size:SizeOf(Extended)),
(Name:'LIST'; iType:vtList; Size:SizeOf(TPrologVariableList)),
(Name:'STRUCT'; iType:vtStruct; Size:SizeOf(TPrologVariableStruct)));
Приложение 3
Интерфейсная часть модуля с функциями и предикатами интерпретатора.
unit PrologRunTime;
interface
Uses SysUtils,CompileUnit, ProgramClasses, CommonFunctions;
type
TErrorCode=(ecType, ecNo, ecOverflow, ecDivideZero, ecExpressionValue,
ecArgsCount, ecArgType, ecTan, ecRealAsInteger, ecTypeInExtData,
ecListTail,ecPredicateParams,ecExtDataAbsent, ecExtDataDelete,
ecRangeError,ecConvertError,ecFileOpenError,ecFileCloseError,
ecFileAccessError,
ecCloseProgram,
ecStopPrologProgram);
//ecType - ошибка типа
//ecNo - нет ошибок
//ecOverflow - переполнение
//ecDivideZero - деление на ноль
//ecExpressionValue - выражение возвращает нелогическое значение
//ecArgsCount - неверное количество аргументов у функции
//ecArgType - ошибка типа аргумента функции
//ecTan - ошибка выполнения операции тангенса
//ecRealAsInteger - ошибка конвертирования реального числа в целое
// возникает, когда функции требуется целое число, а у предлагаемого
// аргумента функции есть ненулевая дробная часть
//ecTypeInExtData - ошибка типа при вызове базы данных
//ecListTail - разделение списка на голову и хвост оказалось неуспешным
//ecCloseProgram - закрытие программы
//ecStopPrologProgram - остановка программы
//ecPredicateParams - неверные параметры предиката
TRunTimeError=class(TObject)
Code :TErrorCode;
PredicateName :string;
x,y :integer;
constructor Create;
procedure SetError(err:TErrorCode);
procedure ShowOnScreen;
end;
TOperatorFunction=function (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
TStdFunction=function (Args:TPrologVariables):TPrologVariable;
TStdPredicate=function (VarPacket:TPrologVariables; BackTracking:Boolean):Boolean;
function VariableToStr(v:TPrologVariable;
PrintName:Boolean=True; PrintCommas:Boolean=True;
SquareBrackets:boolean=True):string;
function EqualOperator (Dst:TPrologVariable;
Src:TPrologVariable):Boolean;
function OperatorEQ (
Oper1:TPrologVariable; Oper2:TPrologVariable;
Variables:TPrologVariables):TPrologVariable;
function OperatorPlus (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
function OperatorMinus (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
function OperatorMultiply (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
function OperatorDivide (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
function OperatorGT (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
function OperatorLT (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
function OperatorGE (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
function OperatorLE (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
function OperatorNotEQ (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
function OperatorAND (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
function OperatorOR (
Oper1:TPrologVariable; Oper2:TPrologVariable):TPrologVariable;
function StdFunctionNot(Args:TPrologVariables):TPrologVariable;
function StdFunctionSin(Args:TPrologVariables):TPrologVariable;
function StdFunctionCos(Args:TPrologVariables):TPrologVariable;
function StdFunctionTan(Args:TPrologVariables):TPrologVariable;
function StdFunctionInt(Args:TPrologVariables):TPrologVariable;
function StdFunctionFrac(Args:TPrologVariables):TPrologVariable;
function StdFunctionSubStr(Args:TPrologVariables):TPrologVariable;
function StdFunctionFindStr(Args:TPrologVariables):TPrologVariable;
function StdFunctionChr(Args:TPrologVariables):TPrologVariable;
function StdFunctionAsc(Args:TPrologVariables):TPrologVariable;
function StdFunctionExp(Args:TPrologVariables):TPrologVariable;
function StdFunctionLn(Args:TPrologVariables):TPrologVariable;
function StdFunctionNumbToStr(Args:TPrologVariables):TPrologVariable;
function StdFunctionStrToNumb(Args:TPrologVariables):TPrologVariable;
function StdFunctionAbs(Args:TPrologVariables):TPrologVariable;
function StdPWrite(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPWriteLn(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPnl(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPIsInteger(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPIsReal(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPIsNumeric(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPIsString(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPIsBoolean(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPIsList(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPIsStruct(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPIsFree(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPReadInt(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPReadString(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPReadReal(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPDBAppendZ(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPDBAppendA(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPDBDelete(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPDBClear(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPFileOpenRead(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPFileOpenWrite(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPFileClose(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPFileRead(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPFileWrite(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPEOF(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPStringToList(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
function StdPFail(VarPacket:TPrologVariables;
BackTracking:Boolean):Boolean;
var
RunTimeError :TRuntimeError;
Приложение 4.
Текст демонтрационной программы.
DOMAINS
ListElement:Complex {}
Integer {}
Real {}
String {}
StringList {}
ParamsList:List of ListElement {Список параметров конфигурации}
StringList:List of String {Список с запросами}
ALIAS
DBDEMOS
DATABASES
Configs:'Configs.DB' {}
Task:String[33] {}
Frequency:Integer[4] {}
Processor:String[17] {}
Memory:Integer[4] {}
VideoMemory:Integer[4] {}
HDD:Integer[4] {}
MonitorSize:Integer[4] {}
Addition1Name:String[17] {}
Addition1Value:String[9] {}
Addition2Name:String[17] {}
Addition2Value:String[9] {}
Addition3Name:String[17] {}
Addition3Value:String[9] {}
Addition4Name:String[17] {}
Addition4Value:String[9] {}
DeviceClass:'DeviceClass.db' {}
TypeName:String[17] {}
SubType:String[33] {}
SubTypeIndex:Real{}
PREDICATES
_ReadParameters {Вспомогательный к ReadParameters}
String {Элемент списка}
StringList {Входной список}
StringList {Выходной список}
AddElementToStringList {Добавляет элемент к списку}
String {Элемент}
StringList {Входной список}
StringList {Выходной список}
AddNewAddition {Добавить в список дополнительных устройств}
StringList {список имен доп. уст-в}
StringList {список типов доп. уст-в}
String {новое имя доп. уст-ва}
String {новый тип доп. уст-ва}
StringList {вых. список имен доп. уст-в}
StringList {вых. список типов доп. уст-в}
ChooseConfig {выбор конфигурации}
StringList {список с запросами}
ParamsList {Входной список с параметрами}
ParamsList {Выходной список с параметрами}
GetListElement {Выдает по номеру элемент списка}
ParamsList {Список, в котором ищется элемент}
Integer {Номер искомого элемента}
Integer {Текущий счетчик}
ListElement {Возвращаемое значение}
Max {Выбирает максимальное значение}
ListElement {Значение 1}
ListElement {Значение 2}
ListElement {возвращаемое значение }
PrintAdditions {Печать дополнительных устройств}
StringList {Имена устройств}
StringList {Типы устройств}
ReadParameters {Читает параметры в список}
StringList {входной список}
StringList {выходной список}
run {Запускаемый предикат}
SelectProcessor {выбор процессора}
String {Процессор 1}
Integer {Частота 1}
String {Процессор 2}
Integer {Частота 2}
String {Выбранный процессор}
Integer {Выбранная частота}
GOAL
run
CLAUSES
ReadParameters(InList, OutList) if
ReadString(St),nl,
_ReadParameters(St, InList, OutList).
_ReadParameters("", InList, InList).
_ReadParameters(St, InList, OutList) if
AddElementToStringList(St, InList, InList2),
ReadParameters(InList2, OutList).
AddElementToStringList(A,T,[A|T]).
GetListElement([H|_],N,N,H).
GetListElement([_|T],N,N1,K) if
N2=N1+1,
GetListElement(T,N,N2,K).
Max (Value1, Value2, Value1) if Value1>=Value2.
Max (Value1, Value2, Value2) if Value1<Value2.
SelectProcessor(OldProc,OldFreq,Proc1,Freq1,Proc1,OldFreq) if
DeviceClass("Processor",OldProc,OldProcNumb),
DeviceClass("Processor",Proc1,Proc1Numb),
OldProcNumb=Proc1Numb,
OldFreq>=Freq1.
SelectProcessor(OldProc,OldFreq1,Proc1,Freq1,Proc1,Freq1) if
DeviceClass("Processor",OldProc,OldProcNumb),
DeviceClass("Processor",Proc1,Proc1Numb),
OldProcNumb=Proc1Numb,
OldFreq<Freq1.
SelectProcessor(OldProc,OldFreq,Proc1,Freq1,OldProc,OldFreq) if
DeviceClass("Processor",OldProc,OldProcNumb),
DeviceClass("Processor",Proc1,Proc1Numb),
OldProcNumb>Proc1Numb.
SelectProcessor(OldProc,OldFreq,Proc1,Freq1,Proc1,Freq1) if
DeviceClass("Processor",OldProc,OldProcNumb),
DeviceClass("Processor",Proc1,Proc1Numb),
OldProcNumb<Proc1Numb.
{CreateParamsList(Freq,Proc,Mem,VMem,HDD,Monitor,Names,Vals,
[Freq,Proc,Mem,VMem,HDD,Monitor,Names,Vals]).}
AddNewAddition(N,V,"","",N,V).
AddNewAddition([],[],An,Av,[An],[Av]).
AddNewAddition([Hn|Tn],[Hv|Tv],Hn,Av,[Hn|Tn],[Hv|Tv]) if
DeviceClass(Hn,Hv,OldNumb),
DeviceClass(Hn,Av,NewNumb),
OldNumb>=NewNumb.
AddNewAddition([Hn|Tn],[Hv|Tv],Hn,Av,[Hn|Tn],[Av|Tv]) if
DeviceClass(Hn,Hv,OldNumb),
DeviceClass(Hn,Av,NewNumb),
OldNumb<NewNumb.
AddNewAddition([Hn|Tn],[Hv|Tv],An,Av,[Hn|NewN],[Hv|NewV]) if
AddNewAddition(Tn,Tv,An,Av,NewN,NewV).
ChooseConfig([],InParams,InParams).
ChooseConfig([H|T], InParams, OutParams) if
Configs(H,Freq1,Proc1,Mem1,VMem1,HDD1,Monitor1,an1,av1,an2,av2,an3,av3,an4,av4),
GetListElement(InParams,6,0,OldAddsNames),
GetListElement(InParams,7,0,OldAddsVals),
AddNewAddition(OldAddsNames,OldAddsVals,an1,av1,AddsNames1,AddsVals1),
AddNewAddition(AddsNames1,AddsVals1,an2,av2,AddsNames2,AddsVals2),
AddNewAddition(AddsNames2,AddsVals2,an3,av3,AddsNames3,AddsVals3),
AddNewAddition(AddsNames3,AddsVals3,an4,av4,AddsNames4,AddsVals4),
GetListElement(InParams,5,0,OldMonitor),
Max(Monitor1,OldMonitor,NewMonitor),
GetListElement(InParams,4,0,OldHDD),
{Max(HDD1,OldHDD,NewHDD),}
NewHDD=OldHDD+HDD1,
GetListElement(InParams,3,0,OldVMem),
Max(VMem1,OldVMem,NewVMem),
GetListElement(InParams,2,0,OldMem),
Max(Mem1,OldMem,NewMem),
GetListElement(InParams,1,0,OldProc),
GetListElement(InParams,0,0,OldFreq),
SelectProcessor(OldProc,OldFreq,Proc1,Freq1,NewProc,NewFreq),
{CreateParamsList(NewFreq,NewProc,NewMem,NewVMem,NewHDD,NewMonitor,AddsNames4,AddsVals4,InParams1),
ChooseConfig(T,InParams1,OutParams)}
ChooseConfig(T,[NewFreq,NewProc,NewMem,NewVMem,NewHDD,NewMonitor,AddsNames4,AddsVals4],OutParams).
PrintAdditions([],[]).
PrintAdditions([Hn|Tn],[Hv|Tv]) if
Write(Hn), Write(" "), WriteLn(Hv),
PrintAdditions(Tn,Tv).
run if
{ReadParameters([],A),
WriteLn(A),}
ChooseConfig(["Internet","сочинение музыки","Delphi 3"],[0,"86",0,0,0,0,[],[]],B),
{WriteLn(B),}
GetListElement(B,0,0,Freq),
GetListElement(B,1,0,Proc),
WriteLn("Процессор: ",Proc," ",Freq," MHz"),
GetListElement(B,2,0,Mem),
WriteLn("Память: ",Mem," МБайт"),
GetListElement(B,3,0,VMem),
WriteLn("Видео память: ",VMem," МБайт"),
GetListElement(B,4,0,HDD),
WriteLn("Винчестер: ",HDD," МБайт"),
GetListElement(B,5,0,Monitor),
WriteLn("Монитор: ",Monitor,""""),
GetListElement(B,6,0,Names),
GetListElement(B,7,0,Vals),
PrintAdditions(Names,Vals).
Аннотация
В рамках данного дипломного проекта разработан интерпретатор языка Пролог с визуальным вводом программы и возможностью работы с универсальными базами данных.
Настоящая пояснительная записка включает в себя описание механизма вывода в языке Пролог и роли логического программирования в развитии вычислительной техники.
Приводится описание разработанного интерпретатора, а также необходимые для работы с ним документа: требования по эксплуатации, руководство по установке, руководство пользователя, тексты программ.
Приводится расчет затрат на разработку программного продукта.
Приводится анализ опасных и вредных факторов, возникающих при эксплуатации программы интерпретатора.
Содержание
Введение.......................................................................................................... 4
1. Исследовательская часть............................................................................. 8
1.1. Роль реляционных языков в развитии вычислительной техники.......... 8
1.2. Основные механизмы дедукции............................................................ 10
1.3. Исчисление предикатов как язык для решения задач.......................... 12
1.3.1 Унификация и принцип резольвенции в исчислении предикатов...... 13
1.3.2. Методы поиска доказательства в исчислении предикатов................ 15
1.3.2.1. Исчисление предикатов при решении задач................................... 15
1.3.2.2. Стратегии перебора......................................................................... 16
1.3.2.3. Стратегии упрощения...................................................................... 17
1.3.2.4. Стратегии очищения........................................................................ 18
1.3.2.5. Формы доказательства с отфильтровыванием предшествующих вершин........................................................................................................................... 4
1.3.2.6. Стратегии поддерживающего множества......................................... 4
1.3.2.7. Стратегии упорядочения................................................................... 5
1.4. Анализ характеристик существующих интерпретаторов...................... 6
1.5. Необходимость разработки интерпретатора языка Пролог................. 8
1.6. Выбор языка программирования........................................................... 8
2. Конструкторская часть............................................................................. 10
2.1. Синтаксис программ на Прологе в нотации Бэкуса-Наура................. 10
2.2. Общая структура интерпретатора........................................................ 10
2.2.1. Принцип работы предкомпилятора................................................... 11
2.2.1.1. Работа лексического анализатора................................................... 11
2.2.1.2. Синтаксический анализатор............................................................ 12
2.2.1.3. Анализ арифметического выражения............................................. 13
2.2.1.4. Анализ параметров предикатов...................................................... 15
2.2.1.5. Проверка типов параметров............................................................ 15
2.3. Работа интерпретатора.......................................................................... 16
2.3.1. Выполнение обращений к базам данных........................................... 18
2.3.2. Вычисление арифметических выражений.......................................... 19
2.4. Объекты, используемые компилятором и интерпретатором............... 19
2.4.1. Объекты переменных TPrologVariable, TPrologVariables, TPrologVariableList, TPrologVariableStruct.................................................................................... 19
2.5.2. Стандартные функции и предикаты................................................... 21
2.6. Представление Пролог-программы в виде объектов........................... 21
2.7. Основные модули................................................................................... 23
2.8. Демонстрационная программа по выбору конфигурации компьютера. 25
3. Технологическая часть.............................................................................. 28
3.1. Требования по эксплуатации интерпретатора языка Пролог............. 28
3.2. Установка системы................................................................................. 28
3.3. Руководство пользователя программы интерпретатора языка Пролог. 29
3.3.1. Запуск программы.............................................................................. 29
3.3.2. Перечень функций, реализуемых системой....................................... 29
3.3.3. Редактирование Пролог-программы................................................. 29
3.3.4. Запуск программы на Прологе и ее отладка..................................... 34
3.3.5. Работа с меню...................................................................................... 35
3.4. Описание процесса выполнения программы, написанной на языке Пролог. 38
3.5. Общие сведенья об интерпретаторе...................................................... 39
3.6. Особенности работы Пролог-программы с базами данных................ 39
3.7. Описание стандартных предикатов....................................................... 40
3.8. Описание функций.................................................................................. 43
4. Организационно-экономическая часть.................................................... 45
4.1. Расчет затрат на разработку интерпретатора Пролог......................... 45
5. Промышленная экология и безопасность................................................ 47
5.1. Введение................................................................................................. 47
5.2. Анализ характера загрязнения окружающей среды при производстве вычислительной техники............................................................................... 48
5.2.1. Источники загрязнения....................................................................... 48
5.2.2. Очистка воздуха от вредных примесей.............................................. 50
5.3. Анализ влияния опасных и вредных факторов, при эксплуатации программы интерпретатора Пролог................................................................................ 52
5.3.1. Повышенный уровень шума на рабочем месте................................. 53
5.3.2. Опасный уровень напряжения электрической цепи, замыкание которой может произойти через человека............................................................................. 54
5.3.3. Пожарная опасность........................................................................... 55
5.3.4. Повышенный уровень электромагнитных излучений....................... 56
5.3.5 Повышенная яркость света.................................................................. 57
5.3.6. Прямая и отраженная блеклость........................................................ 58
5.3.7. Нарушение микроклимата рабочих помещений............................... 58
5.3.8. Защита от психофизиологических факторов..................................... 59
5.4. Анализ использования защитных экранов для снижения влияния опасных и вредных факторов, во время работы на автоматизированном рабочем месте. 60
5.4.1 Основные функции защитных экранов, необходимые для снижения влияния вредных и опасных факторов, во время работы с программным средством. 60
5.4.1.1. Защита от электростатического и электромагнитного воздействий. 61
5.4.1.2. Защита от рентгеновского излучения............................................. 61
5.4.1.3. Защита от ультрафиолетового излучения...................................... 61
5.4.2. анализ основных типов защитных экранов, которые приемлемы для снижения влияния вредных и опасных факторов, во время с программным средством. 62
5.4.2.1. Сетчатый (частичная защита зрения).............................................. 62
5.4.2.2. Стеклянный двухслойный с заземлением (частичная защита зрения, частичная защита здоровья)......................................................................... 62
5.4.2.3. Стеклянный многослойный с заземлением (полная защита зрения, полная защита здоровья).......................................................................................... 63
5.5. Расчет необходимого звукопоглощения, при работе с АРМ............... 63
Заключение.................................................................................................... 66
Литература.................................................................................................... 67
Приложения................................................................................................... 68
Приложение 1................................................................................................ 68
Приложение 2................................................................................................ 73
Приложение 3................................................................................................ 81
Приложение 4................................................................................................ 87
Введение
Разрабатываемый программный продукт предназначен для визуального создания, редактирования и интерпретации программ, написанных на языке Пролог с возможностью работы с универсальными базами данных.
Постоянно возрастающий объем информации, которую необходимо обрабатывать современным компьютерам предъявляет более широкие требования к современным базам данных. Если на заре развития компьютерной техники база данных была обычным файлом, который представлял собой типизированный файл, к которому можно было обращаться по абсолютному номеру записи, то сейчас база данных представляет собой интеллектуальную среду, которая включает в себя подчас несколько таблиц с данными, связанными между собой. Причем конечный пользователь из-за сложности структуры базы не знает, в каком месте файла хранятся данным, с которыми он работает. Современные базы данных обладают встроенными возможностями защиты прав доступа, а также способами поддержки целостности данных и их непротиворечивости. Это достигается за счет включения в сами базы данных отдельный частей программы, которые действуют независимо от пользовательской программы как программы-серверы. Доступ к таблицам стал значительно проще за счет использования языка SQL, который помогает быстро выбирать нужный пользователю сегмент информации из общего объема, также удалять ненужную информацию и добавлять новую.
Базы данных сейчас используются не только как обычные хранилища информации, но и как хранилища знаний. Поэтому появляется новое требование к базам данных, которое пришло от баз знаний, - это возможность логического вывода новых знаний из уже известных, а также работа в режиме экспертной системы.
В самом узком смысле термин экспертная система используется для описания одной из небольшого числа программ, разработанных общепризнанными специалистами в инженерии знаний. Назначение этих программ состоит в воспроизведении возможности решения задач, которыми обладает эксперт. Большинство экспертных систем не может полностью заменить человека. Такие системы используются для повышения эффективности работы и расширения знаний персонала средней квалификации.
В широком смысле экспертная система - это любая программа, применяемая для экспертных консультаций. Данное определение охватывает все программы, используемые в качестве экспертных систем, не учитывая того момента, что истинные эксперты могли и не участвовать в создании этих программ.
В любой системе экспертных консультаций обязательно должны иметься следующие три компоненты:
1. язык представления знаний, с помощью которого можно интуитивно представить знания о сложной области;
2. стратегия решения задач, позволяющая выполнять действия с представленными знаниями столь же компетентно, как это делают эксперты-люди;
3. интерфейс с пользователем, обеспечивающий естественность и удобство доступа к знаниям, которыми обладает программа, и способный объяснять свои ответы, как неопытным пользователям, так и пользователям-экспертам[1].
Традиционным языком в создании экспертным систем является язык Пролог. Это классический язык логического программирования. Он имеет встроенный механизм вывода, основанный на принципе резолюций, помогающий формально обращаться со знаниями. Кроме того, язык Пролог является реляционным языком программирования, то есть оптимально приспособлен для работы с реляционными базами данных. Так как Пролог оперирует правилами, программисту не нужно задумываться над программированием последовательности действий для машины, как это делается при программировании на процедурных языках. Программист просто составляет совокупность правил, описывающую данную предметную область, а Пролог выполняет составленную программу, используя алгоритм бэктрекинга.
Как указывалось ранее, немаловажным в экспертной системе является интерфейс с пользователем как профессионалам в данной предметной области, так и непрофессионалом. Вследствие этого, интерфейс с человеком должен осуществляться на естественном языке. Так как Пролог является декларативным языком и основан на исчислении высказываний, то на нем достаточно несложно можно написать обработку естественного языка.
Актуальным вопросом всегда был вид представления знаний. Изначально в Прологе база знаний хранилась в текстовом файле в формате языка Пролог, который загружался в память, и компилировался во время исполнения программы. Это было явным недостатком Пролога, так как ведение такой базы знаний возможно только человеком и только вручную, то есть, используя только текстовый редактор, а не какую-то специализированную программу. Это ограничивало возможности применения Пролога. Кроме этого, еще одним ограничением было то, что Прологу приходилось загружать в память всю базу знаний. То есть, если оперативной памяти компьютера не хватало, то программа не могла работать.
Подключение к Прологу универсальных баз данных позволяет снять эти два ограничения. Универсальными базами данных могут пользоваться другие программы, которые специализированы для ввода того или иного формата представления знаний. Таким образом, увеличивается скорость и качество ввода знаний. Более того, знания могут добавляться прямо по ходу выполнения Пролог-программы. Становится возможным поступление данных сразу с разных точек (с разных компьютеров).
Также использование баз данных позволяет снять ограничение на объем оперативной памяти компьютера, так как менеджер баз данных грузит в память только те данные, которые требуются в настоящий момент, а не все сразу. Также не нужна компиляция знаний во время выполнения программы, так как они уже находятся в нужном формате. Использование баз данных замедляет скорость работы программы, так как ей приходится обращаться к диску за данными, но менеджер баз данных позволяет уменьшить это замедление за счет кэширования данных и опережающего чтения.
Разрабатываемая система позволяет снять высокие требования к объему памяти компьютера, так как использует универсальные базы данных. Теперь база знаний может храниться в файле базы данных и загружаться в память компьютера по необходимости. Использование баз данных позволяет работать с одной базой знаний нескольким программам, а также предоставляется возможность удобного редактирования базы с помощью других программ. Загрузка и поиск записей в БД возложена на операционную систему, которая централизовано и эффективно распределяет доступ к базам данных для нескольких программ, а также за счет встроенного кэширования позволяет снизить зависимость скорости выполнения программы от скорости работы диска.
Система содержит интегрированную среду разработчика, которая предоставляет широкие возможности по визуальному вводу, редактированию и отладке программы на Прологе.
Исследовательская часть
Роль реляционных языков в развитии вычислительной
Техники
В настоящее время растет круг практических систем, использующих достижения искусственного интеллекта на современных ЭВМ, появились престижные проекты создания ЭВМ новых поколений, в которых интеллектуальный интерфейс с конечным пользователем (непрофессионалом в информатике) является центральным элементом. В японском проекте создания ЭВМ пятого поколения язык Пролог прямо называется базовым языком программирования[5].
Близость Пролога к конечному пользователю объясняется тем, что он является декларативным языком. Чтобы задать определенную последовательность действий, приводящих к решению задачи, в программе на Прологе необходимо описать ее содержание в терминах объектов и отношений между ними. Таким образом, вместо алгоритма решения задачи, программист составляет ее логическую спецификацию.
Что же касается построения алгоритма, то это автоматически выполняется самой Пролог-системой с помощью встроенного механизма вывода. При этом цель решения задачи представляется в виде запроса к базе знаний, в которой содержится описание предметной области задачи. Для поиска в базе данных значений, требуемых в запросе, Пролог-система инициирует механизм вывода. Таким образом, вычисления в Прологе представляют собой процесс дедукции, направленный на построение доказательства целевого утверждения задачи.[1]
Семантика языка Пролог значительно отличается от семантики других языков программирования. Вообще, языки программирования можно разбить на три широкие категории в соответствии с природой семантики этих языков:
· Процедурные языки;
· Функциональные языки;
· Реляционные языки.
Смысл конструкции процедурного языка определяется в терминах поведения компьютера при выполнении этой конструкции. В функциональном языке смысл конструкции (например, вызов функции) определяется в терминах значения, которое она вырабатывает. А в реляционном языке – отношение между отдельными сущностями или классами сущностей. Таким образом, процедурные языки можно назвать языками низкого уровня, так как они дают картину мира, близкую к взгляду на мир с позиций компьютера. Языки же высокого уровня обеспечивают взгляд на мир, приближающийся к картине мира, представленной в спецификации задачи. При использовании идеального реляционного языка становится возможным написание программы, структурно изоморфной по отношению к своей спецификации, то есть для каждой вариации формы спецификации будет существовать соответствующая вариация формы программы.
Хотя Пролог и далек от идеального реляционного языка, он в то же время достаточно близок к такому языку. Это позволяет программисту воспользоваться упомянутыми выше преимуществами идеальных реляционных языков. Программист может мыслить в терминах структуры отношений, не заботясь о точности их трансляции в программу. То есть данный язык позволяет работать специалисту на высоком концептуальном уровне.[1]
Возможны три точки зрения программиста на Пролог-программу.
1. Реляционный подход. При этом программа рассматривается как множество взаимоопределенных, возможно очень сложных, взаимоотношений. Реляционный подход пригоден в том случае, когда хорошо известна структура предметной области. Процесс программирования при этом сводится к аксиоматическому определению каждого отношения. Входной и выходной потоки, а также поведение программы являются результатами действия запросов к отношению. Если отношение реализовано корректно, то будут правильными также входной и выходной потоки.
2. Подход к программе с позиций потока данных. Такой взгляд на программу уместен, когда известна природа выходного потока (то есть множество ответов). При программировании реализуется такая внутренняя структура программы, которая создает желаемый выходной поток. Если важен порядок следования ответов в выходном потоке, то при построении программы следует в явной форме учитывать процедурные факторы.
3. Поведенческий подход к программе. Поведенческий подход пригоден тогда, когда известно лишь желаемое поведение программы. Процесс программирования связан с построением такой внутренней структуры программы, которая обеспечит заданное поведение. При разработке такой программы следует обязательно учитывать процедурные факторы и влияние побочных эффектов.
Эти три подхода не являются взаимоисключающими, они представляют собой разные способы мышления в процессе программирования. С точки зрения стиля программирования рекомендуется применять либо реляционный подход, либо подход к программе с позиций потока данных, а к поведенческому следует прибегать лишь в случае крайней необходимости. Причина заключается в том, что программы, при составлении которых применялся поведенческий подход, почти всегда трудно читать, сопровождать и переводить с одной версии Пролог на другую.
Основные механизмы дедукции
Существуют два метода логического вывода, называемые прямой цепочкой рассуждений и обратной цепочкой.
Прямая цепочка рассуждений предполагает использование правил для логического вывода новых фактов, а также фактов, которые имплицитно существовали ранее, но могут быть сделаны явными посредством применения правил. То есть механизм вывода работает для пополнения изначального запаса истинных фактов фактами, которые подразумеваются посредством набора правил. Подобная прямая цепочка рассуждений на практике неприменима: в системе с реальным числом правил имеется столь много подразумеваемых (скрытых) фактов, что, будучи обнаружены, они затмят те несколько фактов, которые действительно представляют интерес и являются полезными.
Однако системы, основанные на прямой цепочке рассуждений, существуют. Любая такая система имеет дополнительный механизм (иногда весьма специфичный в зависимости от проблемы) для того, чтобы определить, с каким следующим правил ей предстоит работать. Вместо простого цикла, который механически выбирает правила, механизм выбора четко устанавливает приоритет выбора тех или иных фактов и правил.
Рассмотрим теперь иной способ получения логического вывода на основе фактов и правил. Начнем с заключения, которое представляет для нас интерес и не является явным истинным фактом. Оно не находится среди хранимых фактов, когда мы запускаем систему.
Механизм вывода просматривает все правила, которые приводят к данному факту как к заключению. Затем механизм просматривает посылки этих правил. Возможно, они уже хранятся среди истинных фактов. Тогда можно считать, что изучаемых факт является истинным и должен быть добавлен в хранилище истинных фактов. Если ни одно из правил не может быть использовано для непосредственного определения рассматриваемого значения из-за того, что необходимо установить истинность их посылок, то в таком случае необходимо идти в обратном направлении и попытаться установить достоверность всех посылок в тех правилах, которые могут применяться для установления истинности конечного вывода. Перемещение на много уровней назад в древовидной структуре даст нам факты, которые являются истинными. Это и есть обратная цепочка рассуждений.
Механизм вывода на Прологе основан на обратной цепочке рассуждений. Процесс выполнения программы сводится к установлению истинности определенного предложения в Прологе (и обычно в определении величин определенных переменных в процессе) посредством обратной цепочки рассуждений и продолжается до тех пор, пока не будут найдены некоторые базовые истинные факты, известные системе.[3]
Дата: 2019-07-24, просмотров: 350.