Руководство фирмы рассматривает кандидатов на замещение вакантной должности бухгалтера. Задача заключается в том, чтобы, используя описанный выше метод, выявить наилучшего претендента. Обсуждение среди членов руководства фирмы дало следующий результат:
d 1 : "Если кандидат имеет требуемые квалификацию, образование и опыт ведения бухгалтерского учета, то он — удовлетворяющий (отвечающий требованиям)";
d 2 : "Если он вдобавок к вышеописанным требованиям умеет работать с современным программным обеспечением (ПО), то он — более чем удовлетворяющий";
d 3 : "Если он дополнительно к условиям d 2 обладает необходимыми юридическими знаниями, то он — безупречный";
d 4 : "Если он имеет все оговоренное в d 3, кроме способности работать с современным ПО, то он — очень удовлетворяющий";
d 5 : "Если кандидат имеет необходимую квалификацию, имеет опыт ведения бухгалтерского учета, обладает юридическими знаниями, но не имеет высшего образования, он все же будет удовлетворяющим";
d 6 : "Если он не имеет квалификации и не имеет опыта ведения бухгалтерского учета, то он — неудовлетворяющий".
Анализ приведенных информационных фрагментов позволяет выявить шесть критериев, используемых для принятия решения:
Х1 — квалификация; Х2 — образование; Х3, — опыт ведения бухгалтерского учета; Х4, — умение работать с современным ПО; Х5 — юридическая грамотность, Y — удовлетворительность.
Для формулирования правил следует определить возможные значения лингвистических переменных Xi и Y, которые будут использоваться для оценки кандидатов:
d 1 : "Если Х1 = ПОДХОДЯЩЯЯ и X 2 = ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ. то Y = УДОВЛЕТВОРЯЮЩИЙ";
d 2 : "Если Х1 = ПОДХОДЯЩАЯ и X 2 = ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ, и X 4 = СПОСОБЕН, то Y = БОЛЕЕ ЧЕМ УДОВЛЕТВОРЯЮЩИЙ";
d 3 : "Если Х1 = ПОДХОДЯЩАЯ и Х2 = ВЫСШЕЕ, и X 3 = ДОСТАТОЧНЫЙ, и Х4 = СПОСОБЕН, и X 5 = ОБЛАДАЕТ, то Y = БЕЗУПРЕЧНЫЙ";
d 4 : "Если Х1 = ПОДХОДЯЩАЯ и Х2 = ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ, и X 4 = ОБЛАДАЕТ, то Y = ОЧЕНЬ УДОВЛЕТВОРЯЮЩИЙ";
d 5 : "Если Х1 = ПОДХОДЯЩАЯ и X 2 = НЕ ВЫСШЕЕ, и Х3 = ДОСТАТОЧНЫЙ, и X 5 = ОБЛАДАЕТ, то Y = УДОВЛЕТВОРЯЮЩИЙ";
d 6 : "Если Х1 = НЕ ИМЕЕТ и Х3 = НЕДОСТАТОЧНЫЙ, то Y = НЕУДОВЛЕТВОРЯЮЩИЙ".
Переменная Y задана на множестве J = {0; 0,1; 0,2; ...; 1}.
Значения переменной Y заданы с помощью следующих функций принадлежности:
S = УДОВЛЕТВОРЯЮЩИЙ определено как mS (х) = х, х Î J;
MS = БОЛЕЕ ЧЕМ УДОВЛЕТВОРЯЮЩИЙ — как mMS ( x )= Ö x ; x Î J ;
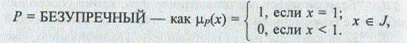
VS = ОЧЕНЬ УДОВЛЕТВОРЯЮЩИЙ — как mVS ( x ) = х2, x Î J ,
US = НЕУДОВЛЕТВОРЯЮЩИЙ — как mVS ( x ) = 1 - х, х Î J.
Выбор производится из пяти кандидатов на множестве U = { u 1 , и2, u 3 , u 4 , u 5 }.
В рассматриваемой задаче оценки кандидатов заданы следующими нечеткими множествами:
ПОДХОДЯЩАЯ (квалификация) А = {0,8/u 1, 0,61 u 2 , 0,5/ u 3 , 0,1/ u 4 , 0,3/ u 5 };
ВЫСШЕЕ (образование) В = {0,5/ u 1 ,1/ u 2 , 0/ u 3 , 0,5/ u 4 , 1/ u 5 };
ДОСТАТОЧНЫЙ (опыт) С = {0,6/ u 1 , 0,9/и2, 1/ u 3 , 0,7/ u 4 , 1/ u 5 };
СПОСОБЕН (работать с ПО) D = {1/ u 1 , 0,3/и2, 1/ u 3 , 0/ u 4 , 0/ u 5 }',
ОБЛАДАЕТ (юридическими знаниями) Е = {0/ u 1, 0,5/ u 2 , 1/ u 3 , 0,8/ u 4 , 1/ u 5 }.
С учетом введенных обозначений правила d 1 , ..., d 6 принимают вид:
d 1 : “Если Х= А и В, и С, то Y = S ”;
d 2 : "Если Х= А и В, и С, и D, то Y = MS ":
d 3 : “Если X = А и В, и С, и D, и E, то Y = P ”;
d 4 : “Если X = А и B, и С, и Е, то Y = VS ”;
d 5 : “Если X = A, и не В, и С, и E, то Y = S ”;
d6: “Если Х = не A и не С, то Y = US ”.
Вычислим функции принадлежности 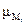 для левых частей приведенных правил:
для левых частей приведенных правил:
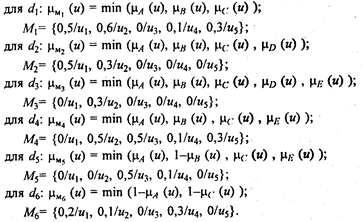
Теперь правила можно записать в виде:
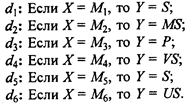
Используя для преобразования правил вида "Если Х = М, то Y = Q" импликацию Лукасевича mD(u, j) = min(l, 1-mM /(u) + mY (j)), для каждой пары ( u , j ) Î U х J получаем следующие нечеткие отношения на U ´ J:
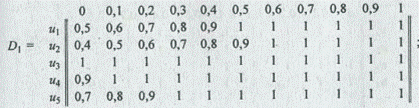

В результате пересечения отношений D 1 , ..., D 6 получаем общее функциональное решение:

Для вычисления удовлетворительности каждой из альтернатив применим правило композиционного вывода в нечеткой среде:
Ek = Gk ° D , где Е k — степень удовлетворения альтернативы k;
Gk — отображение альтернативы k в виде нечеткого подмножества на U , D — общее функциональное решение. Тогда
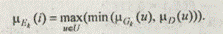
Кроме того, в этом случае 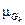 (u) = 0; u ¹ uk , (u) = 1; u = uk. Отсюда
(u) = 0; u ¹ uk , (u) = 1; u = uk. Отсюда 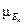 (i) =
(i) = 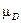 (uk , i) Другими словами, Е k есть k-я строка в матрице D. Теперь применим описанную выше процедуру для сравнения нечетких подмножеств в единичном интервале для получения наилучшего решения на основе точечных оценок.
(uk , i) Другими словами, Е k есть k-я строка в матрице D. Теперь применим описанную выше процедуру для сравнения нечетких подмножеств в единичном интервале для получения наилучшего решения на основе точечных оценок.
Для первой альтернативы
E 1 ={0,5/0; 0,6/0,1; 0,7/0,2; 0,8/0,3; 0,9/0,4; 1/0,5; 1/0,6; 1/0,7; 1/0,8; 0,9/0,9; 0,8/1}.
Вычисляем уровневые множества Ej a и мощность такого множества М(Е a ) по формуле
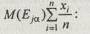

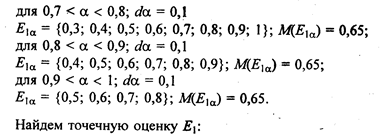

Аналогично находим точечные оценки для других альтернатив:
для второй альтернативы F ( E 2 ) = 0,656;
для третьей — F ( E 3 ) = 0,575;
для четвертой — F ( E 4 ) = 0,483;
для пятой — F ( E 5 ) = 0,562.
В качестве лучшей выбираем альтернативу, имеющую наибольшую точечную оценку. В нашем примере это альтернатива и2, следовательно, она и будет наилучшей. Второе место занимает альтернатива u 3 ; третье – u 5 , четвертое – и1, а самой худшей из альтернатив является u 4 .
Формализация знаний с помощью правил позволяет учитывать различную важность критериев и самих правил. Предположим, что в рассмотренной задаче ЛПР считает крайне важным умение кандидата на должность бухгалтера работать с программным обеспечением. Тогда в правилах d 2 и d 3 значением критерия Х4 будет понятие ОЧЕНЬ СПОСОБЕН, описываемое нечетким множеством D 1 следующего вида:
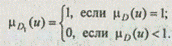
Правило d 4 исключим из рассмотрения, так как теперь кандидат, не владеющий умением работать с ПО, не является ОЧЕНЬ УДОВЛЕТВОРЯЮЩИМ. Тогда соответствующие левым частям правил нечеткие множества М i , i = 1, .... 6, i ¹ 4, будут иметь вид:


F(u1)—0,560; F(u2)— 0,600; F(u3)—0,575; F(u4)— 0,475; F(u5)— 0,530.
Сравнение полученных результатов показывает, что с повышением значимости критерия Х4 ранжировка альтернатив несколько изменилась: и1 и u 5 поменялись местами. Этот факт согласуется с исходными данными, так как кандидат и1 имеет максимальное значение по критерию Х4, а u 5 - минимальное.
Для учета различной важности правил будем использовать нормированные весовые коэффициенты, которые можно получить либо путем попарных сравнений, либо путем экспертного назначения весов.
В рассматриваемой задаче возможны различные подходы к выбору кандидата на должность: мягкий, жесткий, рациональный и т. д. Мягкий подход обычно имеет место в условиях дефицита времени и квалифицированных кадров, основную директиву этого подхода можно сформулировать так: "лишь бы умел что-нибудь делать". При мягком подходе самый большой вес будет иметь правило d 6 а все остальные будут одинаково значимыми. Значения весовых коэффициентов правил приведены в табл. 4.5.
Жесткий подход к выбору кандидата на должность возможен в случае избытка квалифицированных кадров и ресурса времени, отводимого для выбора. Целью такого подхода является поиск кандидата, наиболее соответствующего идеалу. Назначенные ЛПР экспертные оценки важности правил с использованием 10-балльной шкалы и соответствующие весовые коэффициенты приведены в табл. 4.5.
Таблица 4.5
Оценки важности правил
| Правило | d 1 | d 2 | d 3 | d 4 | d 5 | d 6 |
| Мягкая экспертная оценка | 2 | 2 | 2 | 2 | 2 | 10 |
| Коэффициент | 0,6 | 0,6 | 0,6 | 0,6 | 0,6 | 3 |
| Жесткая экспертная оценка | 2 | 3 | 10 | 3 | 2 | 0 |
| Коэффициент | 0,6 | 0,9 | 3 | 0,9 | 0,6 | 0 |
Нечеткие отношения D 1 , ..., D 6 , возводятся в степени, соответствующие весовым коэффициентам правил, после чего выполняется их пересечение и получается общее решение D .
При мягком подходе к принятию решения получены следующие точечные оценки альтернатив: F ( u 1 ) - 0,494; F ( u 2 ) - 0,533; Р( u 3 ) - 0,530; Р( u 4 ) - 0,437; Р( u 5 ) - 0,539. Полученные результаты можно интерпретировать следующим образом: наиболее предпочтительными кандидатами являются u 5 , и2 и u 3 , за ними следует и1, а худшей альтернативой является u 4 . Таким образом, при мягком подходе лучшие альтернативы становятся слабо различимыми, что выглядит естественно, поскольку все они являются неплохими кандидатами.
При жестком подходе множество точечных оценок альтернатив имеет вид: F ( u 1 ) - 0,555; F ( u 2 ) - 0,828; Р( u 3 ) - 0,549; Р( u 4 )- 0,512; Р( u 5 ) - 0,558. Абсолютное предпочтение имеет кандидатура и2, на втором месте с очень близкими оценками находятся кандидаты u 5 и и1, на третьем – u 3 и на последнем – u 4 . Нетрудно заметить, что при жесткой оценке ослабляются различия между претендентами, далекими от идеала.
Подход с использованием правил, имеющих одинаковую важность, можно считать усредненным, или рациональным.
Рассмотренный метод принятия решений с использованием правил нечеткого вывода является адаптацией нечеткой логики к процессам принятия решений с исходными данными в виде точечных оценок. В ряде случаев оценивание альтернатив удобнее производить с использованием нечетких чисел, которые являются значениями лингвистических переменных. При этом правила могут применяться не одновременно, а последовательно. Такой подход к компьютерной поддержке процессов принятия решений используется в интеллектуальных системах с нечеткой логикой.
Рассмотрим решение задачи о выборе бухгалтера с использованием такой системы. Для этого введем следующие лингвистические переменные:
ОБРАЗОВАНИЕ (Высшее, Среднее)
ОПЫТ (Отсутствует, Приемлемый, Большой)
УМЕНИЕ РАБОТАТЬ С ПО (Есть, Нет)
ЮРИДИЧЕСКАЯ ГРАМОТНОСТЬ (Есть, Нет)
СПЕЦИАЛИСТ (Удовлетворяющий, Неудовлетворяющий)
КАНДИДАТ (Хороший, Очень хороший. Безупречный).
В скобках приведены возможные значения лингвистических переменных, каждое из которых представлено нечетким числом (множеством). Отношения между лингвистическими переменными задаются с помощью правил:
d 1 : "Если ОБРАЗОВАНИЕ = Высшее или ОБРАЗОВАНИЕ = Среднее и ОПЫТ = Приемлемый или ОПЫТ == Большой, то СПЕЦИАЛИСТ = Удовлетворяющий, иначе СПЕЦИАЛИСТ = Неудовлетворяющий";
d 2 : "Если СПЕЦИАЛИСТ = Удовлетворяющий и УМЕНИЕ РАБОТАТЬ С ПО = Есть, то КАНДИДАТ = Хороший";
d 3 : "Если СПЕЦИАЛИСТ = Удовлетворяющий и ЮРИДИЧЕСКАЯ ГРАМОТНОСТЬ = Есть, то КАНДИДАТ = Очень хороший";
d 4 : "Если СПЕЦИАЛИСТ = Удовлетворяющий и УМЕНИЕ РАБОТАТЬ С ПО = Есть, и ЮРИДИЧЕСКАЯ ГРАМОТНОСТЬ = Есть, то КАНДИДАТ = Безупречный".
Правила записываются в базу знаний интеллектуальной системы. В процессе решения задачи пользователем задаются исходные данные, которые представляют собой значения лингвистических переменных, соответствующих альтернативам. Обработка этих данных осуществляется посредством процедур нечеткого логического вывода. Результатами работы системы являются нечеткое множество, полученное для заданного кандидата, и мера его сходства с возможными исходами, т. е. нечеткими множествами:
СПЕЦИАЛИСТ (Удовлетворяющий);
СПЕЦИАЛИСТ (Неудовлетворяющий);
КАНДИДАТ (Хороший);
КАНДИДАТ (Очень хороший);
КАНДИДАТ (Безупречный).
Значения лингвистических переменных для альтернатив u 1 , ..., u 5 приведены в табл. 4.6.
Таблица 4.6
Исходные данные для логического вывода
| Лингвистическая переменная | Альтернатива | ||||
| u1 | u2 | u3 | u 4 | u 5 | |
| ОБРАЗОВАНИЕ | Среднее | Высшее | Не (Среднее или Высшее) | Среднее | Высшее |
| ОПЫТ | Приемлемый | Большой | Большой | Приемлемый Ç Большой | Большой |
| УМЕНИЕ РАБОТАТЬ C ПО | Есть | Нет | Есть | Нет | Нет |
| ЮРИДИЧЕСКАЯ ГРАМОТНОСТЬ | Нет | Нет Ç Есть | Есть | Есть | Есть |
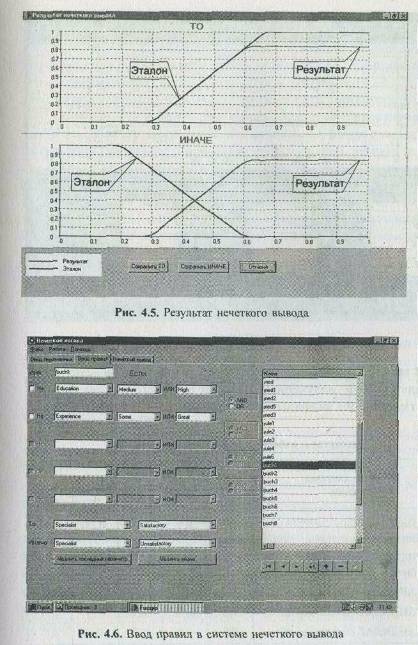
На рис. 4.5 показан результат вывода с использованием правила d 1 для альтернативы u 1 .
На рис. 4.6 и 4.7 показаны экранные формы интеллектуальной программной системы нечеткого логического вывода, используемые для ввода исходной информации.
В табл. 4.7. приведены результирующие лингвистические оценки альтернатив, полученные методом нечеткого вывода, и соответствующие им значения мер сходства.
Таблица 4.7
Дата: 2019-04-23, просмотров: 360.