Рассмотрев один из вариантов двоичного неравномерного кодирования, попробуем найти ответы на следующие вопросы: возможно ли такое кодирование без использования разделителя знаков? Существует ли наиболее оптимальный способ неравномерного двоичного кодирования?
Суть первой проблемы состоит в нахождении такого варианта кодирования сообщения, при котором последующее выделение из него каждого отдельного знака (т.е. декодирование) оказывается однозначным без специальных указателей разделения знаков. Наиболее простыми и употребимыми кодами такого типа являются так называемые префиксные коды, которые удовлетворяют следующему условию (условию Фано):
ииииииииииии
Неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает с началом какого-либо иного более длинного кода.
Например, если имеется код ПО, то уже не могут использоваться коды 1, 11, 1101, 110101 и пр. Если условие Фано выполняется, то при прочтении (расшифровке) закодированного сообщения путем сопоставления со списком кодов всегда можно точно указать, где заканчивается один код и начинается другой.
Пример: Пусть имеется следующая таблица префиксных кодов:
| а | л | м | р | у | ы |
| 10 | 010 | 00 | 11 | 0110 | 0111 |
Требуется декодировать сообщение: 00100010000111010101110000110. Декодирование производится циклическим повторением следующих действий:
1. отрезать от текущего сообщения крайний левый символ, присоединить к рабочему кодовому слову;
2. сравнить рабочее кодовое слово с кодовой таблицей; если совпадения нет, перейти к (1);
3. декодировать рабочее кодовое слово, очистить его;
4. проверить, имеются ли еще знаки в сообщении; если «да», перейти к (1).
Применение данного алгоритма дает:
| Шаг | Рабочее слово | Текущее сообщение | Распознанный знак | Декодированное сообщение |
| 0 | пусто | 00100010000111010101110000110 | - | - |
| 1 | 0 | 0100010000111010101110000110 | нет | - |
| 2 | 00 | 100010000111010101110000110 | м | М |
| 3 | 1 | 00010000111010101110000110 | нет | М |
| 4 | 10 | 0010000111010101110000110 | а | МА |
| 5 | 0 | 010000111010101110000110 | нет | МА |
| 6 | 00 | 10000111010101110000110 | м | Мам |
| • • • |
Доведя процедуру до конца, получим сообщение: «мама мыла раму».
Код Хаффмана
Способ оптимального префиксного двоичного кодирования был предложен Д.Хаффманом. Построение кодов Хаффмана мы рассмотрим на следующем примере: пусть имеется первичный алфавит А, состоящий из шести знаков a1…а6 с вероятностями появления в сообщении, соответственно, 0,3; 0,2; 0,2; 0,15; 0,1; 0,05. Создадим новый вспомогательный алфавит Аb объединив два знака с наименьшими вероятностями (а5 и а6) и заменив их одним знаком (например, а(1)); вероятность нового знака будет равна сумме вероятностей тех, что в него вошли, т.е. 0,15; остальные знаки исходного алфавита включим в новый без изменений; общее число знаков в новом алфавите, очевидно, будет на 1 меньше, чем в исходном. Аналогичным образом продолжим создавать новые алфавиты, пока в последнем не останется два знака; ясно, что число таких
шагов будет равно N - 2, где N - число знаков исходного алфавита (в нашем случае N = 6, следовательно, необходимо построить 4 вспомогательных алфавита). В промежуточных алфавитах каждый раз будем переупорядочивать знаки по убыванию вероятностей. Всю процедуру построения представим в виде таблицы:
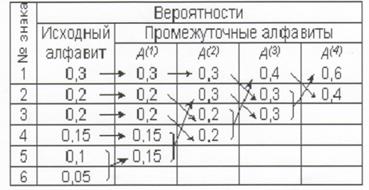
Теперь в обратном направлении поведем процедуру кодирования. Двум знакам последнего алфавита присвоим коды 0 и 1 (которому какой - роли не играет; условимся, что верхний знак будет иметь код 0, а нижний - 1). В нашем примере знак а1(4) алфавита А(4), имеющий вероятность 0,6 , получит код 0, а а2(4) с вероятностью 0,4 - код 1. В алфавите A(3) знак а1(3) с вероятностью 0,4 сохранит свой код (1); коды знаков a2(3) и a3(3), объединенных знаком a1(4) с вероятностью 0,6 , будут уже двузначным: их первой цифрой станет код связанного с ними знака (т.е. 0), а вторая цифра -как условились - у верхнего 0, у нижнего - 1; таким образом, а2(3) будет иметь код 00, a a3(3) - код 01. Полностью процедура кодирования
представлена в следующей таблице:
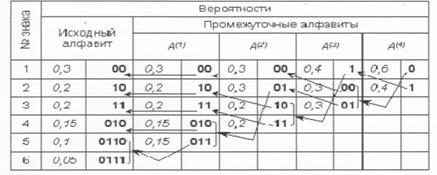
Из самой процедуры построения кодов легко видеть, что они удовлетворяют условию Фано и, следовательно, не требуют разделителя. Средняя длина кода при этом оказывается: К(2) = 0,3-2+0,2-2+0,2-2+0,15-3+0,1-4+0,05-4 = 2,45
Для сравнения можно найти I1{A)-она оказывается равной 2,409. что соответствует избыточности кода Q = 0,0169, т.е. менее 2%.
Код Хаффмана важен в теоретическом отношении, поскольку он является самым экономичным из всех возможных, т.е. ни для какого метода алфавитного кодирования длина кода не может оказаться меньше, чем код Хаффмана. Можно заключить, что существует метод построения оптимального неравномерного алфавитного кода. Метод Хаффмана и его модификация - метод адаптивного кодирования (динамическое кодирование Хаффмана) - нашли применение в программах-архиваторах, программах резервного копирования файлов и дисков, в системах сжатия информации в модемах и факсах.
Дата: 2019-05-29, просмотров: 392.