На этапе реализации информационной системы следует:
3.1. Выбрать архитектуру и описать ее:
3.1.1 Выбор архитектуры.
Архитектура информационной системы - концепция, определяющая модель, структуру, выполняемые функции и взаимосвязь компонентов информационной системы.
С точки зрения программно-аппаратной реализации можно выделить ряд типовых архитектур ИС.
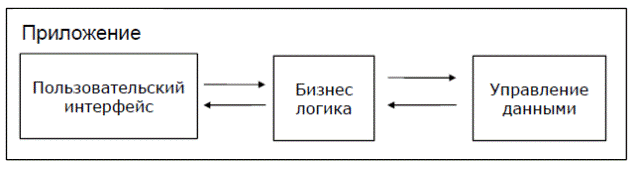
Рисунок 3.1 – Три слоя выполнения функций
Компоненты информационной системы по выполняемым функциям можно разделить на три слоя: слой представления, слой бизнес-логики и слой доступа к данным.
Слой представления - все, что связано с взаимодействием с пользователем: нажатие кнопок, движение мыши, обрисовка изображения, вывод результатов поиска и т.д.
Бизнес логика - правила, алгоритмы реакции приложения на действия пользователя или на внутренние события, правила обработки данных.
Слой доступа к данным - хранение, выборка, модификация и удаление данных, связанных с решаемой приложением прикладной задачей
При выборе архитектуры ставиться две задачи:
а) породить некоторое количество лучших архитектур-кандидатов и их гибридов;
б) совершить многокритериальный выбор из этих архитектур.
Выбор также поделим на две части: содержательное рассмотрение и оформление результата (обоснование).
В многокритериальном выборе центральным являются критерии. Какая архитектура лучше - это вопрос про "главный критерий", каковых оказывается неожиданно много, и каковые никуда не деваются при содержательном рассмотрении архитектурных альтернатив. Все зависит конечно же от тех задач которые ставятся для разрабатываемой ИС и средств ее реализации.
Ниже представлены традиционные архитектуры информационных систем и приведены их достоинства и недостатки:
1. Файл-серверная архитектура.
Появились локальные сети. Файлы начали передаваться по сети. Сначала были одноранговые сети - все компьютеры равноправны.
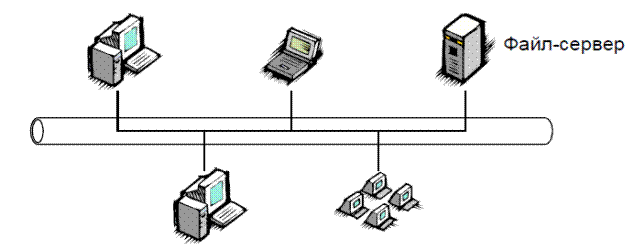
Рисунок 3.2 – Файл-серверная архитектура
Потом возникла идея хранения всех общедоступных файлов на выделенном компьютере в сети - файл-сервере.

Рисунок 3.3 – Модель файлового сервера
Файл-серверные приложения — приложения, схожие по своей структуре с локальными приложениями и использующие сетевой ресурс для хранения программы и данных. Функции сервера: хранения данных и кода программы. Функции клиента: обработка данных происходит исключительно на стороне клиента.
Количество клиентов ограничено десятками.
Плюсы:
- Многопользовательский режим работы с данными;
- Удобство централизованного управления доступом;
- Низкая стоимость разработки.
Минусы:
- Низкая производительность;
- Низкая надежность;
- Слабые возможности расширения.
Недостатки архитектуры с файловым сервером очевидны и вытекают главным образом из того, что данные хранятся в одном месте, а обрабатываются в другом. Это означает, что их нужно передавать по сети, что приводит к очень высоким нагрузкам на сеть и, вследствие этого, резкому снижению производительности приложения при увеличении числа одновременно работающих клиентов. Вторым важным недостатком такой архитектуры является децентрализованное решение проблем целостности и согласованности данных и одновременного доступа к данным. Такое решение снижает надежность приложения.
2. Клиент-серверная архитектура.
Ключевым отличием архитектуры клиент-сервер от архитектуры файл-сервер является абстрагирование от внутреннего представления данных (физической схемы данных). Теперь клиентские программы манипулируют данными на уровне логической схемы.
Итак, использование архитектуры клиент-сервер позволило создавать надежные (в смысле целостности данных) многопользовательские ИС с централизованной базой данных, независимые от аппаратной (а часто и программной) части сервера БД и поддерживающие графический интерфейс пользователя (ГИП) на клиентских станциях, связанных локальной сетью. Причем издержки на разработку приложений существенно сокращались.
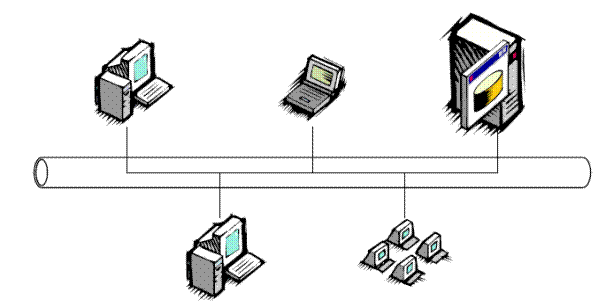
Рисунок 3.4 - Клиент-серверная архитектура
Основные особенности:
- Клиентская программа работает с данными через запросы к серверному ПО;
- Базовые функции приложения разделены между клиентом и сервером.
Плюсы:
- Полная поддержка многопользовательской работы;
- Гарантия целостности данных.
Минусы:
- Бизнес логика приложений осталась в клиентском ПО. При любом изменении алгоритмов, надо обновлять пользовательское ПО на каждом клиенте;
- Высокие требования к пропускной способности коммуникационных каналов с сервером, что препятствует использование клиентских станций иначе как в локальной сети;
- Слабая защита данных от взлома, в особенности от недобросовестных пользователей системы;
- Высокая сложность администрирования и настройки рабочих мест пользователей системы;
- Необходимость использовать мощные ПК на клиентских местах;
- Высокая сложность разработки системы из-за необходимости выполнять бизнес-логику и обеспечивать пользовательский интерфейс в одной программе.
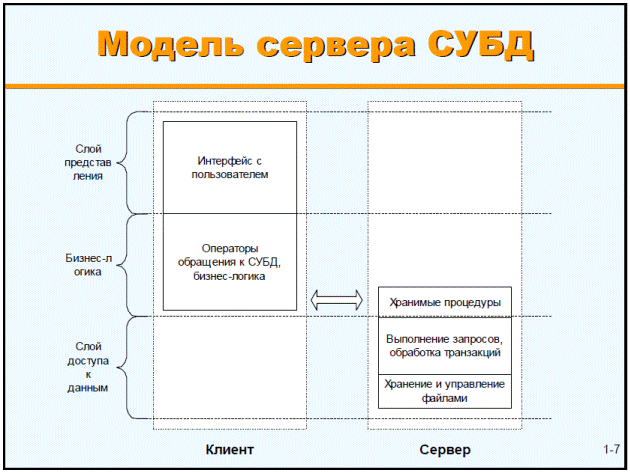
Рисунок 3.5 – Модель сервера СУБД
Нетрудно заметить, что большинство недостатков классической или 2-слойной архитектуры клиент-сервер проистекают от использования клиентской станции в качестве исполнителя бизнес-логики ИС. Поэтому очевидным шагом дальнейшей эволюции архитектур ИС явилась идея "тонкого клиента", то есть разбиения алгоритмов обработки данных на части связанные с выполнением бизнес-функций и связанные с отображением информации в удобном для человека представлении. При этом на клиентской машине оставляют лишь вторую часть, связанную с первичной проверкой и отображением информации, перенося всю реальную функциональность системы на серверную часть.
3. Переходная к трехслойной архитектуре (2.5 слоя).
Использование хранимых процедур и вычисление данных на стороне сервера сокращают трафик, увеличивают безопасность. Клиент все равно реализует часть бизнес-логики.
Как видно, такая организация системы весьма напоминает организацию первых унитарных систем с той лишь разницей, что на пользовательском месте стоит не терминал (с пресловутым зеленым экраном), а персональный компьютер, обеспечивающий ГИП, например, в последнее время в качестве клиентских программ часто применяют стандартные www-браузеры. Конечно, такой возврат к почти унитарным системам произошел уже на ином технологическом уровне. Обязательным стало использование СУБД со всеми их преимуществами. Программы для серверной части пишут, в основном, на специализированных языках, пользуясь механизмом хранимых процедур сервера БД. Таким образом, на уровне логической организации, ИС в архитектуре клиент-сервер с тонким клиентом расщепляется на три слоя - слой данных, слой бизнес-функций (хранимые процедуры) и слой представления. К сожалению, обычно, в такой схеме построения ИС не удается написать всю бизнес-логику приложения на не предназначенных для этого встроенных языках СУБД. Поэтому, очень часто часть бизнес-функций реализуется в клиентской части систем, которая от этого неотвратимо "толстеет". Отчасти поэтому, отчасти потому, что физически такие ИС состоят из двух компонентов, эту архитектуру часто называют 2.5-слойный клиент-сервер.
В отличие от 2-слойной архитектуры 2.5-слойная архитектура обычно не требует наличия высокоскоростных каналов связи между клиентской и серверной частями системы, так как по сети передаются уже готовые результаты вычислений - почти все вычисления производятся на серверной стороне. Существенно улучшается также и защита информации - пользователям даются права на доступ к функциям системы, а не на доступ к ее данным и т.д. Однако вместе с преимуществами унитарного подхода архитектура 2.5 перенимает и все его недостатки, как-то:
- ограниченную масштабируемость;
- зависимость от программной платформы;
- ограниченное использование сетевых вычислительных ресурсов.
Кроме того программы для серверной части системы пишутся на встроенных в СУБД языках описания хранимых процедур, предназначенных для валидации данных и построения несложных отчетов, а вовсе не для написания ИС масштаба предприятия. Все это снижает быстродействие системы, повышает трудоемкость создания с модификации ИС и самым негативным образом сказывается на стоимости аппаратных средств, необходимых для ее функционирования.
4. Трехуровневая клиент-серверная архитектура.
Для решения этих проблем и была предложена так называемая 3-слойная архитектура клиент-сервер. Основным ее отличием от архитектуры 2.5 является физическое разделение программ, отвечающих за хранение данных (СУБД) от программ эти данные обрабатывающих (сервер приложения (СП), application server (AS)). Такое разделение программных компонент позволяет оптимизировать нагрузки как на сетевое, так и на вычислительное оборудование комплекса.
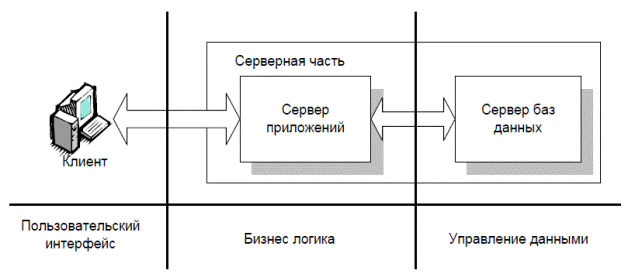
Рисунок 3.6 - Трехуровневая клиент-серверная архитектура

Рисунок 3.7 – Трехуровневая модель сервера приложения
Компоненты трехзвенной архитектуры, с точки зрения программного обеспечения реализуют определенные сервера БД, web-сервера и браузеры. Место любого из этих компонентов может занять программное обеспечение любого производителя.
Плюсы:
- Тонкий клиент;
- Между клиентской программой и сервером приложения передается лишь минимально необходимый поток данных - аргументы вызываемых функций и возвращаемые от них значения. Это теоретический предел эффективности использования линий связи, даже работа с ANSI-терминалами (не говоря уже об использование протокола http) требует большей нагрузки на сеть;
- Сервер приложения ИС может быть запущен в одном или нескольких экземплярах на одном или нескольких компьютерах, что позволяет использовать вычислительные мощности организации столь эффективно и безопасно как этого пожелает администратор ИС;
- Дешевый трафик между сервером приложений и СУБД. Трафик между сервером приложений и СУБД может быть большим, однако это всегда трафик локальной сети, а их пропускная способность достаточно велика и дешева. В крайнем случае, всегда можно запустить СП и СУБД на одной машине, что автоматически сведет сетевой трафик к нулю;
- Снижение нагрузки на сервер данных по сравнению с 2.5-слойной схемой, а значит и повышение скорости работы системы в целом;
- Дешевле наращивать функциональность и обновлять ПО.
Минусы:
- Выше расходы на администрирование и обслуживание серверной части.
Масштабируемость систем выполненных в 3-слойной архитектуре впечатляет. Одна и та же система может работать как на одном отдельно стоящем компьютере, выполняя на нем программы СУБД, СП и клиентской части, так и в сети, состоящей из сотен и тысяч машин. Как уже было отмечено, единственным фактором, препятствующим бесконечной масштабируемости, является лишь требование ведения единой базы данных.
Помимо требования увеличения производительности системы с ростом масштабов деятельности важным фактором является и расширение ее функциональной наполненности. И здесь 3-слойная схема выигрывает у своих предшественников. Для расширения функциональности не обязательно менять всю систему как в случае 2.5-слойной схемы - достаточно установить новый сервер приложения с требуемой функцией. Отпадают и многие проблемы связанные с переустановкой клиентских частей программы на множестве компьютеров, быть может весьма удаленных, столь актуальные для 2-слойной схемы - парадигма "тонкого" клиента предоставляет для этого целый ряд возможностей.
5. Internet/Intranet – технологии.
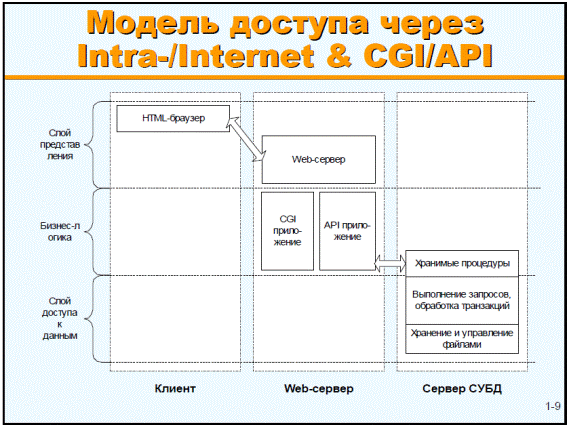
Рисунок 3.8 – Модель доступа через Intra/Internet & CGI/API
6. Архитектура на основе Internet/Intranet с мигрирующими программами.
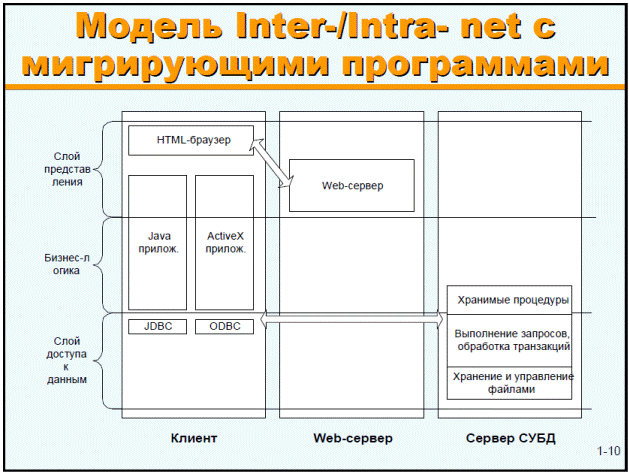
Рисунок 3.9 – Модель Inter/Intra – net с мигрирующими программами
3.1.2. Описание архитектуры. Здесь следует выделить основные определения, принцип построения, основные достоинства и критерии выбора данной архитектуры.
Пример:
Поговорим о том, что же все-таки такое клиент-сервер. Как правило, компьютеры и программы, входящие в состав информационной системы, не являются равноправными. Некоторые из них владеют ресурсами (файловая система, процессор, принтер, база данных и т.д.), другие имеют возможность обращаться к этим ресурсам. Компьютер (или программу), управляющий ресурсом, называют сервером этого ресурса (файл-сервер, сервер базы данных, вычислительный сервер). Клиент и сервер какого-либо ресурса могут находиться как в рамках одной вычислительной системы, так и на различных компьютерах, связанных сетью. Соответственно, говорят о технологии клиент-сервер применительно к информационным системам, локальным и глобальным сетям и т.д.
Такое широкое определение рождает некоторую путаницу. Так, файл-серверная система тоже использует технологию клиент-сервер, однако с точки зрения архитектуры прикладных программ важным является то, какого рода ресурсы сервер предоставляет клиентам.
Понятие архитектуры клиент-сервер в системах управления предприятием связано с делением любой прикладной программы на три основных компонента или слоя. Этими тремя компонентами являются:
- компонент представления (визуализации) данных;
- компонент прикладной логики;
- компонент управления базой данных.
Действительно, любая программа, компьютеризирующая выполнение той или иной прикладной задачи, должна обмениваться информацией с пользователем, осуществлять собственно обработку этой информации в рамках автоматизации того или иного бизнес-процесса, и, наконец, хранить данные используемые в программе, на том или ином постоянном носителе.
Для локальных приложений, полностью работающих на ПЭВМ (например, Word или Excel), все эти компоненты собраны вместе и не могут быть распределены между различными компьютерами. Такая программа является монолитной и использует для выполнения ресурсы только того компьютера, на котором выполняется.
В файл-серверных приложениях часть компоненты хранения переносится на файловый сервер, однако, все манипуляции со структурами данных выполняются на клиентской машине, и код пользовательской программы тоже работает только на ней.
Критерием, позволяющим отнести прикладную программы к архитектуре клиент-сервер является то, что хотя бы один из трех ее компонентов полностью выполняется на другом компьютере, и взаимодействие между компонентами на разных компьютерах осуществляется через ту или иную сетевую среду посредством передачи запросов на получение того или иного ресурса.
Поскольку архитектура клиент-сервер является частным случаем технологии клиент-сервер, в ней обязательно есть клиент и сервер. Соответственно, выделяют клиентскую и серверную стороны приложения. Клиентская сторона приложения функционирует на рабочем месте пользователя, в роли которого в подавляющем числе случаев выступает персональный компьютер. Серверная сторона функционирует на специализированном комплексе, включающем в себя мощные аппаратные средства, требуемый набор стандартного программного обеспечения, систему управления базами данных и собственно структуры данных.
Взаимодействие клиентской и серверной частей приложения осуществляется через сеть - локальную или глобальную. При этом с точки зрения клиента и сервера взаимодействие осуществляется прозрачно, соответственно сетевой компонент здесь включает в себя совокупность необходимого сетевого оборудования, набор программных технологий, обеспечивающих передачу данных между узлами сети, а также собственно протокол или протоколы для обмена запросами и результатами их выполнения.
Компонент визуализации прикладной задачи осуществляет ввод информации пользователем с помощью тех или иных средств, а также вывод информации на экран и печать. Компонент визуализации для архитектуры клиент-сервер всегда исполняется на рабочем месте пользователя (поскольку должен же он наблюдать какие-либо результаты работы программы).
Компонент прикладной логики решает собственно ту или иную задачу, связанную с обработкой данных в той или иной предметной области. Этот компонент может быть распределен между клиентской и серверной частью различным образом в зависимости от применяемой модели.
Компонент хранения базы данных осуществляет физические операции, связанные с хранением данных, чтением информации из БД и записью в нее. В архитектуре клиент-сервер этот компонент всегда выполняется на сервере.
С точки зрения количества составных частей клиент-серверные системы делятся на двухуровневые и трехуровневые. Двухуровневые системы состоят только из клиента и сервера. В трехуровневых же между пользовательским клиентом и сервером, осуществляющим хранение и обработку базы данных, появляется третий, промежуточный слой, являющийся для пользователя сервером, а для системы управления базами данных - клиентом. Такая архитектура позволяет более гибко распределять функции системы и нагрузку между компонентами программно-аппаратного комплекса, а также может снизить требования к ресурсам рабочих мест пользователей. Необходимой платой за это является то, что подобные системы намного сложнее в разработке, внедрении и эксплуатации и требуют значительных затрат и высококвалифицированного персонала.
Почему же все-таки была выбрана архитектуры клиент-сервер для информационной системы:
Во-первых, архитектура клиент-сервер становится жизненно необходимой, когда число пользователей одновременно активно пользующихся одними и теми же данным превышает 10-15 человек. В силу принципиальных ограничений, присущих файл-серверным приложениям, 15 параллельно работающих пользователей такие системы переносят с трудом, а на 20 пользователях часто разваливаются. Таким образом, если перед предприятием встает задача построения системы, в которых число мест, одновременно активно работающих с данными, превышает 20, практически единственным вариантом для него является клиент-сервер.
Справедливости ради следует заметить, что большие ЭВМ тоже способны справиться с десятками или даже сотнями пользователей. Однако, из-за высокой стоимости аппаратных средств, дороговизны разработки, и, что немаловажно, немалыми затратами на эксплуатацию подобной техники и программ для нее, вариант использования централизованной архитектуры при внедрении новых систем в нашей стране почти никогда не рассматривается.
Другим критическим моментом для выбора архитектуры клиент-сервер является переход к решению задач масштаба предприятия и управление предприятием в целом. Автоматизация отдельных рабочих мест может быть с успехом выполнена даже без использования сетевых технологий, с задачами масштаба отдела может справиться и файл-сервер, но построение интегрированной автоматизированной системы охватывающей все предприятие или, по крайней мере, какую-либо из подсистем управления, возможно только с использованием технологий клиент-сервер.
Еще одной ситуацией, когда клиент-сервер - единственный способ построения системы, является наличие в автоматизированной системе удаленных пользователей, с которыми необходимо обмениваться информации в реальном масштабе времени. Под реальным масштабом времени мы здесь понимаем секунды-минуты. Обмен данными на дискетах в таком случае не пригоден принципиально, а архитектура файл-сервер потребует очень высоких скоростей обмена, а это может быть либо принципиально невозможно, либо очень дорого.
И, наконец, архитектура клиент-сервер необходима тогда, когда задача обеспечения целостности информации становится критической. Под критической, мы здесь понимаем ситуацию, в которой цена ошибки в данных может быть сопоставима со стоимостью создания системы клиент-сервер. Прежде всего, это актуально для финансовых служб предприятий.
На основе выше сказанного, можно сделать вывод, что архитектура клиент-сервер полностью отвечает поставленным требованиям и может быть использована при разработке.
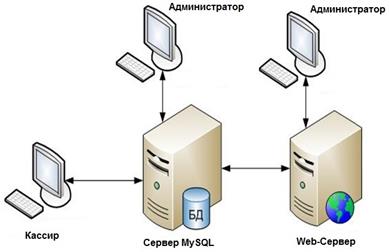
Рисунок 3.1 - Архитектура системы
3.2. Выбрать СУБД и описать ее:
3.2.1 Выбор СУБД.
При разработке информационной системы одним из самых важных этапов является выбор системы управления баз данных (СУБД).
Существует множество методик выбора СУБД. Простейшая из них основана на оценке того, насколько существующие системы удовлетворяют основным требованиям создаваемого проекта информационной системы. Более сложным и дорогостоящим вариантом является создание испытательного проекта на основе нескольких систем и последующий выбор наиболее подходящего из кандидатов. Но даже в этом случае необходимо ограничивать круг возможных систем, опираясь на некие критерии отбора.
Основные требования к СУБД, или, другими словами, критерии выбора, которые мы используем при анализе той или иной системы, могут отличаться в зависимости от целей, которые перед ней ставятся. Условно можно выделить несколько групп:
- Моделирование данных;
- Особенности архитектуры и функциональные возможности;
- Контроль работы системы;
- Особенности разработки приложений;
- Производительность;
- Надежность;
- Требования к рабочей среде;
- Смешанные критерии.
Рассмотрим каждую из этих групп в отдельности:
1. Моделирование данных.
• Используемая модель данных. Существует множество моделей данных; самые распространенные: иерархическая, сетевая, реляционная, объектно-реляционная и объектная. Вопрос об использовании той или иной модели должен решаться на начальном этапе проектирования информационной системы.
• Триггеры и хранимые процедуры. Триггер - программа базы данных, вызываемая всякий раз при вставке, изменении или удалении строки таблицы. Триггеры обеспечивают проверку любых изменений на корректность, прежде чем эти изменения будут приняты. Хранимая процедура – программа, которая хранится на сервере и может вызываться клиентом. Поскольку хранимые процедуры выполняются непосредственно на сервере базы данных, обеспечивается более высокое быстродействие, нежели при выполнении тех же операций средствами клиента БД. В различных программных продуктах для реализации триггеров и хранимых процедур используются различные инструменты.
• Средства поиска. Некоторые современные системы имеют встроенные дополнительные средства контекстного поиска.
• Предусмотренные типы данных. Здесь следует учесть два фактически независимых критерия: базовые или основные типы данных, заложенные в систему, и наличие возможности расширения типов. В то время, как отклонения базовых наборов типов данных у современных систем от некоего стандартного, обычно, не велики, механизмы расширения типов данных в системах того или иного производителя существенно различаются.
• Реализация языка запросов. Все современные системы совместимы со стандартным языком доступа к данным SQL-92, однако многие из них реализуют те или иные расширения данного стандарта.
2. Особенности архитектуры и функциональные возможности.
• Мобильность. Мобильность – это независимость системы от среды, в которой она работает. Средой в данном случае является как аппаратура, так и программное обеспечение (операционная система).
• Масштабируемость. При выборе СУБД необходимо учитывать, сможет ли данная система соответствовать росту информационной системы, причем рост может проявляться в увеличении числа пользователей, объема хранимых данных и объеме обрабатываемой информации.
• Распределенность. Основной причиной применения информационных систем на основе баз данных является стремление объединить взгляды на всю информацию организации. Самый простой и надежный подход - централизация хранения и обработки данных на одном сервере. К сожалению, это не всегда возможно и приходится применять распределенные базы данных. Различные системы имеют разные возможности управления распределенными базами данных.
• Сетевые возможности. Многие системы позволяют использовать широкий диапазон сетевых протоколов и служб для работы и администрирования.
3. Контроль работы системы
• Контроль использования памяти компьютера. Система может иметь возможность управления использованием как оперативной памяти, так и дискового пространства. Во втором случае это может выражаться, например, в сжатии баз данных, или удалении избыточных файлов.
• Автонастройка. Многие современные системы включают в себя возможности самоконфигурирования, которые, как правило, опираются на результаты работы сервисов самодиагностики производительности. Данная возможность позволяет выявить слабые места конфигурации системы и автоматически настроить ее на максимальную производительность.
4. Особенности разработки приложений.
Многие производители СУБД выпускают так же средства разработки приложений для своих систем. Как правило, эти средства позволяют наилучшим образом реализовать все возможности сервера, поэтому при анализе СУБД стоит рассмотреть так же и возможности средств разработки приложений.
• Средства проектирования. Некоторые системы имеют средства автоматического проектирования, как баз данных, так и прикладных программ. Средства проектирования различных производителей могут существенно различаться.
• Многоязыковая поддержка. Поддержка большого количества национальных языков расширяет область применения системы и приложений, построенных на ее основе.
• Возможности разработки Web-приложений. При разработке различных приложений зачастую возникает необходимость использовать возможности среды Internet. Средства разработки некоторых производителей имеют большой набор инструментов для построения приложений под Web.
• Поддерживаемые языки программирования. Широкий спектр используемых языков программирования повышает доступность системы для разработчиков, а также может существенно повлиять на быстродействие и функциональность создаваемых приложений.
5. Производительность.
• Рейтинг TPC (Transactions per Cent). Для тестирования производительности применяются различные средства, и существует множество тестовых рейтингов. Одним из самых популярных и объективных является TPC-анализ производительности систем. Фактически TPC анализ рассматривает композицию СУБД и аппаратуры, на которой эта СУБД работает. Показатель TPC – это отношение количества запросов обрабатываемых за некий промежуток времени к стоимости всей системы.
• Возможности параллельной архитектуры. Для обеспечения параллельной обработки данных существует, как минимум, два подхода: распараллеливание обработки последовательности запросов на несколько процессоров, либо использование нескольких компьютеров-клиентов, работающих с одной БД, которые объединяют в так называемый параллельный сервер.
• Возможности оптимизирования запросов. При использовании непроцедурных языков запросов, выполнение этих запросов может быть очень неоптимальным. Поэтому необходимо произвести процесс оптимизации запросов, т.е. выбрать такой способ выполнения запросов, когда по начальному представлению запроса путем его синтаксических и семантических преобразований вырабатывается процедурный план выполнения запроса, наиболее оптимальный при существующих в базе данных управляющих структурах.
6. Надежность.
Понятие надежности системы имеет много смыслов – это и сохранность информации независящая от любых сбоев, и безотказность работы системы в любых условиях, и обеспечение защиты данных от несанкционированного доступа.
• Восстановление после сбоев. При возникновении программных или аппаратных сбоев целостность, да и работоспособность всей системы может быть нарушена. От того, как эффективно спланирован механизм восстановления после сбоев, зависит жизнеспособность системы.
• Резервное копирование. В результате аппаратного сбоя может быть частично поврежден или выведен из строя носитель информации и тогда восстановление данных невозможно, если не было предусмотрено резервное копирование базы данных, или ее части. Резервное копирование спасает и в ситуациях, когда происходит логический сбой системы, например при ошибочном удалении таблиц. Существует множество механизмов резервирования данных (хранение одной или более копий всей базы данных, хранение копии ее части, копирование логической структуры и т.д.). Зачастую в систему закладывается возможность использования нескольких таких механизмов.
• Откат изменений. При выполнении транзакции применяется простое правило – либо транзакция выполняется полностью, либо не выполняется вообще. Это означает, что в случае сбоев, все результаты недоведенных до конца транзакций должны быть аннулированы. Механизм отката может иметь различное быстродействие и эффективность.
• Многоуровневая система защиты. Информационная система организации почти всегда включает в себя секретную информацию, поэтому для предотвращения несанкционированного доступа используется служба идентификации пользователей. Уровень защиты может быть различным. Кроме непосредственной идентификации пользователей при входе в систему может использоваться также механизм шифрования данных при передаче по линиям связи.
7. Требования к рабочей среде.
• Поддерживаемые аппаратные платформы.
• Минимальные требования к оборудованию.
• Максимальный размер адресуемой памяти. Поскольку почти все современные системы используют свою файловую систему, немаловажным фактором является то, какой максимальный объем физической памяти они могут использовать.
• Операционные системы, под управлением которых способна работать СУБД.
8. Смешанные критерии.
• Качество и полнота документации. К сожалению, не все системы имеют полную и подробную документацию.
• Локализованность. Возможность использования национальных языков не во всех системах реализована полностью.
• Модель формирования стоимости. Как правило, производители СУБД используют определенные модели формирования стоимости. Например, стоимость одного и того же продукта может существенно изменяться в зависимости от того, сколько пользователей будет с ним работать.
• Стабильность производителя.
• Распространенность СУБД.
Этот перечень, безусловно, не является полным и не претендует на жесткую классификацию требований, предъявляемых к СУБД каждой конкретной информационной системой. В каком-то случае может оказаться, что часть из них просто не являются важными. В другом окажется, что существуют и другие, не перечисленные здесь критерии, и именно они определят выбор СУБД.
3.2.2. Описание СУБД. Здесь следует выделить основные определения, основные достоинства и критерии выбора данной СУБД.
Пример:
В данном дипломном проекте при разработке информационной системы использовалась клиент-серверная СУБД MySQL . Основанием для выбора послужил ряд положительных сторон MySQL:
- многопоточность, поддержка нескольких одновременных запросов;
- оптимизация связей с присоединением многих данных за один проход;
- записи фиксированной и переменной длины;
- ODBC драйвер в комплекте с исходником;
- поддержка ключевых полей и специальных полей в операторе;
- легкость управления таблицей, включая добавление и удаление ключей и полей;
- поддержка чисел длинной от 1 до 4 байт (ints, float, double, fixed), строк переменной длины и меток времени;
- до 16 ключей в таблице. Каждый ключ может иметь до 15 полей;
- псевдонимы применимы как к таблицам, так и к отдельным колонкам в таблице;
- все поля имеют значение по умолчанию. Можно использовать на любом подмножестве полей;
- все операции работы со строками не обращают внимания на регистр символов в обрабатываемых строках;
- гибкая система привилегий и паролей;
- гибкая поддержка форматов чисел, строк переменной длины и меток времени;
- интерфейс с языками C и Perl, PHP;
- основанная на потоках, быстрая система памяти;
- быстрая работа, масштабируемость;
- совместимость с ANSI SQL;
- хорошая поддержка со стороны провайдеров услуг хостинга;
- утилита проверки и ремонта таблицы (isamchk);
- быстрая поддержка транзакций через механизм InnoDB;
- является продуктом класса Open Source (открытые исходные тексты), который можно получить бесплатно.
СУБД MySQL использует традиционную архитектуру клиент-сервер. Программа сервера базы данных расположена на компьютере, где хранится база данных. Она ждет запросы клиентов, поступающие по сети, и обеспечивает доступ к содержимому базы данных для извлечения информации, запрашиваемой клиентами. Клиентская программа осуществляет подключение к серверу и передает запросы ему. В общем случае клиент и сервер MySQL находятся на разных компьютерах, позволяя подключаться к серверу MySQL с любого компьютера, находящегося в сети. Но это совсем не значит, что любой человек может подключиться к вашей базе данных. В СУБД MySQL есть собственная система защиты, которая позволяет настроить доступ к базе данных только тем, кто имеет на это право, а также разграничить права доступа, разрешая только те операции, которые необходимы данному пользователю.
MySQL портирована на большое количество платформ: AIX , BSDi , FreeBSD , HP - UX , GNU / Linux , Mac OS X , NetBSD , OpenBSD , OS /2 Warp , SGI IRIX , Solaris , SunOS , SCO Open Server , SCO UnixWare , Tru 64, Windows 95, Windows 98, Windows NT , Windows 2000, Windows XP , Windows Server 2003, WinCE , Windows Vista и Windows 7.
MySQL имеет API для языков Delphi , C , C ++, Эйфель, Java , Лисп, Perl , PHP , Python , Ruby , Smalltalk и Tcl , библиотеки для языков платформы . NET , а также обеспечивает поддержку для ODBC посредством ODBC -драйвера MyODBC .
Таким образом, СУБД MySQL оптимально подходит для нашей разрабатываемой информационной системы.
3.3. Разработать структуру баз данных:
3.3.1. Основные сущности предметной области. Для описания основных сущностей следует построить таблицу (см. таблицу 3.1), она должна содержать 3 столбца: 1 столбец «Объект» - указать название таблицы (сущности); 2 столбец «Атрибуты» - указать атрибуты таблицы (сущности); 3 столбец «Описание» - сделать описание атрибута.
Далее следует описать структуру каждой сущности, для этого строим таблицу для каждой сущности (см. таблицу 3.2). Таблицы должны содержать 3 столбца: 1 столбец «Имя поля» - указать имя атрибута описываемой сущности; 2 столбец «Тип данных» - указать тип данных атрибута; 3 столбец «Размер поля» - описать размер поля атрибута и указать ключевой атрибут в каждой сущности.
Пример:
Таблица 3.1 – Основные сущности предметной области
| Объект | Атрибут | Описание |
| Таблица « Gruppa_tovara » | Kod_grupi | Код группы |
| Nazvanie_grupi | Название группы | |
| Таблица « Tovar » | Kod_tovara | Код товара |
| Naimenovanie | Название товара | |
| Ed_izmerenia | Единица измерения товара | |
| Cena_zakupki | Цена закупочная на товар | |
| Cena_realizacii | Цена реализации товара | |
| Kod_grupi | Код группы, в которую он входит | |
| Таблица « Prodaja_tovara » | Kod_cheka | Код выбитого чека |
| Kod_tovara | Код товара | |
| Kol-vo_prod_tov | Количество проданного товара | |
| Cena_real_tov | Цена реализации товара | |
| Dohod | Доход от реализации товара | |
| Data | Дата выбитого чека | |
| Vremj | Время выбитого чека | |
| Kod_prodavca | Код продавца выбившего чек | |
| Kod_operacii | Код операции | |
| Таблица « Prodavec » | Kod_prodavca | Индивидуальный код продавца |
| Familia | Фамилия продавца | |
| Imj | Имя продавца | |
| Otchestvo | Отчество продавца | |
| Telefon | Контактный телефон продавца | |
| Adres_propiski | Адрес прописки | |
| Таблица « PrihodRashod » | Kod_operacii | Код операции |
| Data | Дата | |
| Vremj | Время | |
| Summa | Сумма операции | |
| Tip_operacii | Тип операции | |
| Таблица « Sklad » | Kod_operacii | Код операции |
| Cena_zakupki | Закупочная цена товара | |
| Kolichestvo_tovara | Количество товара | |
| Summa | Сумма товара | |
| Kod_postavki | Код поставки товара | |
| Kod_tovara | Код поставляемого товара | |
| Таблица « Postavka_tovara » | Kod_postavki | Код поставки товара |
| Kod_postavchika | Код поставщика данного товара | |
| Kol-vo_post_tov | Количество поставленного товара | |
| Cena_post_tov | Цена поставки товара | |
| Summa | Сумма товара | |
| Kod_menegera | Код менеджера поставившего данный товар | |
| Kod_tovara | Код поставляемого товара | |
| Таблица « Postavchiki » | Kod_postavchika | Индивидуальный код фирмы-поставщика |
| Name | Название фирмы поставщика | |
| Telefon | Контактный телефон фирмы-поставщика | |
| Ured_adres | Юридический адрес фирмы-поставщика | |
| Таблица « Meneger_postavok » | Kod_menegera | Индивидуальный код менеджера поставляющего товар от конкретной фирмы |
| Familia | Фамилия менеджера | |
| Imj | Имя менеджера | |
| Otchestvo | Отчество менеджера | |
| Telefon | Контактный телефон менеджера |
Таблица 3.2 - Структура таблицы «Gruppa_tovara»
| Имя поля | Тип данных | Размер поля |
| Kod_grupi | Числовой | Длинное целое (ключ) |
| Nazvanie_grupi | Текстовый | 20 0 |
3.3.2. Модель «Сущность-связь». Для описания модели следует построить таблицу (см. таблицу 3.3), которая должна содержать 3 столбца: 1 столбец «Исходный объект» - следует указать исходную сущность (объект); 2 столбец «Конечный объект» - следует указать конечную сущность (объект); 3 столбец «Тип связи» - следует указать тип связи между сущностями (объектами).
Пример:
Таблица 3.3 - Модель «Сущность-связь»
| Исходный объект | Конечный объект | Тип связи |
| Gruppa _ tovara | Tovar | 1: M |
| Tovar | Sklad | 1 : M |
| Prodavec | Prodaja_tovara | 1 : M |
| PrihodRashod | Sklad | M : 1 |
| Prodaja_tovara | PrihodRashod | 1 :М |
| Postavka_tovara | PrihodRashod | 1 :М |
| Postavchiki | Postavka_tovara | 1 :М |
| Meneger_postavok | Postavka_tovara | 1 :М |
3.4. Реализация базы данных. Построить логическую и физическую модель базы данных.
Пример:
По результатам анализа выше представленных параметров была предложена клиент-серверная база данных, логическая и физическая модели которой изображены на рисунках 3.2 и 3.3 соответственно.
Для разработки базы данных использовалась программа ERwin. С помощью ERwin можно выполнить проектирование на логическом и физическом уровне, а также создать базу данных на сервере.
На логическом уровне проектирование выполняется путем выделения сущностей, атрибутов сущностей и взаимосвязей между сущностями. Логическая модель независима от особенностей физической реализации объекта. Логическая модель данных является источником информации для физического проектирования.
Логическая модель базы данных информационной системы торгового предприятия представлена на рисунке 3.2.
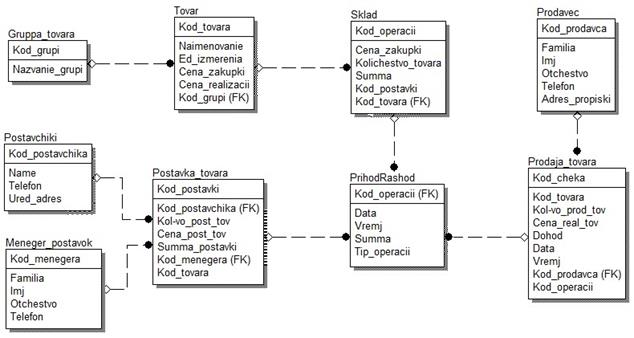
Рисунок 3.2 - Логическая модель БД информационной системы торгового предприятия
Физическое проектирование базы данных предусматривает принятие решения о способах реализации модели на основе конкретной СУБД. ERwin автоматически создает имена таблиц и столбцов на основе имен соответствующих сущностей и атрибутов, учитывая максимальную длину имени и другие синтаксические ограничения, накладываемые СУБД MySQL . Тип данных каждого столбца при переходе на физический уровень соответствуют типу данных, допустимому в СУБД MySQL . Между фазами физического и логического проектирования всегда имеется обратная связь, поскольку решения, принятые на этапе физического проектирования, могут потребовать некоторого пересмотра логической модели данных.
Физическая модель содержит девять таблиц. Столбец, расположенный в верхней части изображения таблицы и отделенный горизонтальной чертой, является первичным ключом. Рядом с именем каждого столбца указывается тип данных этого столбца.
Физическая модель базы данных информационной системы торгового предприятия представлена на рисунке 3.3.

Рисунок 3.3 - Физическая модель БД информационной системы торгового предприятия
Дата: 2019-04-23, просмотров: 1228.