Компьютер может обрабатывать информацию, представленную только в цифровой форме, т. е. в виде последовательности цифр (0 и 1). Текст, звук, изображение и т.д. при обработке в компьютере преобразуются в числовую форму и представляются в виде двоичных кодов.
Текстовое сообщение состоит из последовательности СИМВОЛОВ: символов-букв, символов-цифр, символов-знаков. Из символов-букв образуются слова, которые в свою очередь, вместе с символами-цифрами и символами-знаками образуют предложения, в результате чего и создается текстовое сообщение.
Исторически сложилось так, что первые разработчики компьютеров были носителями английского языка. Для человека, заинтересованного в использовании лишь одного естественного алфавита (скажем, английского) требуется отображать примерно 100 символов: 52 буквы = 26 х 2 (прописные и строчные), 10 цифр, знаки препинания (. , : ! " ; ? – … ), разделительные знаки (три вида скобок, пробел и т.д.), знаки арифметических операций (+, -, *, /, ^), специальные символы (№ % _ # $, ^, &, >, <, |, \). Получается чуть больше 100 символов. Такой сравнительно небольшой базовый набор символов можно закодировать набором двоичных чисел от 0 до 27 (всего 128 позиций) при помощи таблиц соответствия этого набора машинным кодам (фактически, двоичным числам), что и было сделано. Например, пробел представляется как 100000 (в 2-ичной с/с), 32 (в 10-ичной с/с) или 20 (в 16-ричной с/с). Таблица соответствия получила название ASCII (American Standard Code for Information Interchange, произносим «аскей»). Кодировка ASCII была заложена при разработке компьютера IBM PC и стала одной из распространенных систем кодирования (стала стандартом).
Как правило, код символа ASCII хранится в памяти компьютера в одном байте и может быть представлен двумя шестнадцатеричными цифрами (две тетрады по 4 бита). Будем представлять байт состоящим из двух полубайтов:
!__!__!__!__ ½ __!__!__!__!
старший младший
полубайт полубайт
Однако в рамках ASCII создание многоязычных документов являлось очень проблематичной, а в большинстве случаев, и совершенно невыполнимой задачей. Базового набора кодов стало быстро не хватать, что потребовало расширения таблицы ASCII. В результате возникла новая таблица кодировок, получившая название «расширенная таблица ASCII», число знакомест в которой возросло до 28. При использовании для кодирования одного байта (8 битов) получим 28=256 различных комбинаций из 0 и 1, т.е. 256 возможных представлений символов (коды символов будут принимать значения от 0 до 255).
Например:
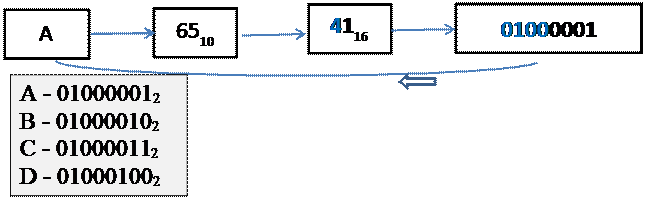
Система ASCII стала международной (общепринятой) только в первой половине кодов от 0 до 127 (шестнадцатеричные коды 00 – 7F, их двоичные эквиваленты 00000000 – 01111111). Вторая половина кодов от 128 до 255 (шестнадцатеричные коды 80 – FF, их двоичные эквиваленты 10000000 – 11111111) – расширение стандарта ASCII – включала символы западноевропейских алфавитов (немецкого, французского и т.д.), некоторые греческие буквы, специальные символы. В расширении стандарта, кроме букв национального алфавита, кодируются и символы псевдографики[1].
В странах, для которых нужных символов в кодировке IBM не оказалось, программисты стали создавать резидентные программы и драйверы, позволяющие вводить необходимые символы с клавиатуры и загружать измененную кодировку в знакогенератор компьютера. Для кодировки русских букв (кириллицы) некоторое время применялось много разных таблиц кодировок, что создавало неудобства. В результате стали применять «модифицированную альтернативную кодировку ГОСТа». В ней русские буквы расположены на позициях редко используемых символов национальных алфавитов и греческих букв кодировки IBM (это позволяет использовать DOS-программы без изменений).
Для операционной системы Windows фирма Microsoft разработала кодовую таблицу, называемую ANSI-кодировкой (American National Standard Institute). Для русскоязычных пользователей употребляется модифицированная «русская» версия ANSI-таблицы. Таким образом, при использовании программ для DOS и Windows пользователь вынужден работать с двумя различными кодировками символов. В терминологии Windows первая кодировка называется OEM-кодировкой, вторая – ANSI-кодировкой. Windows содержит стандартные функции для перекодировки из OEM в ANSI и обратно. Многие Windows-программы автоматически выполняют это преобразование.
В консольном режиме примеряется ОЕМ-кодировка, в которой для представления символов со значениями кодов 128-255 используется кодовая таблица 866 – MS DOS.
В программах, исполняемых и создаваемых под управлением MS Windows, применяется для тех же символов кодовая таблица 1251 (ANSI -кодировка). Поэтому текст с русскими буквами (их коды находятся в диапазоне 128-255), подготовленный в редакторе MS Windows, нельзя правильно отобразить в консольном окне – нужна перекодировка из MS Windows в MS DOS и обратно.
Дата: 2019-05-28, просмотров: 374.