1. ГЕОМЕТРИЧЕСКИЕ МЕТОДЫ.
В основе геометрических методов лежит понятие меры близости объектов в n-мерном признаковом пространстве описаний. Центральной задачей при создании систем распознавания является выбор типа меры близости.
Меру близости необходимо выбирать таким образом, чтобы она, с одной стороны, отвечала представлению разработчика о близости объектов рассматриваемых классов, а с другой - позволяла бы упростить процедуры синтеза оптимальных частных алгоритмов.
Сущность меры близости применительно к рассматриваемому классу задач покажем на примере двух классов в 2-х мерном пространстве описаний.
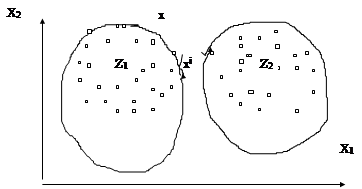 |
Интерпретация рисунка приводит к естественному выводу о предпочтительности отнесения объекта Х к первому классу. В то же время классификация объекта Хi вызывает затруднения и необходимы расчеты.
Очевидно, что классификация образов с помощью функции расстояния эффективен только в тех случаях, когда классы образов обнаруживают тенденцию к кластеризации (группированию).
Поскольку близость классифицируемого образа к образам класса будет использоваться в качестве критерия для его классификации, назовем такой подход классификацией образов по критерию минимума расстояния.
Классы могут быть представлены путем перечисления членов класса (как на рисунку: точки в кластерах) или с помощью эталонных образов (например, центральными объектами z1 и z2).
Заметим также, что в рассматриваемом классе задач описания объектов являются векторными.
Рассмотрим М классов. Пусть эти классы допускают их представление с помощью эталонных образов Z1,Z2, . . .,Zm. Евклидово расстояние между произвольным вектором образа Х и i-м эталоном определяется следующим выражением:
_____________
Di = || X - Zi || = √( X - Zi )/ ( X - Zi ) (1)
где || Х || - Евклидова норма;

 х1
х1
х2
Х = х3 - вектор образа распознаваемого объекта;
:
хn

 z1
z1
Z = : - вектор образа эталона класса;
zn
n 1
|| Х || = [Σ Xj2 ]2
j=1
X / = ( x1 ,x2 , . . .,xn) - транспонированный вектор;
X / Z - скалярное произведение;
n
X/ Z = Σ Xj/ Zj
j = 1
Классификатор, построенный по принципу минимума расстояния, вычисляет расстояние, отделяющее классифицируемый образ Х от эталона каждого класса, и зачисляет этот образ в класс,, оказавшийся ближайшим к нему. Другими словами, образ Х приписывается к классу Wi , если условие Di < Dj для всех j ¹ i .
Путем несложных преобразований исходно формуле (1) можно придать более удобный для вычислений вид.
di (X) = X/ Zi - 1/2 Zi/ Zi, i = 1,2,...,M,
где образ Х относится к классу Wi, если условие di (X) > dj (X) справедливо для всех j ¹ i.
Пример:
z1 . . . z5
z1/ = ( 1 2 6 3 1 ) z2/ = ( 6 4 3 2 1 )
x/ = ( 1 3 5 2 1 )
 | |||
 | |||
d1(x) = ( 1 3 5 2 1 ) -1/2 ( 1 2 6 3 1 ) = ( 1+6+30+6+1 ) - 1/2 ( 1+4+36+9+1 ) =
= 44 - 1/2 51 = 18.5;
d2(x) = (6+12+15+4+1) - 1/2 (36+16+9+4+1) = 38 - 1/2 66 =5
d1(x) > d2(x) , поэтому образ х принадлежит первому классу.
Меры сходства не исчерпываются расстояниями. В качестве примера можно привести не метрическую функцию сходства
z x /
s ( x , z ) = -----------,
|| x || || z ||
представляющую собой косинус угла, образованного векторами X и Z. Этой мерой целесообразно пользоваться, когда кластеры располагаются вдоль главных осей или растянуты вдоль лучей, направленных от начала координат.
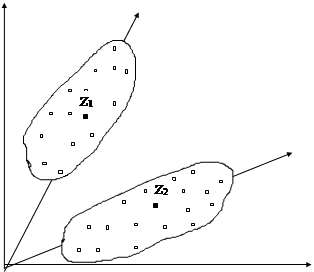 |
Однако использование данной меры связано с определенными ограничениями: достаточное отстояние кластеров друг от друга и от начала координат.
Для двоичных признаков (признаки принимают значения либо `` 0`` либо ``1``) может использоваться мера Танимото
z x /
s ( x , z ) = ------------------- .
x / x + z / z - x / z
Перечисленные меры близости не учитывают корреляционные связи между признаками. Устранить этот недостаток позволяет критерий известный по названием расстояние Махаланобиса, определяемое для образов x и m как
d = ( x - m ) / с -1 ( x - m ),
где c - ковариационная матрица совокупности образов, m - вектор средних значений, а х - представляет образ с переменными характеристиками(классифицируемый образ).
2. ЛОГИЧЕСКИЕ МЕТОДЫ
Объекты классов и реализация представляются в виде булевых функций:
Ωi = fi (x1, . . . , xn) , i = 1, . . . ,k
и G = (x1 , . . . , xn).
Заданы правила использования булевых функций при распознавании:
W = (w1 , . . . , wn).
Процедура распознавания состоит в определении неизвестной функции
F(Ω1 , . . . ,Ωk),удовлетворяющей уравнению
_
G (x1,. . . , xn ) + F(Ω1 , . . . , Ωk)= I, (1)
Где F - совокупность булевых функций априорного описания.
 Пример:
Пример:
F(Ω1) = x1x2+x3 или 110 + 001
Ωi = f1i + f2i
F(Ω2) = x1x3+x2 или 101 + 010
Правило классификации:
_ _
G ЄΩi, если G + f1 = I или G + f2 = I .
_
Пусть G = x1 x2 или 110 ( G = 001).
Найти F такую, чтобы выполнялось равенство 1.
 _
_
G + f1 = 001 + 110 = 111 = I
Ω1 : _
G + f2 = 001 + 001 = 001 ¹ I
_
G + f1 = 001 + 101 = 101 ¹ I
Ω:2: _
G + f2 = 001 + 010 = 011 ¹ I
Вывод: G принадлежит Ω1.
3. СТРУКТУРНЫЕ МЕТОДЫ
При структурном подходе к распознаванию признаками служат образы, называемые непроизводными элементами, а также отношения между ними, характеризующие структуру образа.
Для описания образов через непроизводные элементы и их отношения специальный язык образов.
Правила такого языка, позволяющие составлять образы из непроизводных элементов, называется порождающей грамматикой.
Пример:
Заданы непроизводные элементы:


 в d
в d
а с
и правило объединения: головная часть присоединяется к хвостовой по прямым углом и записывается, например, ав, т.е.
в
 а
а
 Фигура будет иметь следующую грамматическую структуру: авсd.
Фигура будет иметь следующую грамматическую структуру: авсd.
В основе процедур(алгоритмов) распознавания лежат правила грамматического разбора.
4. ВЕРОЯТНОСТНЫЕ МЕТОДЫ
Статистический подход основывается на математических правилах классификации, которые формулируются и выводятся в терминах математической статистики.
Пример. Пусть совокупность объектов подразделена на два класса -Ω1 и Ω2, а для характеристики объектов используется один признак х. Известны описания классов - условные плотности распределения вероятностей значений признака объектов 1-го и 2-го классов, т.е. функции f1(x) и f2(x), а также априорные вероятности появления объектов 1-го и 2-го классов: р(Ω1) и р(Ω2).
В результате эксперимента определено значение признака распознаваемого объекта, равное х0.
Определить, к какому классу относится объект ?
Обозначим через х0 некоторое пока не определенное значение признака х и условимся о следующем правиле принятия решений:
n если измеренное значение признака распознаваемого объекта х0>х0, то объект будем относить ко второму классу;
n если х0< х0 - к первому.
|

  
|





Если объект относится к первому классу, а его считают объектом второго класса, то совершена ошибка, которая называется ошибкой 1-го рода.
Условная вероятность ошибки 1-го рода равна
∞
Q1 = ʃ f1(х) d(x)
x0
Если объект относится ко второму классу, а его считают объектом 1-го класса, то совершена ошибка, которую называют ошибкой второго рада.
Условная вероятность ошибки 2-го рада равна
x0
Q2 = ʃ f2(x)
-∞
Для определения значения х0 введем понятие платежной матрицы
 = || с || = с11 с12 ,
= || с || = с11 с12 ,
с21 с22
где с11 и с22 - потери, связанные с правильными решениями, а с12 и с21 - потери, связанные с совершением ошибок первого и второго рода соответственно.
Значение х0 определяется в зависимости от значения коэффициента правдоподобия
l (x) = f2(x)/f1(x).
Значению х0 соответствует критическое (пороговое) значение l (x) = l0
р(Ω1)(c12-c11)
 l0 =
l0 =
p(Ω2)(c21-c22)
Значение х0 позволяет оптимальным образом (в смысле минимума среднего риска) разделить признаковое пространство на две области: R1 и R2.
Область R1 состоит из значений х ≤ х0, для которых l(x) ≤ l0 а R2 - из значений х > х0, для которых l(x) > l0
Поэтому решение об отнесении объекта к первому классу следует принимать, если значение коэффициента правдоподобия меньше его критического значения, и ко второму классу, если больше.
На практике при построении систем распознавания возможны ситуации, когда известны:
а) f1(x), f2(x), р(Ω1), р(Ω2) и ||с|
б) f1(x), f2(x) и платежная матрица, но не известны р(Ω1), р(Ω2).
в) f1(x), f2(x), но не известны ни р(Ω1), р(Ω2) ни платежная матрица.
В каждой из этих ситуаций применяются свои критерии распознавания, а именно - критерий Байеса, минимаксный критерий, критерий Неймана-Пирсона.
Признаковая информация представляется в виде таблиц распознавания вида
| Классы | Градации признака хi | |||
| хi1 | xi2 | ... | xim | |
| А1 | 0.6 | 0.5 | ... | 0.1 |
| А2 | 0.7 | 0.4 | ... | 0.2 |
| ... | ... | ... | ... | |
| An | 0.1 | 0.2 | ... | 0.1 |
Наиболее часто используется критерий Байеса, который выражается формулой
p ( Aj ) p ( bk / Aj )
 p ( Aj / bk ) =
p ( Aj / bk ) =
M
S p(Ai) p(bk/Ai)
i=1
где
p(Aj/bk) - вероятность гипотезы о принадлежности реализации bк к j-му классу.
Bk = { x1l, . . . , xnk, . . . , xNp},
хi - признаки классов, l,k,p - градации признаков,
p(Aj) - априорная вероятность проявления j-го класса(Aj);
p(bk/Aj) - условная вероятность проявления признаков реализации bk у класса Aj.
M - количество классов.
P(Aj) = mj / F ( mj - количество объектов j-го класса, F - суммарное количество объектов всех классов).
N
P(bk/Aj) = П p(xil/Aj), где p(xil/Aj) - вероятность проявления l-ой градации i-го
i=1
признака у класса Aj.
N - количество признаков в рабочем словаре.
В результате вычислений по формуле Байеса получим значения p(Aj/bk) для каждого класса.
Решение о принадлежности реализации к конкретному классу принимается по максимуму вычисленной вероятности.
ЭКСПЕРТНЫЕ СИСТЕМЫ
КОНЦЕПЦИЯ ЗНАНИЙ
При изучении интеллектуальных систем традиционно возникает вопрос, – что же такое знания и чем они отличаются от обычных данных, десятилетиями обрабатываемых ЭВМ.
Можно предложить несколько рабочих определений, в рамках которых это становится очевидным.
Данные – это отдельные факты, характеризующие объекты, процессы и явления в предметной области, а также их свойства. Данные интерпретируются специальными программами. Они пассивны. Нет содержательной информации.
При обработке на ЭАМ данные трансформируются, условно проходя следующие этапы:
- данные как результат измерений и наблюдений;
- данные на материальных носителях информации (таблицы, протоколы, справочники);
- модели (структуры) данных в виде диаграмм, графиков, функций;
- данные в компьютере на языке описания данных;
- базы данных на машинных носителях.
Знания связаны с данными, основываются на них, но представляют собой результат мыслительной деятельности человека, обобщают его опыт, приобретенный в ходе выполнения какой-либо практической деятельности. Они получаются эмпирическим путем.
Знания – это выявленные закономерности предметной области (принципы, связи, законы), позволяющие решать задачи в этой области. Они могут быть активны, т.е. определенные действия при выполнении соответствующих условий.
В отличие от данных знания обладают следующими свойствами:
· внутренней интерпретируемостью – вместе с информацией в БЗ представлены информационные структуры, позволяющие не только хранить знания, но и использовать их;
· структурированностью – выполняется декомпозиция сложных объектов на более простые и установление связей между ними;
· связанностью – отражаются закономерности относительно фактов, процессов, явлений и причинно-следственные отношения между ними;
· активностью –знания предполагают целенаправленное использование информации, способность управлять информационными процессами по решению определенных задач.
Все эти свойства знаний в конечном итоге должны обеспечить возможность СИИ моделировать рассуждения человека при решении прикладных задач – со знаниями тесно связано понятие процедуры получения решений задач (стратегии обработки знаний). В системах обработки знаний такую процедуру называют механизмом вывода, логическим выводом или машиной вывода. Принципы построения механизма вывода в СИИ определяются способом представления знаний и видом моделируемых рассуждений.
При обработке на ЭВМ знания трансформируются аналогично данным:
- знания в памяти человека как результат мышления;
- материальные носители знаний (учебники, методические пособия);_
- поле знаний - условное описание основных объектов предметной области, их атрибутов и закономерностей, их связывающих;
- знания, описанные на языках представления знаний (продукционные языки, семантические сети, фреймы и т.д.);
- базы знаний.
Часто используются такие определения знаний:
Знания – это хорошо структурированные данные, и данные о данных, или метаданные.
Существует множество способов определять понятия. Один из широко применяемых способов основан на идее интенсионала.
Интенсионал понятия – это определение через понятие более высокого уровня абстракции с указанием специфических свойств. Этот способ определяет знания.
Другой способ определяет понятие через перечисление понятий более низкого уровня иерархии или фактов, относящихся к определяемому. Это есть определение через данные, или экстенсионал, понятия.
Пример: интенсионал: курсант- это учащийся военного училища.
Экстенсионал: курсант- это Иванов, Петров….
Для хранения данных используются базы данных (для них характерны большой объем и относительно небольшая удельная стоимость информации), для хранения знаний – базы знаний – основа любой интеллектуальной системы.
Знания могут быть классифицированы по следующим категориям:
- поверхностные – знания о видимых взаимосвязях между отдельными событиями и фактами в предметной области;
- глубинные – абстракции, аналогии, схемы, отображающие структуру и процессы в предметной области.
Знания, на которые опирается человек, решая те или иную задачу, существенно разнородны.
Это прежде всего:
· понятийные знания (набор понятий и их взаимосвязи);
· конструктивные знания (знания о структуре и взамодествии частей различных объектов);
· процедурные знания (методы, алгоритмы и программы решения различных задач);
· фактографические знания (количественные и качественные характеристики объектов, явлений и их элементов).
Современные ЭС работают в основном с поверхностными знаниями, т. к. в настоящее время нет адекватных моделей, позволяющих работать с глубинными знаниями.
Кроме того, знания можно разделить на процедурные и декларативные. Исторически первичными были процедурные знания, т.е. знания, ”растворенные” в алгоритмах. Они управляли данными. Для их изменения требовалось изменять программы. Однако с развитием ИИ приоритет данных постепенно изменялся, и все большая часть знаний сосредотачивалась в структурах данных (таблицы, списки, абстрактные типы данных), т.е. увеличивалась роль декларативных знаний.
Сегодня знания приобрели чисто декларативную форму, т.е. знаниями считаются предложения, записанные на языках представления знаний, приближенных к естественному и понятных неспециалистам.
Существуют десятки моделей (или языков) представления знаний для различных предметных областей. Большинство из них м.б. сведено к следующим классам:
- продукционные;
- семантические сети;
- фреймы;
- формальные логические модели.
ПОЛЕ ЗНАНИЙ
Одна из наиболее творческих процедур при построении ЭС – процедура концептуального анализа полученных знаний или структурирование.
Структурирование – это процесс создания полуформализованного описания предметной области. Такое полуформализованное описание называется полем знаний. Обычно оно создается в графической форме.
Поле знаний Рz можно описать следующим образом:
Pz=<Sk,Sf>,
где Sk - концептуальная структура предметной области;
Sf – функциональная структура предметной области.
Концептуальная структура, или модель предметной области, служит для описания ее объектов и отношений между ними, т.е. можно сказать, что концептуальная модель Sk представляет собой следующее:
Sk=<A,R>,
где А – множество объектов предметной области;
R – множество отношений, связывающих объекты.
Множество отношений представляет собой связи между объектами. При помощи этих отношений инженер по знаниям фиксирует концептуальное устройство предметной области, иерархию понятий, свойство и структуру объектов. Разработка концептуальной структуры имеет самостоятельное значение, не зависимое от конечной цели – разработки экспертных систем. Эта структура может служить для целей обучения, повышения квалификации, для прогнозирования, объяснения, реструктурирования и т.п.
Дата: 2019-05-28, просмотров: 378.