База данных (БД) представляет собой совокупность данных различного характера, отображающих состояние объектов и их отношения в рассматриваемой конкретной предметной области. Под предметной областью понимается множество объектов, которые должны быть представлены для использования в САПР. Базы данных обеспечивают хранение информации, а также удобный и быстрый доступ к ней. Информация в БД должна быть непротиворечивой, целостной, обладать минимальной избыточностью и быть защищенной от несанкционированного доступа.
Сведения, хранимые в базах данных САПР РЭС, можно условно разделить на две основные группы: архив БД и рабочий массив БД.
В архиве находятся такие сведения, которые редко изменяются, например, справочные данные о типах и параметрах унифицированных деталей, приборов и элементов (транзисторов, резисторов, конденсаторов и т. п.). Кроме того, в архиве хранятся данные о типовых проектных решениях и технологических процессах, материалах, правилах и ограничениях, регламентируемых ГОСТами и нормативами, об условных графических изображениях на чертежах схем и т.д.
Рабочий массив БД включает результаты предыдущих этапов проектирования конкретных РЭС, предназначенные для использования на последующих этапах (технические описания, спецификации и другие документы, содержащие информацию о проекте). Особенностью этой части базы данных является ее более частое обновление, чем архива.
Система управления базой данных (СУБД) представляет собой совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД. По характеру применения выделяют персональные (локальные) и многопользовательские (сетевые или удаленные) СУБД.
Персональные СУБД предоставляют возможность создания локальных БД, т. е. работающих на одном компьютере. К персональным СУБД относятся Paradox, dBase, FoxPro, Access и др.
Непременной частью многопользовательских СУБД является сеть, обеспечивающая аппаратную связь ЭВМ и делающая возможной корпоративную работу множества пользователей с одними и теми же данными. Наиболее известными многопользовательскими СУБД являются Oracle, Informix, SyBase, MicrosoftSQLServer, InterBase. Набор прикладных программ (приложений БД) служит для обработки данных, содержащихся в БД. Необходимо заметить, что иногда термином «база данных» обозначают не только саму БД, но и приложения, обрабатывающие ее данные. Так, например, в системе сквозного проектирования печатных плат DeltaDesign вся информация о радиоэлектронных компонентах хранится в специальной БД — библиотеке компонентов РЭС, для управления которой используется специальный программный модуль (менеджер библиотек). Расположение БД в значительной степени влияет на характер прикладной программы, обрабатывающей содержащиеся в этой базе данные.
Различают одноуровневые (однозвенные), двухуровневые (двухзвенные) и многоуровневые (многозвенные) приложения БД.
Одноуровневыми называют приложения, использующие локальные БД.
К двухуровневым относят приложения, использующие удаленные базы данных и содержащие так называемые клиентскую и серверную части.
Многоуровневые (обычно трехуровневые) приложения БД содержат клиентскую часть, сервер приложений и сервер базы данных. В зависимости от характера СУБД (локальная или сетевая) и приложения БД (одно-, двух- или многоуровневых) различают несколько вариантов структуры информационного обеспечения САПР [1]: • локальная структура; • структура «файл-сервер»; • двухуровневая структура «клиент-сервер»; • трехуровневая структура «клиент-сервер».
Особенностью локальных БД является расположение их на одном компьютере с использующими их программами. В этом случаеговорят, что информационная система имеет локальную структуру (рис. 3.3).
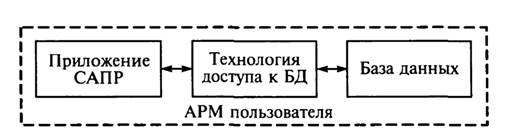
Рис. 3.3. Локальная структура баз данных
Работа с БД происходит, как правило, в однопользовательском режиме. Для управления совместным доступом к БД необходимы специальные средства контроля и защиты. Каждая разновидность БД осуществляет подобный контроль своими способами и обычно имеет встроенные средства разграничения доступа.
При использовании локальной БД в сети можно организовать многопользовательский доступ. В этом случае файлы БД и предназначенное для работы с ней программное обеспечение располагаются на сервере сети. Каждый пользователь запускает со своего компьютера это серверное приложение. Такой сетевой вариант использования локальной БД соответствует структуре «файл- сервер». Приложение для работы с БД при использовании структуры «файл-сервер» также может быть записано на каждый компьютер пользователя, при этом приложению должно быть известно местонахождение общей БД, как показано на рис. 3.4.
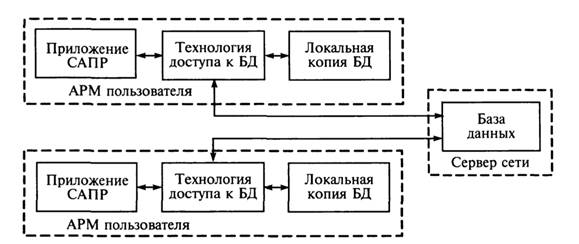
3.4. Структура «файл-сервер»
При работе с данными на каждом пользовательском компьютере сети используется локальная копия БД, данные в которой периодически обновляются из БД на сервере. Структура «файл-сервер» обычно применяется в сетях с небольшим числом пользователей, для ее реализации используют персональные СУБД, например Paradox или dBase. Достоинствами этой структуры являются простота реализации, а также то, что приложение фактически разрабатывается в расчете на одного пользователя и не зависит от компьютера сети, на который оно устанавливается. Тем не менее структуре «файл-сервер» присущ и ряд значительных недостатков, наиболее существенными из которых являются следующие. Во-первых, если пользователю необходимо несколько записей из таблицы БД, с сервера по сети пересылается вся таблица. В результате циркуляции в сети больших объемов избыточной информации резко возрастает нагрузка на сеть, что приводит к снижению ее быстродействия и, следовательно, производительности САПР в целом. Во-вторых, в связи с тем что на каждом отдельном компьютере сети имеется своя копия БД, изменения, сделанные в ней одним пользователем, в течение некоторого времени остаются неизвестными для других пользователей, поэтому требуются постоянное обновление БД и синхронизация работы пользователей. В-третьих, так как управление БД осуществляется с разных компьютеров, то в значительной степени затруднена организация управления доступом, а также соблюдение требований по защите информации и поддержания целостности БД.
Когда база данных размещается на специализированном компьютере — сервере сети, а приложение, осуществляющее работу с этой БД, находится на компьютере пользователя, то такая структура получила название «клиент-сервер» (рис. 3.5).
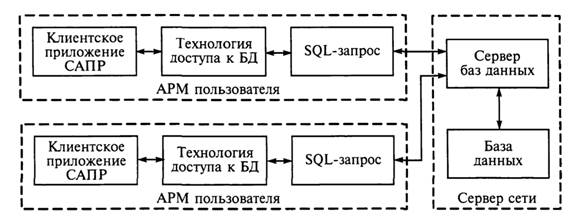
Рис. 3.5. Двухуровневая структура «клиент-сервер»
В этом случае все информационное обеспечение САПР делится на две неоднородные части: сервер и клиент БД. В связи с тем что компьютер- сервер отделен от клиента, иногда его также называют удаленным сервером. Здесь под клиентом понимается программное обеспечение пользователя, использующее БД. Для получения данных клиент формирует и отсылает запрос удаленному серверу, на котором размещена БД. Запрос формулируется на языке SQL, являющемся стандартным средством доступа к серверу. После получения запроса удаленный сервер направляет его специальной программе (серверу баз данных), управляющей удаленной БД и обеспечивающей выполнение запроса и выдачу его результатов клиенту. Такая структура обладает следующими достоинствами: • снижается нагрузка на сеть; • повышается защищенность информации, в связи с тем что обработка запросов всех клиентов выполняется единой программой, расположенной на сервере; • упрощается клиентское ПО за счет отсутствия в нем кода, связанного с контролем БД и разграничением доступа к ней.
Для реализации структуры «клиент-сервер» обычно используются многопользовательские СУБД, например Oracle или MicrosoftSQLServer. Часто подобные СУБД также называют промышленными, поскольку они позволяют организовать доступ к информации в БД большому числу пользователей организации или предприятия. Промышленные СУБД являются сложными системами и требуют мощной вычислительной техники и высококвалифицированного обслуживания. Описанная структура является двухуровневой (уровень приложения клиента и уровень сервера БД). Иногда клиентское ПО также называют сильным или «толстым» клиентом.
Дальнейшее развитие данной структуры привело к появлению трехуровневого варианта: приложение-клиент, сервер приложений и сервер БД (рис. 3.6).
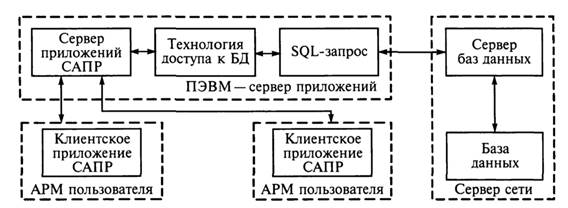
Рис. 3.6. Трехуровневая структура «клиент-сервер»
В трехуровневой структуре часть средств и кода, предназначенных для организации доступа к данным и их обработке, из приложения клиента передается серверу приложений. Само клиентское приложение при этом называют слабым или «тонким» клиентом. В сервере приложений удобно располагать средства и код,общие для всех клиентских приложений, например, средства доступа к БД. Основные достоинства трехуровневой структуры «клиент-сервер» состоят в том, что, во-первых, сервер БД разгружается от выполнения ряда операций, которые перенесены на сервер приложений, во-вторых, уменьшается размер клиентских приложений за счет упрощения кода и, в-третьих, облегчается настройка самих клиентов — при изменении общего кода сервера приложений автоматически изменяется поведение приложений-клиентов. Какой бы структуре не было отдано предпочтение, СУБД должна предоставлять доступ к данным любым пользователям независимо от представления данных, физического размещения в памяти, технологии доступа к запрашиваемым данным и решать проблемы одновременного запроса одних и тех же данных разными пользователями, обеспечения защиты данных от несанкционированного доступа. Для корректного выполнения всех требуемых функций СУБД должна использовать различные описания данных, поэтому проект базы данных начинают с анализа предметной области и выявления требований к ней отдельных пользователей, которыми могут быть, например, инженеры-проектировщики РЭС, для которых и создается конкретная БД.
Разработка базы данных, как правило, поручается администратору базы данных (АБД). Функции АБД могут выполнять как отдельный специалист, так и группа специалистов или даже штатное подразделение, которое управляет всеми аппаратными и программными средствами базы данных. Объединяя представления отдельных пользователей о содержимом БД, полученные в результате опроса, и свои представления, АБД создает обобщенное неформальное описание создаваемой базы данных. Такое описание, выполненное с использованием средств естественного языка, математического аппарата и других средств, понятных всем разработчикам базы данных, называют инфологической моделью данных (рис. 3.7).

Рис. 3.7. Трехуровневое представление моделей данных
Заметим, что эта модель полностью независима от физических параметров среды хранения данных. Остальные модели, представленные на рис. 3.7, машинно-ориентированные. С их помощью СУБД позволяет программам и пользователям осуществлять доступ к необходимой информации, которая отыскивается СУБД на запоминающих устройствах по физической модели данных. Так как доступ к данным осуществляется с помощью конкретной СУБД, модели должны быть представлены на языке описания данных этой СУБД. Это описание, создаваемое АБД по инфологической модели данных, называют даталогической моделью. Такая трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ. Администратор БД может при необходимости реорганизовать физическую структуру хранимых данных, изменив лишь физическую модель данных, а также подключить к системе любое число новых пользователей, дополнив даталогическую модель, причем указанные изменения физической и даталогической моделей не будут замечены существующими пользователями системы. Следовательно, независимость данных обеспечивает возможность реализации одного из рассмотренных в подразд. 3.1 принципов создания САПР — принципа развития, т. е. возможности модернизации баз данных без разрушения существующего программного обеспечения САПР.
В процессе развития теории и практического использования баз данных, а также средств вычислительной техники созданы СУБД, поддерживающие различные даталогические модели представления данных: иерархическую, сетевую, объектно-ориентированную и реляционную.
В иерархической модели данные представляются в виде древовидной структуры, что удобно для работы с иерархически упорядоченной информацией, однако при работе со сложными функционально-логическими связями данных иерархическая модель оказывается слишком громоздкой.
В сетевой модели данные организуются в виде сложных структур, состоящих из «наборов» — поименованных двухуровневых деревьев графа. Недостатками сетевой модели является жесткость структуры и высокая сложность ее реализации.

 В объектно-ориентированной модели отдельные записи базы данных представляются в виде объектов. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам объектно-ориентированных языков программирования. Объектно- ориентированные модели сочетают особенности сетевой и реляционной моделей и используются для создания крупных БД со сложными структурами данных.
В объектно-ориентированной модели отдельные записи базы данных представляются в виде объектов. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам объектно-ориентированных языков программирования. Объектно- ориентированные модели сочетают особенности сетевой и реляционной моделей и используются для создания крупных БД со сложными структурами данных.
Реляционная модель основана на использовании для обработки данных математического аппарата теории множеств. В данной модели любое представление данных сводится к совокупности двумерных таблиц особого вида, связанных между собой отношениями (relation). Достоинствами реляционной модели данных являются простота, гибкость структуры, возможность математического описания и удобство реализации на ЭВМ. Необходимо заметить, что большинство современных БД являются реляционными.
Реляционные базы данных
Реляционная база данных состоит из взаимосвязанных таблиц, содержащих информацию об объектах одного типа, а совокупность всех таблиц образует единую БД. Каждая таблица БД состоит из строк и столбцов и предназначена для хранения данных об однотипных объектах информационной системы САПР. Строки таблицы называются записями, столбцы таблицы — полями. Каждое поле должно иметь уникальное в пределах таблицы имя. На рис. 3.8 схематично изображен фрагмент таблицы базы данных со справочной информацией о транзисторах.
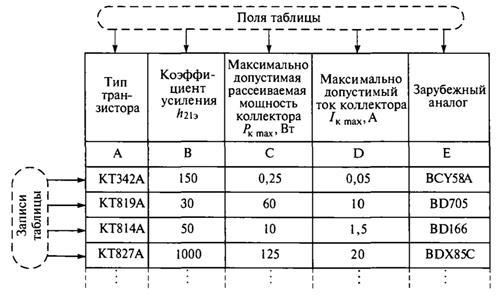
Рис. 3.8. Фрагмент таблицы базы данных «Транзисторы»
Для представления в БД традиционному наименованию полей соответствуют уникальные имена А, В, С, D и Е. Поле может содержать символьные или числовые данные одного из допустимых типов. Необходимо заметить, что особенности организации таблиц зависят от конкретной СУБД, при этом существуют общие правила создания таблиц. Основу таблицы составляет описание ее полей, каждая таблица должна иметь хотя бы одно поле. С таблицей можно выполнять следующие операции: создание, т. е. определение структуры, реструктуризация, переименование и удаление. Понятие структуры таблицы является более широким и включает описание полей, ключ, индексы, ограничения на значения полей, ограничения ссылочной целостности между таблицами и пароли.
Ключ представляет собой комбинацию полей, данные в которых однозначно определяют каждую запись в таблице. Простой ключ состоит из одного поля, а составной — из нескольких полей. Поля, по которым построен ключ, называют ключевыми. В каждой таблице может быть определен только один ключ, обеспечивающий однозначную идентификацию записей таблицы, ускорение выполнения запросов к БД, установление связи между отдельными таблицами БД.
Иногда ключ также называют первичным или главным индексом. Необходимо заметить, что таблицы различных форматов имеют свои особенности построения ключей, но, тем не менее, существуют общие требования:
• ключ должен быть уникальным, достаточным и не избыточным, т. е. он не содержит поля, которые можно удалить без нарушения уникальности ключа;
• в состав ключа не могут входить поля некоторых типов, например поле с графическими данными или поле с комментариями. Выбор ключевого поля не всегда прост и однозначен, особенно для таблиц, содержащих множество полей. Нежелательно выбирать в качестве ключевых поля, содержащие, например, фамилии людей в таблице проектировщиков какого-либо изделия РЭС или названия готовой продукции, заготовок или компонентов РЭС в таблице данных склада. В этом случае высока вероятность существования однофамильцев, изделий с одинаковыми названиями, которые различаются, к примеру, цветом, климатическим исполнением, набором дополнительной комплектации. Для подобных таблиц в качестве ключа можно использовать, например, поле кода сотрудника и поле артикула изделия, причем указанные значения должны быть уникальными.
Как и ключ, индекс представляет собой своеобразное оглавление таблицы, которое просматривается перед обращением к ее записям. Индекс также строят по полям таблицы, однако его главной особенностью является то, что он может допускать повторение значений составляющих его полей. Поля, по которым построен индекс, называют индексными. Простой индекс состоит из одного поля, а составной (сложный) — из нескольких полей. Индексы при их создании именуются. Использование индекса позволяет увеличить скорость поиска данных, проводить сортировку записей таблицы, устанавливать связи между отдельными таблицами БД. Одной из главных задач СУБД является обеспечение быстрого доступа к данным (поиска данных). Время доступа к данным в значительной степени зависит от используемых для поиска методов и способов.
В настоящее время используют следующие методы доступа к данным таблиц: последовательный, прямой и индекснопоследовательный.
При последовательном доступе выполняются поочередный просмотр всех записей таблицы и выбор из них требуемых. Существенным недостатком метода являются значительные временные затраты на поиск, прямо пропорциональные числу записей таблицы. Поэтому его используют, как правило, только для относительно небольших таблиц.
При прямом доступе выбор нужной записи в таблице осуществляется на основании ключа или индекса. При этом просмотр других записей не выполняется.
Индексно-последовательный доступ включает в себя элементы последовательного и прямого методов доступа и используется при поиске группы записей. Сущность метода заключается в том, что находится индекс первой записи, удовлетворяющей заданным условиям, и соответствующая запись выбирается из таблицы (прямой доступ). После обработки первой найденной записи осуществляется последовательный переход к следующему значению индекса, и в таблице выбирается запись, соответствующая значению этого индекса. Достоинством прямого и индексно-последовательного методов является максимально возможная скорость доступа к данным, а недостатком — расход памяти ЭВМ на хранение информации о ключах и индексах.
Указанные методы доступа реализуются СУБД и не требуют специального программирования, а задачей разработчика является определение соответствующей структуры БД, и в том числе определение ключей и индексов. Например, если для поля создан индекс, то при поиске записей по этому полю автоматически используется индексно-последовательный метод доступа, а если индекс отсутствует — то последовательный метод.
Кроме рассмотренных методов доступа к данным при выполнении операций с таблицами используется один из следующих способов доступа к данным — навигационный или реляционный.
Навигационный способ доступа заключается в обработке каждой отдельной записи таблицы и обычно используется в локальных или удаленных БД небольшого размера. Если необходимо обработать несколько записей, то они обрабатываются поочередно.
Реляционный способ доступа основан на SQL-запросах, предназначен для обработки группы записей и ориентирован на выполнение операций с удаленными БД, несмотря на то, что его можно использовать и для локальных БД. Способ доступа к данным выбирается программистом и зависит от средств доступа к БД, используемых при разработке приложения. Следовательно, методы доступа к данным определяются структурой БД, а способы доступа — приложением.
В частном случае БД может состоять из одной таблицы, однако, как правило, реляционная БД включает набор взаимосвязанных таблиц. Процесс организации связи между таблицами получил название связывание или соединение таблиц. Связи между таблицами можно устанавливать как при создании БД, так и при выполнении соответствующего приложения САПР при помощи средств, предоставляемых СУБД. Для связи таблиц используются так называемые поля связи, или совпадающие поля. Поля связи обязательно должны быть индексированными. В подчиненной таблице для связи с главной таблицей задается индекс, называемый внешним ключом. Состав полей этого индекса должен полностью или частично совпадать с составом полей индекса главной таблицы. На рис. 3.9 показан упрощенный пример схемы связи между двумя таблицами, в названия полей которых включены префиксы, указывающие на принадлежность поля соответствующей таблице.
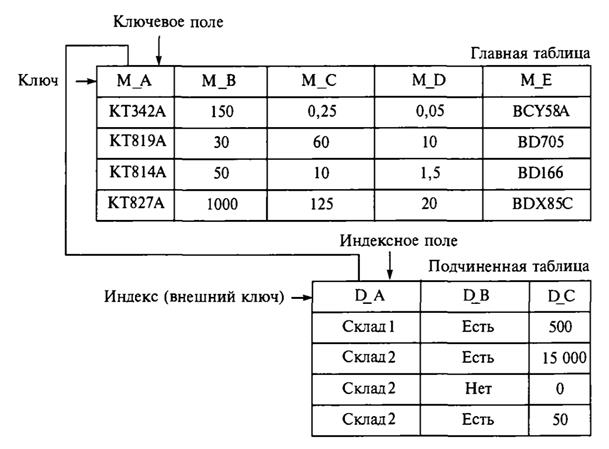
Рис. 3.9. Схема связи между таблицами базы данных
Так, названия полей главной таблицы начинаются с буквы М (Master), а подчиненной таблицы — с буквы D (Detail). Такой принцип именования полей облегчает ориентацию в их названиях, особенно при большом количестве таблиц. В главной таблице содержание полей аналогично соответствующим полям на рис. 3.8 (тип транзистора, коэффициент усиления, мощность, ток и аналог), а поля D_A, D_B и D_C подчиненной таблицы содержат информацию о складах комплектующих, их наличии и количестве соответственно. В главной таблице (см. рис. 3.9) определен ключ, построенный по полю М_А, а в подчиненной — индекс, составленный по полю D_A. Связь между таблицами устанавливается по полям D_A и М_А. Индекс по полю D_A является внешним ключом. Связь между таблицами определяет отношение подчиненности, при котором одна таблица является главной (иногда называемой родительской или мастером — Master), а вторая — подчиненной (в другой терминологии дочерней или детальной — Detail).
Существуют следующие виды связи: «один-к-одному», «один-ко- многим», «многие-к-одному» и «многие-ко-многим».
Отношение «один-к-одному» означает, что одной записи в главной таблице соответствует одна запись в подчиненной таблице, и обычно используется при разбиении таблицы с множеством полей на несколько отдельных таблиц. В этом случае в первой таблице остаются поля с наиболее важной информацией, а остальные поля переносятся в другие таблицы.
Отношение «один-ко-многим» встречается наиболее часто и означает, что одной записи главной таблицы может соответствовать как несколько записей в подчиненной таблице, так и ни одной. После установления связи между таблицами при перемещении на какую-либо запись в главной таблице в подчиненной автоматически становятся доступными записи, у которых значение поля связи равно значению поля связи текущей записи главной таблицы. Типичным примером является, например, организация учета расхода комплектующих при сборке изделий РЭС, для чего удобно создать две таблицы:
• таблицу готовой продукции, содержащую такую информацию об изделиях, как наименование, шифр, годовой объем выпуска;
• таблицу комплектующих, в которую заносятся данные о выдаче необходимых ЭРЭ для сборки изделия и о возврате дефектных элементов.
В этой ситуации главной является таблица готовой продукции, а подчиненной — таблица комплектующих. В одном изделии РЭС обычно содержится множество разнообразных ЭРЭ, поэтому одной записи в главной таблице может соответствовать множество записей в подчиненной таблице. Если на сборку изделия еще не выдавались комплектующие, то для него нет записей в подчиненной таблице. После связывания обеих таблиц при выборе записи с данными конкретного изделия в таблице комплектующих будут доступны только записи с данными об ЭРЭ, примененных в этом изделии.
Отношение «многие-ко-многим» имеет место, когда одной записи главной таблицы может соответствовать несколько записей подчиненной таблицы и одновременно одной записи подчиненной таблицы — несколько записей главной.
На практике отношение «многие-ко-многим» реализуется редко из-за сложности организации связи между таблицами и взаимодействия между их записями. Кроме того, для данного отношения понятия главной и подчиненной таблиц не имеют смысла. Среди рассмотренных наиболее общим является отношение «один-ко-многим», другие же виды отношений по сути являются его вариантами. Так, отношение «один-к-одному» представляет собой частный случаи отношения «один-ко-многим», а отношение «многие-к-одному» является его зеркальным отображением. Отношение «многие-ко-многим» сводится путем преобразования и разделения таблиц к отношению «один-ко-многим». Одно из наиболее главных требований к БД — обеспечение целостности и непротиворечивости информации, хранящейся в БД.
Одним из путей выполнения этого требования является использование механизма транзакций. Транзакция представляет собой выполнение последовательности операций, переводящих БД из одного целостного состояния в другое. Использование транзакций необходимо при выполнении последовательности взаимосвязанных операций с БД, а также при многопользовательском доступе к БД.
При этом возможны две ситуации.
1. Успешно выполнены все операции. В этом случае транзакция также считается успешной, все изменения в БД, которые были произведены в рамках транзакции отдельными операциями, подтверждаются, и в результате БД переходит из одного целостного состояния в другое.
2. Неудачное завершение одной или нескольких операций. При этом вся транзакция считается неуспешной, и результаты выполнения всех, даже успешно выполненных операций, отменяются, и происходит возврат БД в состояние, в котором она находилась до начала транзакции.
Часто в транзакцию объединяют операции над несколькими таблицами, в том случае, когда необходимо внесение в разные таблицы взаимосвязанных изменений, например, осуществляется перенос записей из одной таблицы в другую. Здесь возможна ситуация, когда запись из одной таблицы уже удалена, но во вторую таблицу еще не попала, что бывает, в частности, при сбое электропитания компьютера. Если же запись сначала заносится во вторую таблицу и только потом удаляется из первой, тогда сбой может привести к появлению одной записи в двух таблицах. И в первом и во втором случае нарушается целостность и непротиворечивость БД. Именно поэтому операции удаления записи из одной таблицы и занесения ее в другую таблицу объединяют в одну транзакцию, выполнение которой гарантирует, что при любом ее результате целостность БД нарушена не будет.
Для реализации механизма транзакций СУБД предоставляют ряд средств, в том числе бизнес-правила. Бизнес-правила — это механизмы управления БД, не имеющие отношения к бизнесу как к предпринимательству и предназначенные для поддержания БД в целостном состоянии, а также выполнения некоторых других действий (например, накапливания статистических данных по работе с БД).
Бизнес-правила реализуют следующие ограничения БД:
• задание допустимого диапазона значений и значений по умолчанию;
• обеспечение уникальности значения;
• запрет пустого значения;
• ограничения ссылочной целостности.
Бизнес-правила реализуются на физическом и (или) программном уровнях.
В первом случае эти правила задаются при создании таблиц и входят в структуру БД. При этом заданное на физическом уровне ограничение в дальнейшей работе с БД нельзя нарушить или обойти.
Во втором случае бизнес-правила определяются на программном уровне, причем действие этих правил распространяется только на приложение, в котором они реализованы. Преимущество такого подхода заключается в простоте изменения бизнес-правил, а недостаток — в снижении безопасности БД, так как каждое приложение может устанавливать свои правила управления БД. Проектирование реляционной БД начинается с разработки структуры данных, т. е. с определения состава таблиц и связей между ними. Иногда проектирование структуры БД называют проектированием на логическом уровне. В качестве основных критериев оценки эффективности структуры БД рассматриваются скорость доступа к данным, отсутствие дублирования и целостность данных.
При проектировании структуры БД выделяют три основных подхода.
1. Сбор информации об объектах решаемой задачи в рамках одной таблицы и последующее разбиение ее на несколько взаимосвязанных таблиц.
2. Определение типов исходных данных, их взаимосвязей и требований к обработке данных, а затем получение структуры БД с помощью CASE-средств.
3. Использование методов системного анализа для структурирования информации.
Различают два способа проектирования БД: ручное и автоматизированное.
Ручное проектирование применяется для разработки относительно небольших БД. Однако во многих пакетах САПР используются крупные базы данных, состоящие из нескольких десятков или сотен различных взаимосвязанных таблиц.
Для облегчения проектирования таких БД предназначены программные средства класса ETL (ExtractTransferLoad), которые обеспечивают извлечение, приведение к общему формату, преобразование и загрузку данных в хранилища, а также системы автоматизации разработки приложений — средства CASE.
Средства CASE (ComputerAidedSoftwareEngineering) представляют собой наборпрограмм, поддерживающих процессы создания и сопровождения сложных информационных систем. К таким программам относятся средства анализа и формулировки требований, проектирования БД и соответствующего программного обеспечения, генерации кода, верификации, тестирования, контроля качества, управления конфигурацией и проектом в целом. Система CASE включает в себя набор CASE-средств определенного функционального назначения в виде единого программного продукта. CASE-системы для разработки баз данных классифицируют по ориентации на этапы жизненного цикла, функциональной полноте, типу используемых моделей, степени независимости от СУБД и программно-аппаратной платформе.
По ориентации на этапы жизненного цикла выделяют следующие основные типы CASE-систем:
• системы построения и анализа моделей предметной области, например,Design/IDEF фирмы MetaSoftware и AllFusionProcessModeler (прежнее название BPWin) фирмы ComputerAssociates;
• системы анализа и проектирования, позволяющие создавать проектные спецификации, такие, как VantageTeamBuilder фирмы Cayenne, Silverrun (SilverrunTechnologies), PRO-I (McDonnellDouglas);
• системыпроектированияБД, напримерAllFusionERwinDataModeler (ComputerAssociates), S-Designer (SPD) иDataBaseDesigner (Oracle);
• системыразработкиприложений — Uniface (Compuware), JAM (JYACC), PowerBuilder (Sybase), Developer/2000 (Oracle), NewEra (Informix), SQLWindows (Centura), Delphi (Borland). По функциональной полноте CASE-системы условно делятся на следующие группы:
• системы, предназначенные для решения частных задач на одном или нескольких этапах жизненного цикла, например All- FusionERwinDataModeler, S-Designer и Silverrun (SilverrunTechnologies);
• интегрированные системы, поддерживающие весь жизненный цикл информационной системы, например VantageTeamBuilder и система Designer/2000 совместно с Developer/2000. По типу моделей CASE-системы бывают трех видов: структурные, объектно-ориентированные и комбинированные. Структурные системы CASE основаны на методах структурного и модульного программирования, структурного анализа и синтеза, например,VantageTeamBuilder.
Объектно-ориентированные CASE-системы позволяют сократить сроки разработки, повысить надежность и качество функционирования информационной системы. Типичными примерами объектно-ориентированных систем CASE являются RationalRose фирмы RationalSoftware и ObjectTeam фирмы Cayenne. КомбинированныеCASE-системы, например Designer/2000, поддерживают одновременно и структурное, и объектно-ориентированное программирование.
По степени независимости от СУБД среди CASE-систем выделяют две группы: независимые и встроенные в СУБД:
• независимые CASE-системы поставляются в виде автономных средств, не входящих в состав конкретной СУБД и обычно поддерживающих несколько форматов баз данных. К числу независимых относятся SDesigner, AllFusionERwinDataModeler и Silverrun;
• встроенные CASE-системы, как правило, поддерживают только один формат базы данных, в состав СУБД которой они входят. Примером встроенной системы является система Designer/2000, входящая в состав СУБД Oracle. По программно-аппаратной платформе различают CASE-системы, ориентированные на работу с определенными типами ПЭВМ и операционных систем, под управлением которых возможно использование программного продукта, созданного с помощью конкретной CASE-системы.
Дата: 2019-02-19, просмотров: 375.