В анализе стохастических процессов важное значение имеют статистические взаимосвязи между случайными величинами. В качестве количественных характеристик подобных взаимосвязей в статистике используют два показателя ковариацию и корреляцию.
Ковариация выражает степень статистической зависимости между двумя множествами данных и определяется из соотношения:
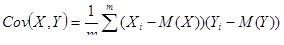
где X,Y –множество значений случайных величин размерности m ; М(Х) – математическое ожидание случайной величины Х; М(Y) – математическое ожидание случайной величины Y .
Как следует из этой формулы, положительная ковариация наблюдается в том случае, когда большим значениям случайной величины Х соответствуют большие значения случайной величины Y, т.е. между ними существует тесная прямая взаимосвязь. Отрицательная ковариация будет иметь место при соответствии малым значениям случайной величины Х больших значений случайной величины Y. При слабо выраженной зависимости значение показателя ковариации близко к 0.
Ковариация зависит от единиц измерения исследуемых величин, что ограничивает ее применение на практике. Более удобным для использования в анализе является производный от нее показатель – коэффициент корреляции R , вычисляемый по формуле:
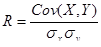
Коэффициент корреляции обладает теми же свойствами, что и ковариация, однако является безразмерной величиной и принимает значения от –1 (характеризует линейную обратную взаимосвязь) до +1 (характеризует линейную прямую взаимосвязь). Для независимых случайных величин значение коэффициента корреляции близко к 0.
Определение количественных характеристик для оценки тесноты взаимосвязи между случайными величинами в MS Excel может быть осуществлено двумя способами:
· С помощью статистических функций КОВАР() и КОРРЕЛ();
· С помощью специальных инструментов статистического анализа.
Если число исследуемых переменных больше двух, более удобным является использование инструмента анализа.
Инструмент анализа данных - Корреляция
Определим степень тесноты взаимосвязей между переменными V,Q,P,NCF,NPV. При этом в качестве меры будем использовать показатель корреляции R.
· Выбрать в главном меню тему Сервис, пункт Анализ данных. Результатом выполнения этих действий будет появление диалогового окна (Рисунок 13. Анализ данных), содержащего список инструментов анализа.
· Выбрать из списка Инструменты анализа пункт Корреляция. Результатом будет появление окна диалога инструмента Корреляция. (Рисунок 14. Заполнение окна диалога инструмента Корреляция)
· Заполнить поля диалогового окна, как показано на рисунке.
Рисунок 13. Анализ данных . Список инструментов анализа

Рисунок 14. Заполнение окна диалога инструмента Корреляция
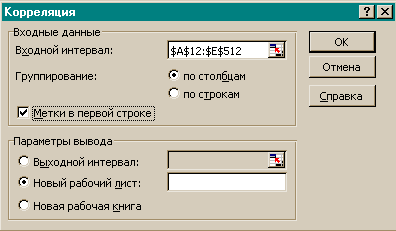
Таблица 21. Результаты корреляционного анализа
| Переменные расходы (V) | Количество (Q) | Цена (P) | Поступления (NCF) | ЧСС (NPV) | |
| Переменные расходы (V) | 1 | ||||
| Количество (Q) | 0,0527583 | 1 | |||
| Цена (P) | 0,0523678 | -0,0611898 | 1 | ||
| Поступления (NCF) | -0,394848848 | 0,548358 | 0,672387 | 1 | |
| ЧСС (NPV) | -0,394848848 | 0,548358 | 0,672387 | 1 | 1 |
Результаты корреляционного анализа представлены в виде квадратной матрицы (Таблица 21. Результаты корреляционного анализа), заполненной только на половину, поскольку значение коэффициента корреляции между двумя случайными величинами не зависит от порядка их обработки. Эта матрица симметрична относительно главной диагонали, элементы которой равны 1, так как каждая переменная коррелирует сама с собой.
Как следует из результатов корреляционного анализа, выдвинутая в процессе решения гипотеза о независимости распределений ключевых переменных V, Q, P в целом подтвердилась. Значения коэффициентов корреляции между переменными расходами V, количеством Q и ценой Р достаточно близки к 0.
В свою очередь величина показателя NPV напрямую зависит от величины потока платежей (R = 1). Кроме того, существует корреляционная зависимость средней степени между Q и NPV (R = 0,548), P и NPV (R = 0,67). Как и следовало ожидать, между величинами V и NPV существует умеренная обратная корреляционная зависимость (R = -0,39).
Полезность проведения последующего статистического анализа результатов имитационного эксперимента также в том, что во многих случаях он позволяет выявить некорректности в исходных данных либо даже ошибки в постановке задачи.
Следует отметить, что близкие к нулевым значения коэффициента корреляции R указывают на отсутствие линейной связи между исследуемыми переменными, но не исключает возможности нелинейной зависимости. Кроме того, высокая корреляция не обязательно всегда означает наличие причинной связи, так как две исследуемые переменные могут зависеть от значений третьей.
При проведении имитационного эксперимента и последующего вероятностного анализа полученных результатов мы исходили из предположения о нормальном распределении исходных и выходных показателей. Вместе с тем справедливость сделанных допущений, по крайней мере для выходного показателя NPV , нуждается в проверке.
Для проверки гипотезы о нормальном распределении случайной величины применяются специальные статистические критерии: Колмогорова-Смирнова. В целом MS Excel позволяет быстро и эффективно рассчитать требуемый критерий и провести статистическую оценку гипотез.
Однако в простейшем случае для этих целей можно использовать такие характеристики распределения, как асимметрия (скос) и эксцесс. Для нормального распределения эти характеристики должны быть равны 0. На практике близкими к нулевым значениями можно пренебречь. Смысл коэффициента асимметрии заключается в следующем: в случае положительного значения коэффициента (положительного скоса) самые высокие доходы считаются более вероятными, чем самые низкие. Соответственно в случае отрицательного коэффициента асимметрии более вероятными будут считаться самые низкие доходы.
Экономический смысл эксцесса заключается в следующим: Если две операции имеют симметричные распределения доходов и одинаковые средние, менее рискованной считается инвестиция с большей величиной эксцесса.
Для вычисления коэффициента асимметрии и эксцесса реализованы специальные статистические функции – СКОС() и ЭКСЦЕСС().
Дата: 2019-02-02, просмотров: 432.