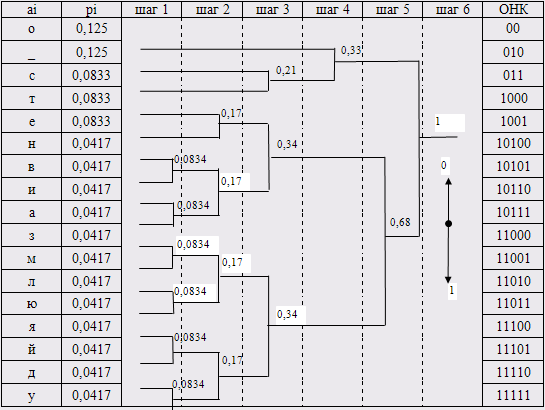
Расчет ОНК Хаффмена
При расчёте оптимального неравномерного кода Хаффмена нам потребуются вероятности появления символов в нашем сообщении. Они у нас уже рассчитаны и выстроены в порядке убывания.
Сам оптимальный неравномерный код Хаффмена мы будем вычислять при помощи алгоритма Хаффмена:
Шаг 1. "Склеиваются" две самых маленьких вероятности.
Шаг 2. В усечённом алфавите снова "склеивают" две самых маленьких вероятности.
Объединение вероятностей заканчивается, когда в усечённом алфавите остаётся лишь одна вероятность.
Критерий Фано
Полученный ОНК Хаффмена обязан обладать свойством пре-фиксности, то есть ни одно слово ОНК не должно являться началом другого слова. Критерий Фано позволяет однозначно декодировать сжатое сообщение.
Cообщение примет вид:
S=1001101011011111001001010101100011101010011101000100001100010111101111111001100101101000

Характеристики ОНК
1. Средняя длина ОНК
Lcp.онк= 4.23 [бит]
2. Энтропия ОНК
H(A)= 1,18 [бит/символ]
3. Максимальная энтропия
Hmax= log 17= 4,08 [бит/символ]
4. Относительная энтропия
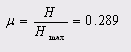
5. Информационная избыточность
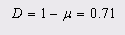
6. Абсолютная недогруженость

7. Коэффициент сжатия
Кс = 1- Lcp.онк/ LРДК = 0,15 = 15 %
8. Коэффициент эффективности Кэ
Кэ=Н/ Lcp.онк = 0,27
Эффективность ОНК тем выше, чем больше средняя длина ОНК стремится к энтропии.
Эффективность ОНК
Однозначно декодировать ОНК можно с помощью критерия Фано, который говорит о свойстве префиксности, которым обладают коды. Благодаря сжатию информации возможно значительно сократить исходный код.
Эффективность ОНК можно определить с помощью коэффициента эффективности, то есть чем ближе Кэ стремится к единице, тем эффективнее оптимальный неравномерный код.
ОНК не обладает избыточностью, так как к нему не прикрепляются контрольные биты.
Помехоустойчивое кодирование. Назначение
Назначение помехоустойчивого кодирования состоит в защите данных от действия помех.
Эти коды делятся на две группы:
· Обнаруживающие коды – коды только обнаруживают ошибки, но не указывают их адрес
· Корректирующие коды – обнаруживают наличие ошибки, вычисляют адрес ошибки (позицию), в котором появился ошибочный бит.
Обнаруживающие коды
Двоичный код становится обнаруживающим за счет добавления дополнительных контрольных бит.
Можно назвать следующие обнаруживающие коды: обнаруживающий код четности (ОКЧ), обнаруживающий код удвоения (ОКУ), обнаруживающий код инверсией (ОКИ), обнаруживающий код стандартный телеграфный код № 3 и другие.
7.1.1 Обнаруживающий код четности (ОКЧ)
Данный двоичный код дополняется одним контрольным битом в конце слова.
nи - длина информационной части, количество бит.
nк - длина контрольной части.
n = nи + nк - длина слова.
Пример.
Генерация.
Пусть исходное слово 0101.
Макет ОКЧ - 0101К,
где К – контрольный бит, равно сумме по модулю 2 информационных бит исходника.
К = 0 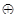 1
1  0 1 = 0
0 1 = 0
ОКЧ (n; nи )
ОКЧ (5; 4) = 01010
Проверим:
S = 0 1 0 1 0 = 0 -  ошибки , то есть ошибки не существует
ошибки , то есть ошибки не существует
| Количество ошибок | Передано | Принято | Наличие ошибки |
| Нет ошибок | 01010 | 01010 | S = 0, ошибки
|
| 1 ошибка | 01010 | 11010 | S = 1,  ошибка ошибка
|
| 2 ошибки | 01010 | 11011 | S = 0,  ошибки ошибки
|
| 3 ошибки | 01010 | 10011 | S = 1, ошибка
|
| 4 ошибки | 01010 | 10111 | S = 0, ошибки
|
Недостаток: ОКЧ позволяет определять наличие ошибки при нечетном их количестве и не определяет ошибку при их четном количестве.
Эффективность.
1. Минимальное количество контрольных бит.
2. Просто и удобный алгоритм генерации кода и диагностики (обнаружения ошибок).
7.1.2 Обнаруживающий код удвоения (ОКУ)
Генерация ОКУ.
Пусть исходное сообщение будет 0101.
Макет ОКУ: 0101 К1 К2 К3 К4,
где nи = 0101 и nк = К1 К2 К3 К4, то есть nи = nк.
Контрольные биты равны соответствующим информационным битам.
ОКУ (8; 4) = 01010101
Диагностика.
При диагностике суммируются по модулю 2 информационная и контрольная части ОКУ.

Во всех остальных случаях ошибка существует.
Передано 01010101.
Принято 00010101.

Эффективность ОКУ.
1. Обнаруживает любое число ошибок и приблизительно указывает адрес ошибки;
2. Простота алгоритма генерации и диагностики;
3. Недостаток – избыточность, длина контрольной части 100%.
7.1.3 Обнаруживающий код инверсии (ОКИ)
Генерация ОКИ.
Пусть исходное сообщение будет 0101.
Макет ОКИ: 0101 К1 К2 К3 К4,
где nи = 0101 и nк = К1 К2 К3 К4, то есть nи = nк.
Контрольные биты ОКИ равны инверсии соответствующих бит
информационной части исходника.
ОКУ (8; 4) = 01011010
Диагностика.
При диагностике суммируются по модулю 2 информационная и
контрольная части ОКУ.

Если S = 1 – ошибка не существует. S=0 - 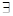 ошибка
ошибка
Передано 01011010.
Принято 10011011.

Эффективность ОКИ.
1. Обнаруживает любое число ошибок и приблизительно указывает адрес ошибки.
2. Простота алгоритма генерации и диагностики.
3. Недостатком является избыточность, длина контрольной части 100%.
7.1.4 Обнаруживающий код Стандартный телеграфный код (ОК СТК №3) №3
Количество единиц в двоичном коде называется весом кода.
Для всех символов, букв, цифр, спецзнаков разработаны двоичные коды весом, равным 3 ( т. е. содержат 3 единицы).
Диагностика.
Если в принятом двоичном слове количество единиц равно 3, то ошибки нет. Во всех остальных случаях ошибка есть.
Символ с ошибкой не корректируется, а удаляется.
Дата: 2019-12-22, просмотров: 685.