Будем предполагать, что имеем упорядоченный по возрастанию массив чисел. Основная идея - выбрать случайно некоторый элемент AM и сравнить его с аргументом поиска Х. Если AM=Х, то поиск закончен; если AM <X, то мы заключаем, что все элементы с индексами, меньшими или равными М, можно исключить из дальнейшего поиска. Аналогично, если AM >X.
Выбор М совершенно произволен в том смысле, что корректность алгоритма от него не зависит. Однако на его эффективность выбор влияет. Ясно, что наша задача – исключить как можно больше элементов из дальнейшего поиска. Оптимальным решением будет выбор среднего элемента, т.е. середины массива.
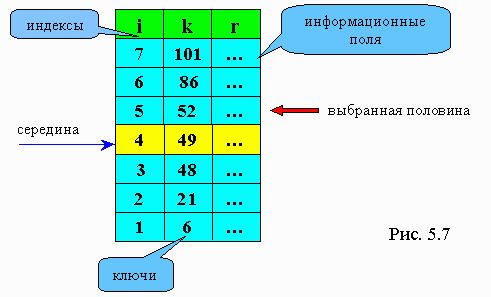
Рассмотрим пример, представленный на рис. 5.7. Допустим нам необходимо найти элемент с ключом 52. Первым сравниваемым элементом будет 49. Так как 49<52, то ищем следующую середину среди элементов, расположенных выше 49. Это число 86. 86>52, поэтому теперь ищем 52 среди элементов, расположенных ниже 86, но выше 49. На следующем шаге обнаруживаем, что очередное значение середины равно 52. Мы нашли элемент в массиве с заданным ключом.
Алгоритм бинарного поиска:
low = 1
hi = n
while (low <= hi) do
mid = (low + hi) div 2
if key = k(mid) then
search = mid
return
endif
if key < k(mid) then
hi = mid - 1
else
low = mid + 1
endif
endwhile
search = 0
return
Использование данного алгоритма позволяет найти запись с ключем, равным, например, 101 в таблице поиска рис. 5.7, за три сравнения (в последовательном поиске понадобилось бы семь сравнений).
Если С - количество сравнений, а n - число элементов в таблице, то
С = log2n , следовательно, эффективность бинарного поиска имеет порядок
О( log 2 N )
Например, n = 1024.
При последовательном поиске C = 512, а при бинарном
С = 10.
Можно совместить бинарный и индексно-последовательный поиск (при больших объемах данных), учитывая, что последний также используется при отсортированном массиве.
Поиск по бинарному дереву
Назначение его в том, чтобы по заданному ключу осуществить поиск узла дерева. Длительность операции зависит от структуры дерева. Действительно, дерево может быть вырождено в однонаправленный список, как правое на рис. 5.8 справа.
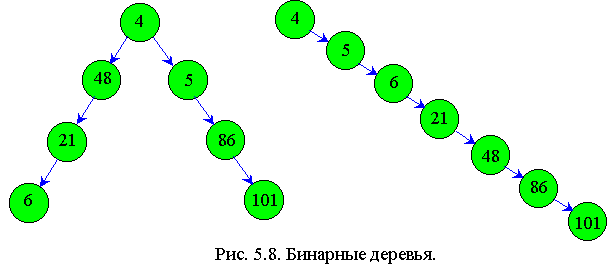
В этом случае время поиска будет такое же, как и в однонаправленном списке, т.е. придется перебирать N/2 элементов.
Наибольшего эффекта использования дерева достигается в том случае, когда дерево сбалансировано. В этом случае для поиска придотся перебрать не больше log2N элементов. В этом случае эффективность поиска по бинарному дереву имеет порядок O (log2N).
Поиск элемента в бинарном дереве называется бинарным поиском по дереву.
Такое дерево называют деревом бинарного поиска.
Суть поиска заключается в следующем. Анализируем вершину очередного поддерева. Если ключ меньше информационного поля вершины, то анализируем левое поддерево, больше - правое.
Алгоритм поиска по бинарному дереву:
p = tree
whlie p <> nil do
if key = k(p) then
search = p
return
endif
if key < k(p) then
p = left(p)
else
p = right(p)
endif
endwhile
search = nil
return
Очень часто следствием поиска являются ситуации:
если узел с заданным ключом не найден, то его надо вставить
если узел с заданным ключом найден,
то его надо удалить.
Дата: 2019-12-10, просмотров: 369.