Г.А. Доррер
Введение в специальность
Лекции для студентов 1 курса направлени й
ИНФОРМАТИКА И ВЫЧИСЛИТЕЛЬНАЯ ТЕХНИКА
ПРОГРАММНАЯ ИНЖЕНЕРИЯ
Красноярск – 2019
Оглавление
ВВЕДЕНИЕ. 3
История и методология информатики.. 4
Эволюция вычислительной техники.. 18
Развитие программного обеспечения.. 40
О становлении системной и программной инженерии.. 46
СТАНДАРТЫ В ОБЛАСТИ программной инженерии.. 66
Вопросы практической программной инженерии.. 71
5.3Модели жизненного цикла ПО.. 86
5.4 Инструментальные средства моделирования систем.. 92
5.5ИНСТРУМЕНТАЛЬНЫЕ СРЕДСТВА ПРОГРАММНОЙ ИНЖЕНЕРИИ.. 96
Инструментальные средства управления проектом.. 97
Основные тезисы программной инженерии.. 98
ВВЕДЕНИЕ
Информатика – наука, систематизирующая приемы создания, хранения, обработки и передачи информации средствами вычислительной техники, а также принципы функционирования этих средств и методы управления ими.. Теоретической основой информатики является группа фундаментальных наук таких как теория информации, теория алгоритмов, математическая логика, теория формальных языков и грамматик, комбинаторный анализ и т.д. Термин "информатика" начал использоваться в отечественной научно- технической литературе в начале 80-х годов и быстро приобрел широкую популярность. Первоначально он возник во Франции в середине 60-х годов (фр. informatique) и применяется в странах Европы для обозначения области научных знаний, связанных с автоматизацией обработки информации с помощью ЭВМ. Если говорить более точно, русскоязычный термин "информатика" объединил в себе (кроме всех прочих значений) наименование двух существенно различных дисциплин "computer science" ("вычислительная наука") и "information science". Термин "information science" уместно по аналогии с " computer science", переводить как "информационное дело" – наука по организации распространения научно-технической информации. Возможно, имеет смысл и в русском языке развести "information science" и "computer science", отделить науку информатику от связанной с ней областью практической деятельности.
Развитие информатики привело к созданию информационных технологий – процессов, использующих совокупность средств и методов сбора, обработки и передачи данных (первичной информации) для получения информации нового качества о состоянии объекта, процесса или явления (информационного продукта).
Если цель технологии материального производства – выпуск продукции, удовлетворяющей потребности человека или системы, то цель информационной технологии – производство информации для ее анализа человеком и принятия на его основе решения по выполнению какого-либо действия. В последние годы появился термин новые информационные технологии, которым обозначаются технологии, основанные на использовании компьютерных и телекоммуникационных средств.
Информационные технологии представляют собой обширную область научной и практической деятельности. В нее наряду с другими направлениями входит программная инженерия – сравнительно новое направление научной и инженерной деятельности в области информатики, сформировавшееся в последние десятилетия. В центре внимания этого направления находятся вопросы научного планирования, проектирования, оценки, конструирования и эффективного использования крупных программных систем, создаваемых людьми для удовлетворения установленных требований, а также проблемы успешной организации коллективных, бригадных методов работы при создании таких систем.
Важнейшим требованием в программной инженерии является следование определенной методологии, суть которой состоит в применении систематизированного, научного и предсказуемого процесса проектирования, производства и сопровождения программных комплексов, в том числе, и реального времени.
Настоящее пособие в рамках курса «Введение в специальность» ставит целью ознакомить студентов первого курса направлений подготовки09.03.01 «Информатика и вычислительная техника» и 09.03.04 «Программная инженерия» с основными понятиями информатики, вычислительной техники, программирования, системной и программной инженерии, со стандартами, определяющими процесс обучения специалистов, а также процессы жизненного цикла и разработки программных систем.
Учитывая, что большое количество источников информации для этой области написано на английском языке, при изучении этого курса требуется чтение и перевод англоязычных текстов.
Что такое информация
Информация является одним из ценнейших ресурсов общества наряду с такими традиционными материальными видами ресурсов, как нефть, газ, полезные ископаемые и другие, а значит, процесс ее переработки по аналогии с процессами переработки материальных ресурсов можно воспринимать как технологию .
Государственный стандарт ГОСТ 34.003-90 – Автоматизированные системы. Термины и определения. Вводит следующие определения.
Данные - любые сведения, зафиксированные на каком-либо носителе.
Информация – данные, обработанные и представленные в форме, удобной для восприятия человеком. Информация отражает смысл, который присвоен данным. Информация рассматривается как приращение наших знаний об окружающем нас мире на основе имеющихся данных. Информация неотделима от процесса информирования пользователя. Именно полезность информации отличает ее от данных. Данные преобразуются в информацию только в момент использования и осознания их значения: активные используемые сведения – информация; пассивные, законсервированные сведения – данные.
В быту информация – это любые воспринимаемые человеком сведения об окружающем мире; в технике информация – это любые сообщения, передаваемые с помощью сигналов или символов; в теории информации, согласно К. Шеннону, информация – это сведения, уменьшающие неопределѐнность (энтропию); в кибернетике, по мнению Н. Винера, информация – это сведения, используемые системой в целях самосохранения и развития в условиях среды; в семантике информация – это сообщение, несущее новый смысл. Важнейшими методологическими принципами информатики является изучение объектов и явлений окружающего мира с точки зрения процессов сбора обработки и выдачи информации о них, а также определенного сходства этих процессов при их реализации в искусственных и естественных (в том числе в биологических и социальных) системах. Как и всякий объект, информация обладает свойствами. Характерной отличительной особенностью информации от других объектов природы и общества, является дуализм: на свойства информации влияют как свойства исходных данных, составляющих ее содержательную часть, так и свойства методов, фиксирующих эту информацию.
С точки зрения информатики наиболее важными представляются следующие общие качественные свойства информации. Объективность информации. Объективный – существующий вне и независимо от человеческого сознания. Информация – это отражение внешнего объективного мира. Информация объективна, если она не зависит от методов ее фиксации, чьего-либо мнения, суждения.
Достоверность информации. Информация достоверна, если она отражает истинное положение дел. Объективная информация всегда достоверна, но достоверная информация может быть как объективной, так и субъективной. Полнота информации. Информацию можно назвать полной, если ее достаточно для понимания и принятия решений. Неполная информация может привести к ошибочному выводу или решению. Точность информации определяется степенью ее близости к реальному состоянию объекта, процесса, явления и т. п. Актуальность информации – важность для настоящего времени, злободневность, насущность. Только вовремя полученная информация может быть полезна. Полезность (ценность) информации. Полезность может быть оценена применительно к нуждам конкретных ее потребителей и оценивается по тем задачам, которые можно решить с ее помощью. Использование терминов – больше информации и – меньше информации‖ предполагает возможность её измерения или хотя бы количественного соотнесения. С течением времени количество информации растет, информация накапливается, происходит ее систематизация, оценка и обобщение. Это свойство назвали ростом и кумулированием информации. (лат. cumulatio – увеличение, скопление). Старение информации заключается в уменьшении ее ценности с течением времени. Старит информацию не само время, а появление новой информации, которая уточняет, дополняет или отвергает полностью или частично более раннюю.
Соотношение понятий "данные", "информация" и "знания"
Понятие "данные" не тождественно понятию "информация". Данные (калька от англ. data) — это представление фактов и идей в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе.
Станут ли данные информацией, зависит от того, известен ли метод преобразования данных в известные понятия. То есть, чтобы извлечь из данных информацию необходимо подобрать соответствующий форме данных адекватный метод получения информации. Данные, составляющие информацию, имеют свойства, однозначно определяющие адекватный метод получения этой информации. Причем необходимо учитывать тот факт, что информация не является статичным объектом – она динамически меняется и существует только в момент взаимодействия данных и методов. Информация существует только в момент протекания информационного процесса. Все остальное время она содержится в виде данных. По своей природе данные являются объективными, так как это результат регистрации объективно существующих сигналах, вызванных изменениями в материальных телах или полях. Методы являются субъективными. В основе искусственных методов лежат алгоритмы (упорядоченные последовательности команд), составленные и подготовленные людьми (субъектами).
Переходя к рассмотрению подходов к определению понятия "знания" можно выделить следующие трактовки. Знания – форма существования и систематизации результатов познавательной деятельности человека. В книге Б. Г. Тамма «Применение знании в автоматизированных системах проектирования и управления» приводятся основные свойства знаний:
1. Знания могут быть представлены в форме данных. В частности, в виде текста на некотором формальном языке, в виде сети, задающей связи разного рода между элементами знаний. Из этого свойства следует, что знание есть некоторая более высокая степень организации данных, которая допускает специальную интерпретацию.
2. Знания обладают способностью управлять информационными процессами (вычислениями). Точнее, в системе, в которой применяются знания, протекание процессов определяется знаниями и почти не зависит от устройства системы.
3. Знания могут содержать процедурную часть — программы. Но применение этих программ управляется знаниями, в частности, связывание параметров и запуск программ могут происходить автоматически внутри системы, использующей знания, без ведома того, кто запустил процесс, использующий знания.
4. Знания делятся на отдельные фрагменты — описания объектов, процессов, ситуаций, явлений. Такие фрагменты (модули знаний) называются фреймами. Фреймы могут быть связаны друг с другом родовидовыми отношениями, могут быть и узлами семантических сетей.
5. При работе со знаниями важна прагматическая сторона — знания всегда используются для чего-то, в частности, для решения задач, какую бы сложную структуру они ни имели.
Можно констатировать тот факт, что знание – это информация, но не всякая информация – знание. Информация выступает как знания, отчужденные от его носителей и обобществленные для всеобщего пользования. Другими словами, информация – это превращенная форма знаний, обеспечивающая их распространение и социальное функционирование. Получая информацию, пользователь превращает ее путем интеллектуального усвоения в свои личностные знания. Здесь мы имеем дело с так называемыми информационно-когнитивными процессами, связанными с представлением личностных знаний в виде информации и воссозданием этих знаний на основе информации.
Таким образом, можно сделать вывод, что фиксируемые воспринимаемые факты окружающего мира представляют собой данные. При использовании данных в процессе решения конкретных задач – появляется информация. Результаты решения задач, истинная, проверенная информация (сведения), обобщенная в виде законов, теорий, совокупностей взглядов и представлений представляет собой знания.
1. 2 Информация как ресурс
Информация как объект представляет собой данные, записанные на каком-либо носителе, и воспринятые с целью содержательной интерпретации потребителем. В этом качестве она может рассматриваться как ресурс.
Под ресурсами обычно понимают материальные средства. Однако информация также является важнейшим ресурсом любой деятельности, а развитие информационной инфраструктуры определяет развитие технологий и цивилизации в целом [].
Среди специфических особенностей, присущих информации как ресурсу, отметим следующие:
· практически не убывающая потенциальная эффективность (сравним – потенциальная эффективность сырья уменьшается по мере его использования, в случае возобновляемых ресурсов их потенциальная эффективность может восстанавливаться через некоторое время, потенциальная эффективность искусственных технических систем также имеет предел – срок службы),
· тиражируемость и многократность использования (труд, затрачиваемый на размножение информации незначителен и, им можно пренебречь при оценке эффективности использования информации),
· коммулятивность (т. е. усиление при накоплении),
· зависимость фактической реализуемости и эффективности от степени использования информации (в отличие от к. п. д. оборудования или коэффициента использования сырья), информация существует только когда есть источник, канал передачи и приемник - потребитель, желающий и способный воспринять информацию.
Информационная сфера предприятия (организации) должна включать весь спектр различных видов информации, отображающей состояние и функционирование предприятия (организации), а именно:
· с точки зрения взаимодействия с окружающей средой - входящая и исходящая;
· в зависимости от сроков хранения постоянная, условно-постоянная и переменная (регулярно обновляемая);
· по характеру обработки - машинная и внемашинная;
· по уровням управления - цеховая, производственная, заводская, корпоративная и т.д.;
· по характеру деятельности - бухгалтерская, учетно-отчетная, плановая, конструкторская, технологическая, диспетчерская,
· по логической организации - фактографическая, документальная, геоинформационная и другие.
Информационный процесс – процесс работы с информацией. Наиболее распространенные виды информационных процессов - сбор, передача, обработка, систематизация, хранение, защита, поиск, представление.
1.3 Информационные ресурсы
Бурное развитие информационных процессов и систем потребовало законодательного обеспечения этой области человеческой деятельности. В частности, был принят ряд законов, регламентирующих эту деятельность. Объектом информационных процессов является информационный ресурс. В Законе РФ 1993 года "Об информации, информатизации и защите информации" информационные ресурсы определены как отдельные документы и отдельные массивы документов, документы и массивы документов в информационных системах, предназначенные и самостоятельно оформленные для распространения среди неограниченного круга лиц, либо служащий основой для предоставления информационных услуг.
В более широком смысле под информационным ресурсом (ИР) понимаются «знания, подготовленные людьми для социального использования в обществе и зафиксированные на материальных носителях в виде документов, баз данных и знаний, алгоритмов, компьютерных программ, а также произведений искусства, литературы и науки» []. Информационные ресурсы страны, региона, организации рассматриваются как стратегические ресурсы, аналогичные по значимости запасам сырья, энергии и т. п.
Информационные ресурсы служат основой для создания информационных продуктов и оказания информационных услуг. Под информационным продуктом понимается совокупность данных, сформированных производителем для распространения в вещественной или невещественной форме с помощью информационных услуг. Перечень услуг определяется объемом, качеством и сферой применения информационных ресурсов.
Приведенное определение отражает ключевые признаки, которыми должна обладать информационная сущность для того, чтобы быть представленной в общедоступном каталоге ИР. Во-первых, ИР – это продукт, предназначенный для распространения среди неопределенного круга лиц, для которых он представляет интерес, т. е. имеет потребительскую ценность. Второй ключевой признак ИР – оформление, обеспечивающее возможность самостоятельного распространения.
Решение большинства задач систематизации ИР связано с использованием метаданных. Под метаданными понимается информация, характеризующая какую-либо другую информацию. Система метаданных выступает в качестве центрального звена любой информационной системы. Метаданные могут быть как частью ИР, так и храниться отдельно от него.
В связи с большой ролью информационных ресурсов в жизни современного общества и необходимостью создания различных информационных систем возникла необходимость классификации ИР. Существовавшие ранее системы классификации ИР, например, принятые в информационно-библиотечной деятельности, оказываются недостаточными в современных условиях.
Новый этап создания систем классификации информационных объектов начался в 1990-е годы и был вызван широким распространением Интернета. Одно из наиболее революционных воздействий Интернета на различные информационные отрасли заключалось в необходимости интеграции моделей и унификации подходов различных отраслей информационной индустрии. В результате возникла необходимость в создании единого языка, позволяющего описать многообразные типы информационных объектов, для создания возможности использования соответствующих программных приложений. Таким языком оказалась спецификация MIME (Multipurpose Internet Mail Extention), разработанная первоначально для электронной почты, но получившая распространение позже при возникновении web - технологий.
Дальнейшее развитие классификация типов информационных объектов получила в рамках Дублинского ядра метаданных (Dublin Core Metadata Element Set – DCMI) [30]. DCMI представляет собой инвариантную к предметной области композицию наиболее общих полей описания ИР, введенную для обеспечения глобальной интероперабельности приложений, работающих с метаданными (т.е. способности приложений обмениваться информацией друг с другом и совместно использовать информацию, которой они обмениваются). Всего в рамках этой системы выделено девять типов ИР. Ниже приводится перечень типов с определениями, принятыми разработчиками.
· Коллекция. Множество, содержащее элементы. Ресурс описывается как группа, части ресурса могут быть описаны отдельно, к ним осуществлен отдельный доступ.
· Данные. Информация представлена в определенной структуре (например, списки, таблицы, базы данных), обеспечивающей возможность прямой машинной обработки.
· Событие. Непродолжительное, ограниченное во времени явление. Метаданные для события могут определять цель, место, длительность, субъектов события и связи с другими событиями и ресурсами. Примером являются выставки, конференции, семинары, презентации, представления, дискуссия и др.
· Изображение. Ресурс, первично предназначенный служить для визуального представления, отличного от текста. К данному типу относятся изображения и фотографии физических объектов, рисунки, чертежи, мультипликация, фильмы, диаграммы, карты, музыкальная нотация.
· Интерактивный объект. Объект данного типа требует взаимодействия с пользователем для того, чтобы быть понятым, исполненным или реализованным. Примеры: интерактивные формы на web-страницах, апплеты, обучающие средства, чаты, виртуальная реальность.
· Сервис. Система, которая выполняет одну или более функцию для конечного пользователя. Примеры: службы фотокопирования, банковский сервис, служба аутентификации, межбиблиотечный абонемент, web -сервер.
· Программные средства. Компьютерная программа в исходном или компилированном коде, которая пригодна в неизменном виде для инсталляции на другой машине.
· Аудио. Ресурс, первоначально предназначенный служить для звукового представления. Например, аудиокомпакт – диск, запись речи или звуков.
· Текст. Ресурс, первоначально представляющий собой слова для чтения (книги, письма, газеты, стихи, статьи, диссертации, рукописи).
Данная классификация является, несомненно, результатом длительных дискуссий, в которых принимали участие высококвалифицированные специалисты многих стран, и потому она имеет будущее. Однако пока эта классификация выглядит довольно непривычно: трудно признать видом информационного ресурса банковское обслуживание, web-сервер или событие реального мира.
1.4 Определение количества информации
В классической теории информации под словом информация подразумеваются данные. Известно, по крайней мере, два определения количества информации. Оба определения очень близки между собой, принципиальное различие между ними появляется лишь при попытке ввести смысловое содержание информации. Первое определение (по Шеннону) рассматривает процесс передачи и переработки информации с вероятностной точки зрения, второе (по Хартли) использует комбинаторный подход.
Исходная гипотеза при определении количества информации по Шеннону – чем больше неопределенности в принятом сообщении, тем больше информации в нем содержится. Поэтому количество информации J определяют следующим образом:
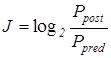 . (1)
. (1)
Здесь 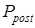 – вероятность некоторого события после поступления информации в систему,
– вероятность некоторого события после поступления информации в систему,
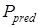 – вероятность того же события до поступления информации в систему.
– вероятность того же события до поступления информации в систему.
Если шумы отсутствуют, то можно считать, что вероятность данного события после поступления сообщения на вход системы 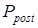 равна единице, тогда
равна единице, тогда
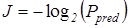 . (2)
. (2)
Для измерения количества информации введена специальная единица измерения, которая называется бит (bit = binary digit). Количество информации J в битах равно правой части приведенных выше определений.
Примеры
При наличии двух равновероятных событий в отсутствии шумов при 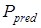 =1/2 количество переданной информации равно
=1/2 количество переданной информации равно
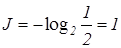 бит.
бит.
Если же до поступления информации вероятность оценивалась величиной =1/8, то количество переданной информации будет больше:
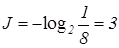 бит.
бит.
Возможны и другие определения количества информации.
Рассмотрим комбинаторное определение информации, предложенное Хартли. Сообщение, как правило, набирается или составляется из символов или элементов: буквенного алфавита, цифр, слов или фраз, названий цвета, предметов и так далее. Обозначим общее число символов в алфавите через т. Например, если сообщение формируется из двух независимо и равновероятно появляющихся символов, то нетрудно видеть, что число возможных комбинаций равно 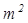 . Действительно, зафиксировав один из двух символов сообщения
. Действительно, зафиксировав один из двух символов сообщения 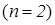 и комбинируя его со всеми возможными т символами алфавита, получим
и комбинируя его со всеми возможными т символами алфавита, получим 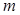 различных сообщений. После этого фиксируем следующий символ алфавита и снова его комбинируем со всеми символами алфавита, получим еще т сообщений. С учетом предыдущего имеем 2т сообщений. Продолжив этот процесс до тех пор, пока не будет зафиксирован последний из т символов алфавита, получим всего mm=т2 сообщений. В общем случае, если сообщение содержит п элементов (п — длина сообщения), число возможных сообщений
различных сообщений. После этого фиксируем следующий символ алфавита и снова его комбинируем со всеми символами алфавита, получим еще т сообщений. С учетом предыдущего имеем 2т сообщений. Продолжив этот процесс до тех пор, пока не будет зафиксирован последний из т символов алфавита, получим всего mm=т2 сообщений. В общем случае, если сообщение содержит п элементов (п — длина сообщения), число возможных сообщений
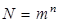 .
.
Пример. Предположим, имеется набор из трех букв А, В, С, а сообщение формируется из двух.
Согласно приведенной выше формуле, число возможных сообщений будет АА, ВА, СА, АВ, ВВ, СВ, АС, ВС, СС, т. е. N = 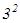 = 9.
= 9.
Однако нетрудно видеть, что это выражение неудобно брать в качестве меры количества информации, так как, во-первых, если все множество или ансамбль возможных сообщений состоит из одного сообщения (N = 1), то информация в нем должна отсутствовать, во-вторых, если есть два независимых источника сообщений, каждый из которых имеет в своем ансамбле 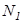 и
и 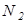 сообщений, то общее число возможных сообщений от этих двух источников
сообщений, то общее число возможных сообщений от этих двух источников
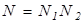
т. е. является произведением, тогда как количества информации должны складываться, и общее количество должно быть прямо пропорционально числу символов в сообщении. Поэтому за количество информации берут двоичный логарифм числа возможных сообщений
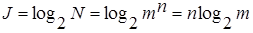 . (3)
. (3)
Можно показать, что при равновероятном появлении символов формулы (1) и (3) эквивалентны.
В нашем примере n =2, m=3, количество информации J = 2log2 3 = 3.17 бит.
Определение информатики
 Академик В. М. Глушков (1923 – 1982) определил информатику следующим образом: "Понятие информатики охватывает области, связанные с разработкой, созданием, использованием и материально-техническим обслуживанием системы обработки информации, включая машины, оборудование, математическое обеспечение, организационные аспекты, а также комплекс промышленного, коммерческого, административного, социального и политического воздействия". Объектом информатики как науки является информация.
Академик В. М. Глушков (1923 – 1982) определил информатику следующим образом: "Понятие информатики охватывает области, связанные с разработкой, созданием, использованием и материально-техническим обслуживанием системы обработки информации, включая машины, оборудование, математическое обеспечение, организационные аспекты, а также комплекс промышленного, коммерческого, административного, социального и политического воздействия". Объектом информатики как науки является информация.
Структура информатики
Информатика представляет собой единство разнообразных отраслей науки, техники и производства, связанных с переработкой информации главным образом с помощью компьютеров и телекоммуникационных средств связи во всех сферах человеческой деятельности. Историю информатики можно рассматривать, как историю ее отдельных структурных единиц. В структуре информатики выделим следующие компоненты.
Теоретическая информатика – часть информатики, включающая ряд математических разделов. Она опирается на математическую логику и включает такие разделы как теория алгоритмов и автоматов, теория информации и теория кодирования, теория формальных языков и грамматик, исследование операций и другие. Этот раздел информатики использует математические методы для общего изучения процессов обработки информации.
Информационные системы – раздел информатики, связанный с решением вопросов по анализу потоков информации в различных сложных системах, их оптимизации, структурировании, принципах хранения и поиска информации. Информационно-справочные системы, информационно-поисковые системы, гигантские современные глобальные системы хранения и поиска информации привлекают внимание все большего круга пользователей.
Искусственный интеллект – область информатики, в которой решаются сложнейшие проблемы, находящиеся на пересечении с психологией, физиологией, лингвистикой и другими науками. Поскольку мы далеко не все знаем о том, как мыслит человек, исследования по искусственному интеллекту, несмотря на полувековую историю, все еще не привели к решению ряда принципиальных проблем. Основные направления разработок, относящихся к этой области – моделирование рассуждений, компьютерная лингвистика, машинный перевод, создание экспертных систем, распознавание образов и другие. В качестве составных частей информатики можно рассматривать вычислительную технику и программирование, но поскольку эти компоненты являются особенно важными в контексте разрабатываемой программы, они будут рассмотрены в отдельных разделах. Здесь приведем только их краткую характеристику.
Вычислительная техника – область информатики, в котором разрабатываются общие принципы построения вычислительных систем. Речь идет не о технических деталях и электронных схемах (это лежит за пределами информатики как таковой), а о принципиальных решениях на уровне, так называемой, архитектуры вычислительных (компьютерных) систем, определяющей состав, назначение, функциональные возможности и принципы взаимодействия устройств. Примеры принципиальных, ставших классическими решений в этой области – неймановская архитектура компьютеров первых поколений, шинная архитектура ЭВМ старших поколений, архитектура параллельной (многопроцессорной) обработки информации.
Программирование и программная инженерия – деятельность, связанная с разработкой систем программного обеспечения. Здесь отметим лишь основные разделы современного программирования: создание системного программного обеспечения и создание прикладного программного обеспечения. Среди системного – разработка новых языков программирования и компиляторов к ним, разработка интерфейсных систем.
Информационные системы
Информационной системой называется комплекс, включающий вычислительное и коммуникационное оборудование, программное обеспечение, лингвистические средства и информационные ресурсы, а также системный персонал и обеспечивающий поддержку динамической информационной модели некоторой части реального мира для удовлетворения информационных потребностей пользователей. Часть реального мира, которая моделируется информационной системой, называется ее предметной областью. Под динамической моделью здесь понимается изменяемость модели во времени. Это «живая», действующая модель, в которой отображаются изменения, происходящие в предметной области. Такая система должна обладать памятью, позволяющей ей сохранять не только сведения о текущем состоянии предметной области, но и в некоторых случаях предысторию. Поскольку модель предметной области, поддерживаемая информационной системой, материализуется в форме организованных необходимым образом информационных ресурсов, она называется информационной моделью. Информационная система может входить в качестве компонента (подсистемы) в более сложную систему, такую, например, как система управления торговой компанией, САПР или система управления производством. Информационные системы уже многие десятки и даже сотни лет существуют и используются на практике в форме различного рода картотек и/или коллекций бумажных документов. Однако в таких системах отсутствует какая-либо автоматизация обработки данных, они позволяют лишь регистрировать и поддерживать в систематизированной форме на бумажных носителях результаты произведенных натурных измерений. В настоящее время под информационными системами, как правило, подразумеваются автоматизированные информационные системы, осуществляющие в том числе и функции автоматической обработки данных. Информационные системы используют ресурсы нескольких категории — средства вычислительной техники, системное и прикладное программное обеспечение, информационные, лингвистические и человеческие ресурсы. Лингвистические ресурсы информационных систем служат для: представления информационных ресурсов в системе; описания их свойств и свойств окружающей среды, позволяющего системе адекватно интерпретировать поддерживаемые информационные ресурсы; обеспечения взаимодействия пользователей с системой.
В общем случае к числу лингвистических ресурсов относятся те или иные естественные или искусственные языки, а также средства их лингвистической поддержки — словари лексики естественных языков, тезаурусы предметной области, переводные словари и др. Следует отметить, что тезаурусы играют в информационных системах двоякую роль. С одной стороны, это средство лингвистической поддержки используемого в системе естественного языка. Поэтому он должен быть отнесен к категориям лингвистических ресурсов. Вместе с тем тезаурус используется как контекст для интерпретации семантики поддерживаемых в системе документов, представленных на естественном языке. В связи с этим правомерно также считать тезаурус информационным ресурсом системы. Используемый в конкретных случаях набор лингвистических ресурсов системы зависит от требований, предъявляемых к ней. Информационные ресурсы системы составляют главный компонент модели предметной области, которую система поддерживает. Они являются вместе с тем «сырьем» и «конечным продуктом» работы информационной системы. Конкретный вид информационных ресурсов зависит от характера системы. Важно заметить, что в любой информационной системе поддерживается две категории информационных ресурсов. Ресурсы первой категории непосредственно используются конечными пользователями системы. Ресурсы второй категории можно было бы назвать метаресурсами. Описывая свойства ресурсов первой категории, они позволяют системе корректно оперировать ими. Как уже отмечалось, ресурсы первой категории часто называют данными независимо от среды их представления (изображения, текстовые документы, аудиозаписи и т.д.), а метаресурсы — метаданными. Используя эту терминологию, можно сказать, что метаданные — это данные о данных. Однако фактически метаданные могут описывать свойства не только собственно данных, но и информационной системы в целом отдельных ее механизмов и их функций, других ее ресурсов, поддерживаемых технологий, пользователей и т.д. Конкретные функции метаданных и их состав в значительной мере зависят от специфики рассматриваемой сие темы и характера конкретных информационных ресурсов. Уместно вспомнить, что данные в информационной системе представляют собой некоторую абстрактную модель реальности. Рассматривая соотношение между данными и метаданными, можно сказать, что метаданные — это данные более высокого уровня абстракции по отношению к описываемым ими данным.
Необходимая степень формализованности представления метаданных в информационной системе зависит от характера их использования. Метаданные, предназначенные для компьютерного использования, представляются в формализованном виде. Если же они предназначены для пользователей, то чаще всего представляются на естественном языке. В системах, основанных на технологиях баз данных, поддерживаются структурированные данные, организованные в виде таблиц или каких-либо иных структур данных. К информационным ресурсам систем баз данных относятся также и схемы баз данных. В таких системах они относятся к категории метаданных. В текстовых системах информационные ресурсы включают коллекции документов, представленных на естественных языках. Это информационные ресурсы для конечных пользователей. Кроме того, поддерживаются метаданные — тезаурусы, спецификации онтологии и т.п., которые являются информационными ресурсами, используемыми самой системой.
Искусственный интеллект
Исследователи, работающие в этом направлении, надеются достичь такого понимания механизмов интеллекта, при котором можно будет составлять компьютерные программы с человеческим или более высоким уровнем интеллекта. Общий подход состоит в разработке методов решения задач, для которых отсутствуют формальные алгоритмы: понимание естественного языка, обучение, доказательство теорем, распознавание сложных образов и т.д. Теоретические исследования направлены на изучение интеллектуальных процессов и создание соответствующих математических моделей. Экспериментальные работы ведутся путем составления компьютерных программ и создания машин, решающих частные интеллектуальные задачи или разумно ведущих себя в заданной ситуации. Систематические исследования в области искусственного интеллекта начались лишь с появлением цифрового компьютера. Первая научная статья по искусственному интеллекту была опубликована в 1950 г. А. Тьюрингом. Ниже будут указаны основные направления исследований в области искусственного интеллекта и соответствующие методы.
Представление знания.
Многие трудности при создании машин, выполняющих определенные интеллектуальные задачи, связаны с вопросами о том, какую информацию должна иметь программа, каким образом на основании этой исходной информации могут быть сделаны дальнейшие выводы и как эта информация должна храниться в компьютере. Необходимостью решения этих проблем были вызваны к жизни исследования, цель которых – ответить на вопрос, что такое знание.
Представление знаний – вопрос, возникающий в когнитологии (науке о мышлении), в информатике и в исследованиях искусственного интеллекта. В когнитологии он связан с тем, как люди хранят и обрабатывают информацию. В информатике – с подбором представления конкретных и обобщённых знаний, сведений и фактов для накопления и обработки информации в ЭВМ. Главная задача в искусственном интеллекте – научиться хранить знания таким образом, чтобы программы могли осмысленно обрабатывать их и достигнуть тем подобия человеческого интеллекта. Под термином «представление знаний» чаще всего подразумеваются способы представления знаний, ориентированные на автоматическую обработку современными компьютерами, и, в частности, представления, состоящие из явных объектов и из суждений или утверждений о них. Представление знаний в подобной явной форме позволяет компьютерам делать дедуктивные выводы из ранее сохранённого знания. Существуют десятки моделей (или языков) представления знаний для различных предметных областей. Большинство из них может быть сведено к следующим классам: – продукционные; – семантические сети; – фреймы; – формальные логические модели.
Продукционная модель,
или модель, основанная на правилах, позволяет представить знания в виде предложений типа: если (условие), то (действие). Под, условием понимается некоторое предложение-образец, по которому осуществляется поиск в базе знаний, а под действием - действия, выполняемые при успешном исходе поиска (они могут быть промежуточными, выступающими далее как условия, и терминальными или целевыми, завершающими работу системы). При использовании продукционной модели база знаний состоит из набора правил, Программа, управляющая перебором правил, называется машиной вывода. Чаще всего вывод бывает прямой (от данных к поиску цели) или обратный (от цели для ее подтверждения - к данным). Данные – это исходные факты, на основании которых запускается машина вывода - программа, перебирающая правила из базы. Продукционная модель чаще всего применяется в промышленных экспертных системах. Она привлекает разработчиков своей наглядностью, высокой модульностью, легкостью внесения дополнений и изменений и простотой механизма логического вывода.
Семантические сети
Семантика – это наука, устанавливающая отношения между символами и объектами, которые они обозначают. Семантическая сеть – это ориентированный граф, вершины которого – понятия, а дуги – отношения между ними. Понятиями обычно выступают абстрактные или конкретные объекты, а отношения – это связи типа: "это" ("i t"), "имеет частью" ("has part"), "принадлежит", "любит" и т.д.. Характерной особенностью семантических сетей является обязательное наличие трех типов отношений: класс – элемент класса; свойство – значение; пример – элемента класса.
Проблема поиска решения в базе знаний типа семантической сети сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, отображающей поставленный вопрос. Основное преимущество этой модели – в соответствии современным представлениям об организации долговременной памяти человека. Недостаток модели – сложность поиска вывода на семантической сети.
Фрейм (англ. frame - каркас или рамка) – структура знаний для восприятия пространственных сцен. Под фреймом понимается абстрактный образ или ситуация. В психологии и философии известно понятие абстрактного образа. Например, слово "комната" вызывает у слушающих образ комнаты: "жилое помещение с четырьмя стенами, полом, потолком, окнами и дверью, площадью 6-20 м2 ". Из этого описания ничего нельзя убрать (например, убрав окна мы получим уже чулан, а не комнату), но в нем есть "дырки", или "слоты", – это незаполненные значения некоторых атрибутов: количество окон, цвет стен, высота потолка. покрытие пола и др. В теории фреймов такой образ называется фреймом. Фреймом называется также и формализованная модель для отображения образа. Модель фрейма является достаточно универсальной, поскольку позволяет отобразить все многообразие знаний о мире через:
· фреймы-структуры, для обозначения объектов и понятий (заем, залог, вексель);
· фреймы-роли (менеджер, кассир, клиент);
· фреймы-сценарии (банкротство, собрание акционеров, празднование именин);
· фреймы-ситуации (тревога, авария, рабочий режим устройства) и др.
Важнейшим свойством теории фреймов является заимствованное из теории семантических сетей наследование свойств. И во фреймах, и в семантических сетях наследование происходит по АКО-связям (A-Kind-Of = вроде этого). Слот АКО указывает на фрейм более высокого уровня иерархии, откуда неявно наследуются, т.е. переносятся, значения аналогичных слотов. Основным преимуществом фреймов как модели представления знаний является способность отражать концептуальную основу организации памяти человека, а также гибкость и наглядность.
Компьютерная лингвистика
Естественный язык, на котором в настоящее время представляется наибольший объем информации, является слишком сложной структурой. Проблемы языковой коммуникации "человек - компьютер - человек" и моделирования языка лежат в области исследований такой молодой науки, как компьютерная лингвистика, которая образовалась на стыке информатики и лингвистики. Компьютерная лингвистика, направление в прикладной лингвистике, ориентированное на использование компьютерных инструментов – программ, компьютерных технологий организации и обработки данных – для моделирования функционирования языка в тех или иных условиях, ситуациях, проблемных сферах и т.д., а также вся сфера применения компьютерных моделей языка в лингвистике и смежных дисциплинах. Как особое научное направление компьютерная лингвистика оформилась в 1960-е годы. Русский термин «компьютерная лингвистика» является калькой с английского computational linguistics. Поток публикаций в этой области очень велик. Компьютерная лингвистика как особая прикладная дисциплина выделяется прежде всего по инструменту – т. е. по использованию компьютерных средств обработки языковых данных. Сфера КЛ весьма разнообразна и включает такие области, как компьютерное моделирование общения, моделирование структуры сюжета, гипертекстовые технологии представления текста, машинный перевод, компьютерная лексикография. В узком смысле проблематика КЛ часто связывается с междисциплинарным прикладным направлением с несколько неудачным названием «обработка естественного языка» (перевод английского термина Natural Language Processing). Имевшее место в 1970-е годы возникновение и бурное развитие этого направления связано в первую очередь со стремительным ростом количества конечных пользователей ЭВМ. Поскольку обучение языкам и технологии программирования всех пользователей невозможно и нецелесообразно, возникла проблема организации взаимодействия конечных пользователей с компьютерными программами. Одним из способов решения этой задачи является разработка систем, позволяющих взаимодействовать с ЭВМ на естественном языке или каком-то ограниченном его варианте. Важнейшим направлением компьютерной лингвистики является разработка информационно-поисковых систем (ИПС). Последние возникли в конце 1950-х – начале 1960-х годов как ответ на резкое возрастание объемов научно-технической информации. По типу хранимой и обрабатываемой информации, а также по особенностям поиска ИПС разделяются на две больших группы – документальные и фактографические. В документальных ИПС хранятся тексты документов или их описания (рефераты, библиографические карточки и т.д.). Фактографические ИПС имеют дело с описанием конкретных фактов, причем не обязательно в текстовой форме. В настоящее время фактографические ИПС строятся на основе технологий баз данных (БД). Для обеспечения информационного поиска в ИПС создаются специальные информационно-поисковые языки, в основе которых лежат информационно-поисковые тезаурусы.
К области компьютерной лингвистики в определенной степени могут быть отнесены работы в области создания гипертекстовых систем, рассматриваемых как особый способ организации текста и даже как 16
принципиально новый вид текста, противопоставленный по многим своим свойствам обычному тексту, сформированному в гутенберговской традиции книгопечатания. В 1950-х годах составлялись программы компьютерного перевода с одного языка на другой. Они были не очень эффективны, и спустя несколько лет пришлось признать, что для успешного перевода необходимо, чтобы программа «понимала» текст, который переводит. В настоящее время прилагаются усилия к тому, чтобы наделить компьютеры более полным пониманием все больших и больших фрагментов и закономерностей естественного языка. Такое понимание оценивается по эффективности программ, отвечающих на вопросы по тексту на основании информации, содержащейся в тексте, и заложенной в программу «способности к рассуждению».
2.7 Информационные технологии
Технология при переводе с греческого означает искусство, мастерство, умение, а это ни что иное, как процессы. Под процессом следует понимать определенную совокупность действий, направленных на достижение поставленной цели. Процесс должен определяться выбранной человеком стратегией и реализоваться с помощью совокупности различных средств и методов.
Информационная технология – процесс, использующий совокупность средств и методов сбора, обработки и передачи данных (первичной информации) для получения информации нового качества о состоянии объекта, процесса или явления (информационного продукта).
Если цель технологии материального производства – выпуск продукции, удовлетворяющей потребности человека или системы, то цель информационной технологии – производство информации для ее анализа человеком и принятия на его основе решения по выполнению какого-либо действия. В последние годы появился термин новые информационные технологии, которым обозначаются технологии, основанные на использовании компьютерных и телекоммуникационных средств.
Можно выделить три основных принципа новых информационных технологий:
· интерактивный (диалоговый) режим работы с компьютером и телекоммуникационной системой;
· интегрированность с другими программными продуктами;
· гибкость процесса изменения как данных, так и постановок задач.
В настоящее время область информационных технологий представляет собой:
· обширную область знаний, имеющую фундаментальный характер, которая объединяет множество научных направлений таких как вычислительная математика, искусственный интеллект, программная инженерия, веб-технологии и другие;
· важную часть информационной индустрии и обширную область профессиональной деятельности, влияющую на все процессы современного общества;
· актуальное и активно развивающееся образовательное направление – Информатика и вычислительная техника ( Computing ), к которому относится, в том числе, и интересующие нас направления 09.03.01 и 09.03.04.
В качестве критериев классификации информационных технологий используют виды управленческой деятельности, виды обеспечения или реализуемые функции. В наиболее общем виде применительно к данному курсу можно выделить для дальнейшего рассмотрения следующие классы информационных технологий:
· информационные сетевые компьютерные технологии;
· информационные технологии организации человеко-машинного интерфейса;
· информационные технологии создания, обработки и управления документами;
· информационные технологии управления данными;
· технологии защиты информации;
· информационные технологии управления знаниями.
О становлении информационных технологий
Упомянем основные события, предшествовавшие и способствовавшие созданию информационных систем и технологий.
· В 1944 году в США создана первая электронно-вычислительная машина UNIVAC, которая открыла возможность быстрой обработки больших объемов данных.
· В 1948 году Клод Шеннон сформулировал основные положения математической теории связи, положенные в дальнейшем в фундамент теории информации.
· В те же годы Норберт Винер показал прикладные аспекты этой теории в своей книге «Кибернетика или управление и связь в животном и машине».
· В 1951 году под руководством академика С.А. Лебедева создана первая отечественная электронно-вычислительная машина МЭСМ. В следующем году создана ЭВМ БЭСМ, которая стала первой серийно выпускаемой машиной в нашей стране.
· В начале 50-х годов инженеры фирмы Веll Laboratories изобрели транзистор, что привело к появлению новых поколений ЭВМ и вызвало проникновение информационных технологий в различные области жизни, науки, образования и техники.
· В середине 50-х годов начались работы по автоматизации программирования. А. А. Ляпуновым был предложен язык логических схем программ для операторного программирования. Тогда же были разработаны первые версии языков программирования (Фортран, Алгол) и созданы соответствующие трансляторы. В 1960 году в качестве международного стандарта был принят язык Алгол-60.
· В начале 60-х годов в США разработана система COBOL, явившаяся прототипом систем управления базами данных (СУБД).
· В 60-е годы началась автоматизация простейших производственных функций, появились первые локальные системы управления в крупных фирмах для решения регулярных задач высокой размерности, в основном информационного и справочного характера, отдельные решения задач оптимального распределения ресурсов и т. д. В СССР начали создаваться автоматизированные системы управления предприятиями (АСУП).
· В 1962 году академик В. М. Глушков предложил проект Общегосударственной автоматизированной системы (ОГАС) для управления экономикой страны на базе сети вычислительных центров и систем широкополосной связи. Техническую основу ОГАС должна была составить Единая государственная сеть вычислительных центров (ЕГСВЦ), охватывающая всю страну. К сожалению, этот проект не был реализован. Кстати, В. М. Глушков первым предложил термин «безбумажная информатика».
· 1967 – черный год отечественной вычислительной техники. На правительственном уровне было принято решение о копировании американских ЭВМ IBM/360 (копии получили название ЕС ЭВМ), а многие отечественные проекты были заморожены. Это привело к ослаблению научно-технической базы в области информационных технологий и нарастающей зависимости страны от зарубежных разработок.
· 1970-е годы – первые интегрированные комплексы, работающие в пакетном режиме, повышение уровня интеллектуальности решаемых задач, формирование первых систем цифровой связи, отработка комплексных решений автоматизации управления предприятием, начало формирования современной концепции новых информационных технологий.
· 1980-е годы – появление персональных ЭВМ и локальных вычислительных сетей; расширение использования информационных технологий на основе распределённых систем, реальное воздействие элементов новых информационных технологий на всех участников производственных процессов; непосредственное влияние на процессы принятия решений высшим руководством фирм. Развития систем управления качеством на базе стандартов ISO 900х, рождение CASE- и CALS-технологий.
· 1990-е годы – появление и широкое распространение Интернет; интеграция информационных технологий в различных областях; на базе новых информационных технологий бурно развивается международная интеграция бизнеса и электронная коммерция; совместное использование данных и обмен информацией изменяют общество, возникают новые парадигмы организации производства, стандарты реконфигурации и управления проектами, внедрение технологий реинжиниринга и виртуального предприятия.
· 1994 г. – в Неаполе лидеры стран Большой семерки подчеркнули необходимость разработки всемирных проектов информационного общества, создания системы стандартов в области информационных технологий.
Германия
В 1936 году Конрад Цузе начал работу над своим первым вычислителем серии Z, имеющим память и (пока ограниченную) возможность программирования. Созданная, в основном, на механической основе, но уже на базе двоичной логики, модель Z1, завершенная в 1938 году, так и не заработала достаточно надѐжно, из-за недостаточной точности выполнения составных частей. В 1939 году Цузе создал второй вычислитель Z2, но еѐ планы и фотографии были уничтожены при бомбардировке во время Второй Мировой Войны поэтому о ней почти ничего не известно. Z2 работала на электромагнитных переключателях, созданных в 1835 году ученым Джозефом Хенри. Следующая машина Цузе – Z3, была завершена в 1941 году. Она была построена на телефонных реле и работала вполне удовлетворительно. Тем самым, Z3 стала первым работающим компьютером, управляемым программой. Во многих отношениях Z3 была подобна современным машинам, в ней впервые был представлен ряд новшеств, таких как арифметика с плавающей запятой. Замена сложной в реализации десятичной системы на двоичную, сделала машины Цузе более простыми и, а значит, более надѐжными; считается, что это одна из причин того, что Цузе преуспел там, где Бэббидж потерпел неудачу. Программы для Z3 хранились на перфорированной плѐнке. Условные переходы отсутствовали, но в 1990-х было теоретически доказано, что Z3 является универсальным компьютером (если игнорировать ограничения на размер физической памяти). В двух патентах 1936 года, Конрад Цузе упоминал, что машинные команды могут храниться в той же памяти что и данные – предугадав тем самым то, что позже стало известно как архитектура фон Неймана.
Великобритания
Во время Второй мировой войны Великобритания достигла определѐнных успехов во взломе зашифрованных немецких переговоров. Код немецкой шифровальной машины Lorenz SZ 40/42 использовалась для армейской связи высокого уровня. Первые перехваты передач с таких машин были зафиксированы в 1941 году. Для взлома этого кода была создана машина «Колосс» (Colossus). «Колосс» стал первым полностью электронным вычислительным устройством. В нѐм использовалось большое количество электровакуумных ламп, ввод информации выполнялся с перфоленты. «Колосс» можно было настроить на выполнение различных операций булевой логики, но он не являлся тьюринг-полной машиной. Информация о существовании этой машины держалась в секрете до 1970-х гг. Уинстон Черчилль лично подписал приказ о разрушении машины. Из-за своей секретности «Колосс» не упомянут во многих трудах по истории вычислительной техники.
Соединенные штаты Америки
В 1937 году Клод Шеннон показал, что существует соответствие один-к-одному между концепциями булевой логики и некоторыми электронными схемами, которые получили название «логические вентили», которые в настоящее время повсеместно используются в цифровых компьютерах. Он продемонстрировал, что электронные связи и переключатели могут представлять выражение булевой алгебры. Так своей работой "A Symbolic Analysis of Relay and Switching Circuits" он создал основу для практического проектирования цифровых схем. В ноябре 1937 года Джорж Стибиц завершил в Bell Labs создание компьютера «Model K» на основе релейных переключателей. В 1939 году в Endicott laboratories в IBM началась работа над Harvard Mark I. Официально известный как Automatic Sequence Controlled Calculator, Mark I был электромеханическим компьютером общего назначения, созданного с финансированием IBM и при помощи со стороны персонала IBM, под руководством гарвардского математика Howard Aiken. Mark I был перенесѐн в Гарвардский университет и начал работу в мае 1944 года.
Первое поколение (1937–1953)
На роль первой в истории электронной вычислительной машины в разные периоды претендовало несколько разработок. Общим у них было использование схем на базе электронно-вакуумных ламп вместо электромеханических реле. Предполагалось, что электронные ключи будут значительно надежнее, поскольку в них отсутствуют движущиеся части, однако технология того времени была настолько несовершенной, что по надежности электронные лампы оказались ненамного лучше, чем реле. Однако у электронных компонентов имелось одно важное преимущество: выполненные на них ключи могли переключаться примерно в тысячу раз быстрее своих электромеханических аналогов. Первой электронной вычислительной машиной чаще всего называют специализированный калькулятор ABC (Atanasoff–Berry Computer). Разработан он был в период с 1939 по 1942 год профессором Джоном Атанасовым (John V. Atanasoff, 1903–1995). ABC обладал памятью на 50 слов длиной 50 бит, а запоминающими элементами служили конденсаторы с цепями регенерации. В качестве вторичной памяти использовались перфокарты, где отверстия не перфорировались, а прожигались. Другой кандидат на роль первой электронной ВМ —программируемый электронный калькулятор общего назначения ENIAC (Electronic Numerical Integrator and Computer — электронный цифровой интегратор и вычислитель). Идея калькулятора, выдвинутая в 1942 году Джоном Мочли (John J. Mauchly, 1907–1980) из университета Пенсильвании, была реализована им совместно с Преспером Эккертом (J. Presper Eckert, 1919–1995) в 1946 году. Использовалась десятичная система счисления. Программа задавалась схемой коммутации триггеров на 40 наборных полях. При пробной эксплуатации выяснилось, что надежность машины чрезвычайно низка — поиск неисправностей занимал от нескольких часов до нескольких суток.
В Советском Союзе в 1947 году под руководством С. А. Лебедева (1902 – 1974) начаты работы по созданию малой электронной счетной машины (МЭСМ). Эта машина была запущена в эксплуатацию в 1951 году и стала первой электронной ВМ в СССР и континентальной Европе.
 В 1952 году Эккерт и Мочли создали первую коммерчески успешную машину UNIVAC. Также в 1952 году в опытную эксплуатацию была запущена вычислительная машина М-1 (И. С. Брук, Н. Я. Матюхин, А. Б. Залкинд). М-1 содержала 730 электронных ламп, оперативную память емкостью 256 25-разрядных слов, рулонный телетайп и обладала производительностью 15–20 операций/с. Впервые была применена двухадресная система команд. Чуть позже группой выпускников МЭИ под руководством И. С. Брука создана машина М-2 с емкостью оперативной памяти 512 34-разрядных слов и быстродействием 2000 операций/с.
В 1952 году Эккерт и Мочли создали первую коммерчески успешную машину UNIVAC. Также в 1952 году в опытную эксплуатацию была запущена вычислительная машина М-1 (И. С. Брук, Н. Я. Матюхин, А. Б. Залкинд). М-1 содержала 730 электронных ламп, оперативную память емкостью 256 25-разрядных слов, рулонный телетайп и обладала производительностью 15–20 операций/с. Впервые была применена двухадресная система команд. Чуть позже группой выпускников МЭИ под руководством И. С. Брука создана машина М-2 с емкостью оперативной памяти 512 34-разрядных слов и быстродействием 2000 операций/с.
В апреле 1953 года в эксплуатацию вступила самая быстродействующая в Европе большая электронно-счетная машина БЭСМ-1, созданная под руководством С. А. Лебедева. Ее быстродействие составило 8000–10000 операций/с. Всего же под руководством С.А. Лебедева в последующие годы были созданы 15 типов ЭВМ, начиная с ламповых (БЭСМ-1, БЭСМ-2, М-20) и заканчивая современными суперкомпьютерами на интегральных схемах (БЭСМ-6, ЭЛЬБРУС).
Второе поколение (1954–1962)
Второе поколение характеризуется рядом достижений в элементной базе, структуре и программном обеспечении. Принято считать, что поводом для выделения нового поколения ВМ стали технологические изменения, и, главным образом, переход от электронных ламп к полупроводниковым диодам и транзисторам со временем переключения порядка 0,3 мс. Первой ВМ, выполненной полностью на полупроводниковых диодах и транзисторах, стала TRADIC (TRAnisitor DIgital Computer), построенная в Bell Labs по заказу военно-воздушных сил США как прототип бортовой ВМ. Машина состояла из 700 транзисторов и 10 000 германиевых диодов. За два года эксплуатации TRADIC отказали только 17 полупроводниковых элементов, что говорит о прорыве в области надежности, по сравнению с машинами на электронных лампах. Со вторым поколением ВМ ассоциируют еще одно принципиальное технологическое усовершенствование — переход от устройств памяти на базе ртутных линий задержки к устройствам на магнитных сердечниках. В запоминающих устройствах (ЗУ) на линиях задержки данные хранились в виде акустической волны, непрерывно циркулирующей по кольцу из линий задержки, а доступ к элементу данных становился возможным лишь в момент прохождения соответствующего участка волны вблизи устройства считывания/записи. Главным преимуществом ЗУ на магнитных сердечниках стал произвольный доступ к данным, когда в любой момент доступен любой элемент данных, причем время доступа не зависит от того, какой это элемент. Технологический прогресс дополняют важные изменения в архитектуре ВМ. Прежде всего, это касается появления в составе процессора ВМ индексных регистров, что позволило упростить доступ к элементам массивов. Вторым принципиальным изменением в структуре ВМ стало добавление аппаратного блока обработки чисел в формате с плавающей запятой. Третье значимое нововведение в архитектуре ВМ — появление в составе вычислительной машины процессоров ввода/вывода, позволяющих освободить центральный процессор от рутинных операций по управлению вводом/выводом. Ко второму поколению относятся и две первые суперЭВМ, разработанные для ускорения численных вычислений в научных приложениях: LARC (Livermore Atomic Research Computer) и IBM 7030. Помимо прочего, в этих ВМ нашли воплощение еще две новинки: совмещение операций процессора с обращением к памяти и простейшие формы параллельной обработки данных. Заметным событием данного периода стало появление в 1958 году машины М-20. В этой ВМ, в частности, были реализованы: частичное совмещение операций, аппаратные средства поддержки программных циклов, возможность параллельной работы процессора и устройства вывода. Оперативная память емкостью 4096 45 разрядных слов была выполнена на магнитных сердечниках. Шестидесятые годы XX века стали периодом бурного развития вычислительной техники в СССР. За этот период разработаны и запущены в производство вычислительные машины «Урал-1», «Урал-4», «Урал-11», «Урал-14», БЭСМ-2, М-40, «Минск-1», «Минск-2», «Минск-22», «Минск-32». В 1960 году под руководством В. М. Глушкова и Б. Н. Малиновского разработана первая полупроводниковая управляющая машина «Днепр».
Третье поколение (1963–1972)
Третье поколение ознаменовалось резким увеличением вычислительной мощности ВМ, ставшим следствием больших успехов в области архитектуры, технологии и программного обеспечения. Основные технологические достижения связаны с переходом от дискретных полупроводниковых элементов к интегральным микросхемам и началом применения полупроводниковых запоминающих устройств, начинающих вытеснять ЗУ на магнитных сердечниках. В первых ВМ третьего поколения использовались интегральные схемы с малой степенью интеграции (small-scale integrated circuits, SSI), где на одном кристалле размещается порядка 10 транзисторов. Ближе к концу рассматриваемого периода на смену SSI стали приходить интегральные схемы средней степени интеграции (medium-scale integrated circuits, MSI), в которых число транзисторов на кристалле увеличилось на порядок. К этому же времени относится повсеместное применение многослойных печатных плат. Все шире востребуются преимущества параллельной обработки, реализуемые за счет множественных функциональных блоков, совмещения во времени работы центрального процессора и операций ввода/вывода, конвейеризации потоков команд и данных.
В 1964 году Сеймур Крей (Seymour Cray, 1925–1996) построил вычислительную систему CDC 6600, в архитектуру которой впервые был заложен функциональный параллелизм. Благодаря наличию 10 независимых функциональных блоков, способных работать параллельно, и 32 независимых модулей памяти удалось достичь быстродействия в 1 MFLOPS (миллион операций с плавающей запятой в секунду). Пятью годами позже Крей создал CDC 7600 с конвейеризированными функциональными блоками и быстродействием 10 MFLOPS. CDC 7600 называют первой конвейерной вычислительной системой (конвейерным процессором). Революционной вехой в истории ВТ стало создание семейства вычислительных машин IBM 360, архитектура и программное обеспечение которых на долгие годы служили эталоном для последующих больших универсальных ВМ (mainframes). В машинах этого семейства нашли воплощение многие новые для того периода идеи, в частности: предварительная выборка команд, отдельные блоки для операций с фиксированной и плавающей запятой, конвейеризация команд, кэш-память. К третьему поколению ВС относятся также первые параллельные вычислительные системы: SOLOMON корпорации Westinghause и ILLIAC IV – совместная разработка Иллинойского университета и компании Burroughs.
Среди вычислительных машин, разработанных в этот период в СССР, прежде всего необходимо отметить «быстродействующую электронно-счетную машину» — БЭСМ-6 (С. А. Лебедев) с производительностью 1 млн операций/с. Продолжением линии М-20 стали М-220 и М-222 с производительностью до 200 000 операций/с. Оригинальная ВМ для инженерных расчетов «Мир-1» была создана под руководством В. М. Глушкова. В качестве входного языка этой ВМ использован язык программирования высокого уровня «Аналитик», во многом напоминающий язык Алгол.
Пятое поколение (1985 - ???)
Компьютеры пятого поколения – широкомасштабная правительственная программа в Японии по развитию компьютерной индустрии и искусственного интеллекта, предпринятая в 1980-е годы. Целью программы было создание cуперкомпьютера c мощными функциями искусственного интеллекта. Если предыдущие поколения совершенствовались за счёт увеличения количества элементов на единицу площади (миниатюризации), компьютеры пятого поколения должны были интегрировать огромное количество процессоров. Ход разработок представлялся так, что компьютерный интеллект, набирая мощность, начинает изменять сам себя, и целью было создать такую компьютерную среду, которая сама начнёт производить следующую. Для резкого увеличения производительности предлагалось постепенно заменять программные решения аппаратными, поэтому не делалось резкого разделения между задачами для программной и аппаратной базы. Проекты в области параллельной обработки данных тут же начали разрабатывать в других странах. Последующие десять лет проект «компьютеров пятого поколения» стал испытывать ряд трудностей разного типа. Технологии 80-х годов быстро перескочили те барьеры, которые перед началом проекта считались «очевидными» и непреодолимыми. Идея саморазвития системы, по которой система сама должна менять свои внутренние правила и параметры, оказалась непродуктивной. Идея широкомасштабной замены программных средств аппаратными оказалась в корне неверной, в дальнейшем развитие компьютерной индустрии пошло по противоположному пути. С любых точек зрения проект можно считать абсолютным провалом. С этого момента формальный отсчет поколений компьютеров прекращен.
Принципы фон Неймана
В качестве узловых моментов, определяющих появление нового поколения ВТ, обычно выбираются революционные идеи или технологические прорывы, кардинально изменяющие дальнейшее развитие средств автоматизации вычислений. Одной из таких идей принято считать концепцию построения ЭВМ, сформулированную математиком Джоном фон Нейманом (1903 – 1957). Взяв ее за точку отсчета, историю развития ВТ можно представить в виде трех этапов:
· донеймановского периода;
· фон-неймановской архитектуры;
· постнеймановской эпохи – эпохи параллельных и распределенных
вычислений.

|
| Джон фон Нейман |
Принципы Фон-Неймана тесно связаны с понятием архитектура ЭВМ. Архитектура – это наиболее общие принципы построения ЭВМ, реализующие программное управление работой и взаимодействием основных ее функциональных узлов. К архитектуре относятся:
· структура памяти ЭВМ;
· способы доступа к памяти и внешним устройствам;
· возможность изменения конфигурации компьютера;
· система команд;
· форматы данных;
· организация интерфейса.
Впервые термин «архитектура вычислительной машины» (computer architecture) был использован фирмой IBM при разработке машин семейства IBM 360 для описания тех средств, которыми может пользоваться программист, составляя программу на уровне машинных команд.
Наличие заданного набора исполняемых программ было основной особенностью архитектур первых, до-неймановских компьютерных систем. Их программирование всѐ-таки выполнялось, однако требовало огромного объѐма ручной работы по подготовке новой документации, перекоммутации и перестройки блоков и устройств и т. п. Всѐ изменила идея хранения компьютерных программ в общей памяти. Основы учения об архитектуре вычислительных машин заложил выдающийся американский математик Джон фон Нейман. Он подключился к созданию первой в мире ламповой ЭВМ ENIAC в 1944 г., когда ее конструкция была уже выбрана. В процессе работы во время многочисленных дискуссий со своими коллегами Г. Голдстайном и А. Берксом фон Нейман высказал идею принципиально новой ЭВМ. В 1946 г. ученые изложили свои принципы построения вычислительных машин в ставшей классической статье – «Предварительное рассмотрение логической конструкции электронно-вычислительного устройства». С тех пор прошло полвека, но выдвинутые в ней положения сохраняют актуальность и сегодня. Принципы фон Неймана:
· использование двоичной системы счисления для представления данных и команд;
· однородность памяти: как программы (команды), так и данные хранятся в одной и той же памяти; над командами можно выполнять такие же действия, как и над данными;
· адресуемость памяти: основная память состоит из пронумерованных ячеек; процессору в произвольный момент времени доступна любая ячейка;
· последовательное программное управление: программа состоит из набора команд, которые располагаются в памяти и выполняются
· процессором друг за другом в определенной последовательности, одна после завершения другой;
· принцип условного перехода: в определенных ситуациях последовательное исполнение команд может быть нарушено.
Первыми пятью компьютерами, в которых были реализованы основные особенности архитектуры фон Неймана, были:
· Манчестерский Марк I. Прототип – Манчестерская малая экспериментальная машина. Университет Манчестера (англ. The University of Manchester), Великобритания, 21 июня 1948 года;
· EDSAC. Кембриджский университет (англ. The Cambridge University), Великобритания, 6 мая 1949 года;
· BINAC. США, апрель или август 1949 года;
· CSIR Mk 1. Австралия, ноябрь 1949 года;
· SEAC. США, 9 мая 1950 года.
Мультипроцессоры
Использование единой общей памяти служит основой для построения параллельно-векторных суперкомпьютеров (Parallel Vector Processor, PVP) и симметричных мультипроцессоров (Symmetric MultiProcessor, или SMP). Симметричные мультипроцессоры состоят из совокупности процессоров, обладающих одинаковыми возможностями доступа к памяти и внешним устройствам и функционирующих под управлением единой операционной системы (ОС). Все процессоры этого типа имеют разделяемую общую память с единым адресным пространством. Степень масштабируемости SMP-систем ограничена в пределах технической реализуемости одинакового для всех процессоров времени доступа в память со скоростью, характерной для однопроцессорных компьютеров. Современные многоядерные микропроцессоры также могут быть отнесены к классу SMP. Параллельно-векторные суперкомпьютеры (Parallel-Vector Processor, PVP) характеризуются наличием специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Эффективное программирование подразумевает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
Мультикомпьютеры
Мультикомпьютеры (системы с распределенной памятью) не обеспечивают общий доступ ко всей имеющейся в системах памяти. Каждый узел мультикомпьютера представляет собой полнофункциональный вычислительный модуль, включающий в себя процессор, память и средства коммуникации. Данный подход используется при построении двух важных типов многопроцессорных вычислительных систем: кластеров (clusters) и массивно-параллельных систем (Massively Parallel Processor, MPP). Кластер представляет собой два или более компьютеров (часто называемых узлами), объединенных при помощи сетевых технологий на базе шинной архитектуры или коммутатора и предстающих перед пользователями в качестве единого информационно-вычислительного ресурса. Массивно-параллельные системы состоят из нескольких вычислительных узлов (как правило, однородных), включающих один или несколько процессоров, локальную для каждого узла память, коммуникационный процессор или сетевой адаптер. Узлы объединяются через высокоскоростную сеть или коммутатор. Архитектурно MPP очень близки к кластерным ВС, но имеют более скоростные (как правило, специализированные) каналы связи между модулями и широкие возможности по масштабированию.
Суперкомпьютеры
Суперкомпьютер (суперЭВМ) – это штучно или мелкосерийно выпускаемая вычислительная система, производительность которой многократно превосходит производительность массово выпускаемых компьютеров [4]. В течение некоторого периода развития вычислительной техники понятия «параллельная вычислительная система» и «суперкомпьютер» могли употребляться практически как синонимы, поскольку каждая ПВС являлась суперкомпьютером, а суперкомпьютеры всегда в той или иной степени воплощали идеи параллелизма. Появление мультиконвейерных и многоядерных процессоров, графических сопроцессоров и т. д. принципиально изменило ситуацию. В настоящее время все суперкомпьютеры являются ПВС, но далеко не все ПВС являются суперкомпьютерами, поскольку любой современный персональный компьютер можно отнести к ПВС. В современно мире ПВС существует признанный «табель о рангах» – ранжированный по реальной производительности список 500 самых мощных вычислительных систем в мире – ТОР-500.
Главной характеристикой ПВС, которая определяет не только положение ВС в TOP-500, но и ее потребительские свойства, является производительность – количество операций, производимых системой за единицу времени. Различают пиковую и реальную производительность. Пиковая производительность – величина, равная произведению пиковой производительности одного процессора на число таких процессоров в рассматриваемой вычислительной системе. Реальная производительность – производительность, которую демонстрирует вычислительная система при решении реальных задач. Для того чтобы оценить эффективность работы вычислительной системы на реальных задачах, были разработаны различные наборы тестов. Наиболее известным из них является LINPACK – программа, предназначенная для решения системы линейных алгебраических уравнений с плотной матрицей с выбором главного элемента по строке. Именно LINPACK используется для формирования списка TOP-500. Анализируя ТОР-500, можно выявить основные закономерности развития суперкомпьютеров. ВС, стоящие ниже 250–280 позиции, не попадают в следующую редакцию, т. е. список каждый раз обновляется на 45–50 %. Суммарная производительность систем в TOP-500 за полгода вырастает на 40-50%. Эти темпы роста также являются устойчивыми. Наблюдается устойчивая тенденция к увеличению числа процессорных ядер как на систему в целом, так и в пересчете на отдельный процессор. Наблюдается тенденция к снижению энергоемкости вычислительных процессов, обусловленную как требованиями экономической эффективности, так и проблемами рассеяния выделяемого вычислительной системой тепла. Еще одним косвенным подтверждением значимости данного показателя стало недавнее появление рейтинга Green-500 современных вычислительных систем, отранжированных по энергоэффективности вычислений. По географической принадлежности продолжает доминировать США, но в последнее время резко активизировался прирост вычислительных мощностей в азиатском регионе, прежде всего за счет Китая и - в последней версии списка - Японии. В отличие от прошлого (XX-го) века, когда фирмы-производители суперкомпьютеров, выполняя государственные заказы, проектировали уникальные архитектуры, в наши пришлось отказаться от дорогостоящих комплектующих изделий в пользу серийно выпускаемой техники. Это позволило сконцентрировать усилия на разработке новых суперкомпьютерных архитектур, создавать системы из самых совершенных на момент создания компонентов, значительно сократить сроки и стоимость разработки суперкомпьютеров. Такой подход во многом определил современные концепции построения многоуровневых открытых и расширяемых систем, стандартизованных интерфейсов, переносимого программного обеспечения. Параллельные ВС перестали быть уделом избранных, к настоящему моменту они получили действительно широкое распространение.
Cети ЭВМ
Сети ЭВМ являются результатом эволюции двух важнейших научно-технических отраслей современной цивилизации – компьютерных и телекоммуникационных технологий. Предшественниками современных сетей являлись многотерминальные централизованные системы, которые имели все внешние признаки локальных вычислительных сетей, однако по существу ими не являлись, так как сохраняли сущность централизованной обработки данных автономно работающего компьютера. Терминальные комплексы могли располагаться на большом расстоянии от процессорных стоек, соединяясь с ними с помощью различных глобальных связей – модемных соединений телефонных сетей или выделенных каналов. Средства обмена данными между компьютерами в автоматическом режиме были разработаны позднее; на основе этого механизма в первых сетях были реализованы службы обмена файлами, синхронизации баз данных, электронной почты и другие, ставшие теперь традиционными, сетевые службы.
Хотя теоретические работы по созданию концепций сетевого взаимодействия велись почти с момента появления вычислительных машин, значимые практические результаты по объединению компьютеров в сети были получены лишь в конце 60-х, когда с помощью глобальных связей и техники коммутации пакетов удалось реализовать взаимодействие машин класса мэйнфреймов и суперкомпьютеров. Эти дорогостоящие компьютеры хранили уникальные данные и программы, обмен которыми позволил повысить эффективность их использования. Советские учѐные из ИТМиВТ АН СССР создавали сети компьютерной связи с 1952 года в рамках работ по созданию автоматизированной системы противоракетной обороны (ПРО). Специалисты под руководством Сергея Лебедева организовали обмен данными между ЭВМ для вычисления траектории противоракеты. Как пишет один из создателей системы Всеволод Бурцев, «в экспериментальном комплексе противоракетной обороны» центральная машина М-40 «осуществляла обмен информацией по пяти дуплексным и асинхронно работающим радиорелейным каналам связи с объектами, находящимися от неѐ на расстоянии от 100 до 200 километров; общий темп поступления информации через радиорелейные линии превышал 1 МГц». В 1956 году западнее озера Балхаш советскими учёными и военными был создан большой полигон, где разрабатываемая система ПРО, вместе с сетью ЭВМ, проходила испытания.
В 1969 году министерство обороны США инициировало работы по объединению в общую сеть суперкомпьютеров оборонных и научно-исследовательских центров. Эта сеть, получившая название ARPANET объединяла компьютеры разных типов, работавшие под управлением различных ОС с дополнительными модулями, реализующими коммуникационные протоколы, общие для всех компьютеров сети. В 1974 году компания IBM объявила о создании собственной сетевой архитектуры для своих мэйнфреймов, получившей название SNA (System Network Architecture, системная сетевая архитектура). В это же время в Европе активно велись работы по созданию и стандартизации сетей X.25. Таким образом, хронологически первыми появились глобальные сети (Wide Area Networks, WAN), то есть сети, объединяющие территориально рассредоточенные компьютеры, возможно, находящиеся в различных городах и странах. Именно при построении глобальных сетей были впервые предложены и отработаны многие основные идеи и концепции современных вычислительных сетей, такие, например, как многоуровневое построение коммуникационных протоколов, технология коммутации пакетов и маршрутизация пакетов в составных сетях.
Развитие сетевых технологий
Глобальные компьютерные сети очень многое унаследовали от других, гораздо более старых и глобальных сетей – телефонных. Главным результатом создания первых глобальных компьютерных сетей был отказ от принципа коммутации каналов, на протяжении многих десятков лет успешно использовавшегося в телефонных сетях. Выделяемый на все время сеанса связи составной канал с постоянной скоростью не мог эффективно использоваться пульсирующим трафиком компьютерных данных, у которого периоды интенсивного обмена чередуются с продолжительными паузами. Эксперименты и математическое моделирование показали, что пульсирующий и в значительной степени не чувствительный к задержкам компьютерный трафик гораздо эффективней передается по сетям, использующим принцип коммутации пакетов, когда данные разделяются на небольшие порции, которые самостоятельно перемещаются по сети за счет встраивания адреса конечного узла в заголовок пакета. Так как прокладка высококачественных линий связи на большие расстояния обходится очень дорого, в первых глобальных сетях часто использовались уже существующие каналы связи, изначально предназначенные совсем для других целей. Например, в течение многих лет глобальные сети строились на основе телефонных каналов тональной частоты, способных в каждый момент времени вести передачу только одного разговора в аналоговой форме. Помимо низкой скорости такие каналы имеют и другой недостаток – они вносят значительные искажения в передаваемые сигналы. Поэтому протоколы глобальных сетей, построенных с использованием каналов связи низкого качества, отличаются сложными процедурами контроля и восстановления данных. Типичным примером таких сетей являются сети X.25, разработанные еще в начале 70-х, когда низкоскоростные аналоговые каналы, арендуемые у телефонных компаний, были преобладающим типом каналов, соединяющих компьютеры и коммутаторы глобальной вычислительной сети. С конца 60-х годов в телефонных сетях все чаще стала применяться передача голоса в цифровой форме, что привело к появлению высокоскоростных цифровых каналов, соединяющих АТС и позволяющих одновременно передавать десятки и сотни разговоров. Была разработана специальная технология плезиохронной цифровой иерархии (Plesiochronous Digital Hierarchy, PDH), предназначенная для создания так называемых первичных, или опорных, сетей. Такие сети не предоставляют услуг конечным пользователям, они являются фундаментом, на котором строятся скоростные цифровые каналы "точка-точка", соединяющие оборудование другой (так называемой наложенной) сети, которая уже работает на конечного пользователя. Появившаяся в конце 80-х годов технология синхронной цифровой иерархии (Synchronous Digital Hierarchy, SDH) расширила диапазон скоростей цифровых каналов до 10 Гбит/c, а технология спектрального мультиплексирования DWDM (Dense Wave Division Multiplexing) – до сотен гигабит и даже нескольких терабит в секунду.
В начале 70-х годов произошло важное событие, непосредственно повлиявшее на эволюцию компьютерных сетей – появление и быстрое широкое распространение мини-компьютеров. Таким образом, появилась концепция распределения компьютерных ресурсов по всему предприятию. Однако при этом все компьютеры одной организации по-прежнему продолжали работать автономно. В середине 80-х годов положение дел в локальных сетях стало меняться. Утвердились стандартные технологии объединения компьютеров в сеть – Ethernet, Arcnet, Token Ring, Token Bus, несколько позже – FDDI. Все стандартные технологии локальных сетей опирались на тот же принцип коммутации, который был с успехом опробован и доказал свои преимущества при передаче трафика данных в глобальных компьютерных сетях – принцип коммутации пакетов. Стандартные сетевые технологии сделали задачу построения локальной сети почти тривиальной. Для создания сети достаточно было приобрести сетевые адаптеры соответствующего стандарта, например Ethernet, стандартный кабель, присоединить адаптеры к кабелю стандартными разъемами и установить на компьютер одну из популярных сетевых операционных систем, например Novell NetWare. После этого сеть начинала работать, и последующее присоединение каждого нового компьютера не вызывало никаких проблем – естественно, если на нем был установлен сетевой адаптер той же технологии. В 80-е годы были приняты основные стандарты на коммуникационные технологии для локальных сетей: в 1980 году – Ethernet, в 1985 – Token Ring, в конце 80-х – протокол передачи данных по оптоволоконным сетям Fiber Distributed Data Interface (FDDI). Это позволило обеспечить совместимость сетевых операционных систем на нижних уровнях, а также стандартизировать интерфейс ОС с драйверами сетевых адаптеров. Конец 90-х выявил явного лидера среди технологий локальных сетей – семейство Ethernet, в которое вошли классическая технология Ethernet 10 Мбит/c, а также Fast Ethernet 100 Мбит/c и Gigabit Ethernet 1000 Мбит/c. Простые алгоритмы работы предопределили низкую стоимость оборудования Ethernet. Широкий диапазон иерархии скоростей позволяет рационально строить локальную сеть, применяя ту технологию, которая в наибольшей степени отвечает задачам предприятия и потребностям пользователей. Важно также, что все технологии Ethernet очень близки друг другу по принципам работы, что упрощает обслуживание и интеграцию построенных на их основе сетей. Начало 80-х годов связано с еще одним знаменательным для истории сетей событием – появлением персональных компьютеров. Эти устройства стали идеальными элементами для построения сетей: с одной стороны, они были достаточно мощными для работы сетевого программного обеспечения, а с другой – явно нуждались в объединении вычислительной мощности для решения сложных задач, а также разделения дорогих периферийных устройств и дисковых массивов. Создание персональных компьютеров послужило мощным катализатором для бурного роста локальных сетей, поскольку появилась отличная материальная основа в виде десятков и сотен машин, принадлежащих одному предприятию и расположенных в пределах одного здания.
GRID-системы
Грид-вычисления (англ. grid – решѐтка, сеть) – это форма распределѐнных вычислений, в которой «виртуальный суперкомпьютер» представлен в виде кластера соединѐнных с помощью сети, слабосвязанных компьютеров, работающих вместе для выполнения огромного количества заданий (операций, работ). Эта технология применяется для решения научных, математических задач, требующих значительных вычислительных ресурсов. Грид-вычисления используются также в коммерческой инфраструктуре для решения таких трудоѐмких задач, как экономическое прогнозирование, сейсмоанализ, разработка и изучение свойств новых лекарств. Термин «грид-вычисления» появился в начале 1990-х гг., как метафора о такой же лѐгкости доступа к вычислительным ресурсам, как и к электрической сети (англ. power grid) в сборнике под редакцией Яна Фостера и Карла Кессельмана «The Grid: Blueprint for a new computing infrastructure». Идея создания распределенных вычислительных систем подобного типа возникла, прежде всего, в научном сообществе и опиралась на следующие наблюдения. К настоящему моменту человечеством накоплены колоссальные вычислительные мощности, причем речь идет об отдельных рабочих станциях, персональных компьютерах и т.д., каждый из которых далеко не суперкомпьютер, но суммарная вычислительная мощность этих устройств впечатляет. Большинство из них имеет доступ к той или иной сети обмена информацией, значит, теоретически возможна организация их совместной деятельности, направленной на решение какой-либо задачи. И – немаловажный фактор – большинство этих мощностей простаивают! Кому-то это утверждение покажется спорным, но как показали исследования, при работе со стандартными офисными приложениями средняя загрузка процессора составляет 5-7%. Идеи грид-системы (включая идеи из областей распределённых вычислений, объектно-ориентированного программирования, использования компьютерных кластеров, веб-сервисов и др.) были собраны и объединены Иэном Фостером, Карлом Кессельманом и Стивом Тики. Они начали создание набора инструментов для грид-компьютинга Globus Toolkit, который включает не только инструменты менеджмента вычислений, но и инструменты управления ресурсами хранения данных, обеспечения безопасности доступа к данным и к самому гриду, мониторинга использования и передвижения данных, а также инструментарий для разработки дополнительных грид-сервисов.
Использование свободного времени процессоров и добровольного компьютинга стало популярным в конце 1990-х годов после возникновения проектов волонтёрских вычислений GIMPS в 1996 году, distributed.net в 1997 году и SETI@home в 1999 году. Эти первые проекты добровольного компьютинга использовали мощности подсоединённых к сети компьютеров обычных пользователей для решения исследовательских задач, требующих больших вычислительных мощностей. Грид-технология применяется для моделирования и обработки данных в экспериментах на Большом адронном коллайдере (грид используется и в других задачах с интенсивными вычислениями). На платформе BOINC в настоящее время ведутся активные вычисления более 60 проектов. Например, проект Fusion (юг Франции, разработка метода получения электричества с помощью термоядерного синтеза на экспериментальном реакторе ITER) также использует грид (EDGeS@Home). Под названием CLOUD начат проект коммерциализации грид-технологий, в рамках которого небольшие компании, институты, нуждающиеся в вычислительных ресурсах, но не могут себе позволить по тем или иным причинам иметь свой суперкомпьютерный центр, могут покупать вычислительное время грида.
Парадигмы программирования
Парадигма программирования – это некоторый цельный набор идей и рекомендаций, определяющих стиль написания программ. Парадигма программирования представляет (и определяет) то, как программист видит выполнение программы. Парадигма программирования определяет то, в каких терминах программист описывает логику программы. Например, в императивном программировании программа описывается как последовательность действий, а в функциональном программировании представляется в виде выражения и множества определений функций (слово определение (англ. definition) следует понимать в математическом смысле). В популярном объектно-ориентированном программировании (в дальнейшем ООП) программу принято рассматривать как набор взаимодействующих объектов. ООП, в основном, есть по сути императивное программирование, дополненное принципом инкапсуляции данных и методов в объект (принцип модульности) и наследованием (принципом повторного использования разработанного функционала). Соответственно, парадигма, в первую очередь, определяется базовой программной единицей и самим принципом достижения модульности программы. В качестве этой единицы выступают:
· инструкция (императивное программирование, FORTRAN/C/PHP),
· функция (функциональное программирование, Haskell/Lisp/F#/Scala),
· прототип (прототипное программирование, JavaScript),
· объект (объектно-ориентированное программирование, С++/Java),
· факт (логическое программирование, PROLOG).
и другие сущности. Важно отметить, что парадигма программирования не определяется однозначно языком программирования – многие современные языки программирования являются мультипарадигменными, то есть допускают использование различных парадигм. Так на языке Си, который не является объектно-ориентированным, можно писать объектно-ориентированным образом, а на Ruby, в основу которого в значительной степени положена объектно-ориентированная парадигма, можно писать согласно стилю функционального программирования.
Своим современным значением в научно-технической области термин «парадигма» обязан, по-видимому, Томасу Куну и его книге «Структура научных революций». Кун называл парадигмами устоявшиеся системы научных взглядов, в рамках которых ведутся исследования. Термин «парадигма программирования» впервые применил Роберт Флойд в своей лекции лауреата премии Тьюринга. Флойд отмечает, что в программировании можно наблюдать явление, подобное парадигмам Куна, но, в отличие от них, парадигмы программирования не являются взаимоисключающими. Приверженность определѐнного человека какой-то одной парадигме иногда носит настолько сильный характер, что споры о преимуществах и недостатках различных парадигм относятся в околокомпьютерных кругах к разряду так называемых «религиозных» войн — холивар.
Логическое программирование
Логическое программирование (ЛП) сводит обработку данных к выбору произвольной композиции определений (уравнений, предикатных форм), дающей успешное получение результата. Именно обработка формул является основой – вычисления рассматриваются как операция над формулой. Перебор вариантов выглядит как обход графа в глубину. Имеются средства управления перебором с целью исключения заведомо бесперспективного поиска. Программирование вариантов освобождает от необходимости формулировать все варианты сразу. В ЛП можно продумывать варианты отношений между образцами формул постепенно, накапливая реально встречающиеся факты и их сочетания.
Понятие жизненного цикла ПО
Одним из базовых понятий методологии проектирования ПО является понятие жизненного цикла. ЖЦ – это непрерывный процесс, который начинается с момента принятия решения о необходимости создания ПО и заканчивается в момент его изъятия из эксплуатации. По международному стандарту ISO/IEC 12207 структура ЖЦ ПО базируется на трех группах процессов:
· основные процессы (приобретение, поставка, разработка, эксплуатация, сопровождение);
· вспомогательные процессы, обеспечивающие выполнение основных процессов (документирование, управление конфигурацией, обеспечение качества, верификация, аттестация, оценка, аудит, решение проблем)
· организационные процессы (управление проектами, создание инфраструктуры проекта, определение, оценка и улучшение ПО, обучение).
Разработка охватывает все работы по созданию ПО и его компонентов (анализ, проектирование и программирование) в соответствии с заданными требованиями, включая оформление проектной и эксплуатационной документации, подготовку материалов, необходимых для проверки работоспособности и качества ПО и обучение персонала. Эксплуатация– работы по внедрению компонентов ПО, конфигурирование БД и рабочих мест пользователей, и непосредственно эксплуатацию, в т.ч. локализацию проблем и устранение причин их возникновения, модификацию ПО в рамках установленного регламента, подготовку предложений по развитию системы. Управление проектом связано с вопросами планирования и организации работ, создания коллективов разработчиков и контроля за сроками и качеством выполнения работ. Техническое и организационное обеспечение проекта включает выбор методов и ИС, определение методов описания промежуточных состояний разработки, разработку методов и средств испытания ПО и т.п. Обеспечение качества проекта связано с проблемами верификации, проверки и тестирования ПО. Верификация – процесс определения того, отвечает ли текущее состояние разработки требованиям. Проверка – оценка соответствия параметров разработки исходным требованиям. Тестирование – идентификация различий между действительными и ожидаемыми результатами и оценкой соответствия характеристик ПО исходным требованиям. Управление конфигурацией является одним из вспомогательных процессов, поддерживающих основные процессы ЖЦ ПО, прежде всего процессы разработки и сопровождения. При создании проектов сложных ИС, состоящих из многих компонентов, каждый из которых может иметь разновидности или версии, возникает проблема учета их связей и функций, создания унифицированной структуры и обеспечения развития всей системы. Управление конфигурацией позволяет организовать, систематически учитывать и контролировать внесение изменений в ПО на всех стадиях ЖЦ. Каждый из вышеперечисленных процессов характеризуется определенными задачами и методами их решения, исходными данными, полученными на предыдущем этапе, и результатами. Результатами анализа, в частности, являются функциональные модели, информационные модели и соответствующие им диаграммы. ЖЦ ПО носит итерационный характер: результаты очередного этапа часто вызывают изменения в проектных решениях, выработанных на более ранних этапах.
Модели жизненного цикла ПО
ЖЦ ПО – это непрерывный процесс, который начинается с момента принятия решения о необходимости создания ПО и заканчивается в момент полного его изъятия из эксплуатации. По длительности жизненного цикла ПС можно разделить на два класса: с малым и большим временем жизни. Этим классам программ соответствуют гибкий (мягкий) подход к их созданию и использованию и жесткий промышленный подход регламентированного проектирования и эксплуатации промышленных изделий.
Спиральная модель ЖЦ
Спиральная модель состоит из четырех секторов диаграммы в декартовых координатах (рис. 5.2). Сектора, следующие: планирование, анализ рисков, инженерия и оценка проекта клиентом. Первая петля спирали начинается в секторе планирования и связана с начальным сбором требований и планированием проекта. Затем проект входит в сектор анализа рисков, где проводится анализ стоимости/выгоды и угроз/благоприятных случаев, чтобы принять решение «да-пет» относительно того, следует ли входить в сектор инженерии (или отказаться от проекта как слишком опасного). Сектор инженерии – это то, где происходит разработка ПО. Результат этой разработки (конструкция, опытный образец или даже конечный продукт) подвергается оценке клиентом, после чего начинается вторая петля спирали.
Рисунок 5.2 Схема спиральной модели жизненного цикла ПО
CASE-средства
CASE (англ. Computer-Aided Software Engineering) — набор инструментов и методов программной инженерии для проектирования программного обеспечения, который помогает обеспечить высокое качество программ, отсутствие ошибок и простоту в обслуживании программных продуктов. Понятие CASE используется в настоящее время в весьма широком смысле. Первоначальное значение этого понятия, ограниченное только задачами автоматизации разработки ПО, в настоящее время приобрело новый смысл, охватывающий большинство процессов жизненного цикла ПО. CASE-технология представляет собой совокупность методов проектирования ПО, а также набор инструментальных средств, позволяющих в наглядной форме моделировать предметную область, анализировать эту модель на всех стадиях разработки и сопровождения ПО и разрабатывать приложения в соответствии с информационными потребностями пользователей. Большинство существующих CASE-средств основано на методах структурного или объектно-ориентированного анализа и проектирования, использующих спецификации в виде диаграмм или текстов для описания внешних требований, связей между моделями системы, динамики поведения системы и архитектуры программных средств.
Система ПО сложна
В прошлом ПО было монолитно и процедурно по своей природе. Типичная программа прошлого, написанная на КОБОЛе, была единственной сущностью, использующей подпрограммы, вызываемые по мере необходимости. Логика программы была последовательна и предсказуема. Сложность такого ПО была просто следствием его размера.
Современное объектно-ориентированное ПО является распределенным (оно может находиться на многих узлах компьютерной сети), и его выполнение случайно и непредсказуемо. Размер современного ПО – сумма размеров его компонентов. Каждый компонент разработан так, чтобы он был ограниченного управляемого размера. В результате размер не является главным фактором в сложности современного ПО.
Сложность современного ПО заключается в «проводах», то есть в связях и коммуникационных путях между компонентами. Связи между компонентами создают зависимости между распределенными компонентами, которые могут быть сложны для понимания и управления.
а б
Рис. 5.1. Пример уменьшения сложности системы путем создания иерархической структуры
Трудность усугубляется тем, что компоненты часто разрабатываются и управляются людьми и коллективами, даже не известными друг другу.
Решение дилеммы находится в замене сетей объектов иерархиями (древовидными структурами) объектов. Все приемлемые сложные системы имеют иерархическую форму. На рисунке 5.1 просто показано, как можно уменьшить сложность системы, допуская только единственный канал связи между двумя пакетами. Каждый пакет определяет интерфейсный объект (это может быть интерфейс Java-стиля или так называемый доминантный класс), через который осуществляется вся связь с пакетом. Несмотря на добавление трех дополнительных объектов, сложность системы, изображенной на рис. 5.1-б явно уменьшена по сравнению с той же самой системой, изображенной на рис. 5.1-а.
5.2 Стадии жизненного цикла программного обеспечения
Жизненный цикл ПО — это абстрактное представление процесса создания и эксплуатации ПО. Он определяет для проекта разработки ПО стадии, шаги, действия, методы, инструменты, а также то, что ожидается сдавать. Все это определяет стратегию разработки ПО. Существует ряд полезных моделей жизненного цикла, определяемых стандартами, которые находятся друг с другом в общем согласии по стадиям жизненного цикла, но отличаются важностью отдельных стадий и взаимодействиями между ними.
Стадии жизненного цикла, рассматриваемые в данном пособии, следующие:
1. анализ требований;
2. проектирование системы;
3. реализация;
4. интеграция и внедрение;
5. процесс функционирования и сопровождения.
Рассмотрим их по порядку.
5.2.1 Анализ требований
«Требования пользователя — это утверждения на естественном языке плюс диаграммы, содержащие сведения, какие услуги ожидаются от системы, и ограничения, при которых система должна работать». Анализ требований включает действия по их определению и составлению их списка. В современной практике анализу требований помогает хорошая степень технической строгости, и поэтому эти требования иногда отождествляют с техническими требованиями.
Определение требований, оказывается, одна из самых больших проблем любого жизненного цикла разработки ПО. Пользователям часто неясно, что они требуют от системы. Часто они не знают реальные требования, преувеличивают их, предъявляют требования, которые противоречат требованиям коллег и т. д. Имеется также риск, как и в любом общении между людьми, что истинное значение требования будет неправильно истолковано. Имеется много методов и технологий выявления требований. Они включают:
· интервьюирование пользователей и экспертов в предметной области;
· анкетные опросы пользователей;
· наблюдение, как пользователи выполняют свои задачи;
· изучение существующих документов системы;
· изучение подобных систем ПО, чтобы выяснить состояние в предметной области;
· изучение опытных образцов рабочих моделей для определения и подтверждения требований;
· объединенные совещания разработчиков и клиентов по разработке приложения.
Спецификация требований следует за выявлением требований. В настоящее время UML – стандартный язык моделирования для спецификации требований (также, как и для проектирования системы). Требования определяются как в графических моделях, так и с помощью текстовых описаний. Поскольку сложную систему нельзя понять с единственной точки зрения, модели снабжаются дополнениями и при необходимости перекрестными точками зрения на систему.
И графические представления, и текст размещаются в хранилище специального CASE-средства. Данное средство облегчает изменения в моделях, если это потребуется. Оно позволяет интегрировать различные модели с перекрывающимися концепциями. CASE-средство позволяет также выполнять преобразования между моделями анализа (где это возможно) и помогает в преобразованиях моделей проектирования.
Анализ требований завершается созданием технического задания.
Большинство организаций использует некоторые шаблоны для технического задания. Шаблон определяет структуру документа и дает руководящие принципы того, как его писать. Основная часть технического задания содержит модели и описания сервисов и ограничений системы. Сервисы системы (то, что система должна делать) часто делятся на функциональные требования и требования к данным. Ограничения системы (то, чем система ограничена) включают соображения, связанные с пользовательским интерфейсом, работой, безопасностью, эксплуатационными условиями, политическими и юридическими ограничениями и т. д.
В РФ до сих пор используется документ ГОСТ 34.602-89 Техническое задание на создание автоматизированной системы.
Тестирование абстрактных моделей затруднено, поскольку большую часть времени оно не может быть автоматизировано. Сквозной контроль и инспекции – вот две популярные и эффективные технологии. Данные технологии схожи. Это предварительные встречи разработчиков и пользователей, на которых «проходятся» по техническому заданию и документам. Обсуждение, которое происходит на встречах, вероятно, раскроет некоторые проблемы. Сущность этих технологий заключается в том, что в течение встреч идентифицируются проблемы, но их решение не определено, и нет никакого «указующего перста» на людей, потенциально ответственных за эти проблемы. Результаты таких совещаний протоколируются и подписываются всеми их участниками.
5.2.2 Проектирование системы
Проектирование ПО – это описание структуры ПО, которое будет реализовано, данных, которые являются частью системы, интерфейсов между компонентами системы и, иногда, используемых алгоритмов. В информационных системах предприятий структуры данных подразумевают БД. Алгоритмы не всегда полностью описываются во время проектирования, чтобы оставить некоторый уровень свободы выполнения программистам (ведь говоря прямо, проектировщики – это не программисты, и они не в состоянии выбрать умные алгоритмические решения).
Проектирование начинается там, где заканчивается анализ. Столь же истинно и тривиально утверждение, что линия, отделяющая анализ от проектирования, во многих проектах не столь уж и ясна. Теоретически проблема проста. Анализ – моделирование, не ограниченное никакой реализацией (аппаратного/программного обеспечения). Проектирование — моделирование, которое учитывает платформу, на которой должна быть реализована система.
На практике различие между анализом и проектированием размыто. Этому имеются две главные причины. Во-первых, современные модели жизненного цикла являются итеративными и пошаговыми. В большинстве таких моделей при разработке в любой момент времени имеются многочисленные разнообразные версии ПО. Некоторые из версий находятся в процессе анализа, другие – в процессе проектирования; некоторые в разработке, другие в производстве и т. д. Во-вторых, и это более важно, для анализа и проектирования используется один и тот же язык моделирования (UML). Переход от анализа к проектированию «по готовности» предпочтительней, чем переход между различными представлениями. Модель анализа уточняется в модели проекта простым дополнением деталей спецификации. Провести линию раздела между анализом и проектированием в таких обстоятельствах очень трудно.
Проектирование, обсужденное выше, более точно называется детальным проектированием, то есть проектированием, которое добавляет детали к моделям анализа. Но имеется другой аспект проектирования системы, а именно структурное проектирование. Структурное проектирование связано с определением структуры системы, которая должна быть детально спроектирована и которой следует твердо придерживаться, а также с принципами и образцами внутренних коммуникаций между компонентами.
Структурное проектирование задает «красоту» системы. Главная цель структурного проектирования состоит в том, чтобы получить систему, которая является приемлемой – понятной, ремонтно-пригодной и расширяемой. Детальный проект должен соответствовать структурному проекту. Из-за расплывчатой линии раздела между анализом и детальным проектированием некоторые ранние структурные решения, может быть, придется заново выбрать внутри технического задания или даже раньше (но после определения требований).
Тестирование структурного проекта двулико. Во-первых, преимущества структуры, предложенной проектировщикам, должны быть продемонстрированы. Нужно показать, что структура поддерживает сложность ПО, гарантирует возможность сопровождения, упрощает разработку и т. д. Во-вторых, тестирование структурного проекта должно подтвердить, что проект компонентов соответствует принципам и шаблонам принятой структуры.
Тестирование детального проекта также имеет два аспекта. Во-первых, чтобы быть тестируемым, должна быть возможность трассировать детальный проект. Управление трассировкой – целая отрасль программной инженерии, занимающаяся поддержанием связей между продуктами ПО в различных стадиях разработки. В случае детального проекта каждый продукт проекта должен быть связан с требованиями в техническом задании, которое мотивировало производство того продукта. Наличие продукта еще не подразумевает, что это требование обеспечено. Следовательно, второй аспект тестирования проекта использует сквозной контроль и инспекции, чтобы оценить качество изделия проекта.
5.2.3 Реализация
Реализация в большей мере связана с программированием. Но программирование подразумевает не только группу людей, сидящих в общем помещении и кодирующих на некотором языке программирования в соответствии со спецификацией проекта. Программирование предполагает намного более интеллектуальные требования, чем это. Проекты могут быть не доопределены в некоторых областях, когда они попадают к программистам, особенно в области проектирования алгоритмов. Завершение спецификаций требует дополнительного проектирования прежде, чем можно будет начать кодирование. В этом смысле программист – тоже проектировщик.
Программист – инженер, имеющий дело с компонентами. Сегодняшнее программирование редко выполняется на пустом месте. Большая часть программирования основана на многократном использовании уже созданных компонентов. Это означает, что программист должен иметь знание о компонентах ПО и должен знать, как найти это ПО, чтобы добавить к нему новые закодированные компоненты приложения. Это трудный вопрос.
Программист – инженер, работающий в двух направлениях. Программирование начинается с преобразования проекта в код. Начальный код не должен программироваться вручную. Используя CASE-средства и IDE-средства (integrated development environments – интегрированные средства разработки), код начинает формироваться (прямое проектирование) из моделей проекта. После того как эта работа будет сделана, произведенный код должен быть скорректирован вручную, чтобы заполнить отсутствующие части (эти «части» существенны и наиболее трудны в программировании). После того как код будет модифицирован программистом, он может обратно воздействовать на модели проекта, корректируя их. Эти технические операции в прямом и обратном направлении называются циклическим проектированием.
Во многих проектах реализация – самая длинная из стадий разработки.
В некоторых моделях жизненного цикла, типа быстрой разработки ПО (раздел 3.3.6), реализация является доминирующей стадией разработки. Реализация – подверженная ошибкам деятельность. Время, потраченное на творческое написание программ, может быть меньше, чем время, потраченное на отладку программы и ее тестирование.
Отладка – это процесс удаления из ПО «блох – bugs» – ошибок в программах. Ошибки в синтаксисе программы и некоторые логические ошибки могут быть определены и исправлены коммерческими средствами отладки. Другие ошибки и дефекты должны быть обнаружены во время тестирования программы. Тестирование может иметь форму просмотра кода (сквозной контроль и инспекции) или может основываться на выполнении программы (наблюдение за поведением программы во время ее выполнения). Управление трассировкой поддерживает возможность использования тестирования, если программы удовлетворяют требованиям пользователя.
Имеются два вида тестирования, основанного па выполнении программы: тестирование на основе технических требований («тестирование черного ящика») и тестирование на основе кода («тестирование белого ящика»). Оба вида используют ту же самую стратегию задания программе входных данных и наблюдения, тот ли выходной результат получается, который ожидался. Различие заключается в том, что при тестировании на основе технических требований программе задаются данные без какого-либо учета логики работы программы. Считается, что программа должна вести себя разумно при любых входных данных. В тестировании на основе кода используются такие входные данные, которые позволяют проверить определенные пути выполнения программы – столько путей и настолько разнообразных, насколько это возможно. Поскольку тестирование на основе технических требований и тестирование на основе кода обнаруживают различные виды ошибок и дефектов, нужно использовать их оба.
Интеграция и внедрение
«Целое – больше, чем сумма его частей». Этот афоризм Аристотеля (384-322 гг. до н. э.), называемый в современном системном анализе свойством эмержентности, охватывает сущность интеграции системы и ее внедрения. Интеграция собирает приложение из набора компонентов, предварительно созданных и проверенных. Внедрение – передача системы клиентам для использования в производстве.
Интеграция ПО означает переход от «программирования в малом» к «программированию в большом». Информационные системы предприятий – все достаточно большие и сложные, и для них интеграция – существенная стадия в жизненном цикле.
Интеграцию также трудно отделить от тестирования. Фактически, стадия интеграции жизненного цикла часто упоминается и обсуждается под термином тестирования интеграции. При широком использовании итеративных моделей жизненного цикла ПО создается как последовательность быстрых пошаговых реализаций. Каждый шаг – интеграция компонентов, до этого проверенных индивидуально, однако при этом до внедрения саму эту интеграцию системы необходимо сначала проверить.
В значительной степени интеграция определяется структурным проектом системы. В свою очередь, структура системы определяет ее компоненты и зависимости между ними. Особенно важно, чтобы структурное решение было в виде иерархии или древовидной структуры. Иерархия (древовидная структура) означает устранение любых циклических зависимостей между компонентами. В случае циклических зависимостей тестирование интеграции отдельных шагов создания ПО (конструкций) может оказаться невозможным.
Рассмотрим структуру зависимых компонентов, где компонент C1 использует компонент C2, а С2 использует компонент С3. Предположим, что C1 и C2 уже были реализованы и индивидуально протестированы, а компонент С3 должен быть еще создан. Задача состоит в том, чтобы объединить C1 и C2. Эта задача требует программирования испытательной заглушки для С3, то есть части кода, которая моделирует поведение отсутствующего компонента С3. Заглушка обеспечивает среду интеграции для выполнения компонента C2. Обычный путь создания заглушки – сделать ее такой, чтобы она обеспечивала те же зависимости входа/выхода, что и в окончательном компоненте С3, и формировать результаты, ожидаемые для компонента С2, жестким кодированием их или читая их из файла.
Все это работает, если только между C2 и С3 нет никаких циклических зависимостей. В присутствии циклических зависимостей оба компонента должны быть полностью реализованы и индивидуально проверены до интеграции. Но даже и тогда циклические зависимости создадут кошмар тестирования. С большими циклами в структурном проекте тестирование интеграции должно быть выполнено как единая операция, называемая тестированием «одним махом». Тестирование «одним махом» может быть успешно выполнено только для небольших программных решений. Это не очень разумно в современной разработке ПО.
Предположим теперь, что С2 и С3 были реализованы и индивидуально протестированы, но C1 должен быть еще разработан. Как мы должны интегрировать C2 и С3, чтобы объединенный экземпляр(конструкция) получал данные и другой контекст, которые стандартно давал бы компонент С1 и так, чтобы мы могли утверждать, что этот экземпляр работает таким образом, как ожидается при наличии C1? Чтобы сделать это, для C1 должен быть запрограммирован тестовый драйвер, чтобы «управлять» интеграцией.
В целом интеграция требует написания дополнительного ПО, заглушек и драйверов, которые полезны только во время интеграции. Это дополнительное тестирующее ПО называется средствами тестирования или «лесами для тестирования», по аналогии с временными лесами, используемыми в строительной индустрии.
Интеграция может проводиться сверху вниз (от корня иерархии зависимостей) или снизу вверх (от компонентов в листьях иерархии). Нисходящий подход требует реализации заглушек. Восходящий подход требует драйверов. В действительности интеграция редко следует только одному из этих подходов. Смешанный подход, иногда называемый «из середины», является преобладающим.
Подобно интеграции, внедрение – не одноразовая операция. ПО внедряется своими версиями. Каждая версия объединяет ряд экземпляров (конструкций), которые предлагаются совместно и функционально полезны пользователям. Перед внедрением ПО системно тестируется разработчиками в реальных условиях. Оно иногда называется альфа-тестированием. За альфа-тестированием следуют приемочные испытания специалистами пользователя. Это иногда называется бета-тестированием (альфа- и бета-тестирование – термины, в большей мере используемые при тестировании системного ПО от имени продавцов ПО, в противоположность разработке прикладного ПО).
Кроме самой системы и приемочных испытаний, внедрение включает ряд других действий. Наиболее важное из этих действий – обучение пользователей. Практически обучение пользователей может начаться задолго до того, как система будет подготовлена к выпуску. Обучение совпадает по времени с производством документации для пользователя.
Спиральная модель
Спиральная модель в действительности является метамоделью, в которой могут содержаться все другие модели жизненного цикла. Модель состоит из четырех секторов диаграммы в декартовых координатах (рис. 5.3). Сектора, следующие: планирование, анализ рисков, инженерия и оценка проекта клиентом. Первая петля спирали начинается в секторе планирования и связана с начальным сбором требований и планированием проекта. Затем проект входит в сектор анализа рисков, где проводится анализ стоимости/выгоды и угроз/благоприятных случаев, чтобы принять решение «да-пет» относительно того, следует ли входить в сектор инженерии (или отказаться от проекта как слишком опасного). Сектор инженерии – это то, где происходит разработка ПО. Результат этой разработки (конструкция, опытный образец или даже конечный продукт) подвергается оценке клиентом, после чего начинается вторая петля спирали.
Фактически спиральная модель имеет отношение к разработке ПО только в одном из этих четырех секторов инженерии.
Акцент на повтор в планировании проекта и оценке проекта клиентом дает всему этому явно итеративный характер. Анализ рисков уникален в спиральной модели. Частые исследования рисков позволяют провести раннюю идентификацию любых появляющихся рисков в проекте. Риски могут быть внутренние (находящиеся под управлением организации) и внешние (риски, которыми организация не может управлять). В любом случае задача анализа рисков состоит в том, чтобы смотреть в будущее, и если ясно, что риски неустранимы, проектирование должно быть прекращено безотносительно к затратам, уже израсходованным.
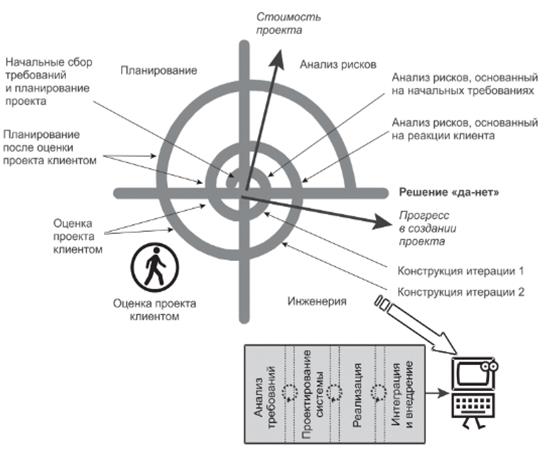
Рисунок 5.3. Спиральная модель жизненного цикла ПО
Каждый фрагмент петли в пределах сектора инженерии может быть итерацией, заканчивающейся созданием конструкции. Любой последовательный фрагмент петли в направлении наружу представляет собой шаг.
Возможны и другие интерпретации фрагментов петли инженерии. Например, вся петля спирали может быть связана с анализом требований. В таком случае фрагмент петли инженерии может быть связан с моделированием требований и созданием раннего опытного образца, чтобы выявить требования. С другой стороны, спиральная модель может содержать монолитную модель водопада. В таком случае будет только одна петля спирали.
Спиральная модель — скорее модель ссылок или метамодель для других моделей. Привлекательная и реалистическая, насколько это возможно, она не может быть перенесена на конкретный задокументированный жизненный цикл, который организации используют при разработке ПО. Спиральная модель — «способ мышления» относительно принципов разработки ПО.
Список литературы
1. Доррер Г.А. Методология программной инженерии. Учебное пособие /Г.А. Доррер – Красноярск: СибГУ, 2019. – 170 с.
2. Попов А.А., Доррер М.Г. Технология разработки ПО. Учебное пособие / А.А. Попов, М.Г. Доррер – Красноярск: СибГУ, 2019. – с.
3. Брукс Ф. Мифический человеко-месяц, или Как создаются программные системы / Ф. Брукс – М.: Символ-Плюс, 2010. — 304 с.
4. Липаев В. А. Программная инженерия. Основы методологии / В.А. Липаев – М.: Теис, 2006 - 609 с.
5. Батоврин В.К. Толковый словарь по системной и программной инженерии: учеб. пособие для вузов / В.К. Батоврин – М.: ДМК Пресс. 2012. – 280 с.
6. Орлик С. В. Введение в программную инженерию и управление жизненным циклом ПО / С.В.Орлик:URL : https://vk.com/sistemnaya_inzheneriya_levenchuk
7. Мацяшек Л.А. Практическая программная инженерия на основе учебного примера. Перевод с англ./ Л.А. Мацяшек, Б.Л. Лонг. – М. Бином. Лаборатория знаний, 2009, - 956 с.
8. Буч Г., Рамбо Д., Джекобсон А. Язык UML. Руководство пользователя: Перевод с англ. / Г. Буч, Д. Джекобсон – М.: ДМК, 2000. – 432 с.
9. Боэм Б. Инженерное проектирование программного обеспечения / Б. Боэм – М.: Радио и связь, 1985. - 512 с.
10. Карпенко С. Н. Программная инженерия: назначение, основные принципы и понятия / С.Н. Карпенко – Н. Новгород: ННГУ, 2005. – 103 с.
Г.А. Доррер
Введение в специальность
Лекции для студентов 1 курса направлени й
ИНФОРМАТИКА И ВЫЧИСЛИТЕЛЬНАЯ ТЕХНИКА
ПРОГРАММНАЯ ИНЖЕНЕРИЯ
Красноярск – 2019
Оглавление
ВВЕДЕНИЕ. 3
История и методология информатики.. 4
Эволюция вычислительной техники.. 18
Развитие программного обеспечения.. 40
О становлении системной и программной инженерии.. 46
СТАНДАРТЫ В ОБЛАСТИ программной инженерии.. 66
Вопросы практической программной инженерии.. 71
5.3Модели жизненного цикла ПО.. 86
5.4 Инструментальные средства моделирования систем.. 92
5.5ИНСТРУМЕНТАЛЬНЫЕ СРЕДСТВА ПРОГРАММНОЙ ИНЖЕНЕРИИ.. 96
Инструментальные средства управления проектом.. 97
Основные тезисы программной инженерии.. 98
ВВЕДЕНИЕ
Информатика – наука, систематизирующая приемы создания, хранения, обработки и передачи информации средствами вычислительной техники, а также принципы функционирования этих средств и методы управления ими.. Теоретической основой информатики является группа фундаментальных наук таких как теория информации, теория алгоритмов, математическая логика, теория формальных языков и грамматик, комбинаторный анализ и т.д. Термин "информатика" начал использоваться в отечественной научно- технической литературе в начале 80-х годов и быстро приобрел широкую популярность. Первоначально он возник во Франции в середине 60-х годов (фр. informatique) и применяется в странах Европы для обозначения области научных знаний, связанных с автоматизацией обработки информации с помощью ЭВМ. Если говорить более точно, русскоязычный термин "информатика" объединил в себе (кроме всех прочих значений) наименование двух существенно различных дисциплин "computer science" ("вычислительная наука") и "information science". Термин "information science" уместно по аналогии с " computer science", переводить как "информационное дело" – наука по организации распространения научно-технической информации. Возможно, имеет смысл и в русском языке развести "information science" и "computer science", отделить науку информатику от связанной с ней областью практической деятельности.
Развитие информатики привело к созданию информационных технологий – процессов, использующих совокупность средств и методов сбора, обработки и передачи данных (первичной информации) для получения информации нового качества о состоянии объекта, процесса или явления (информационного продукта).
Если цель технологии материального производства – выпуск продукции, удовлетворяющей потребности человека или системы, то цель информационной технологии – производство информации для ее анализа человеком и принятия на его основе решения по выполнению какого-либо действия. В последние годы появился термин новые информационные технологии, которым обозначаются технологии, основанные на использовании компьютерных и телекоммуникационных средств.
Информационные технологии представляют собой обширную область научной и практической деятельности. В нее наряду с другими направлениями входит программная инженерия – сравнительно новое направление научной и инженерной деятельности в области информатики, сформировавшееся в последние десятилетия. В центре внимания этого направления находятся вопросы научного планирования, проектирования, оценки, конструирования и эффективного использования крупных программных систем, создаваемых людьми для удовлетворения установленных требований, а также проблемы успешной организации коллективных, бригадных методов работы при создании таких систем.
Важнейшим требованием в программной инженерии является следование определенной методологии, суть которой состоит в применении систематизированного, научного и предсказуемого процесса проектирования, производства и сопровождения программных комплексов, в том числе, и реального времени.
Настоящее пособие в рамках курса «Введение в специальность» ставит целью ознакомить студентов первого курса направлений подготовки09.03.01 «Информатика и вычислительная техника» и 09.03.04 «Программная инженерия» с основными понятиями информатики, вычислительной техники, программирования, системной и программной инженерии, со стандартами, определяющими процесс обучения специалистов, а также процессы жизненного цикла и разработки программных систем.
Учитывая, что большое количество источников информации для этой области написано на английском языке, при изучении этого курса требуется чтение и перевод англоязычных текстов.
Дата: 2019-11-01, просмотров: 725.