При выводе данных в удобном для пользователя формате в Scilab имеется несколько функций, позволяющих выполнить преобразование произвольных типов данных в текстовые данные и производить управление их форматом:
· mprintf – преобразует, форматирует и отображает данные в
командном окне;
· mfprintf – преобразует, форматирует и записывает данные в файл;
· msprintf – преобразует, форматирует и записывает данные в строку.
Форматирование в этих функциях (выравнивание, число значащих цифр и так далее) осуществляется с использованием определенных элементов
нотаций (системой условных обозначений). Они аналогичны тем, которые используются для форматирования строковых данных в языке C++. Например, формат %f преобразует значения с плавающей точкой к соответствующему строковому формату, а формат %.2f, представляют две цифр после десятичного знака, формат %12f представляет при выводе12символов, заполняя по мере необходимости незначащие символы пробелами. Кроме того, имеется возможность комбинировать элементы формата с обычным текстом и специальными непечатными управляющими символов – escape-символами, такими, например, как символ новой строки\n.
Строка, содержащая элементы форматирования, может иметь шесть элементов. Справа налево эти элементы представляют: символ преобразования, подтип, точность, ширина поля, флаги и числовой идентификатор.
В общем виде функции форматирования данных имеют следующий вид:
mprintf(Формат , С писокПеременных);
mfprintf(Формат , С писокПеременных);
msprintf(Формат , С писокПеременных).
Работу перечисленных выше функций рассмотрим на примере функции mprintf:
Строка=mprintf(Формат , С писокПеременных),
где Строка– строковая переменная; Формат– параметр, который является строкой, содержащей символы преобразования (форматирования); С писокПеременных – список переменных, значения которых необходимо отобразить в соответствующем формате.
Каждый Форматявляется строкой символов, который начинается с символа %, и сообщает всё о переменной, значение которой нужно подставить: её тип и модификаторы (ширина, точность, размер):
Формат='%ФлагиШирина.ТочностьРазмерТип'.
Ни один из перечисленных элементов не является обязательным, кроме элемента Тип, а часть элементов формата относятся только к некоторым типам данных. Например, ширина, точность и размер – относятся только к числам.
Обратите внимание на то, что в элементах формата не допускаются пробелы, причем символ преобразования является единственным обязательным полем, наряду с ведущим символом % .
Рассмотрим основные допустимые символы преобразования строки
Форматподробнее.
В соответствии с синтаксисом, формат преобразования начинается с символа % и содержит следующие необязательные и обязательные элементы:
· флаги (необязательно);
· поля ширины и точности (опционные);
· спецификатор подтипа (необязательно);
· символ типа (преобразования) (обязательный).
Эти элементы задаются в порядке, показанном в примере на рис. 1.2.4-5
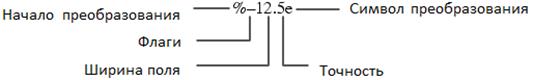
Рис. 1.2.4-5 Пример строки форматирования
Символы преобразования, указывающие нотацию (систему условных обозначений) для преобразования выходных данных, приведены в
Приложении 1.2, табл. 1.2.4-1.
Ширина и точность поля позволяют управлять шириной и точностью выходных данных (Приложение 1.2, табл. 1.2.4-2).
Например, если указать спецификатор формата %5d, то будет гарантировано, что вывод числа всегда занимает 5 символьных позиций (если нужно, то больше, но не меньше). Эта возможность очень полезна при печати таблиц, потому что и большие, и маленькие числа займут в строке одинаковое число позиций.
Следует иметь в виду, что результат вывода будет дополнен до необходимой указанной ширины слева. При этом большие числа, которые требуют для печати большее количество символов, будут выведены полностью.
Поле опции ширины должно быть указано таким, чтобы удовлетворять максимальному размеру ожидаемого выводимого числа. Например, если числа могут состоять из 1, 2 или максимум 3 цифр, то формат %3d подойдет. Опция ширины будет работать неправильно, если потребуется отобразить слишком большое число, которое не умещается в заданной ширине поля.
Числа с плавающей точкой (например, 3.1415) содержат точку, тогда как числа целого типа (например, 27) не имеют такой точки. Для печати чисел с плавающей точкой (double) флаги и правила работают точно так же, как и для целых чисел, но имеют несколько новых опций. Самая важная опция указывает, какое количество цифр может появиться после десятичной точки. Это количество цифр называется точностью ( precision )числа.
В Приложении 1.2, табл. 1.2.4-3 приведены примеры возможных вариантов вывода числа e=2.718281828. Почему красным?
Обратите внимание, что если в качестве элементов формата указаны точка и число, то precision указывает, сколько десятичных знаков должно появиться после десятичной точки.
Если точка для %f не указана, то по умолчанию будет приведен формат %.6f (6 цифр после десятичной точки).
Если указано precision равное 0, то десятичная точка также исчезает. Для того чтобы ее вернуть, нужно после спецификатора формата %f указать ее в виде простого текста.
Можно в одном спецификаторе формата указать одновременно и ширину (width), и точность (precision). Например, 5.2 означает общую длину 5, с 2 цифрами после десятичной точки. Самая распространенная ошибка, когда считают, что это означает 5 цифр до точки и 2 цифры после точки.
Флаги позволяют управлять выравниванием выходных данных с помощью дополнительных флагов.
Ширину и точность с флагами можно комбинировать, чтобы указать левое выравнивание, дополнение слева нулями и применение знака +, - и т. д.
До или после операторов форматирования, перед знаком процента % или после преобразования, можно включать дополнительный текст. Причем этот текст может быть, как обычнымтекстом(текст для печати), так и текстом, состоящим из специальных символов, который нельзя вывести как обычный текст.
В Приложении1.2, табл.1.2.4-4 показаны допустимые специальные непечатные символы.
Рассмотрим несколько примеров форматирования, представленных на рис. 1.2.4-6.
 -->// Примеры форматированного вывода
-->
--> // Пример1. Использование символов %s для вывода текста
--> t ='Текст';
--> mprintf('%s' ,t)
Текст
-->
-->// Пример2. Использование символов %f для вывода числа
--> x = 234.2;
--> mprintf('%6.2f', x)
234.20
-->
--> // Пример3.Вывод элементов матрицы в различных форматах
-->A = %pi * 1000 * ones(1,4) // ones(1,4) – создание матрицы из 1
A =
3141.5927 3141.5927 3141.5927 3141.5927
-->
--> mprintf('%f\n%9.2f\n%+12.5f\n%12.2f\n' ,A)
ans =
!3141.592654 !
! !
! 3141.59 !
! !
! +3141.59265 !
! !
! 3141.59 !
-->// Примеры форматированного вывода
-->
--> // Пример1. Использование символов %s для вывода текста
--> t ='Текст';
--> mprintf('%s' ,t)
Текст
-->
-->// Пример2. Использование символов %f для вывода числа
--> x = 234.2;
--> mprintf('%6.2f', x)
234.20
-->
--> // Пример3.Вывод элементов матрицы в различных форматах
-->A = %pi * 1000 * ones(1,4) // ones(1,4) – создание матрицы из 1
A =
3141.5927 3141.5927 3141.5927 3141.5927
-->
--> mprintf('%f\n%9.2f\n%+12.5f\n%12.2f\n' ,A)
ans =
!3141.592654 !
! !
! 3141.59 !
! !
! +3141.59265 !
! !
! 3141.59 !
|
Рис. 1.2.4-6 Примеры использования функции mprintf
В Примере1 для вывода строки (текста) использованы символы %s. В
Примере2 для вывода значения числовой переменной использован символ %f. В Примере3 создается вектор А, состоящий из четырех элементов, а затем каждый элемент вектора выводится в своем числовом формате %f. Если формат содержит знак плюс (+), число выводится со знаком плюс, если использован формат %n.mf, то число при выводе состоит из n знаков, из которых m – число знаков после запятой. Использование управляющих символов \n позволяет вывести каждый элемент вектора с новой строки.
1.2.5. Списки, структуры и ячейки
Списки
Списки в Scilab – это типы структур данных, состоящих из множества элементов, которые могут иметь разные типы. Они могут быть созданы вручную или с помощью одной из следующих функций:
· list – создает простой список, поля которого могут содержать произвольный тип данных;
· tlist – создать типизированный список;
· mlist – создает матрично-ориентированный список.
Простой список – list обычно используется, когда данные в нем обезличены. В остальных случаях удобно использовать типизированный список
(рис. 1.2.5-1).

--> // Пример создания простого списка и обращение к его элементам
-->
-->lt = list(complex(12, -6), [2312], [12; 34]);
-->lt(1) // Обращение к 1-му элементу списка
12. - 6.i
-->
-->lt(2) // Обращение ко 2-му элементу списка
2312.
-->
-->lt(3) //Обращение к 3-му элементу списка
12.
34.
-->
-->lt(1), lt(3) ($,$) // Обращение к 1-му, 3-му элементу списка и до конца
ans =
12. +6.i
ans =
34.
Рис.1.2.5-1 Пример создания простого списка и обращение к его элементам
Чтобы обратится к элементу списка, достаточно указать его индекс списка, например, к первому, второму и третьему элементу, а затем индекс элемента.
Над простым списком определены операции:
· Доступ к элементам списка – [x,y,z,...]=ИмяСписка(Vi),
где Vi – вектор индексов; [x,y,z,...]=L(:) извлекает все элементы.
· Присвоение значения элементам списка по индексу i L(i)=a.
· Добавление элемента в конец списка L($+1)=e.
· Добавление элемента в начало списка L(0)=e(после этого операция e является элементом списка с индексом 1, а исходные элементы списка смещаются вправо).
· Исключение элементов из спискаL ( i )= null () удаляет i-й элемент списка L.
· Объединение списков L3=lstcat(L1,L2).
· Определение числа элементов списка либо ne = size (L), либо ne=length(L).
· Итерации со списком forj = L ,..., end – цикл с числом итераций length ( L ), переменная цикла j будет равна L ( i ) на i-той итерации.
Примеры некоторых операций над простыми списками и их элементами приведены на рис. 1.2.5-2.
 -->// Примеры о перации над простыми списками и их элементами
-->
--> L1 = list(5, ["М" "Т"]); // Простой список с двумя элементам
--> size(L1) // Размер 2
ans =
2.
-->
--> // L1(0) - не существует! Выдается сообщение: Недопустимый индекс.
--> L1(1) // Доступ к числу 5 с двойной точностью
ans =
5.
-->
--> L1(2) // Доступ к вектору строк
ans =
!М Т !
-->
--> size(L1(2)) // Размер 1, 2
ans =
1. 2.
--> L1(0) ="фу" // Вставка в начало списка
L1 =
L1(1)
фу
L1(2)
5.
L1(3)
!М Т !
-->
--> // L1(0) - не существует, "фу" записано в L1(1)
--> L1($+1) = "Привет"; // Вставка элемента в конец списка
--> L1(2) = "Окно";// Переопределение 2-го элемента списка
--> L1(3) = null(); // Удаление 3-го элемента списка
--> L2 = list("С1", "С2", "С3"); // Объявление нового списка
--> F = lstcat(L2, L1); // Объединение двух списков
-->// Примеры о перации над простыми списками и их элементами
-->
--> L1 = list(5, ["М" "Т"]); // Простой список с двумя элементам
--> size(L1) // Размер 2
ans =
2.
-->
--> // L1(0) - не существует! Выдается сообщение: Недопустимый индекс.
--> L1(1) // Доступ к числу 5 с двойной точностью
ans =
5.
-->
--> L1(2) // Доступ к вектору строк
ans =
!М Т !
-->
--> size(L1(2)) // Размер 1, 2
ans =
1. 2.
--> L1(0) ="фу" // Вставка в начало списка
L1 =
L1(1)
фу
L1(2)
5.
L1(3)
!М Т !
-->
--> // L1(0) - не существует, "фу" записано в L1(1)
--> L1($+1) = "Привет"; // Вставка элемента в конец списка
--> L1(2) = "Окно";// Переопределение 2-го элемента списка
--> L1(3) = null(); // Удаление 3-го элемента списка
--> L2 = list("С1", "С2", "С3"); // Объявление нового списка
--> F = lstcat(L2, L1); // Объединение двух списков
|
Рис. 1.2.5-2. Примеры операций над простыми списками и их элементами
Типизированные списки используются главным образом для определения новых структур данных. Многие функции в Scilab перегружены с помощью типизированных списков. Также некоторые объекты Scilab на самом деле являются типизированными списками, и это скрыто от пользователя.
Отличительной особенностью типизированного списка от простого списка является то, что у него есть поля. Полем списка, по сути, является элемент списка, причем, каждому полю присваивается уникальное имя.
Для определения типизированного списка служит функция tlist:
tlist (Тип,А1,..., An),
где: Тип – символьная строка или вектор символьных строк; А1,..., An –любой фрагмент объекта (matrix, list, string). Символьная строка (Тип) позволяет пользователю определить новые операции, выполняемые над этими объектами. Типы списков tlist и list имеют значения типа, соответственно, 16 и 15.
Стандартные операции с tlist соответствуют операциям list.
Конкретными реализациями списка tlistявляются, например,
Линейные системы, Рациональные матрицы, Полиномиальные матрицы и т.д., которые будут подробно изложены в п. 2.1.
 --> // Создание и обращение к полям типизированного списка
-->
--> TL = tlist(["Nlict", "Year", "Month"], [], [])
TL =
TL(1)
!Nlict Year Month !
TL(2)
[]
TL(3)
[]
-->
--> TL.Year(1) = 2018;
--> TL.Month(1) = "Октябрь";
TL =
TL(1)
!Nlict Year Month !
TL(2)
2018.
TL(3)
Октябрь
-->
-->TL.Month
ans =
Октябрь
-->
-->TL(3)
ans =
Октябрь
-->
-->typeof(TL)
ans =
Nlict
--> // Создание и обращение к полям типизированного списка
-->
--> TL = tlist(["Nlict", "Year", "Month"], [], [])
TL =
TL(1)
!Nlict Year Month !
TL(2)
[]
TL(3)
[]
-->
--> TL.Year(1) = 2018;
--> TL.Month(1) = "Октябрь";
TL =
TL(1)
!Nlict Year Month !
TL(2)
2018.
TL(3)
Октябрь
-->
-->TL.Month
ans =
Октябрь
-->
-->TL(3)
ans =
Октябрь
-->
-->typeof(TL)
ans =
Nlict
|
Рис. 1.2.5-3 Создание типизированного списка
Для работы с типизированными списками использоваться следующие функции:
· tlist – создание типизированногосписка;
· fieldnames –вывод всех полей типизованного списка;
· definedfields –вывод полей, в которых есть данные;
· setfield –установка поля для типизованного списка;
· getfield –извлечениеданных из поля.
Для примера создадим типизированный список, который будет хранить информацию о некотором двигателе. Пусть у этого списка будет три поля: тип двигателя, маркировка, мощность и размерность мощности (рис.1.2.5-4).

--> // Обращения к полям типизированного списка
-->
--> tt = tlist(['Engine', 'type' ,'power', 'dim'], 'П61' ,5, 'кВт')
tt =
tt(1)
!Enginetype power dim !
tt(2)
П61
tt(3)
5.
tt(4)
кВт
-->
-->tt.type
ans =
П61
Pис.1.2.5-4 Примеры обращения к полям типизированного списка
Типизированный список наследует все приемы работы, присущие обычным list-спискам. Он отличается от обычного списка еще и тем, что позволяют создавать пользовательские типы данных. Хотя к элементам типизированного списка можно обращаться по индексам, надо помнить, что это следует делать только на уровне разработчика, а при непосредственном использовании пользователь все же должен использовать имена полей. Поля в типизированном списке при желании можно добавлять.
Для операций доступа, извлечения из списка и присваивания значения элементу в списке имеются две соответствующие функции getfield и setfield. Они могут использоваться во всех типах списков.
Кроме списков list и tlist в Scilab есть еще одна разновидность типизированного списка – mlist. При обычной работе с этими списками пользователь не почувствует между ними разницы. Разница начинает проявляться при программировании пользовательских структур данных.
Типизированные списки являются надстройками над списками типа list и позволяют создавать пользовательские типы данных с уникальным именем в виде строки. К элементам типизированного списка можно обращаться по их уникальным именам.
Дата: 2019-11-01, просмотров: 410.