Построение конкретного корректирующего кода производят, исходя из требуемого объема кода Q, т. е. необходимого числа передаваемых команд или дискретных значений измеряемой величины и статистических данных о наиболее вероятных векторах ошибок в используемом канале связи.
Вектором ошибки называют n-разрядную двоичную последовательность, имеющую единицы в разрядах, подвергшихся искажению, и нули во всех остальных разрядах. Любую искаженную кодовую комбинацию можно рассматривать теперь как сумму (или разность) но модулю 2 исходной разрешенной кодовой комбинации и вектора ошибки.
Исходя из неравенства 2k – l  Q (нулевая комбинация часто не используется, так как не меняет состояния канала связи), определяем число информационных разрядов k , необходимое для передачи заданного числа команд обычным двоичным кодом.
Q (нулевая комбинация часто не используется, так как не меняет состояния канала связи), определяем число информационных разрядов k , необходимое для передачи заданного числа команд обычным двоичным кодом.
Каждой из 2k - 1 ненулевых комбинаций k -разрядного безызбыточного кода нам необходимо поставить в соответствие комбинацию из п символов. Значения символов в п – k проверочных разрядах такой комбинации устанавливаются в результате суммирования по модулю 2 значений символов в определенных информационных разрядах.
Поскольку множество 2k комбинаций информационных символов (включая нулевую) образует подгруппу группы всех n-разрядных комбинаций, то и множество 2k n-разрядных комбинаций, полученных по указанному правилу, тоже является подгруппой группы n-разрядных кодовых комбинаций. Это множество разрешенных кодовых комбинаций и будет групповым кодом.
Нам надлежит определить число проверочных разрядов и номера информационных разрядов, входящих в каждое из равенств для определения символов в проверочных разрядах.
Разложим группу 2n всех n-разрядных комбинаций на смежные классы по подгруппе 2k разрешенных n-разрядных кодовых комбинаций, проверочные разряды в которых еще не заполнены. Помимо самой подгруппы кода в разложении насчитывается 2n-k – 1 смежных классов. Элементы каждого класса представляют собой суммы по модулю 2 комбинаций кода и образующих элементов данного класса. Если за образующие элементы каждого класса принять те наиболее вероятные для заданного канала связи вектора ошибок, которые должны быть исправлены, то в каждом смежном классе сгруппируются кодовые комбинации, получающиеся в результате воздействия на все разрешенные комбинации определенного вектора ошибки. Для исправления любой полученной на выходе канала связи кодовой комбинации теперь достаточно определить, к какому классу смежности она относится. Складывая ее затем (по модулю 2) с образующим элементом этого смежного класса, получаем истинную комбинацию кода.
Ясно, что из общего числа 2n – 1 возможных ошибок групповой код может исправить всего 2n-k – 1 разновидностей ошибок по числу смежных классов.
Чтобы иметь возможность получить информацию о том, к какому смежному классу относится полученная комбинация, каждому смежному классу должна быть поставлена в соответствие некоторая контрольная последовательность символов, называемая опознавателем (синдромом).
Каждый символ опознавателя определяют в результате проверки на приемной стороне справедливости одного из равенств, которые мы составим для определения значений проверочных символов при кодировании.
Ранее указывалось, что в двоичном линейном коде значения проверочных символов подбирают так, чтобы сумма по модулю 2 всех символов (включая проверочный), входящих в каждое из равенств, равнялась нулю. В таком случае число единиц среди этих символов четное. Поэтому операции определения символов опознавателя называют проверками на четность. При отсутствии ошибок в результате всех проверок на четность образуется опознаватель, состоящий из одних нулей. Если проверочное равенство не удовлетворяется, то в соответствующем разряде опознавателя появляется единица. Исправление ошибок возможно лишь при наличии взаимно однозначного соответствия между множеством опознавателей и множеством смежных классов, а следовательно, и множеством подлежащих исправлению векторов ошибок.
Таким образом, количество подлежащих исправлению ошибок является определяющим для выбора числа избыточных символов п – k . Их должно быть достаточно для того, чтобы обеспечить необходимое число опознавателей. Если, например, необходимо исправить все одиночные независимые ошибки, то исправлению подлежат п ошибок:
000…01
000…10
……….
010…00
100…00
Различных ненулевых опознавателей должно быть не менее п. Необходимое число проверочных разрядов, следовательно, должно определяться из соотношения
2n-k -1 n или 2n-k -1 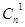
Если необходимо исправить не только все единичные, но и все двойные независимые ошибки, соответствующее неравенство принимает вид
2n-k-l + 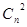
В общем случае для исправления всех независимых ошибок кратности до s включительно получаем
2n-k-l + +…+ 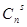
Стоит подчеркнуть, что в приведенных соотношениях указывается теоретический предел минимально возможного числа проверочных символов, который далеко не во всех случаях можно реализовать практически. Часто проверочных символов требуется больше, чем следует из соответствующего равенства.
Одна из причин этого выяснится при рассмотрении процесса сопоставления каждой подлежащей исправлению ошибки с ее опознавателем.
4.8.1 Составление таблицы опознавателей
Начнем для простоты с установления опознавателей для случая исправления одиночных ошибок. Допустим, что необходимо закодировать 15 команд. Тогда требуемое число информационных разрядов равно четырем. Пользуясь соотношением 2n-k - 1= п, определяем общее число разрядов кода, а следовательно, и число ошибок, подлежащих исправлению (n = 7). Три избыточных разряда позволяют использовать в качестве опознавателей трехразрядные двоичные последовательности.
В данном случае ненулевые последовательности в принципе могут быть сопоставлены с подлежащими исправлению ошибками в любом порядке. Однако более целесообразно сопоставлять их с ошибками в разрядах, начиная с младшего, в порядке возрастания двоичных чисел (табл. 4.6).
Таблица 4.6.
| Векторы ошибок | Опознаватели | Векторы ошибок | Опознаватели |
| 0000001 | 001 | 0010000 | 101 |
| 0000010 | 010 | 0100000 | 110 |
| 0000100 | 011 | 1000000 | 111 |
| 0001000 | 100 |
При таком сопоставлении каждый опознаватель представляет собой двоичное число, указывающее номер разряда, в котором произошла ошибка.
Коды, в которых опознаватели устанавливаются по указанному принципу, известны как коды Хэмминга.
Возьмем теперь более сложный случай исправления одиночных и двойных независимых ошибок. В качестве опознавателей одиночных ошибок в первом и втором разрядах можно принять, как и ранее, комбинации 0...001 и 0...010.
Однако в качестве опознавателя одиночной ошибки в третьем разряде комбинацию 0...011 взять нельзя. Такая комбинация соответствует ошибке одновременно в первом и во втором разрядах, а она также подлежит исправлению и, следовательно, ей должен соответствовать свой опознаватель 0...011.
В качестве опознавателя одиночной ошибки в третьем разряде можно взять только трехразрядную комбинацию 0...0100, так как множество двухразрядных комбинаций уже исчерпано. Подлежащий исправлению вектор ошибки 0...0101 также можно рассматривать как результат суммарного воздействия двух векторов ошибок 0...0100 и 0...001 и, следовательно, ему должен быть поставлен в соответствие опознаватель, представляющий собой сумму по модулю 2 опознавателей этих ошибок, т.е. 0...0101.
Аналогично находим, что опознавателем вектора ошибки 0...0110 является комбинация 0...0110.
Определяя опознаватель для одиночной ошибки в четвертом разряде, замечаем, что еще не использована одна из трехразрядных комбинаций, а именно 0...0111. Однако, выбирая в качестве опознавателя единичной ошибки в i-м разряде комбинацию с числом разрядов, меньшим i, необходимо убедиться в том, что для всех остальных подлежащих исправлению векторов ошибок, имеющих единицы в i-м и более младших разрядах, получатся опознаватели, отличные от уже использованных. В нашем случае подлежащими исправлению векторами ошибок с единицами в четвертом и более младших разрядах являются: 0...01001, 0...01010, 0...01100.
Если одиночной ошибке в четвертом разряде поставить в соответствие опознаватель 0...0111, то для указанных векторов опознавателями должны были бы быть соответственно
 0…0111 0…0111 0…0111
0…0111 0…0111 0…0111
0…0001 0…0010 0…0100
_______ ________ _______
0…0110 0…0101 0…0011
Однако эти комбинации уже использованы в качестве опознавателей других векторов ошибок, а именно: 0...0110, 0...0101, 0...0011.
Следовательно, во избежание неоднозначности при декодировании в качестве опознавателя одиночной ошибки в четвертом разряде следует взять четырехразрядную комбинацию 1000. Тогда для векторов ошибок
0...01001, 0...01010, 0...01100
опознавателями соответственно будут:
0...01001, 0...01010, 0...01100.
Аналогично можно установить, что в качестве опознавателя одиночной ошибки в пятом разряде может быть выбрана не использованная ранее четырехразрядная комбинация 01111.
Действительно, для всех остальных подлежащих исправлению векторов ошибок с единицей в пятом и более младших разрядах получаем опознаватели, отличающиеся от ранее установленных:
Векторы ошибок Опознаватели
0...010001 0…01110
0...010010 0…01101
0...010100 0…01011
0...011000 0…00111
Продолжая сопоставление, можно получить таблицу опознавателей для векторов ошибок данного типа с любым числом разрядов. Так как опознаватели векторов ошибок с единицами в нескольких разрядах устанавливаются как суммы по модулю 2 опознавателей одиночных ошибок в этих разрядах, то для определения правил построения кода и составления проверочных равенств достаточно знать только опознаватели одиночных ошибок в каждом из разрядов. Для построения кодов, исправляющих двойные независимые ошибки, таблица таких опознавателей определена с помощью вычислительной машины вплоть до 29-го разряда [Теория кодирования. Сборник. – М.:Мир, 1964]. Опознаватели одиночных ошибок в первых пятнадцати разрядах приведены в табл. 4.7.
По тому же принципу аналогичные таблицы определены и для ошибок других типов, например для тройных независимых ошибок, пачек ошибок в два и три символа.
4.8.2 Определение проверочных равенств
Итак, для любого кода, имеющего целью исправлять наиболее вероятные векторы ошибок заданного канала связи (взаимно независимые ошибки или пачки ошибок), можно составить таблицу опознавателей одиночных ошибок в каждом из разрядов. Пользуясь этой таблицей, нетрудно определить, символы каких разрядов должны входить в каждую из проверок на четность.
Таблица 4.7.
| Номер разряда | Опознаватель | Номер разряда | Опознаватель | Номер разряда | Опознаватель |
| 1 | 00000001 | 6 | 00010000 | 11 | 01101010 |
| 2 | 00000010 | 7 | 00100000 | 12 | 10000000 |
| 3 | 00000100 | 8 | 00110011 | 13 | 10010110 |
| 4 | 00001000 | 9 | 01000000 | 14 | 10110101 |
| 5 | 00001111 | 10 | 01010101 | 15 | 11011011 |
Рассмотрим в качестве примера опознаватели для кодов, предназначенных исправлять единичные ошибки (табл. 4.8).
Таблица 4.8.
| Номер разрядов | Опознаватель | Номер разрядов | Опознаватель | Номер разрядов | Опознаватель |
| 1 | 0001 | 7 | 0111 | 12 | 1100 |
| 2 | 0010 | 8 | 1000 | 13 | 1101 |
| 3 | 0011 | 9 | 1001 | 14 | 1110 |
| 4 | 0100 | 10 | 1010 | 15 | 1111 |
| 5 | 0101 | 11 | 1011 | 16 | 10000 |
| 6 | 0110 |
В принципе можно построить код, усекая эту таблицу на любом уровне. Однако из таблицы видно, что оптимальными будут коды (7, 4), (15, 11), где первое число равно n, а второе k, и другие, которые среди кодов, имеющих одно и то же число проверочных символов, допускают наибольшее число информационных символов.
Усечем эту таблицу на седьмом разряде и найдем номера разрядов, символы которых должны войти в каждое из проверочных равенств.
Предположим, что в результате первой проверки на четность для младшего разряда опознавателя будет получена единица. Очевидно, это может быть следствием ошибки в одном из разрядов, опознаватели которых в младшем разряде имеют единицу. Следовательно, первое проверочное равенство должно включать символы 1, 3, 5 и 7-го разрядов: a1 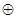 a3 a5 a7=0.
a3 a5 a7=0.
Единица во втором разряде опознавателя может быть следствием ошибки в разрядах, опознаватели которых имеют единицу во втором разряде. Отсюда второе проверочное равенство должно иметь вид a2 a3 a6 a7= 0 .
Аналогично находим и третье равенство: a4 a5 a6 a7= 0 .
Чтобы эти равенства при отсутствии ошибок удовлетворялись для любых значений информационных символов в кодовой комбинации, в нашем распоряжении имеется три проверочных разряда. Мы должны так выбрать номера этих разрядов, чтобы каждый из них входил только в одно из равенств. Это обеспечит однозначное определение значений символов в проверочных разрядах при кодировании. Указанному условию удовлетворяют разряды, опознаватели которых имеют по одной единице. В нашем случае это будут первый, второй и четвертый разряды.
Таким образом, для кода (7, 4), исправляющего одиночные ошибки, искомые правила построения кода, т. е. соотношения, реализуемые в процессе кодирования, принимают вид:
a1=a3 a5 a7,
a2=a3 a6 a7, (4.1)
a4=a5 a6 a7 .
Поскольку построенный код имеет минимальное хэммингово расстояние dmin = 3, он может использоваться с целью обнаружения единичных и двойных ошибок. Обращаясь к табл. 4.8, легко убедиться, что сумма любых двух опознавателей единичных ошибок дает ненулевой опознаватель, что и является признаком наличия ошибки.
Пример 27. Построим групповой код объемом 15 слов, способный исправлять единичные и обнаруживать двойные ошибки.
В соответствии с dи 0 min r+s+1код должен обладать минимальным хэмминговым расстоянием, равным 4. Такой код можно построить в два этапа. Сначала строим код заданного объема, способный исправлять единичные ошибки. Это код Хэмминга (7, 4). Затем добавляем еще один проверочный разряд, который обеспечивает четность числа единиц в разрешенных комбинациях.
Таким образом, получаем код (8, 4). В процессе кодирования реализуются соотношения:
a1=a3 a5 a7,
a2=a3 a6 a7,
a4=a5 a6 a7 .
a8=a1 a2 a3 a4 a5 a6 a7,
Обозначив синдром кода (7, 4) через S1, результат общей проверки на четность — через S2(S2 = 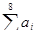 ) и пренебрегая возможностью возникновения ошибок кратности 3 и выше, запишем алгоритм декодирования:
) и пренебрегая возможностью возникновения ошибок кратности 3 и выше, запишем алгоритм декодирования:
при S1= 0 и S2= 0 ошибок нет;
при S1= 0 и S2= 1 ошибка в восьмом разряде;
при S1 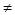 0 и S2= 0 двойная ошибка (коррекция блокируется, посылается запрос повторной передачи);
0 и S2= 0 двойная ошибка (коррекция блокируется, посылается запрос повторной передачи);
при S1 0 и S2= 1 одиночная ошибка (осуществляется ее исправление).
Пример 28. Используя табл. 4.8, составим правила построения кода (8,2), исправляющего все одиночные и двойные ошибки.
Усекая табл. 4.7 на восьмом разряде, найдем следующие проверочные равенства:
a1 a5 a8=0,
a2 a5 a8=0,
a3 a5=0,
a4 a5=0,
a6 a8=0,
a7 a8=0.
Соответственно правила построения кода выразим соотношениями
a1=a5 a8 (4.2 а)
a2=a5 a8 (4.2 б)
a3=a5 (4.2 в)
a4=a5 (4.2 г)
a6=a8 (4.2 д)
a7=a8 (4.2 е)
Отметим, что для построенного кода dmin = 5, и, следовательно, он может использоваться для обнаружения ошибок кратности от 1 до 4.
Соотношения, отражающие процессы кодирования и декодирования двоичных линейных кодов, могут быть реализованы непосредственно с использованием сумматоров по модулю два. Однако декодирующие устройства, построенные таким путем для кодов, предназначенных исправлять многократные ошибки, чрезвычайно громоздки. В этом случае более эффективны другие принципы декодирования.
4.8.3 Мажоритарное декодирование групповых кодов
Для линейных кодов, рассчитанных на исправление многократных ошибок, часто более простыми оказываются декодирующие устройства, построенные по мажоритарному принципу. Это метод декодирования называют также принципом голосования или способом декодирования по большинству проверок. В настоящее время известно значительное число кодов, допускающих мажоритарную схему декодирования, а также сформулированы некоторые подходы при конструировании таких кодов.
Мажоритарное декодирование тоже базируется на системе проверочных равенств. Система последовательно может быть разрешена относительно каждой из независимых переменных, причем в силу избыточности это можно сделать не единственным способом.
Любой символ аi выражается d (минимальное кодовое расстояние) различными независимыми способами в виде линейных комбинаций других символов. При этом может использоваться тривиальная проверка аi = аi. Результаты вычислений подаются на соответствующий этому символу мажоритарный элемент. Последний представляет собой схему, имеющую d входов и один выход, на котором появляется единица, когда возбуждается больше половины его входов, и нуль, когда возбуждается число таких входов меньше половины. Если ошибки отсутствуют, то проверочные равенства не нарушаются и на выходе мажоритарного элемента получаем истинное значение символа. Если число проверок d 2s+ 1 и появление ошибки кратности s и менее не приводит к нарушению более s проверок, то правильное решение может быть принято по большинству неискаженных проверок. Чтобы указанное условие выполнялось, любой другой символ aj(j i) не должен входить более чем в одно проверочное равенство. В этом случае мы имеем дело с системой разделенных проверок.
Пример 29. Построим систему разделенных проверок для декодирования информационных символов рассмотренного ранее группового кода (8,2).
Поскольку код рассчитан на исправление любых единичных и двойных ошибок, число проверочных равенств для определения каждого символа должно быть не менее 5. Подставив в равенства (4.2 а) и (4.2 б) значения а8, полученные из равенств (4.2 д) и (4.2 е) и записав их относительно a5 совместно с равенствами (4.2 в) и (4.2 г) и тривиальным равенством a5 = a5, получим следующую систему разделенных проверок для символа a5:
a5 = a6 a1,
a5 = a7 a2,
а5 = а3,
а5 = a4,
а5 = а5.
Для символа a8 систему разделенных проверок строим аналогично:
a8 = a3 a1,
a8 = a4 a2,
a8 = а6,
a8 = a7,
a8 = а8.
4.8.4 Матричное представление линейных кодов
Матрицей размерности l 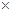 n называют упорядоченное множество l n элементов, расположенных в виде прямоугольной таблицы с l строками и n столбцами:
n называют упорядоченное множество l n элементов, расположенных в виде прямоугольной таблицы с l строками и n столбцами:
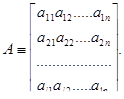
Транспонированной матрицей к матрице А называют матрицу, строками которой являются столбцы, а столбцами строки матрицы А:
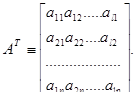
Матрицу размерности n n называют квадратной матрицей порядка n . Квадратную матрицу, у которой по одной из диагоналей расположены только единицы, а все остальные элементы равны нулю, называют единичной матрицей I. Суммой двух матриц А 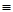 |аij| и В |bij| размерности l n называют матрицу размерности l n:
|аij| и В |bij| размерности l n называют матрицу размерности l n:
А + В |аij| + |bij| |аij + bij|.
Умножение матрицы А |аij| размерности l n на скаляр с дает матрицу размерности l n: сА c |аij| |c аij|.
Матрицы А |аij| размерности l n и В |bjk| размерности n m могут быть перемножены, причем элементами c ik матрицы — произведения размерности l m являются суммы произведений элементов l-й строки матрицы А на соответствующие элементы k-го столбца матрицы В:
c ik = 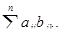
В теории кодирования элементами матрицы являются элементы некоторого поля GF(P), а строки и столбцы матрицы рассматриваются как векторы. Сложение и умножение элементов матриц осуществляется по правилам поля GF(P).
Пример 30. Вычислим произведение матриц с элементами из поля GF (2):
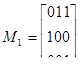
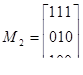
Элементы c ik матрицы произведения М = M1M2 будут равны:
c 11 = (011) (101) = 0 + 0 + 1 = 1
c 12 = (011) (110) = 0 + 1 + 0 = 1
c 13 = (011) (100) = 0 + 0 + 0 = 0
c 21 = (100) (101) = 1 + 0 + 0 = 1
c 22 = (100) (110) = 1 + 0 + 0 = 1
c 23 = (100) (100) = 1 + 0 + 0 = 1
c 31 = (001) (101) = 0 + 0 + 1 = 1
c 32 = (001) (110) = 0 + 0 + 0 = 0
c 33 = (001) (100) = 0 + 0 + 0 = 0
Следовательно, 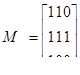
Зная закон построения кода, определим все множество разрешенных кодовых комбинаций. Расположив их друг под другом, получим матрицу, совокупность строк которой является подпространством векторного пространства n-разрядных кодовых комбинаций (векторов) из элементов поля GF(P). В случае двоичного (n, k)-кода матрица насчитывает n столбцов и 2k—1 строк (исключая нулевую). Например, для рассмотренного ранее кода (8,2), исправляющего все одиночные и двойные ошибки, матрица имеет вид

При больших n и k матрица, включающая все векторы кода, слишком громоздка. Однако совокупность векторов, составляющих линейное пространство разрешенных кодовых комбинаций, является линейно зависимей, так как часть векторов может быть представлена в виде линейной комбинации некоторой ограниченной совокупности векторов, называемой базисом пространства.
Совокупность векторов V1, V2, V3, ..., Vn называют линейно зависимой, когда существуют скаляры с1,..сn (не все равные нулю), при которых
c 1V1 + c 2V2+…+ cnVn= 0
В приведенной матрице, например, третья строка представляет собой суммы по модулю два первых двух строк. Для полного определения пространства разрешенных кодовых комбинаций линейного кода достаточно записать в виде матрицы только совокупность линейно независимых векторов. Их число называют размерностью векторного пространства.
Среди 2k – 1 ненулевых двоичных кодовых комбинаций — векторов их только k. Например, для кода (8,2)
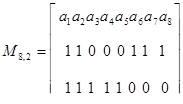
Матрицу, составленную из любой совокупности векторов линейного кода, образующей базис пространства, называют порождающей (образующей) матрицей кода.
Если порождающая матрица содержит k строк по n элементов поля GF(q), то код называют (n, k)-кодом. В каждой комбинации (n, k)-кода k информационных символов и n – k проверочных. Общее число разрешенных кодовых комбинаций (исключая нулевую) Q = qk-1.
Зная порождающую матрицу кода, легко найти разрешенную кодовую комбинацию, соответствующую любой последовательности Аki из k информационных символов.
Она получается в результате умножения вектора Аki на порождающую матрицу Мn,k:
Аni = Аki • Мn,k .
Найдем, например, разрешенную комбинацию кода (8,2), соответствующую информационным символам a5=l, a8 = 1:
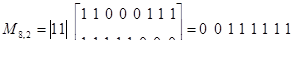 .
.
Пространство строк матрицы остается неизменным при выполнении следующих элементарных операций над строками: 1) перестановка любых двух строк; 2) умножение любой строки на ненулевой элемент поля; 3) сложение какой-либо строки с произведением другой строки на ненулевой элемент поля, а также при перестановке столбцов.
Если образующая матрица кода M2 получена из образующей матрицы кода M1 с помощью элементарных операций над строками, то обе матрицы порождают один и тот же код. Перестановка столбцов образующей матрицы кода приводит к образующей матрице эквивалентного кода. Эквивалентные коды весьма близки по своим свойствам. Корректирующая способность таких кодов одинакова.
Для анализа возможностей линейного (n, k)-кода, а также для упрощения процесса кодирования удобно, чтобы порождающая матрица (Мn,k) состояла из двух матриц: единичной матрицы размерности k k и дописываемой справа матрицы-дополнения (контрольной подматрицы) размерности k • (n – k), которая соответствует n – k проверочным разрядам:
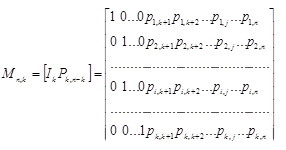 (4.3)
(4.3)
Разрешенные кодовые комбинации кода с такой порождающей матрицей отличаются тем, что первые k символов в них совпадают с исходными информационными, а проверочными оказываются (n - k) последних символов. Действительно, если умножим вектор-строку Ak,i = = (a1 a2…ai...ak) на матрицу Мn,k= [IkPk,n-k], получим вектор
An,i = (a1a2...ai...ak...ak+1...aj...an),
где проверочные символы аj(k +1 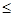 j n) являются линейными комбинациями информационных:
j n) являются линейными комбинациями информационных:
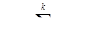 (4.4)
(4.4)
Коды, удовлетворяющие этому условию, называют систематическими. Для каждого линейного кода существует эквивалентный систематический код. Как следует из (4.3), (4.4), информацию о способе построения такого кода содержит матрица-дополнение. Если правила построения кода (уравнения кодирования) известны, то значения символов любой строки матрицы-дополнения получим, применяя эти правила к символам соответствующей строки единичной матрицы.
Пример 31. Запишем матрицы Ik, Рk,n-k_и Mn,k для двоичного кода (7,4).
Единичная матрица на четыре разряда имеет вид

Один из вариантов матрицы дополнения можно записать, используя соотношения (4.1)
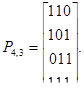
Тогда для двоичного кода Хэммннга имеем:


Запишем также матрицу для систематического кода (7,4):
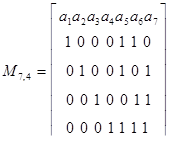
В свою очередь, по заданной матрице-дополнению Pk,n-k можно определить равенства, задающие правила построения кода. Единица в первой строке каждого столбца указывает на то, что в образовании соответствующего столбцу проверочного разряда участвовал первый информационный разряд. Единица в следующей строке любого столбца говорит об участии в образовании проверочного разряда второго информационного разряда и т, д.
Так как матрица-дополнение содержит всю информацию о правилах построения кода, то систематический код с заданными свойствами можно синтезировать путем построения соответствующей матрицы-дополнения.
Так как минимальное кодовое расстояние d для линейного кода равно минимальному весу его ненулевых векторов, то в матрицу-дополнение должны быть включены такие k строк, которые удовлетворяли бы следующему общему условию: вектор-строка образующей матрицы, получающаяся при суммировании любых l (1 l k) строк, должна содержать не менее d – l отличных от нуля символов.
Действительно, при выполнении указанного условия любая разрешенная кодовая комбинация, полученная суммированием l строк образующей матрицы, имеет не менее d ненулевых символов, так как l ненулевых символов она всегда содержит в результате суммирования строк единичной матрицы. Синтезируем таким путем образующую матрицу двоичного систематического кода (7,4) с минимальным кодовым расстоянием d = 3. В каждой вектор-строке матрицы-дополнения согласно сформулированному условию (при l=1) должно быть не менее двух единиц. Среди трехразрядных векторов таких имеется четыре: 011, 110, 101, 111.
Эти векторы могут быть сопоставлены со строками единичной матрицы в любом порядке. В результате получим матрицы систематических кодов, эквивалентных коду Хэмминга, например:
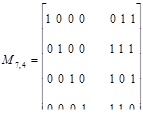
Нетрудно убедиться, что при суммировании нескольких строк такой матрицы (l>1) получим вектор-строку, содержащую не менее d=3 ненулевых символов.
Имея образующую матрицу систематического кода Мn,k= [IkPk,n-k], можно построить так называемую проверочную (контрольную) матрицу Н размерности (n – k) n:
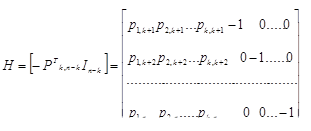
При умножении неискаженного кодового вектора Аni на матрицу, транспонированную к матрице Н, получим вектор, все компоненты которого равны нулю:
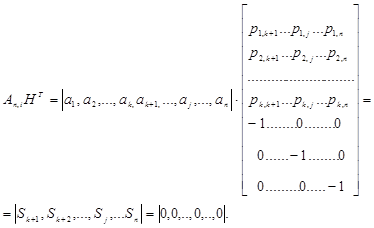
Каждая компонента Sj является результатом проверки справедливости соответствующего уравнения декодирования:
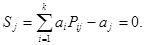
В общем случае, когда кодовый вектор Аni =(a1, a2,…, ai,…,ak,ak+1,…,aj,…,an) искажен вектором ошибки ξni =(ξ1, ξ2,…, ξi,…,ξk,aξk+1,…,ξj,…,ξn), умножение вектора (Аni + ξni) на матрицу Нт дает ненулевые компоненты:

Отсюда видно, что Sj(k +1 j n) представляют собой символы, зависящие только от вектора ошибки, а вектор S = (Sk + 1, Sk + 2, ...,, Sj, ..., Sn) является не чем иным, как опознавателем ошибки (синдромом).
Для двоичных кодов (операция сложения тождественна операции вычитания) проверочная матрица имеет вид
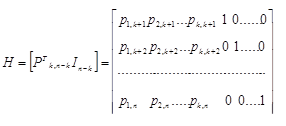
Пример 32. Найдем проверочную матрицу Н для кода (7,4) с образующей матрицей М:
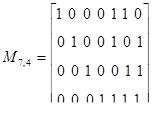
Определим синдромы в случаях отсутствия и наличия ошибки в кодовом векторе 1100011.
Выполним транспонирование матрицы P4,3
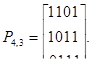
Запишем проверочную матрицу:
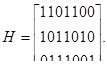
Умножение на Нт неискаженного кодового вектора 1100011 дает нулевой синдром:

При наличии в кодовом векторе ошибки, например, в 4-м разряде (1101011) получим:
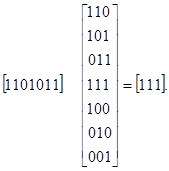
Следовательно, вектор-строка 111 в данном коде является опознавателем (синдромом) ошибки в четвертом разряде. Аналогично можно найти и синдромы других ошибок. Множество всех опознавателей идентично множеству опознавателей кода Хэмминга (7,4), но сопоставлены они конкретным векторам ошибок по-иному, в соответствии с образующей матрицей данного (эквивалентного) кода.
4.8.5 Технические средства кодирования и декодирования для групповых кодов
Кодирующее устройство строится на основании совокупности равенств, отражающих правила построения кода. Определение значений символов в каждом из n – k проверочных разрядов в кодирующем устройстве осуществляется посредством сумматоров по модулю два.
На каждый разряд сумматора (кроме первого) используется четыре элемента И (вентиля) и два элемента ИЛИ.
Сумматор по модулю два выпускают в виде отдельного логического элемента, который на схеме изображается прямоугольником с надписью внутри - М2. Приведем несколько примеров реализации кодирующих и декодирующих устройств групповых кодов.
Пример 33. Рассмотрим техническую реализацию кода (7,4), имеющего целью исправление одиночных ошибок.
Правила построения кода определяются равенствами
a1=a3 a5 a7,
a2=a3 a6 a7,
a4=a5 a6 a7.
Схема кодирующего устройства приведена на рис. 4.6.
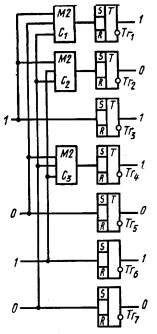
Рис. 4.6.
При поступлении импульса синхронизации со схемы управления подлежащая кодированию k-разрядная комбинация неизбыточного кода переписывается, например, с аналого-кодового преобразователя в информационные разряды n-разрядного регистра. Предположим, что в результате этой операции триггеры регистра установились в состояния, указанные в табл. 4.9.
С некоторой задержкой формируются выходные импульсы сумматоров С1, С2 С3, которые устанавливают триггеры проверочных разрядов в положение 0 или 1 в соответствии с приведенными выше равенствами. Например, в нашем случае ко входам сумматора C1 подводится информация, записанная в 3, 5 и 7-разрядах и, следовательно, триггер Тг1 первого проверочного разряда устанавливается в положение 1, аналогично триггер Тг2 устанавливается в положение 0, а триггер Тг4 — в положение 1.
Сформированная в регистре разрешенная комбинация (табл. 4.10) импульсом, поступающим с блока управления, последовательно или параллельно считывается в линию связи. Далее начинается кодирование следующей комбинации.
Рассмотрим теперь схему декодирования и коррекции ошибок (рис. 4.7), строящуюся на основе совокупности проверочных равенств. Для кода (7, 4) они имеют вид:
a1 a3 a5 a7= 0 ,
a2 a3 a6 a7= 0,
a4 a5 a6 a7= 0 .
Таблица 4.9.
| Тr1 | Тr2 | Tr3 | Тr4 | Тr5 | Tr6 | Тr7 |
| — | — | 1 | — | 0 | 1 | 0 |
Кодовая комбинация, возможно содержащая ошибку, поступает на n-разрядный приемный регистр (на рис. 4.7 триггеры Тг1 –Тг7). По окончании переходного процесса в триггерах с блока управления на каждый из сумматоров (C1 – С3) поступает импульс опроса.
Таблица 4.10.
| Тг1 | Тг2 | Тг3 | Тг4 | Тг5 | Tг6 | Тг7 |
| 1 | 0 | 1 | 1 | 0 | 1 | 0 |
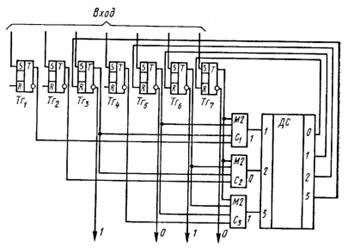
Рис. 4.7.
Выходные импульсы сумматоров устанавливают в положение 0 или 1 триггеры регистра опознавателей. Если проверочные равенства выполняются, все триггеры регистра опознавателей устанавливаются в положение 0, что соответствует отсутствию ошибок. При наличии ошибки в регистр опознавателей запишется опознаватель этого вектора ошибки. Дешифратор ошибки DC ставит в соответствие множеству опознавателей множество векторов ошибок. При опросе выходных вентилей дешифратора сигналы коррекции поступают только на те разряды, в которых вектор ошибки, соответствующий записанному на входе опознавателю, имеет единицы. Сигналы коррекции воздействуют на счетные входы триггеров. Последние изменяют свое состояние, и, таким образом, ошибка исправлена. На триггеры проверочных разрядов импульсы коррекции можно не посылать, если после коррекции информация списывается только с информационных разрядов. Для кода Хэмминга (7,4) любой опознаватель представляет собой двоичное трехразрядное число, равное номеру разряда приемного регистра, в котором записан ошибочный символ.
Предположим, что сформированная ранее в кодирующем устройстве комбинация при передаче исказилась и на приемном регистре была зафиксирована в виде, записанном в табл. 4.11.
Таблица 4.11.
| Тг1 | Тг2 | Тг3 | Тг4 | Тг5 | Тг6 | Tг7 |
| 1 | 0 | 1 | 1 | 1 | 1 | 0 |
По результатам опроса сумматоров получаем:
на выходе С1 a1 a3 a5 a7= 1+1+1+0=1,
на выходе С2 a2 a3 a6 a7= 0+1+1+0=0,
на выходе С3 a4 a5 a6 a7= 1+1+1+0=1 .

Рис. 4.8.
Следовательно, номер разряда, в котором произошло искажение, 101 или 5. Импульс коррекции поступит на счетный вход триггера Тг5, и ошибка будет исправлена.
Пример 34. Реализуем мажоритарное декодирование для группового кода (8,2), рассчитанного на исправление двойных ошибок.
В случае мажоритарного декодирования сигналы с триггеров приемного регистра поступают непосредственно или после сложения по модулю два в соответствии с уравнениями системы разделённых проверок на мажоритарные элементы М, формирующие скорректированные информационные символы.
Схема декодирования представлена на рис. 4.8. На входах мажоритарных элементов указаны сигналы, соответствующие случаю поступления из канала связи кодовой информации, искаженной в обоих информационных разрядах (5-м и 8-м). Реализуя принцип решения «по большинству», мажоритарные элементы восстанавливают на выходе правильные значения информационных символов.
Дата: 2019-07-30, просмотров: 482.