Особенно автор обращает внимание на имена переменных, констант, функций в программе. В программе существуют две позиции на значение имен:
1. Готовность (Доступность). Этим свойством определяются места программы, в которых можно получить доступ к тем или иным объектам (переменным величинам или функциям). Здесь существует 4 основных программных области – программа, модуль, функция, блок. Объекты, которые определяются в самой программе или модуле являются глобальными объектами, а если определяются в пределах блока или функции, то являются локальными объектами.
2. Срок службы (Жизненный цикл). Здесь говорится о длительности упорядочивания ячеек памяти. Различают полное время распространения (статическая продолжительность) и время выполнения блока, в котором определялся объект.
Эти правила дают ряд преимуществ при написании программ:
· Переменная получает определенное значение в пределах функции.
· Локальные переменные не применяются для всей программы, поэтому можно использовать одинаковые имена переменных в различных функциях.
· Глобальные переменные определяются один раз и используются всеми функциями программы.
· Если имена глобальных и локальных переменных совпадают, то в данной функции используются значения локальных переменных. Таким образом, необходимо избегать написания одинаковых имен переменных.
Рекурсия и итерация
В этом параграфе автор рассказывает о очень важном методе решения задач – рекурсивных алгоритмах. Алгоритм называется рекурсивным, если вызов функции происходит в пределах самой функции, т.е. функция ссылается сама на себя. При этом основная мысль состоит в том, чтобы уменьшать рекурсивным образом данную проблему до тех пор, пока не будет получен простейший случай. При этом значительно уменьшается алгоритм решения задачи.
Чтобы достигнуть рекурсивности, локальные переменные величины и параметры должны сохраняться не в статической памяти, а в так называемой динамической памяти, которая реализуется программно.
Также из большого количества шагов состоит итерационный алгоритм. Он содержит промежуточные шаги, которые образуют основу для промежуточных результатов в следующем повторении (итерации). Итерации используются в основном при обработке больших массивов данных. Различают 2 основных вида итераций:
§ Алгоритмы с заранее известным количеством шагов повторения.
§ Алгоритмы с заранее неизвестным количеством шагов повторения.
Программист должен всегда заботиться о том, чтобы все процессы, которые протекают в определенной программе, после конечного числа шагов завершались. К сожалению, зачастую этого не происходит и программа «зацикливается».
Поэтому, если написана какая-то условная или циклическая структура, необходимо следить, чтобы после конечного числа прохождений условие не было больше выполнено. Конечность повторения можно подытожить следующим образом: число шагов зависит от переменных величин программы и оно больше 0, если условие выполняется хотя бы один раз, а значение счетчика определяется в зависимости от действий.
Функции ввода-вывода
В этом параграфе автор рассказывает о наиболее важных стандартных функциях, которые позволяют вводить информацию с клавиатуры и выводить ее на экран.
Ввод и вывод данных в C происходит через файловый интерфейс. При этом с устройствами, как, например, принтер или консоль обращаются как с файлами. В стандартной C-библиотеке для нескольких устройств существуют стандартные файлы:
· stdin (стандартный ввод данных, клавиатура)
· stdout (стандартный вывод, монитор)
· stderr (ошибки вывода, монитор)
С функциями ввода-вывода связан файл заголовка stdio.h стандартной библиотеки заголовков. В нем определены для применения функций необходимые функциональные прототипы, такие как типы и константы (макрокоманды), которые стоят в связи с реализацией и приложением функций. Кроме всего прочего определяется константа EOF, которая служит для внутренней идентификации конца файлов.
Также существует специальная функция вывода информации – printf, которая имеет вид:
int printf(контрольная строка, аргумент1, аргумент2, ... ). Функция printf копирует символы из формата стандартного вывода либо до конца строки, либо до символа %. Чтобы определить тип формата вывода, функция ищет следующие за % символы. Самый часто используемым является формат %d, который выводит целые числа в десятичной системе счисления.
Стандартной функцией ввода данных в C является функция scanf, которая имеет следующий вид: scanf (контрольная строка, аргумент1, аргумент2,...). Она переводит соответственно в управляющую строку "контрольную строку" данного типа и формата. Она задает формат и назначает конвертированные значения через определенный адрес соответствующим переменным величинам arg1, arg2....
Типы данных в C
Числа и числовые системы
В этой параграфе автор рассказывает об основах представления чисел в компьютере.
Значение числа Z = an an-1 ... a0 a-1 ... a-m в позиционной системе счисления по основанию B имеет вид:
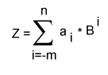
где 0 <= a <B.
Например, в десятичной системе счисления число 1972 выглядит так:
1972 = 1 * 103 + 9 * 102 + 7 * 101 + 2 * 100
Формой представления чисел в компьютере является двоичная. Недостатком этой системы является запутанная, монотонная последовательность цифр при изображении длинных двоичных чисел. Поэтому в информатике также используют часто восьмеричную и шестнадцатеричную системы счисления. Именно о них рассказывает автор в этой главе.
Достаточно часто возникает необходимость преобразования чисел из одной системы в другую, в частности, в наиболее понятную человеку десятичную систему счисления. Правило преобразования из любой системы счисления в десятичную выглядит так:
При переводе числа из любой системы в десятичную надо это число представить в виде суммы степеней основания его системы счисления.
Дробные числа возможно изображать в информатике двумя способами:
§ Изображение с фиксированной точкой (например, 1.25). При этом точка всегда стоит на своем месте в нужном разряде.
§ Изображение с плавающей точкой. При данном изображении число записывается таким образом, что точка скользит всегда к первой отличной от нуля цифре. Такая запись выглядит следующим образом:
Z = М * BE, где M = 0.xxxxxxx...., 1/B <= М <1
Так как основа нам известна, то число может представляться мантиссой М и экспонентой E (нормализованное изображение). Например:
Z = 42.5456 --> 0.425456 * 102 --> M = 425456, E = 2
Основные типы данных
В этом разделе профессор перечисляет соответствующие категории языка C.
К элементарным типам данных, использующихся в C относятся: char (символьный), int (целый), float (вещественный тип с одинарной точностью), double (вещественный тип с двойной точностью), void (пустой, используется для функций и указателей).
Автор выделяет следующие виды констант, использующихся в языке Си:
· целочисленные константы, которые имеют тип signed int.
· Константы с плавающей точкой. Они представляются в десятичном или экспоненциальном виде и имеют тип double.
· Символьные константы указываются в кавычках ‘’.
· Литерные константы имеют тип String и расположены в кавычках “”.
Затем Плате рассматривает основные арифметические операторы («-», «+», «*», «/», «%»), используемые в языке C. Здесь, в отличие от других языков программирования, присваивание значений записывается прямо в операторах, поэтому арифметические операции применяются во всех структурах, где есть операторы. В C также используется также два специальных оператора:
o Инкремент (приращение на 1) – «++»
o Декремент (отрицательное приращение на 1) – «--»
Они могут стоять перед или после операнда, что задает порядок выполнения операций.
Помимо этого в C используются логические операторы:
· ! - логическое отрицание
· && - логическое «и»
· || - логическое «или»
Профессор отдельно выделяет операторы сравнения, используемые в языке:
· < - меньше
· <= - меньше равно
· > - больше
· >= - больше равно
· == - равно (тождественно)
· != - не равно
Специального логического типа данных Boolean в C не существует, а считается, что
Ø Неравно 0 – правда (значение 1)
Ø Равно 0 – ложь (значение 0)
Составные операторы используются для более компактной записи выражений в С. Автор показывает, что здесь возможны следующие записи:
Выражение1 op= Выражение2, которая эквивалентна записи –
Выражение1 = (Выражение1) op (Выражение2), где op – любой оператор.
Затем профессор выделяет два основных вида массивов:
§ Одномерные поля. Определим поле с 5 элементами - int n [5]; Тогда эти 5 переменных величин располагаются в памяти последовательно:
| n [0] | n [1] | n [2] | n [3] | n [4] |
Элементы массива начинаются всегда с индекса 0 и кончаются индексом [n-1].
При этом не происходит проверка на допустимую область памяти компилятором.
§ Многомерные поля. Для многомерных массивов переменные величины задаются несколько другими типами индексов. Пример определения двумерного массива: float x [8] [30];Здесь первый элемент - x [0] [0], и соответственно последний x [7] [29].
Юрген Плате подходит к объяснению работы с символами и строками как с одномерными полями, которые имеют несколько особенностей. Строки могут инициализироваться также в классе памяти auto и должны быть замкнуты '\0 '. Например: char s[] = {'s','t','r','i','n','g','\0'};
Массивы char могут инициализироваться также константами String –
char s[] = "string";
В C не имеется никаких специальных элементов языка для манипуляции строками символов. Ряд функций существуют в C-стандартной библиотеке (копирование, сравнение, длина строк).
В отличие от массивов, которые работают с объектами одного типа, записи задают структуру для описания различных типов под общим именем. Преимущества этих структур состоит в объединении комплексных данных. Например, это персональные данные (Ф.И.О., адрес, социальный статус и т.д.) или студенческие данные (Ф.И.О, адрес, дисциплина, отметка и т.д.).
Записи в языке C описываются с помощью ключевого слова struct:
struct имя структуры {компонент(n)} переменная структуры (n);
Для доступа к элементу записи используются 2 собственных оператора.
При этом для прямого доступа необходима точка как разделитель переменной структуры и имени компонента, т.е переменная структуры . компонент
Структуры могут иметь также элементы, которые являются signed(со знаком) или unsigned(без знака) int, а некоторые имеют битовую длину. Поэтому обозначают эти элементы как поля бита. При определении структуры число битов таких переменных величин указывается определенно, согласно синтаксису:
typedef struct
{ unsigned b1 : 1;
unsigned b2 : 1;
int : 6;
int farbe : 4;
} bitpack;
Таким образом, в этой главе автором рассмотрены практически все типы данных, используемых в С и имеющих широкие возможности применения.
Файлы
Следующей структуре, являющейся основным носителем информации в компьютере, автор посвятил отдельную главу.
Файлы - это основная структура для постоянного хранения и ввода-вывода данных. Файлы состоят из различных компонентов определенного типа данных. В конец файла могут добавляться различные данные.
Вместе с типом файла определяются и несколько стандартных операций с файлами (Open – открытие файла, Close – закрытие файла, Read – чтение из файла данных, Write – запись данных в файл).
Типы доступа
В следующих параграфах автор определяет 2 основных типа доступа для файлов в Cи:
1) Последовательные файлы использовались на заре развития компьютерной техники, так как запись на перфоленту или магнитную ленту могла вестись только последовательно.2) Файлы с произвольным доступом. С появлением жестких дисков, которые позволяют обращаться к любым участкам памяти в любое время, появились файлы с произвольным доступом.В последовательных файлах позиционирование компонентов производится неявно и не подчиняется влиянию программы. В файлах с произвольным доступом операции считывания и записи дополняются указанием индекса компонентов. При этом индекс компонентов отсчитывается, как правило, от 1. Вместе с тем файл с произвольным доступом обладает сходством с типом данных "массив".
Доступ к различным периферийным устройствам в C осуществляется с помощью указателей. При этом файл должен открываться до начала доступа и закрываться после. Для выполнения этих функций используется стандартный файл C-библиотеки <stdio.h>.
Что касается самого распространенного типа файлов – текстовых, то в C они представляют собой файлы, компоненты которых буквы, т.е. символы типа char. Все тексты мы разделяем на строки, и здесь встает проблема: как определить конец строки, когда реализация текстовых файлов во всех программах разная?
В Си используется, так называемый, буферный вывод. Это значит, что выводится только тогда, если конец строки посылается устройству вывода, или выводится совсем, если программа завершает свои действия.
Здесь используют следующие функции языка C:
· int putc(int c, FILE *f) - записывает символы в текстовые файлы.
· int getc(FILE *f) – читает символы из файла.
· int puts(const char *s) – записывает последовательность символов в файл.
· char *gets(char *s) – чтение последовательности из файла.
При бинарном вводе и выводе данные представлены в допустимой форме, а внутреннее изображение в памяти перенесет (побайтово) данные в файл. Например, для бинарной записи переменных величин long нужно 4 байт памяти. Необходимое количество памяти зависит от величины числа и соответственно от его формата.
Функция fwrite записывает указанное количество элементов данных равной величины в файл. Здесь должны передаваться:
· Адрес первого элемента данных. · Величина отдельного элемента данных. · Количество записываемых элементов данных · Выходной файлЗатем автор рассказывает, как получить доступ к отдельным наборам данных файла с произвольным доступом. Для этого в C используются следующие команды:
int fseek(FILE *f, long offset, int origin)
Эта функция ставит указатель на определенную позицию в пределах файла. Функция позиционирует смещение (offset), которое считается в байтах. Значение origin устанавливается в соответствии со смещением (SEEK_SET oder 0 – смещение из начала файла, SEEK_END oder 1 – смещение из текущей позиции, SEEK_CUR oder 2 – смещение из конца файла)
Функция long ftell (FILE *f) указывает текущую позицию в файле, на которой находится указатель файла. В случае ошибки ftell принимает значение -1.
Функция void rewind (FILE *f) перемещает указатель на начало файла и удаляет значение ошибки.
Таким образом, Юрген Плате в отличие от других авторов книг по программированию достаточно подробно описывает процесс работы с файлами, снабжая каждую операцию подробными комментариями и примерами на языке С.
Указатель
В этой главе автор рассказывает об одном из важнейших понятий программирования в C – указателях.
Основы указателя
Указатели - это такие же переменные величины, которые нуждаются в ячейках памяти. Указатель - это переменная величина, которая содержит адрес другого объекта. Потом можно получить доступ к этому объекту косвенно с помощью указателя. В этих адресах памяти содержится либо адреса других переменных величин, либо адреса функций.
Указатели в языке C необходимо применять в следующих случаях:
· при передаче параметра
· при обработке массивов
· для обработки текста
· для доступа к специальным ячейкам памяти
Обозначаются указатели следующим образом: int *pc; , т.е. переменная pc является указателем тип int.
При этом используют преимущественно два типа указателей:
1. Оператор адреса &, который применяется к объекту, доставляющему адрес этого объекта. Например, pc=&c.
2. Смысловой оператор *, который применяет указатель к объекту, находящемуся в этой ячейке. Например, c=*pc; *pc=5;
Особенно важным является то, что * и & имеют более высокий приоритет, чем арифметические операторы. При этом если используются несколько операторов указателя последовательно, то выражение обрабатывается справа налево.
Аргументы указателя обладают возможностью обращаться к объектам функции из другой функции и изменять их.
Автор также показывает, что с указателями можно проводить определенные арифметические операции и операции сравнения. Разрешены, конечно, только такие операции, которые ведут к осмысленным результатам. К указателям могут целочисленные значения прибавляться и вычитаться из них. К указателям могут также применять декремент.
Можно указатели посредством операторов >,> =, <, <=, != и == сравнивать друг с другом. Всевозможные арифметические и логические операции, не описанные выше, не разрешены с указателями.
Указатель и массив
Как отмечает автор в следующих параграфах, между указателями и полями существует ярко выраженная связь. Каждая операция, которая может применяться к элементам массива, может выражаться также и указателями. Программа, содержащая указатели выполняется гораздо быстрее. Однако понять смысл использования указателей гораздо тяжелее.
Присваивание pa = *a [0] показывает, что pa указывает на 0-ой элемент массива a, т.е. pa содержит адрес a [0]. Вместо этого можно записать следующее: pa = a;
К отдельным элементам массива можно обращаться 3 различными способами:
· a [i] - i-ый элемент массива
· * (pa+i) - указатель pa + i * (длина элементов массива a)
· * (a+i) начало массива + i * (длина элементов a)
Таким образом, каждое значение индекса массива может определяться также как значение смещения указателя и наоборот. Выражение pa + i не значит, что к pa значение i прибавляется, а i устанавливает смещение объекта от pa.
Многомерные массивы можно задавать через указатели следующим образом:
Matrix[1][2]=*(Matrix[1]+2)
Matrix[1][2]=*(*(Matrix+1)+2)
Matrix[1][2]=*(*Matrix+1*M+2)
Так называемые структурные указатели имеют несколько другое обозначение:
Указатель на структурную переменную -> название элемента
Например, punkt.px соответствует (*punkt)-> px
Так как структура указателей и массивов очень похожа, то далее автор объясняет как составить массив указателей.
Массив указателей - это массив, состоящий из элементов-указателей. Вектор указателей определяется следующим образом:
Тип исходных данных *Имя вектора[]
Эту запись необходимо отличать от указателя на вектор:
(*Имя вектора) []
Компоненты вектора могут быть также адресами массивов. При этом такой массив указателей похож на многомерный массив.
Например, char *Z[3], где происходит определение массива с 3 элементами, которые являются соответственно указателями типа char. При этом Z является указателем на массив с 3 указателями char.
Указатель на функцию
Помимо указателей на типы данных в C можно определять указатели и на функцию, которые можно использовать затем как переменные величины. Это может пригодиться для передачи значения функции в другую функцию.
Указатель на функцию в C записывается следующим образом:
Тип возврата (*Имя функции) (Аргументы функции)
Здесь необходимо обратить особое внимание на то, что имя функции стоит в скобках. Если мы запишем без скобок *Имя функции (), то функция будет возвращать значение указателя.
Функциональные указатели можно использовать в следующих случаях:
· Как переменную-указатель, которая на функцию указывает.
· Распределять значения функциональных указателей.
· Определять массивы функциональных указателей.
· Передавать указатель на функцию как параметр.
· Получать указатель на функцию как возвращенное значение.
Таким образом, профессор обращает также особенное внимание на широкое использование указателей при программировании в С. Это, в общем-то, оправданно довольно высоким быстродействием программ с указателями, но может привести к дополнительным ошибкам программирования из-за трудностей восприятия указателей.
Дата: 2019-07-31, просмотров: 273.