Рассмотрим рис. 9-10 и попытаемся найти в них кратчайшие туры. Очевидно, что кратчайший тур не должен содержать пересекающихся ребёр (в противном случае, поменяв вершины при пересекающихся рёбрах местами, получим более короткий тур). В первом случае кратчайшим является тур 1-2-4-5-3-1, а во втором – тур 1-2-3-4-5-1. Анализируя множество других аналогичных расположении пяти и более городов, можно сделать следующее общее предположение:
Если можно построить выпуклый многоугольник, по периметру к 
 оторого лежат все города, то такой выпуклый многоугольник является кратчайшим туром.
оторого лежат все города, то такой выпуклый многоугольник является кратчайшим туром.
Однако не всегда можно построить выпуклый многоугольник, по периметру которого лежали бы все города. Велика вероятность того, что некоторые города не войдут в выпуклый многоугольник. Такие города будем называть “центральными”. Так как построить выпуклый многоугольник довольно легко, то задача сводится к тому, чтобы включить в тур в виде выпуклого многоугольника все центральные города с минимальными потерями. Пусть имеется массив T[n+1], содержащий в себе номера городов по порядку, которые должен посетить коммивояжер, т. е. вначале коммивояжер должен посетить город T[1], затем T[2], потом T[3] и т.д., причём T[n+1]=T[1] (коммивояжер должен вернуться в начальный город). Тогда, если выполняется равенство "i 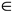 [1,2..n] C[T[i],p]+ C[p,T[i+1]]–C[T[I],T[i+1]] = min, то центральный город с номером p нужно включить в тур между городами T[i] и T[i+1]. Проделав эту операцию для всех центральных городов, в результате получим кратчайший тур. Для задачи, решённой нами методом ветвей и границ, этот алгоритм даёт правильное решение.
[1,2..n] C[T[i],p]+ C[p,T[i+1]]–C[T[I],T[i+1]] = min, то центральный город с номером p нужно включить в тур между городами T[i] и T[i+1]. Проделав эту операцию для всех центральных городов, в результате получим кратчайший тур. Для задачи, решённой нами методом ветвей и границ, этот алгоритм даёт правильное решение.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 1 | 13 | 6 | 13 | 14 | 15 | 14 | 16 | |
| 2 | 13 | 11 | 11 | 8 | 13 | 17 | 14 | |
| 3 | 6 | 11 | 5 | 6 | 11 | 7 | 11 | |
| 4 | 13 | 11 | 5 | 2 | 6 | 7 | 6 | |
| 5 | 14 | 8 | 6 | 2 | 6 | 5 | 6 | |
| 6 | 15 | 13 | 11 | 6 | 6 | 13 | 5 | |
| 7 | 14 | 17 | 7 | 7 | 5 | 13 | 9 | |
| 8 | 16 | 14 | 11 | 6 | 6 | 5 | 9 | |
| табл. 13 | ||||||||
Попробуем решить данным алгоритмом ЗК для восьми городов. Пусть имеем восемь городов, расположение которых показано на рис. 11. Матрица расстояний приведена рядом на табл. 13. Промежуточные построения кратчайшего тура показаны пунктирными линиями, цифры – порядок удаления рёбер. Таким образом, имеем для данного случая кратчайший тур 1-3-7-5-4-8-6-2-1. Длина этого тура: D=6+7+5+2+6+5+ 13+13=57. Этот результат является правильным, т.к. алгоритм лексического перебора, который никогда не ошибается, даёт точно такой же тур. (Следует также отметить, что жадный алгоритм для этого случая ошибается всего на 1 и даёт тур 1-3-4-5-7-8-6-2-1 длиной в 58).

Одним из возможных недостатков такого алгоритма является необходимость знать не матрицу расстояний, а координаты каждого города на плоскости. Если нам известна матрица расстояний между городами, но неизвестны их координаты, то для их нахождения нужно будет решить n систем квадратных уравнений с n неизвестными для каждой координаты. Уже для 6 городов это сделать очень сложно. Если же, наоборот, имеются координаты всех городов, но нет матрицы расстояний между ними, то создать эту матрицу несложно. Это можно легко сделать в уме для 5-6 городов. Для большего количества городов можно воспользоваться возможностями компьютера, в то время как промоделировать решение системы квадратных уравнений на компьютере довольно сложно.
На основе вышеизложенного можно сделать вывод, что этот алгоритм, наряду с деревянным алгоритмом и алгоритмом Дейкстры, можно отнести к приближённым (хотя за этим алгоритмом ни разу не было замечено выдачи неправильного варианта).
Генетические алгоритмы
Пусть дана некоторая сложная функция (целевая функция), зависящая от нескольких переменных, и требуется найти такие значения переменных, при которых значение функции максимально. Задачи такого рода называются задачами оптимизации и встречаются на практике очень часто.
Г  енетический алгоритм - это простая модель эволюции в природе, реализованная в виде компьютерной программы. В нем используются как аналог механизма генетического наследования, так и аналог естественного отбора. При этом сохраняется биологическая терминология в упрощенном виде. Вот как моделируется генетическое наследование:
енетический алгоритм - это простая модель эволюции в природе, реализованная в виде компьютерной программы. В нем используются как аналог механизма генетического наследования, так и аналог естественного отбора. При этом сохраняется биологическая терминология в упрощенном виде. Вот как моделируется генетическое наследование:
| Хромосома | Вектор (последовательность) из нулей и единиц. Каждая позиция (бит) называется геном. |
| Индивидуум = генетический код | Набор хромосом = вариант решения задачи. |
| Кроссовер | Операция, при которой две хромосомы обмениваются своими частями. |
| Мутация | Случайное изменение одной или нескольких позиций в хромосоме. |
Чтобы смоделировать эволюционный процесс, сгенерируем вначале случайную популяцию - несколько индивидуумов со случайным набором хромосом (числовых векторов). Генетический алгоритм имитирует эволюцию этой популяции как циклический процесс скрещивания индивидуумов и смены поколений.
Жизненный цикл популяции - это несколько случайных скрещиваний (посредством кроссовера) и мутаций, в результате которых к популяции добавляется какое-то количество новых индивидуумов. Отбором в генетическом алгоритме называется процесс формирования новой популяции из старой популяции, после чего старая популяция погибает. После отбора к новой популяции опять применяются операции кроссовера и мутации, затем опять происходит отбор, и так далее.
Отбор в генетическом алгоритме тесно связан с принципами естественного отбора в природе следующим образом:
| Приспособленность индивидуума | Значение целевой функции на этом индивидууме. |
| Выживание наиболее приспособленных | Популяция следующего поколения формируется в соответствии с целевой функцией. Чем приспособленнее индивидуум, тем больше вероятность его участия в кроссовере, т.е. размножении. |
Таким образом, модель отбора определяет, каким образом следует строить популяцию следующего поколения. Как правило, вероятность участия индивидуума в скрещивании берется пропорциональной его приспособленности. Часто используется так называемая стратегия элитизма, при которой несколько лучших индивидуумов переходят в следующее поколение без изменений, не участвуя в кроссовере и отборе. В любом случае каждое следующее поколение будет в среднем лучше предыдущего. Когда приспособленность индивидуумов перестает заметно увеличиваться, процесс останавливают и в качестве решения задачи оптимизации берут наилучшего из найденных индивидуумов.
Генетический алгоритм - новейший, но не единственно возможный с  пособ решения задач оптимизации. С давних пор известны два основных пути решения таких задач - переборный и локально-градиентный. У этих методов свои достоинства и недостатки, и в каждом конкретном случае следует подумать, какой из них выбрать.
пособ решения задач оптимизации. С давних пор известны два основных пути решения таких задач - переборный и локально-градиентный. У этих методов свои достоинства и недостатки, и в каждом конкретном случае следует подумать, какой из них выбрать.
Рассмотрим достоинства и недостатки стандартных и генетических методов на примере классической задачи коммивояжера (TSP - traveling salesman problem). Суть задачи состоит в том, чтобы найти кратчайший замкнутый путь обхода нескольких городов, заданных своими координатами. Оказывается, что уже для 30 городов поиск оптимального пути представляет собой сложную задачу, побудившую развитие различных новых методов (в том числе нейросетей и генетических алгоритмов).
Каждый вариант решения (для 30 городов) - это числовая строка, где на j-ом месте стоит номер j-ого по порядку обхода города. Таким образом, в этой задаче 30 параметров, причем не все комбинации значений допустимы. Естественно, первой идеей является полный п  еребор всех вариантов обхода.
еребор всех вариантов обхода.
Переборный метод наиболее прост по своей сути и тривиален в программировании. Для поиска оптимального решения (точки максимума целевой функции) требуется последовательно вычислить значения целевой функции во всех возможных точках, запоминая максимальное решение. Недостатком этого метода является большая вычислительная стоимость. В частности, в задаче коммивояжера потребуется просчитать длины более 1  030 вариантов путей, что совершенно нереально. Однако, если перебор всех вариантов за разумное время возможен, то можно быть абсолютно уверенным в том, что найденное решение действительно оптимально.
030 вариантов путей, что совершенно нереально. Однако, если перебор всех вариантов за разумное время возможен, то можно быть абсолютно уверенным в том, что найденное решение действительно оптимально.
Второй популярный способ основан на методе градиентного спуска. При этом вначале выбираются некоторые случайные значения параметров, а затем эти значения постепенно изменяют, добиваясь наибольшей скорости роста целевой функции. Дост  игнув локального максимума, такой алгоритм останавливается, поэтому для поиска глобального оптимума потребуются дополнительные усилия.
игнув локального максимума, такой алгоритм останавливается, поэтому для поиска глобального оптимума потребуются дополнительные усилия.
Градиентные методы работают очень быстро, но не гарантируют оптимальности найденного решения. Они идеальны для применения в так называемых унимодальных задачах, где целевая функция имеет единственный локальный максимум (он же - глобальный). Легко видеть, что задача коммивояжера унимодальной не является.
Типичная практическая задача, как правило, мультимодальна и многомерна, то есть содержит много параметров. Для таких задач не существует ни одного универсального метода, который позволял бы достаточно быстро найти абсолютно точное решение.
Однако, комбинируя переборный и градиентный методы, можно надеяться получить хотя бы приближенное решение, точность которого будет возрастать при увеличении времени расчета.
Генетический алгоритм представляет собой именно такой комбинированный метод. Механизмы с  крещивания и мутации в каком-то смысле реализуют переборную часть метода, а отбор лучших решений - градиентный спуск. На рисунке показано, что такая комбинация позволяет обеспечить устойчиво хорошую эффективность генетического поиска для любых типов задач.
крещивания и мутации в каком-то смысле реализуют переборную часть метода, а отбор лучших решений - градиентный спуск. На рисунке показано, что такая комбинация позволяет обеспечить устойчиво хорошую эффективность генетического поиска для любых типов задач.
Итак, если на некотором множестве задана с  ложная функция от нескольких переменных, то генетический алгоритм - это программа, которая за разумное время находит точку, где значение функции достаточно близко к максимально возможному. Выбирая приемлемое время расчета, мы получим одно из лучших решений, которые вообще возможно получить за это время.
ложная функция от нескольких переменных, то генетический алгоритм - это программа, которая за разумное время находит точку, где значение функции достаточно близко к максимально возможному. Выбирая приемлемое время расчета, мы получим одно из лучших решений, которые вообще возможно получить за это время.
Дата: 2019-05-29, просмотров: 339.