Определение. Случайные величины Х1, Х2, …, Х n называются независимыми, если для любых x 1, x 2 , …, xn независимы события
{ω: Х1(ω) < x },{ω: Х2(ω) < x },…, {ω: Х n (ω) < xn }.
Из определения непосредственно следует, что для независимых случайных величин Х1, Х2, …, Х n функция распределения n-мерной случайной величины Х = Х1, Х2, …, Х n равна произведению функций распределения случайных величин Х1, Х2, …, Х n
F(x1, x2, …, xn) = F(x1)F(x2)…F(xn). (1)
Продифференцируем равенство (1) n раз по x 1, x 2, …, xn, получим
p(x1, x2, …, xn) = p(x1)p(x2)…p(xn). (2)
Можно дать другое определение независимости случайных величин.
Если закон распределения одной случайной величины не зависит от того, какие возможные значения приняли другие случайные величины, то такие случайные величины называются независимыми в совокупности.
Например, приобретены два лотерейных билета различных выпусков. Пусть Х – размер выигрыша на первый билет, Y – размер выигрыша на второй билет. Случайные величины Х и Y – независимые, так как выигрыш одного билета никак не повлияет на закон распределения другого. Но если билеты одного выпуска, то Х и Y – зависимые.
Две случайные величины называются независимыми, если закон распределения одной из них не меняется от того, какие возможные значения приняла другая величина.
Теорема 1 (свёртки) или «теорема о плотности суммы 2 случайных величин».
Пусть X = (Х1;Х2) – независимая непрерывная двумерная случайная величина, Y = Х1 + Х2. Тогда плотность распределения
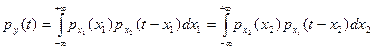 . (3)
. (3)
Доказательство. Можно показать, что если 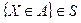 , то
, то
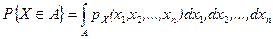 ,
,
где Х = (Х1, Х2, …, Х n). Тогда, если Х = (Х1, Х2), то функцию распределения Y = X1 + X2 можно определить так (рис. 1) –
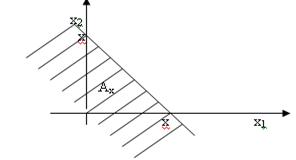
Рис. 1
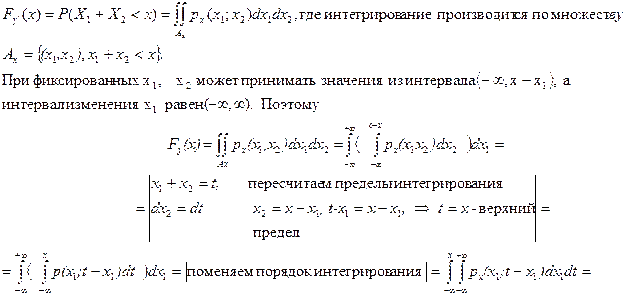
= 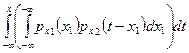 .
.
В соответствии с определением, функция 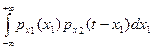 является плотностью распределения случайной величины Y = X1 + X2, т.е.
является плотностью распределения случайной величины Y = X1 + X2, т.е.
py (t) = 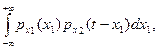 что и требовалось доказать.
что и требовалось доказать.
Выведем формулу для нахождения распределения вероятностей суммы двух независимых дискретных случайных величин.
Теорема 2. Пусть Х1, Х2 – независимые дискретные случайные величины,
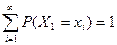 ,
, 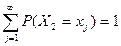 , тогда
, тогда
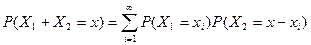 . (4)
. (4)
Доказательство. Представим событие Ax = {Х1+Х2 = x} в виде суммы несовместимых событий
Ax = å(Х1 = xi; Х2 = x – xi).
Так как Х1, Х2 – независимые то P(Х1 = xi; Х2 = x – xi) = P(Х1 = xi) P(Х2 = x – xi), тогда
P(Ax) = P(å(Х1 = xi; Х2 = x – xi)) = å(P(Х1 = xi) P(Х2 = x – xi)),
что и требовалось доказать.
Пример 1. Пусть Х1, Х2 – независимые случайные величины, имеющие нормальное распределение с параметрами N(0;1); Х1, Х2 ~ N(0;1).
Найдём плотность распределения их суммы (обозначим Х1 = x, Y = X1+X2)
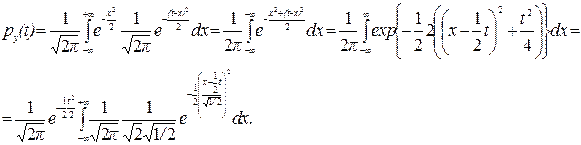
Легко видеть, что подинтегральная функция является плотностью распределения нормальной случайной величины с параметрами а = 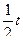 ,
, 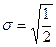 , т.е. интеграл равен 1.
, т.е. интеграл равен 1.
Тогда
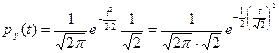 .
.
Функция py (t) является плотностью нормального распределения с параметрами а = 0, s = 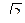 . Таким образом сумма независимых нормальных случайных величин с параметрами (0,1) имеет нормальное распределение с параметрами (0, ), т.е. Y = Х1 + Х2 ~ N(0; ).
. Таким образом сумма независимых нормальных случайных величин с параметрами (0,1) имеет нормальное распределение с параметрами (0, ), т.е. Y = Х1 + Х2 ~ N(0; ).
Пример 2. Пусть заданы две дискретные независимые случайные величины, имеющие распределение Пуассона 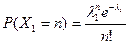
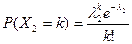 , тогда
, тогда
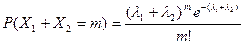 , (5)
, (5)
где k , m , n = 0, 1, 2, …, ¥ .
По теореме 2 имеем:
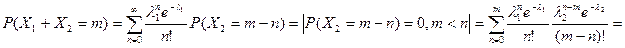
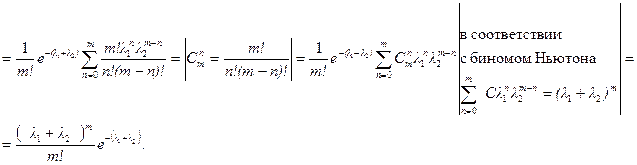
Пример 3. Пусть Х1, Х2 – независимые случайные величины, имеющие экспоненциальное распределение 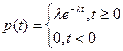 . Найдём плотность Y= Х1+Х2.
. Найдём плотность Y= Х1+Х2.
Обозначим x = x1. Так как Х1, Х2 – независимые случайные величины, то воспользуемся «теоремой свертки»
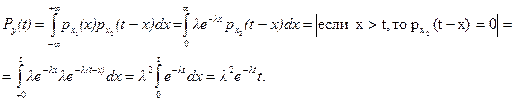
Можно показать, что если задана сумма 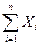 (Х i имеют экспоненциальное распределение с параметром l), то Y= имеет распределение
(Х i имеют экспоненциальное распределение с параметром l), то Y= имеет распределение 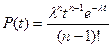 , которое называется распределением Эрланга (n – 1) порядка. Этот закон был получен при моделировании работы телефонных станций в первых работах по теории массового обслуживания.
, которое называется распределением Эрланга (n – 1) порядка. Этот закон был получен при моделировании работы телефонных станций в первых работах по теории массового обслуживания.
В математической статистике часто используют законы распределения случайных величин, являющихся функциями независимых нормальных случайных величин. Рассмотрим три закона наиболее часто встречающихся при моделировании случайных явлений.
Теорема 3. Если независимы случайные величины Х1, ..., Х n, то независимы также функции от этих случайных величин Y1 = f1(Х1), ...,Yn = fn(Х n).
Распределение Пирсона (c2-распределение). Пусть Х1, ..., Х n – независимые нормальные случайные величины с параметрами а = 0, s = 1. Составим случайную величину
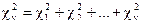 .
.
Закон распределения случайной величины 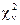 называется
называется 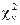 -распределением (распределением Пирсона) с n степенями свободы.
-распределением (распределением Пирсона) с n степенями свободы.
Ранее нами была найдена плотность распределения квадрата нормальной случайной
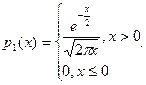
Написанное выражение соответствует плотности распределения c2 с числом степеней свободы n = 1. Получим плотность распределения при n = 2. Пусть 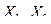 – независимые нормально распределенные случайные величины: Х i ~ N(0,1), i = 1,2. Так как Х1, Х2 независимы, то по теореме, сформулированной ранее независимы также
– независимые нормально распределенные случайные величины: Х i ~ N(0,1), i = 1,2. Так как Х1, Х2 независимы, то по теореме, сформулированной ранее независимы также 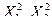 .
.
Воспользуемся теоремой свёртки: n = 2, 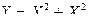 , тогда для t > 0
, тогда для t > 0 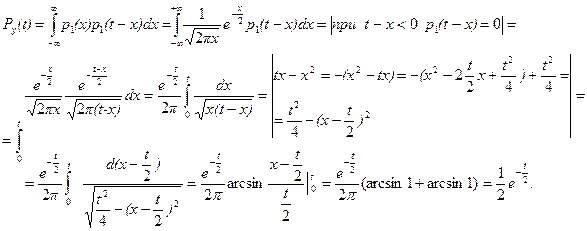
Таким образом, 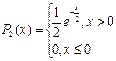
Можно показать, что плотность 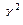 для х > 0 имеет вид
для х > 0 имеет вид 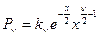 , где kn – некоторый коэффициент для выполнения условия
, где kn – некоторый коэффициент для выполнения условия 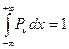 . При n ® ¥ распределение Пирсона стремится к нормальному распределению.
. При n ® ¥ распределение Пирсона стремится к нормальному распределению.
Пусть Х1, Х2, …, Хn ~ N(a,s), тогда случайные величины 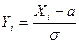 ~ N(0,1). Следовательно, случайная величина
~ N(0,1). Следовательно, случайная величина 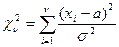 имеет c2 распределение с n степенями свободы.
имеет c2 распределение с n степенями свободы.
Распределение Пирсона табулировано и используется в различных приложениях математической статистики (например, при проверке гипотезы о соответствии закона распределения).
Дата: 2019-05-28, просмотров: 387.