Мы применили нашу реализацию алгоритма к тестовой функции, решающей алгебраическое уравнение четвертой степени x4+ax3+bx2+cx+d=0.
Функция не содержит циклов и не может быть распараллелена традиционными способами. Полученная многопоточная версия функции была реализована с помощью библиотеки pthread под операционной системой Linux. Экспериментальные запуски были проведены на четырехпроцессорном Intel Itanium, на которых установлена ОС RedHat Linux 7; использовались компиляторы GCC 3.3.1 и ICC 8.00b. Программа запускалась 100 раз, время ее выполнения измерялось с помощью высокоточных аппаратных счетчиков. Вычислялось среднее значение времени выполнения μ и среднеквадратичное отклонение σ. Все значения времени выполнения, не укладывающиеся в промежуток [μ-2σ,μ+2σ] удалялись из выборки, после чего среднее значение пересчитывалось. Эта величина использовалась для подсчета ускорения. Результаты эксперимента приведены на Рис. 4.
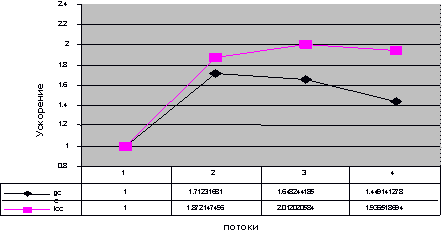
Рис. 4. Ускорение, достигнутое на Itanium
3. Маскирующие преобразования программ
Другим направлением, развиваемым в рамках IRE является исследование маскировки (obfuscation) программ. Мы рассматриваем проблему защиты программ от обратной инженерии, проводимой с целью модификации и/или включения фрагментов защищаемой программы во вновь разрабатываемый программный код. Защита в данном случае состоит в том, чтобы затруднить понимание деталей реализации компонент большой программной системы, сделав его настолько дорогим, чтобы дешевле было разработать оригинальное программное обеспечение.
Одним из способов такой защиты является маскировка программ, заклю-чающаяся в применении к исходному тексту программы цепочки маски-рующих преобразований, то есть преобразований, сохраняющих реализуемую программой функцию (являющихся функционально эквивалентными), но затрудняющих понимание этой функции.
Целью нашего исследования является новый метод маскировки программ, удовлетворяющего следующим требованиям:
Исходная и замаскированная программа записаны на языке Си.
В методе применяются цепочки маскирующих преобразований, элементы которых берутся из некоторого заранее зафиксированного множества параметризованных маскирующих преобра-зований.
Все цепочки таких преобразований порождаются автоматически поддерживающими метод инструментальными средствами и являются допустимыми по своим характеристикам, то есть уве-личивают размер маскируемой программы и/или уменьшают скорость её работы не более чем в фиксированное количество раз.
Метод маскировки устойчив относительно современных методов ста-тического и полустатического анализа программ, развитых для языка Си.
Предложена новая методология анализа маскирующих преобразований, которая позволяет давать качественную и количественную характеристику преобразований. Количественная характеристика преобразований позволяет дать их классификацию и выявить среди них наиболее подходящие для использования при маскировке программ. Основываясь на проведённом исследовании нами предложен новый метод маскировки программ, который удовлетворяет всем целям, сформулированным выше.
3.1. Методология анализа маскирующих преобразований программ
Для оценки действия маскирующих преобразований на программу мы используем несколько показателей сложности кода программ. Традиционно, подобного рода показатели называются "метрики", в дальнейшем мы будем придерживаться этого термина и в нашей работе. Метрики сложности кода программы ставят в соответствие любой программе некоторое число, которое тем больше, чем "сложнее" программа. Простейшая метрика LC размера процедуры равна количеству инструкций промежуточного представления MIF в записи процедуры. Метрика YC сложности циклической структуры равна мощности транзитивного замыкания отношения достижимости в графе потока управления процедуры. Метрика DC сложности потока данных определяется как количество дуг в графе зависимостей по данным, строящемся по результатам анализа достигающих определений программы. Метрика UC количества недостижимого кода определяется как количество инструкций в программе, которые не выполняются ни при каких наборах входных данных. Известно, что точное вычисление метрик DC и UC является алгоритмически неразрешимой задачей.
Через O(p,e) мы обозначим применение метода маскировки O к программе p. e - это параметр, который позволяет выбрать единственную программу p' = O(p,e) из множества функционально эквивалентных замаскированных программ O(p). В частности, параметр e может быть случайным числом. Множество изменения параметра e обозначим через E. Тогда LC(p) - значение метрики LC до маскировки, а LC(O(p,e)) - после маскировки.
Композитная метрика цены TC преобразования O(p,e) вычисляется по метрикам LC и UC следующим образом:
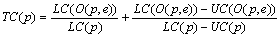
Для конечного множества D программ цена маскирующего преобразования определяется как 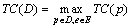 .
.
Метод маскировки называется допустимым для множества D, если 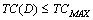 , где константа TCMAX устанавливается директивно, исходя из эксплуатационных требований к замаскированной программе.
, где константа TCMAX устанавливается директивно, исходя из эксплуатационных требований к замаскированной программе.
Композитная метрика MC усложнения программы вычисляется по метрикам YC и DC следующим образом:
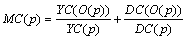
Для конечного множества D программ усложнение определяется как 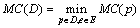 . Чем больше метрика усложнения программы, тем сложнее для понимания становится замаскированная программа в силу увеличения числа информационных и управляющих связей.
. Чем больше метрика усложнения программы, тем сложнее для понимания становится замаскированная программа в силу увеличения числа информационных и управляющих связей.
Для оценки сложности самого маскирующего преобразования вводится оценка OC сложности маскирующего преобразования, которая определяется как требуемая для выполнения данного маскирующего преобразования глубина анализа программы согласно таблице 1.
| Требуемая глубина анализа | Значение OC |
| Лексический анализ | 0 |
| Синтаксический анализ | 1 |
| Семантический анализ | 2 |
| Анализ потока управления | 3 |
| Консервативный анализ потока данных | 4 |
| Полустатический анализ | 5 |
| Точный анализ потока данных | 6 |
Таблица 1. Шкала оценки сложности маскирующих преобразований
Для оценки степени различия текстов программ вводится расстояние ρ(p1,p2) между текстами программ p1 и p2, которое используется для оценки устойчивости маскирующего преобразования. Введём расстояние ρC между графами потока управления двух процедур, равное минимальному количеству операций удаления и добавления рёбер и дуг, переводящих один граф в граф, изоморфный другому. Аналогично введём расстояние ρD между графами зависимостей по данным двух процедур. Обозначим через ρCD(f1,f2) сумму ρC(f1,f2)+ρD(f1,f2). Тогда расстояние ρ(p1,p2) вычисляется по формуле
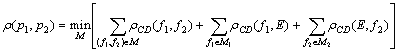
Здесь минимум берётся по всевозможным множествам M, состоящим из пар (f1,f2), где f1 - процедура из программы p1, f2 - процедура из программы p2. Все процедуры f1 и f2 встречаются в M не более одного раза. Через M1 обозначено множество процедур программы p1, отсутствующих в M, а через M2 - множество процедур программы p2, отсутствующих в M. E - это пустой граф.
Такие подготовительные определения позволяют нам определить понятие устойчивости метода маскировки программ по отношению к заданному набору алгоритмов их анализа и основанным на них методам демаскировки программ следующим образом.
Пусть  - это множество маскирующих преобразований и необходимых для их выполнения алгоритмов анализа программ. Тогда метод маскировки - это цепочка
- это множество маскирующих преобразований и необходимых для их выполнения алгоритмов анализа программ. Тогда метод маскировки - это цепочка 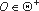 . Все алгоритмы
. Все алгоритмы  анализа, необходимые для выполнения маскирующего преобразования oi, находятся в цепочке O перед oi. Пусть
анализа, необходимые для выполнения маскирующего преобразования oi, находятся в цепочке O перед oi. Пусть 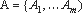 - заданный набор демаскирующих преобразований и необходимых для их выполнения алгоритмов анализа программ. Метод демас-кировки - это цепочка
- заданный набор демаскирующих преобразований и необходимых для их выполнения алгоритмов анализа программ. Метод демас-кировки - это цепочка  . Все алгоритмы
. Все алгоритмы 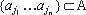 анализа, необходимые для выполнения маскирующего преобразования aj, находятся в цепочке A перед aj. Длину |A| строки A назовём сложностью метода демаскировки. Метод маскировки O называется устойчивым для множества программ D по отношению к множеству демаскирующих преобразований с порогом устойчивости Δ, если выполняются следующие условия:
анализа, необходимые для выполнения маскирующего преобразования aj, находятся в цепочке A перед aj. Длину |A| строки A назовём сложностью метода демаскировки. Метод маскировки O называется устойчивым для множества программ D по отношению к множеству демаскирующих преобразований с порогом устойчивости Δ, если выполняются следующие условия:
Метод маскировки O является допустимым, то есть  .
.
Для любой программы p`, полученной из p, любой метод демаскировки A сложности не более C получает программу p" отстоящую от p более чем на Δ, то есть:
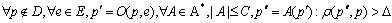
Константа Δ называется порогом устойчивости.
Параметры C и Δ подбираются эмпирически. Параметр C - это оценка вычислительных ресурсов используемых для атаки на замаскированную программу. Чем больше C, тем более сложные методы демаскировки могут применяться для атаки. Параметр Δ зависит от ценности защищаемой программы и уровня экспертизы, ожидаемого при атаке на замаскированную программу. Чем больше ценность маскируемой программы и чем выше ожидаемый уровень подготовки лиц, выполняющих атаку на замаскированную программу, тем больше должен быть порог устойчивости Δ.
Наш анализ методов маскировки программ исходит из предположения, что множество всех возможных алгоритмов анализа и преобразования программ, которые могут использоваться для демаскировки программ, фиксировано. Для нашего анализа мы выбрали представительное множество методов, составленное следующим образом. Большинство рассматриваемых демаскирующих преобразований являются оптимизирующими преобразованиями, используемыми в оптимизирующих компиляторах. К таким преобразованиям относятся, например, устранение общих подвыражений и устранение мёртвого кода. Кроме них описываются алгоритмы полустатического анализа такие, как построение и анализ покрытия дуг и базовых блоков, и основанные на них разработанные в рамках данной работы демаскирующие преобразования.
В рамках нашего исследования нам удалось получить качественную и количественную характеристику опубликованных другими исследователями и разработчиками систем маскировки маскирующих преобразований. Был проведён сравнительный анализ их цены TC, усложнения маскируемой программы MC и оценки сложности OC. На примере программы, вычисляющей функцию Фибоначчи, проводится ранжирование маскирующих преобразований по соотношению усложнение/цена.
3.2. Анализ маскирующих преобразований
Все маскирующие преобразования делятся на текстуальные преобразования, преобразования управляющей структуры и преобразования структур данных. Преобразования управляющей структуры в свою очередь делятся на две группы: маскирующие преобразования реструктуризации всей программы и маскирующие преобразования над одной процедурой. Преобразования структур данных в рамках данной работы не рассматривались.
В группе текстуальных маскирующих преобразований рассматриваются преобразования удаления комментариев, переформатирования текста программы и изменения идентификаторов в тексте программы. В группе маскирующих преобразований управляющей структуры, воздействующих на программу в целом, рассматриваются преобразования открытой вставки процедур, выделения процедур, переплетения процедур, клонирования процедур, устранения библиотечных вызовов. В группе маскирующих преобразований маскировки над одной процедурой рассмотрены преобразования внесения непрозрачных предикатов и переменных, внесения недостижимого кода, внесения мёртвого кода, внесения дублирующего кода, внесения тождеств, преобразования сводимого графа потока управления к несводимому, клонирования базовых блоков, развёртки циклов, разложения циклов, переплетения циклов, диспетчеризации потока управления, локализации переменных, расширения области действия переменных, повторного использования переменных, повышения косвенности.
| Int fib(int n) { int a, b, c; a = 1; b = 1; if (n <= 1) return 1; for (; n > 1; n--) { c = a + b; a = b; b = c; } return c; } | int fib(int n) { int a, b, c, i; long long t; a = 1; b = 1; if (n <= 1) return 1; while (1) { t = n * n % 65537; for (i = 0; i < 15; i++) t = t * t % 65537; if (n * t <= 1) break; c = a + b; a = b; b = c; n--; } return c; } |
| (a) исходная программа | (b) замаскированная программа |
Рис. 5. Пример применения маскирующего преобразования внесения тождеств
На Рис. 5 показан пример применения маскирующего преобразования внесения тождеств к программе, вычисляющей функцию Фибоначчи. Преобразование основано на малой теореме Ферма  для любого целого a, такого, что
для любого целого a, такого, что 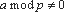 , и простого числа p). В таблице 2 приведена цена применения маскирующего преобразования и полученное усложнение программы. Для этого примера цена равна 3.83, а усложнение программы - 4.85. Расстояние между исходной и замаскированной программой равно 21.
, и простого числа p). В таблице 2 приведена цена применения маскирующего преобразования и полученное усложнение программы. Для этого примера цена равна 3.83, а усложнение программы - 4.85. Расстояние между исходной и замаскированной программой равно 21.
| LC | UC | YC | DC | |
| Исх. процедура fib | 12 | 0 | 0.1111 | 14 |
| Замаскированная fib | 23 | 0 | 0.3086 | 29 |
Таблица 2. Оценка влияния маскирующего преобразования внесения тождеств
Другое маскирующее преобразование - введение непрозрачных предикатов - является ключевым для повышения устойчивости других маскирующих преобразований, например, внесения недостижимого кода. Непрозрачным предикатом называется предикат, всегда принимающий единственное значение true или false. При маскировке программы предикат строится таким образом, что его значение известно, но установить по тексту замаскированной программы, является ли некоторый предикат непрозрачным, трудно. В работе рассматриваются методы построения непрозрачных предикатов, использующие динамические структуры данных и булевские формулы.
На основании определения устойчивости маскирующих преобразований, дан-ного выше, становится возможным провести анализ всех опубликованных маскирующих преобразований для выявления их устойчивости по отношению к нашему множеству демаскирующих преобразований и алгоритмов анализа. Мы можем ввести количественную классификацию маскирующих преобразований и выявить наиболее устойчивые маскирующие преобразования. Для этого вводятся - эвристическая оценка CL сложности анализа, которая устанавливает глубину анализа замаскированной программы, необходимого для выполнения демаскирующего преобразования, и эвристическая оценка SL степени поддержки демаскировки, устанавливающая необходимую степень участия человека в процессе демаскировки. Для оценки CL используется шкала, приведённая в таблице 1. Для оценки SL используется шкала: "автоматический анализ" (0 баллов), "полуавтоматический анализ" (1 балл), "ручной анализ с развитой инструментальной поддержкой" (2 балла), "только ручной анализ" (3 балла). Итоговая оценка DL трудоёмкости анализа равна
DC=CL+SL
В нашей работе показано, что для каждого маскирующего преобразования можно предложить автоматический или полуавтоматический метод демаски-ровки, позволяющий приблизить демаскированную программу p` к исходной программе p. При использовании полустатических алгоритмов анализа программ мы исходим из предположения, что для замаскированной программы существует достаточное количество тестовых наборов, обеспечивающее требуемый уровень доверия.
Таким образом можно получить количественную классификацию маскирующих преобразований. Для каждого маскирующего преобразования приводится оценка сложности маскировки и оценка трудоёмкости демаскировки. Значение, получаемое как разность оценки трудоёмкости демаскировки и оценки сложности маскировки, позволяет оценить насколько демаскировка данного маскирующего преобразования сложнее, чем маскировка. Исходя из этого определяются маскирующие преобразования, применение которых неоправдано, например, переформатирование программы, разложение циклов, локализация переменных; методы маскировки, которые следует применять только в комплексе с другими методами, например, изменение идентификаторов, внесение дублирующего кода и методы маскировки, применение которых наиболее оправдано, например, внесение тождеств, переплетение процедур, построение диспетчера, повышение косвенности. Сравнение двух маскирующих преобразований приведено в таблице 3. Через D обозначена разность OC-DL, через ρ1 обозначено расстояние между текстами замаскированной и исходной программ fib, а через ρ2 - расстояние между текстами демаскированной и исходной программ. Из таблицы следует, что маскирующее преобразование построения диспетчера предпочтительнее, так как, при равных с методом внесения тождеств трудо-затратах на демаскировку, обеспечивает лучшее соотношение усложнения программы к цене преобразования.
| Преобразование | OC | TC | MC | ρ1 | CL | SL | DL | ρ2 | D | 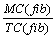 <> <>
|
| Внесение тождеств | 2 | 3.83 | 4.85 | 21 | 4 - 5 | 2 | 7 | 0 | 5 | 1.27 |
| Построение диспетчера | 2 | 3.83 | 6.14 | 39 | 5 | 2 | 7 | 2 | 5 | 1.60 |
Таблица 3. Сравнение методов маскировки
Дата: 2019-05-28, просмотров: 307.