О некоторых задачах анализа и трансформации программ
С.С. Гайсарян, А.В. Чернов, А.А. Белеванцев, О.Р. Маликов, Д.М. Мельник, А.В. Меньшикова
Аннотация.
В настоящей статье обсуждаются некоторые перспективные направления исследований, проводимые в отделе компиляторных технологий Института системного программирования РАН. Методы анализа и трансформации программ, ранее применявшиеся в основном в оптимизирующих компиляторах, в настоящее время находят применение при решении множества смежных задач, таких как обеспечение безопасности программ, генерация тестов для программ и т. д.
Введение
В настоящей статье обсуждаются некоторые перспективные направления исследований, проводимые в отделе компиляторных технологий Института системного программирования РАН. Методы анализа и трансформации программ, ранее применявшиеся в основном в оптимизирующих компиляторах, в настоящее время находят применение при решении множества смежных задач, таких как обеспечение безопасности программ, генерация тестов для программ и т. д.
В отделе ведётся работа и в традиционной области оптимизации программ. Упор делается на разработку новых методов анализа указателей в программах на языке Си. Также проводятся исследования так называемых "полустатических" (profile-based) методов оптимизации программ. Такие методы заключаются в использовании на стадии оптимизации кода информации, накопленной с предварительных её запусков.
Данная работа посвящена рассмотрению трёх направлений. Во-первых, это так называемая маскировка программ, преследующая цель, полностью сохранив пользовательское поведение программы, изменить её текст так, что обратная инженерия или повторное использование ее фрагментов или программы целиком становится сложным. Во-вторых, это задачи автоматической оптимизации программы для работы на многопроцессорных системах с общей памятью путём разбиения её на нити. В-третьих, это задача автоматического выявления уязвимостей в программе.
Для поддержки работ по исследованию методов анализа и трансформации программ в отделе разработана интегрированная инструментальная среда (Integrated Research Environment, IRE), которая содержит большое количество различных алгоритмов анализа и трансформации программ и предоставляет удобный интерфейс пользователя.
Данная работа имеет следующую структуру: в разделе 2 мы рассматриваем задачу автоматического разбиения программы на нити, в разделе 3 рассматриваются задачи маскировки программ, а в разделе 4 задача автоматического выявления уязвимостей. Далее в разделе 5 кратко описывается интегрированная среда IRE, её состав и внутреннее представление MIF, используемое всеми компонентами IRE. Наконец, в разделе 6 мы формулируем выводы данной работы и даём направления дальнейших исследований.
Алгоритм разбиения программы на нити
В настоящем разделе рассматривается построение промежуточного представления программы, над которым работает алгоритм, а также подробно описывается сам алгоритм разбиения программ на нити. Подробное описание алгоритма можно найти в [3]. Алгоритм состоит из трех частей:
Построение ценовой модели, отражающей свойства локальности
Разбиение программы на нити
Дополнительные оптимизации
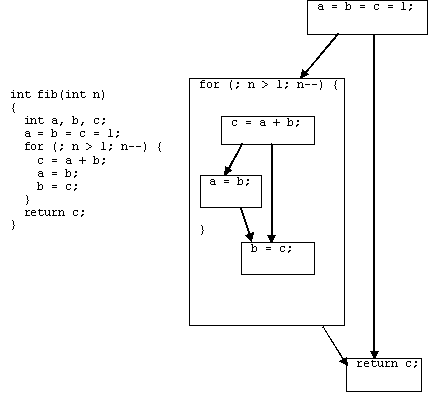
Рис. 1. Пример функции и ее DDG.
Граф зависимостей по данным
При разделении программы на нити прежде всего нужно учитывать зависимости по данным. Поэтому естественно потребовать, чтобы промежуточное представление программы содержало легкодоступную информацию о зависимостях по данным между различными частями программы. В то же время необходимо максимально отразить сведения о "естественном" параллелизме программы, причем на разных уровнях - от отдельных инструкций, до более крупных программных блоков.
Представлением, обладающим всеми необходимыми нам свойствами, является иерархический граф зависимостей по данным, используемый в [9] (data dependence graph, DDG). Узлом такого графа может являться:
Простой оператор (сложение, умножение, сравнение, присваивание и т.д.)
Более сложный оператор (условный оператор, оператор цикла и т.д.)
Граф зависимостей по данным следующего уровня, инкапсули-рующий свойства соответствующего программного блока
Дуги графа DDG представляют собой зависимости по данным между узлами. Более формально, пусть u и v - узлы DDG, причем в последовательной программе u предшествует v. Дуга (u, v) входит в граф тогда и только тогда, когда между u и v есть зависимость по данным одного из трех типов:
"запись-чтение" (в узле v необходимы результаты вычислений узла u),
"чтение-запись" (в узле v записывается переменная, значение которой считывается в u),
"запись-запись" (оба узла записывают одну и ту же пере-менную).
Наличие одной из указанных зависимостей по данным между узлами говорит о том, что при параллельном выполнении программы для получения результатов, совпадающих с последовательной версией, необходимо выполнить u раньше, чем v.
Легко заметить, что граф зависимостей по данным является ориентированным ациклическим графом. Это объясняется тем, что циклы в DDG означают наличие циклических зависимостей по данным, возможных, в свою очередь, только в операторах цикла исходной программы. Но циклы, как и другие сложные операторы, раскрываются на более низком уровне иерархии, обеспечивая разрыв таких зависимостей по данным. Это свойство графа будет использоваться нами в дальнейшем.
Пример функции и ее графа зависимостей по данным приведен на Рис. 1. DDG состоит из трех узлов: двух простых узлов и оператора цикла, раскрывающегося в DDG второго уровня.
Граф зависимостей по данным строится для каждой функции программы. Алгоритм построения состоит из следующих этапов:
Построение графа потока управления программы.
Выбор программных блоков, которые будут узлами текущего уровня иерархии DDG.
Нахождение зависимостей по данным между этими узлами с помощью алгоритма достигающих определений.
Если необходимо, продвинуться на следующий уровень иерархии и достроить граф.
Для того, чтобы отразить на графе побочные эффекты работы функции, в графе вводится специальный узел EXIT. Все узлы, генерирующие побочные эффекты (например, осуществляющие запись в глобальную переменную), связаны дугой с узлом EXIT. Все этапы алгоритма разделения на нити, описанные ниже, работают с представлением программы в виде графа зависимостей по данным.
Ценовая модель
Нашей целью является построение разбиения программы на нити, максимально использующего возникающие события локальности. Чтобы иметь возможность судить о степени оптимальности того или иного разбиения, необходимо ввести некоторую ценовую модель. Так как мы оптимизируем время выполнения программы, то естественно ввести веса узлов графа зависимости по данным, равные времени выполнения узла в последовательной программе.
Время выполнения узла может быть найдено с помощью профилирования программы. Для этого необходимо инструментировать исходный код программы, вставляя вызовы функций из библиотеки поддержки, вычисляющих время выполнения инструкций, и выполнить программу на нескольких наборах типичных входных данных. Для получения более точных результатов можно воспользоваться высокоточными аппаратными счетчиками, имеющимися на большинстве современных архитектур (например, инструкцией RDTSC для Pentium III и выше). Эта оценка времени выполнения точно показывает реальное время выполнения программы, но затрудняет эмуляцию кэша на этапе разделения на нити, так как сложно определить, насколько уменьшится время выполнения узла при попадании в кэш (возможно, при профилировании это попадание уже произошло).
Ценовая модель должна также отражать события локальности, происходящие во время выполнения программы. Статических весов для узлов DDG для этой цели недостаточно. Необходима эмуляция кэша в процессе разделения на нити и соответствующая корректировка времени выполнения узла.
2.1.3. Разбиение на нити
На этом шаге производится собственно разбиение графа зависимостей по данным на нити. Количество нитей является параметром алгоритма. Так как целью разбиения является получение выигрыша по времени, возникающего из-за увеличения количества событий локальности в каждой нити, то необходимо привязать каждую нить к одному конкретному процессору или, точнее, к конкретному кэшу. Поэтому количество нитей, на которые производится разбиение, обычно равно количеству процессоров в системе.
Алгоритм разбиения состоит в итерировании списка узлов графа, еще не назначенных конкретной нити, и определения нити для какого-либо из узлов (группы таких алгоритмов обычно называются list scheduling). На каждом шаге такой алгоритм делает локально оптимальный выбор. Это значит, что при выборе очередного узла из списка делается попытка присвоить его каждой из имеющихся нитей, после чего выбирается лучшая.
Для того, чтобы иметь возможность оценивать варианты присвоения узла нити, необходимо ввести некоторую оценочную функцию. В нашем случае такая функция содержит время выполнения нити, а также среднеквадратичное отклонение времен выполнения всех нитей. Это следует из того соображения, что в оптимальном разбиении времена выполнения нитей должны быть достаточно близки друг к другу. Возможно включение и других параметров.
При включении узла в какую-либо нить необходимо провести пересчет вре-мени выполнения этой нити. Алгоритм пересчета состоит из следующих шагов:
Учет времени, необходимого на синхронизацию с другими нитями, если она требуется.
Учет возникающих событий локальности.
Рассмотрим более подробно каждый из этих шагов.
Виды уязвимостей защиты
В настоящее время сложилась некоторая классификация уязвимостей защиты в зависимости от типа программных ошибок, которые могут приводить к появлению уязвимости в программе. В рамках данной работы мы рассмотрим лишь некоторые виды уязвимостей.
Переполнение буфера (buffer overflow). Данная уязвимость возникает как следствие отсутствия контроля или недостаточного контроля за выходом за пределы массива в памяти. Языки Си/Си++, чаще всего используемые для разработки программного обеспечения системного уровня, не реализуют авто-матического контроля выхода за пределы массива во время выполнения программы. Это самый старый из известных типов уязвимостей (знаменитый червь Морриса использовал, среди прочих, уязвимости переполнения буфера в программах sendmail и fingerd), уязвимости такого типа наиболее просто использовать.
По месту расположения буфера в памяти процесса различают переполнения буфера в стеке (stack buffer overflow), куче (heap buffer overflow) и области статических данных (bss buffer overflow). Все три вида переполнения буфера могут с успехом быть использованы для выполнения произвольного кода уязвимым процессом. Так, упомянутая выше программа rsync содержала уязвимость буфера в куче. Рассмотрим для примера более детально уязвимость переполнения буфера в стеке как наиболее простую на примере следующей простой программы:
#include < stdio.h>
int main(int argc, char **argv)
{
char buf[80];
gets(buf);
printf("%s", buf);
return 0;
}
Предположим, что стек процесса растёт в направлении уменьшения адресов памяти. В таком случае непосредственно перед выполнением функции gets стек будет иметь следующую структуру:
| SP+96 | Аргументы командной строки, переменные окружения и т. д. |
| SP+88 | Аргументы функции main (argc, argv) |
| SP+84 | Адрес возврата из main в инициализационный код |
| SP+80 | Адрес предыдущего стекового фрейма |
| SP+80 | Сохранённые регистры (если есть), локальные переменные (если есть) |
| SP | Буфер (char buf[80]) |
Как известно, функция gets не позволяет ограничивать длину вводимой со стандартного потока ввода строки. Вся введённая строка до символа '\n', кроме него самого, будет записана в память по адресам, начинающимся с адреса массива buf. При этом, если длина введённой строки превысит 80 символов, то первые 80 символов строки будут размещены в памяти, отведённой под массив buf, а последующие символы будут записаны в ячейки памяти, непосред-ственно следующие за buf. То есть, таким образом будут испорчены сначала сохранённые регистры и локальные переменные, затем адрес предыдущего стекового фрейма, затем адрес возврата из функции main и т. д. В момент, когда функция main будет завершаться с помощью оператора return, процессор выполнит переход по адресу, хранящемуся в стеке, но этот адрес испорчен в результате выполнения функции gets, поэтому переход произойдёт совсем в другое место, чем стандартный код завершения процесса.
Теперь, чтобы проэксплуатировать такое переполнение буфера, необходимо подать на вход программе специальным образом подготовленную строку, которая будет содержать небольшую программу, выполняющую нужные злоумышленнику действия (это так называемый shellcode, который в простейшем случае просто выполняет вызов стандартного командного интерпретатора /bin/sh). Кроме того, нужно так подобрать размер подаваемых на вход данных, чтобы при их чтении на место, где размещается адрес возврата из main, попал адрес начала shellcode. В результате в момент завершения работы функции main произойдёт переход на начало фрагмента shellcode, в результате чего будет запущен интерпретатор командной строки. Интерпретатор командной строки будет иметь полномочия пользователя, под которым работал уязвимый процесс, кроме того, стандартные средства аутентификации оказываются обойденными.
Для предотвращения выполнения произвольного кода в случае использования переполнения буфера используются такие приёмы, как запрет выполнения кода в стеке, отображение стандартных библиотек в адресное пространство процесса со случайных адресов, динамический контроль барьерных данных и так далее. Но не один из этих приёмов не может гарантировать предотвращения использования уязвимости переполнения буфера в стеке, поэтому ошибки приводящие к переполнению буфера должны быть устранены непосредственно в исходном коде.
Ошибки форматных строк (format string vulnerability). Этот тип уязвимостей защиты возникает из-за недостаточного контроля параметров при использо-вании функций форматного ввода-вывода printf, fprintf, scanf, и т. д. стандартной библиотеки языка Си. Эти функции принимают в качестве одного из параметров символьную строку, задающую формат ввода или вывода последующих аргументов функции. Если пользователь программы может управлять форматной строкой (например, форматная строка вводится в программу пользователем), он может сформировать её таким образом, что по некоторым ячейкам памяти (адресами которых он может управлять) окажутся записанными указанные пользователем значения, что открывает возможности, например, для переписывания адреса возврата функции и исполнения кода, заданного пользователем.
Уязвимость форматных строк возникает, по сути, из-за того, что широко используемые в программах на Си функции, интерпретируют достаточно мощный язык, неограниченное использование возможностей которого приводит к нежелательным последствиям. Как следствие, в безопасной программе не должно быть форматных строк, содержимое которых прямо или косвенно зависит от внешних по отношению к программе данных. Если же такое невозможно, при конструировании форматной строки она должна быть тщательно проверена. В простейшем случае из пользовательского ввода должны "отфильтровываться" опасные символы "%" и "$".
Уязвимости "испорченного ввода" (tainted input vulnerability). Это широкий класс уязвимостей защиты, в качестве подкласса включающий в себя уязвимости форматных строк. Уязвимости испорченного ввода могут возникать в случаях, когда вводимые пользователем данные без достаточного контроля передаются интерпретатору некоторого внешнего языка (обычно это язык Unix shell или SQL). В этом случае пользователь может таким образом задать входные данные, что запущенный интерпретатор выполнит совсем не ту команду, которая предполагалась авторами уязвимой программы. Рассмотрим следующий пример:
#include < stdio.h>
#include < stdlib.h>
int main(void)
{
char buf[80], cmd[100];
fgets(buf, sizeof(buf), 80);
snprintf(cmd, sizeof(cmd), "ls -l %s", buf);
system(cmd);
return 0;
}
В этом примере ожидается, что пользователь программы вводит имя файла, а программа вызывает стандартную программу ls, которая печатает информацию о введённом файле. При этом для вызова программы ls командная строка передаётся интерпретатору командной строки /bin/sh. Это можно использовать если ввести в программу строку, содержащую, например, символ ; (точка с запятой), например "myfile ; rm -rf /". Строка, фактически переданная интерпретатору командной строки будет равна "ls -l myfile ; rm -rf /", то есть фактически будет состоять из двух команд интерпретатора shell, а не из одной, при этом вторая команда - это запрос на удаление всей файловой системы.
Как и в случае уязвимости форматной строки, достаточное условие отсутствия уязвимости типа испорченного ввода в программе состоит в том, что "опасные" аргументы "опасных" функций никак не должны зависеть от внешних по отношению к программе данных.
Кроме перечисленных здесь типов уязвимостей защиты существуют и другие типы, например - уязвимости как следствие синхронизационных ошибок (race conditions), некорректная работа с временными файлами, слабое шифрование и другие классы уязвимостей. В рамках данной работы мы остановимся лишь на трёх перечисленных выше типах.
Результаты экспериментов
Текущий прототип инструментального средства был проверен на нескольких тестовых примерах, как широко распространённых (bftpd), так и являющихся частью приложений, разрабатываемых в фирме Nortel для своего оборудования. Были получены следующие результаты.
| Application | Total number of warnings | Number of "true positives" | Number of "possible errors" | Number of "false positives" | "false positives" % | FlexeLint |
| Bigfoot | 20 | 4 | 3 | 13 | 65% | 0 (0%) |
| Log_api | 4 | 1 | 3 | 0 | 0% | 0 (0%) |
| Bftpd | 57 | 2 | 32 | 23 | 40% | 0 (0%) |
| Config_api | 11 | 9 | 0 | 2 | 18% | 1 (11%) |
Таблица 6. Результаты запуска инструментального средства
В этой таблице, в столбце "Total" приведено общее количество сообщений об обнаруженных ошибках, выведенных нашим инструментальным средством. В столбце "True" дано количество сообщений, указывающих на действительные проблемы в коде. В столбце "Possible" дано количество сообщений, истинность или ложность которых мы не смогли подтвердить из-за недостатка информации о программе. В столбце "False" дано количество ложных срабатываний. Наконец, в столбце "FlexeLint" дано количество истинных сообщений об ошибке, выявленных инструментальным средством FlexeLint.
Как видно из проведённых испытаний, текущий прототип системы для обнаружения уязвимостей защиты демонстрирует очень хорошие результаты. Процент ложных срабатываний оказался намного ниже, чем у других аналогичных инструментальных средств.
Интегрированная среда
Все направления исследований, описанные в настоящей статье реализуются на базе единой интегрированной среды для изучения алгоритмов анализа и опти-мизации программ [1]. IRE является системой с открытыми исходными кодами и распространяется на условиях Общей публичной лицензии GNU (GNU General Public License). Система доступна для загрузки из сети Интернет [4]. Интегрированная среда построена как набор связанных друг с другом инструментов, работающих над общим промежуточным представлением программ MIF. Для управления инструментами ИС предоставляется графический интерфейс пользователя.
В настоящее время в качестве исходного и целевого языка программирования используется язык Си, но внутреннее представление разработано таким образом, чтобы поддерживать широкий класс процедурных и объектно-ориен-тированных языков программирования. Все компоненты ИС реализованы на языке Java, за исключением транслятора из Си в MIF, который реализован на языке Си.
Состав среды
Программа на языке Си транслируется в промежуточное представление с помощью компонента "Анализатор Си в MIF". В настоящее время поддерживается стандарт ISO C90 и некоторые расширения GNU. Чтобы обеспечить независимость интегрированной среды от деталей реализации стандартной библиотеки Си для каждой конкретной платформы и обеспечить возможность корректной генерации программы на Си по её внутреннему представлению, анализатор использует собственный набор стандартных заго-ловочных файлов (stdio.h и т. д.). На уровне стандартной библиотеки полностью поддерживается стандарт ISO C90 и некоторые заголовочные файлы POSIX. Внутреннее представление программы находится в памяти инте-грированной среды, но возможно сохранение внутреннего представления в файле.
Компонент "Генератор MIF ->C" позволяет по программе во внутреннем представлении получить программу на языке Си. При генерации программы корректно генерируются директивы #include для всех использованных в исходной программе системных заголовочных файлов. Для проведения полустатического анализа программ генератор поддерживает несколько типов инструментирования программы. Инструментирование программы заключается во внесении в ее текст специальных операторов, собирающих информацию о ходе выполнения программы. В настоящее время генератор поддерживает инструментализацию программы для сбора полных трасс выполнения программы, профилирование базовых блоков и дуг, профилирование значений. Собранные в результате выполнения инструментированной программы профили выполнения могут впоследствии использоваться для анализа и преобразования программ.
Компоненты "Анализаторы" реализуют различные методы статического и полустатического анализа программ. При этом сама программа не трансформируется, а во внутреннее представление программы добавляется полученная в результате выполнения анализа информация. В интегрированной среде эти компоненты доступны посредством пункта меню Analyze. Например, алгоритм разбиения программы на базовые блоки, доступный через пункт меню Mark basic blocks, строит граф потока управления программы, создаёт соотвествующие структуры данных в памяти системы и добавляет ссылки на построенный граф в структуры данных внутреннего представления программы.
Компоненты "Трансформаторы" реализуют различные преобразования программ. При этом результатом работы компонента трансформации является новая программа во внутреннем представлении, для которой в интегрированной среде создаётся новое окно. Исходная программа сохраняется неизменной. Трансформационные компоненты доступны в интегрированной среде посредством пунктов меню Optimize, Transform и Obfuscate в зависимости от класса преобразования.
Компоненты "Визуализаторы" реализуют различные алгоритмы визуализации информации о программе. Эти компоненты доступны посредством пункта меню Vizualize интегрированной среды.
Промежуточное представление
Промежуточное представление MIF используется всеми инструментами интегрированной среды. Оно является представлением среднего уровня и спроектировано таким образом, чтобы представлять программы, написанные на широком спектре процедурных и объектно-ориентированных языков программирования.
Программа в представлении MIF представляет собой последовательность четвёрок, которые используются для представления как декларативной, так и императивной информации о программе. Текстуальное представление MIF используется как интерфейс между анализатором языка и интегрированной средой, а также для хранения анализируемых программ.
Заключение
В данной работе мы рассмотрели несколько направлений исследований, которые ведутся в отделе компиляторных технологий Института системного программирования РАН. Эти исследования используют интегрированную среду исследования алгоритмов анализа и трансформации программ, разрабатываемую в ИСП РАН и на факультете ВМиК МГУ. Открытость и расширяемость интегрированной среды позволяет достаточно легко накапливать прототипные реализации алгоритмов анализа и трансформации программ, которые разрабатываются в рамках проводимых исследований.
Накопление библиотеки алгоритмов позволяет с успехом применять интегрированную среду в учебном процессе факультетов ВМиК МГУ и ФПМЭ МФТИ. Студенты, выполняя курсовые и дипломные работы, получают в своё распоряжение развитый инструментарий методов анализа и оптимизации, на основе которых они могут реализовывать новые методы анализа и оптимизации. После включения в интегрированную среду результаты работы станут доступны для дальнейшего использования. Другое учебное применение интегрированной среды заключается в использовании её в качестве пособия для изучающих курсы по методам анализа и оптимизации программ.
В дальнейшем мы планируем развивать все три рассмотренных в данной работе направления работ, а также усовершенствовать интегрированную среду для облегчения её использования. Для этого, в частности, планируется реализация объектной библиотеки и объектно-ориентированного интерфейса ко внутреннему представлению.
Список литературы
А. В. Чернов. Интегрированная инструментальная среда Poirot для изучения методов маскировки программ. Препринт Института системного программирования РАН. М.: ИСП РАН, 2003.
A. Chernov. A New Program Obfuscation Method. In Proceedings of the Adrei Ershov Fifth International Conference "Perspectives of Systems Informatics". International Workshop on Program Understanding, Novosibirsk, July 14-16, 2003.
A. Chernov, A. Belevantsev, O. Malikov. A Thread Partitioning Algorithm for Data Locality Improvement. To appear in Proceedings of Fifth International Conference on Parallel Processing and Applied Mathematics (PPAM 2003), Czestochowa, Poland, September 7-10, 2003.
The IRE Home Page. http://www.ispras.ru/groups/ctt/ire.html
J. E. Moreira. On the implementation and effectiveness of autoscheduling for shared-memory multiprocessors. Ph.D. thesis, Department of Electrical and Computer Engineering, Univ. of Illinois at Urbana-Champaign, 1995.
J. G. Steffan, C. B. Colohan, A. Zhai, and T. C. Mowry. Improving Value Communication for Thread-Level Speculation. Computer Science Department Carnegie Mellon University. 2002.
SUIF Compiler System Group (http://suif.stanford.edu)
M. E. Wolf and M. Lam. A data locality optimizing algorithm. In ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), Totonto, CA, June 1991.
X. Tang, J. Wang, K. Theobald, and G. R. Gao. Thread partitioning and scheduling based on cost model. ACAPS Tech. Memo 106, School. of Computer Science, McGill University, Montreal, Quebec. Apr. 1997.
R. P. Wilson, M. S. Lam. Efficient context-sensitive pointer analysis for C programs. In Proceedings of the ACM SIGPLAN'95 Conference on Programming Language Design and Implementation, pages 1-12, June 1995.
S. Muchnick. Advanced Compiler Design and Implementation. Morgan Kaufmann Publishers, 1997.
D. Wagner, J. S. Foster, E. A. Brewer, A. Aiken. A First Step towards Automated Detection of Buffer Overrun Vulnerabilities. In Proceedings of Network and Distributed System Security Symposium, pages 3-17, February 2000.
О некоторых задачах анализа и трансформации программ
С.С. Гайсарян, А.В. Чернов, А.А. Белеванцев, О.Р. Маликов, Д.М. Мельник, А.В. Меньшикова
Аннотация.
В настоящей статье обсуждаются некоторые перспективные направления исследований, проводимые в отделе компиляторных технологий Института системного программирования РАН. Методы анализа и трансформации программ, ранее применявшиеся в основном в оптимизирующих компиляторах, в настоящее время находят применение при решении множества смежных задач, таких как обеспечение безопасности программ, генерация тестов для программ и т. д.
Введение
В настоящей статье обсуждаются некоторые перспективные направления исследований, проводимые в отделе компиляторных технологий Института системного программирования РАН. Методы анализа и трансформации программ, ранее применявшиеся в основном в оптимизирующих компиляторах, в настоящее время находят применение при решении множества смежных задач, таких как обеспечение безопасности программ, генерация тестов для программ и т. д.
В отделе ведётся работа и в традиционной области оптимизации программ. Упор делается на разработку новых методов анализа указателей в программах на языке Си. Также проводятся исследования так называемых "полустатических" (profile-based) методов оптимизации программ. Такие методы заключаются в использовании на стадии оптимизации кода информации, накопленной с предварительных её запусков.
Данная работа посвящена рассмотрению трёх направлений. Во-первых, это так называемая маскировка программ, преследующая цель, полностью сохранив пользовательское поведение программы, изменить её текст так, что обратная инженерия или повторное использование ее фрагментов или программы целиком становится сложным. Во-вторых, это задачи автоматической оптимизации программы для работы на многопроцессорных системах с общей памятью путём разбиения её на нити. В-третьих, это задача автоматического выявления уязвимостей в программе.
Для поддержки работ по исследованию методов анализа и трансформации программ в отделе разработана интегрированная инструментальная среда (Integrated Research Environment, IRE), которая содержит большое количество различных алгоритмов анализа и трансформации программ и предоставляет удобный интерфейс пользователя.
Данная работа имеет следующую структуру: в разделе 2 мы рассматриваем задачу автоматического разбиения программы на нити, в разделе 3 рассматриваются задачи маскировки программ, а в разделе 4 задача автоматического выявления уязвимостей. Далее в разделе 5 кратко описывается интегрированная среда IRE, её состав и внутреннее представление MIF, используемое всеми компонентами IRE. Наконец, в разделе 6 мы формулируем выводы данной работы и даём направления дальнейших исследований.
Дата: 2019-05-28, просмотров: 291.