Настольные издательские ситсемы
связи с широким распространением в последние годы мультимедийных и сетевых компьютерных технологий издательское дело вышло на новый уровень своего развития. Появились настольные издательские системы(НИС) – специализированные программно-аппаратные комплексы, предназначенные для подготовки оригинал-макетов печатной продукции. При этом осуществляется верстка (оформление и размещение) подготовленного к публикации материала.
Основным отличием НИС от текстовых редакторов и процессоров является то, что они предназначены в первую очередь для оформления документа, а не для ввода текста и проверки правописания, хотя в определенной степени могут выполнять и эти функции. НИС не предполагает создания исходных материалов для печати, для этого удобнее использовать текстовые процессоры для набора текста и графические пакеты для создания иллюстраций.
НИС работают только в графическом режиме. Необходимым требованием их работы является соответствие изображения на экране реальному результату (WYSIWYG—WhatYouSeeIsWhatYouGet –что видите, то и получаете).
Верстка различных типов документов обладает спецификой, для учета которой предпочтительно использовать соответствующие НИС. Наиболее распространенными сейчас являются следующие системы:
· Adobe PageMaker— популярная программа с многочисленными функциями, позволяющая удобно работать с журнальными и газетными многостраничными публикациями. Программа содержит большое количество функций по оформлению публикаций, многие полезные функции добавлены в этот пакет с помощью дополнительных утилит (вспомогательных программ);
· Corel Ventura— программа, которая была одной из первых НИС. Она ориентируется на создание книг, брошюр, журналов и других больших многостраничных публикаций. Программа обладает большими возможностями по размещению и оформлению текста. Последняя версия программы распространяется с пакетомCorelDraw, элементы которого позволяют создать высококачественные иллюстрации;
· QuarkXPress— НИС для профессиональной работы. Включает большое количество функций по оформлению публикации любой сложности и содержания. Разнообразные возможности позволяют реализовать любые проекты по дизайну. Она также имеет дополнительные утилиты, расширяющие возможности программы;
· FrameMaker— НИС, наиболее удобная для работы с большими публикациями, которые имеют сложную структуру, например технические публикации. В программе можно работать с различными иллюстрациями, а также легко оформлять таблицы и формулы, но программа имеет ограниченные функциональные возможности по сравнению сCorel Ventura;
· Microsoft Publisher— эта НИС содержит достаточный для оформления публикации набор функций. Она удобна для начинающих пользователей простой инсталляцией и средствами, облегчающими процесс создания публикаций (PageWizard).
Поскольку НИС предназначена для работ, связанных с полиграфией, ее использование предполагает знание пользователем правил оформления публикаций.
Конверторы шрифтов
4. Системы оптического распознавания (OCR-системы)
Оптическое распознавание символов(англ.optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные — последовательность кодов, использующихся для представления символов в компьютере (например, в текстовом редакторе).
История
· 1929 году - Густав Таушек (Gustav Tauschek) получил патент на метод оптического распознавания текста в Германии;
· 1933 год - Гендель (Paul W. Handel) получил патент на свой метод в США ;
· 1935 год – Г. Таушек также получил патент США на свой метод;
· 1950 год - Дэвид Х. Шепард (David H. Shepard) - построил машину, решающую задачу преобразования печатных сообщений в машинный язык для обработки компьютером.
· 1955 год - Первая коммерческая система была установлена на «Ридерс Дайджест»
· 1965 год - «Ридерс Дайджест» и «Ар-Си-Эй» начали сотрудничество с целью создать машину для чтения документов, использующую оптическое распознавание текста, предназначенную для оцифровки серийных номеров купонов «Ридерс Дайджест», вернувшихся из рекламных объявлений.
· 1965 год - Почтовая служба Соединённых Штатов для сортировки почты использует машины, работающие по принципу оптического распознавания текста, созданные на основе технологий, разработанных исследователем Яковом Рабиновым.
· 1971 год - Почта Канады использует системы оптического распознавания символов
· 1974 год - Рэй Курцвейл создал компанию «Курцвейл Компьютер Продактс», и начал работать над развитием первой системы оптического распознавания символов, способной распознать текст, напечатанный любым шрифтом.
· 1978 год - Компания «Курцвейл Компьютер Продактс» начала продажи коммерческой версии компьютерной программы оптического распознавания символов.
· 1992 год – Начало продажи первой коммерчески успешной программой, распознающей кириллицу, «AutoR» российской компании «ОКРУС» (ОС DOS).
· Конец 60-х годов – разработка и испытание шрифтонезависимого алгоритма распознования текста выпускниками МФТИ, биофизиками: Г. М. Зенкиным и А. П. Петровым
При создании электронных библиотек и архивов путем перевода книг и документов в цифровой компьютерный формат, при переходе предприятий от бумажного к электронному документообороту, при необходимости отредактировать полученный по факсу документ используются системы оптического распознавания символов.
С помощью сканера несложно получить изображение страницы текста в графическом файле.
Однако для получения документа в формате текстового файла необходимо провести распознавание текста, т. е. преобразовать элементы графического изображения в последовательности текстовых символов.
-Сначала необходимо распознать структуру размещения текста на странице: выделить колонки, таблицы, изображения и т. д.
-Далее выделенные текстовые фрагменты графического изображения страницы необходимо преобразовать в текст.
5. Системы машинного перевода
«Машинный перевод – выполняемое на компьютере действие по преобразованию текста на одном естественном языке в эквивалентный по содержанию текст на другом языке, а также результат такого действия». Авторы статьи подчеркивают, что при нынешнем уровне машинного перевода без участия человека не обойтись. Чтобы компьютер мог перевести текст, ему нужна помощь предредактора, который тем или иным образом предварительно обрабатывает подлежащий переводу текст, интерредактора, который участвует в процессе перевода, и постредактора, который исправляет ошибки и недочеты в переведенном машиной тексте.
В основе работы программы-переводчика лежит алгоритм перевода – последовательность однозначно и строго определенных действий над текстом для нахождения соответствий в данной паре языков L1 – L2 при заданном направлении перевода (с одного конкретного языка на другой). Обычные словари и грамматики разных языков не применимы для машинного перевода, так как описывают значения слов и грамматические закономерности в нестрогой форме, никак не приемлемой для «машинного» использования. Следовательно, нужна формальная грамматика языка, т.е. логически непротиворечивая и явно выраженная (безо всяких подразумеваний и недомолвок). Как только начали появляться формальные описания различных областей языка – прежде всего морфологии и синтаксиса, – наметился прогресс и в разработке систем автоматического перевода. Чтобы успешно работать, система машинного перевода включает в себя, во-первых, двуязычные словари, снабженные необходимой информацией (морфологической, относящейся к формам слова, синтаксической, описывающей способы сочетания слов в предложении, и семантической, т.е. отвечающей за смысл), а во-вторых – средства грамматического анализа, в основе которых лежит какая-нибудь из формальных, т.е. строгих, грамматик. Наиболее распространенной является следующая последовательность формальных операций, обеспечивающих анализ и синтез в системе машинного перевода.
1. На первом этапе осуществляется ввод текста и поиск входных словоформ (слов в конкретной грамматической форме, например дательного падежа множественного числа) во входном словаре (словаре языка, с которого производится перевод) с сопутствующим морфологическим анализом, в ходе которого устанавливается принадлежность данной словоформы к определенной лексеме (слову как единице словаря). В процессе анализа из формы слова могут быть получены также сведения, относящиеся к другим уровням организации языковой системы, например, каким членом предложения может быть данное слово.
2. Следующий этап включает в себя перевод идиоматических словосочетаний, фразеологических единств или штампов данной предметной области (например, при англо-русском переводе обороты типа in case of, in accordance with получают единый цифровой эквивалент и исключаются из дальнейшего грамматического анализа); определение основных грамматических (морфологических, синтаксических, семантических и лексических) характеристик элементов входного текста (например, числа существительных, времени глагола, их роли в данном предложении и пр.), производимое в рамках входного языка; разрешение неоднозначности (скажем, англ. round может быть существительным, прилагательным, наречием, глаголом или же предлогом); анализ и перевод слов. Обычно на этом этапе однозначные слова отделяются от многозначных (имеющих более одного переводного эквивалента в выходном языке), после чего однозначные слова переводятся по спискам эквивалентов, а для перевода многозначных слов используются так называемые контекстологические словари, словарные статьи которых представляют собой алгоритмы запроса к контексту на наличие/отсутствие контекстных определителей значения.
3. Окончательный грамматический анализ, в ходе которого доопределяется необходимая грамматическая информация с учетом данных выходного языка (например, при русских существительных типа сани, ножницы глагол должен стоять в форме множественного числа, притом, что в оригинале может быть и единственное число).
4. Синтез выходных словоформ и предложения в целом на выходном языке. Здесь не получится обойтись простым переводом «узлов» дерева на другой язык. Синтаксис каждого языка устроен на свой лад: то, что в русском предложении – подлежащее, в другом языке может (или должно) быть выражено дополнением, а дополнение, наоборот, должно преобразоваться в подлежащее; то, что в одном языке обозначается группой слов, переводится на другой всего одним словом и т. д. В связи с этим в машинную память помимо наборов синтаксических правил для каждого языка «вкладывают» и правила преобразования синтаксических структур. К этому добавляют правила перехода от уже преобразованной структуры к предложению того языка, на который делается перевод. Такой переход от структуры к реальному предложению называется синтаксическим синтезом.
В зависимости от особенностей морфологии, синтаксиса и семантики конкретной языковой пары, а также направления перевода общий алгоритм перевода может включать и другие этапы, а также модификации названных этапов или порядка их следования, но вариации такого рода в современных системах, как правило, незначительны. Анализ и синтез могут производиться как пофразно, так и для всего текста, введенного в память компьютера; в последнем случае алгоритм перевода предусматривает определение так называемых анафорических связей (такова, например, связь местоимения с замещаемым им существительным – скажем, местоимения им со словом местоимения в самом этом пояснении в скобках).
Для решения проблемы многозначности слова используется анализ контекста. Дело в том, что каждое из нескольких значений многозначного слова в большинстве случаев реализуются в своем наборе контекстов. То есть у каждого из «конкурирующих» (при интерпретации) значений – свой набор контекстов. И именно вот эта зависимость значения от окружения позволяет слушающему понять высказывание правильно. Для правильного понимания высказывания необходимо в полной мере учитывать также правила обусловленности выбранного значения лексическим окружением (действующие при «фразеологической» интерпретации слова), правила обусловленности выбранного значения семантическим контекстом (так называемые законы семантического согласования) и правила обусловленности выбранного значения грамматическим (морфолого-синтаксическим) контекстом. То есть для решения проблемы «моносемизации» слов при автоматическом переводе основой служит изучение и тщательное описание закономерностей лексической, семантической и грамматической сочетаемости. При этом правила такой сочетаемости достаточно подробно описываются в словарях – а именно, (а) с мощным охватом лексики, но весьма бегло и нетщательно, а также весьма имплицитно это делается в традиционной лексикографии; и, с другой стороны, (б) в выборочном порядке (со слабым охватом лексики), но зато весьма аккуратно и тщательно, и довольно-таки эксплицитно это делается в работах по «толково-комбинаторной» лексикографии (последних сорока лет).
Действующие системы машинного перевода, как правило, ориентированы на конкретные пары языков (например, французский и русский или японский и английский) и используют, как правило, переводные соответствия либо на поверхностном уровне, либо на некотором промежуточном уровне между входным и выходным языком. Качество машинного перевода зависит от объема словаря, объема информации, приписываемой лексическим единицам, от тщательности составления и проверки работы алгоритмов анализа и синтеза, от эффективности программного обеспечения. Современные аппаратные и программные средства допускают использование словарей большого объема, содержащих подробную грамматическую информацию. Информация может быть представлена как в декларативной (описательной), так и в процедурной (учитывающей потребности алгоритма) форме.
В практике переводческой деятельности и в информационной технологии различаются два основных подхода к машинному переводу. С одной стороны, результаты машинного перевода могут быть использованы для поверхностного ознакомления с содержанием документа на незнакомом языке. В этом случае он может использоваться как сигнальная информация и не требует тщательного редактирования. Другой подход предполагает использование машинного перевода вместо обычного «человеческого». Это предполагает тщательное редактирование и настройку системы перевода на определенную предметную область. Здесь играют роль полнота словаря, ориентированность его на содержание и набор языковых средств переводимых текстов, эффективность способов разрешения лексической многозначности, результативность работы алгоритмов извлечения грамматической информации, нахождения переводных соответствий и алгоритмов синтеза. На практике перевод такого типа становится экономически выгодным, если объем переводимых текстов достаточно велик (не менее нескольких десятков тысяч страниц в год), если тексты достаточно однородны, словари системы полны и допускают дальнейшее расширение, а программное обеспечение удобно для постредактирования.
6. Электронные словари
Современный переводчик не может конкурировать на рынке переводческих услуг без овладения информационными технологиями перевода. Перевод с помощью компьютера (Computer Aided Translation – CAT) включает следующие основные компьютерные технологии.
Установленные на компьютере (офлайновые) общелингвистические и специализированные электронные словари.
Системы автоматизированного перевода.
Системы переводческой памяти.
Онлайновые (сетевые) специализированные и толковые словари.
Лингвистический поиск в сети Интернет.
Современные электронные словари позволяют не только быстро найти перевод слова или выражения на различные языки, но и отыскать примеры его употребления, грамматические формы и устойчивые словосочетания, в которых это слово используется. Среди офлайновых словарей, которые нужны для каждодневной работы профессиональному переводчику, следует выделить в первую очередь Lingvo и Multitran. Это наиболее полные профессиональные многоязычные словари, включающие большое количество узкоспециализированных тематик.
Если офлайновые словари не позволяют найти приемлемого перевода терминов и выражений, то следует обратиться к поиску в сети Интернет. В Интернете можно найти перевод терминов и словосочетаний, сокращений и названий, материалы по теме перевода на русском языке и на языке перевода, а также вспомогательные для переводчика материалы (нормативные документы, обсуждения сложных тем и опыта перевода на форумах переводчиков и др.).
Системы автоматизированного (машинного) перевода (Machine Translation, MT) могут быть использованы для быстрого перевода с различных языком больших объемов текста по специальным тематикам с учетом их специфики. После редактирования такой перевод приближается по качеству к ручному переводу. Машинный перевод является одной из технологий перевода с помощью компьютера (CAT). При машинном переводе приложение осуществляет автоматический связный перевод текста на другой естественный язык с использованием словарей и набора правил перевода с учетом морфологии, синтаксиса и семантических связей без участия человека или при его минимальном участии.
Существуют следующие виды систем машинного перевода.
FAMT (Fully-automatedmachine translation) – полностью автоматизированный машинный перевод (автоматический);
HAMT (Human-assistedmachine translation) – машинный перевод при участии человека
(автоматизированный в интерактивном режиме);
MAHT (Machine-assistedhuman translation) – перевод, осуществляемый человеком с использованием компьютера.
Автоматизированный перевод типа HAMT рассматривается в пособии на примере системы
PROMT.
CAT перевод типа MAHT реализуется в виде систем переводческой памяти (Translation Memory), которые используют для перевода переведенные ранее фрагменты текста, что существенно
повышает производительность переводчика без потери качества. При командной работе над проектом, такие системы позволяют использовать коллективный опыт переводчиков и обеспечивают единство терминологии, что значительно повышает единообразие перевода различными переводчиками и скорость перевода. В пособии подробно рассмотрена работа с программой памяти переводов memoQ.
1 СЛОВАРЬ LINGVO
1.1 Основные функции словаря Lingvo
Электронный словарь ABBYY Lingvo x5 (www.lingvo.ru) – это словарь с большой и современной словарной базой, который включает около 220 общелексических, тематических, лингвострановедческих и толковых словарей (профессиональная версия):
 20 языков: английский, русский, немецкий, французский, испанский, итальянский,
20 языков: английский, русский, немецкий, французский, испанский, итальянский,
португальский, греческий, финский, китайский, латинский, турецкий, украинский,
казахский, татарский, польский, венгерский, датский, нидерландский, норвежский, 220
словарей, более 12 миллионов словарных статей.
Толковые словари английского языка: Oxford English Dictionary, Oxford American Dictionary, Collins Cobuild Dictionary. Словарь New Oxford American Dictionary содержит более 1000
иллюстраций.
Толковые словари русского языка: словарь Даля, словарьОжегова-Шведовой,Большая Советская энциклоперия, Большой энциклопедический словарь, Толковый словарь и др.
Около 76 000 слов и фраз в словарях общей лексики и разговорниках на английском,
немецком, французском, итальянском, испанском и китайском озвучены дикторами-
носителями этих языков.
Для тех, кто изучает английский язык, в программу включены всемирно известный учебный словарь Collins Cobuild Advanced Learner’s English Dictionary ивидео-словарьWord Express
компании English Club TV. В освоении английского помогут занимательные ситуативные видео-диалогиFull Contact, иллюстрированный толковый словарь английского языка New Oxford American Dictionary иангло-русскийграмматический словарь.
Приложение Lingvo Tutor для изучения иностранных языков, содержит комплекс упражнений для расширения словарного запаса и повышения грамотности при изучении языков. Эти упражнения включают такие разделы, как “Знакомство”, “Мозаика”,
“Варианты”, “Написание” и “Самопроверка”.
Видеоуроки предназначены для совершенствования речевого общения. В Lingvo x5 входит коллекция развлекательных и познавательных сюжетов с погружением в языковую среду.
Lingvo обеспечивает пользователям доступ к словарям через лингвистический онлайн-порталLingvo.Pro. Портал позволяет обращаться к базе переводов, дополнять ее и взаимодействовать с другими пользователями. Используя этот портал, компания ABBYY развивает модель SaaS(Software-as-a-Service),позволяющую расширить доступность своих продуктов для пользователей.
Перевод слова и словосочетания в Lingvo отображается в виде карточки перевода, в которой показывается начало словарных статей из всех словарей с заголовком, совпадающим с заданным словом или словосочетанием.
Всплывающий перевод при наведении курсора мыши на слово помогает при чтении текста в программе Word, WordPad, Excel. PDF-файлов,в браузере Explorer,интернет-страниц,ICQ, Flash-
роликов и субтитров к фильмам.
В программу Lingvo включены примеры писем на английском, немецком, французском и испанском языках по материалам двуязычных словарей Oxford Concise. Примеры описывают самые распространенные жизненные ситуации и полезны для ведения переписки.
При наличии интернет-подключения,Lingvo обеспечивает доступ конлайн-базепамяти переводов (ТМ – translation memory) для английского, немецкого и французского языков. Программа показывает примеры современного употребления слов и словосочетаний в предложениях из художественной и технической литературы, законодательных и юридических документов, синтернет-сайтов.С помощью этой базы пользователь может подобрать точный перевод слова, определить, действительно ли употребляется в речи данный оборот, найти новые варианты перевода и примеры их использования. База памяти переводов содержит более миллиона предложений. Чтобы получить примеры из памяти переводов в карточке наведите курсор мыши на интересующий перевод и после появления рамки вокруг слова нажмите на него левой кнопкой мыши.
8. ИПС (информационно-поисковая система)
ИПС (информационно-поисковая система) – это система, обеспечивающая поиск и отбор необходимых данных в специальной базе с описаниями источников информации (индексе) на основе информационно-поискового языка и соответствующих правил поиска.
Главной задачей любой ИПС является поиск информации релевантной информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу, и не найти ничего лишнего. Поэтому вводится качественная характеристика процедуры поиска – релевантность.
Релевантность – это соответствие результатов поиска сформулированному запросу.
Далее мы будем, в основном, рассматривать ИПС для всемирной паутины (WWW). Основными показателями ИПС для WWW являются пространственный масштаб и специализация.
По пространственному масштабу ИПС можно разделить на локальные, глобальные, региональные и специализированные. Локальные поисковые системы могут быть разработаны для быстрого поиска страниц в масштабе отдельного сервера.
Региональные ИПС описывают информационные ресурсы определенного региона, например, русскоязычные страницы в Интернете. Глобальные поисковые системы в отличие от локальных стремятся объять необъятное – по возможности наиболее полно описать ресурсы всего информационного пространства сети Интернет.
Кроме того, ИПС также могут специализироваться по поиску различных источников информации, например, документов WWW, файлов, адресов и т.д.
Рассмотрим подробнее основные задачи, которые должны решить разработчики ИПС. Как следует из определения, ИПС для WWW проводят поиск в собственной базе (индексе) с описанием распределенных источников информации.
Следовательно, сначала нужно описать информационные ресурсы и создать индекс. Построение индекса начинается с определения начального набора URL источников информации. Затем проводится процедура индексирования.
Индексирование – описание источников информации и построение специальной базы данных (индекса) для эффективного поиска.
В некоторых информационно-поисковых системах описание источников информации проводится персоналом ИПС, то есть, людьми, которые составляют краткую аннотацию на каждый ресурс. Затем, как правило, проводится сортировка аннотаций по темам (составление тематического каталога). Конечно, описание, составленное человеком, будет совершенно адекватно источнику. Правда, в этом случае процедура описания занимает значительный период времени, поэтому формируемый индекс имеет, как правило, ограниченный объем. Зато поиск в подобной системе можно будет проводить так же легко, как в тематических каталогах библиотек.
В ИПС второго типа процедура описания информационных ресурсов автоматизирована. Для этого разрабатывается специальная программа-робот, которая по определенной технологии обходит ресурсы, описывает их (проводит индексирование) и анализирует ссылки с текущей страницы для расширения области поиска. Как может описать документ программа? Чаще всего просто составляется список слов, которые встречаются в тексте и других частях документа, при этом учитывается частота повторения и местоположение слова, то есть, слову приписывается своеобразный весовой коэффициент в зависимости от его значимости. Например, если слово находится в названии Web-страницы, робот пометит этот факт для себя. Поскольку описание автоматизировано, затраты времени невелики, и индекс может оказаться очень большим по размеру.
Следовательно, следующей задачей для ИПС второго типа является разработка робота-индексировщика. Для поиска в системах данного типа пользователю придется научиться составлять запросы, в простейшем случае состоящие из нескольких слов. Тогда ИПС будет искать в своем индексе документы, в описаниях которых встречаются слова из запроса. Для проведения более качественного поиска необходимо разрабатывать специальный язык запросов для пользователя. В зависимости от особенностей построения модели индекса и поддерживаемого языка запросов разрабатывается механизм поиска и алгоритм сортировки результатов поиска. Поскольку индекс имеет значительный объем, количество найденных документов может оказаться достаточно большим. Следовательно, чрезвычайно важно, как поисковая машина проведет поиск и отсортирует его результаты.
Не последнее значение имеет внешний вид поисковой системы, предстающий перед пользователем, поэтому одной из задач является разработка удобного и красивого интерфейса. Наконец, исключительно важна форма представления результатов поиска, поскольку пользователю необходимо узнать как можно больше о найденном источнике информации, чтобы принять правильное решение о необходимости его посещения.
Для обращения к поисковому серверу пользователь использует стандартную программу-клиент для всемирной паутины, то есть браузер. По адресу домашней страницы ИПС пользователь работает с интерфейсом поисковой системы, который служит для общения пользователя с поисковым аппаратом системы (системой формирования запросов и просмотра результатов поиска).
Системы распознавание речи
В настоящее время речевое распознавание находит все новые и новые области применения, начиная от приложений, осуществляющих преобразование речевой информации в текст и заканчивая бортовыми устройствами управления автомобилем.
Выделяют несколько основных способов распознавания речи:
1. Распознавание отдельных команд – раздельное произнесение и последующее распознавание слова или словосочетания из небольшого заранее заданного словаря. Точность распознавания ограничена объемом заданного словаря
2. Распознавание по грамматике – распознавание фраз, соответствующих определенным правилам. Для задания грамматик используются стандартные XML-языки, обмен данными между системой распознавания и приложением осуществляется по протоколу MRCP.
3. Поиск ключевых слов в потоке слитной речи – распознавание отдельных участков речи. Речь может быть как спонтанной, так и соответствующей определённым правилам. Произнесенная речь не полностью преобразуется в текст - в ней автоматически находятся те участки, которые содержат заданные слова или словосочетания.
4. Распознавание слитной речи на большом словаре – все, что сказано, дословно преобразуется в текст. Достоверность распознавания достаточно высока.
5. Распознавание речи с помощью нейронных систем. На базе нейронных сетей можно создавать обучаемые и самообучающиеся системы, что является важной предпосылкой для их применения в системах распознавания (и синтеза) речи.
а) Представление речи в виде набора числовых параметров. После выделения информативных признаков речевого сигнала можно представить эти признаки в виде некоторого набора числовых параметров (т.е. в виде вектора в некотором числовом пространстве). Далее задача распознавания примитивов речи сводится к их классификации при помощи обучаемой нейронной сети.
б) Нейронные ансамбли. В качестве модели нейронной сети, пригодной для распознавания речи и обучаемой без учителя можно выбрать самоорганизующуюся карту признаков Кохонена. В ней для множества входных сигналов формируется нейронные ансамбли, представляющие эти сигналы. Этот алгоритм обладает способностью к статистическому усреднению, что позволяет решить проблему изменчивости речи.
в) Генетические алгоритмы. При использовании генетических алгоритмов создаются правила отбора, позволяющие определить, лучше или хуже справляется новая нейронная сеть с решением задачи. Кроме того, определяются правила модификации нейронной сети. Изменяя достаточно долго архитектуру нейронной сети и отбирая те архитектуры, которые позволяют решить задачу наилучшим образом, рано или поздно можно получить верное решение задачи.
Методы распознавания речи.
1. Метод скрытых марковских моделей. Базируется на следующих предположениях: речь может быть разбита на сегменты, внутри которых речевой сигнал может рассматриваться как стационарный, переход между этими состояниями осуществляется мгновенно; вероятность символа наблюдения, порождаемого моделью, зависит только от текущего состояния модели и не зависит от предыдущих.
2. Метод скользящего окна. Суть: определение вхождения ключевого слова с помощью алгоритма Витерби. Так как ключевое слово может начинаться и заканчиваться в любом месте сигнала, то этот метод перебирает все возможные пары начала и конца вхождения ключевого слова и находит самый вероятный путь для ключевого слова и этого отрезка, как если бы ключевое слово присутствовало в нем. Для каждого найденного вероятного пути ключевого слова применяется функция правдоподобия, основанная на срабатывании, если значение пути, рассчитанное в соответствии с применяемым методом оценки пути, больше предопределенного значения. Недостатки: большая вычислительная сложность; команды могут включать слова, которые плохо распознаются с помощью алгоритма распознавания ключевого слова.
3. Метод моделей заполнителей. Для алгоритмов распознавания ключевого слова слово для распознавания представляется встроенным в инородную речь. На этом основании методы моделей заполнителей обрабатывают эту инородную речь с помощью явного моделирования инородной речи за счет второстепенных моделей. Для этого в словарь системы распознавания добавляются «обобщенные» слова. Роль этих слов в том, чтобы любой сегмент сигнала незнакомого слова или неречевого акустического события был распознан системой как одно слово или цепочка из обобщенных слов. Для каждого обобщенного слова создается и обучается акустическая модель на корпусе данных с соответствующими размеченными сегментами сигнала. На выходе из декодера выдается цепочка, состоящая из слов словаря (ключевых слов) и обобщенных слов. Обобщенные слова затем отбрасываются, и оставшаяся часть цепочки считается результатом распознавания. Недостатки: ключевые слова могут быть распознаны как обобщенные; сложность оптимального выбора алфавита обобщенных слов.
№ 6. Системы управления данными. Электронные таблицы, базы данных.
База данных (БД) представляет собой совокупность структурированных данных, хранимых в памяти вычислительной системы и отображающих состояние объектов и их взаимосвязей в рассматриваемой предметной области.
Логическую структуру данных, хранимых в базе, называют моделью представления данных. К основным моделям представления данных (моделям данных) относятся иерархическая, сетевая, реляционная.
Система управления базами данных (СУБД) — это комплекс языковых и программных средств, предназначенный для создания, ведения и совместного использования БД многими пользователями. Обычно СУБД различают по используемой модели данных. Так, СУБД, основанные на использовании реляционной модели данных, называют реляционными СУБД.
Для работы с базой данных зачастую достаточно средств СУБД. Однако если требуется обеспечить удобство работы с БД неквалифицированным пользователям или интерфейс СУБД не устраивает пользователей, то могут быть разработаны приложения. Их создание требует программирования. Приложение представляет собой программу или комплекс программ, обеспечивающих автоматизацию решения какой-либо прикладной задачи. Приложения могут создаваться в среде или вне среды СУБД — с помощью системы программирования, использующей средства доступа к БД, к примеру, Delphiили С++ Вuildег. Приложения, разработанные в среде СУБД, часто называют приложениями СУБД, а приложения, разработанные вне СУБД, — внешними приложениями.
Словарь данных представляет собой подсистему БД, предназначенную для централизованного хранения информации о структурах данных, взаимосвязях файлов БД друг с другом, типах данных и форматах их представления, принадлежности данных пользователям, кодах защиты и разграничения доступа и т. п.
Информационные системы, основанные на использовании БД, обычно функционируют в архитектуре клиент-сервер. В этом случае БД размещается на компьютере-сервере, и к ней осуществляется совместный доступ.
Сервером определенного ресурса в компьютерной сети называется компьютер (программа), управляющий этим ресурсом,клиентом — компьютер (программа), использующий этот ресурс. В качестве ресурса компьютерной сети могут выступать, к примеру, базы данных, файлы, службы печати, почтовые службы.
Достоинством организации информационной системы на архитектуре клиент-сервер является удачное сочетание централизованного хранения, обслуживания и коллективного доступа к общей корпоративной информации с индивидуальной работой пользователей.
Согласно основному принципу архитектуры клиент-сервер, данные обрабатываются только на сервере. Пользователь или приложение формируют запросы, которые поступают к серверу БД в виде инструкций языка SQL. Сервер базы данных обеспечивает поиск и извлечение нужных данных, которые затем передаются на компьютер пользователя. Достоинством такого подхода в сравнении предыдущим является заметно меньший объем передаваемых данных.
Выделяют следующие виды СУБД :
* полнофункциональные СУБД;
* серверы БД;
* средства разработки программ работы с БД.
Полнофункциональные СУБД представляют собой традиционные СУБД. К ним относятся dBaseIV,MicrosoftAccess,MicrosoftFoxPro и др.
Серверы БД предназначены для организации центров обработки данных в сетях ЭВМ. Серверы БД обеспечивают обработку запросов клиентских программ обычно с помощью операторов SQL. Примерами серверов БД являются:MicrosoftSQLServer,InterBaseи др.
В роли клиентских программ в общем случае могут использоваться СУБД, электронные таблицы, текстовые процессоры, программы электронной почты и др.
Средства разработки программ работы с БД могут использоваться для создания следующих программ:
* клиентских программ;
* серверов БД и их отдельных компонентов;
* пользовательских приложений.
По характеру использования СУБД делят на многопользовательские (промышленные) и локальные (персональные).
Промышленные, СУБД представляют собой программную основу для разработки автоматизированных систем управления крупными экономическими объектами. Промышленные СУБД должны удовлетворять следующим требованиям:
* возможность организации совместной параллельной работы многих пользователей;
* масштабируемость;
* переносимость на различные аппаратные и программные платформы;
* устойчивость по отношению к сбоям различного рода, в том числе наличие многоуровневой системы резервирования хранимой информации;
* обеспечение безопасности хранимых данных и развитой структурированной системы доступа к ним.
Персональные СУБД — это программное обеспечение, ориентированное на решение задач локального пользователя или небольшой группы пользователей и предназначенное для использования на персональном компьютере. Это объясняет и их второе название — настольные. Определяющими характеристиками настольных систем являются:
* относительная простота эксплуатации, позволяющая создавать на их основе работоспособные пользовательские приложения;
* относительно ограниченные требования к аппаратным ресурсам.
По используемой модели данных СУБД разделяют на иерархические, сетевые, реляционные, объектно-ориентированные и др. Некоторые СУБД могут одновременно поддерживать несколько моделей данных.
Для работы с данными, хранящимися в базе, используются следующие типы языков:
* язык описания данных — высокоуровневый непроцедурный язык
декларативного типа, предназначенный для описания логической
структуры данных;
* язык манипулирования данными — совокупность конструкций, обеспечивающих выполнение основных операций по работе с данными: ввод, модификацию и выборку данных по запросам.
Названные языки в различных СУБД могут иметь отличия. Наибольшее распространение получили два стандартизованных языка: QBE— язык запросов по образцу иSQL— структурированный язык запросов.QBEв основном обладает свойствами языка манипулирования данными,SQLсочетает в себе свойства языков обоих типов.
СУБД реализует следующие основные функции низкого уровня:
* управление данными во внешней памяти;
* управление буферами оперативной памяти;
* управление транзакциями;
* ведение журнала изменений в БД;
* обеспечение целостности и безопасности БД.
Реализация функции управления данными во внешней памяти обеспечивает организацию управления ресурсами в файловой системе ОС.
Необходимость буферизации данных обусловлена тем, что объем оперативной памяти меньше объема внешней памяти. Буферы представляют собой области оперативной памяти, предназначенные для ускорения обмена между внешней и оперативной памятью. В буферах временно хранятся фрагменты БД, данные из которых предполагается использовать при обращении к СУБД или планируется записать в базу после обработки.
Механизм транзакций используется в СУБД для поддержания целостности данных в базе. Транзакцией называется некоторая неделимая последовательность операций над данными БД, которая отслеживается СУБД от начала и до завершения. Если по каким-либо причинам (сбои и отказы оборудования, ошибки в программном обеспечении, включая приложение) транзакция остается незавершенной, то она отменяется.
Транзакции присущи три основных свойства:
* атомарность (выполняются все входящие в транзакцию операции или ни одна);
* сериализуемость (отсутствует взаимное влияние выполняемых в одно и то же время транзакций);
* долговечность (даже крах системы не приводит к утрате результатов зафиксированной транзакции).
Примером транзакции является операция перевода денег с одного счета на другой в банковской системе. Сначала снимают деньги с одного счета, затем начисляют их на другой счет. Если хотя бы одно из действий не выполнится успешно, результат операции окажется неверным и будет нарушен баланс операции.
Ведение журнала изменений выполняется СУБД для обеспечения надежности хранения данных в базе при наличии аппаратных и программных сбоев.
Обеспечение целостности БД составляет необходимое условие успешного функционирования БД, особенно при ее сетевом использовании. Целостность БД — это свойство базы данных, означающее, что в ней содержится полная, непротиворечивая и адекватно отражающая предметную область информация. Целостное состояние БД описывается с помощью ограничений целостности в виде условий, которым должны удовлетворять хранимые в базе данные.
Обеспечение безопасности достигается в СУБД шифрованием данных, парольной защитой, поддержкой уровней доступа к базе данных и отдельным ее элементам (таблицам, формам, отчетам и др.).
Модели организации данных
Применение того или иного вида взаимосвязей определило три основные модели баз данных: иерархическую, сетевую и реляционную.
Иерархическая модель представляется в виде древовидного
графа, в котором объекты выделяются по уровням соподчиненности (иерархии) объектов.
Достоинство иерархической модели данных состоит в том, что она позволяет описать их структуру, как на логическом, так и на физическом уровне. Недостатками данной модели являются жесткая фиксированность взаимосвязей между элементами данных, вследствие чего любые изменения связей требуют изменения структуры, а также жесткая зависимость физической и логической организации данных. Быстрота доступа в иерархической модели достигнута за счет потери информационной гибкости.
В иерархической модели используется вид связи между элементами данных "один ко многим". Если применяется взаимосвязь вида "многие ко многим", то приходят к сетевой модели данных.
Сетевая модель базы данных для поставленной задачи представлена в виде диаграммы связей. В сетевой модели допустимы любые виды связей между записями и отсутствует ограничение на число обратных связей. Но должно соблюдаться одно правило: связь включает основную и зависимую записи
Достоинство сетевой модели БД — большая информационная гибкость по сравнению с иерархической моделью. Однако сохраняется общий для обеих моделей недостаток — достаточно жесткая структура, что препятствует развитию информационной базы системы управления. При необходимости частой реорганизации информационной базы (например, при использовании настраиваемых базовых информационных технологий) применяют наиболее совершенную модель БД — реляционную, в которой отсутствуют различия между объектами и взаимосвязями.
В реляционной модели базы данных взаимосвязи между элементами данных представляются в виде двумерных таблиц, называемых отношениями. Отношения обладают следующими свойствами: каждый элемент таблицы представляет собой один элемент данных (повторяющиеся группы отсутствуют); элементы столбца имеют одинаковую природу, и столбцам однозначно присвоены имена; в таблице нет двух одинаковых строк; строки и столбцы могут просматриваться в любом порядке вне зависимости от их информационного содержания.
Преимуществами реляционной модели БД являются простота логической модели (таблицы привычны для представления информации); гибкость системы защиты (для каждого отношения может быть задана правомерность доступа); независимость данных; возможность построения простого языка манипулирования данными с помощью математически строгой теории реляционной алгебры (алгебры отношений).
Типы данных в базах данных
Информационные системы работают со следующими основными типами данных.
Текстовые данные. Значение каждого текстового (символьного) данного представлено совокупностью произвольных алфавитно-цифровых символов, длина которой чаще всего не превышает 255 (например, 5, 10, 140). Текстовыми данными представляют в ИС фамилии и должности людей, названия фирм, продуктов, приборов и т.д. В частном случае значение текстового данного может быть именем какого-то файла, который содержит неструктурированную информацию произвольной длины (например, биографию или фотографию объекта). Фактически это структурированная ссылка, позволяющая резко расширить информативность вашей таблицы.
Числовые данные. Данные этого типа обычно используются для представления атрибутов, со значениями которых нужно проводить арифметические операции (весов, цен, коэффициентов и т.п.). Числовое данное, как правило, имеет дополнительные характеристики, например: целое число длиной 2 байта, число с плавающей точкой (4 байта) в фиксированном формате и др. Разделителем целой и дробной части обычно служит точка.
Данные типа даты и (или) времени. Данные типа даты задаются в каком-то известном машине формате, например, — ДД.ММ.ГГ (день, месяц, год). С первого взгляда — это частный случай текстового данного. Однако использование в ИС особого типа для даты имеет следующие преимущества. Во-первых, система получает возможность вести жесткий контроль (например, значение месяца может быть только дискретным в диапазоне 01-12). Во-вторых, появляется возможность автоматизированного представления формата даты в зависимости от традиций той или иной страны (например, в США принят формат ММ-ДД-ГТ). В-третьих, при программировании значительно упрощаются арифметические операции с датами (попробуйте, например, вручную вычислить дату спустя 57 дней после заданного числа). Те же преимущества имеет использование данного типа времени.
Логические данные. Данное этого типа (иногда его называют булевым) может принимать только одно из двух взаимоисключающих значений - True или False (условно: 1 или 0). Фактически это переключатель, значение которого можно интерпретировать как «Да» и «Нет» или как «Истина» и «Ложь». Логический тип удобно использовать для тех атрибутов, которые могут принимать одно из двух взаимоисключающих значений, например, наличие водительских прав (да -нет), военнообязанный (да-нет) и т.п.
Поля объекта OLE. Значением таких данных может быть любой объект OLE, который имеется на компьютере (графика, звук, видео). В частности, в список учащихся можно включить не только статическую фотографию учащегося, но и его голос.
Пользовательские типы. Во многих системах пользователям предоставляется возможность создавать собственные типы данных, например: «День недели» (понедельник, вторник и т.д.), «Адрес» (почтовый индекс - город - ...) и др.
В частном случае значение текстового данного может быть совокупностью пробелов, а значение числового данного - нулем. Если же в таблицу вообще не введена информация, значение будет пустым (Null). He следует путать Null (отсутствие данных) с нулем или пробелами. Во многих системах пользователю важно зафиксировать отсутствие данных для каких-то экземпляров объекта (например, отсутствие адреса, «Адрес is Null»). Если случайно ввести в такую строку таблицы пробел, система сочтет, что адрес задан, и данный экземпляр не попадет в список объектов с отсутствующими адресами.
Электронные таблицы
Электронные таблицы (ЭТ) предназначены для хранения и обработки информации, представленной в табличной форме. Электронные таблицы– это двумерные массивы, состоящие из столбцов и строк; их обычно называют рабочими листами. Программные средства для проектирования электронных таблиц называюттабличными процессорами.
Электронная таблица– это компьютерный эквивалент обычной таблицы, состоящей из строк и граф, на пересечении которых располагаются клетки, содержащие числовую информацию, формулы или текст.
Табличный процессор – это комплекс взаимосвязанных программ, предназначенный для обработки электронных таблиц.
Функции табличных процессоров весьма разнообразны:
- создание и редактирование электронных таблиц;
- оформление и печать электронных таблиц;
- создание многотабличных документов, объединенных формулами;
- построение диаграмм, их модификация и решение экономических задач графическими методами;
- работа с электронными таблицами как с базами данных: сортировка таблиц, выборка данных по запросам,
- создание итоговых и сводных таблиц;
- использование информации при построении таблиц из внешних баз данных;
- решение экономических задач типа “что-если” путем подбора параметров;
- решение оптимизационных задач;
- статистическая обработка данных;
- создание слайд-шоу;
- разработка макрокоманд, настройка среды под потребности пользователя и т.д.
Табличные процессоры представляют собой удобное средство для проведения экономических, бухгалтерских, инженерных и статистических расчетов. Они позволяют не только создавать таблицы, но и проводить сложный экономический анализ, моделировать и оптимизировать решение различного рода хозяйственных ситуаций. В каждом пакете имеются сотни встроенных математических функций и алгоритмов статистической обработки данных. Кроме того, имеются мощные средства для связи таблиц между собой, создания и редактирования электронных баз данных.
Специальные средства позволяют автоматически получать и распечатывать настраиваемые отчеты с использованием десятков различных типов таблиц, графиков, диаграмм, снабжать их комментариями и графическими иллюстрациями.
Табличные процессоры имеют встроенную справочную систему, предоставляющую пользователю информацию по конкретным командам меню и другие справочные данные. Многомерные таблицы позволяют быстро делать выборки в базе данных по любому критерию.
Что же такое электронная таблица? Это средство информационных технологий, позволяющее решать целый комплекс задач:
- Выполнение вычислений. Издавна многие расчеты выполняются в табличной форме, особенно в области делопроизводства: многочисленные расчетные ведомости, табуляграммы, сметы расходов и т. п. Кроме того, решение численными методами целого ряда математических задач; удобно выполнять в табличной форме. Электронные таблицы представляют собой удобный инструмент для автоматизации таких вычислений. Стало возможно решать на персональном компьютере многие вычислительные задачи программирования на каком-либо алгоритмическом языке.
- Математическое моделирование.
Использование математических формул в ЭТ позволяет представить взаимосвязь между различными параметрами некоторой реальной системы. Основное свойство ЭТ – мгновенный пересчет формул при изменении значений входящих в них операндов. Благодаря этому свойству, таблица представляет собой удобный инструмент для организации численного эксперимента:
- подбор параметров,
- прогноз поведения моделируемой системы,
- анализ зависимостей,
- планирование.
Дополнительные удобства для моделирования дает возможность графического представления данных (диаграммы);
- Использование электронной таблицы в качестве базы данных.
По сравнению с СУБД электронные таблицы имеют меньшие возможности в этой области. Однако некоторые операции манипулирования данными, свойственные реляционным СУБД, в них реализованы. Это поиск информации по заданным условиям и сортировка информации.
В электронных таблицах предусмотрен также графический режим работы, который дает возможность графического представления (в виде графиков, диаграмм) числовой информации, содержащейся в таблице.
Электронные таблицы просты в обращении, быстро осваиваются пользователями с начальной компьютерной подготовкой и во много раз упрощают и ускоряют работу бухгалтеров, экономистов, ученых.
Появление электронных таблиц исторически совпадает с началом распространения персональных компьютеров. Первая программа для работы с электронными таблицами — табличный процессор, была создана в 1979 году, предназначалась для компьютеров типа Apple II и называлась VisiCalc.В 1982 году появляется знаменитый табличный процессор Lotus 1-2-3, предназначенный для IBM PC. Lotus объединял в себе вычислительные возможности электронных таблиц, деловую графику и функции реляционнойСУБД.Популярность табличных процессоров росла очень быстро. Появлялись новые программные продукты этого класса: Multiplan, Quattro Pro, SuperCalc и другие.
Самые популярные табличные процессоры — Microsoft Excel, Lotus 1—2—3, SuperCalc, Quattro Pro. Ситуация, сложившаяся на рынке электронных таблиц, в настоящее время характеризуется явным лидирующим положением фирмыMicrosoft; 80% всех пользователей электронных таблиц предпочитаютExcel. На втором месте по объему продаж - Lotus 1—2—3, затем QuattroPro.
7. Электронные тезаурусы, словники и словари.
Компьютерная лексикография — прикладная научная дисциплина в языкознании, которая изучает методы использования компьютерной техники для составления словарей. Считается, что к.л. – это временная дисциплина периода перехода от ручной и рукописной лексикографической практики к новым безбумажным информационным технологиям.
В рамках компьютерной лексикографии разрабатываются компьютерные технологии составления и эксплуатации словарей. Специальные программы, такие как базы данных, компьютерные картотеки и программы обработки текста, позволяют в автоматическом режиме формировать словарные статьи, а также хранить словарную информацию и обрабатывать ее. Множество различных компьютерных лексикографических программ разделяются на две большие группы: программы поддержки лексикографических работ и автоматические словари различных типов, включающие лексикографические базы данных. Автоматический словарь – это словарь в специальном машинном формате, предназначенный для использования человеком-пользователем или компьютерной программой обработки текста. Иными словами, различаются автоматические словари конечного пользователя-человека и автоматические словари для программ обработки текста. Автоматические словари, предназначенные для конечного пользователя, по интерфейсу и структуре словарной статьи существенно отличаются от автоматических словарей, включенных в системы машинного перевода, системы автоматического реферирования, информационного поиска и т.д. Чаще всего они являются компьютерными версиями хорошо известных обычных словарей. На рынке программного обеспечения имеются компьютерные аналоги толковых словарей английского языка (автоматический Вебстер, автоматический толковый словарь английского языка издательства Коллинз, автоматический вариант Нового большого англо-русского словаря под ред. Ю.Д.Апресяна и Э.М.Медниковой), существует и компьютерная версия словаря Ожегова. Автоматические словари для программ обработки текста можно назвать автоматическими словарями в точном смысле. Они, как правило, не предназначены для обычного пользователя, а особенности их структуры и сфера охвата словарного материала задаются теми программами, которые с ними взаимодействуют.
Термин "Компьютерная лексикография" был создан для обозначения изучения машиночитаемых словарей Робертом Амслером и появился в середине 1980-х годов. Термин "машиночитаемой" означает, что данные из словаря (которые хранятся в электронном виде) могут быть обработаны, изучены и проанализированы с помощью вычислительной техники. Эта дисциплина не получила значительного внимания вплоть, до начала 1990-х годов.
Основные понятия компьютерной лексикографии
Автоматический словарь — см. выше
Программы поддержки лексикографических работ – это компьютерные программы, призванные тем или иным образом облегчить труд лексикографа. Традиционная форма фиксации словарных данных - это католожная карточка, где описывается слово, пример словоупотребления, источник примера, синтаксическая информация и дополнительная информация, исходя из целей создания словаря. Каталожные карточки собираются в картотеки, а из картотек уже формируются словари различного рода.
Вместо обычной картотеки в компьютерных средах используются записи в базы данных. Лексикографические базы данных фиксируют первичный материал, который используется для написания словарных статей словаря. Лексикографические базы данных не существуют, но традиционные стандартные пакеты для баз данных (MS Access, Paradox, D-Base) подходят для такой работы.
Другим этапом лексикографической работы является поиск примеров на словоупотребление и формирование картотеки примеров. На компьютере это намного проще, так как выбор примеров из корпуса текстов автоматизируется с помощью макросов или специальных программ-конкордансов (конкорданс – словарь примеров).
Гипертекст — это множество текстов со связывающими их отношениями (системой переходов).
Средства навигации по словарю — ссылки, внедренные в различные элементы электронной среды. Они являются частью гипертекстового устройства электронного словаря, представляющего собой соединение смысловой структуры, структуры внутренних связей некоего содержания и технической среды, а также технических средств, дающих человеку возможность осваивать структуру смысловых связей, а также осуществлять переходы между взаимосвязанными элементами.
Электронные словари для конечного пользователя (человека)
Электронный словарь для к. п. — это любой упорядоченный, относительно конечный массив лингвистической информации, представленный в виде списка, таблицы или перечня, удобного для размещения в памяти ЭВМ и снабженного программами автоматической обработки и пополнения. Электронные словари позволяют осуществлять быстрый поиск нужных слов, часто с учетом морфологических форм и с возможностью поиска сочетаний слов (примеров употребления), а также с возможностью изменения направления перевода (например, англо-русский или русско-английский)
Одним из преимуществ электронных словарей перед традиционными является тот факт, что составление электронного словаря отнимает меньше времени и усилий со стороны лексикографа. Создание традиционного словаря включает в себя: формирование словника, составление картотеки примеров (вручную), написание словарных статей, создание рукописного варианта словаря, перепечатывание и редактирование рукописи, авторская доработка, перепечатка и корректура, верстка словаря, корректура, печать словаря, словарь.
Создание электронного словаря включает в себя: формирование словника, составление корпуса примеров (с использованием электронных корпусов текстов), написание словарных статей, копирование статей в базу данных словаря, корректура текста словаря непосредственно в базе данных, словарь.
Типы электронных словарей
· Портативные электронные словари - здесь в роли электронного словаря выступает специальное портативное устройство. Существует целый класс подобных устройств, предназначенных для туристов, переводчиков, а также других людей, использующих иностранные языки. Существуют: non-talking (обычные электронные) dictionaries, talkingdictionaries (электронные словари с модулем синтеза речи), speech-to-speechdictionaries (электронные словари с модулями синтеза и распознавания речи), сканеры-переводчики
· Словари-программы (lingvo, например)
· Онлайн-словари - размещены на веб-сайте, и для доступа к ним требуется постоянное подключение компьютера к Интернету; составлением таких словарей занимается т.н. кибер-лексикография. Онлайновые словари и словари-программы предусматривают возможность
· Терминологические базы данных - электронная оболочка данных, разбитых на узкоспециализированные области и ориентированных на определенные группы пользователей с различными интересами, знаниями и уровнем подготовки.
Электронные словари
Словари представляют собой совокупность единиц, расположенных в определённом порядке, и используются в качестве справочника, который объясняет значения вписываемых единиц, даёт различную информацию о них или их перевод на другой язык, сообщает сведения о предметах, обозначаемых этими единицами.
Словари выполняют три основные социальные функции:
q информативную,
q коммуникативную,
q нормативную.
Первая позволяет кратчайшим способом – через обозначения – приобщиться к накопленным знаниям, вторая дает возможность выбрать необходимые слова родного или иностранного языка при общении, а третья, фиксируя значения и употребления слов, способствует совершенствованию и унификации языка как средства общения.
Электронные словари – вид программного обеспечения для решения лингвистических задач, доказывающий преимущества «безбумажного» подхода к обработке и хранению информации. Во-первых, они компактны и легко помещаются на одном компакт-диске. Во-вторых, гораздо удобнее в использовании: отыскать нужное слово можно гораздо быстрее, причем сразу и общие, и специализированные его значения, подключая и отключая дополнительные словари. В-третьих, электронные словари пополняемы – как за счет подключаемых словарей, так и за счет возможности создавать пользовательские словари. В-четвертых, электронные словари опережают в своем развитии «бумажные». В-пятых, электронные словари могут быть озвучены, проиллюстрированы и анимированы.
Электронные словари сочетают большой объем информации с удобством пользования, что достигается быстродействием системы поиска. Чтобы найти слово в электронном словаре, обычно достаточно просто напечатать его в командной строке словаря, нажать клавишу ENTER – и в отдельном окошке появится перевод. Многие словари позволяют переводить слова, не выходя из текстового редактopa или другого офисного приложения, с которым Вы работаете в данный момент. Для этого надо выделить нужное слово и нажать определенную комбинацию клавиш, называемых «горячими». Каждый элемент информации о слове может быть гиперссылкой в другую словарную статью. Система гиперссылок обеспечивает возможность быстрого доступа к нужной информации без изнурительного поиска, одним щелчком мыши.
Электронные словари позволяют:
q открыть и просмотреть весь список слов, находящихся в словаре в алфавитном порядке,
q найти при помощи быстродействующих поисковых средств любое слово из словаря,
q создать пользовательский словарь,
q ввести новое слово или словосочетание в словарь,
q ввести слово и его перевод из подготовленного ранее текстового файла,
q изменить грамматическую информацию или перевод в словарной статье,
q удалить слово из словаря,
q сохранить словарь.
Существуют различные классификации электронных словарей. Наиболее общей является классификация словарей на энциклопедические и лингвистические. Статьи в словарях обычно располагаются в алфавитном или систематическом порядке. Энциклопедические словари представляют собой научное или научно-популярное справочное издание, содержащее систематизированную информацию по различным областям знаний и практической деятельности. Наиболее популярными являются следующие энциклопедии: Энциклопедический словарь Брокгауза и Ефрона, Британская энциклопедия "Британика" (Великобритания и США), Энциклопедический словарь Мейера (Германия)и другие.
В отличие от энциклопедических словарей, сообщающих сведения о соответствующих реалиях – предметах, явлениях, событиях, лингвистические словари содержат информацию о значениях и употреблении слов, грамматические и фонетические особенности слов и т.п. В лингвистических словарях решается проблема соотношения между языком и речью: словари представляют слова в изолированном виде, фиксируя, прежде всего их общеобязательные и устоявшиеся значения, тогда как в живой речи значения слов могут претерпевать изменения. Стремясь отразить реальное бытие слова в языке и речи, словари выводят его значения из употреблений в разнообразных контекстах, сопровождают слово пометами и уточнениями, примерами и иллюстрациями, показывающими ситуации, в которых слово используется, и связанные с ним ассоциации. Для лингвистических словарей решается проблема размещения слов в словаре и значений в словарной статье с целью отражения общей структуры лексического состава языка и семантической структуры отдельного слова, а также проблема способов выделения и толкования значений (в связи с этим используются современные методы лексикологии и разрабатывается лексикографический метаязык).
Лингвистические словари можно разделить по следующим параметрам:
q по толкованию слов – толковые словари, разъясняющие значение и употребление слов средствами одного и того же языка (объяснения, перефразирования, синонимы и т.п.),
q по числу языков – переводные (двуязычные и многоязычные), дающие перевод и разъясняющие значение и употребление слов средствами другого языка,
q по отбору лексики – тезаурусы, охватывающие всю или большую часть лексики языка, и частные словари, отражающие некоторые тематические и стилевые пласты лексики (словари терминологические, диалектные, просторечия, языка писателей и др.), либо особые разновидности слов (словари неологизмов, архаизмов, редких слов, сокращений, иностранных слов, собственных имён),
q по способу описания слова – специальные, раскрывающие отдельные аспекты слов и отношений между ними (словари этимологические, словообразовательные, словосочетаний, грамматические, орфографические, орфоэпические, синонимические, антонимические, паронимические, рифм и др.),
q по единице лексикографического описания (меньше или больше слова) – словари корней, морфем, фразеологические, словари цитат,
q по расположению материала – идеографические, аналогические (слова располагаются не по алфавиту, а по смысловым ассоциациям), обратные,
q по назначению – словари ошибок, трудностей,
q по частоте употребительности – частотные словари (в них
приводятся числовые характеристики употребительности слов, словоформ, словосочетаний какого-либо конкретного языка, языка того или иного писателя, какого-либо произведения и т.п.).
Теорией и практикой составления словарей занимается лексикография (от греч. lexikos – относящийся к слову, grapho – пишу). С накоплением огромных словарных баз данных и развитием электронно-вычислительной техники лексикография получила новое развитие в конце прошлого века – были созданы электронные словари для массового пользователя.
Электронный словарь Lingvo является одним из многочисленных программных продуктов, разработанных российской компанией ABBYY SoftwareHouse. Подробную информацию о словаре можно найти на сайте компании по адресу http://www.abbyy.com.
Существуют двуязычные и многоязычные версии словаря Lingvo, которые постоянно совершенствуются. Двуязычный англо-русский и русско-английский словарь Lingvo создан на основе более десятка лучших английских и русских словарей: TheOxfordEnglishDictionary, Merriam-Webster'sCollegiateDictionary, Collins COBUILD EnglishLanguageDictionary, Новый большой англо-русский словарь, Толковый словарь живого великорусского языка В. И. Даля, Большой энциклопедический словарь и др. В нем представлена наиболее современная английская лексика. Начиная с версии 8.0, в состав системных словарей Lingvo входит Грамматический словарь английского языка LingvoGrammatical. Многоязычная версия Lingvo включает словари, которые позволяют переводить с русского языка на английский, немецкий, французский, испанский, итальянский и наоборот.
При вводе текста с клавиатуры в строку запроса программа начинает автоматически листать свой словарь по мере набора слова. Если переводимого слова или его грамматической формы в словаре нет, то программа выдаст перевод наиболее похожего слова. Перевод слова может варьироваться в зависимости от подключаемых словарей, так как в стандартный установочный пакет входит ряд русских и иностранных словарей. Словари подключаются и отключаются с помощью кнопок на основной панели программы. Несмотря на большой объем словарей, поиск осуществляется очень быстро.
Перевод слова появляется в отдельном окне, в котором также предусмотрена возможность переключения между словарями. Благодаря многооконному интерфейсу можно одновременно держать открытыми несколько словарных статей. Это особенно полезно, если необходимо разобраться с нюансами значений. Варианты перевода даются с указанием части речи и грамматических характеристик слова. Если переводимое слово – глагол, то указывается его вид – совершенный или несовершенный, если существительное – род, если местоимение – то род, лицо и самые употребительные падежные формы. При переводе с английского на русский дается транскрипция переводимого слова, а также, что особенно ценно, – наиболее употребительные словосочетания. При наличии звуковой карты можно прослушать и правильное звучание английских слов. В Lingvo включены 5000 наиболее употребительных слов, озвученных дикторами из Оксфорда.
В 1999 году производитель Lingvo – компания ABBYY выступила с интересной инициативой. Она предложила всем желающим размещать свои собственные словари на сайте http://www.lingvo.ru. Сегодня на сайте уже содержится множество авторских словарей, доступных для свободного использования и распространения. Среди них такие экзотические, как словарь хакерской терминологии, глоссарий сетевых терминов, словарь терминов и сокращений, связанных с трубопроводами для транспортировки нефти и газа, словарь терминов, связанных с промышленной кройкой и шитьем, созданием лекал и др. На сайте компании можно принять участие в конкурсе пользовательских словарей и бесплатно скачать полюбившиеся. Средства разработки словарей также распространяются бесплатно.
Современный переводчик не может конкурировать на рынке переводческих услуг без овладения информационными технологиями перевода. Перевод с помощью компьютера (ComputerAidedTranslation – CAT) включает следующие основные компьютерные технологии.
Установленные на компьютере (офлайновые) общелингвистические и специализированные электронные словари.
Системы автоматизированного перевода.
Системы переводческой памяти.
Онлайновые (сетевые) специализированные и толковые словари.
Лингвистический поиск в сети Интернет.
Современные электронные словари позволяют не только быстро найти перевод слова или выражения на различные языки, но и отыскать примеры его употребления, грамматические формы и устойчивые словосочетания, в которых это слово используется. Среди офлайновых словарей, которые нужны для каждодневной работы профессиональному переводчику, следует выделить в первую очередь Lingvo и Multitran. Это наиболее полные профессиональные многоязычные словари, включающие большое количество узкоспециализированных тематик.
Если офлайновые словари не позволяют найти приемлемого перевода терминов и выражений, то следует обратиться к поиску в сети Интернет. В Интернете можно найти перевод терминов и словосочетаний, сокращений и названий, материалы по теме перевода на русском языке и на языке перевода, а также вспомогательные для переводчика материалы (нормативные документы, обсуждения сложных тем и опыта перевода на форумах переводчиков и др.).
Системы автоматизированного (машинного) перевода (MachineTranslation, MT) могут быть использованы для быстрого перевода с различных языком больших объемов текста по специальным тематикам с учетом их специфики. После редактирования такой перевод приближается по качеству к ручному переводу. Машинный перевод является одной из технологий перевода с помощью компьютера (CAT). При машинном переводе приложение осуществляет автоматический связный перевод текста на другой естественный язык с использованием словарей и набора правил перевода с учетом морфологии, синтаксиса и семантических связей без участия человека или при его минимальном участии.
Существуют следующие виды систем машинного перевода.
FAMT (Fully-automatedmachinetranslation) – полностью автоматизированный машинный перевод (автоматический);
HAMT (Human-assistedmachinetranslation) – машинный перевод при участии человека
(автоматизированный в интерактивном режиме);
MAHT (Machine-assistedhumantranslation) – перевод, осуществляемый человеком с использованием компьютера.
Автоматизированный перевод типа HAMT рассматривается в пособии на примере системы
PROMT.
CAT перевод типа MAHT реализуется в виде систем переводческой памяти (TranslationMemory), которые используют для перевода переведенные ранее фрагменты текста, что существенно
повышает производительность переводчика без потери качества. При командной работе над проектом, такие системы позволяют использовать коллективный опыт переводчиков и обеспечивают единство терминологии, что значительно повышает единообразие перевода различными переводчиками и скорость перевода. В пособии подробно рассмотрена работа с программой памяти переводов memoQ.
1 СЛОВАРЬ LINGVO
1.1 Основные функции словаря Lingvo
Электронный словарь ABBYY Lingvo x5 (www.lingvo.ru) – это словарь с большой и современной словарной базой, который включает около 220 общелексических, тематических, лингвострановедческих и толковых словарей (профессиональная версия):
 20 языков: английский, русский, немецкий, французский, испанский, итальянский,
20 языков: английский, русский, немецкий, французский, испанский, итальянский,
португальский, греческий, финский, китайский, латинский, турецкий, украинский,
казахский, татарский, польский, венгерский, датский, нидерландский, норвежский, 220
словарей, более 12 миллионов словарных статей.
Толковыесловарианглийскогоязыка: Oxford English Dictionary, Oxford American Dictionary, Collins Cobuild Dictionary. Словарь NewOxfordAmericanDictionary содержит более 1000
иллюстраций.
Толковые словари русского языка: словарь Даля, словарьОжегова-Шведовой,Большая Советская энциклоперия, Большой энциклопедический словарь, Толковый словарь и др.
Около 76 000 слов и фраз в словарях общей лексики и разговорниках на английском,
немецком, французском, итальянском, испанском и китайском озвучены дикторами-
носителями этих языков.
Для тех, кто изучает английский язык, в программу включены всемирно известный учебный словарь CollinsCobuildAdvancedLearner’sEnglishDictionaryивидео-словарьWordExpress
компании EnglishClub TV. В освоении английского помогут занимательные ситуативные видео-диалогиFullContact, иллюстрированный толковый словарь английского языка NewOxfordAmericanDictionaryиангло-русскийграмматический словарь.
Приложение LingvoTutor для изучения иностранных языков, содержит комплекс упражнений для расширения словарного запаса и повышения грамотности при изучении языков. Эти упражнения включают такие разделы, как “Знакомство”, “Мозаика”,
“Варианты”, “Написание” и “Самопроверка”.
Видеоуроки предназначены для совершенствования речевого общения. В Lingvo x5 входит коллекция развлекательных и познавательных сюжетов с погружением в языковую среду.
Lingvo обеспечивает пользователям доступ к словарям через лингвистический онлайн-порталLingvo.Pro. Портал позволяет обращаться к базе переводов, дополнять ее и взаимодействовать с другими пользователями. Используя этот портал, компания ABBYY развивает модель SaaS(Software-as-a-Service),позволяющую расширить доступность своих продуктов для пользователей.
Перевод слова и словосочетания в Lingvo отображается в виде карточки перевода, в которой показывается начало словарных статей из всех словарей с заголовком, совпадающим с заданным словом или словосочетанием.
Всплывающий перевод при наведении курсора мыши на слово помогает при чтении текста в программе Word, WordPad, Excel. PDF-файлов,в браузере Explorer,интернет-страниц,ICQ, Flash-
роликов и субтитров к фильмам.
В программу Lingvo включены примеры писем на английском, немецком, французском и испанском языках по материалам двуязычных словарей OxfordConcise. Примеры описывают самые распространенные жизненные ситуации и полезны для ведения переписки.
При наличии интернет-подключения,Lingvo обеспечивает доступ конлайн-базепамяти переводов (ТМ – translationmemory) для английского, немецкого и французского языков. Программа показывает примеры современного употребления слов и словосочетаний в предложениях из художественной и технической литературы, законодательных и юридических документов, синтернет-сайтов.С помощью этой базы пользователь может подобрать точный перевод слова, определить, действительно ли употребляется в речи данный оборот, найти новые варианты перевода и примеры их использования. База памяти переводов содержит более миллиона предложений. Чтобы получить примеры из памяти переводов в карточке наведите курсор мыши на интересующий перевод и после появления рамки вокруг слова нажмите на него левой кнопкой мыши.
Электронные словники
СЛОВНИК -1) вэнциклопедическихизданиях - полныйпереченьназванийстатей (терминов), какправило, скраткойаннотациейиуказаниемразмеровстатей (впечатныхзнаках).2) Влингвистическихсловарях - алфавитныйилисистематическийпереченьсловарныхединиц, подлежащихтолкованиюилипереводу.
Ключевой для переводчика технической документации в данных условиях является технология TRANSLATION MEMORY (TM). Системам машинного перевода уделено мало места, так как возможности их ограничены и это не позволяет рекомендовать их для применения в процессе профессиональной работы над текстом.
В последнее время устойчиво возрастает объем переводов, связанных с информационными технологиями, причем переводческим и компьютерным компаниям приходится иметь дело не только с подготовкой документации, но и с локализацией программного обеспечения, т.е. с переводом ресурсов, содержащихся в exe- и dll- файлах. И с последующим тестированием ПО.
Что же такое машинный перевод и системы автоматизированного перевода, чем они отличаются и как могут помочь переводчику в его работе.
Машинный перевод
Машинный перевод — процесс перевода текстов (письменных, а в идеале и устных) с одного естественного языка на другой полностью специальной компьютерной . Так же называется направление научных исследований, связанных с построением подобных систем.
Автоматизированный перевод
Вместо «машинный» иногда употребляеся слово автоматический, что не влияет на смысл. Однако термин автоматизированный перевод имеет совсем другое значение — при нём программа просто помогает человеку переводить тексты.
Автоматизированный перевод предполагает такие формы взаимодействия:
- Частично автоматизированный перевод: например, использование переводчиком-человеком компьютерных .
- Системы с разделением труда: компьютер обучен переводить только фразы жёстко заданной структуры (но делает это так, чтобы исправлять за ним не требовалось), а всё не уложившееся в схему отдает человеку.
В англоязычной терминологии также различаются термины machinetranslation, MT (полностью автоматический перевод) и machine-aided или machine-assistedtranslation (MAT) (автоматизированный); если же надо обозначить и то, и другое, пишут M(A)T.
История машинного перевода
Мысль использовать ЭВМ для перевода была высказана в году в , сразу после появления первых ЭВМ. Первая публичная машинного перевода (так называемый Джорджтаунский эксперимент) состоялась в году. Несмотря на примитивность той системы (словарь в 150 слов, из 6 правил, перевод нескольких простых фраз), этот эксперимент получил широкий резонанс: начались исследования в , , , , , , , и других странах; в том же 1954 году и в .
К середине в США для практического использования были предоставлены две системы русско-английского перевода:
- MARK (в Департаменте иностранной техники ВВС США);
- GAT (разработка Джорджтаунского университета, использовалась в Национальной лаборатории атомной энергии в Окридже и в центре Евратома в г. Испра, Италия).
Однако созданная для оценки подобных систем комиссия пришла к выводу, что в силу низкого качества машинно переведённых текстов эта деятельность в условиях США нерентабельна. Хотя комиссия рекомендовала продолжать и углублять теоретические разработки, в целом её выводы привели к росту , снижению финансирования, часто к полному прекращению работ по этой тематике.
Тем не менее, в ряде стран исследования продолжались, чему способствовал постоянный прогресс вычислительной техники. Особенно существенным фактором стало появление мини- и персональных компьютеров, а с ними всё более сложных словарных, и т. п. систем, ориентированных на работу с естественноязыковыми данными. Росла и необходимость в переводе как таковом ввиду роста международных связей. Все это привело к новому подъёму этой области, наступившему примерно с середины .В наступило время широкого практического использования переводческих систем, сложился рынок коммерческих разработок по этой теме.
Впрочем, мечты, с которыми род людской взялся полвека назад за задачу машинного перевода, в значительной мере остаются мечтами: высококачественный перевод текстов широкой тематики по-прежнему недостижим. Однако несомненным является ускорение работы переводчика при использовании систем машинного перевода: по оценкам конца 1980-х, до пяти раз.
В настоящее время существует множество коммерческих проектов машинного перевода. Одним из пионеров в области машинного перевода была компания . В России большой вклад в развитие машинного перевода внесла группа под руководством проф. Р. Г. Пиотровского (Российский государственный педагогический университет им. Герцена, ).
Качество перевода
Качество перевода зависит от тематики и исходного текста. Машинный перевод художественных текстов практически всегда оказывается неудовлетворительного качества. Тем не менее для технических документов при наличии специализированных машинных словарей и некоторой настройке системы на особенности того или иного типа текстов возможно получение перевода приемлемого качества, который нуждается лишь в небольшой редакторской корректировке. Чем более формализован стиль исходного документа, тем большего качества перевода можно ожидать. Самых лучших результатов при использовании машинного перевода можно достичь для текстов, написанных в техническом (различные описания и руководства) и официально-деловом стиле.
Применение машинного перевода без настройки на тематику (или с намеренно неверной настройкой) служит предметом многочисленных бродящих по Интернету шуток. Из пространных примеров наиболее известен текст «Гуртовщики Мыши» (перевод компьютерной документации программой Poliglossum на основе медицинского, коммерческого и юридического словарей); из кратких — фраза «Mycathasgivenbirthtofourkittens, twoyellow, onewhiteandoneblack», которую программа ПРОМТ превращает в «Мой кот родил четырёх котят, два жёлтых цвета, одно белое и одного афроамериканца».
Чаще всего подобные шутки связаны с тем, что программа не распознаёт контекст фразы и переводит термины дословно, к тому же не отличая собственных имён от обычных слов. Та же программа ПРОМТ превращает «bra-ketnotation» в «примечание Кети лифчика», «Liealgebra» — в «алгебру Лжи», «eccentricityvector» — в «вектор оригинальности» и т. п.
Автоматизированный перевод
Автоматизированный перевод (АП, Computer-AidedTranslation) — текстов на с использованием компьютерных технологий. От машинного перевода (МП) он отличается тем, что весь процесс перевода осуществляется человеком, компьютер лишь помогает ему произвести готовый текст либо за меньшее время, либо с лучшим качеством.
Идея АП появилась с момента появления компьютеров: переводчики всегда выступали против стандартной в те годы концепции МП, на которую было направлено большинство исследований в области компьютерной лингвистики, но поддерживали использование компьютеров для помощи переводчикам. В годы Европейское объединение угля и стали (предшественник современного ) стало создавать терминологические базы данных под общим названием . В Советском Союзе для создания баз такого рода был создан .
В современной форме идея АП была развита в статье Мартина Кея 1980 года, который выдвинул следующий тезис: "bytakingoverwhatismechanicalandroutine, it (computer) freeshumanbeingsforwhatisessentiallyhuman" (компьютер берет на себя рутинные операции и освобождает человека для операций, требующих человеческого мышления).
В настоящее время наиболее распространенными способами использования компьютеров при письменном переводе является работа со словарями и глоссариями, памятью переводов ( TranslationMemory, TM), содержащей примеры ранее переведенных текстов, а также использование так называемых , больших коллекций текстов на одном или нескольких языках, что дает сжатое описание того, как слова и выражения реально используются в языке в целом или в конкретной предметной области.
Для программного обеспечения часто применяются специализированные средства, например, , которые позволяют переводить меню и сообщения в программных ресурсах и непосредственно в откомпилированных программах, а также тестировать корректность локализации. Для перевода аудиовизуальных материалов (главным образом фильмов) также используются специализированные средства, например, , которые объединяют в себе некоторые аспекты памяти переводов, но дополнительно обеспечивают возможность появления субтитров по времени, их форматирования на экране, следования видеостандартам и т.п.
При синхронном переводе использование средств автоматизированного перевода по необходимости ограничено. Одним из примеров является использование словарей, загружаемых на . Другим примеров может служить полуавтоматическое извлечение списков терминов при подготовке к синхронному переводу в узкой предметной области.
В узких предметных областях при большом количестве исходных текстов и устоявшейся терминологии переводчики могут использовать и машинный перевод, который может обеспечить хорошее качество перевода терминологии и устойчивых выражений в узкой области. Переводчик в этом случае осуществляет полученного текста. Более половины текстов внутри (главным образом юридические тесты и текущая корреспонденция) переводится с использованием МП.
Память переводов
Па́мятьперево́дов (ПП, translationmemory, TM иногда называемая «Накопитель переводов») — база данных, содержащая набор ранее переведенных . Одна запись в такой базе данных соответствует «единице перевода» ( translationunit), за которую обычно принимается одно (реже — часть сложносочинённого предложения, либо ). Если очередное предложение исходного текста в точности совпадает с предложением, хранящимся в базе (точное соответствие, exactmatch), оно может быть автоматически подставлено в перевод. Новое предложение может также слегка отличаться от хранящегося в базе (неточное соответствие, fuzzymatch). Такое предложение может быть также подставлено в перевод, но переводчик будет должен внести необходимые изменения.
Помимо ускорения процесса перевода повторяющихся фрагментов и изменений, внесенных в уже переведенные тексты (например, новых версий программных продуктов или изменений в законодательстве), системы ПП также обеспечивают единообразие перевода терминологии в одинаковых фрагментах, что особенно важно при техническом переводе. С другой стороны, если переводчик регулярно подставляет в свой перевод точные соответствия, извлеченные из баз переводов, без контроля их использования в новом контексте, качество переведенного текста может ухудшиться.
В каждой конкретной системе ПП данные хранятся в своем собственном формате (текстовый формат в Wordfast, база данных Access в DejaVu), но существует международный стандарт ( TranslationMemoryeXchangeformat), который основан на XML и который могут порождать практически все системы ПП. Благодаря этому результаты работы переводчиков можно обменивать между приложениями, то есть переводчик работающий с OmegaT может использовать ПП, созданную в ТРАДОСе и наоборот.
Большинство систем ПП как минимум поддерживают создание и использование словарей пользователя, создание новых баз данных на основе параллельных текстов ( alignment), а также полуавтоматическое извлечение терминологии из оригинальных и параллельных текстов.
Система «Антиплагиат»
Среди программных продуктов для определения авторства текстов можно выделить систему «Антиплагиат» (http://www.antiplagiat.ru). Этот интернет-сервис предлагает осуществить проверку текстовых документов на наличие заимствований из общедоступных сетевых источников. Система позволяет проводить атрибуцию текстов на различных языках. На первом этапе система собирает информацию из различных источников: загружает из Интернета и обрабатывает сайты, находящиеся в открытом доступе, базы научных статей и рефератов. Загруженные документы проходят процедуру фильтрации, в результате которой отбрасывается бесполезная с точки зрения потенциального цитирования информация (например, HTML-страницы с большим количеством рекламы, новостные заголовки и т. д.). На следующем этапе каждый из полученных таким образом текстов определенным образом форматируется и заносится в системную базу данных. Кроме того, в общую базу текстов поступают документы, загруженные на проверку пользователем, если такая возможность была разрешена им во время процедуры загрузки. Все пользовательские документы, загружаемые для проверки, ставятся в очередь на обработку. Поиск совпадений осуществляется методом сравнения последовательностей символов без учета языковых особенностей и речевых взаимосвязей. За счет этого достигается высокая, в несколько секунд, скорость поиска совпадений. Проверка документа, например, реферата среднего размера, занимает несколько секунд. После проверки документа пользователь получает отчет, в котором представляются результаты. Структура отчета позволяет выделять в проверяемом тексте заимствованные части как по всем источникам, так и по их любому подмножеству.
Все программные алгоритмы, используемые в «Антиплагиате», являются коммерческойтайной компании «Форексис», и открытого доступа к ним нет. К недостаткам системы можно отнести невозможность «отлавливать» заимствованный текст при условии, что в каждом из предложений текста добавлено или убрано всего лишь одно слово. На данный момент существуют программы, например «Антиплагиат киллер» (http://otlichnik.biz/publ/antiplagiat_killer_2_0/1-1-0-4), позволяющие «обходить» систему «Антиплагиат».
Авторский инвариант и лингвистические спектры
В рамках относительно небольшого текста значения большинства формальных характеристик не позволяют установить авторский стиль. Кроме того, на коротких текстах часто не проявляются и другие характеристики, например, особенности использования авторской фразеологии и идиоматики, а также метафорической системы, системы эпитетов и т. д. С другой стороны, грамматические особенности авторского стиля – частота употребления неполнозначных, служебных слов (частиц, союзов, предлогов, некоторых модальных слов, вводных выражений) – для текстов порядка 1 000–2 000 слов сохраняются. Такой метод определения авторства текста иногда называют лингвостатистическим анализом неполнозначной лексики.
Система «Стилеанализатор»
Проблему атрибуции текстов в работах [8; 13] предлагается решать при помощи нейронных сетей и методов иерархической кластеризации. предложены подходы для сравнения стилей текстов по частотным признакам с использованием гипергеометрического критерия (двустороннего точного критерия Фишера) и критерия хи-квадрат. Под частотным признаком понимается любой признак стиля текста, допускающий возможность нахождения частоты его появления в тексте (например, число появления абзацев в тексте). На основе проведенных исследований разработан программный комплекс «Стилеанализатор». Он позволил провести исследования зависимости от объемов текстовых фрагментов качества классификации текстов по авторству, по жанровым типам и источникам.
Система «Авторовед»
Еслизадачу определения авторства сформулировать как задачу классификации, то одним из широко применяемых выходов является построение бинарного классификатора. Все тексты,включая обучающую часть выборки, разворачиваются в очень большой вектор, индексируемый словами. После этого имеется два множества точек из обучающей выборки в многомерном пространстве: принадлежащие данному автору и не принадлежащие автору.
ИТАК, в основе формальных методов атрибуции текстов лежит представление о том, что с возрастанием объема текста параметры, характеризующие авторский стиль, становятся устойчивыми с вероятностной точки зрения, что позволяет устанавливать авторство по стабильноповторяющимся формальным характеристикам текста. Поэтому более высокое качество атрибуции достигается для текстов большого объема, и менее точный результат получается длятекстов маленького объема.
Открытым остается вопрос о выборе авторского инварианта (набора формальных параметров текста). Часто на практике решается ограниченный круг задач для предварительнозаданного набора текстов. Настройка, тестирование и демонстрация инструментов анализаориентирована только на эти тексты, и нет никакой гарантии, что методы будут эффективносправляться с задачей на других данных. Иными словами, для построения универсального инезависящего от текстов авторского инварианта необходимо искать новые пути формирования характеристик.
Установив набор характеристик, исследователь сталкивается с проблемой их структуризации, в чем существенную помощь могут оказать классические статистические методы.С помощью факторного анализа и анализа главных компонент можно установить вклад тойили иной характеристики в процесс распознавания автора, иерархический кластерный анализпозволит сделать объединение отдельных характеристик в подгруппы, подгрупп в группыи т. д. Немалую помощь можно получить от нейронных сетей прямого распространения, еслипопытаться обучить сеть на наборе примеров, взяв в качестве входов отдельные характеристики, а затем оценивать, какое влияние оказывает тот или иной вход на систему выходов.
Недостаочно исследованы зависимости качества классификации различными методамиот объемов фрагментов и от числа классов. Наконец, имеющиеся программы анализа текстовне ориентированы на комплексное исследование и сравнение стилей текстов (для разных задач анализа стилей текстов с использованием различных методов их решения, различныхчастотных признаков, различного текстового материала и т. д.).
К проблемам, затрудняющим исследования в области атрибуции текстов, относится такжепроблема составления выборки эталонных текстов. Желательно, чтобы произведения былиподобраны следующим образом: тексты разных писателей в максимальной степени различались друг от друга, а тексты одного писателя были максимально близки. Но существует немало случаев, когда известный писатель в какой-то период своего творчества менял стильизложения, или произведения были написаны в соавторстве. Эти факты создают дополнительные сложности при решении задачи установления авторства.
Необходимо проводить дальнейшие исследования, направленные на поиск новых или совершенствование уже имеющихся методов атрибуции текстов, а также на проведение экспериментов, целью которых является поиск характеристик, позволяющих четко разделять стили авторов, в том числе и на малых объемах выборки.
Парсеры
Интернет – практически безграничное хранилище информации. Найти и обработать необходимые тексты в большом объеме за короткое время человек или даже группа людей не в состоянии. А качественно написанный парсер справляется с такого рода работой эффективно, быстро, и работать он может круглосуточно.
Интернет-магазины – это, в первую очередь, информация о тысячах товарных позиций. Написать вручную все описания сложно, а порой и невозможно физически. Тут на помощь приходит парсер, который найдет нужные описания в Сети. Так, многие интернет-магазины занимаются парсингом цен с интернет-каталогов, чтобы держаться на конкуретном уровне. Агрегаторы новостей работают на основе парсинга, отыскивая нужную информацию, но уже не во всей Сети, а на определенных новостных сайтах. Зачастую парсеры используют в качестве средства для наполнения сайта, отыскивая необходимые информационные материалы.
Наиболее известный пример парсера – это роботы поисковиков, обрабатывающие тексты по определенному принципу и составляющие список ответов на поисковые запросы. Программы для проверки уникальности текста также являются парсерами. Они ищут похожие на проверяемый тексты, и если находят совпадения, дают на них ссылку. Парсеры также могут использоваться и для более узких целей.
Алгоритм, по которому работает парсер:
1. Поиск в Интернете нужных текстов и скачивание их.
2. Обработка текстов.
3. Оформление результатов работы в файл (текстовый, табличный, базы данных и т.п.).
Парсер в основном работает на компьютере, на котором он установлен, не блуждая по просторам Всемирной сети.
В основе парсинга – использование регулярных выражений. Это конструкция, задающая принципы поиска и обработки информации. Парсеры пишутся на языках программирования, в которых предусмотрена возможность обработки строк.
Регулярные выражения, или, как их еще называют на профессиональном сленге, маски, шаблоны, представляют собой набор определенных знаков, позволяющих описать ту информацию, которую необходимо найти. Например, можно задать поиск по определенному слову, по набору слов, по принципу их размещения, по дате и по каким угодно другим параметрам.
Типы корпусов
Существуют различные подходы к классификации корпусов текстов в зависимости от типа текстов, способов их организации, языка и т.д.
С точки зрения их использования лингвистами наиболее значимы следующие виды корпусов:
1) исследовательские – создаются с целью изучения различных аспектов функционирования языка;
2) иллюстративные – служат для выделения в них лингвистических примеров, подтверждающих те или иные языковые факты, обнаруженные иными лингвистическими приемами;
3) статические – содержат тексты какого-то небольшого временного промежутка;
4) в динамические корпуса включают письменные источники большого временного периода, они предназначены для проведения различных диахронических исследований.
Если в корпус включены тексты только на одном языке, то это одноязычный корпус. Существуют также многоязычные корпуса, которые объединяют несколько одноязычных корпусов с приблизительно одинаковой выборкой текстов и репрезентативностью. Также разрабатываются корпуса параллельных текстов: в них включаются тексты с их переводами на другой язык (или языки).
Корпусная лингвистика в России развивается с некоторым отставанием. Первые электронные корпуса РЯ начали появляться не в России, а в Европе. Самым известным из таких корпусов является Упсальский корпус русского языка, созданный в Швеции. Сегодня этот корпус хранится на сервере Тюбингенского университета в Германии.
Национальный корпус русского языка (http://www.ruscorpora.ru/) – общедоступный для поиска электронный онлайновый корпус русских текстов – был создан недавно (2004 г.) и находится в стации разработки.
В Корпус входят как письменные тексты (художественные, мемуары, публицистика, научная, религиозная литература, повседневная печатная продукция), так и записи устных текстов (публичной речи и частных бесед). В корпус также входят подкорпуса поэтических и диалектных текстов, русско-английский, англо-русский и немецко-русский корпуса параллельных текстов, синтаксический, акцентологический и обучающий подкорпуса. Объём Национального корпуса русского языка составляет свыше 70 тыс. текстов общим объемом свыше 150 млн словоупотреблений. На сегодняшний день в корпусе используется четыре типа разметки: метатекстовая, морфологическая, акцентная и семантическая. Поиск можно осуществлять как во всем массиве текстов, так и в текстах, отобранных по определенному критерию (жанр, автор, время написания и др.).
11. Поисковые системы. Контекстный поиск. Язык поискового запроса.
Контекстный поиск
Средства контекстного поиска позволяют искать документы по содержащимся в них словам и фразам, которые могут объединяться логическими операциями. Результаты поиска ранжируются по релевантности (соответствия критерию поиска) на основе частоты встречаемости слов запроса в найденных документах и во всей коллекции в целом.
Для обеспечения высокой скорости поиска по коллекции документов предварительно создается индекс, в котором для каждого слова устанавливаются ссылки на все документы, где это слово встречалось. Дополнительно в индексе хранится информация о положении слова в документе, частоте встречаемости и т.п. Все слова в текстовом индексе могут храниться в нормальной форме, что уменьшает его объем в несколько раз. Дополнительно из индекса устраняются часто встречающиеся стоп-слова, не участвующие в поиске (союзы, предлоги, наречия и т.п.).
В результате учета морфологии (русского и английского языков) находятся документы, содержащие все грамматические формы слов запроса. Использование синтаксического анализатора при индексации документов позволяет снимать морфологическую омонимию в тех случаях, когда различные слова имеют совпадающие грамматические формы. Подключение тезауруса позволяет расширить запрос близкими по смыслу словами, используя разные типы смысловых связей.
Тематический поиск
Возможности тематического поиска опираются на средства автоматического анализа текста и позволяют найти в коллекции документов как документы по заданной теме, так и темы, связанные по смыслу с заданной. Эти возможности могут оказать большую помощь при поиске, например в случае, если пользователь затрудняется точно подобрать ключевые слова, или же, если он хочет сузить область поиска, уточнив тематику, по которой следует искать документы.
Поиск по теме обладает более высокой точностью и полнотой по сравнению с простым контекстным поиском. Так, если контекстный поиск находит все документы, содержащие заданные слова, то тематический поиск возвращает лишь те документы, в которых словам запроса соответствует одна из ключевых тем. Кроме того, он позволяет найти документы, вовсе не содержащие слов из названия заданной темы, однако имеющие к ней отношение.
Эта возможность оказывается полезна, прежде всего, аналитику, ведущему мониторинг событий, связанных с интересующей темой. Она позволяет определить «смысловое окружение» темы в коллекции документов и, уточнив зарос, выбрать требуемую информацию. Например, в ответ на запрос «нефть» можно получить следующий список тем «добыча нефти», «экспорт нефти», «государственная нефтяная компания Азербайджана», «Азербайджан», «Ангарский НХК», «топливные компании», «ЮКОС» и т.д.
Нечеткий поиск
Технология нечеткого поиска позволяет расширять запрос близкими по написанию словами, содержащимися в коллекции документов, по которым ведется поиск. Оригинальный алгоритм способен найти все лексикографически близкие слова, отличающиеся заменами, пропусками и вставками символов.
Нечеткий поиск целесообразно применять при поиске слов с опечатками, а также в тех случаях, когда возникают сомнения в правильном написании фамилии, названия организации и т.п. Например, запрос «Инкомбанк» может быть расширен словами: «инкомбан», «инко-банки», «винкомбанке». А если пользователь забыл точное название медицинского препарата «ипрониазид», то можно задать что-нибудь похожее, например «импронизид», нужные документы будут найдены.
Алгоритмы, используемые при реализации нечеткого поиска, основаны на оригинальной системе ассоциативного доступа к словам, содержащимся в текстовом индексе. В качестве единиц поиска используются цепочки букв, составляющих слово. Для ускорения поиска предварительно создается отдельный индекс, содержащий фрагменты слов со ссылками на слова, в которых эти фрагменты встретились. Таким образом находятся слова, фрагменты которых совпадают с фрагментами слова в запросе. Задавая длину фрагментов и их количество в слове, можно регулировать полноту поиска — отбирать слова по степени близости к запросу.
Поиск по подобию
Поиск документов по подобию позволяет найти документы, близкие по содержанию к заданному. В качестве модели смысла текста при сравнении документов используются семантическая сеть или набор ключевых тем.
Семантическая (смысловая) структура коллекция документов строится с использованием средств автоматического анализа текста и нейросетевых алгоритмов, в частности алгоритмов классификации на основе самоорганизующихся тематических карт, тематических сетей и пр.

Тематическая карта разбита на ряд шестиугольных областей, каждой из которых соответствует множество близких по содержанию документов - тематический класс. При этом близким областям обычно соответствуют близкие классы документов, что является основной особенностью карты. Яркость области пропорциональна количеству отнесенных к ней документов. Встречающиеся на карте названия отражают основные темы документов в соответствующих областях.
Щелкнув мышью по выбранной области, можно просмотреть фрагмент карты в увеличенном масштабе. Для смещения окна увеличения по карте следуют использовать стрелки "компаса", расположенного под картой. Щелчок по центру компаса вызывает возврат к полному виду карты.
Для получения подробной информации об интересующей области достаточно щелкнуть мышью шестиугольник карты. При этом справа от карты отображается список основных тем документов в выбранной области. Снизу под картой представляется список всех документов, относящихся к области, с автоматически построенными рефератами. Щелкнув мышью по названию темы, можно получить список документов по теме из области. Посещенные области карты помечаются голубым цветом.
Такое отображение позволяет наглядно изобразить тематический состав большой коллекции документов в целом (десятки тысяч текстов) и помочь пользователю сориентироваться в океане информации.
Семантическая (тематическая) сеть документов представляется рядом основных тем коллекции с ассоциативными связями между ними. Щелкнув мышью по интересующей теме, можно перейти к следующему фрагменту сети, который содержит темы, наиболее сильно связанные с выбранной. Размер шара, соответствующего теме, пропорционален общему количеству документов по теме. Яркость связи пропорциональная силе ассоциативной связи между парой тем. При этом стрелкой обозначены связи от темы к подтеме.
Для поиска фрагмента семантической сети, относящегося к интересующему запросу, пользователь вводит соответствующие слова в поле формы программного приложения. Яркость окраски шаров, соответствующих найденным темам, пропорциональна релевантности (близости) тем к запросу. Для поиска смысловых цепочек вводятся слова, описывающие пару тем. На рисунке отображается ряд путей, представляющих наиболее сильные связи между заданными темами. Для удобства восприятия на картинке отображается не более двадцати тем, наиболее сильно связанных с введенным запросом или выбранной темой. Программное приложение обеспечивает возможность фильтровать темы, отображаемые на картинке, по частоте встречаемости в документах, фильтровать связи между темами по силе ассоциации в коллекции документов.
В нижней части экрана программного приложения отображается список документов по темам запроса, которые упорядочены по релевантности. Дополнительно на каждый документ выдается его реферат, также построенный автоматически, который содержит наиболее информативный фрагмент (или фрагменты) текста. В зависимости от вида поиска (по запросу или по отдельной теме) реферат может быть общий или тематический. В правом окне дополнительно отображается полный список связанных тем. Щелкнув мышью по выбранной теме в списке, можно получить в нижней части экрана список документов, которые относятся и к темам запроса и к выбранной теме - раскрывают смысловую связь. При этом перемещение по навигатору, сопровождающееся сменой фрагмента семантической сети, не происходит.
Контекстный поиск
Средства контекстного поиска позволяют искать документы по содержащимся в них словам и фразам, которые могут объединяться логическими операциями. Результаты поиска ранжируются по релевантности (соответствия критерию поиска) на основе частоты встречаемости слов запроса в найденных документах и во всей коллекции в целом.
Для обеспечения высокой скорости поиска по коллекции документов предварительно создается индекс, в котором для каждого слова устанавливаются ссылки на все документы, где это слово встречалось. Дополнительно в индексе хранится информация о положении слова в документе, частоте встречаемости и т.п. Все слова в текстовом индексе могут храниться в нормальной форме, что уменьшает его объем в несколько раз. Дополнительно из индекса устраняются часто встречающиеся стоп-слова, не участвующие в поиске (союзы, предлоги, наречия и т.п.).
В результате учета морфологии (русского и английского языков) находятся документы, содержащие все грамматические формы слов запроса. Использование синтаксического анализатора при индексации документов позволяет снимать морфологическую омонимию в тех случаях, когда различные слова имеют совпадающие грамматические формы. Подключение тезауруса позволяет расширить запрос близкими по смыслу словами, используя разные типы смысловых связей.
Введение
Важно отметить, что программный синтез речи, построенный с использованием лингвистически обоснованных алгоритмов и правил, является в то же время моделью функционирования звуковой системы языка.
Вместе с тем понятна и прикладная значимость действующих систем автоматического синтеза речи. В частности, для достижения современного уровня преподавания русского языка как иностранного и иностранных языков русскоязычным студентам необходимо использовать современные компьютерные методы обучения с опорой на естественно звучащий автоматический синтез речи. На основе такого синтеза речи могут быть созданы массовые и достаточно дешевые программы и тренажеры, обучающие чтению, т. е. обеспечивающие одновременное овладение графикой изучаемого языка в соотнесении с произносительными нормами. Кроме того, такие тренажеры могут использоваться для исправления произносительного акцента.
Разработка системы, обеспечивающей естественно-речевое общение человека и ЭВМ, во многом облегчает доступ к компьютерной технике для специалистов гуманитарного профиля, в частности, филологов, работающих с текстами. Возможность естественного озвучивания текстов создает психологически комфортную среду для работы на компьютере.
Автоматический анализ и синтез слитной речи является обязательным компонентом систем искуственного интеллекта и необходимым условием развития информационно-справочных систем, т. к. их потенциальным пользователем становится любой человек, имеющий телефон: он может звонить по телефону, запрашивать информацию в обычной речевой форме, и в такой же форме ее получать.
Практическая потребность в создании такого рода систем весьма велика и в социальной сфере, например, как средство социальной реабилитации слепых и слабовидящих. Создание речевого дисплея в виде так называемого “электронного чтеца” кардинально расширяет возможности обучения и интеллектуального обслуживания людей с такого рода физическими недостатками.
Классификация методов автоматического синтеза речи:
1. Метод непосредственного кодирования речевой волны (дискретизация и сжатие) с последующим ее восстановлением. (Цифровое кодирование — восстановление речи.)
2. Формантный или параметрический синтез. (Синтез по правилам.)
3. Цифровое моделирование голосового тракта или синтез, основанный на принципах линейного прогнозирования (КЛП-синтез).
В общепринятых классификациях не упоминается такой метод синтеза, как компиляция (компилятивный синтез). Этот метод, в отличие от синтеза по правилам, оперирует заранее записанными (оцифрованными) участками речи, но, в отличие от методов кодирования-восстановления, позволяет озвучивать произвольный текст, а не заранее заданный словарь или фразарий.
Синтез речи
Многим из вас наверняка доводилось управлять компьютером или смартфоном с помощью голоса. Когда вы говорите Навигатору «Поехали на Гоголя, 25» или произносите в приложении Яндекс поисковый запрос, технология распознавания речи преобразует ваш голос в текстовую команду. Но есть и обратная задача: превратить текст, который есть в распоряжении компьютера, в голос.
Если набор текстов, которые надо озвучить, относительно невелик и в них встречаются одни и те же выражения — как, например, в объявлениях об отправлении и прибытии поездов на вокзале, — достаточно пригласить диктора, записать в студии нужные слова и фразы, а затем собрать из них сообщение. С произвольными текстами, однако, такой подход не работает. Здесь пригодится технология синтеза речи.
В Яндексе для озвучивания текстов используется технология синтеза речи из комплекса Yandex Speechkit. Она, например, позволяет узнать, как произносятся иностранные слова и фразы в Переводчике. Благодаря синтезу речи собственный голос получил и Автопоэт.
Подготовка текста
Задача синтеза речи решается в несколько этапов. Сначала специальный алгоритм подготавливает текст, чтобы роботу было удобно его читать: записывает все числа словами, разворачивает сокращения. Затем текст делится на фразы, то есть на словосочетания с непрерывной интонацией — для этого компьютер ориентируется на знаки препинания и устойчивые конструкции. Для всех слов составляется фонетическая транскрипция.
тобы понять, как читать слово и где поставить в нём ударение, робот сначала обращается к классическим, составленным вручную словарям, которые встроены в систему. Если в нужного слова в словаре нет, компьютер строит транскрипцию самостоятельно — опираясь на правила, заимствованные из академических справочников. Наконец, если обычных правил оказывается недостаточно — а такое случается, ведь любой живой язык постоянно меняется, — он использует статистические правила. Если слово встречалось в корпусе тренировочных текстов, система запомнит, на какой слог в нём обычно делали ударение дикторы.
Голоса
Наконец, о самом голосе. Узнаваемыми наши голоса, в первую очередь, делает тембр, который зависит от особенностей строения органов речевого аппарата у каждого человека. Тембр вашего голоса можно смоделировать, то есть описать его характеристики — для этого достаточно начитать в студии небольшой корпус текстов. После этого данные о вашем тембре можно использовать при синтезе речи на любом языке, даже таком, которого вы не знаете. Когда роботу нужно что-то сказать вам, он использует генератор звуковых волн — вокодер. В него загружается информация о частотных характеристиках фразы, полученная от акустической модели, а также данные о тембре, который придаёт голосу узнаваемую окраску.
Автоматический синтез
текста (АС), операция, в которой по заданной грамматической и семантической информации строится содержащий эту информацию текст на естественном языке; операция выполняется по некоторому алгоритму в соответствии с заранее разработанным описанием данного языка. Обратная операция называется автоматическим анализом текста. АС подразделяется на три этапа:
- семантический ≈ переход от смысловой записи фразы к её синтаксической структуре;
- синтаксический ≈ переход от синтаксической структуры фразы к представляющей фразу цепочке лексико-грамматических характеристик словоформ;
- лексико-морфологический ≈ переход от лексико-грамматической характеристики к реальной словоформе. АС ≈ необходимый этап в разных видах автоматической обработки текстов, в частности при машинном переводе. АС следует отличать от автоматического порождения текстов, при котором строятся произвольные правильные тексты безотносительно к какому бы то ни было предварительному смысловому заданию.
14. Компьютерный контент-анализ и авторизация текстов. Проект ВААЛ.
Контент-анализ,количественный анализа текстов и текстовых массивов с целью последующей содержательной интерпретации выявленных числовых закономерностей. Основная идея контент-анализа проста и интуитивно наглядна. При восприятии текста и особенно больших текстовых потоков мы достаточно хорошо ощущаем, что разные формальные и содержательные компоненты представлены в них в разной степени, причем эта степень по крайней мере отчасти поддается измерению: ее мерой служит то место, которое они занимают в общем объеме, и/или частота их встречаемости.
Замысел контент-анализа заключается в том, чтобы систематизировать эти интуитивные ощущения, сделать их наглядными и проверяемыми и разработать методику целенаправленного сбора тех текстовых свидетельств, на которых эти ощущения основываются.
При этом предполагается, что вооруженный такой методикой исследователь сможет не просто упорядочить свои ощущения и сделать свои выводы более обоснованными, но даже узнать из текста больше, чем хотел сказать его автор, ибо, скажем, настойчивое повторение в тексте каких-то тем или употребление каких-то характерных формальных элементов или конструкций может не осознаваться автором, но обнаруживает и определенным образом интерпретируется исследователем.
Реально главной отличительной чертой контент-анализа является не его декларируемая во многих определениях «систематичность» и «объективность» (эти черты присущи и другим методам анализа текстов), а его квантитативный характер. Контент-анализ – это прежде всего количественный метод, предполагающий числовую оценку каких-то компонентов текста, могущую дополняться также различными качественными классификациями и выявлением тех или иных структурных закономерностей.
С точки зрения лингвистов и специалистов по информатике, контент-анализ является типичным примером прикладного информационного анализа текста, сводящегося к извлечению из всего разнообразия имеющейся в нем информации каких-то специально интересующих исследователя компонентов и представлению их в удобной для восприятия и последующего анализа форме. Многочисленные конкретные варианты контент-анализа различаются в зависимости от того, каковы эти компоненты и что именно понимается под текстом. Конкретные прикладные цели контент-анализа также варьируют в широких пределах. В их числе – описание тенденций в изменении содержания коммуникативных процессов; описание различий в содержании коммуникативных процессов в различных странах; сравнение различных СМИ; выявление используемых пропагандистских приемов; определение намерений и иных характеристик участников коммуникации; определение психологического состояния индивидов и/или групп; выявление установок, интересов и ценностей (и, шире, систем убеждений и «моделей мира») различных групп населения и общественных институтов; выявление фокусов внимания индивидов, групп и социальных институтов и др.
В 1930–1940-х годах были выполнены исследования, признаваемые ныне классикой контент-анализа, прежде всего работы Г.Лассуэлла, деятельность которого продолжалась и в послевоенные годы. Во время Второй мировой войны имел место самый, пожалуй, знаменитый эпизод в истории контент-анализа – это предсказание британскими аналитиками времени начала использования Германией крылатых ракет «Фау-1» и баллистических ракет «Фау-2» против Великобритании, сделанное на основе анализа (совместно с американцами) внутренних пропагандистских кампаний в Германии. Начиная с 1950-х годов контент-анализ как исследовательский метод активно используется практически во всех науках, так или иначе практикующих анализ текстовых источников – в теории массовой коммуникации, в социологии, политологии, истории и источниковедении, в культурологии, литературоведении, прикладной лингвистике, психологии и психиатрии.
Локальные контент-аналитические проекты периодически реализуются в ходе различного рода социологических мониторингов – общенациональных и региональных. Наиболее широкое распространение контент-анализ получил в теории массовой коммуникации, политологии и социологии.
Существует ряд исследовательских методов – либо специально разработанных для анализа политических текстов (например, метод когнитивного картирования), либо применимых и применяемых для этой цели (например, метод семантического дифференциала или различные подходы, предполагающие изучение структуры текста и механизмов его воздействия), – которые не могут быть сведены к стандартному контент-анализу даже при максимально широком его понимании.
Тем не менее контент-анализ действительно занимает среди аналитических методов особое место в силу того, что является среди них самым технологичным и в силу этого в наибольшей степени подходящим для систематического мониторинга больших информационных потоков. Помимо этого, контент-анализ достаточно гибок для того, чтобы в его рамки мог быть успешно «вписан» весьма разнообразный круг конкретных типов исследований. Наконец, будучи в основе своей количественным методом (хотя и содержащим немалую качественную составляющую), контент-анализ в определенной степени поддается формализации и компьютеризации.
Проект ВААЛ
Система ВААЛ, работа над которой ведется с 1992 года, позволяет прогнозировать эффект неосознаваемого воздействия текстов на массовую аудиторию, анализировать тексты с точки зрения такого воздействия, составлять тексты с заданным вектором воздействия, выявлять личностно-психологические качества авторов текста, проводить углубленный контент-анализ текстов и делать многое другое.
 Области возможного применения
Области возможного применения
· Составление текстов выступлений с заранее заданными характеристиками воздействия на потенциальную аудиторию.
· Активное формирование эмоционального отношения к политическому деятелю со стороны различных социальных групп.
· Составление эмоционально окрашенных рекламных статей.
· Поиск наиболее удачных названий и торговых марок.
· Психо- и гипнотерапия.
· Неявное психологическое тестирование и экспресс-диагностика.
· Создание легких в усвоении учебных материалов.
· Научные исследования в области психолингвистики и смежных с нею дисциплинах.
· Журналистика и другие сферы деятельности, использующие в качестве инструмента СЛОВО.
· Социологические и социолингвистические исследования.
· Информационные войны.
· Контент-анализ текстов.
· Мониторинг СМИ.
Система позволяет
· Оценивать неосознаваемое эмоциональное воздействие фонетической структуры текстов и отдельных слов на подсознание человека.
· Генерировать слова с заданными фоносемантическими характеристиками.
· Оценивать неосознаваемое эмоциональное воздействие фонетической структуры текстов на подсознание человека.
· Задавать характеристики желаемого воздействия и целенаправленно корректировать тексты по выбранным параметрам в целях достижения необходимого эффекта воздействия.
· Оценивать звуко-цветовые характеристики слов и текстов.
· Производить словарный анализ текстов.
· Осуществлять полноценный контент-анализ текста по большому числу специально составленных встроенных категорий и категорий, задаваемых самим пользователем.
· Производить выделение тем, затрагиваемых в текстах, и осуществлять на основе этого автоматическую категоризацию.
· Производить эмоционально-лексический анализ текстов.
· Настраиваться на различные социальные и профессиональные группы людей, которые могут быть выделены по используемой ими лексике.
· Производить вторичный анализ данных путем их визуализации, факторного и корреляционного анализа.
Реализация
Система реализована в виде набора DLL-библиотек, которые подключаются к наиболее популярному текстовому процессору WordforWindows. Просто в главном меню появляется новый пункт. Такой способ реализации позволяет сохранить для пользователя привычную удобную среду создания документов и максимально облегчает освоение системы ВААЛ.
15. Семантические сети. Моделирование семантики слова.
Термин «семантическая сеть" обозначает семейство представлений, основанных на графах. Эти представления отличаются главным образом именами вершин, связей и выводами, которые можно делать в этих структурах.
Под семантической сетью подразумевают систему знаний некоторой предметной области, имеющую определенный смысл в виде целостного образа сети, узлы которой соответствуют понятиям и объектам, а дуги - отношениям между объектами. При построении семантической сети отсутствуют ограничения на число связей и на сложность сети. Для того чтобы формализация оказалась возможной, семантическую сеть необходимо систематизировать.
Базовые структуры в этих моделях знаний могут быть представлены графом, множество вершин и дуг которого образуют сеть. Развитию моделей этого класса в большей степени послужили проблемы алгоритмизации понимания естественного языка. Семантические сети (СС) обычно используют для представления знаний общего характера.
Кроме общих исходных предпосылок различные СС существенно отличаются. Это объясняется тем, что конкретные типы СС разрабатываются для различных целей различных приложений.
Не всякий помеченный сетевой граф можно рассматривать как СС, поскольку семантичность не присуща графу априори. Для того, чтобы приписать графу некоторую семантику, необходимо тщательно определить:
1. Что обозначают вершины и дуги графа.
2. Как их можно использовать при обработке.
Создание СС – это реализация попытки обеспечить интегрированное представление данных, категорий (типов) данных, свойств категорий и операций над данными и категориями. Особенность СС заключается в целостности системы, выполненной на ее основе, т.е. возможности разделить базу знаний и механизм вывода, при этом интерпретация СС реализуется с помощью использующих эту сеть процедур.
При построении семантической сети отсутствуют ограничения на число элементов и связей. Поэтому систематизация отношений между объектами в сети необходима для дальнейшей формализации. Пример семантической сети представлен на рисунке ниже.
Моделирование семантики.
При моделировании семантики предложения прежде всего возникает вопрос о том, что считать смыслом предложения. Однозначного ответа на него в настоящее время не существует. Однако большинство исследователей сходится на том, что смысл предложения представляет собой сложное, многоаспектное образование. В содержании предложения сложнейшим образом сфокусированы характеристики экстралингвистической действительности, ее отражения в сознании человека в виде концептуальных структур, коммуникативных установок участников общения, а также особенности самого языка. При моделировании семантики предложения каждый из названных аспектов может получить статус исходного или даже единственного, если прочие аспекты по каким-либо соображениям не рассматриваются. В зависимости от того, какой исходный аспект кладется в основу моделирования семантики предложения, возможны, в принципе, четыре подхода: онтологоцентрический, концептоцентрический, синтактикоцентрический, антропоцентрический. В рамках каждого из них существует некоторая система воззрений, разработанных с различной степенью детальности. Поэтому важно выявить фундаментальные принципы и постулаты, которыми можно руководствоваться, строя теорию с преимущественной ориентацией на какой-нибудь один аспект.
16. Системы автоматического аннотирования и реферирования.
Рефератомназывают:
· доклад на определенную тему, включающий обзор соответствующих литературных и других источников;
· изложение содержания научной работы, книги и т.д.
Под аннотациейпонимается краткая характеристика произведения печати или рукописи. Обычно аннотация приводится после библиографического описания источника.
Аннотацию от реферата отличают:
· существенно меньший объем;
· обязательная констатация назначения аннотируемого произведения (для каких категорий читателей оно предназначено).
Автоматические реферирование и аннотирование получили значительную актуальность в связи с развитием Internet и каталогов информационных ресурсов. Для экономии времени поиска пользователям предлагаются каталоги аннотаций и рефератов источников.
Формирование рефератов и аннотаций вручную требует колоссальных человеческих ресурсов, поэтому и возникла задача создания методов автоматического реферирования и аннотирования.
Автоматическое реферирование и аннотирование — одно из направлений компьютерной обработки естественно-языковых текстов *. И в этом качестве оно относится к фундаментальным технологиям ИИ.
Основные тенденции для данной области:
· аннотированные каталоги перерастают в гипертекстовые (с их минусами и плюсами);
· на всех крупных сайтах Internet предусматривают оглавления (карта сайта — sitemap) и функции поиска по сайту;
· использование онтологических словарей-тезаурусов общего и специализированного назначения, а также методов ИИ.
Потребности в средствах автоматического реферирования и аннотирования испытывают: корпоративные системы документооборота; поисковые машины и каталоги ресурсов Internet; автоматизированные информационно-библиотечные системы; каналы вещания; службы рассылки новостей и др.
Методы автоматического реферирования и аннотирования подразделяются на поверхностные и глубинные.
Поверхностные методыбазируются на «экстрагировании» текста, т.е. извлечении из него фрагментов, оцениваемых системой как важнейшие, и объединении их в реферат или аннотацию. Важность фрагментов определяется:
· по маркерам важности (оборотам типа «идея ... состоит в...», «главным результатом ... является...», «в заключении нужно сказать, что...» и т.д.);
· по количеству заданных в запросе ключевых слов, входящих во фрагмент, и др.
При объединении выделенных предложений в реферат или аннотацию учитываются их зависимости друг от друга (удаленность выделяемых мыслей). «Стыки» между предложениями (фрагментами) «сглаживаются».
Глубинные методы, развиваемые в настоящее время, базируются на применении тезаурусов и развитых механизмов синтаксического разбора текста.
К традиционным системам автоматического реферирования и аннотирования, реализующим поверхностные методы, можно отнести:
· MicrosoftWord (функция автоматического реферирования);
· ОРФО 5.0 (разработчик — компания «Информатик»), включающую функцию автоматического аннотирования русских текстов;
· «Либретто» (разработчик — компания «МедиаЛингва»), обеспечивающую автоматическое реферирование и аннотирование русских и английских текстов (система встраивается в Word);
· пакет «МедиаЛингваАннотатор SDK 1.0», служащий инструментарием для реализации функций автоматического реферирования и аннотирования в прикладных ИАС;
· поисковую систему «Следопыт», включающую средства автоматического реферирования и аннотирования документов;
· поисковую машину «Золотой Ключик» компании Textar, обеспечивающую составление рефератов и аннотаций;
· IntelligentTextMiner (IBM);
· OracleContext;
· программные компоненты для разработки систем управления знаниями InxightSummarizer фирмы InxightSoftware, Inc.
Перечисленные средства обеспечивают выбор оригинальных фрагментов из исходных документов и соединение их в короткий текст.
Сделаем два замечания. Во-первых, источниками информации для рефератов и аннотаций могут служить не только тексты, но и видеозаписи, разнообразные табличные документы и т.д. Во-вторых, краткое изложение предполагает передачу основной мысли не обязательно теми же словами.
Основные требования к реферату:
· сжатие (объем реферата должен составлять от 5 до 30 % от объема исходного документа);
· возможность использования нескольких источников;
· выражение всех основных мыслей оригинала.
Выделяют три вида рефератов:
1. повествовательные, формирующие общее представление об источнике;
2. информационные, заменяющие источник (содержат основную или новую фактическую информацию);
3. критические (обзоры), отражающие не только суть источника, но и мнение о нем (т.е. содержащие дополнительные выводы, которых нет в оригинале).
Построение реферата человеком включает следующие этапы:
o анализ источника;
o выделение в источнике наиболее важных и информативных фрагментов;
o формирование выводов.
Отметим следующие новые задачи, связанные с компьютерным реферированием.
1. Создание одноязычных рефератов из источников на разных языках.
2. Построение рефератов по гибридным источникам, включающим как текстовые, так и числовые данные в разных формах (таблицы, диаграммы, графики и т. д.).
3. Создание рефератов на основе массивов документов. Например, построение единого реферата по сборнику тезисов докладов научной конференции. Одна из областей применения подобных средств — формирование новостных сообщений по газетным источникам.
4. Растущий объем мультимедийной информации обусловливает актуальность разработки средств ее автоматического реферирования. Методы извлечения семантики из мультимедийной информации находятся на начальных стадиях развития.
Средства автоматического аннотирования в целом аналогичны средствам автоматического реферирования. Однако требования к сжатию текста для них, как правило, на порядок более жесткие.
Обобщенная архитектура систем автоматического реферирования (3 типа):
Первый тип.
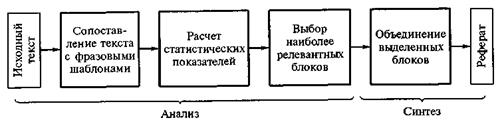
Второй тип.
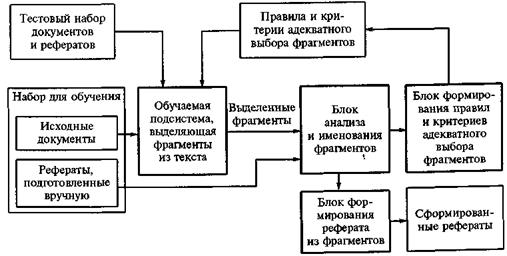
Третий тип.
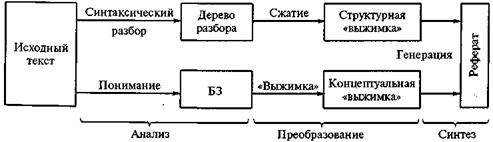
17. Экспертные системы. Системы искусственного интеллекта. Лингвистический аспект искусственного интеллекта.
Понятие и назначение экспертной системы (ЭС).
В начале 80-х годов в исследованиях по искусственному интеллекту сформировалось самостоятельное направление, получившее название "экспертные системы" (ЭС). Основным назначением ЭС является разработка программных средств, которые при решении задач, трудных для человека, получают результаты, не уступающие по качеству и эффективности решения, решениям получаемым человеком-экспертом. ЭС используются для решения так называемых неформализованных задач, общим для которых является то, что:
· задачи не могут быть заданы в числовой форме;
· цели нельзя выразить в терминах точно определённой целевой функции;
· не существует алгоритмического решения задачи;
· если алгоритмическое решение есть, то его нельзя использовать из-за ограниченности ресурсов (время, память).
Кроме того, неформализованные задачи обладают ошибочностью, неполнотой, неоднозначностью и противоречивостью как исходных данных, так и знаний о решаемой задаче.
Экспертная система - это программное средство, использующее экспертные знания для обеспечения высокоэффективного решения неформализованных задач в узкой предметной области. Основу ЭС составляет база знаний (БЗ) о предметной области, которая накапливается в процессе построения и эксплуатации ЭС. Накопление и организация знаний - важнейшее свойство всех ЭС.
Экспертная система — это программное средство, использующее знания экспертов, для высокоэффективного решения задач в интересующей пользователя предметной области. Она называется системой, а не просто программой, так как содержит базу знаний, решатель проблемы и компоненту поддержки. Последняя из них помогает пользователю взаимодействовать с основной программой.
Эксперт — это человек, способный ясно выражать свои мысли и пользующийся репутацией специалиста, умеющего находить правильные решения проблем в конкретной предметной области. Эксперт использует свои приёмы и ухищрения, чтобы сделать поиск решения более эффективным, и ЭС моделирует все его стратегии.
Инженер знаний — человек, как правило, имеющий познания в информатике и искусственном интеллекте и знающий, как надо строить ЭС. Инженер знаний опрашивает экспертов, организует знания, решает, каким образом они должны быть представлены в ЭС, и может помочь программисту в написании программ.
Средство построения ЭС — это программное средство, используемое инженером знаний или программистом для построения ЭС. Этот инструмент отличается от обычных языков программирования тем, что обеспечивает удобные способы представления сложных высокоуровневых понятий.
Пользователь — это человек, который использует уже построенную ЭС. Так, пользователем может быть юрист, использующий для квалификации конкретного случая; студент, которому ЭС помогает изучать информатику и т. д. Термин пользователь несколько неоднозначен. Обычно он обозначает конечного пользователя. Однако из рис.2 следует, что пользователем может быть:
· создатель инструмента, отлаживающий средство построения ЭС;
· инженер знаний, уточняющий существующие в ЭС знания;
· эксперт, добавляющий в систему новые знания;
· клерк, заносящий в систему текущую информацию.
Важно различать инструмент, который используется для построения ЭС, и саму ЭС. Инструмент построения ЭС включает как язык, используемый для доступа к знаниям, содержащимся в системе, и их представления, так и поддерживающие средства – программы, которые помогают пользователям взаимодействовать с компонентой экспертной системы, решающей проблему.
Системы ИИ
Термин искусственный интеллект (ИИ) является русским переводом английского термина artificalintelligence. Создателем ИИ многие ученые считают Алана Тьюринга, автора знаменитой машины Тьюринга, которая стала одним из математических определений алгоритма. В 1950 году в английском журнале “Mind” в статье “ComputingMachineryandIntelligence” (в русском переводе статья называлась «Может ли машина мыслить?») Алан Тьюринг предложил критерий, позволяющий определить, обладает ли машина мыслительными способностями. Этот тест заключается в следующем: человек и машина при помощи записок ведут диалог, а судья (человек), находясь в другом месте, должен определить по запискам, кому они принадлежат, человеку или машине. Если ему это не удается, то это будет означать, что машина успешно прошла тест. До сих пор не одна машина такой тест не прошла.
Не существует единого и общепринятого определения ИИ. Это не удивительно, так как нет универсального определения человеческого интеллекта.
Лингвистический аспект ИИ
Искусственный интеллект самым непосредственным образом связан с развитием компьютерной техники, достигшей поразительных успехов, и, по сути дела, порождён ею.
Сравнительно недавно возникло понятие «система класса искусственного интеллекта», под которым подразумевается система, оперирующая знаниями и извлекающая из них то, что диктуется теми или иными потребностями. Системы класса искусственного интеллекта многообразны, но все они состоят из трёх основных элементов: компьютерной техники, соответствующих программ и знаний. Все 3 составляющие тесно связаны между собой. Исходной же величиной являются знания. (см.: В.А.Звегинцев 2001: 227)
Знания – многомерная величина, но общественно ценные знания, которыми оперируют системы класса искусственного интеллекта, всегда выражаются на языке.
Проблемы языка носят всепроникающий характер, и любая проблема информатики, искусственного интеллекта, экспертных систем имеет языковой аспект, что, к сожалению, не всегда понимается в полной мере. Корень многих недоразумений кроется в неточном определении информационной природы естественного языка. Здесь важно иметь в виду, что язык – это не только форма выражения готовых мыслей, сколько способ содержательной организации и представления знаний. Этот способ первичен, универсален, он возник с самим зарождением человеческого интеллекта и служит надежным инструментом его развития.Эффективное использование знаний, содержащихся в текстах, требует новых стратегий обработки информации, отличных от традиционных логических подходов. Такие стратегии должны учитывать смысловые законы естественного языка. Оперативная, удобная, развивающаяся кооперация человека и машины будет опираться на естественный язык, точнее, на определённый подъязык, связанный с некоторой сферой общения или классом решаемых задач.
Лингвистическое обеспечение автоматизированных систем – это совокупность средств, позволяющих осуществлять компьютеризацию языковой деятельности. Речь, в частности, идет о создании того или иного типа автоматизированной системы обработки текста (АСОТ) – некоторого процессора, на входе и на выходе которого присутствует текстовая информация на естественном языке. Типы АСОТ многообразны и могут быть нацелены на моделирование различных языковых процессоров, таких, например, как диалоговое взаимодействие, сжатие информации, реферирование текста, логическая обработка содержания, перевод на другой естественный язык и т.д. С собственной лингвистической точки зрения процессы, осуществляемые в машине при решении подобных задач, сводятся к перезаписи информации на тех или иных (естественных и искусственных) языках. Внешние критерии, которыми руководствуются создатели АСОТ, подводятся под общую формулу «оптимизация общения человека и машины».
Можно назвать некоторые из наиболее фундаментальных качеств естественного языка:
1) принципиальная нечёткость значения языковых выражений
2) динамичность языковой системы
3) образность номинаций, основанная прежде всего на метафоричности
4) бесконечные творческие возможности в освоении новых знаний
5) семантическая мощь словаря, позволяющая выражать любую информацию с помощью конечного инвентаря элементов
6) гибкость в передаче информации
7) разнообразие функций
8) специфическая системность. (см.: А.А.Реформатский 1996: 310)
В целом естественный язык может быть с полным основанием оценен как сложнейший объект для моделирования.
По мере развития компьютерных систем становится всё более очевидным, что использование этих систем намного расширится, если станет возможным использование человеческой речи при работе непосредственно с компьютером, и, в частности, станет возможным управление машиной обычным голосом в реальном времени, а также ввод и вывод информации в виде обычной человеческой речи. (см.: А.Тьюринг, «Человек и машина»: www.liceum3.info/SCIENCE/i_intel.htm )
Существующие технологии распознавания речи не имеют пока достаточных возможностей для их широкого использования, но на данном этапе исследований проводится интенсивный поиск возможностей употребления коротких многозначных слов (процедур) для облегчения понимания. Распознавание речи в настоящее время нашло реальное применение в жизни, пожалуй, только в тех случаях, когда используемый словарь сокращен до 10 знаков, например при обработке номеров кредитных карт и прочих кодов доступа в базирующихся на компьютерах системах, обрабатывающих передаваемые по телефону данные. Так что насущная задача – распознавание, по крайней мере, 20 тысяч слов естественного языка – остается пока недостижимой. Эти возможности пока недоступны для широкого коммерческого использования. Однако ряд компаний своими силами пытается использовать уже существующие в данной области науки знания.
Для успешного распознавания речи следует решить следующие задачи:
1) обработать словарь (фонемный состав),
2) обработать синтаксис,
3) сократить речь (включая возможное использование жёстких сценариев),
4) выбрать диктора (учитывая возраст, пол, родной язык и диалект),
5) тренировать диктора,
6) разработать особенного вида микрофон (принимая во внимание направленность и местоположение микрофона),
7) разработать условия работы системы и получения результата с указанием ошибок. (см.: В.А.Абидин, «Речевые технологии»: speetech.com/raspoznavanie-rechi/ )
Существующие сегодня системы распознавания речи основываются на сборе всей доступной (порой даже избыточной) информации, необходимой для распознавания слов.
Исследователи считают, что задача распознавания образца речи, основанная на качестве сигнала, подверженного изменениям, будет достаточной для распознавания, но, тем не менее, в настоящее время даже при распознавании небольших сообщений нормальной речи, пока невозможно после получения разнообразных реальных сигналов осуществить прямую трансформацию в лингвистические символы, что является желаемым результатом.
Свойства языкового знака.
Знакомявл. предметы, действия и явления, т.е. любые материальные объекты, кот. могут замещать ту или иную реалию. Знак – это двусторонняя единица, носитель соц-ной инфы. Языковой знак – цепочка фонематически расчленённых звуков – означает и понятие за ним закреплённое – означаемое.
1 тип знаков, копии или изображения (иконический). Этот тип знаков сохраняет сходство с обозначаемыми предметами. 2 тип – знаки, признаки или симптомы (индексальный) – несут информацию о предмете, следствие естественной и причинной связи с ним. 3 тип – знаки сигналов – несут информацию по договорённости. 4 тип – знаки-символы – несут информацию о предмете в отвлечении от предмета каких-либо свойств (напр. Голубь – символ мира).
Языковые знаки распределяются по трём группам:
1. естественные языки (фонетические);
2. искусственные языки (графически письменный язык, ручная речь глухонемых);
3. знаки, сопряжённые с фонетическим языком (интонация, жесты, мимика, паузы).
Своеобразие языкового знаказакл. в том, что это первичный неконвенциональный знак, объективно сформировавший-ся в процессе эволюции чел-а и чел-кого общества вообще. Среди других видов знаков, используемых в чел-ком обществе, языковой знак занимает особое место:
1. своей материальной и идеальной природой;
2. своеобразием своего генезиса, т.е. происхождения, эволюции и функционирования;
3. выполняемыми функциями;
4. формой своего существования или выражения;
5. своей ролью в жизни общества и мн. др. признаками.
Осн. свойства знака вообще и языкового знака в частности.
1. заместительная функция (любой знак что-то означает);
2. коммуникативность (любой знак явл. ср-вом общения);
3. социальность (любые знаки возникают и существуют в обществе);
4. системность (любой З. явл. элементом какой-то системы);
5. материальность (любой знак должен быть доступен чувственному восприятию – чувствовать, видеть, ощущать).
Своеобразие языка как знаковой системызакл. в универ-сальности (языковой З. исп-ся во всех сферах чел-кой деят-ти); первичности по отношению к др. знаковым системам; в посто-янном развитии и совершенстве; в полисемантичности.
Виды знаковых систем
Знаки принято отличать от признаков (симптомов). Последние не являются средствами целенаправленной передачи информации кем-то. В них план выражения (означающее, экспонент) и план содержания (означаемое) находятся в причинно-следственной связи (например, лужи воды на земле как свидетельство недавно прошедшего дождя). В собственно знаках, используемых для целенаправленной передачи информации, связь между двумя сторонами не обусловлена природными, причинно-следственными отношениями, а часто подчинена принципу условности (конвенциональности) или же принципу произвольности (арбитрарности). Возможны, однако, как уже отмечалось, многочисленные случаи той или иной мотивировки знаков, допускаемые данной системой.
Люди пользуются множеством разнообразных знаковых систем, которые можно классифицировать прежде всего с учётом канала связи (среды, в которой осуществляется их передача). Так, можно говорить о знаках звуковых (вокальных, аудитивных), зрительных, тактильных и т.д. Люди располагают, помимо звукового языка как основной коммуникативной системы, жестикуляцией, мимикой, фонационными средствами, представляющими собой особое использование голоса, и т.д. В их распоряжении имеются как естественные (спонтанно возникшие), так и искусственные, созданные ими же коммуникативные системы (письмо; сигнализация с помощью технических устройств и прочих средств: светофор, способы обозначения воинских различий и т.п., системы символов в логике, математике, физике, химии, технике, языки типа эсперанто, языки программирования и т.п.). В некоторых ситуациях общения наблюдается одновременная передача знаков разного рода, использование разных сред (мультимедийная коммуникация).
Классификация
Различают следующие виды искусственных языков:
Языки программирования и компьютерные языки — языки для автоматической обработки информации с помощью ЭВМ.
Информационные языки — языки, используемые в различных системах обработки информации.
Формализованные языки науки — языки, предназначенные для символической записи научных фактов и теорий математики, логики, химии и других наук.
Языки несуществующих народов, созданные в беллетристических или развлекательных целях, например: эльфийский язык, придуманный Дж. Толкином, клингонский язык, придуманный Марком Окрандом для фантастического сериала «StarTrek» (см. Вымышленные языки), язык На'ви, созданный для фильма «Аватар».
Международные вспомогательные языки — языки, создаваемые из элементов естественных языков и предлагаемые в качестве вспомогательного средства межнационального общения.
Идея создания нового языка международного общения зародилась в XVII—XVIII веках в результате постепенного уменьшения международной роли латыни. Первоначально это были преимущественно проекты рационального языка, освобождённого от логических ошибок живых языков и основанного на логической классификации понятий. Позднее появляются проекты по образцу и материалам живых языков. Первым таким проектом был универсалглот, опубликованный в 1868 году в Париже Жаном Пирро. Проект Пирро, предвосхитивший многие детали позднейших проектов, остался незамеченным общественностью.
Следующим проектом международного языка стал волапюк, созданный в 1880 немецким языковедом И. Шлейером. Он вызвал весьма большой резонанс в обществе.
Наиболее известным искусственным языком стал эсперанто (Л. Заменгоф, 1887) — единственный искусственный язык, получивший широкое распространение и объединивший вокруг себя довольно многих сторонников международного языка.
Из искусственных языков наиболее известны:
бейсик-инглиш
эсперанто
Макатон
волапюк
идо
интерлингва
латино-сине-флексионе
логлан
ложбан
на'ви
новиаль
окциденталь
сольресоль
ифкуиль
клингонский язык
эльфийские языки
Также есть языки, которые специально были разработаны для общения с внеземным разумом. Например — линкос.
По цели создания искусственные языки можно разделить на следующие группы:
Философские и логические языки — языки, имеющие четкую логическую структуру словообразования и синтаксиса: ложбан, токипона, ифкуиль, илакш.
Вспомогательные языки — предназначены для практического общения: эсперанто, интерлингва, словио, словянски.
Артистические или эстетические языки — создаются для творческого и эстетического удовольствия: квенья.
Также язык создается для постановки эксперимента, например для проверки гипотезы Сепира-Уорфа (о том, что язык, на котором говорит человек, ограничивает сознание, загоняет его в определённые рамки).
По своей структуре проекты искусственного языка могут быть разделены на следующие группы:
Априорные языки — на основе логических или эмпирических классификаций понятий: логлан, ложбан, ро, сольресоль, ифкуиль, илакш.
Апостериорные языки — языки, построенные преимущественно на основе интернациональной лексики: интерлингва, окциденталь
Смешанные языки — слова и словообразование частично заимствованы из неискусственных языков, частично созданы на основе искусственно придуманных слов и словообразовательных элементов: волапюк, идо, эсперанто, нэо.
Число носителей искусственных языков можно назвать лишь приблизительно, ввиду того что систематического учета носителей не ведётся.
По степени практического употребления искусственные языки делят на проекты, получившие широкое распространение: идо, интерлингва, эсперанто. Такие языки, как и национальные языки, называют «социализованными», среди искусственных их объединяют под термином плановые языки. Промежуточное положение занимают такие проекты искусственного языка, которые имеют некоторое количество сторонников, например, логлан (и его потомок ложбан), словио и другие. Большинство искусственных языков имеет единственного носителя — автора языка (по этой причине их более корректно называть «лингвопроектами», а не языками).
20. Нейронная сеть и размытая логика (fuzzylogic). Их преимущества в обработке языковой информации.
Нейронные сети – это одно из направлений исследований в области искусственного интеллекта, основанное на попытках воспроизвести нервную систему человека. А именно: способность нервной системы обучаться и исправлять ошибки, что должно позволить смоделировать, хотя и достаточно грубо, работу человеческого мозга.
В 60-80 годах XX века приоритетным направлением исследований в области искусственного интеллекта были экспертные системы. Экспертные системы хорошо себя зарекомендовали, но только в узкоспециализированных областях. Для создания более универсальных интеллектуальных систем требовался другой подход. Наверное, это привело к тому, что исследователи искусственного интеллекта обратили внимание на биологические нейронные сети, которые лежат в основе человеческого мозга.
Нейронные сети в искусственном интеллекте – это упрощенные модели биологических нейронных сетей.
На этом сходство заканчивается. Структура человеческого мозга гораздо более сложная, чем описанная выше, и поэтому воспроизвести ее хотя бы более менее точно не представляется возможным.
У нейронных сетей много важных свойств, но ключевое из них – это способность к обучению. Обучение нейронной сети в первую очередь заключается в изменении «силы» синаптических связей между нейронами. Следующий пример наглядно это демонстрирует. В классическом опыте Павлова, каждый раз непосредственно перед кормлением собаки звонил колокольчик. Собака достаточно быстро научилась ассоциировать звонок колокольчика с приемом пищи. Это явилось следствием того, что синаптические связи между участками головного мозга, ответственными за слух и слюнные железы, усилились. И в последующем возбуждение нейронной сети звуком колокольчика, стало приводить к более сильному слюноотделению у собаки.
На сегодняшний день нейронные сети являются одним из приоритетных направлений исследований в области искусственного интеллекта.
Построение моделей приближенных размышлений человека и использование их в компьютерных системах представляет сегодня одну из важнейших проблем науки.
Основы нечеткой логики были заложены в конце 60-х лет в работах известного американского математика Латфи Заде. Исследования такого рода было вызвано возрастающим неудовольствием экспертными системами. Хваленый "искусственный интеллект", который легко справлялся с задачами управления сложными техническими комплексами, был беспомощным при простейших высказываниях повседневной жизни, типа "Если в машине перед тобой силит неопытный водитель - держись от нее подальше". Для создания действительно интеллектуальных систем, способных адекватно взаимодействовать с человеком, был необходим новый математический аппарат, который переводит неоднозначные жизненные утверждения в язык четких и формальных математических формул. Первым серьезным шагом в этом направлении стала теория нечетких множеств, разработанная Заде. Его работа "FuzzySets", опубликованная в 1965 году в журнале "InformationandControl", заложила основы моделирования интеллектуальной деятельности человека и стала начальным толчком к развитию новой математической теории. Он же дал и название для новой области науки - "fuzzylogic" (fuzzy - нечеткий, размытый, мягкий).
Чтобы стать классиком, надо немного опередить свое время. Существует легенда о том, каким образом была создана теория "нечетких множеств". Один раз Заде имел длинную дискуссию со своим другом относительно того, чья из жен более привлекательна. Термин "привлекательная" является неопределенным и в результате дискуссии они не смогли прийти к удовлетворительному итогу. Это заставило Загде сформулировать концепцию, которая выражает нечеткие понятия типа "привлекательная" в числовой форме.
Дальнейшие работы профессора Латфи Заде и его последователей заложили фундамент новой теории и создали предпосылки для внедрения методов нечеткого управления в инженерную практику.
Аппарат теории нечетких множеств, продемонстрировав ряд многообещающих возможностей применения - от систем управления летательными аппаратами до прогнозирования итогов выборов, оказался вместе с тем сложным для воплощения. Учитывая имеющийся уровень технологии, нечеткая логика заняла свое место среди других специальных научных дисциплин - где-то посредине между экспертными системами и нейронными сетями.
Свое второе рождение теория нечеткой логики пережила в начале восьмидесятых годов, когда несколько групп исследователей (в-основном в США и Япони) всерьез занялись созданием электронных систем различного применения, использующих нечеткие управляющие алгоритмы. Теоретические основы для этого были заложены в ранних работах Коско и других ученых.
Третий период начался с конца 80-х годов и до сих пор. Этот период характеризуется бумом практического применения теории нечеткой логики в разных сферах науки и техники. До 90-ого года появилось около 40 патентов, относящихся к нечеткой логике (30 - японских). Сорок восемь японских компаний создают лабораторию LIFE (LaboratoryforInternationalFuzzyEngineering), японское правительство финансирует 5-летнюю программу по нечеткой логике, которая включает 19 разных проектов - от систем оценки глобального загрязнения атмосферы и предвидения землетрясений до АСУ заводских цехов. Результатом выполнения этой программы было появление целого ряда новых массовых микрочипов, базирующихся на нечеткой логике. Сегодня их можно найти в стиральных машинах и видеокамерах, цехах заводов и моторных отсеках автомобилей, в системах управления складскими роботами и боевыми вертолетами.
В США развитие нечеткой логики идет по пути создания систем для большого бизнеса и военных. Нечеткая логика применяется при анализе новых рынков, биржевой игре, оценки политических рейтингов, выборе оптимальной ценовой стратегии и т.п. Появились и коммерческие системы массового применения.
Смещение центра исследований нечетких систем в сторону практических применений привело к постановке целого ряда проблем, в частности:
· новые архитектуры компьютеров для нечетких вычислений;
· элементная база нечетких компьютеров и контроллеров;
· инструментальные средства разработки;
· инженерные методы расчета и разработки нечетких систем управления, и т.п..
Нейронечеткие или гибридные системы, включающие в себя нечеткую логику, нейронные сети, генетические алгоритмы и экспертные системы, являются эффективным средством при решении большого круга задач реального, мира.
Каждый интеллектуальный метод обладает своими индивидуальными особенностями (например, возможностью к обучению, способностью объяснения решений), которые делают его пригодным только для решения конкретных специфических задач.
Например, нейронные сети успешно применяются в распознавании моделей, они неэффективны в объяснении способов достижения своих решений.
Системы нечеткой логики, которые связаны с неточной информацией, устно применяются при объяснении своих решений, но не могут автоматически пополнять систему правил, которые необходимы для принятия этих решений.
Эти ограничения послужили толчком для создания интеллектуальных гибридных систем, где два или более методов объединяются для того, чтобы преодолеть ограничения каждого метода в отдельности.
Гибридные системы играют важную роль при решении задач в различных приикладных областях. Во многих сложных областях существуют проблемы, связанные с отдельными компонентами, каждый из которых может требовать своих методов обработки.
Пусть в сложной прикладной области имеется две отдельные подзадачи, например задача обработки сигнала и задача вывода решения, тогда нейронная сеть и экспертная система будут использованы соответственно для ре этих отдельных задач.
Интеллектуальные гибридные системы успешно применяются во многих областях, таких как управление, техническое проектирование, торговля, о кредита, медицинская диагностика и когнитивное моделирование. Кроме того, диапазон приложения данных систем непрерывно растет.
В то время, как нечеткая логика обеспечивает механизм логического вывода из когнитивной неопределенности, вычислительные нейронные сети обладают такими заметными преимуществами, как обучение, адаптация, отказоустойчивость, параллелизм и обобщение.
Для того чтобы система могла обрабатывать когнитивные неопределенности так, как это делают люди, нужно применить концепцию нечеткой логики в нейронных сетях. Такие гибридные системы называются нечеткими нейронными или нечетко-нейронными сетями.
Нейронные сети используются для настройки функций принадлежи нечетких системах, которые применяются в качестве систем принятия решений.
Нечеткая логика может описывать научные знания напрямую, используя правила лингвистических меток, однако много времени обычно занимает процесс проектирования и настройки функций принадлежности, которые определяют эти метки.
Обучающие методы нейронных сетей автоматизируют этот процесс, существенно сокращая время разработки и затраты на получение данных функций.
Теоретически нейронные сети и системы нечеткой логики равноценны, поскольку они взаимно трансформируемы, тем не менее на практике каждая из них имеет свои преимущества и недостатки.
В нейронных сетях знания автоматически приобретаются за счет применения алгоритма вывода с обратным ходом, но процесс обучения выполняется относительно медленно, а анализ обученной сети сложен ("черный ящик").
Невозможно извлечь структурированные знания (правила) из обученной нейронной сети, а также собрать особую информацию о проблеме для того, чтобы упростить процедуру обучения.
Нечеткие системы находят большое применение, поскольку их поведение может быть описано с помощью правил нечеткой логики, таким образом, можно управлять, регулируя эти правила. Следует отметить, что приобретение знаний — процесс достаточно сложный, при этом область измене каждого входного параметра необходимо разбивать на несколько интервалов; применение систем нечеткой логики ограничено областями, в которых допустимы знания эксперта и набор входных параметров достаточно мал.
Для решения проблемы приобретения знаний нейронные сети дополняются свойством автоматического получения правил нечеткой логики из числовых данных.
Вычислительный процесс представляет собой использование следующих нечетких нейронных сетей. Процесс начинается с разработки "нечеткого нейрона", который основан на распознавании биологических нейронных морфологии согласно механизму обучения. При этом можно выделить следующие три этапа вычислительного процесса нечеткой нейронной сети:
· разработка нечетких нейронных моделей на основе биологических нейронов;
· модели синоптических соединений, которые вносят неопределенность в нейронные сети;
· разработка алгоритмов обучения (метод регулирования синоптических весовых коэффициентов)
Настольные издательские ситсемы
связи с широким распространением в последние годы мультимедийных и сетевых компьютерных технологий издательское дело вышло на новый уровень своего развития. Появились настольные издательские системы(НИС) – специализированные программно-аппаратные комплексы, предназначенные для подготовки оригинал-макетов печатной продукции. При этом осуществляется верстка (оформление и размещение) подготовленного к публикации материала.
Основным отличием НИС от текстовых редакторов и процессоров является то, что они предназначены в первую очередь для оформления документа, а не для ввода текста и проверки правописания, хотя в определенной степени могут выполнять и эти функции. НИС не предполагает создания исходных материалов для печати, для этого удобнее использовать текстовые процессоры для набора текста и графические пакеты для создания иллюстраций.
НИС работают только в графическом режиме. Необходимым требованием их работы является соответствие изображения на экране реальному результату (WYSIWYG—WhatYouSeeIsWhatYouGet –что видите, то и получаете).
Верстка различных типов документов обладает спецификой, для учета которой предпочтительно использовать соответствующие НИС. Наиболее распространенными сейчас являются следующие системы:
· Adobe PageMaker— популярная программа с многочисленными функциями, позволяющая удобно работать с журнальными и газетными многостраничными публикациями. Программа содержит большое количество функций по оформлению публикаций, многие полезные функции добавлены в этот пакет с помощью дополнительных утилит (вспомогательных программ);
· Corel Ventura— программа, которая была одной из первых НИС. Она ориентируется на создание книг, брошюр, журналов и других больших многостраничных публикаций. Программа обладает большими возможностями по размещению и оформлению текста. Последняя версия программы распространяется с пакетомCorelDraw, элементы которого позволяют создать высококачественные иллюстрации;
· QuarkXPress— НИС для профессиональной работы. Включает большое количество функций по оформлению публикации любой сложности и содержания. Разнообразные возможности позволяют реализовать любые проекты по дизайну. Она также имеет дополнительные утилиты, расширяющие возможности программы;
· FrameMaker— НИС, наиболее удобная для работы с большими публикациями, которые имеют сложную структуру, например технические публикации. В программе можно работать с различными иллюстрациями, а также легко оформлять таблицы и формулы, но программа имеет ограниченные функциональные возможности по сравнению сCorel Ventura;
· Microsoft Publisher— эта НИС содержит достаточный для оформления публикации набор функций. Она удобна для начинающих пользователей простой инсталляцией и средствами, облегчающими процесс создания публикаций (PageWizard).
Поскольку НИС предназначена для работ, связанных с полиграфией, ее использование предполагает знание пользователем правил оформления публикаций.
Дата: 2019-03-06, просмотров: 931.