Обработка SQL-запроса, поступившего серверу MSS, проходит в несколько этапов: разбор, разрешение имен, оптимизация, компиляция и выполнение (рис. 11.1).

Рис. 11.1. Этапы обработки SQL-запроса
Обработка любого SQL-запроса начинается с синтаксического разбора текста запроса для проверки его на соответствие правилам языка. На этапе разрешения имен осуществляется проверка наличия (возможность доступа) используемых в запросе объектов БД (таблиц, столбцов таблиц, пользовательских и встроенных функций и пр.).
Запрос, прошедший этапы разбора и разрешения имен, поступает на обработку специальной компоненте сервера, называемой оптимизатором. Основная задача оптимизатора – построение плана запроса. План запроса представляет собой алгоритм выполнения SQL-запроса. На каждом шаге алгоритма выполняется элементарное действие сервера СУБД. План любого запроса может быть получен с помощью MSMS. На рис. 11.2 представлен пример графического изображения плана запроса, полученного с помощью MSMS.

Рис. 11.2. Графическое представление плана запроса
При построении плана запроса для каждого шага вычисляется числовая величина, пропорциональная продолжительности выполнения шага, называемая стоимостью. Суммарная стоимость шагов плана составляет стоимость всего запроса и, соответственно, является величиной, пропорциональной продолжительности выполнения запроса. На рис. 11.2 показано процентное распределение стоимости запроса (Cost) по шагам плана запроса.
Критерием оптимизации при построении плана является минимизация общей стоимости запроса. Оптимизатор, формирующий план запроса, учитывает статистику, собираемую сервером СУБД, а также наличие специальных объектов БД, предназначенных для ускорения выполнения запросов и называемых индексами.
После построения плана запроса осуществляется его компиляция. Откомпилированный запрос (точнее план запроса), помещается в специальную область памяти, называемую библиотечным кэшем. Кэш потом используется для ускорения выполнения будущих аналогичных запросов. Откомпилированный план выполняется (точнее интерпретируется) сервером СУБД.
Индекс – это объект БД, позволяющий ускорить поиск в определенной таблице. Для получения данных из таблицы наличие индексов не является обязательным. Если нет подходящего индекса, оптимизатор запланирует простой последовательный перебор всех строк таблицы (говорят «просканирует таблицу») для поиска необходимых данных. Иначе говоря, если индекс не позволяет ускорить процесс поиска данных – он является бесполезным.
Как и любой другой объект базы данных, индекс может быть создан с помощью DDL-оператора CREATE, модифицирован с помощью ALTER и удален с помощью оператора DROP. Для одной таблицы может быть построено несколько индексов.
Разработчик SQL-запросов, не выходящий за рамки стандартного SQL, никак непосредственно не может повлиять на процесс формирования оптимизатором плана запроса. Однако существуют специальные средства, выходящие за рамки стандартного языка SQL, позволяющие «подсказать» оптимизатору о необходимости применения индекса. В русскоязычной литературе сложился термин «хинт» (от англ. hint – подсказка) для обозначения инструкций-подсказок, позволяющих повлиять на работу оптимизатора. Применение хинтов выходит за рамки этого пособия, с их перечнем и принципами применения можно ознакомиться в издании [5].
Структура, используемая MSS для хранения индексов в БД, представляет собой сбалансированное дерево, узлами которого являются страницы – стандартные блоки данных размером 8К, используемые MSS для хранения информации. Более подробно с внутренней организацией индексов можно ознакомиться в пособии [3].
MSS поддерживает несколько типов индексов: кластеризованные и некластеризованные индексы, уникальные и неуникальные, XML-индексы, пространственные индексы, а также полнотекстовые индексы.
Пространственные индексы и полнотекстовые индексы в этом пособии не рассматриваются. Для знакомства с этими типами индексов рекомендуется изучить пособия [3, 5].
Индексы XML будут рассматриваться позже в главе, посвященной применению XML в БД MSS.
Наиболее часто применяются кластеризованные и некластеризованные индексы, которые могут быть уникальными и неуникальными.
Кластеризованные индексы
Обычно кластеризованные индексы формируются автоматически при создании таблицы. Дело в том, что наличие первичного ключа (ограничение PRIMARY KEY) в таблице БД влечет автоматическое создание индекса при создании таблицы. Если при этом в свойствах столбца первичного ключа специально не указано ключевое слово NONCLUSTERED, то автоматически создастся кластеризованный индекс.
С помощью системной процедуры SP_HELPINDEX можно получить перечень индексов, связанных с заданной (параметр процедуры) таблицей. Сценарий, представленный на рис. 11.3, демонстрирует вызов процедуры SP_HELPINDEX, формирующей перечень индексов, связанных с таблицей TEACHER.
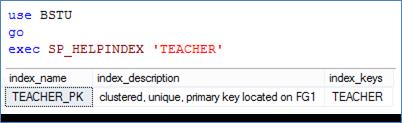
Рис. 11.3. Применение системной процедуры SP_HELPINDEX
для получения перечня индексов, связанных с таблицей TEACHER
Каждая строка результирующего набора, сформированного процедурой SP_HELPINDEX, соответствует одному индексу. В столбце index_ name содержатся имена индексов (на рис. 11.3 – TEACHER_ PK), в столбце index_ description – описание индексов (кластеризованный, уникальный, созданный для первичного ключа, расположен в файловой группе FG1), в столбце index_ keys перечислены имена столбцов (TEACHER) таблицы, по значениям которых осуществляется построение соответствующего индекса (говорят «индексируемые столбцы»).
Основной особенностью кластеризованного индекса является то, что при его построении таблица становится частью индекса. Другими словами, строки таблиц, имеющих кластеризованные индексы, физически упорядочены в соответствии со значениями индексируемых столбцов. В связи с этим в таблице может быть только один кластеризованный индекс. На рис. 11.4 представлен сценарий, состоящий из трех пакетов (пакет – группа операторов T-SQL, завершающаяся оператором GO). В первом пакете создается временная таблица # EXPLORE. Операторы второго пакета добавляют в созданную таблицу 10 000 строк. При этом в столбец TKEY с помощью встроенной функции RAND вводится случайное числовое значение. Наконец, третий пакет выводит количество строк в таблице # EXPLORE.
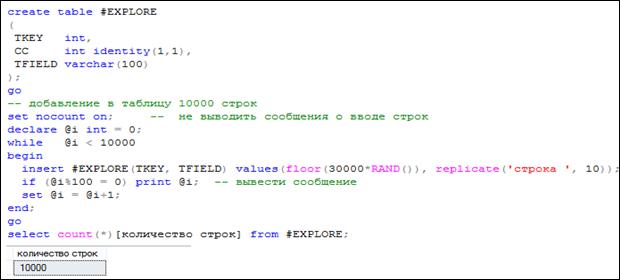
Рис. 11.4. Создание временной таблицы # EXPLORE и добавление в нее 10 000 строк
Заметим: таблица # EXPLORE не имеет индексов. Поэтому SELECT-запрос, выполняющий поиск и сортировку строк, с заданным диапазоном значений столбца TKEY (рис. 11.5), приводит к полному сканированию таблицы (компонент Table Scan плана запроса) # EXPLORE и последующей сортировке (компонент Sort). Общая стоимость запроса (Estimate Subtree Cost) составляет 0,174. При этом на сканирование таблицы пришлось 58% стоимости, на сортировку – 42%.
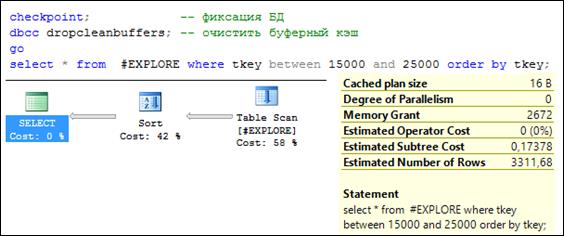
Рис. 11.5. План SELECT-запроса к таблице, не имеющей кластерного индекса
Кратко поясним назначение пакета (рис. 11.5), предшествующего исследуемому оператору SELECT.
Оператор CHECKPOINT языка T-SQL позволяет записать образы страниц из буферного кэша в файлы БД. Сразу после выполнения этого оператора все образы страниц, расположенные в буферном кэше сервера, и соответствующие им оригинальные страницы в файлах БД совпадают.
Оператор DBCC DROPCLEANBUFFER позволяет очистить буферный кэш. Сразу после выполнения этого оператора буферный кэш не содержит никаких образов страниц, и поэтому следующая DML-операция приведет в физическому чтению страниц из файлов БД.
Совместное применение этих двух операторов позволяет устранить эффект, возникающий из-за кэширования страниц, что позволяет более объективно сравнивать время (если оно измеряется) выполнения нескольких запросов. Отметим при этом, что очистка буферного кэша никак не влияет на величину стоимости запроса.
В сценарии на рис. 11.6 создается кластерный индекс (второй пакет) с именем # EXPLORE_ CLU по столбцу TKEY таблицы # EXPLORE. Ключевое слова ASC (по возрастанию) указывает порядок, в котором строится индекс. В третьем пакете сценария выполняется SELECT-запрос, аналогичный запросу на рис. 11.5.
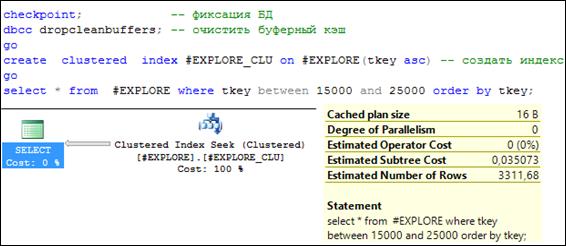
Рис. 11.6. Актуальный план запроса к таблице, имеющей кластерный индекс
План запроса, представленный на рис. 11.6, существенно отличается от плана аналогичного запроса, показанного на рис. 11.5. Во-первых, сканирование осуществляется не по всей таблице, а по части кластеризованного индекса (компонент Clustered Index Seek). Во-вторых, отсутствует компонент сортировки. При этом стоимость запроса (Estimate Subtree Cost) составляет 0,035, что почти в 5 раз меньше, чем при запросе к таблице, не имеющей индекса.
Пятикратное повышение скорости выполнения запроса достигается за счет следующего.
1. Выбор строк таблицы # EXPLORE по диапазону значений столбца TKEY не требует сканирования всей таблицы. Индекс по столбцу TKEY позволяет серверу сразу позиционироваться на первую строку выбираемой группы строк и сканировать только строки, соответствующие заданному диапазону.
2. Строки таблицы # EXPLORE уже расположены в порядке возрастания значений столбца TKEY, так как она сама является частью индекса. Поэтому сортировка не требуется.
Заметим, что, если бы в SELECT-запросе на рис. 11.6 результат сортировался в порядке убывания значений столбца TKEY, то бы план запроса и его стоимость (и соответственно время выполнения) не изменились. Просто вывод строк в результирующий набор будет осуществляться в обратном порядке.
Обратим внимание, что в индексируемом столбце TKEY таблицы # EXPLORE допускаются повторения. Соответственно индекс # EXPLORE_ CLU (рис. 11.6) допускает повторение значений индексного ключа (комбинации значений индексируемых столбцов). Такие индексы называются неуникальными.
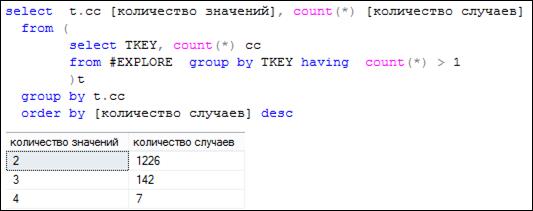
Рис. 11.7. Значения в индексируемом столбце TKEY
не являются уникальными
В сценарии на рис. 11.8 удаляется неуникальный кластерный индекс # EXPLORE_ CLU и создается уникальный индекс # EXPLORE_ UNIQ_ CLU. При этом возникает ошибка, сообщение о которой приводится на рис. 11.8. Ошибка возникла из-за того, что при создании уникального индекса в индексируемом столбце были обнаружены дубликаты значений.
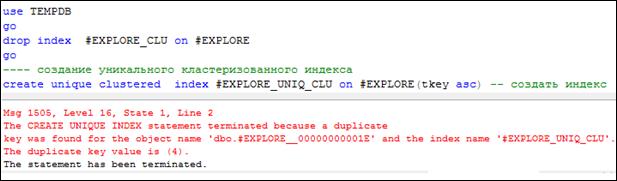
Рис. 11.8. Ошибка при создании уникального индекса над столбцом таблицы
с повторяющимися значениями
Создание уникального индекса по столбцу CC, содержащего только уникальные значения (столбец обладает свойством IDENTITY), завершается успешно (рис. 11.9).
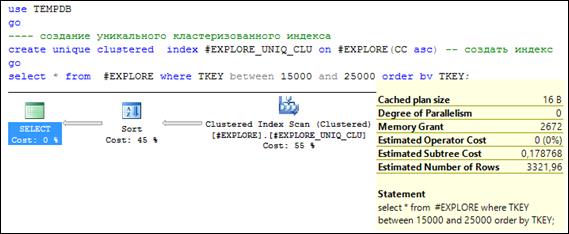
Рис. 11.9. Создание уникального кластерного индекса # EXPLORE_ UNIQ_ CLU
над столбцом СС таблицы # EXPLORE
Обратите внимание на план SELECT-запроса в сценарии на рис. 11.9. Он отличается от плана на рис. 11.6 и похож на план запроса к таблице без индексов (рис. 11.5). При этом во всех трех случаях выполняется один и тот же SELECT-запрос. В соответствии планом (рис. 11.9) выполнение запроса будет осуществляться в два этапа: сначала полное сканирование кластерного индекса # EXPLORE_ UNIQ_ CLU (напомним: кластерный индекс – это и есть таблица) для выбора значений соответствующих WHERE-условию, а затем выполняется сортировка выбранных строк. Заметьте, что стоимость запроса примерно такая же, как и в запросе к неиндексированной таблице (рис. 11.5).
В запросе на рис. 11.10 сортировка выполняется по значениям индексируемого столбца CC. Сравнив этот запрос с планом запроса на рис. 11.9, заметим, что операции сортировки нет. Она не требуется, так как строки таблицы # EXPLORE являются частью кластерного индекса # EXPLORE_ UNIQ_ CLU и уже находятся в требуемом порядке. Обратите внимание: стоимость запроса значительно снизилась и вся сосредоточена на операции сканирования кластерного индекса.
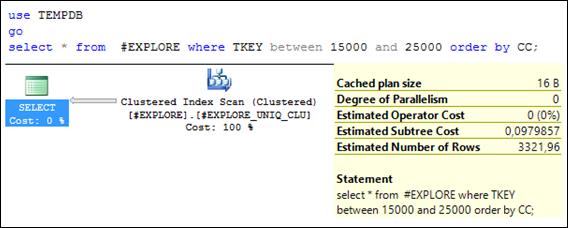
Рис. 11.10. SELECT-запрос, сортирующий результат запроса
по значениям индексируемого столбца
Если изменить WHERE-условие таким образом, чтобы фильтрация строк осуществлялась по значениям индексируемого столбца (рис. 11.11), то план становится похожим на план запроса, представленного на рис. 11.6. Кроме того, обратите внимание, что стоимость запроса тоже снизилась.
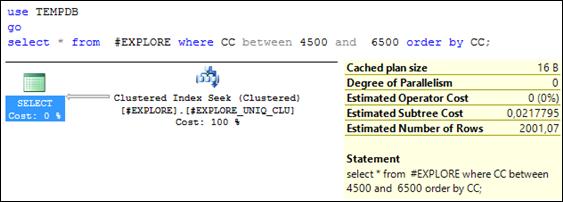
Рис. 11.11. SELECT-запрос, фильтрующий и сортирующий строки
по значениям индексируемого столбца
Еще раз напомним, что по умолчанию для таблицы БД со столбцом, имеющим свойство PRIMARY KEY (ограничение целостности – первичный ключ), при создании таблицы автоматически создается кластеризованный уникальный индекс.
Некластеризованные индексы
Некластеризованные индексы в отличие от кластеризованных никак не влияют на физический порядок строк в таблице. Как и в случае кластеризованных индексов, данные индекса организованы в виде сбалансированного дерева. С таблицей некластеризованный индекс связан указателями на ее строки. Для одной таблицы БД допускается создавать до 1023 некластеризованных индексов.
Индексы, соответствующие ограничению PRIMARY KEY, не обязательно должны быть кластеризованными. На рис. 11.12 представлен пример создания таблицы TEACHER, имеющей столбец со свойством PRIMARY KEY и соответствующим некластеризованным индексом.
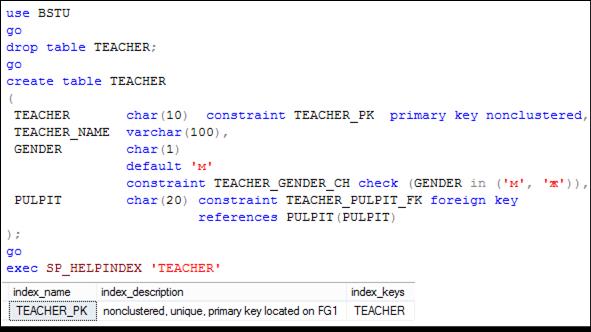
Рис. 11.12. Создание таблицы TEACHER со столбцом TEACHER, являющимся
первичным ключом с соответствующим ему некластеризованным индексом
Во всех приводимых до сих пор примерах использовались индексы, созданные по одному столбцу таблицы. Такие индексы называются простыми. MSS допускает создавать индексы по нескольким столбцам – такие индексы называются составными. Составными могут быть кластеризованные и некластеризованные индексы. Например, составному первичному ключу по умолчанию соответствует составной кластерный индекс.
На рис. 11.13 приведен пример создания составного неуникального, некластеризованного индекса # EXPLORE_ CX по двум столбцам TKEY и CC таблицы # EXPLORE (рис. 11.4).
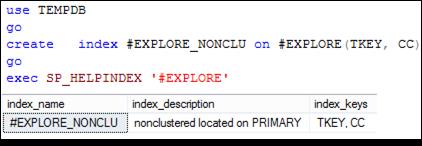
Рис. 11.13. Создание составного некластеризованного индекса с именем
# EXPLORE_ NONCLU по столбцам TKEY и CC таблицы # EXPLORE
Обратите внимание на то, что некластеризованный составной индекс не применяется оптимизатором ни при фильтрации (рис. 11.14), ни при сортировке (рис. 11.15) строк таблицы # EXPLORE. В обоих случаях осуществляется сканирование всей таблицы (на плане – Table Scan).
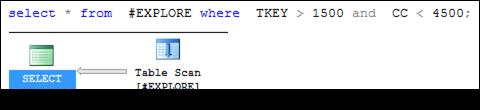
Рис. 11.14. Составной некластеризованный индекс # EXPLORE_ NONCLU,
неиспользуемый при фильтрации по индексируемым столбцам
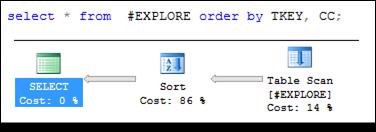
Рис. 11.15. Составной некластеризованный индекс # EXPLORE_ NONCLU,
неиспользуемый при сортировке по индексируемым столбцам
Но если хотя бы одно из индексируемых значений зафиксировать (задать одно значение), то оптимизатор применит индекс (рис. 11.16, 11.17).
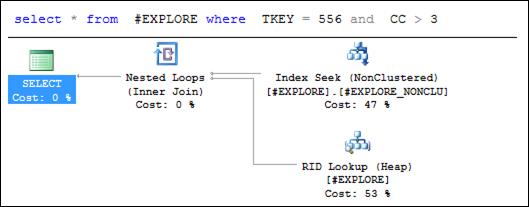
Рис. 11.16. Применение индекса при выполнении запроса (при фиксации в секции WHERE значения индексируемого столбца TKEY
составного индекса # EXPLORE_ NONCLU)
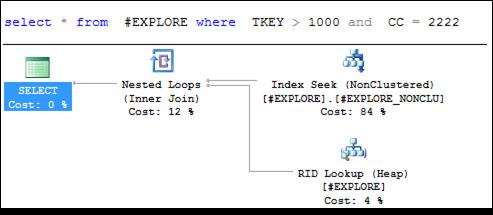
Рис. 11.17. Применение индекса при выполнении запроса (при фиксации в секции WHERE значения индексируемого столбца СС составного индекса # EXPLORE_ NONCLU)
Планы запросов на рис. 11.16 и 11.17 содержат по три компонента. Выполнение запроса начинается с позиционирования (установка текущего указателя на первую строку в группе отобранных строк индекса) в индексе # EXPLORE_ NONCLU (на плане – Index Seek) и считывание данных из хранилища строк (Heap) с помощью указателя на строку таблицы (RID Lookup). На втором этапе считанные данные из индекса и хранилища строк объединяются (Inner Join).
На рис. 11.18 демонстрируется запрос, аналогичный запросу, представленному на рис. 11.16, но в результирующий набор выводится только два столбца TKEY и CC. Обратите внимание: TKEY и CC – индексируемые столбцы (рис. 11.13).
Если в SELECT-списке указываются только индексируемые столбцы (рис. 11.18), то хранилище строк (Heap) в плане запроса не применяется
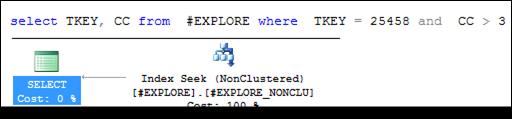
Рис. 11.18. SELECT-запрос с использованием только индексируемых столбцов
Сравнив планы запросов, представленных на рис. 11.16 и 11.18, заметим, что в последнем не используется хранилище строк (Heap). Это происходит потому, что значения столбцов TKEY и CC хранятся в индексе и считываются именно оттуда.
Наиболее часто составной индекс применяется при группировке и вычислениях по индексируемым столбцам (рис. 11.19).
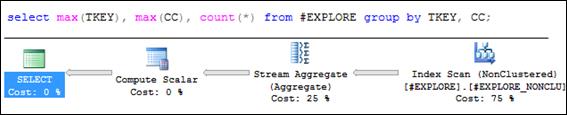
Рис. 11.18. SELECT-запрос с группировкой по индексируемым столбцам
При группировке с вычислениями по двум индексируемым столбцам хранилище строк не используется, выборка данных осуществляется через сканирование индекса.
Удалим составной индекс # EXPLORE_ NONCLU и создадим два отдельных индекса # EXPLORE_ TKEY, # EXPLORE_СС (рис. 11.19).
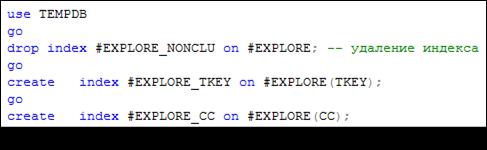
Рис. 11.19. Удаление индекса # EXPLORE_ NONCLU, создание двух
некластеризованных индексов
Проанализировав запросы на рис. 11.20, приходим к выводу, что во всех трех случаях применяется полное сканирование таблицы.
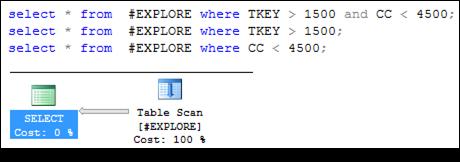
Рис. 11.20. Одинаковый план запроса для всех трех запросов к таблице
# EXPLORE, имеющей 2 индекса # EXPLORE_ TKEY и # EXPLORE_СС (рис. 11.19)
Индекс применяется лишь в тех случаях, когда в SELECT-списке и в WHERE-выражении используется один и тот же индексируемый столбец (рис. 11.21). Иначе выполняется сканирование всей таблицы (рис. 11.22).
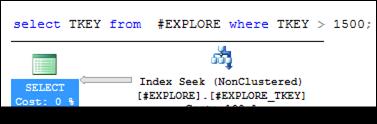
Рис. 11.21. Индексируемый столбец TKEY используется
в SELECT-списке и WHERE-выражении
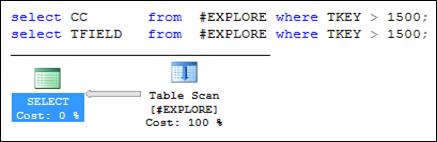
Рис. 11.22. Одинаковый план запроса для двух запросов к таблице # EXPLORE
Рассмотрим возможность совместного применения кластеризованного и некластеризованного индексов. Для этого удалим все существующие индексы таблицы # EXPLORE и выполним сценарий, представленный на рис. 11.23. Заметим, что кластеризованный индекс построен по столбцу CC, а некластеризованный – по столбцу TKEY.
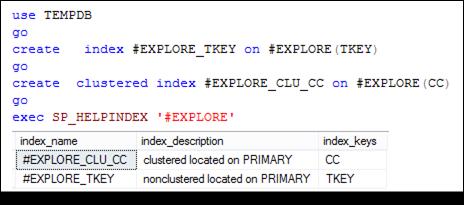
Рис. 11.23. Создание кластеризованного и некластеризованного
индексов таблицы # EXPLORE
Выполнив два запроса, представленных на рис. 11.22, получим два разных плана (рис. 11.24, 11.25).
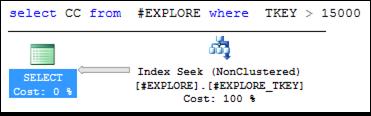
Рис. 11.24. План выполнения первого запроса, представленного на рис. 11.22
при наличии кластеризованного и некластеризованных индексов,
созданных в сценарии на рис. 11.23
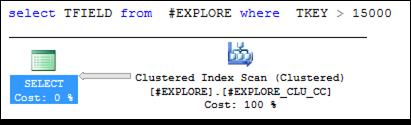
Рис. 11.25. План выполнения второго запроса, представленного на рис. 11.22
при наличии кластеризованного и некластеризованных индексов,
созданных в сценарии на рис. 11.23
В первом случае (рис. 11.24) выполнение запроса сводится к позиционированию в некластеризованном индексе # EXPLORE_ TKEY и считыванию строк в соответствии с диапазоном, заданным во WHERE-выражении. При этом возникает вопрос: каким образом извлекаются данные из столбца CC, указанного в SELECT-списке запроса? Дело в том, что при наличии кластеризованного индекса строка таблицы является частью индекса, а некластеризованный индекс хранит не указатели на строки кластеризованного индекса, а значения его индексируемых столбцов (по которым осуществляется поиск строк в кластеризованном индексе). Таким образом, значения столбца CC будут храниться в строках некластеризованного индекса # EXPLORE_ TKEY.
Во втором случае (рис. 11.25) некластеризованный индекс не применяется – для извлечения значений столбца TFIELD требуется доступ к кластеризованному индексу (он в данном случае совпадает с таблицей # EXPLORE), поэтому оптимизатор «предпочел» сканирование всего индекса.
Индексы покрытия
Как уже отмечалось, избежать полного сканирования таблицы можно с помощью кластеризованного, некластеризованного индексов или их совместного применения. Рассмотрим еще один способ оптимизации запросов.
Вернемся к запросам в примере на рис. 11.22. Таблица # EXPLORE имеет индекс # EXPLORE_ TKEY по столбцу TKEY. Выполнение запросов сводится к сканированию всей таблицы.
Путь необходимо оптимизировать выполнение первого запроса. Для удобства воспроизведем исходный для оптимизации план запроса. Заметим еще раз: в плане запроса не применяется существующий индекс # EXPLORE_ TKEY потому что, даже если отфильтровать строки таблицы с помощью индекса, все равно придется извлекать значения столбца CC из таблицы.
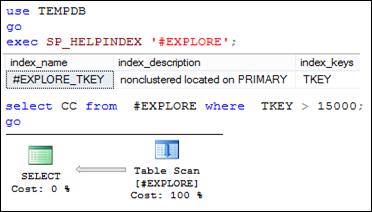
Рис. 11.26. План выполнения запроса, предполагающий сканирование таблицы
Для оптимизации SELECT-запроса, представленного на рис. 11.26 может быть использован другой вид некластеризованного индекса, называемого индексом покрытия запроса или просто индексом покрытия.
Индекс покрытия запроса позволяет включить в состав индексной строки значения одного или нескольких неиндексируемых столбцов. На рис. 11.27 представлен пример создания индекса покрытия. Созданный индекс покрытия # EXPLORE_ TKEY_ X включает значения столбца CC (ключевое слово INCLUDE).
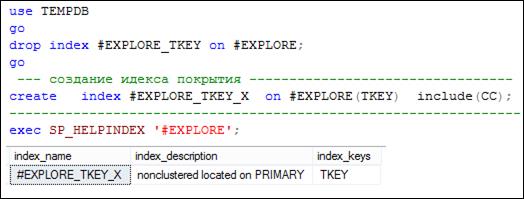
Рис. 11.27. Удаление индекса # EXPLORE_ TKEY и создание
индекса покрытия # EXPLORE_ TKEY_ X
Выполнив запрос, представленный на рис. 11.26 еще раз, получим иной план выполнения запроса, применяющий только некластеризованный индекс для позиционирования и выбора строк, соответствующих WHERE-условию (рис. 11.28).
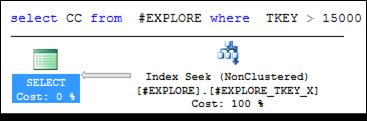
Рис. 11.28. План запроса, использующего индекс покрытия
Дата: 2019-02-25, просмотров: 382.