Конструкции ROLLUP и CUBE применяются в секции GROUP BY и служат для вычисления агрегатных значений над подмножествами строк.
На рис. 7.98 представлен пример использования конструкции ROLLUP.
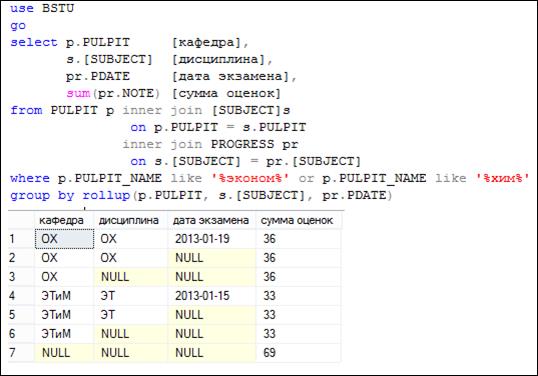
Рис. 7.98. Применение конструкции ROLLUP
Все строки результирующего набора (рис. 7.98) разобьем на две группы: 1) строки, не содержащие значения NULL (строки 1, 4); 2) строки, содержащие одно значение NULL (2, 5); 3) строки, содержащие два значения NULL (3, 6); 4) строки, содержащие три значения NULL (7).
В первой группе находятся строки, которые могут быть сформированы с помощью аналогичного запроса, но без конструкции ROLLUP (рис. 7.99)
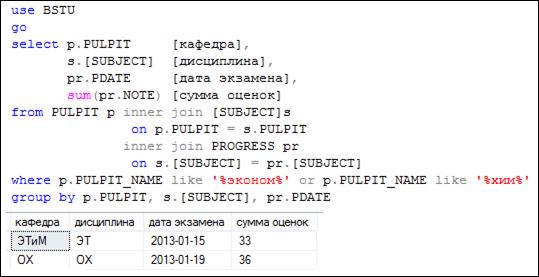
Рис. 7.99. Запрос, аналогичный запросу на рис. 7.98, но без конструкции ROLLUP
Вторая группа строк представляет собой результаты группировок первой группы строк, но по двум столбцам (рис. 7.100).
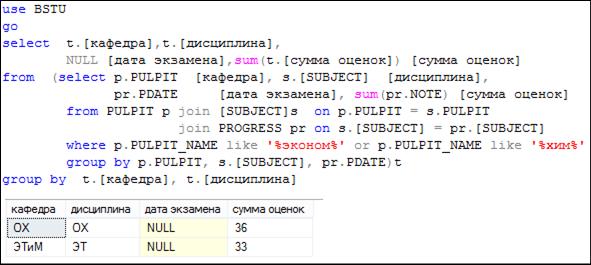
Рис. 7.100. Группировка результата выполнения запроса на рис. 7.99
Третья группа строк представляет собой результаты группировок второй группы строк, но по одному столбцу (рис. 7.101).
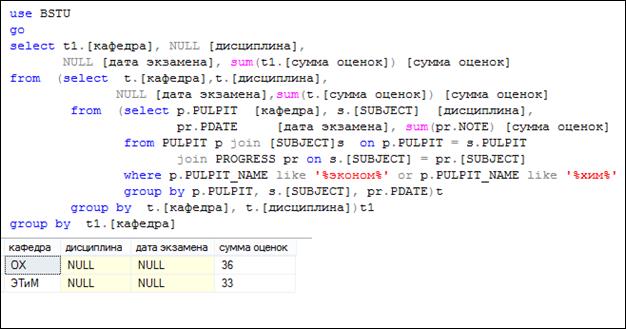
Рис. 7.101. Группировка результата выполнения запроса на рис. 7.100
Последняя строка (в четвертой группе только одна строка) результирующего набора на рис. 7.98 может быть получена с помощью агрегирующей функции SUM, примененной к результату запроса на рис. 7.101 без секции GROUP BY. В виду громоздкости этот запрос здесь не рассматривается, но проанализировав строку 7 результирующего набора на рис. 7.96, можно легко убедиться в том, что она может быть получена в результате группировки всех строк результирующего набора запроса на рис. 7.101.
Сформулируем правило формирования результирующего набора SELECT-запроса, применяющего в секции GROUP BY конструкцию ROLLUP.
1. Результирующий набор содержит n + 1 групп строк, где n – количество выражений для группировки, указанных в скобках за ключевым словом ROLLUP.
2. Первая группа строк является результатом выполнения группировки по всем n выражениям.
3. Вторая группа строк является результатом группировки первой группы строк по n – 1 первым выражениям. Причем столбцы, по которым не выполнялась группировка, заполняются значениями NULL.
4. Группа строк k является группировкой группы строк, полученной на предыдущем этапе по n – k + 1 первым выражениям.
5. Последняя (n + 1)-я группа содержит одну строку. Значения во всех столбцах, соответствующих выражениям в ROLLUP, равны NULL. Значение в столбце, соответствующем агрегатной функции, вычисляется по всем строкам исходного для группировки набора строк.
На рис. 7.102 представлен запрос и сформированный им результирующий набор строк. В секции GROUP BY запроса применяется конструкция CUBE. Обратите внимание, что список столбцов в скобках, следующих за ключевым словом CUBE, аналогичен ROLLUP-списку на рис. 7.98.
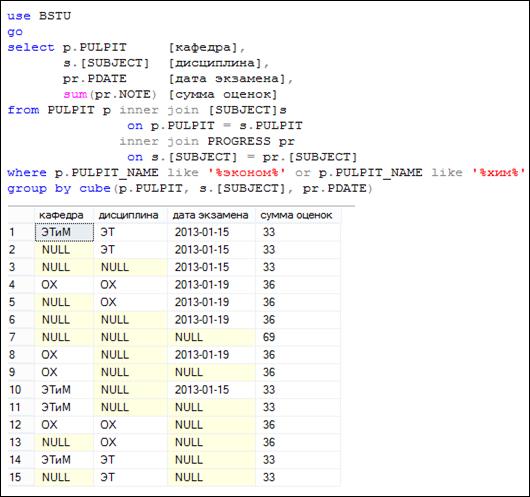
Рис. 7.102. Применение конструкции CUBE
Сравним результирующие наборы строк, полученные в результате запросов, представленных на рис. 7.98 и 7.102. Заметим, что все строки результирующего набора на рис. 7.98 имеются в результирующем наборе на рис. 7.102, но не наоборот.
Рассмотрим строки 2 и 5 результирующего набора на рис. 7.102. Этих строк нет в результирующем наборе на рис. 7.98. Эти строки получены в результате группировки по столбцам SUBJECT и PDATE исходного для секции GROUP BY набора строк.
Проанализировав результирующий набор на рис. 7.102, не сложно выяснить, что каждая строка относится к одной из групп строк, которые получаются как результат выполнения группировки по подмножеству выражений, указанных в CUBE-списке. Например: строки 1 и 4 – это результат группировки по столбцам (выражениям) PULPIT, SUBJECT и PDATE; строки 2 и 5 – результат группировки по столбцам SUBJECT и PDATE; строки 8 и 10 – результат группировки по столбцам PULPIT и PDATE и т. д.
Сформулируем правило формирования результирующего набора SELECT-запроса, применяющего в секции GROUP BY конструкцию CUBE.
1. Формируется множество всех подмножеств выражений, указанных в CUBE-списке.
2. Для каждого непустого подмножества, сформированного в п. 1 выполняется группировка. Если количество элементов подмножества меньше количества элементов CUBE-списка, то соответствующие значения в строках заполняются NULL (как это делалось конструкцией ROLLUP). Сформированные строки помещаются в результирующий набор секции GROUP BY.
3. Для пустого подмножества, сформированного в п. 1 выполняется группировка аналогичная той, что выполнялась в п. 5 правил для ROLLUP.
Секция HAVING
Для фильтрации результирующего набора строк, сформированного секцией GROUP BY, служит секция HAVING. На рис. 7.103 представлен SELECT-запрос? применяющий секцию GROUP BY, а на рис. 7.104 тот же запрос, но дополненный секцией HAVING.
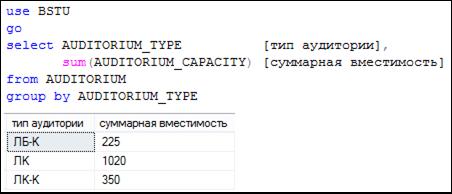
Рис. 7.103. Запрос с применением секции GROUP BY
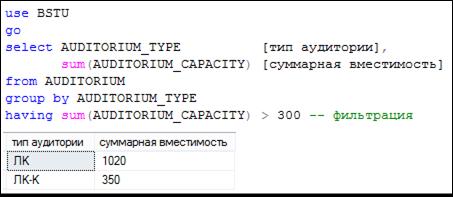
Рис. 7.104. Запрос с применением секции HAVING
Смысл секции HAVING такой же, как и у секции WHERE. Основное отличие – действие секции HAVING распространяется на результат выполнения секции GROUP BY, а действие секции WHERE – на результат секции FROM.
Логическое выражение, указанное в HAVING, вычисляется для каждой строки результирующего набора, сформированного секцией GROUP BY. Как и в случае с секцией WHERE, строка отбирается в результирующий набор секции, если логическое выражение принимает значение «истина». При этом следует помнить, что в логическом выражении могут применяться лишь такие компоненты, которые основываются на выражениях из секции GROUP BY и/или значениях, которые могут быть вычислены. Применительно к рис. 7.104 в HAVING можно использовать выражения, построенные над значением из столбца AUDITORIUM_ TYPE, и/или агрегатные функции. В случае, приведенном на рис. 7.104, отфильтровываются такие группы строк, в которых сумма значений в столбце AUDITORIUM_ CAPACITY превышает 300. На рис. 7.105 представлен еще один пример использования секции HAVING.
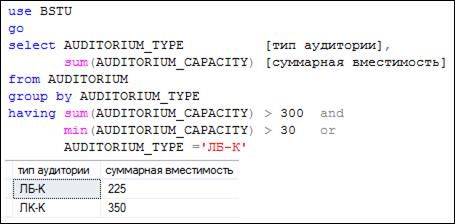
Рис. 7.105. Секция HAVING, использующая составное логическое выражение
Следует обратить внимание на то, что в логическом выражении HAVING могут использоваться выражения, которых нет в SELECT-списке, как, например, это сделано в запросе на рис. 7.105: применяется агрегатная функция MIN.
Секция ORDER BY
В большинстве SELECT-запросов секция ORDER BY выполняется последней. Назначение секции – сортировка результирующего набора строк. Исходным набором для секции ОRDER BY является результат выполнения одной из предшествующих секций (см. рис. 7.2 на рис. 122), результатом – этот же набор, но в заданном порядке строк. Следует обратить внимание на то, что в секции ORDER BY могут использоваться псевдонимы имен столбцов, назначенные в SELECT-списке. В общем случае в ORDER BY может быть указано несколько выражений, в простейшем – просто столбец (рис. 7.106).
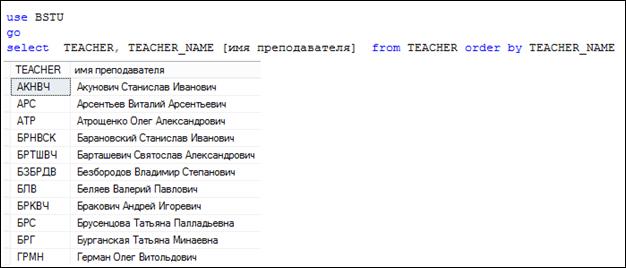
Рис. 7.106. Пример SELECT-запроса, использующего секцию ORDER BY
Выполненная в запросе (рис. 7.106) сортировка формирует результирующий набор строк, упорядоченный в порядке возрастания значений из столбца TEACHER_ NAME. При этом порядок сортировки в данном запросе задан неявно. Для того чтобы задать порядок явно, следует применять ключевые слова ASC (рис. 7.107, в порядке возрастания) или DESC (рис. 7.108, в порядке убывания).

Рис. 7.107. Применение ключевого слова ASC в секции ORDER BY
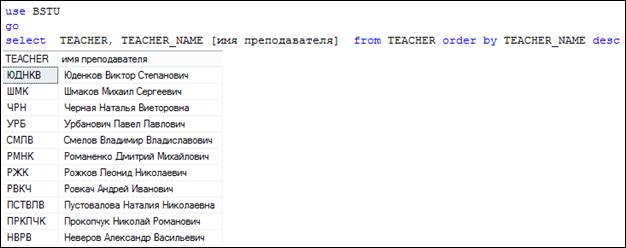
Рис. 7.108. Применение ключевого слова DESC
в секции ORDER BY для сортировки в порядке убывания
В секции ORDER BY через запятую может быть перечислено несколько выражений, используемых для сортировки (рис. 7.109), причем для каждого из них может быть указан свой порядок сортировки (ключевые слова ASC или DESC).
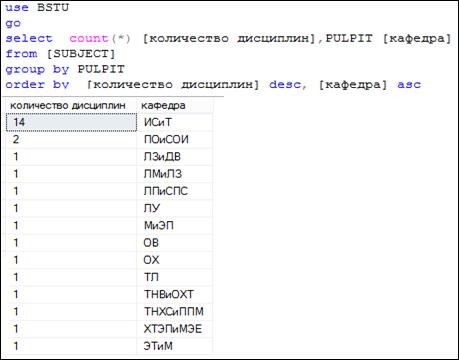
Рис. 7.109. Применение нескольких выражений в секции ORDER BY
Исходным набором строк для секции ORDER BY в SELECT-запросе на рис. 7.109 является результирующий набор секции GROUP BY. Сортировка выполняется по двум выражениям: значениям столбца количество дисциплин и значениям столбца кафедра. Следует обратить внимание на следующее: в секции ORDER BY применяются псевдонимы столбцов; для каждого выражения в секции ORDER BY указан свой порядок сортировки.
Выражения в секции ORDER BY могут быть достаточно сложными. В примере на рис. 7.110 применяется оператор CASE (подробно рассматривается позже), который в зависимости от логических условий, следующих за ключевыми словами WHEN, формирует значения, указывающиеся за ключевыми словами THEN или ELSE.
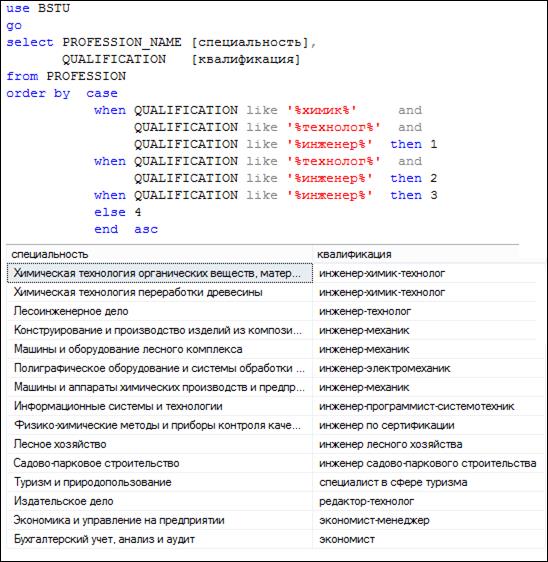
Рис. 7.110. Применение сложных выражений в секции ORDER BY
В результате выполнения сортировки лидирующими в результирующем наборе окажутся строки, содержащие в значении столбца QUALIFCATION три подстроки: химик, технолог и инженер; затем будут следовать строки, содержащие в QUALIFCATION подстроки технолог и инженер; далее – содержащие подстроку инженер; и, наконец, последними будут строки, не удовлетворяющие перечисленным требованиям.
Следует помнить, что опция TOP применяется после ORDER BY и позволяет отобрать заданное количество лидирующих строк отсортированного результирующего набора (7.111).
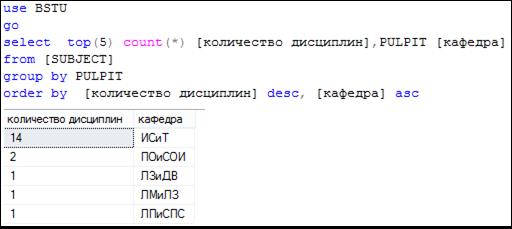
Рис. 7.111. Применение сложных выражений в секции ORDER BY
Кроме того, применение опции DISTINCT, избавляющей результирующий набор от повторяющихся строк, позволяет применять в выражениях ORDER BY только те столбцы, которые указаны в SELECT-списке запроса.
Секции COMPUTE и COMPUTE BY
Секции COMPUTE и COMPUTE BYпредназначены для формирования дополнительных результирующих наборов с итоговыми строками. Применение этих секций возможно только для БД, управляемых Microsoft SQL Server, так как они предусмотрены стандартами SQL.
На рис. 7.112 представлен пример использования секции COMPUTE для вычисления суммарного, минимального и максимального значений в столбце AUDITORIUM_ CAPACITY таблицы AUDITORIUM. Исходным является результирующий набор, сформированный в любой завершающей секции SELECT-запроса. Секция COMPUTE формирует дополнительный результирующий набор строк, состоящий только из одной строки, столбцы которой содержат итоговые значения. Для вычисления итоговых значений допускается применение только агрегатных функций (табл. 7.2) и не допускается использование псевдонимов столбцов. При выполнении секции формируются столбцы, имена которых задаются автоматически и соответствуют агрегатным функциям, используемым в секции COMPUTE.
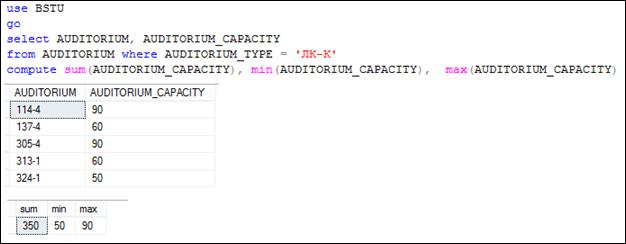
Рис. 7.112. Применение секции COMPUTE
Допускается использование нескольких секций COMPUTE для одного SELECT-запроса (7.113). Каждой секции COMPUTE соответствует свой отдельный результирующий набор строк.
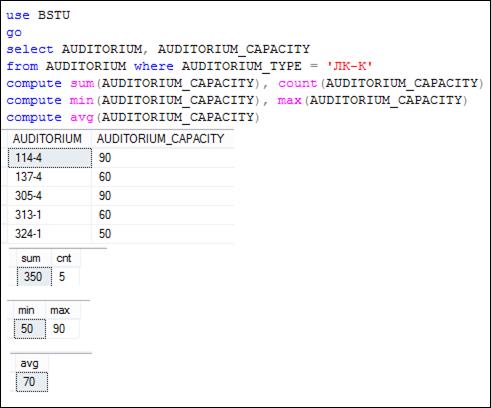
Рис. 7.113. Применение нескольких секций COMPUTE в одном SELECT-запросе
На рис. 7.114 приведен пример применения секции COMPUTE в SELECT-запросе, использующем группировку (GROUP BY).
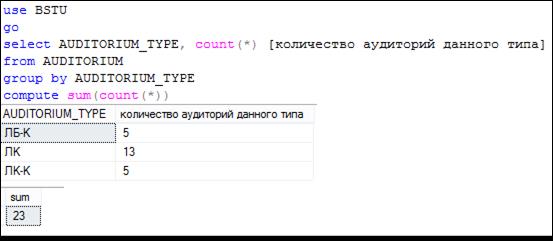
Рис. 7.114. Совместное применение секций GROUP BY и COMPUTE
Обратите внимание на принцип вычисления суммарного количества строк в секции COMPUTE.
Применение секции COMPUTE BY несколько отличается от применения COMPUTE. Назначение этой секции – вычисление промежуточных итогов. Секция может быть применена только совместно с секцией ORDER BY. Причем за ключевым словом BY секции COMPUTEBY может быть записана такая же последовательность выражений (ASC и DESC не указывается), как в секции ORDER BY. Если в ORDER BY через запятую указано несколько выражений, то в COMPUTE BY допускается указывать только первые слева, без пропуска.
На рис. 7.115 приведен пример SELECT-запроса с применением секции COMPUTE BY и первые четыре результирующих набора, сформированных этим запросом. При использовании COMPUTE BY формируется несколько результирующих наборов, каждый из которых можно отнести к одному из двух типов.
Первый тип – это набор строк, структура которых формируется на основе SELECT-списка. В набор первого типа включаются строки, имеющие одно и то же значение выражений, указанных за ключевым словом BY секции COMPUTE BY.
Второй тип – это набор, состоящий из одной строки, сформированной по тому же принципу, что и при выполнении секции COMPUTE без BY. Агрегатные функции вычисляются только над строками предшествующего набора первого типа.
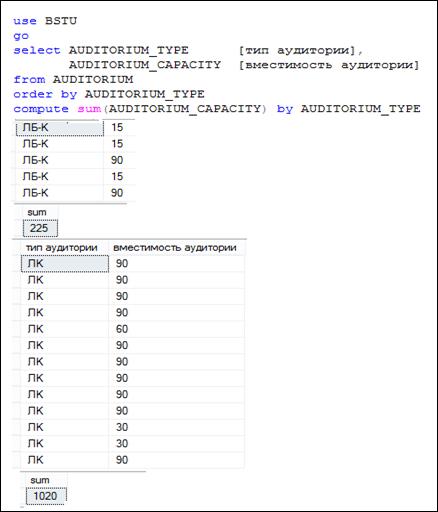
Рис. 7.115. Пример использования секции COMPUTE BY
В целом результат выполнения COMPUTE BY формирует последовательность чередующихся результирующих наборов первого и второго типов.
7.8. Конструкция SELECT … INTO
Конструкция SELECT … INTO очень удобна при создании новой таблицы на основе существующей таблицы-образца. В секции INTO указывается имя создаваемой таблицы. Имена и типы данных столбцов новой таблицы будут совпадать с именами (или псевдонимами), заданными в SELECT-списке оператора. Кроме того, в созданную таблицу будут добавлены строки сформированного оператором SELECT результирующего набора.
На рис. 7.116 представлен сценарий, в котором с помощью первого оператора SELECT создается новая таблица с именем # TEACHER1 (временная таблица) на основе таблицы TEACHER, а с помощью второго – выводятся строки новой таблицы.
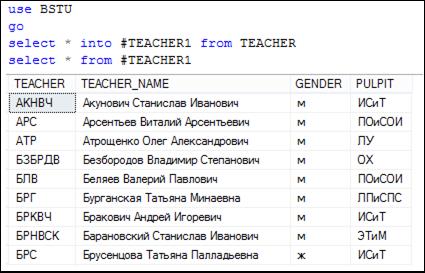
Рис. 7.116. Создание новой таблицы с помощью конструкции SELECT … INTO
Не сложно убедиться, что в таблицу # TEACHER1 скопированы все строки таблицы TEACHER (рис. 7.117).

Рис. 7.117. Количество строк исходной и новой таблиц совпадает
Проанализировав структуры и свойства таблиц TEACHER и # TEACHER1 с помощью уже знакомой нам утилиты SP_HELP, заметим, что структуры (количество столбцов, их имена и типы) таблиц совпадают, ограничений целостности типа DEFAULT, CHECK, PRIMARY KEY и FOREIGN KEY, существующих в таблице TEACHER, в # TEACHER1 нет, но свойство столбцов NOT NULL в новой таблице сохранилось (рис. 7.118, 7.119).
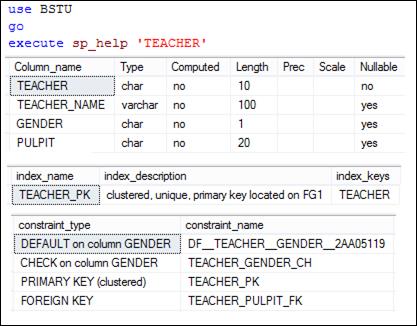
Рис. 7.118. Структура и свойства столбцов таблицы TEACHER
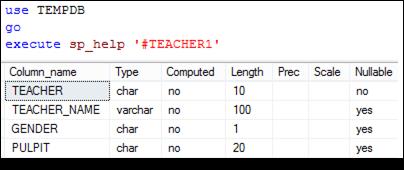
Рис. 7.119. Структура и свойства столбцов таблицы #TEACHER1
На рис. 7.120 демонстрируется более сложный пример применения конструкции SELECT … INTO с использованием псевдонимов столбцов и секции WHERE.
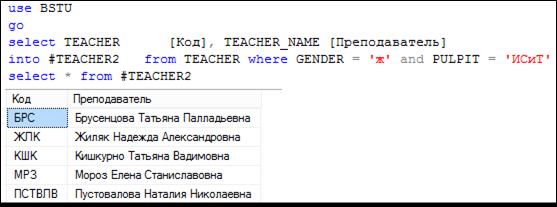
Рис. 7.120. Создание таблицы # TEACHER2
Обратите внимание на следующее.
1. В новой таблице только два столбца – столько, сколько указано в SELECT-списке.
2. Имена столбцов в новой таблице совпадают с заданными в SELECT-списке псевдонимами.
3. В новую таблицу добавляются только те строки, которые удовлетворяют условию в секции WHERE.
Дата: 2019-02-25, просмотров: 430.