В некоторых случаях бывает важным, чтобы часть запросов выполнялась особенно быстро. Если эти запросы основаны на WHERE-фильтрации строк, то может быть эффективным применение фильтруемых некластеризованных индексов.
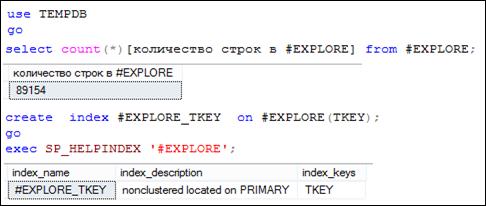
Рис. 11.33. Создание некластеризованного индекса # EXPLORE_ TKEY
Для исследования эффективности фильтруемых индексов увеличим количество строк в таблице # EXPLORE и создадим некластеризованный индекс по столбцу TKEY (рис. 11.33). Выполним три запроса (рис. 11.34 –11.36), убедимся, что в плане выполнения применяется созданный (рис. 11.33) индекс и зафиксируем стоимости запросов.
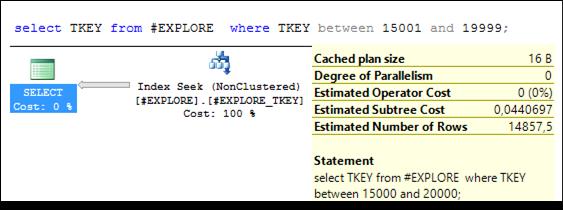
Рис. 11.34. Выполнение запроса со стоимостью 0,044
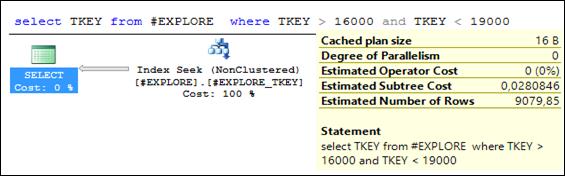
Рис. 11.35. Выполнение запроса со стоимостью 0,028
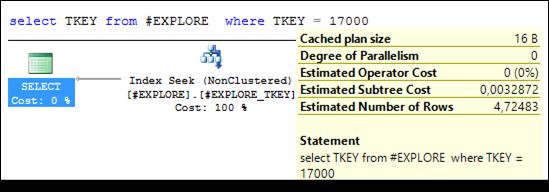
Рис. 11.36. Выполнение запроса со стоимостью 0,033
На рис. 11.37 приведен сценарий, в котором создается фильтрующий индекс с именем # EXPLORE_ WHERE. Обратите внимание на ключевое слово WHERE и следующее за ним логическое условие в операторе CREATE INDEX: фильтруемый индекс создается только для строк таблицы # EXPLORE, которые удовлетворяют этому логическому условию. Кроме того, заметим, что WHERE-выражение при создании индекса описывает подмножество строк, являющееся надмножеством для всех подмножеств строк, выбираемых запросами на рис. 11.34–11.36.
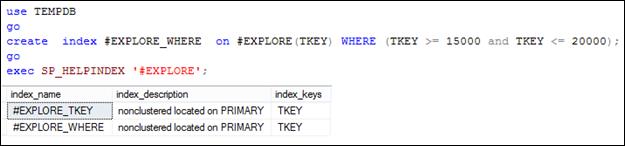
Рис. 11.37. Создание некластеризованного фильтруемого
индекса # EXPLORE_ WHERE
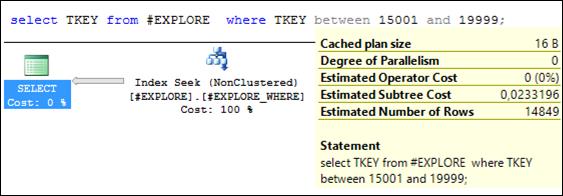
Рис. 11.38. Выполнение запроса со стоимостью 0,023 (меньше стоимости 0,044 запроса на рис. 11.34)
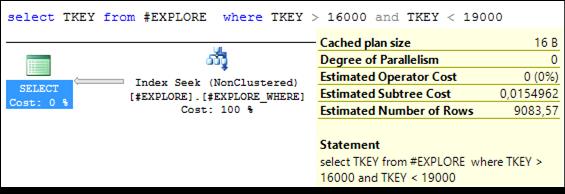
Рис. 11.39. Выполнение запроса со стоимостью 0,015
(меньше стоимости 0,028 запроса на рис. 11.35)
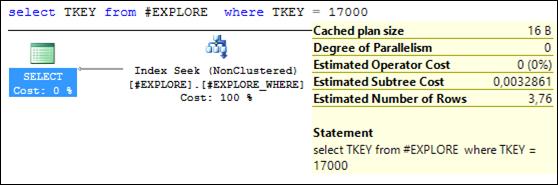
Рис. 11.40. Выполнение запроса со стоимостью 0,0033
(совпадает со стоимостью 0,0033 запроса на рис. 11.36)
Повторим три запроса к таблице # EXPLORE (рис. 11.38–11.40). Убедимся, что в плане запросов применяется созданный фильтруемый индекс (рис. 11.37). Зафиксируем стоимости этих запросов. При сравнении стоимости двух серий запросов можно убедиться в том, что в двух из трех запросов стоимость существенно снизилась.
На рис. 11.41 представлен запрос, WHERE-выражение которого описывает множество строк, включающее строки, не входящие во множество строк, соответствующее WHERE-выражению фильтрующего индекса # EXPLORE_ WHERE. План выполнения этого запроса не применяет фильтрующий индекс, а основывается на позиционировании в индексе #EXPLORE_ TKEY.
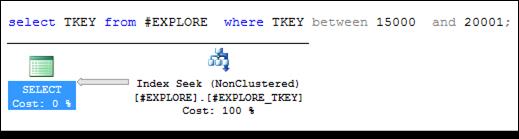
Рис. 11.41. План выполнения запроса, не применяющего фильтрующий индекс
Допускается создание некластеризованных фильтрующих индексов покрытия (рис. 11.42). Обратите внимание: WHERE-выражение в операторе создания индекса содержит логическое выражение, в котором задействованы два столбца таблицы, хотя индексирование выполняется только по одному из них. Как и прежде, если множество строк, выбираемое WHERE-выражением SELECT-запроса, является подмножеством множества индексируемых фильтрующим индексом строк, то оптимизатор будет его применять в плане запроса (рис. 11.43).
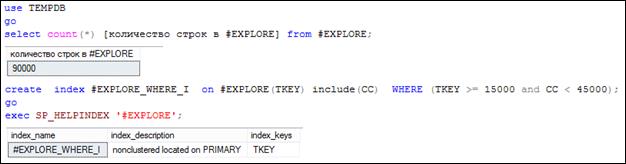
Рис. 11.42. Создание некластеризованного фильтрующего индекса покрытия
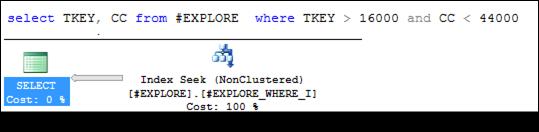
Рис. 11.43. Фильтрующий индекс покрытия, использующийся в плане запроса
Дата: 2019-02-25, просмотров: 392.