Подзапрос – это SELECT-запрос, выполненный в рамках другого запроса. При этом основной SELECT-запрос называется внешним, а SELECT-запрос, который выполняется в рамках внешнего – внутренним.
На рис. 7.16 приведен пример SELECT-запроса, содержащего три подзапроса в списке SELECT.
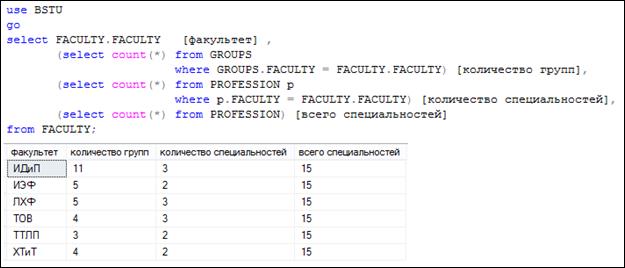
Рис. 7.16. Применение подзапросов в списке SELECT
Внешний SELECT-запрос выбирает строки из таблицы FACULTY, три внутренних – из таблиц GROUPS и PROFESSION. Обратите внимание, что столбец с именем FACULTY присутствует во всех трех таблицах, поэтому для однозначности применяются двухкомпонентные имена столбцов в формате ТАБЛИЦА.СТОЛБЕЦ.
Подзапросы бывают двух видов: коррелируемые и независимые.
Коррелируемый подзапрос зависит от внешнего запроса и выполняется для каждой строки результирующего набора. На рис. 7.16 два первых подзапроса являются коррелируемыми. Обратите внимание: в логических выражениях секций WHERE (подробно рассматривается позже) используется значение столбца FACULTY таблицы FACULTY, формируемое во внешнем запросе.
Независимый подзапрос не зависит от внешнего запроса и выполняется только один раз, но результат его выполнения подставляется в каждую строку результирующего набора. На рис. 7.16 третий подзапрос является независимым.
Важно понимать, что в SELECT-списке допускается применять только такие подзапросы, которые формируют скалярный результирующий набор (набор, состоящий из одной строки и одного столбца).
Отметим следующее.
Запись выражения для SELECT-запроса на рис. 7.16 можно сократить, если применить для имен таблиц псевдонимы.
Пример на рис. 7.16 носит исключительно учебное назначение. В реальности здесь не следовало бы применять коррелируемые запросы, а можно было использовать многотабличный запрос с JOIN-соединением таблиц FACULTY, GROUPS и PROFESSION.
Псевдонимы и многотабличные запросы рассматриваются позже при описании возможностей секции FROM оператора SELECT.
Секция FROM
Секция FROM содержит выражение, которое интерпретируется как набор однородных строк с явно поименованными столбцами.
В простейшем случае в секции FROM может быть указана таблица БД (рис. 7.17).
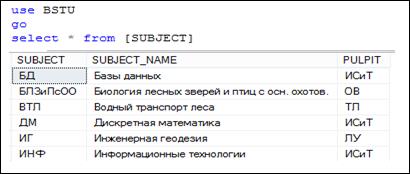
Рис. 7.17. Источник строк – таблица
В качестве источника строк во FROM может выступать результат другого SELECT-запроса (7.18). Другими словами, в секции FROM можно выполнить подзапрос.
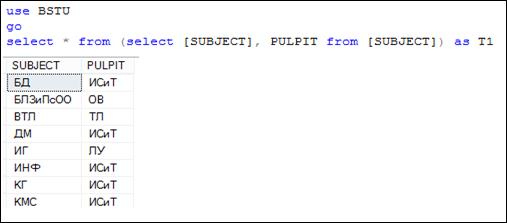
Рис. 7.18. Источник строк – SELECT-запрос
Если во FROM используется SELECT-запрос, то его результирующий набор, выступающий в качестве источника строк, должен быть поименован с помощью ключевого слова AS (может быть опущено), задающего псевдоним. На рис. 7.18 результирующий набор поименован символом T1. Обратите внимание, что SELECT-список внутреннего запроса, расположенного во FROM, содержит только два из трех столбцов таблицы SUBJECT, и имена этих столбцов унаследовал результирующий набор внешнего SELECT-запроса.

Рис. 7.19. Применение псевдонимов столбцов в подзпросе
В подзапросе примера на рис. 7.19 для выбираемых столбцов указываются имена-псевдонимы. В этом случае внешний запрос «видит» только псевдонимы исходного набора. Обратите внимание, что окончательный результирующий набор имеет только один столбец с именем, заданным в псевдонимом SELECT-списка внешнего столбца.
Многотабличные запросы. Если секция FROM содержит выражение, включающее несколько таблиц, то говорят о многотабличных запросах. На рис. 7.20 представлен пример простейшего многотабличного запроса и фрагмент сформированного им результирующего набора.
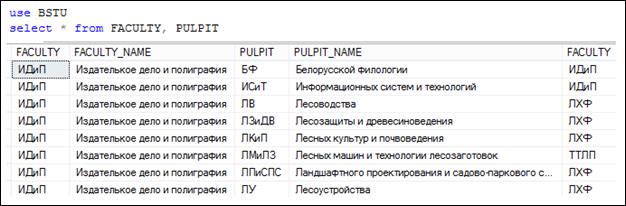
Рис. 7.20. Пример простейшего многотабличного запроса
Секция FROM содержит две таблицы: FACLUTY и PULPIT. Обратите внимание, что результирующий набор содержит два столбца с именем FACULTY. Это произошло из-за того, что таблицы имеют столбцы с одинаковыми именами. Поэтому, если в SELECT-списке потребуется явно указать столбец с именем FACULTY, то необходимо уточнить к какой именно таблице он относится (рис. 7.21).
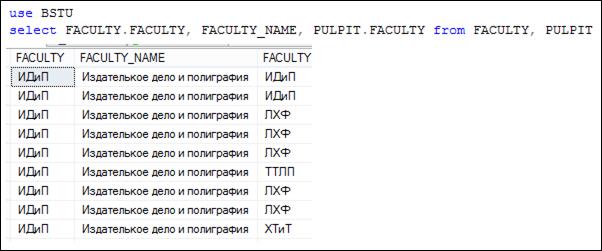
Рис. 7.21. Формирование результирующего набора с двумя столбцами, имеющими одинаковое имя
В SELECT-списке запроса (рис. 7.21) перечислены три столбца. Для двух столбцов с именем FACULTY явно указаны таблицы, к которым они относятся, а для FACULTY_ NAME таблица не указана. Столбец FACULTY_ NAME содержится только в таблице FACULTY, поэтому такая запись не вызывает двусмысленности. Этот же запрос можно записать с применением псевдонимов для используемых во FROM таблиц (7.22).
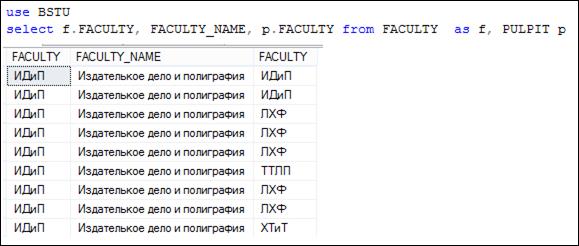
Рис. 7.22. Применение псевдонимов таблиц
Считается хорошей практикой при написании многотабличных запросов, во избежание путаницы, имя таблицы или псевдонима указывать для каждого столбца SELECT-списка.
Рассмотрим результирующий набор, сформированный запросом, представленным на рис. 7.22. В соответствии с SELECT-списком он состоит из трех столбцов: первые два относятся к таблице FACULTY, а третий – к PULPIT.
Результирующий набор создается по следующим правилам:
1) каждая строка таблицы FACULTY соединяется со всеми строками таблицы PULPIT, образуя промежуточный набор однородных строк, имеющий суммарное количество столбцов и количество строк, равное произведению количеств строк таблиц FACULTY и PULPIT (рис. 7.23);
2) из всех столбцов промежуточного набора «вырезаются» столбцы, указанные в списке SELECT.

Рис. 7.23. Количество строк в результирующем наборе запроса, представленного на рис. 7.22
Если в секции FROM перечислено через запятую более двух таблиц, то правило формирования результирующего набора применяется слева направо для всех таблиц. Сначала строится результирующий набор для первой пары таблиц, потом он соединяется с третьей таблицей, образуя очередной набор, и т. д. В конечном наборе количество столбцов равно суммарному количеству столбцов всех таблиц, а количество строк – произведению числа их строк.
Применение псевдонимов таблиц дает возможность дважды указать одну и ту же таблицу в секции FROM (рис. 2.24).
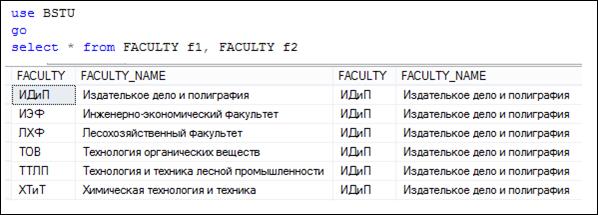
Рис. 7.24. Таблица FACULTY дважды указана в секции FROM
В многотабличных запросах в секции FROM можно использовать подзапросы (рис. 7.25).
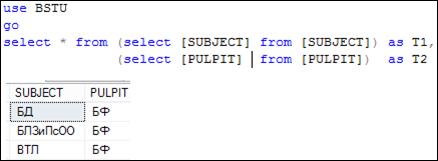
Рис. 7.25. Применение двух подзапросов в секции FROM
Соединение таблиц CROSS JOIN. В примерах на рис. 7.20–7.22, 7.24, 7.25 выполнялась операция, которая в теории БД называется соединением таблиц. Действительно, в результате этих операций получался набор, строки которого представляют собой соединение строк двух или более таблиц. Способ соединения, рассмотренный в этих примерах, наиболее простой: каждая строка одной таблицы соединяется с каждой строкой другой таблицы. Такое соединение называют декартовым произведением таблиц.
Для выполнения декартова произведения двух или более таблиц следует просто перечислить их через запятую в секции FROM. Существует другой способ записи этой же операции с помощью выражения CROSS JOIN.
На рис. 7.26 приведены примеры записи декартова произведения таблиц с применением CROSS JOIN.
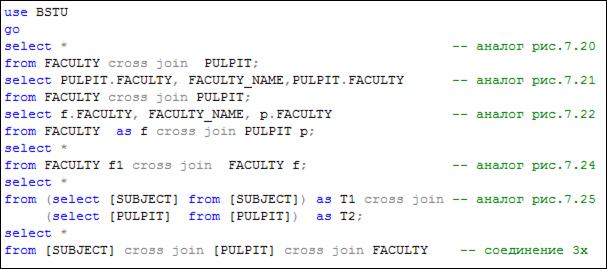
Рис. 7.26. Примеры применения выражения CROSS JOIN
Соединение таблиц INNER JOIN. Соединение таблиц INNER JOIN (внутреннее соединение) – наиболее часто используемый вид соединения реляционных таблиц.
На рис. 7.27 приведен пример SELECT-запроса с использованием внутреннего соединения таблиц FACULTY и PULPIT и фрагмент результирующего набора.
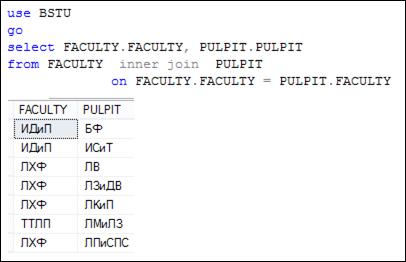
Рис. 7.27. Пример внутреннего соединения двух таблиц
Обратите внимание, что выражение, описывающее внутреннее соединение, состоит из двух частей: собственно выражение INNER JOIN, указываемое между двумя соединяемыми таблицами; логическое выражение, записываемое после ключевого слова ON.
Результирующий набор SELECT-запроса на рис. 7.27 создается по следующим правилам:
1) выполняется декартово произведение для таблиц FACULTY и PULPIT;
2) из результирующего набора, полученного на предыдущем шаге, выбираются строки, удовлетворяющие условию логического выражения, указанного после ON;
3) из всех столбцов результирующего набора «вырезаются» столбцы, указанные в списке SELECT.
Аналогичный результат может быть получен, если выполнить следующий SELECT-запрос (рис. 7.28). Проанализировав этот запрос, не сложно понять, что он в точности повторяет правила внутреннего соединения таблиц, описанные выше. Основное отличие в том, что отбор строк в этих запросах выполняется на разных этапах: в первом случае при формировании набора строк в секции FROM, во втором – при фильтрации строк в секции WHERE (подробно об этой секции позже).

Рис. 7.28. Запрос, формирующий результат, аналогичный
результату запроса на рис. 7.27
На рис. 7.29 приведен запрос, вычисляющий с помощью встроенной функции COUNT (рассматривается позже) количество строк в результирующих наборах, сформированных шестью запросами.
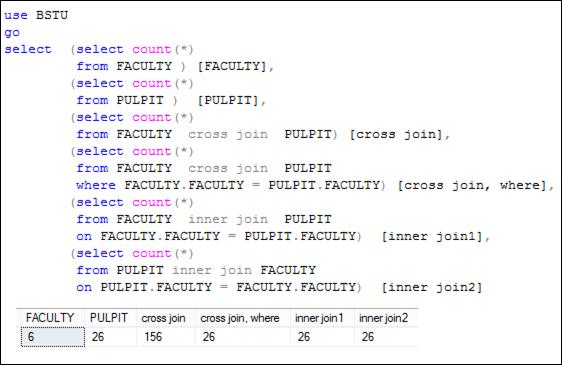
Рис. 7.29. Количество строк в результирующих наборах,
формируемых различными запросами
Обратите внимание на следующее: количество строк, формируемое при внутреннем соединении, не превышает количества строк декартова произведения таблиц; запросы на рис. 7.27 и 7.28 формируют одинаковое число строк; операция INNER JOIN является коммутативной – формируемый результирующий набор не зависит от порядка, в котором указаны таблицы.
Внутреннее соединение можно выполнить для двух и более таблиц. В примере на рис. 7.30 соединяются три таблицы: FACULTY, PULPIT и SUBJECT. Обратите внимание на использование псевдонимов таблиц.
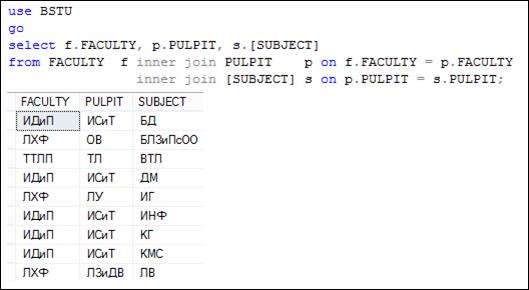
Рис. 7.30. Внутреннее соединение трех таблиц
Допускается применение подзапросов. На рис. 7.31 представлен пример использование подзапроса в конструкции INNER JOIN.
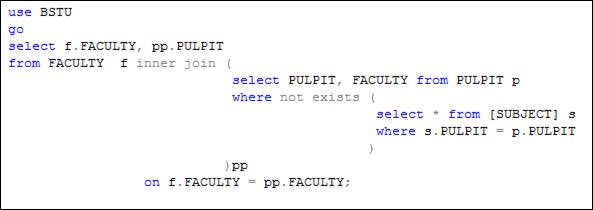
Рис. 7.31. Применение подзапросов в конструкции INNER JOIN
Обратите внимание на то, что подзапрос, используемый в INNER JOIN, сам содержит подзапрос в секции WHERE. Такая иерархия подзапросов является типичной. Принцип применения подзапросов в секции WHERE будет рассматриваться позже.
Логическое условие, указываемое после ключевого слова ON, не обязательно должно содержать условие, записываемое в виде равенства – это может любое логическое выражение. Пример на рис. 7.32 демонстрирует применение условия в виде неравенства.
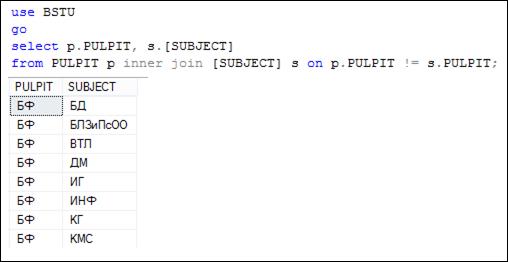
Рис. 7.32. Логическое условие после ON в виде неравенства
С помощью INNER JOIN можно соединять таблицу саму с собой. Обычно такие запросы применяются для получения информации об иерархических связях между строками одной таблицы. На рис. 7.33 создается и заполняется таблица с именем [Руководители и Исполнители], с помощью которой демонстрируется внутреннее соединение таблицы с собой.
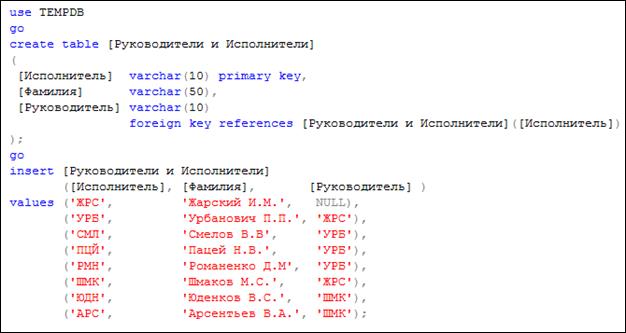
Рис. 7.33. Создание таблицы [Руководители и Исполнители]
Обратите внимание: в таблице [Руководители и Исполнители] установлена иерархическая связь между строками. Каждая строка описывает члена какой-то организации, в которой устанавливается отношение руководитель – исполнитель. При этом руководитель, может выступать исполнителем для руководителя более высокого уровня. Исполнитель, для которого нет руководителя (в столбце [Руководитель] значение NULL), является руководителем самого высокого уровня.
Кроме того, следует обратить внимание на ограничение FOREIGN KEY, указанное для таблицы [Руководители и Исполнители] – оно ссылается на эту же таблицу.
На рис. 7.34 демонстрируется запрос, использующий внутреннее соединение с собой таблицы [Руководители и Исполнители].

Рис. 7.34. Внутреннее соединение с собой таблицы
[Руководители и Исполнители]
Соединение таблиц OUTER JOIN. Еще раз рассмотрим пример внутреннего соединения таблиц PULPIT и TEACHER. На рис. 7.35 представлены два SELECT-запроса с внутренним соединением этих таблиц. В первом запросе подсчитывается количество строк в результирующем наборе, во втором – формируется сам результирующий набор. Обратим внимание: результирующий набор содержит 13 строк.
Отметим, что в результирующий набор попали те строки из PULPIT, для которых в таблице TEACHER нашлись строки, в которых значение в столбце FACULTY совпадает со значением в одноименном столбце таблицы TEACHER.
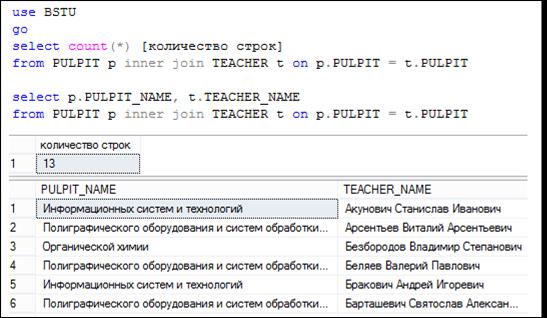
Рис. 7.35. Внутреннее соединение таблиц PULPIT и TEACHER
Запрос, представленный на рис. 7.36, формирует результирующий набор из таблицы PULPIT со строками, имеющими такие значения в столбце FACULTY, каких нет в одноименном столбце ни в одной из строк таблицы TEACHER. Другими словами, этот запрос формирует набор строк из PULPIT, которые не соединились ни с одной строкой из таблицы в запросе на рис. 7.35. Обратим внимание: количество не соединившихся строк таблицы PULPIT равно 22.
Внешнее соединение двух таблиц формирует набор строк, состоящий из двух частей:
1) результат внутреннего соединения двух таблиц;
2) строки из двух таблиц, которые не смогли соединиться; если в SELECT-списке указаны столбцы двух таблиц, то значения в столбцах, соответствующих незаполненной (несоединенной) части строки, будут NULL.
Имеется два вида внешнего соединения: LEFT OUTER JOIN – левое внешнее соединение и RIGHT OUTER JOIN – правое внешнее соединение.
Левое внешнее соединение, в соответствии со вторым пунктом правила, включает в набор несоединенные строки таблицы, имя которой записано слева от ключевых слов LEFT OUTER JOIN, а правое внешнее соединение – несоединенные строки таблицы, имя которой записано справа от RIGHT OUTER JOIN.
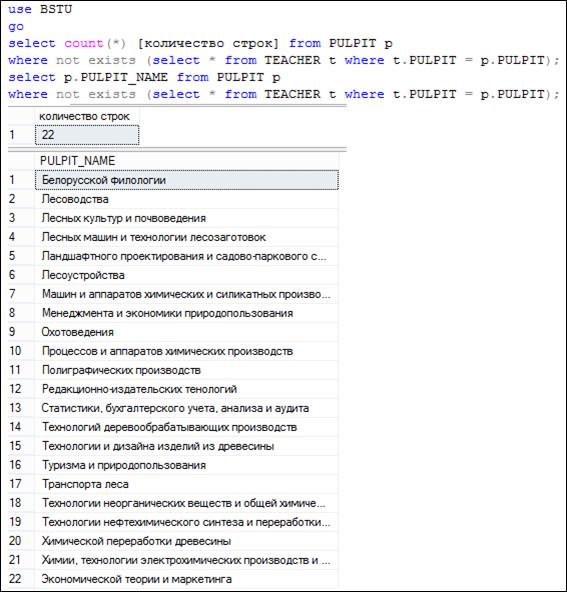
Рис. 7.36. Несоединенные строки таблицы PULPIT в запросе на рис. 7.35
На рис. 7.37 представлены три SELECT-запроса, содержащие левое внешнее соединение таблиц PULPIT и TEACHER: в первом запросе вычисляется количество строк в результирующем наборе; во втором запросе в результирующий набор выводятся строки, содержащие значение NULL в столбце TEACHER_ NAME; в третьем запросе в результирующий набор выводятся строки, содержащие значение не NULL в столбце TEACHER_ NAME.
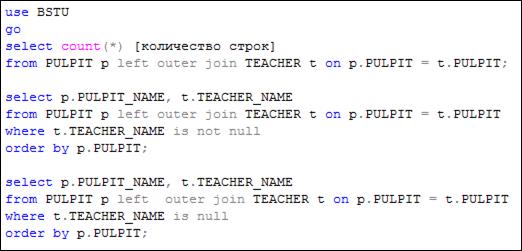
Рис. 7.37. SELECT-запросы, содержащие левое внешнее соединение двух таблиц: PULPIT и TEACHER
На рис. 7.38–7.40 продемонстрированы результирующие наборы, сформированные тремя запросами, представленными на рис. 7.37.
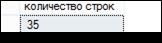
Рис. 7.38. Результат выполнения первого SELECT-запроса на рис. 7.37

Рис. 7.39. Результат выполнения второго SELECT-запроса на рис. 7.37
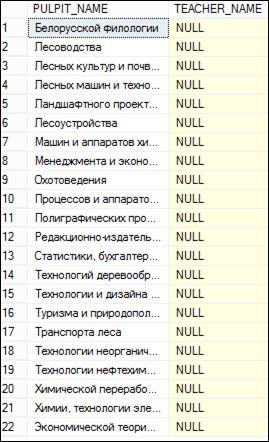
Рис. 7.40. Результат выполнения третьего SELECT-запроса на рис. 7.37
Необходимо обратить внимание на следующее: на рис. 7.39 результирующий набор содержит те же строки, что и результирующий набор на рис. 7.35; на рис. 7.40 результирующий набор содержит те же строки, что и результирующий набор на рис. 7.36; если у второго или третьего SELECT-запроса на рис. 7.37 убрать секцию WHERE, то результирующий набор такого запроса будет содержать 35 строк (рис. 7.38), являющихся объединением двух результирующих наборов, представленных на рис. 7.39 и 7.40; столбец TEACHER_ NAME принимает значение NULL в строках результирующего набора, соответствующих несоединенным строкам (рис. 7.40).
Заметим, что, в общем случае, соединение OUTER JOIN не коммутативно. На рис. 7.41 представлен SELECT-запрос, в котором используется левое внешнее соединение между таблицами TEACHER и PULPIT. Обратите внимание: таблицы при соединении перечислены в обратном порядке, нежели в запросах на рис. 7.37; количество строк в результирующем наборе равно 13 (против 35 на рис. 7.37). Таким образом, внешнее соединение на рис. 7.41 соединяет все 13 строк (рис. 7.42) таблицы TEACHER с 13 строками таблицы PULPIT. Такое совпадение обусловлено еще и тем, что у таблицы TEACHER существует ограничение FOREIGN KEY, ссылающееся на таблицу PULPIT и поэтому, в принципе, нельзя добавить в таблицу TEACHER значения, которые не свяжутся по заданному логическому выражению в ON с таблицей PULPIT.
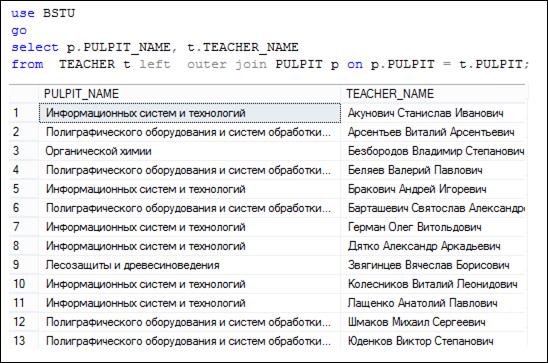
Рис. 7.41. Левое внешнее соединение с обратным порядком таблиц по отношению к соединению в запросах на рис. 7.37
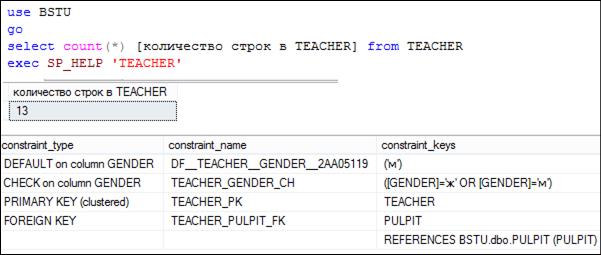
Рис. 7.42. Количество строк в таблице TEACHER (равно 13), ограничение FOREIGN KEY таблицы TEACHER
Рассмотрим правое внешнее соединение между таблицами PULPIT и TEACHER. На рис. 7.43 представлен пример использования соединения RIGHT OUTER JOIN между таблицами PULPIT и TEACHER.
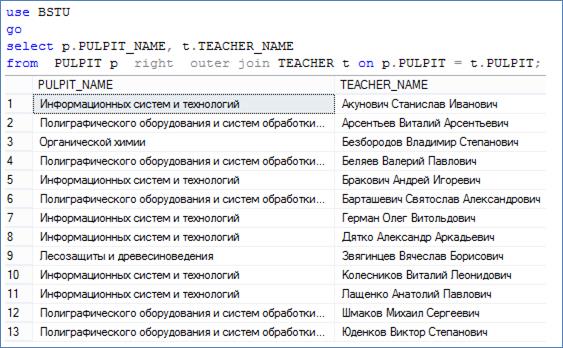
Рис. 7.43. Пример правого внешнего соединения таблицы PULPIT и TEACHER
Обратите внимание: результат запроса на рис. 7.43 совпадает с результатом запроса на рис. 7.41.
Возьмем за основу сценарий на рис. 7.37, поменяем порядок таблиц, изменим вид внешнего соединения LEFT на RIGHT и получим сценарий, представленный на рис. 7.44.
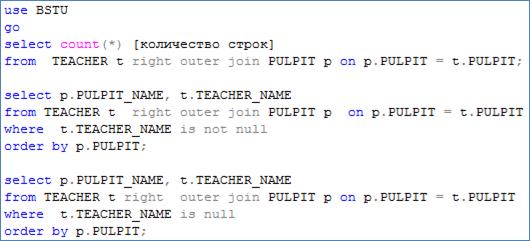
Рис. 7.44. Модифицированный сценарий на рис. 7.37: изменен порядок таблиц в соединении и вид внешнего соединения LEFT на RIGHT
В результате выполнения сценария на рис. 7.44 формируется три результирующих набора (рис. 7.45–7.47).
Рис. 7.45. Результат выполнения первого SELECT-запроса на рис. 7.44

Рис. 7.46. Результат выполнения второго SELECT-запроса на рис. 7.44
Не сложно заметить, что результаты, полученные после выполнения сценариев на рис. 7.37 и 7.44., совпадают. Проведенные исследования позволяют сформулировать следующее правило. Если в SELECT-запросе с внешним соединением двух таблиц:
1) поменять порядок соединения этих таблиц;
2) изменить вид внешнего соединения на альтернативный, то получим SELECT-запрос, формирующий результирующий набор, совпадающий с результирующим набором исходного SELECT-запроса.
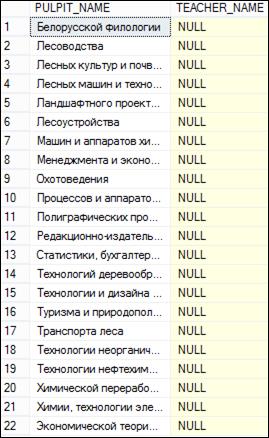
Рис. 7.47. Результат выполнения третьего SELECT-запроса на рис. 7.44
Как и прежде, вместо таблицы допускается использование подзапроса. На рис. 7.48 представлен запрос с применением соединения трех таблиц FACULTY, PULPIT и TEACHER.
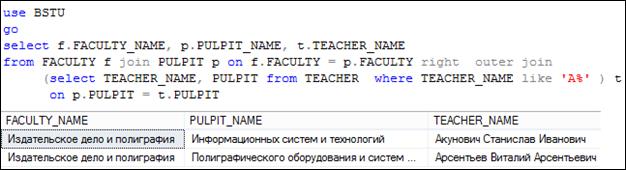
Рис. 7.48. SELECT-запрос, использующий внутреннее соединение
и внешнее соединение с подзапросом
Между FACULTY и PULPUIT установлено внутреннее соединение, результат которого с помощью правого внешнего соединения связан с результатом SELECT-запроса над таблицей TEACHER (выбираются строки, у которых значение столбца TEACHER_ NAME начинается с символа A).
Секция WHERE
Исходным набором строк для секции WHERE является результирующий набор секции FROM. Секция WHERE предназначена для фильтрации строки, содержит логическое выражение, вычисляемое для каждой строки исходного набора. Если значение логического выражения принимает значение «истина», то строка помещается в результирующий набор секции WHERE. На рис. 7.48 представлен SELECT-запрос, выполняющий пять подзапросов, применяющих секцию WHERE для отбора (фильтрации) строк из таблицы AUDITORIUM (в данном случае результирующий набор секции FROM состоит из всех строк таблицы AUDITORIUM).
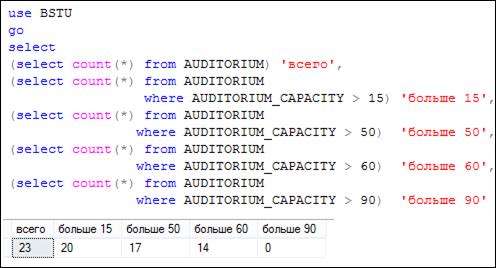
Рис. 7.49. Вычисление количества строк в результирующих
наборах подзапросов
Все подзапросы на рис. 7.49 в секции WHERE применяют логическое выражение, сравнивающее значение в столбце AUDITORIUM_ CAPACITY с заданной величиной. Функция COUNT (более подробно рассматривается позже) подсчитывает количество строк, которое сформировал бы SELECT-запрос (но в данных запросах выводит только одну строку), если бы не применялась агрегатная функция. Обратите внимание: последний запрос сформировал бы пустой результирующий набор (количество строк равно нулю).
Запрос на рис. 7.50 формирует и выводит результирующий набор, состоящий из 14 строк. Сравните с количеством строк, вычисленным в четвертом подзапросе на рис. 7.49.
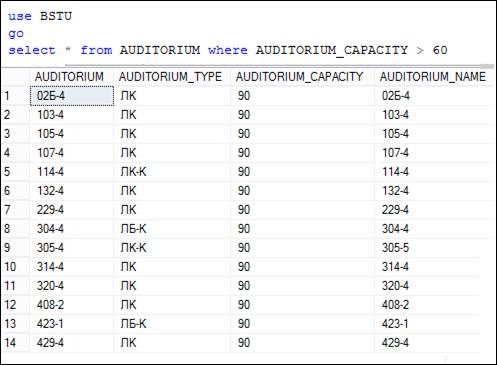
Рис. 7.50. Простейший SELECT-запрос, формирующий 14 строк
в результирующий набор секции WHERE
Операции сравнения
Логические выражения, применяемые в секции WHERE, как правило, основываются на операциях сравнения (табл. 7.1).
Таблица 7.1
Операции сравнения
| Символ | Операция сравнения |
| = | Равенство |
| <> | Неравенство |
| != | Неравенство |
| > | Больше |
| >= | Больше или равно |
| < | Меньше |
| <= | Меньше или равно |
Операции сравнения применимы ко всем основным типам данных: числовым, денежным, символьным, датам и времени.
На рис. 7.51–7.53 представлены примеры использования операций сравнения в секции WHERE.
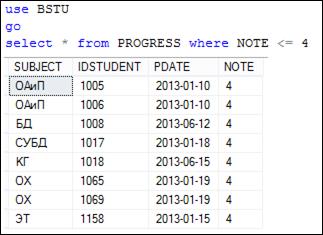
Рис. 7.51. Применение в секции WHERE операции «меньше или равно»
для сравнения числовых значений
Применение операций сравнения для чисел не вызывает сложности понимания, т. к. сравнение осуществляется естественным для чисел способом. Аналогично сравниваются денежные данные.
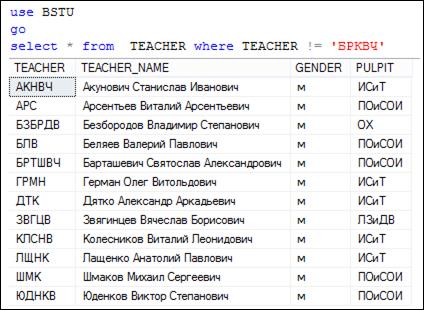
Рис. 7.52. Применение в секции WHERE операции «не равно»
для сравнения строковых значений
Сравнение строк осуществляется общепринятым в программировании способом: если сравниваются две строки, состоящие из одинакового количества символов, то сравниваются два числа, образованные кодами символов, входящими в эти строки; если строки состоят из разного количества символов, то короткая строка дополняется необходимым количеством пробелов справа и сравнение сводится к первому варианту. Следует также отметить, что на сравнение строк влияет параметр COLLATION, значение которого может быть установлено на уровне БД, столбца таблицы или операции сравнения. Подробные сведения об этом системном параметре можно получить в пособии [5].
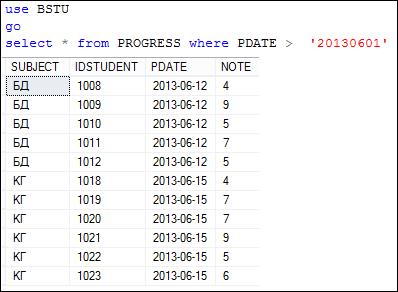
Рис. 7.53. Применение в секции WHERE операции «больше» для сравнения даты
При сравнении двух дат большей считается та, которая хронологически на оси времени расположена правее. Аналогично сравнивается время. Если в операции сравнения дат или времени необходимо применить литералы, то применять их следует в соответствии с правилами, описанными в п. 5.2.1.3, или применять явное преобразование к соответствующему типу с помощью функций CAST или CONVERT.
Сравнение строк
Кроме общепринятых операций (табл. 7.1) для сравнения строк применяются предикаты: LIKE, CONTAINS и FREETEXT. Предикатом называется выражение, значениями которого могут быть только «истина» и «ложь».
Предикаты CONTAINS и FREETEXT чаще применяются при полнотекстовом поиске, поэтому здесь они не рассматриваются. Для ознакомления с их возможностями рекомендуется воспользоваться пособием [5].
Предикат LIKE позволяет осуществлять сравнение одной строки с множеством строк, заданным с помощью шаблона. Шаблон – это строка, которая с помощью специальных символов позволяет описать множество строк. При этом LIKE принимает значение «истина» в том случае, если сравниваемая строка будет найдена во множестве строк, описанном с помощью шаблона. Или говорят иначе – если строка будет соответствовать заданному шаблону.
Приведем несколько типичных примеров использования предиката LIKE. Запрос на рис. 7.54 демонстрирует содержимое столбца QUALIFICATION таблицы PROFESSION, а запросы на рис. 7.55–7.58 демонстрируют применение LIKE с шаблоном на основе специального символа %.
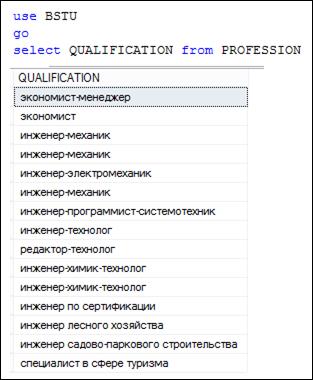
Рис. 7.54. Содержимое столбца QUALIFICATION таблицы PROFESSION
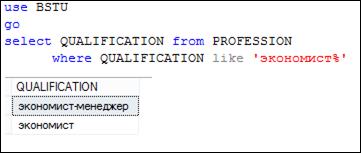
Рис. 7.55. Выбор строк, начинающихся с цепочки символов экономист в столбце QUALIFICATION таблицы PROFESSION
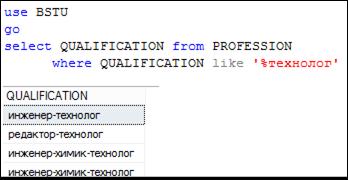
Рис. 7.56. Выбор строк, завершающихся цепочкой символов технолог
в столбце QUALIFICATION таблицы PROFESSION
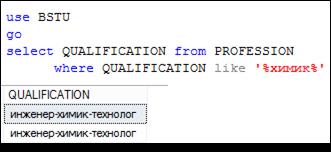
Рис. 7.57. Выбор строк, содержащих цепочку символов химик
в столбце QUALIFICATION таблицы PROFESSION
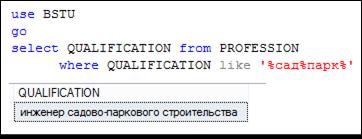
Рис. 7.58. Выбор строк, содержащих последовательно две цепочки символов
сад и парк в столбце QUALIFICATION таблицы PROFESSION
Символ % обозначает любое (включая ноль) количество любых символов. Шаблон экономист% описывает множество строк, которые начинаются с цепочки символов экономист, %технолог – множество строк, заканчивающихся цепочкой символов технолог, а шаблон %химик% – множество строк, содержащих цепочку химик. В шаблоне можно указать несколько цепочек. Например, %сад%парк% описывает множество строк, содержащих последовательно две цепочки символов сад и парк.
На рис. 7.59 демонстрируется шаблон с применением символа _ (подчеркивание). Этот символ означает, что вместо него может стоять ровно один любой символ. Обратите внимание, что в сочетании с символом % символ подчеркивание позволяет указать, что требуется как минимум один любой символ.
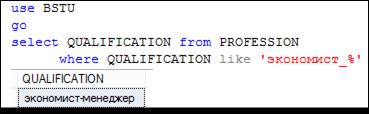
Рис. 7.59. Выбор строк, начинающихся с цепочки символов экономист
и следующего за ней любого символа в столбце QUALIFICATION
таблицы PROFESSION
Более подробно о возможностях описания множества строк с помощью шаблонов, можно узнать в издании [5].
Сравнение значений NULL
На рис. 7.60 представлен пример, демонстрирующий корректное и некорректное сравнение величин в секции WHERE.
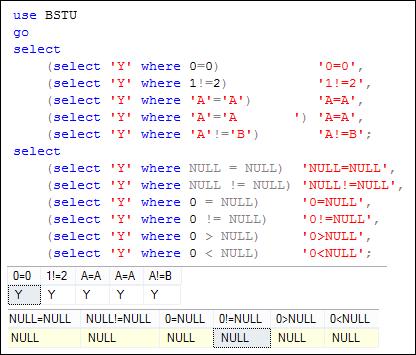
Рис. 7.60. Сравнение с NULL в секции WHERE
Корректное сравнение демонстрируется с помощью пяти подзапросов в первом операторе SELECT, некорректное – во втором. Некорректность вызвана применением операторов сравнения к значениям NULL. Обратите внимание: результат второго SELECT-запроса содержит во всех столбцах значение NULL – признак неопределенности (в данном случае – отсутствия) значения.
Сравнения со значением NULL допускается только с помощью операции IS NULL, либо IS NOT NULL (рис. 7.61).
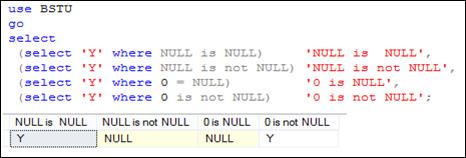
Рис. 7.61. Сравнение с NULL с помощью операции IS NULL
На рис. 7.62 представлен пример использования операции IS NULL для поиска строк в таблице PULPIT, содержащих в столбце FACULTY значение NULL.

Рис. 7.62. Фильтрация строк в таблице PULPIT с помощью операции IS NULL
С помощью оператора UPDATE (подробно разбирается позже) во всех строках таблицы PULPIT со значением ЛХФ в столбце FACULTY это значение заменяется на NULL. Затем выполняется SELECT-запрос, использующий в секции WHERE операцию IS NULL для выбора строк со значением NULL в столбце FACULTY.
На рис. 7.63 представлен пример использования операций IS NULL и IS NOT NULL при подсчете строк в таблице PULPIT.
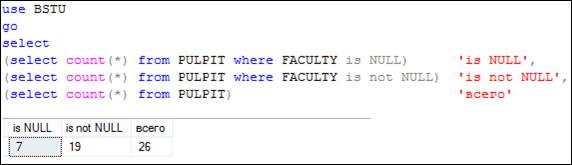
Рис. 7.63. Применение IS NULL и IS NOT NULL в секции WHERE подзапросов
При использовании значения NULL в столбцах таблицы следует помнить следующее.
1. Для поиска строк со значениями NULL необходимо применять только операции IS NULL или IS NOT NULL.
2. Результатом любой другой операции, использующей в качестве операнда значение NULL, является NULL.
3. В секции WHERE значение логического выражения равное NULL интерпретируется как «ложь».
Для удобства работы с NULL-значениями предназначены две встроенные функции IS NULL и COALESCE.
На рис. 7.64 приведен пример использования функции IS NULL в SELECT-списке, а также фрагмент результирующего набора.
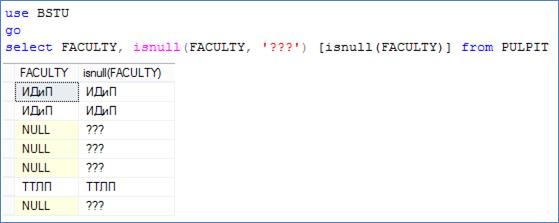
Рис. 7.64. Применение встроенной функции IS NULL в SELECT-списке
Функция IS NULL принимает два параметра и проверяет их значения на NULL слева направо. Функция возвращает первое значение не равное NULL.
Функция COALESCE очень похожа на IS NULL, но может принимать любое количество параметров. Аналогично функции IS NULL она слева направо проверяет значения параметров и возвращает первое значение не равное NULL (рис. 7.65).
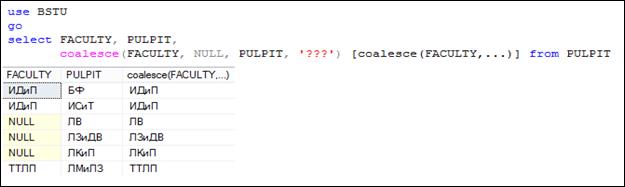
Рис. 7.65. Применение встроенной функции COALESCE в SELECT-списке
Функции IS NULL и COALESCE можно применять в секции WHERE. На рис. 7.66 приведен пример SELECT-запроса, использующего функцию IS NULL в секции WHERE.

Рис. 7.66. Применение встроенной функции ISNULL
в секции WHERE SELECT-запроса
Дата: 2019-02-25, просмотров: 395.